 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Bayesian Unsupervised Lifelong Learning
Jun 13, 2021
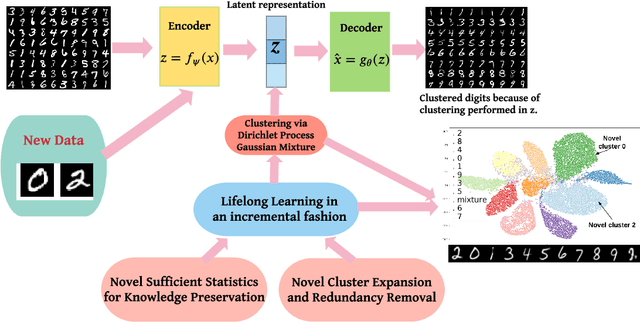

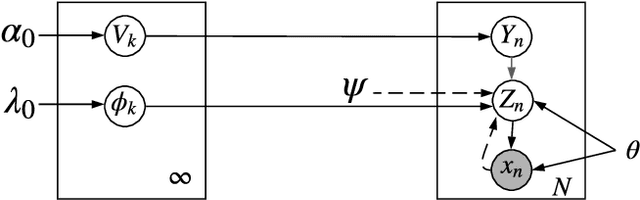
Lifelong Learning (LL) refers to the ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Much attention has been given lately to Supervised Lifelong Learning (SLL) with a stream of labelled data. In contrast, we focus on resolving challenges in Unsupervised Lifelong Learning (ULL) with streaming unlabelled data when the data distribution and the unknown class labels evolve over time. Bayesian framework is natural to incorporate past knowledge and sequentially update the belief with new data. We develop a fully Bayesian inference framework for ULL with a novel end-to-end Deep Bayesian Unsupervised Lifelong Learning (DBULL) algorithm, which can progressively discover new clusters without forgetting the past with unlabelled data while learning latent representations. To efficiently maintain past knowledge, we develop a novel knowledge preservation mechanism via sufficient statistics of the latent representation for raw data. To detect the potential new clusters on the fly, we develop an automatic cluster discovery and redundancy removal strategy in our inference inspired by Nonparametric Bayesian statistics techniques. We demonstrate the effectiveness of our approach using image and text corpora benchmark datasets in both LL and batch settings.
A Novel Low Complexity Faster-than-Nyquist (FTN) Signaling Detector for Ultra High-Order QAM
Jul 02, 2021



Faster-than-Nyquist (FTN) signaling is a promising non-orthogonal pulse modulation technique that can improve the spectral efficiency (SE) of next generation communication systems at the expense of higher detection complexity to remove the introduced inter-symbol interference (ISI). In this paper, we investigate the detection problem of ultra high-order quadrature-amplitude modulation (QAM) FTN signaling where we exploit a mathematical programming technique based on the alternating directions multiplier method (ADMM). The proposed ADMM sequence estimation (ADMMSE) FTN signaling detector demonstrates an excellent trade-off between performance and computational effort enabling, for the first time in the FTN signaling literature, successful detection and SE gains for QAM modulation orders as high as 64K (65,536). The complexity of the proposed ADMMSE detector is polynomial in the length of the transmit symbols sequence and its sensitivity to the modulation order increases only logarithmically. Simulation results show that for 16-QAM, the proposed ADMMSE FTN signaling detector achieves comparable SE gains to the generalized approach semidefinite relaxation-based sequence estimation (GASDRSE) FTN signaling detector, but at an experimentally evaluated much lower computational time. Simulation results additionally show SE gains for modulation orders starting from 4-QAM, or quadrature phase shift keying (QPSK), up to and including 64K-QAM when compared to conventional Nyquist signaling. The very low computational effort required makes the proposed ADMMSE detector a practically promising FTN signaling detector for both low order and ultra high-order QAM FTN signaling systems.
