 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Methods of Adaptive Signal Processing on Graphs Using Vertex-Time Autoregressive Models
Mar 10, 2020
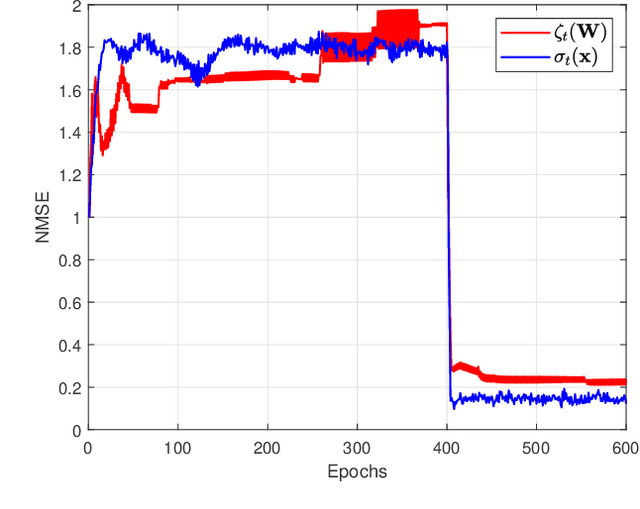
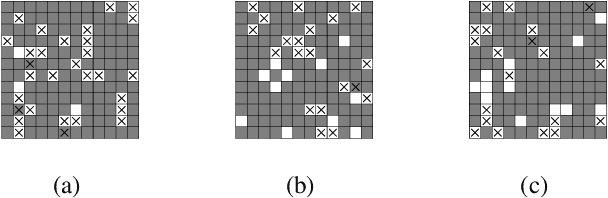
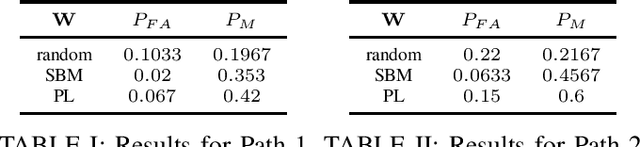
The concept of a random process has been recently extended to graph signals, whereby random graph processes are a class of multivariate stochastic processes whose coefficients are matrices with a \textit{graph-topological} structure. The system identification problem of a random graph process therefore revolves around determining its underlying topology, or mathematically, the graph shift operators (GSOs) i.e. an adjacency matrix or a Laplacian matrix. In the same work that introduced random graph processes, a \textit{batch} optimization method to solve for the GSO was also proposed for the random graph process based on a \textit{causal} vertex-time autoregressive model. To this end, the online version of this optimization problem was proposed via the framework of adaptive filtering. The modified stochastic gradient projection method was employed on the regularized least squares objective to create the filter. The recursion is divided into 3 regularized sub-problems to address issues like multi-convexity, sparsity, commutativity and bias. A discussion on convergence analysis is also included. Finally, experiments are conducted to illustrate the performance of the proposed algorithm, from traditional MSE measure to successful recovery rate regardless correct values, all of which to shed light on the potential, the limit and the possible research attempt of this work.
About Explicit Variance Minimization: Training Neural Networks for Medical Imaging With Limited Data Annotations
May 28, 2021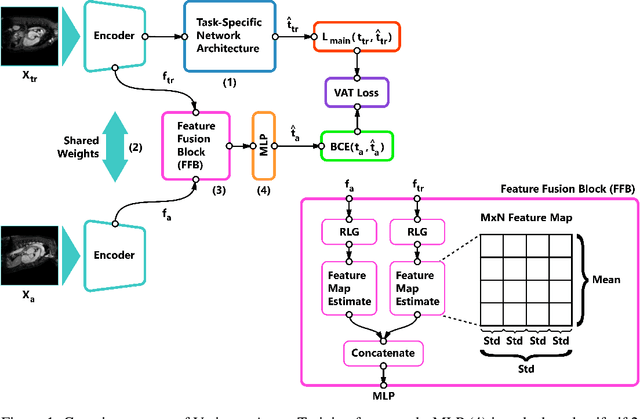
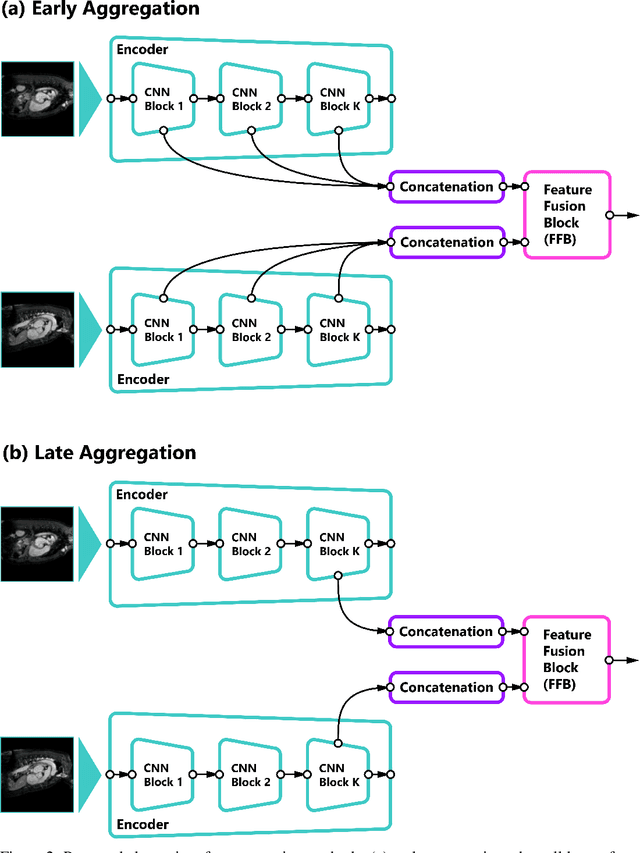
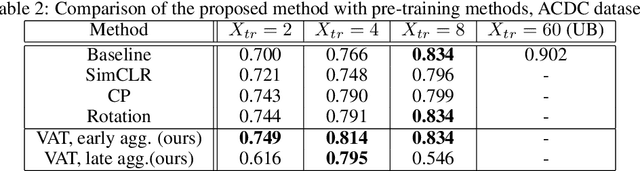
Self-supervised learning methods for computer vision have demonstrated the effectiveness of pre-training feature representations, resulting in well-generalizing Deep Neural Networks, even if the annotated data are limited. However, representation learning techniques require a significant amount of time for model training, with most of it time spent on precise hyper-parameter optimization and selection of