 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Weak Form Generalized Hamiltonian Learning
Apr 11, 2021

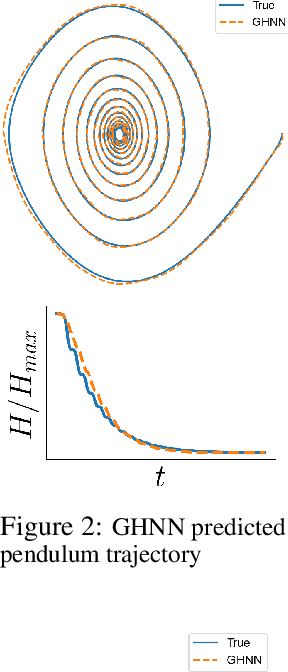


We present a method for learning generalized Hamiltonian decompositions of ordinary differential equations given a set of noisy time series measurements. Our method simultaneously learns a continuous time model and a scalar energy function for a general dynamical system. Learning predictive models in this form allows one to place strong, high-level, physics inspired priors onto the form of the learnt governing equations for general dynamical systems. Moreover, having shown how our method extends and unifies some previous work in deep learning with physics inspired priors, we present a novel method for learning continuous time models from the weak form of the governing equations which is less computationally taxing than standard adjoint methods.
* 34th Conference on Neural Information Processing Systems, 18 pages
Giga-voxel multidimensional fluorescence imaging combining single-pixel detection and data fusion
Jul 26, 2021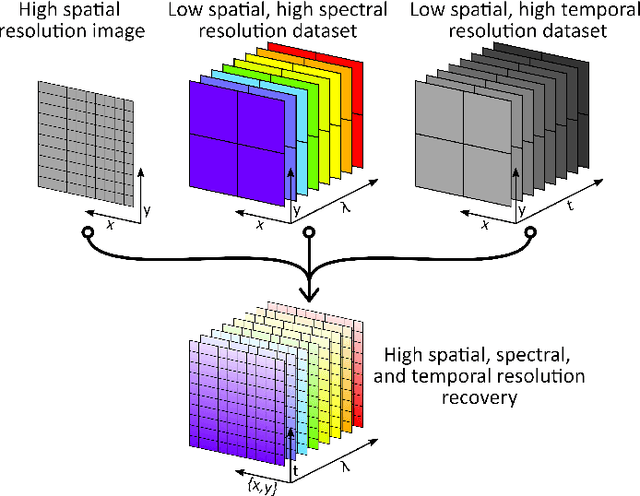
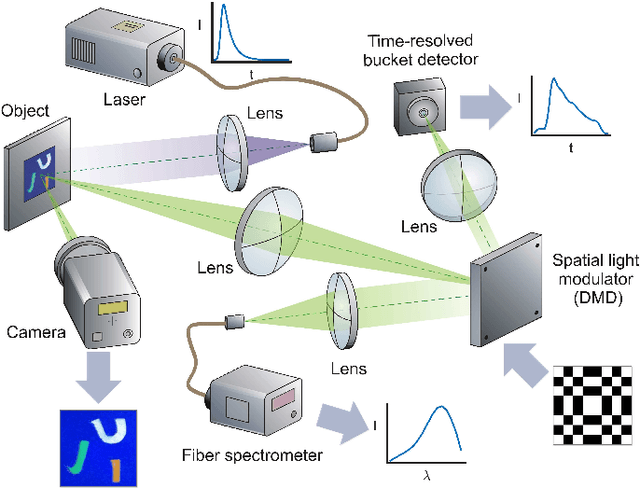
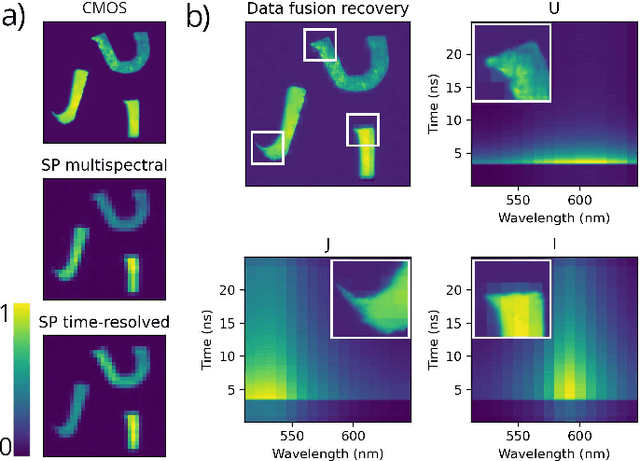
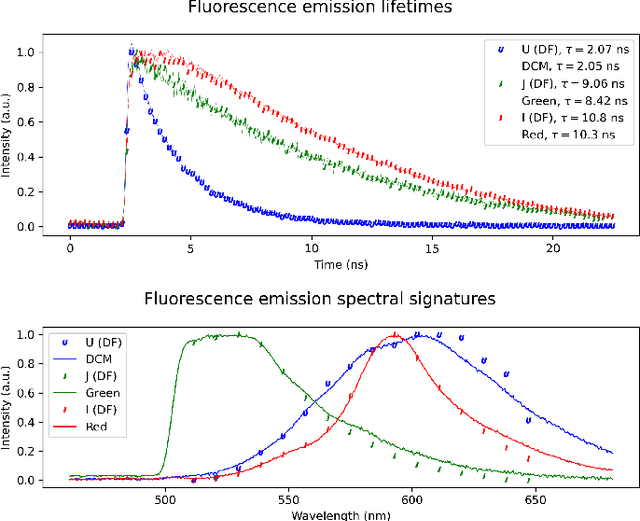