Adaptive Dynamic Programming for Model-free Tracking of Trajectories with Time-varying Parameters
Oct 28, 2019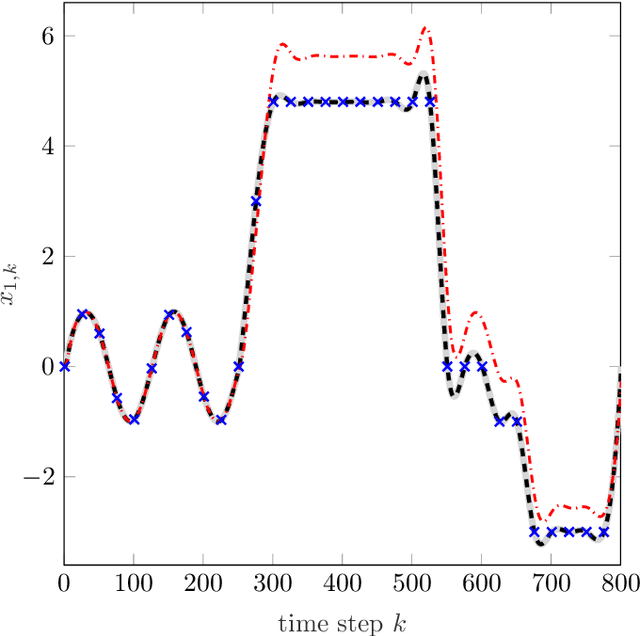
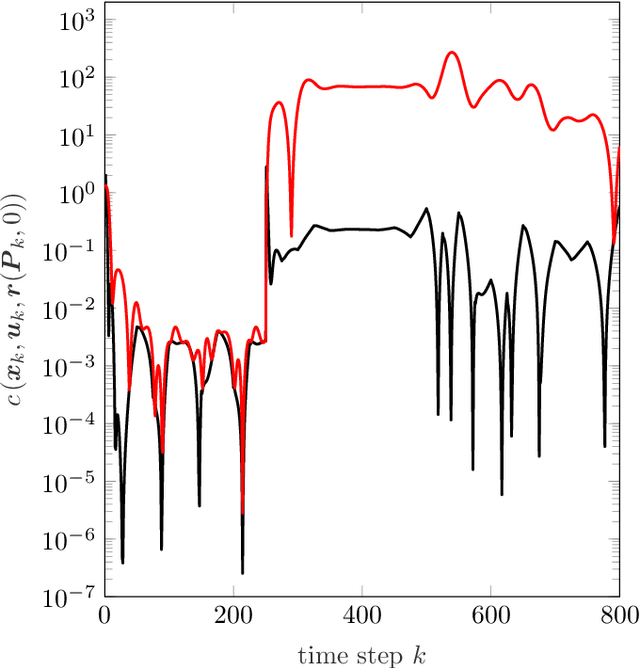
In order to autonomously learn to control unknown systems optimally w.r.t. an objective function, Adaptive Dynamic Programming (ADP) is well-suited to adapt controllers based on experience from interaction with the system. In recent years, many researchers focused on the tracking case, where the aim is to follow a desired trajectory. So far, ADP tracking controllers assume that the reference trajectory follows time-invariant exo-system dynamics-an assumption that does not hold for many applications. In order to overcome this limitation, we propose a new Q-function which explicitly incorporates a parametrized approximation of the reference trajectory. This allows to learn to track a general class of trajectories by means of ADP. Once our Q-function has been learned, the associated controller copes with time-varying reference trajectories without need of further training and independent of exo-system dynamics. After proposing our general model-free off-policy tracking method, we provide analysis of the important special case of linear quadratic tracking. We conclude our paper with an example which demonstrates that our new method successfully learns the optimal tracking controller and outperforms existing approaches in terms of tracking error and cost.
