 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Experimental Validation of Linear and Nonlinear MPC on an Articulated Unmanned Ground Vehicle
Mar 25, 2021

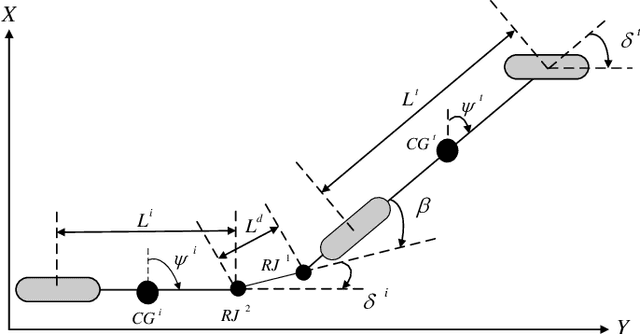
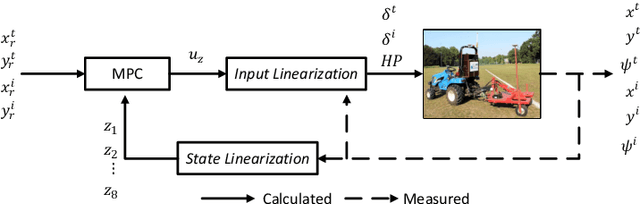
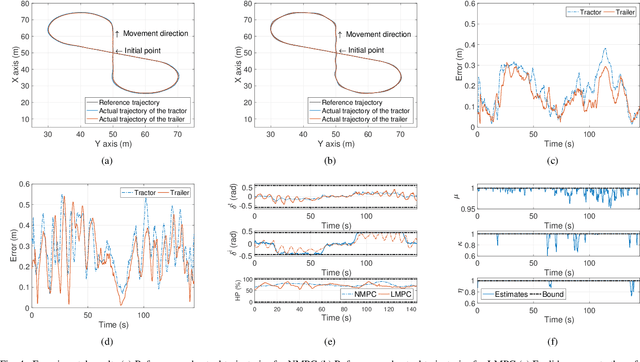
This paper focuses on the trajectory tracking control problem for an articulated unmanned ground vehicle. We propose and compare two approaches in terms of performance and computational complexity. The first uses a nonlinear mathematical model derived from first principles and combines a nonlinear model predictive controller (NMPC) with a nonlinear moving horizon estimator (NMHE) to produce a control strategy. The second is based on an input-state linearization (ISL) of the original model followed by linear model predictive control (LMPC). A fast real-time iteration scheme is proposed, implemented for the NMHE-NMPC framework and benchmarked against the ISL-LMPC framework, which is a traditional and cheap method. The experimental results for a time-based trajectory show that the NMHE-NMPC framework with the proposed real-time iteration scheme gives better trajectory tracking performance than the ISL-LMPC framework and the required computation time is feasible for real-time applications. Moreover, the ISL-LMPC produces results of a quality comparable to the NMHE-NMPC framework at a significantly reduced computational cost.