Time-resolved fluorescence imaging is a key tool in biomedical applications, as it allows to non-invasively obtain functional and structural information. However, the big amount of collected data introduces challenges in both acquisition speed and processing needs. Here, we introduce a novel technique that allows to reconstruct a Giga-voxel 4D hypercube in a fast manner while only measuring 0.03 % of the information. The system combines two single-pixel cameras and a conventional 2D array detector working in parallel. Data fusion techniques are introduced to combine the individual 2D and 3D projections acquired by each sensor in the final high-resolution 4D hypercube, which can be used to identify different fluorophore species by their spectral and temporal signatures.
A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the United States
Sep 24, 2021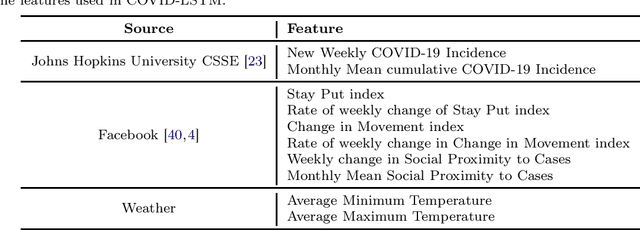
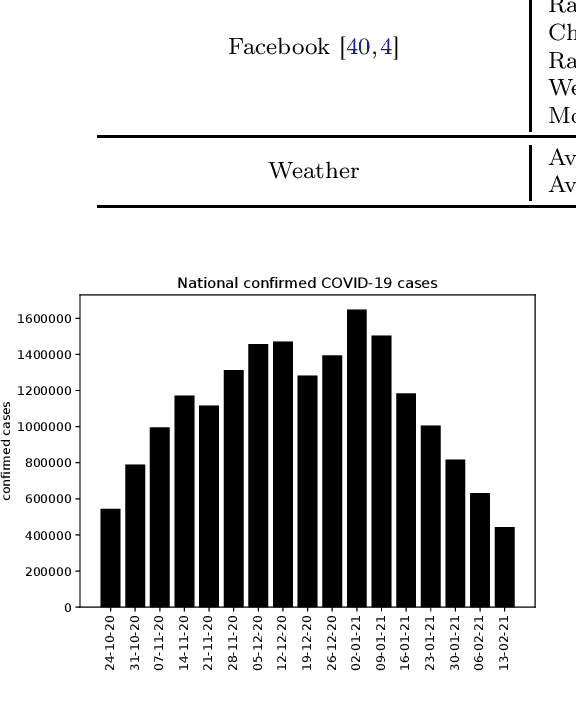
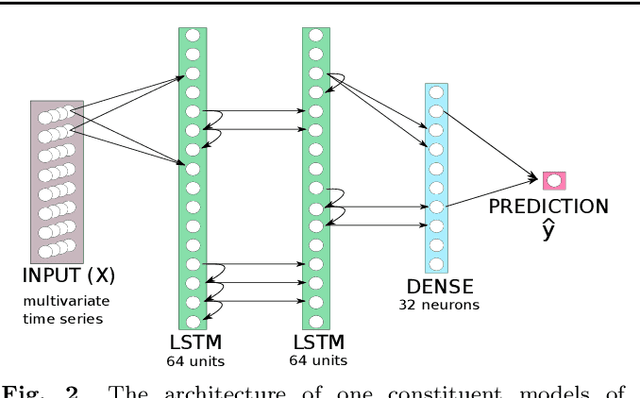
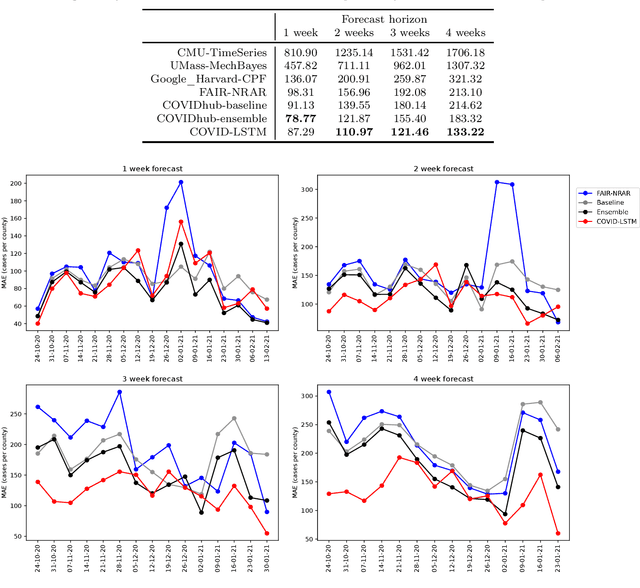
With COVID-19 affecting every country globally and changing everyday life, the ability to forecast the spread of the disease is more important than any previous epidemic. The conventional methods of disease-spread modeling, compartmental models, are based on the assumption of spatiotemporal homogeneity of the spread of the virus, which may cause forecasting to underperform, especially at high spatial resolutions. In this paper we approach the forecasting task with an alternative technique -- spatiotemporal machine learning. We present COVID-LSTM, a data-driven model based on a Long Short-term Memory deep learning architecture for forecasting COVID-19 incidence at the county-level in the US. We use the weekly number of new positive cases as temporal input, and hand-engineered spatial features from Facebook movement and connectedness datasets to capture the spread of the disease in time and space. COVID-LSTM outperforms the COVID-19 Forecast Hub's Ensemble model (COVIDhub-ensemble) on our 17-week evaluation period, making it the first model to be more accurate than the COVIDhub-ensemble over one or more forecast periods. Over the 4-week forecast horizon, our model is on average 50 cases per county more accurate than the COVIDhub-ensemble. We highlight that the underutilization of data-driven forecasting of disease spread prior to COVID-19 is likely due to the lack of sufficient data available for previous diseases, in addition to the recent advances in machine learning methods for spatiotemporal forecasting. We discuss the impediments to the wider uptake of data-driven forecasting, and whether it is likely that more deep learning-based models will be used in the future.
