 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Analysis of Privacy-(un)aware IoT Applications
Nov 24, 2019


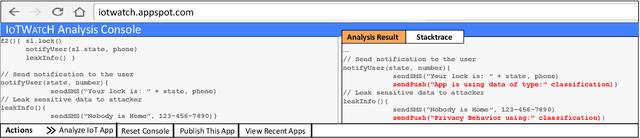
Users trust IoT apps to control and automate their smart devices. These apps necessarily have access to sensitive data to implement their functionality. However, users lack visibility into how their sensitive data is used (or leaked), and they often blindly trust the app developers. In this paper, we present IoTWatcH, a novel dynamic analysis tool that uncovers the privacy risks of IoT apps in real-time. We designed and built IoTWatcH based on an IoT privacy survey that considers the privacy needs of IoT users. IoTWatcH provides users with a simple interface to specify their privacy preferences with an IoT app. Then, in runtime, it analyzes both the data that is sent out of the IoT app and its recipients using Natural Language Processing (NLP) techniques. Moreover, IoTWatcH informs the users with its findings to make them aware of the privacy risks with the IoT app. We implemented IoTWatcH on real IoT applications. Specifically, we analyzed 540 IoT apps to train the NLP model and evaluate its effectiveness. IoTWatcH successfully classifies IoT app data sent to external parties to correct privacy labels with an average accuracy of 94.25%, and flags IoT apps that leak privacy data to unauthorized parties. Finally, IoTWatcH yields minimal overhead to an IoT app's execution, on average 105 ms additional latency.
RGB-D Salient Object Detection with Ubiquitous Target Awareness
Sep 08, 2021

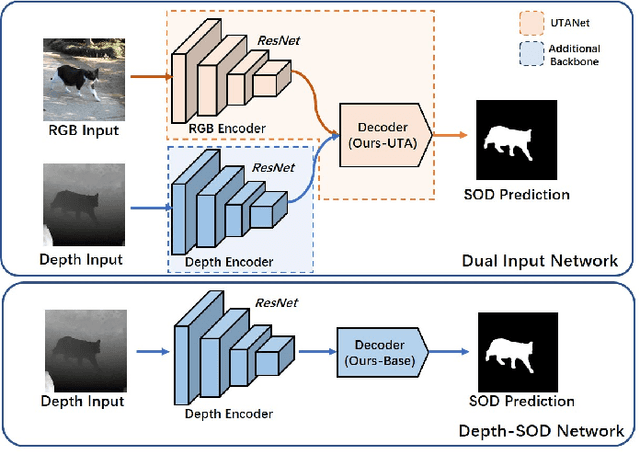

Conventional RGB-D salient object detection methods aim to leverage depth as complementary information to find the salient regions in both modalities. However, the salient object detection results heavily rely on the quality of captured depth data which sometimes are unavailable. In this work, we make the first attempt to solve the RGB-D salient object detection problem with a novel depth-awareness framework. This framework only relies on RGB data in the testing phase, utilizing captured depth data as supervision for representation learning. To construct our framework as well as achieving accurate salient detection results, we propose a Ubiquitous Target Awareness (UTA) network to solve three important challenges in RGB-D SOD task: 1) a depth awareness module to excavate depth information and to mine ambiguous regions via adaptive depth-error weights, 2) a spatial-aware cross-modal interaction and a channel-aware cross-level interaction, exploiting the low-level boundary cues and amplifying high-level salient channels, and 3) a gated multi-scale predictor module to perceive the object saliency in different contextual scales. Besides its high performance, our proposed UTA network is depth-free for inference and runs in real-time with 43 FPS. Experimental evidence demonstrates that our proposed network not only surpasses the state-of-the-art methods on five public RGB-D SOD benchmarks by a large margin, but also verifies its extensibility on five public RGB SOD benchmarks.