Communication constrained cloud-based long-term visual localization in real time
Mar 10, 2019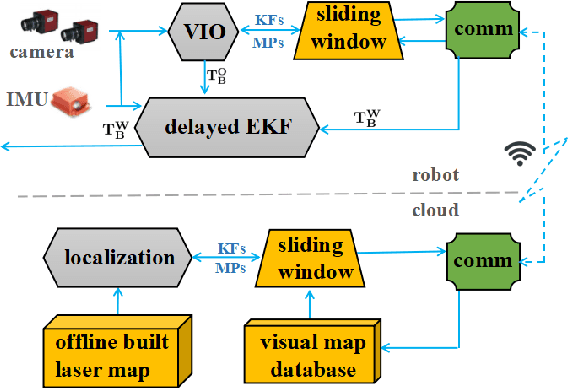
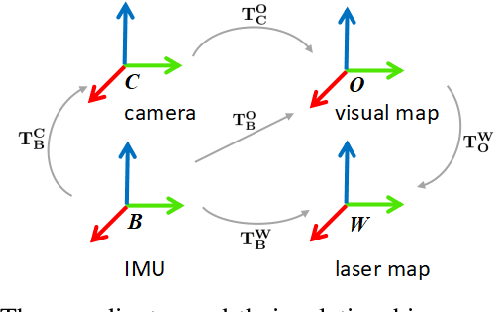

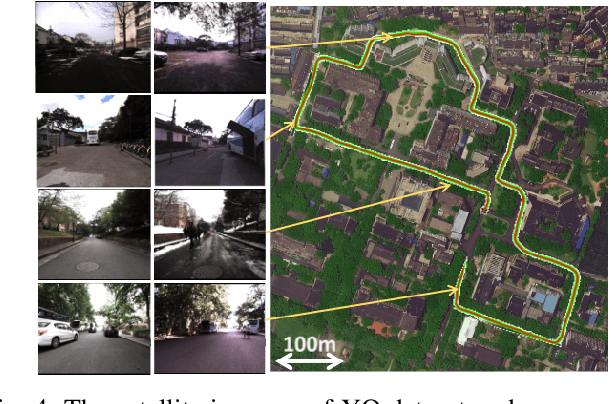
Visual localization is one of the primary capabilities for mobile robots. Long-term visual localization in real time is particularly challenging, in which the robot is required to efficiently localize itself using visual data where appearance may change significantly over time. In this paper, we propose a cloud-based visual localization system targeting at long-term localization in real time. On the robot, we employ two estimators to achieve accurate and real-time performance. One is a sliding-window based visual inertial odometry, which integrates constraints from consecutive observations and self-motion measurements, as well as the constraints induced by localization on the cloud. This estimator builds a local visual submap as the virtual observation which is then sent to the cloud as new localization constraints. The other one is a delayed state Extended Kalman Filter to fuse the pose of the robot localized from the cloud, the local odometry and the high-frequency inertial measurements. On the cloud, we propose a longer sliding-window based localization method to aggregate the virtual observations for larger field of view, leading to more robust alignment between virtual observations and the map. Under this architecture, the robot can achieve drift-free and real-time localization using onboard resources even in a network with limited bandwidth, high latency and existence of package loss, which enables the autonomous navigation in real-world environment. We evaluate the effectiveness of our system on a dataset with challenging seasonal and illuminative variations. We further validate the robustness of the system under challenging network conditions.
User-Centric Semi-Automated Infographics Authoring and Recommendation
Aug 27, 2021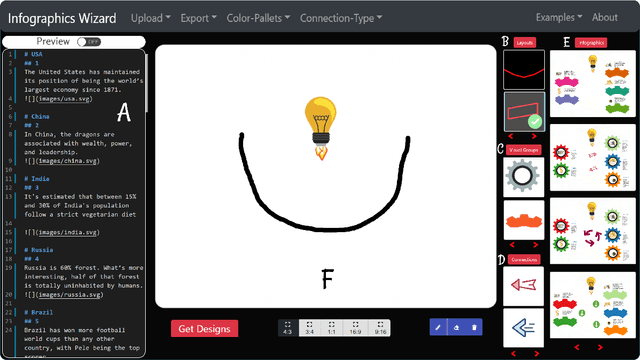



Designing infographics can be a tedious process for non-experts and time-consuming even for professional designers. Based on the literature and a formative study, we propose a flexible framework for automated and semi-automated infographics design. This framework captures the main design components in infographics and streamlines the generation workflow into three steps, allowing users to control and optimize each aspect independently. Based on the framework, we also propose an interactive tool, \name{}, for assisting novice designers with creating high-quality infographics from an input in a markdown format by offering recommendations of different design components of infographics. Simultaneously, more experienced designers can provide custom designs and layout ideas to the tool using a canvas to control the automated generation process partially. As part of our work, we also contribute an individual visual group (VG) and connection designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs. This dataset plays a crucial role in diversifying the infographic designs created by our framework. We evaluate our approach with a comparison against similar tools, a user study with novice and expert designers, and a case study. Results confirm that our framework and \name{} excel in creating customized infographics and exploring a large variety of designs.