Federated Learning for Internet of Things: A Federated Learning Framework for On-device Anomaly Data Detection
Jun 15, 2021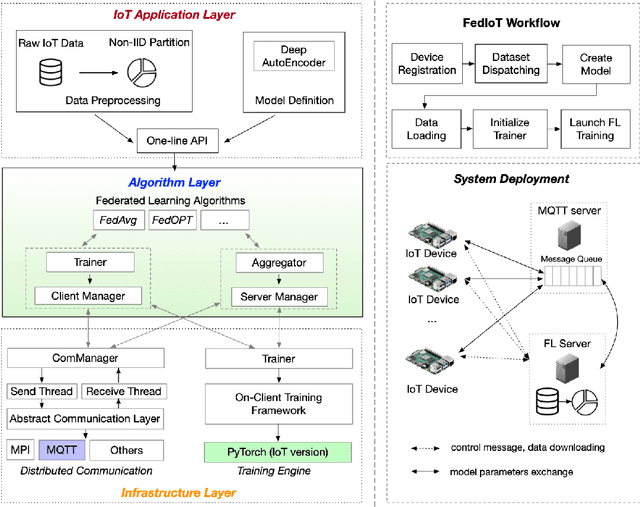
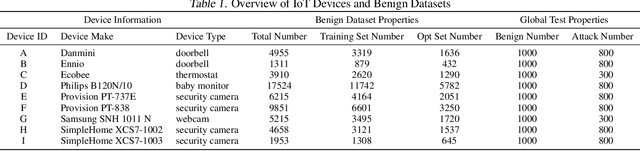

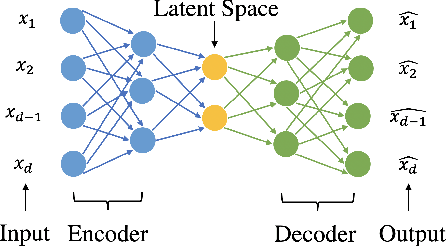
Federated learning can be a promising solution for enabling IoT cybersecurity (i.e., anomaly detection in the IoT environment) while preserving data privacy and mitigating the high communication/storage overhead (e.g., high-frequency data from time-series sensors) of centralized over-the-cloud approaches. In this paper, to further push forward this direction with a comprehensive study in both algorithm and system design, we build FedIoT platform that contains a synthesized dataset using N-BaIoT, FedDetect algorithm, and a system design for IoT devices. Furthermore, the proposed FedDetect learning framework improves the performance by utilizing an adaptive optimizer (e.g., Adam) and a cross-round learning rate scheduler. In a network of realistic IoT devices (Raspberry PI), we evaluate FedIoT platform and FedDetect algorithm in both model and system performance. Our results demonstrate the efficacy of federated learning in detecting a large range of attack types. The system efficiency analysis indicates that both end-to-end training time and memory cost are affordable and promising for resource-constrained IoT devices. The source code is publicly available.
Deep Learning to Ternary Hash Codes by Continuation
Jul 16, 2021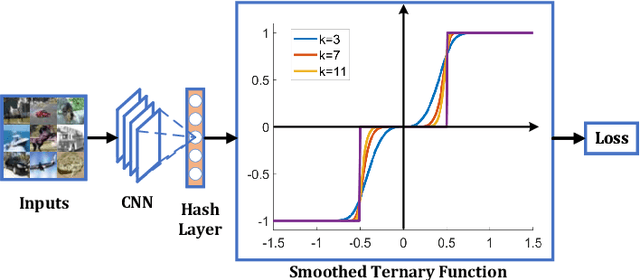
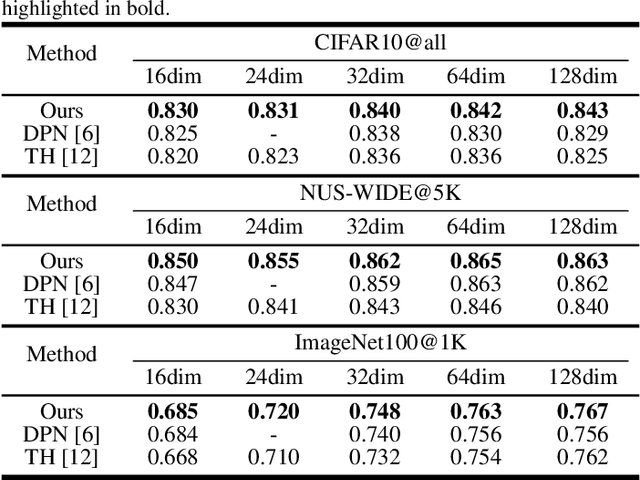
Recently, it has been observed that {0,1,-1}-ternary codes which are simply generated from deep features by hard thresholding, tend to outperform {-1,1}-binary codes in image retrieval. To obtain better ternary codes, we for the first time propose to jointly learn the features with the codes by appending a smoothed function to the networks. During training, the function could evolve into a non-smoothed ternary function by a continuation method. The method circumvents the difficulty of directly training discrete functions and reduces the quantization errors of ternary codes. Experiments show that the generated codes indeed could achieve higher retrieval accuracy.