High-Dimensional Robust Mean Estimation in Nearly-Linear Time
Nov 23, 2018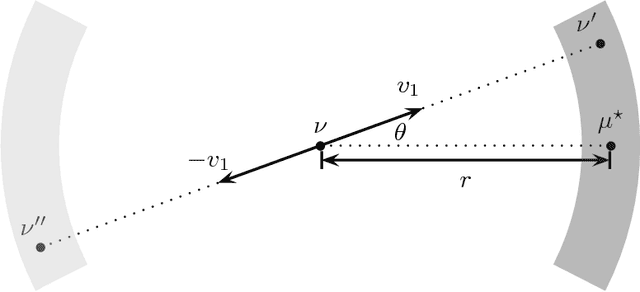
We study the fundamental problem of high-dimensional mean estimation in a robust model where a constant fraction of the samples are adversarially corrupted. Recent work gave the first polynomial time algorithms for this problem with dimension-independent error guarantees for several families of structured distributions. In this work, we give the first nearly-linear time algorithms for high-dimensional robust mean estimation. Specifically, we focus on distributions with (i) known covariance and sub-gaussian tails, and (ii) unknown bounded covariance. Given $N$ samples on $\mathbb{R}^d$, an $\epsilon$-fraction of which may be arbitrarily corrupted, our algorithms run in time $\tilde{O}(Nd) / \mathrm{poly}(\epsilon)$ and approximate the true mean within the information-theoretically optimal error, up to constant factors. Previous robust algorithms with comparable error guarantees have running times $\tilde{\Omega}(N d^2)$, for $\epsilon = \Omega(1)$. Our algorithms rely on a natural family of SDPs parameterized by our current guess $\nu$ for the unknown mean $\mu^\star$. We give a win-win analysis establishing the following: either a near-optimal solution to the primal SDP yields a good candidate for $\mu^\star$ -- independent of our current guess $\nu$ -- or the dual SDP yields a new guess $\nu'$ whose distance from $\mu^\star$ is smaller by a constant factor. We exploit the special structure of the corresponding SDPs to show that they are approximately solvable in nearly-linear time. Our approach is quite general, and we believe it can also be applied to obtain nearly-linear time algorithms for other high-dimensional robust learning problems.
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 13, 2021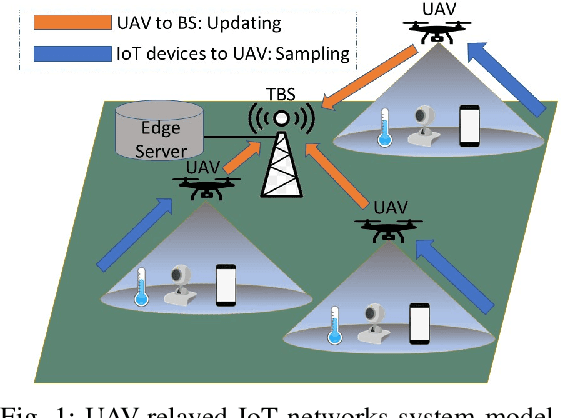
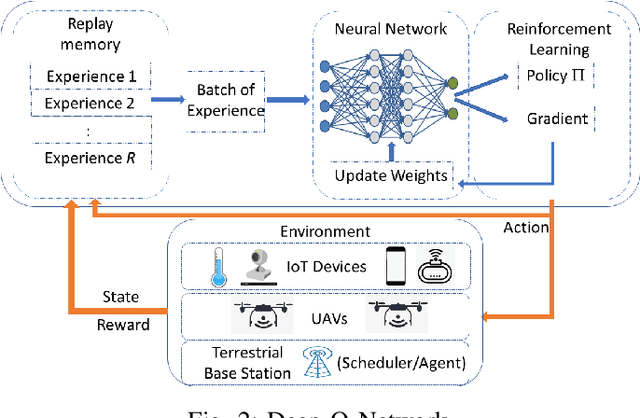
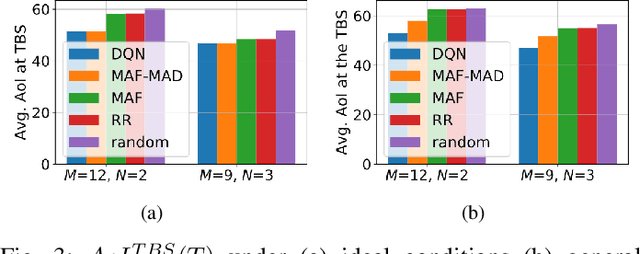
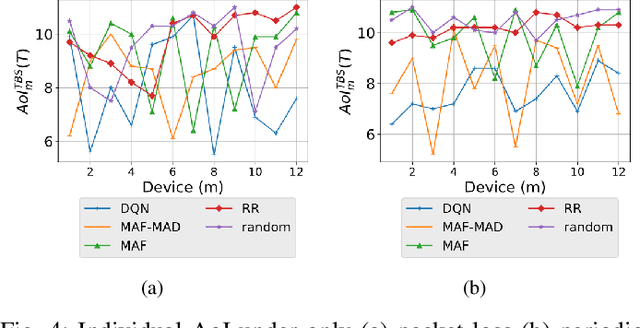
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.