Distributed Transformations of Hamiltonian Shapes based on Line Moves
Aug 24, 2021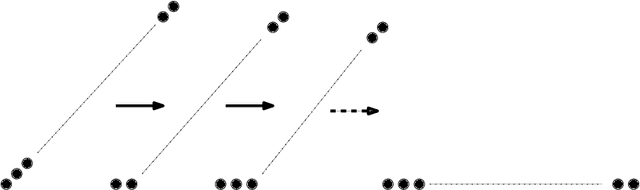
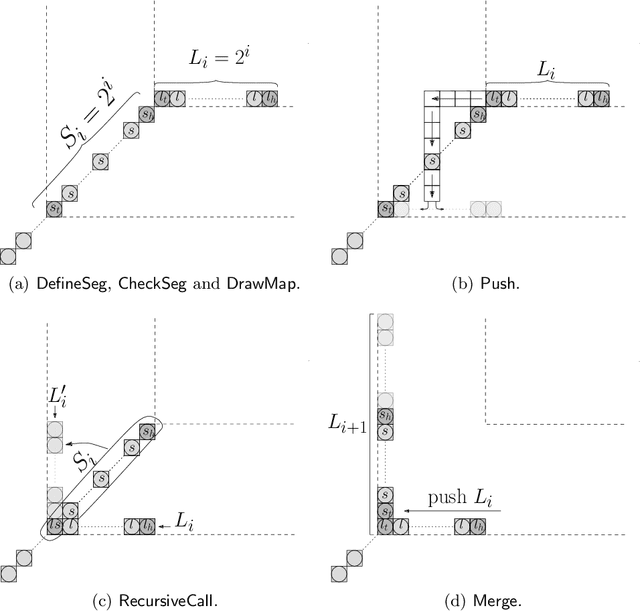
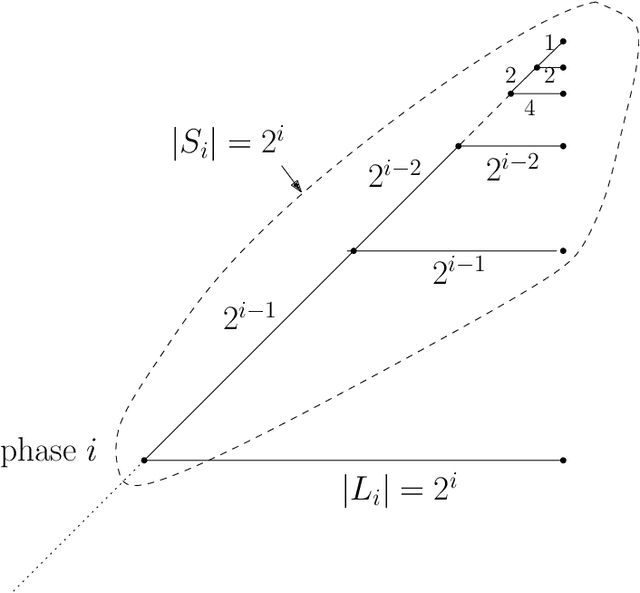

We consider a discrete system of $n$ simple indistinguishable devices, called \emph{agents}, forming a \emph{connected} shape $S_I$ on a two-dimensional square grid. Agents are equipped with a linear-strength mechanism, called a \emph{line move}, by which an agent can push a whole line of consecutive agents in one of the four directions in a single time-step. We study the problem of transforming an initial shape $S_I$ into a given target shape $S_F$ via a finite sequence of line moves in a distributed model, where each agent can observe the states of nearby agents in a Moore neighbourhood. Our main contribution is the first distributed connectivity-preserving transformation that exploits line moves within a total of $O(n \log_2 n)$ moves, which is asymptotically equivalent to that of the best-known centralised transformations. The algorithm solves the \emph{line formation problem} that allows agents to form a final straight line $S_L$, starting from any shape $ S_I $, whose \emph{associated graph} contains a Hamiltonian path.
Deep 3D Mask Volume for View Synthesis of Dynamic Scenes
Aug 30, 2021
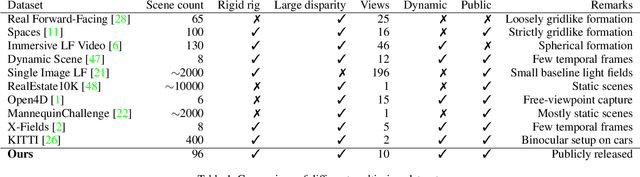


Image view synthesis has seen great success in reconstructing photorealistic visuals, thanks to deep learning and various novel representations. The next key step in immersive virtual experiences is view synthesis of dynamic scenes. However, several challenges exist due to the lack of high-quality training datasets, and the additional time dimension for videos of dynamic scenes. To address this issue, we introduce a multi-view video dataset, captured with a custom 10-camera rig in 120FPS. The dataset contains 96 high-quality scenes showing various visual effects and human interactions in outdoor scenes. We develop a new algorithm, Deep 3D Mask Volume, which enables temporally-stable view extrapolation from binocular videos of dynamic scenes, captured by static cameras. Our algorithm addresses the temporal inconsistency of disocclusions by identifying the error-prone areas with a 3D mask volume, and replaces them with static background observed throughout the video. Our method enables manipulation in 3D space as opposed to simple 2D masks, We demonstrate better temporal stability than frame-by-frame static view synthesis methods, or those that use 2D masks. The resulting view synthesis videos show minimal flickering artifacts and allow for larger translational movements.