Detection of data drift and outliers affecting machine learning model performance over time
Jan 20, 2021

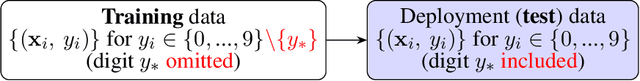
A trained ML model is deployed on another `test' dataset where target feature values (labels) are unknown. Drift is distribution change between the training and deployment data, which is concerning if model performance changes. For a cat/dog image classifier, for instance, drift during deployment could be rabbit images (new class) or cat/dog images with changed characteristics (change in distribution). We wish to detect these changes but can't measure accuracy without deployment data labels. We instead detect drift indirectly by nonparametrically testing the distribution of model prediction confidence for changes. This generalizes our method and sidesteps domain-specific feature representation. We address important statistical issues, particularly Type-1 error control in sequential testing, using Change Point Models (CPMs; see Adams and Ross 2012). We also use nonparametric outlier methods to show the user suspicious observations for model diagnosis, since the before/after change confidence distributions overlap significantly. In experiments to demonstrate robustness, we train on a subset of MNIST digit classes, then insert drift (e.g., unseen digit class) in deployment data in various settings (gradual/sudden changes in the drift proportion). A novel loss function is introduced to compare the performance (detection delay, Type-1 and 2 errors) of a drift detector under different levels of drift class contamination.
A Single Example Can Improve Zero-Shot Data Generation
Aug 16, 2021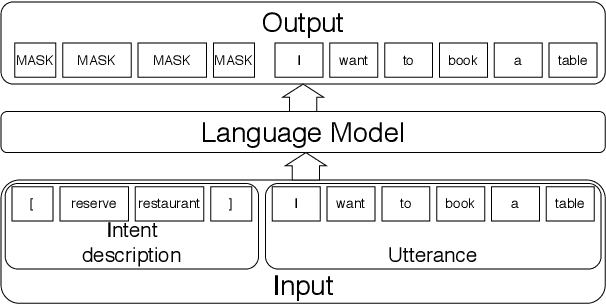
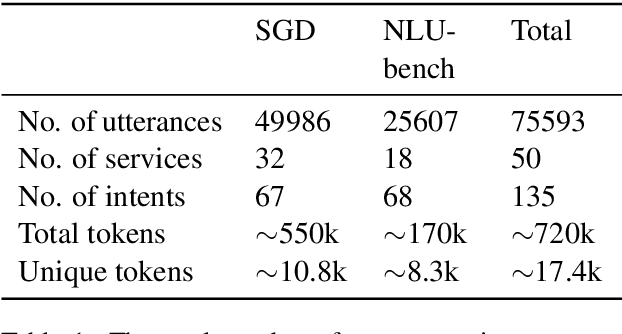
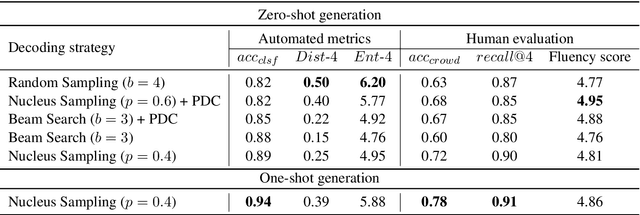
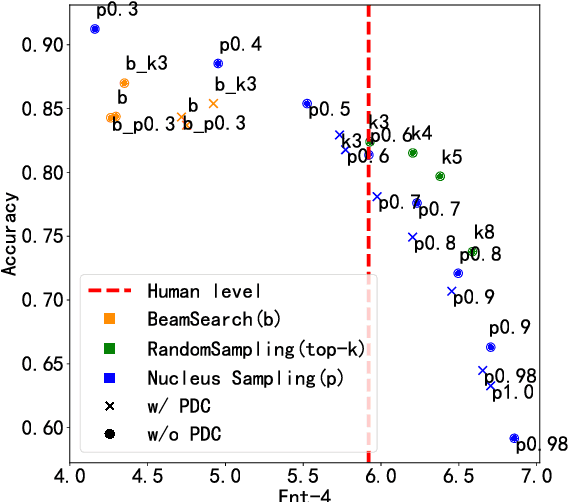
Sub-tasks of intent classification, such as robustness to distribution shift, adaptation to specific user groups and personalization, out-of-domain detection, require extensive and flexible datasets for experiments and evaluation. As collecting such datasets is time- and labor-consuming, we propose to use text generation methods to gather datasets. The generator should be trained to generate utterances that belong to the given intent. We explore two approaches to generating task-oriented utterances. In the zero-shot approach, the model is trained to generate utterances from seen intents and is further used to generate utterances for intents unseen during training. In the one-shot approach, the model is presented with a single utterance from a test intent. We perform a thorough automatic, and human evaluation of the dataset generated utilizing two proposed approaches. Our results reveal that the attributes of the generated data are close to original test sets, collected via crowd-sourcing.