MARC: Mining Association Rules from datasets by using Clustering models
Jul 14, 2021


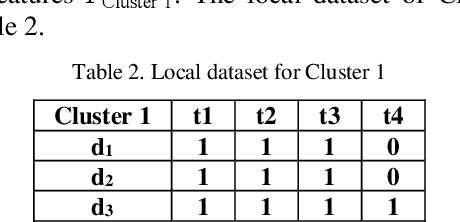
Association rules are useful to discover relationships, which are mostly hidden, between the different items in large datasets. Symbolic models are the principal tools to extract association rules. This basic technique is time-consuming, and it generates a big number of associated rules. To overcome this drawback, we suggest a new method, called MARC, to extract the more important association rules of two important levels: Type I, and Type II. This approach relies on a multi-topographic unsupervised neural network model as well as clustering quality measures that evaluate the success of a given numerical classification model to behave as a natural symbolic model.
When Deep Classifiers Agree: Analyzing Correlations between Learning Order and Image Statistics
May 19, 2021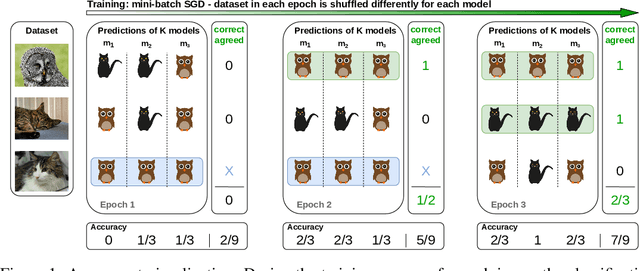
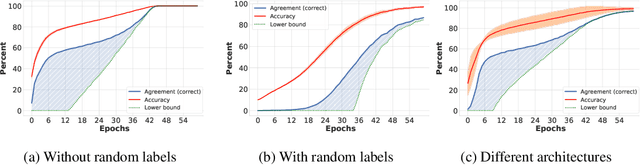

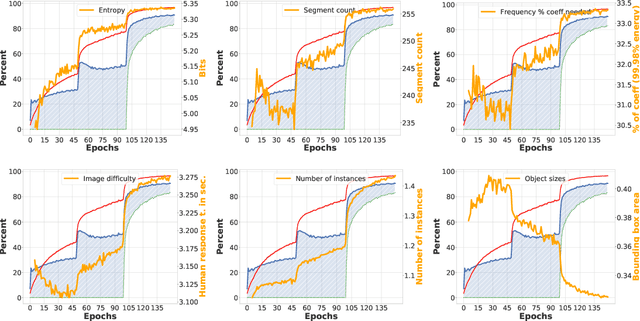
Although a plethora of architectural variants for deep classification has been introduced over time, recent works have found empirical evidence towards similarities in their training process. It has been hypothesized that neural networks converge not only to similar representations, but also exhibit a notion of empirical agreement on which data instances are learned first. Following in the latter works$'$ footsteps, we define a metric to quantify the relationship between such classification agreement over time, and posit that the agreement phenomenon can be mapped to core statistics of the investigated dataset. We empirically corroborate this hypothesis across the CIFAR10, Pascal, ImageNet and KTH-TIPS2 datasets. Our findings indicate that agreement seems to be independent of specific architectures, training hyper-parameters or labels, albeit follows an ordering according to image statistics.