BFTrainer: Low-Cost Training of Neural Networks on Unfillable Supercomputer Nodes
Jun 22, 2021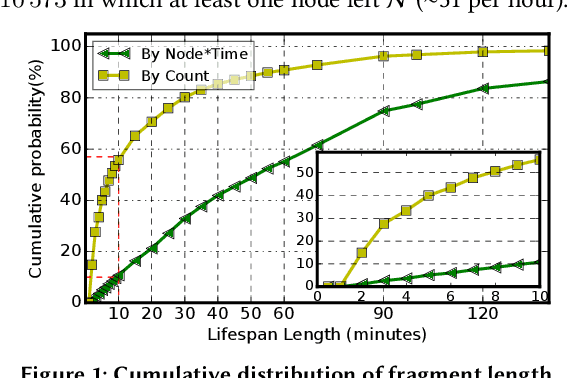
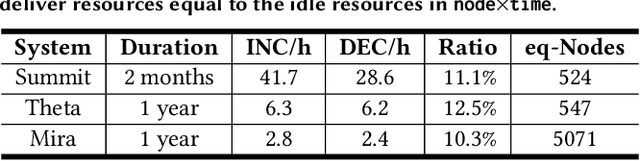
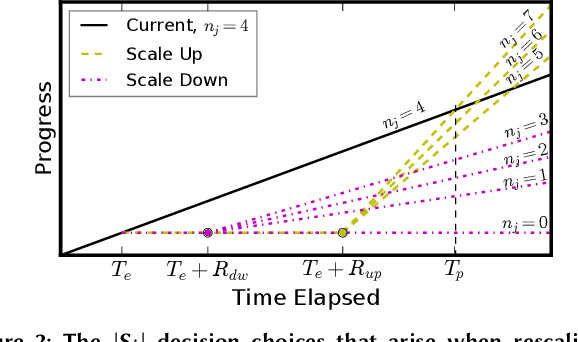

Supercomputer FCFS-based scheduling policies result in many transient idle nodes, a phenomenon that is only partially alleviated by backfill scheduling methods that promote small jobs to run before large jobs. Here we describe how to realize a novel use for these otherwise wasted resources, namely, deep neural network (DNN) training. This important workload is easily organized as many small fragments that can be configured dynamically to fit essentially any node*time hole in a supercomputer's schedule. We describe how the task of rescaling suitable DNN training tasks to fit dynamically changing holes can be formulated as a deterministic mixed integer linear programming (MILP)-based resource allocation algorithm, and show that this MILP problem can be solved efficiently at run time. We show further how this MILP problem can be adapted to optimize for administrator- or user-defined metrics. We validate our method with supercomputer scheduler logs and different DNN training scenarios, and demonstrate efficiencies of up to 93% compared with running the same training tasks on dedicated nodes. Our method thus enables substantial supercomputer resources to be allocated to DNN training with no impact on other applications.
Shaping Individualized Impedance Landscapes for Gait Training via Reinforcement Learning
Sep 05, 2021



Assist-as-needed (AAN) control aims at promoting therapeutic outcomes in robot-assisted rehabilitation by encouraging patients' active participation. Impedance control is used by most AAN controllers to create a compliant force field around a target motion to ensure tracking accuracy while allowing moderate kinematic errors. However, since the parameters governing the shape of the force field are often tuned manually or adapted online based on simplistic assumptions about subjects' learning abilities, the effectiveness of conventional AAN controllers may be limited. In this work, we propose a novel adaptive AAN controller that is capable of autonomously reshaping the force field in a phase-dependent manner according to each individual's motor abilities and task requirements. The proposed controller consists of a modified Policy Improvement with Path Integral algorithm, a model-free, sampling-based reinforcement learning method that learns a subject-specific impedance landscape in real-time, and a hierarchical policy parameter evaluation structure that embeds the AAN paradigm by specifying performance-driven learning goals. The adaptability of the proposed control strategy to subjects' motor responses and its ability to promote short-term motor adaptations are experimentally validated through treadmill training sessions with able-bodied subjects who learned altered gait patterns with the assistance of a powered ankle-foot orthosis.