Surface Defect Classification in Real-Time Using Convolutional Neural Networks
Apr 07, 2019
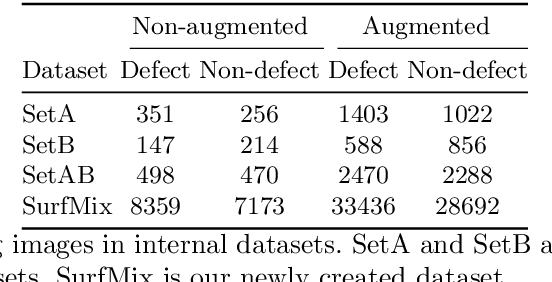
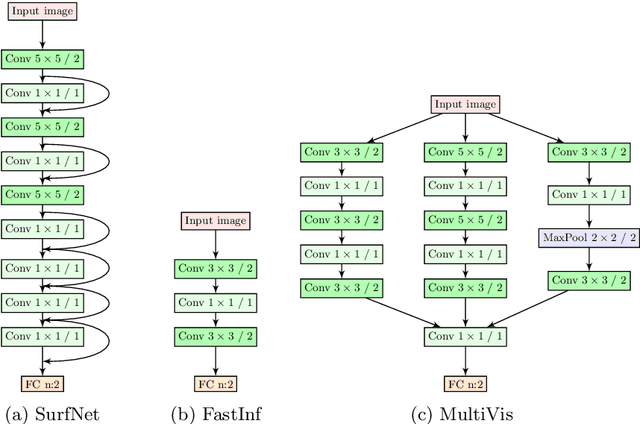
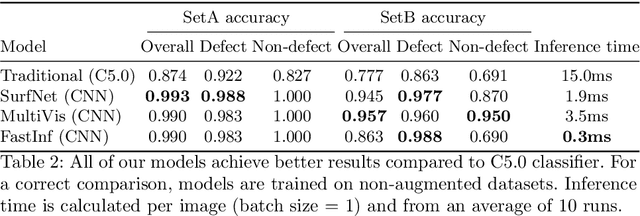
Surface inspection systems are an important application domain for computer vision, as they are used for defect detection and classification in the manufacturing industry. Existing systems use hand-crafted features which require extensive domain knowledge to create. Even though Convolutional neural networks (CNNs) have proven successful in many large-scale challenges, industrial inspection systems have yet barely realized their potential due to two significant challenges: real-time processing speed requirements and specialized narrow domain-specific datasets which are sometimes limited in size. In this paper, we propose CNN models that are specifically designed to handle capacity and real-time speed requirements of surface inspection systems. To train and evaluate our network models, we created a surface image dataset containing more than 22000 labeled images with many types of surface materials and achieved 98.0% accuracy in binary defect classification. To solve the class imbalance problem in our datasets, we introduce neural data augmentation methods which are also applicable to similar domains that suffer from the same problem. Our results show that deep learning based methods are feasible to be used in surface inspection systems and outperform traditional methods in accuracy and inference time by considerable margins.