Accelerating Quadratic Optimization with Reinforcement Learning
Jul 22, 2021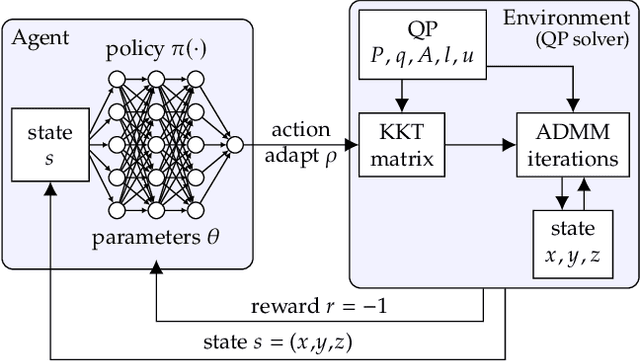
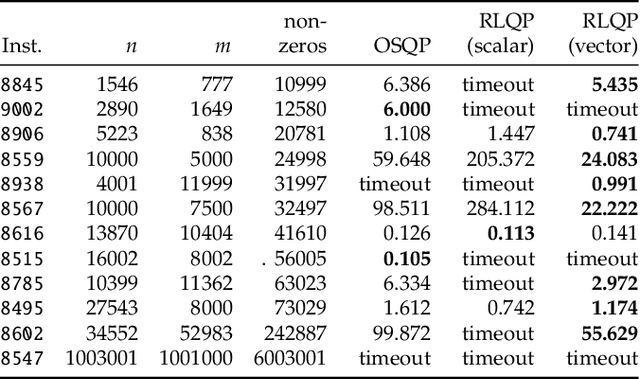
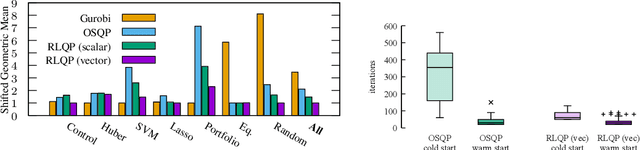
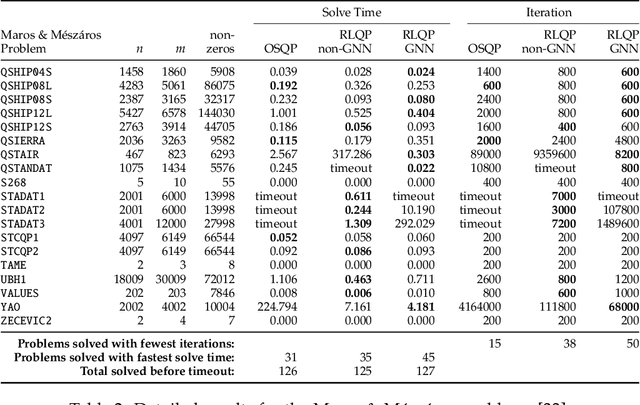
First-order methods for quadratic optimization such as OSQP are widely used for large-scale machine learning and embedded optimal control, where many related problems must be rapidly solved. These methods face two persistent challenges: manual hyperparameter tuning and convergence time to high-accuracy solutions. To address these, we explore how Reinforcement Learning (RL) can learn a policy to tune parameters to accelerate convergence. In experiments with well-known QP benchmarks we find that our RL policy, RLQP, significantly outperforms state-of-the-art QP solvers by up to 3x. RLQP generalizes surprisingly well to previously unseen problems with varying dimension and structure from different applications, including the QPLIB, Netlib LP and Maros-Meszaros problems. Code for RLQP is available at https://github.com/berkeleyautomation/rlqp.