Multi-output Bus Travel Time Prediction with Convolutional LSTM Neural Network
Mar 07, 2019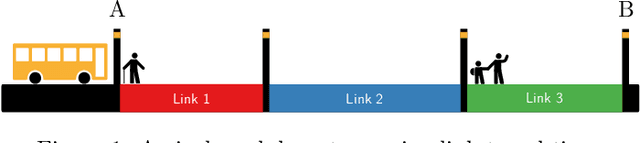

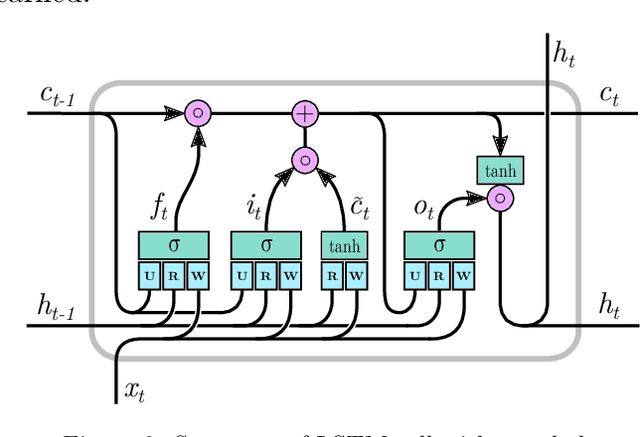
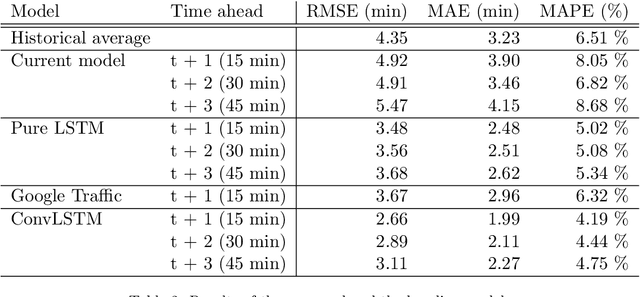
Accurate and reliable travel time predictions in public transport networks are essential for delivering an attractive service that is able to compete with other modes of transport in urban areas. The traditional application of this information, where arrival and departure predictions are displayed on digital boards, is highly visible in the city landscape of most modern metropolises. More recently, the same information has become critical as input for smart-phone trip planners in order to alert passengers about unreachable connections, alternative route choices and prolonged travel times. More sophisticated Intelligent Transport Systems (ITS) include the predictions of connection assurance, i.e. to hold back services in case a connecting service is delayed. In order to operate such systems, and to ensure the confidence of passengers in the systems, the information provided must be accurate and reliable. Traditional methods have trouble with this as congestion, and thus travel time variability, increases in cities, consequently making travel time predictions in urban areas a non-trivial task. This paper presents a system for bus travel time prediction that leverages the non-static spatio-temporal correlations present in urban bus networks, allowing the discovery of complex patterns not captured by traditional methods. The underlying model is a multi-output, multi-time-step, deep neural network that uses a combination of convolutional and long short-term memory (LSTM) layers. The method is empirically evaluated and compared to other popular approaches for link travel time prediction and currently available services, including the currently deployed model in Copenhagen, Denmark. We find that the proposed model significantly outperforms all the other methods we compare with, and is able to detect small irregular peaks in bus travel times very quickly.