Efficient Strategy Synthesis for MDPs with Resource Constraints
May 05, 2021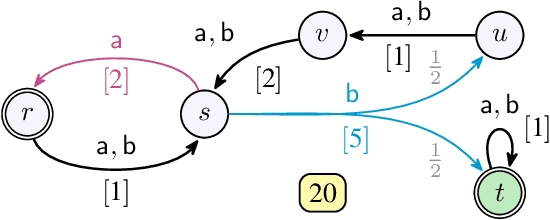
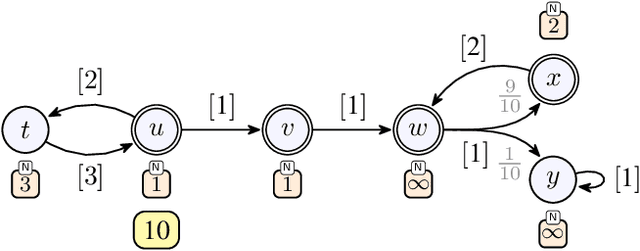
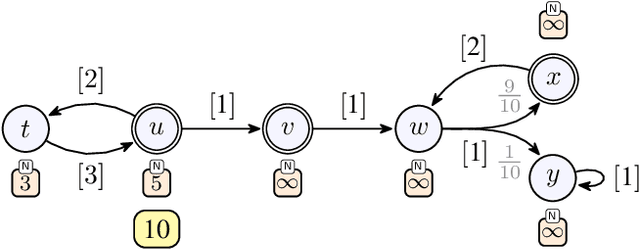
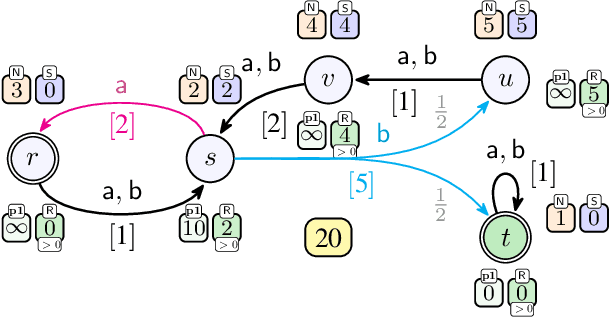
We consider qualitative strategy synthesis for the formalism called consumption Markov decision processes. This formalism can model dynamics of an agents that operates under resource constraints in a stochastic environment. The presented algorithms work in time polynomial with respect to the representation of the model and they synthesize strategies ensuring that a given set of goal states will be reached (once or infinitely many times) with probability 1 without resource exhaustion. In particular, when the amount of resource becomes too low to safely continue in the mission, the strategy changes course of the agent towards one of a designated set of reload states where the agent replenishes the resource to full capacity; with sufficient amount of resource, the agent attempts to fulfill the mission again. We also present two heuristics that attempt to reduce expected time that the agent needs to fulfill the given mission, a parameter important in practical planning. The presented algorithms were implemented and numerical examples demonstrate (i) the effectiveness (in terms of computation time) of the planning approach based on consumption Markov decision processes and (ii) the positive impact of the two heuristics on planning in a realistic example.
The effect of phased recurrent units in the classification of multiple catalogs of astronomical lightcurves
Jun 07, 2021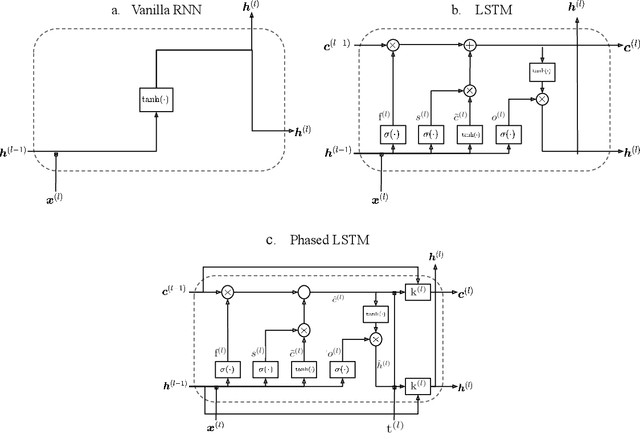
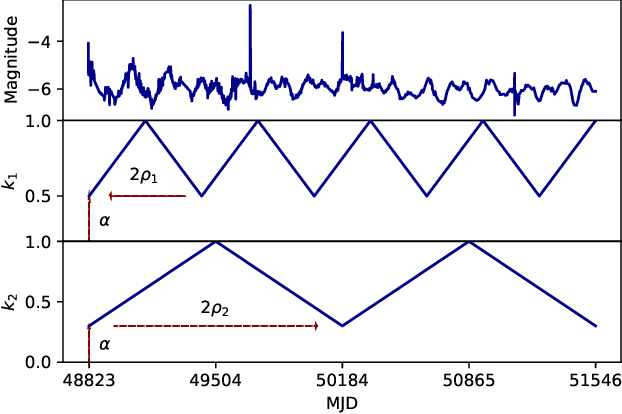
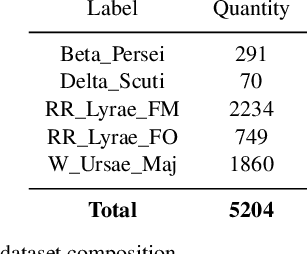
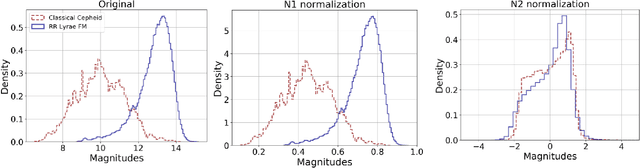