An Integrated Multi-Time-Scale Modeling for Solar Irradiance Forecasting Using Deep Learning
May 07, 2019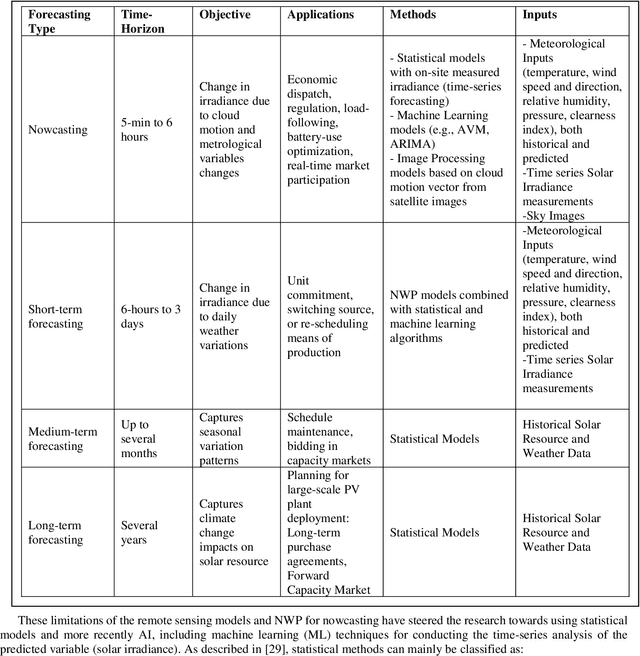
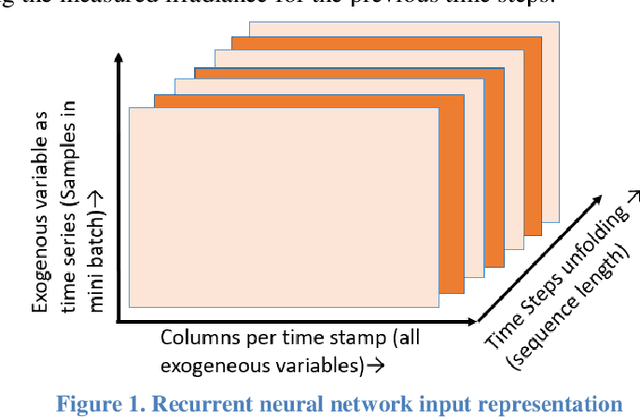
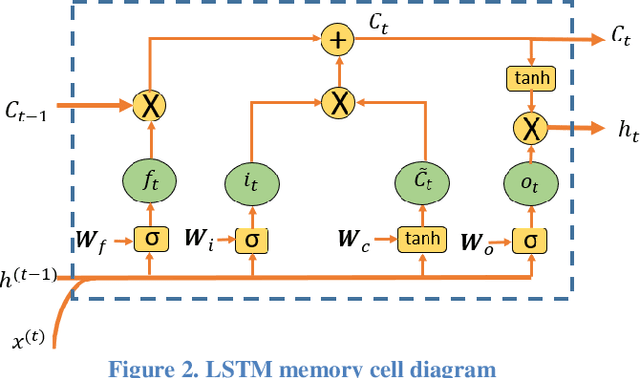
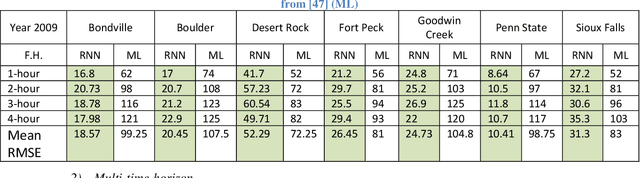
The amount of energy generation from renewable energy sources, particularly from wind and photovoltaic plants, has seen a rapid rise in the last decade. Reliable and economic operation of power systems thus requires an accurate estimate of the power generated from renewable generation plants, particularly those that are intermittent in nature. This has accentuated the need to find an efficient and scalable scheme for forecasting meteorological parameters, such as solar radiation, with better accuracy. For short-term solar irradiance forecasting, the traditional point forecasting methods are rendered less useful due to the non-stationary characteristic of solar power. In this research work, we propose a unified architecture for multi-time-scale predictions for intra-day solar irradiance forecasting using recurrent neural networks (RNN) and long-short-term memory networks (LSTMs). This paper also lays out a framework for extending this modeling approach to intra-hour forecasting horizons, thus making it a multi-time-horizon forecasting approach capable of predicting intra-hour as well as intra-day solar irradiance. We develop an end-to-end pipeline to effectuate the proposed architecture. The robustness of the approach is demonstrated with case studies conducted for geographically scattered sites across the United States. The predictions demonstrate that our proposed unified architecture based approach is effective for multi-time-scale solar forecasts and achieves a lower root-mean-square prediction error when benchmarked against the best-performing methods documented in the literature that use separate models for each time-scale during the day. The proposed method enables multi-time-horizon forecasts with real-time inputs, which have a significant potential for practical industry applications in the evolving grid.