Dense Pruning of Pointwise Convolutions in the Frequency Domain
Sep 16, 2021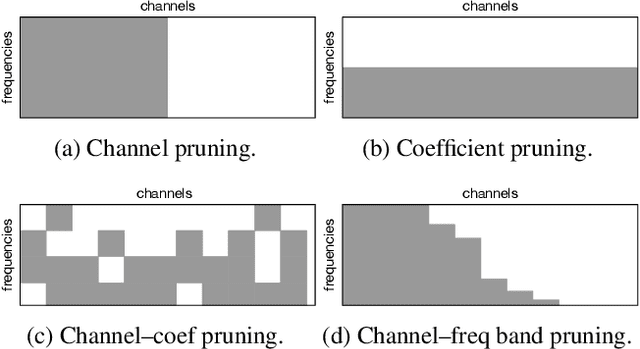

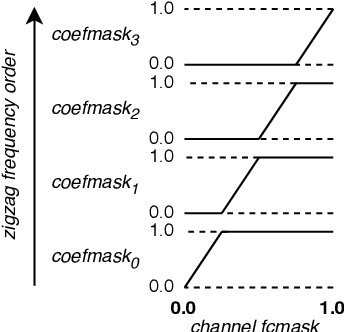

Depthwise separable convolutions and frequency-domain convolutions are two recent ideas for building efficient convolutional neural networks. They are seemingly incompatible: the vast majority of operations in depthwise separable CNNs are in pointwise convolutional layers, but pointwise layers use 1x1 kernels, which do not benefit from frequency transformation. This paper unifies these two ideas by transforming the activations, not the kernels. Our key insights are that 1) pointwise convolutions commute with frequency transformation and thus can be computed in the frequency domain without modification, 2) each channel within a given layer has a different level of sensitivity to frequency domain pruning, and 3) each channel's sensitivity to frequency pruning is approximately monotonic with respect to frequency. We leverage this knowledge by proposing a new technique which wraps each pointwise layer in a discrete cosine transform (DCT) which is truncated to selectively prune coefficients above a given threshold as per the needs of each channel. To learn which frequencies should be pruned from which channels, we introduce a novel learned parameter which specifies each channel's pruning threshold. We add a new regularization term which incentivizes the model to decrease the number of retained frequencies while still maintaining task accuracy. Unlike weight pruning techniques which rely on sparse operators, our contiguous frequency band pruning results in fully dense computation. We apply our technique to MobileNetV2 and in the process reduce computation time by 22% and incur <1% accuracy degradation.
SurpriseNet: Melody Harmonization Conditioning on User-controlled Surprise Contours
Aug 24, 2021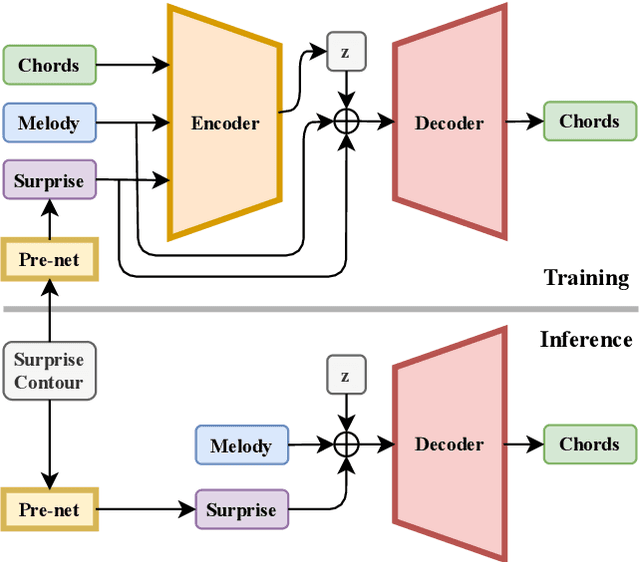
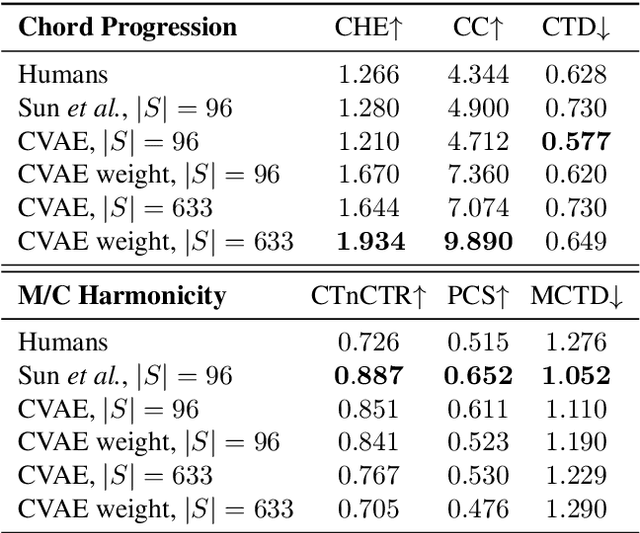
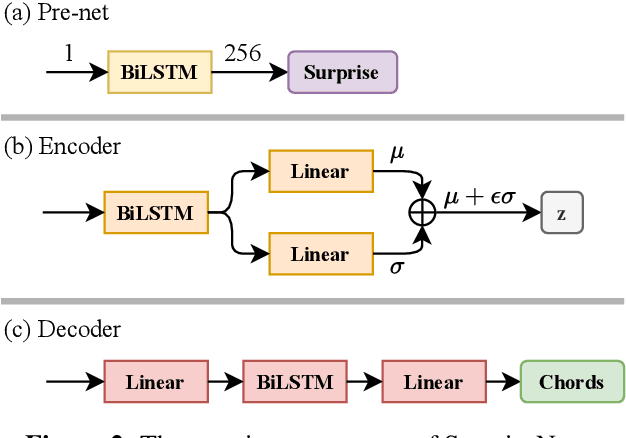