Multimodal analysis of the predictability of hand-gesture properties
Aug 12, 2021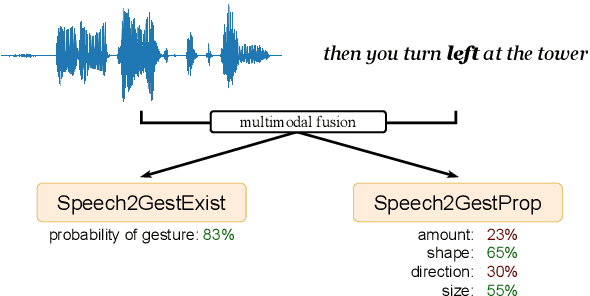
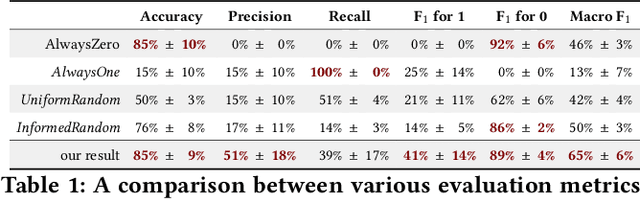
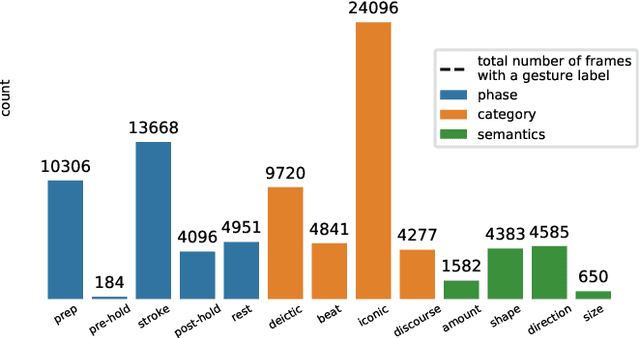
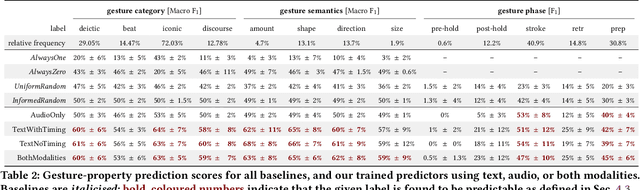
Embodied conversational agents benefit from being able to accompany their speech with gestures. Although many data-driven approaches to gesture generation have been proposed in recent years, it is still unclear whether such systems can consistently generate gestures that convey meaning. We investigate which gesture properties (phase, category, and semantics) can be predicted from speech text and/or audio using contemporary deep learning. In extensive experiments, we show that gesture properties related to gesture meaning (semantics and category) are predictable from text features (time-aligned BERT embeddings) alone, but not from prosodic audio features, while rhythm-related gesture properties (phase) on the other hand can be predicted from either audio, text (with word-level timing information), or both. These results are encouraging as they indicate that it is possible to equip an embodied agent with content-wise meaningful co-speech gestures using a machine-learning model.
Two-Stage Mesh Deep Learning for Automated Tooth Segmentation and Landmark Localization on 3D Intraoral Scans
Sep 24, 2021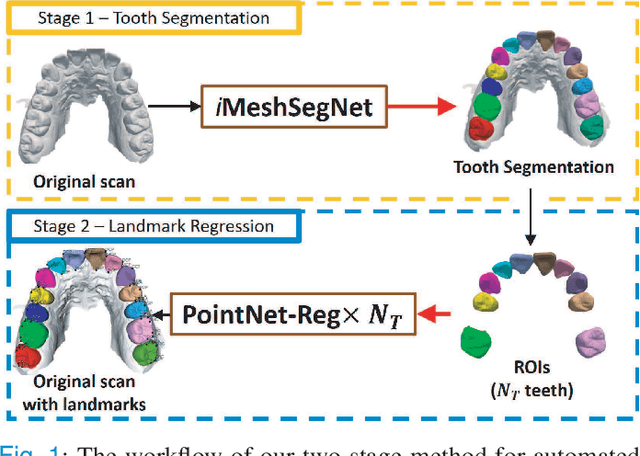
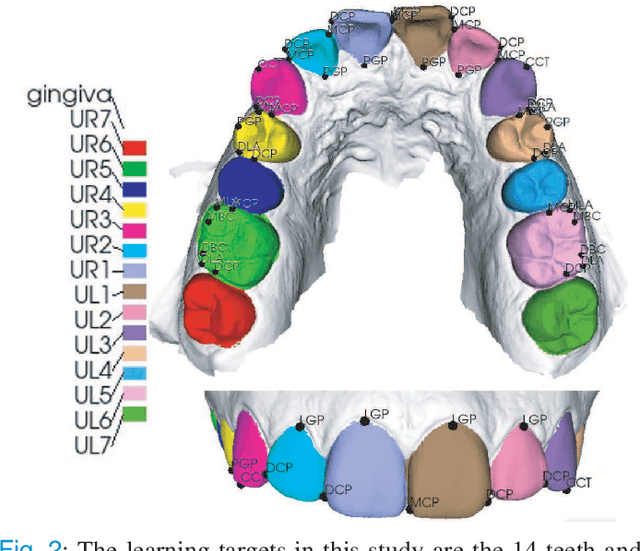
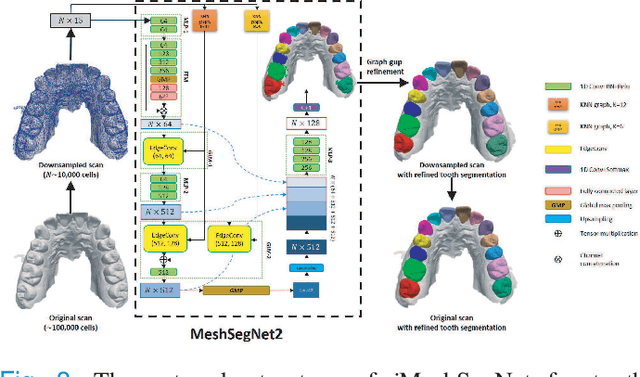
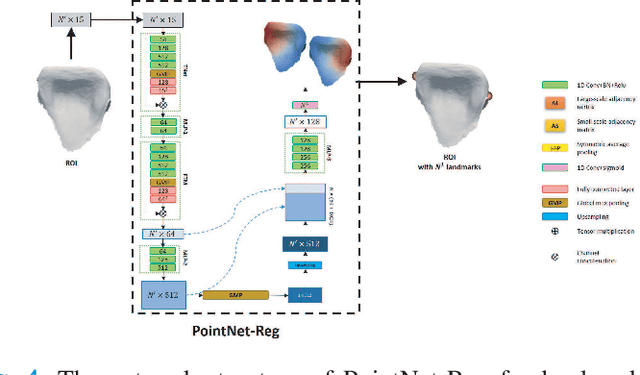