FNAS: Uncertainty-Aware Fast Neural Architecture Search
May 27, 2021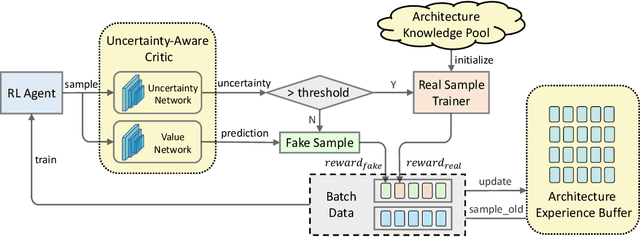
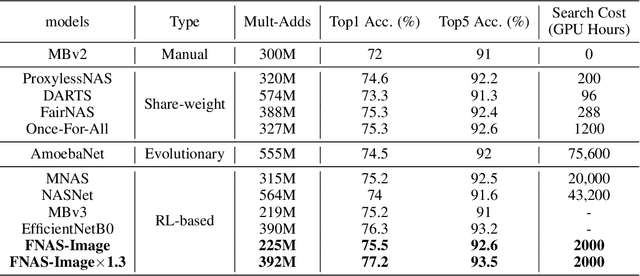
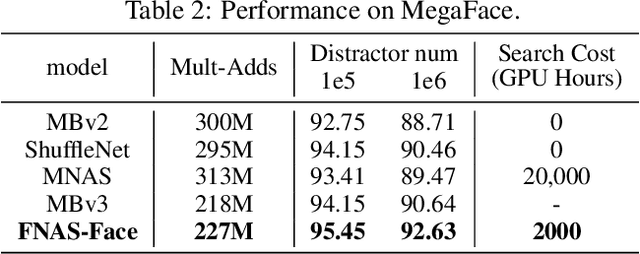
Reinforcement learning (RL)-based neural architecture search (NAS) generally guarantees better convergence yet suffers from the requirement of huge computational resources compared with gradient-based approaches, due to the rollout bottleneck -- exhaustive training for each sampled generation on proxy tasks. In this paper, we propose a general pipeline to accelerate the convergence of the rollout process as well as the RL process in NAS. It is motivated by the interesting observation that both the architecture and the parameter knowledge can be transferred between different experiments and even different tasks. We first introduce an uncertainty-aware critic (value function) in Proximal Policy Optimization (PPO) to utilize the architecture knowledge in previous experiments, which stabilizes the training process and reduces the searching time by 4 times. Further, an architecture knowledge pool together with a block similarity function is proposed to utilize parameter knowledge and reduces the searching time by 2 times. It is the first to introduce block-level weight sharing in RLbased NAS. The block similarity function guarantees a 100% hitting ratio with strict fairness. Besides, we show that a simply designed off-policy correction factor used in "replay buffer" in RL optimization can further reduce half of the searching time. Experiments on the Mobile Neural Architecture Search (MNAS) search space show the proposed Fast Neural Architecture Search (FNAS) accelerates standard RL-based NAS process by ~10x (e.g. ~256 2x2 TPUv2 x days / 20,000 GPU x hour -> 2,000 GPU x hour for MNAS), and guarantees better performance on various vision tasks.
3D UAV Trajectory and Data Collection Optimisation via Deep Reinforcement Learning
Jun 06, 2021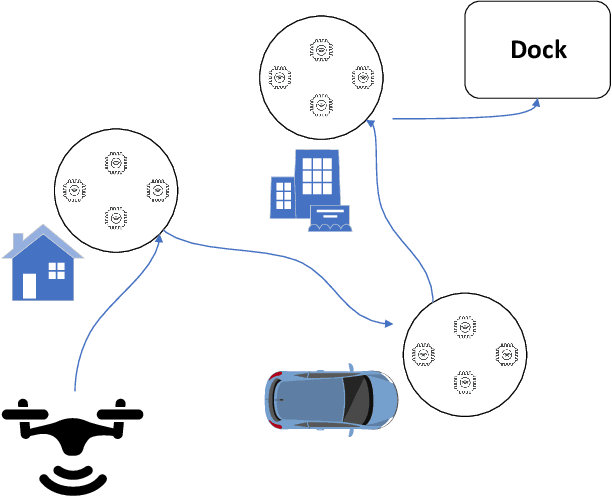
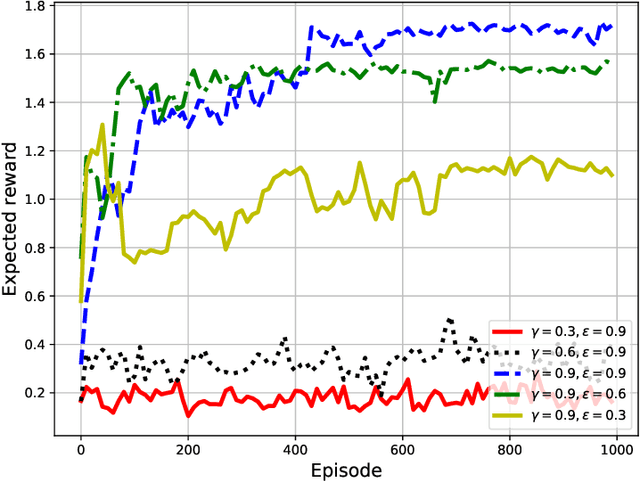
Unmanned aerial vehicles (UAVs) are now beginning to be deployed for enhancing the network performance and coverage in wireless communication. However, due to the limitation of their on-board power and flight time, it is challenging to obtain an optimal resource allocation scheme for the UAV-assisted Internet of Things (IoT). In this paper, we design a new UAV-assisted IoT systems relying on the shortest flight path of the UAVs while maximising the amount of data collected from IoT devices. Then, a deep reinforcement learning-based technique is conceived for finding the optimal trajectory and throughput in a specific coverage area. After training, the UAV has the ability to autonomously collect all the data from user nodes at a significant total sum-rate improvement while minimising the associated resources used. Numerical results are provided to highlight how our techniques strike a balance between the throughput attained, trajectory, and the time spent. More explicitly, we characterise the attainable performance in terms of the UAV trajectory, the expected reward and the total sum-rate.