The surprisingness of a song is an essential and seemingly subjective factor in determining whether the listener likes it. With the help of information theory, it can be described as the transition probability of a music sequence modeled as a Markov chain. In this study, we introduce the concept of deriving entropy variations over time, so that the surprise contour of each chord sequence can be extracted. Based on this, we propose a user-controllable framework that uses a conditional variational autoencoder (CVAE) to harmonize the melody based on the given chord surprise indication. Through explicit conditions, the model can randomly generate various and harmonic chord progressions for a melody, and the Spearman's correlation and p-value significance show that the resulting chord progressions match the given surprise contour quite well. The vanilla CVAE model was evaluated in a basic melody harmonization task (no surprise control) in terms of six objective metrics. The results of experiments on the Hooktheory Lead Sheet Dataset show that our model achieves performance comparable to the state-of-the-art melody harmonization model.
Automatic Head Overcoat Thickness Measure with NASNet-Large-Decoder Net
Jun 22, 2021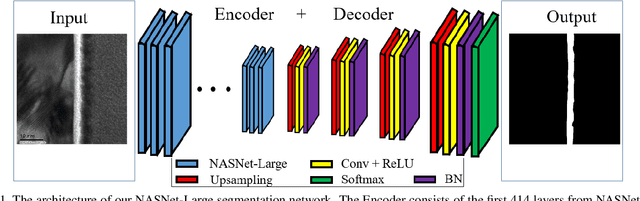
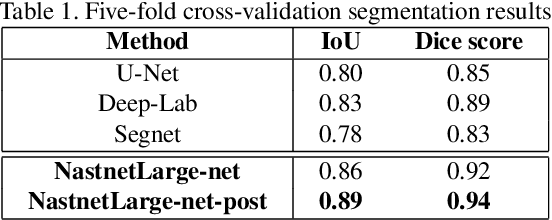
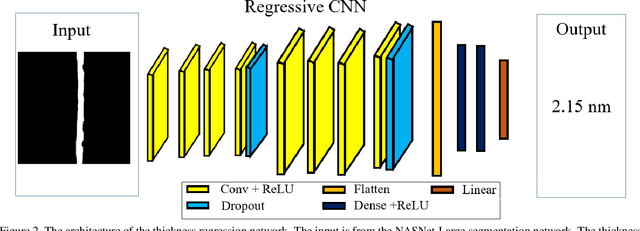
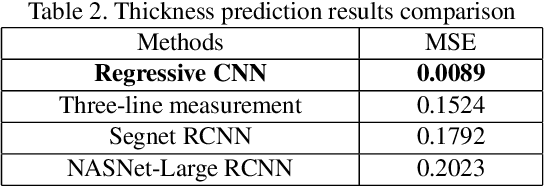
Transmission electron microscopy (TEM) is one of the primary tools to show microstructural characterization of materials as well as film thickness. However, manual determination of film thickness from TEM images is time-consuming as well as subjective, especially when the films in question are very thin and the need for measurement precision is very high. Such is the case for head overcoat (HOC) thickness measurements in the magnetic hard disk drive industry. It is therefore necessary to develop software to automatically measure HOC thickness. In this paper, for the first time, we propose a HOC layer segmentation method using NASNet-Large as an encoder and then followed by a decoder architecture, which is one of the most commonly used architectures in deep learning for image segmentation. To further improve segmentation results, we are the first to propose a post-processing layer to remove irrelevant portions in the segmentation result. To measure the thickness of the segmented HOC layer, we propose a regressive convolutional neural network (RCNN) model as well as orthogonal thickness calculation methods. Experimental results demonstrate a higher dice score for our model which has lower mean squared error and outperforms current state-of-the-art manual measurement.