In the new era of very large telescopes, where data is crucial to expand scientific knowledge, we have witnessed many deep learning applications for the automatic classification of lightcurves. Recurrent neural networks (RNNs) are one of the models used for these applications, and the LSTM unit stands out for being an excellent choice for the representation of long time series. In general, RNNs assume observations at discrete times, which may not suit the irregular sampling of lightcurves. A traditional technique to address irregular sequences consists of adding the sampling time to the network's input, but this is not guaranteed to capture sampling irregularities during training. Alternatively, the Phased LSTM unit has been created to address this problem by updating its state using the sampling times explicitly. In this work, we study the effectiveness of the LSTM and Phased LSTM based architectures for the classification of astronomical lightcurves. We use seven catalogs containing periodic and nonperiodic astronomical objects. Our findings show that LSTM outperformed PLSTM on 6/7 datasets. However, the combination of both units enhances the results in all datasets.
Targeted Muscle Effort Distribution with Exercise Robots: Trajectory and Resistance Effects
Jul 02, 2021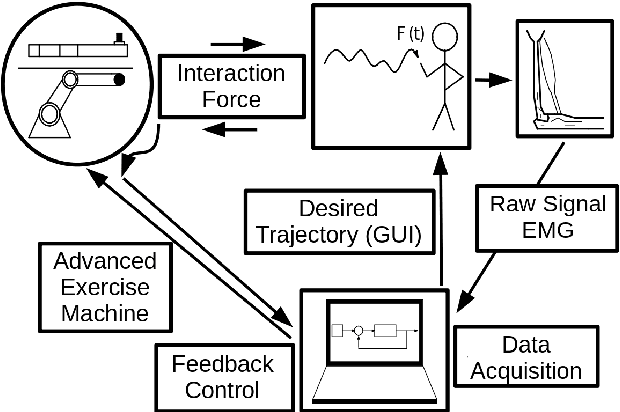
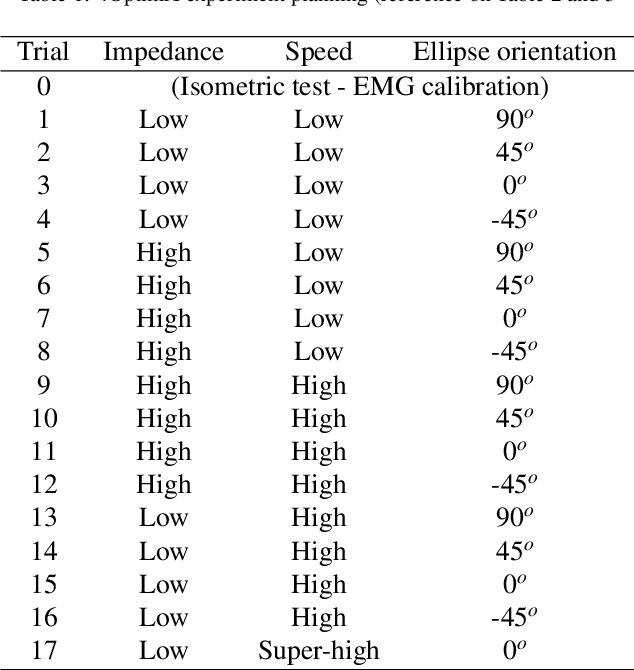


The objective of this work is to relate muscle effort distributions to the trajectory and resistance settings of a robotic exercise and rehabilitation machine. Muscular effort distribution, representing the participation of each muscle in the training activity, was measured with electromyography sensors (EMG) and defined as the individual activation divided by the total muscle group activation. A four degrees-of-freedom robot and its impedance control system are used to create advanced exercise protocols whereby the user is asked to follow a path against the machine's neutral path and resistance. In this work, the robot establishes a zero-effort circular path, and the subject is asked to follow an elliptical trajectory. The control system produces a user-defined stiffness between the deviations from the neutral path and the torque applied by the subject. The