Systematic Clinical Evaluation of A Deep Learning Method for Medical Image Segmentation: Radiosurgery Application
Aug 21, 2021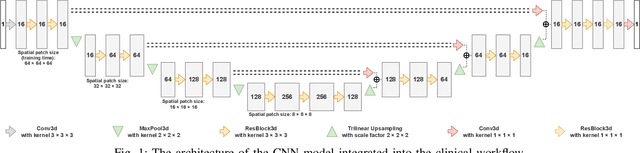
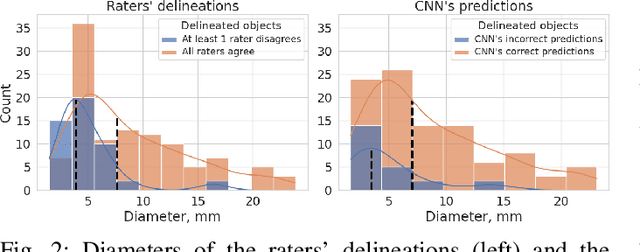
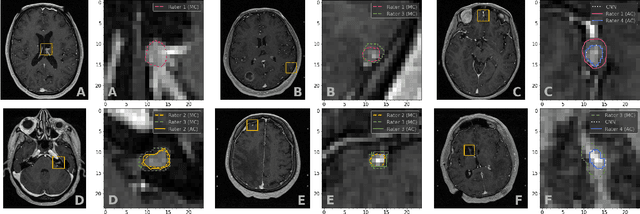
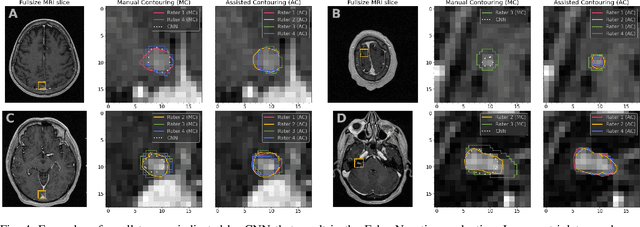
We systematically evaluate a Deep Learning (DL) method in a 3D medical image segmentation task. Our segmentation method is integrated into the radiosurgery treatment process and directly impacts the clinical workflow. With our method, we address the relative drawbacks of manual segmentation: high inter-rater contouring variability and high time consumption of the contouring process. The main extension over the existing evaluations is the careful and detailed analysis that could be further generalized on other medical image segmentation tasks. Firstly, we analyze the changes in the inter-rater detection agreement. We show that the segmentation model reduces the ratio of detection disagreements from 0.162 to 0.085 (p < 0.05). Secondly, we show that the model improves the inter-rater contouring agreement from 0.845 to 0.871 surface Dice Score (p < 0.05). Thirdly, we show that the model accelerates the delineation process in between 1.6 and 2.0 times (p < 0.05). Finally, we design the setup of the clinical experiment to either exclude or estimate the evaluation biases, thus preserve the significance of the results. Besides the clinical evaluation, we also summarize the intuitions and practical ideas for building an efficient DL-based model for 3D medical image segmentation.