Accurately segmenting teeth and identifying the corresponding anatomical landmarks on dental mesh models are essential in computer-aided orthodontic treatment. Manually performing these two tasks is time-consuming, tedious, and, more importantly, highly dependent on orthodontists' experiences due to the abnormality and large-scale variance of patients' teeth. Some machine learning-based methods have been designed and applied in the orthodontic field to automatically segment dental meshes (e.g., intraoral scans). In contrast, the number of studies on tooth landmark localization is still limited. This paper proposes a two-stage framework based on mesh deep learning (called TS-MDL) for joint tooth labeling and landmark identification on raw intraoral scans. Our TS-MDL first adopts an end-to-end \emph{i}MeshSegNet method (i.e., a variant of the existing MeshSegNet with both improved accuracy and efficiency) to label each tooth on the downsampled scan. Guided by the segmentation outputs, our TS-MDL further selects each tooth's region of interest (ROI) on the original mesh to construct a light-weight variant of the pioneering PointNet (i.e., PointNet-Reg) for regressing the corresponding landmark heatmaps. Our TS-MDL was evaluated on a real-clinical dataset, showing promising segmentation and localization performance. Specifically, \emph{i}MeshSegNet in the first stage of TS-MDL reached an averaged Dice similarity coefficient (DSC) at $0.953\pm0.076$, significantly outperforming the original MeshSegNet. In the second stage, PointNet-Reg achieved a mean absolute error (MAE) of $0.623\pm0.718 \, mm$ in distances between the prediction and ground truth for $44$ landmarks, which is superior compared with other networks for landmark detection. All these results suggest the potential usage of our TS-MDL in clinical practices.