trajectory and resistance settings used in the experiments were the orientation of the ellipse and a stiffness parameter. Multiple combinations of these parameters were used to measure their effects on the muscle effort distribution. An artificial neural network (ANN) used part of the data for training the model. Then, the accuracy of the model was evaluated using the rest of the data. The results show how the precision of the model is lost over time. These outcomes show the complexity of the muscle dynamics for long-term estimations suggesting the existence of time-varying dynamics possibly associated with fatigue.
Applications of Artificial Neural Networks in Microorganism Image Analysis: A Comprehensive Review from Conventional Multilayer Perceptron to Popular Convolutional Neural Network and Potential Visual Transformer
Aug 01, 2021
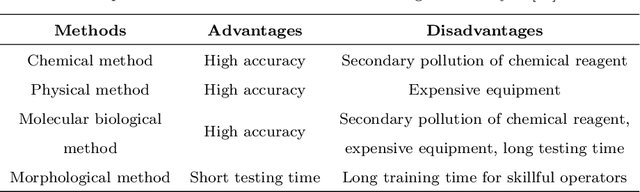
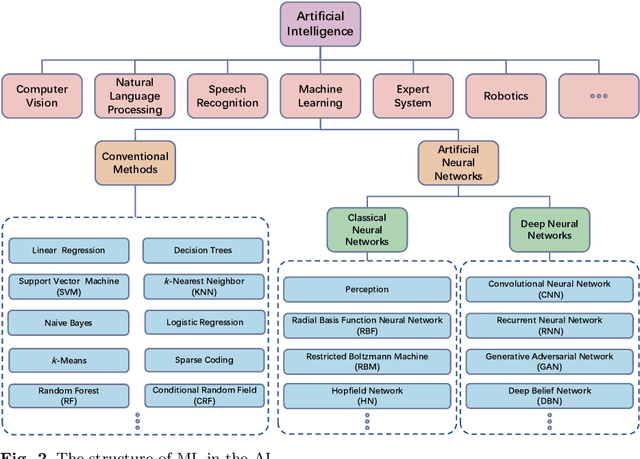
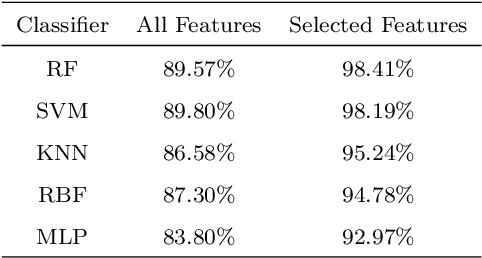
Microorganisms are widely distributed in the human daily living environment. They play an essential role in environmental pollution control, disease prevention and treatment, and food and drug production. The identification, counting, and detection are the basic steps for making full use of different microorganisms. However, the conventional analysis methods are expensive, laborious, and time-consuming. To overcome these limitations, artificial neural networks are applied for microorganism image analysis. We conduct this review to understand the development process of microorganism image analysis based on artificial neural networks. In this review, the background and motivation are introduced first. Then, the development of artificial neural networks and representative networks are introduced. After that, the papers related to microorganism image analysis based on classical and deep neural networks are reviewed from the perspectives of different tasks. In the end, the methodology analysis and potential direction are discussed.