Clustering of check-in sequences using the mixture Markov chain process
Jun 16, 2021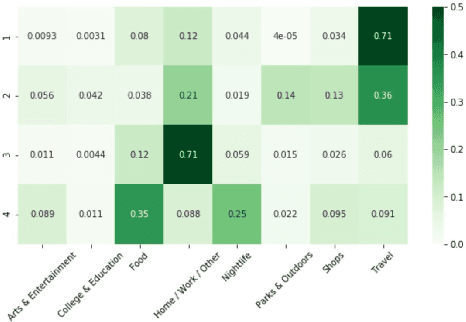
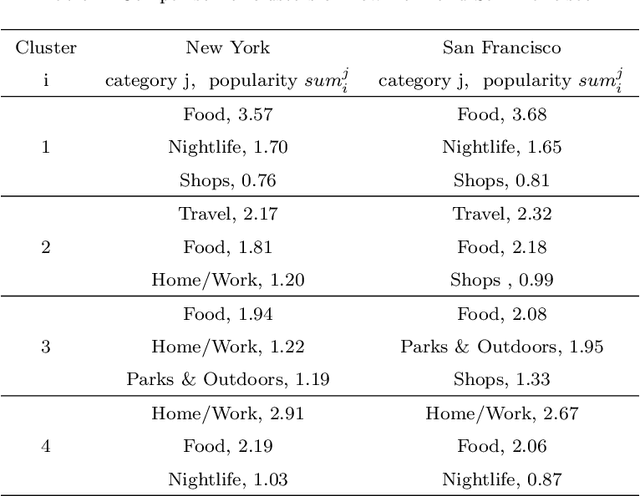
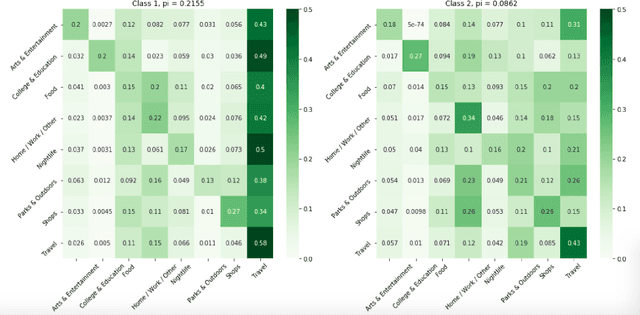
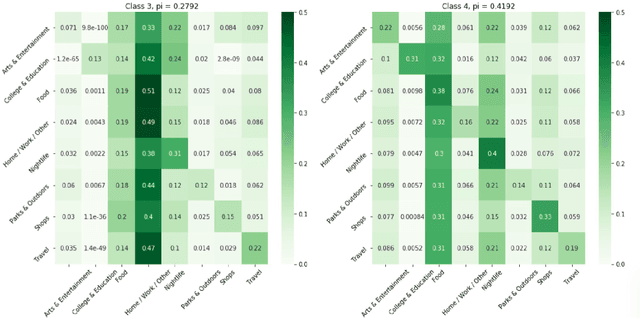
This work is devoted to the clustering of check-in sequences from a geosocial network. We used the mixture Markov chain process as a mathematical model for time-dependent types of data. For clustering, we adjusted the Expectation-Maximization (EM) algorithm. As a result, we obtained highly detailed communities (clusters) of users of the now defunct geosocial network, Weeplaces.