augmentation techniques. We hypothesized that if the annotated dataset has enough morphological diversity to capture the general population's as is common in medical imaging, for example, due to conserved similarities of tissue mythologies, the variance error of the trained model is the prevalent component of the Bias-Variance Trade-off. We propose the Variance Aware Training (VAT) method that exploits this property by introducing the variance error into the model loss function, i.e., enabling minimizing the variance explicitly. Additionally, we provide the theoretical formulation and proof of the proposed method to aid in interpreting the approach. Our method requires selecting only one hyper-parameter and was able to match or improve the state-of-the-art performance of self-supervised methods while achieving an order of magnitude reduction in the GPU training time. We validated VAT on three medical imaging datasets from diverse domains and various learning objectives. These included a Magnetic Resonance Imaging (MRI) dataset for the heart semantic segmentation (MICCAI 2017 ACDC challenge), fundus photography dataset for ordinary regression of diabetic retinopathy progression (Kaggle 2019 APTOS Blindness Detection challenge), and classification of histopathologic scans of lymph node sections (PatchCamelyon dataset).
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
Sep 21, 2021
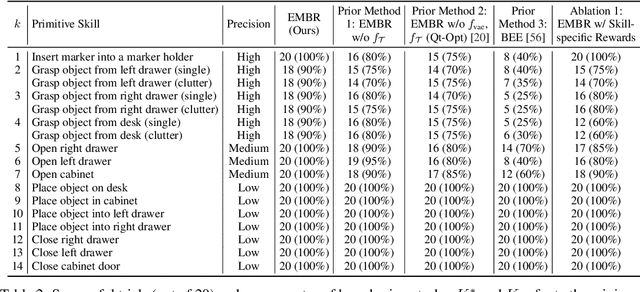
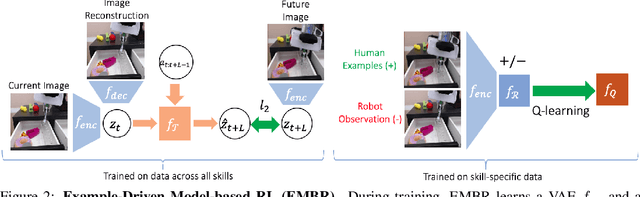

In this paper, we study the problem of learning a repertoire of low-level skills from raw images that can be sequenced to complete long-horizon visuomotor tasks. Reinforcement learning (RL) is a promising approach for acquiring short-horizon skills autonomously. However, the focus of RL algorithms has largely been on the success of those individual skills, more so than learning and grounding a large repertoire of skills that can be sequenced to complete extended multi-stage tasks. The latter demands robustness and persistence, as errors in skills can compound over time, and may require the robot to have a number of primitive skills in its repertoire, rather than just one. To this end, we introduce EMBR, a model-based RL method for learning primitive skills that are suitable for completing long-horizon visuomotor tasks. EMBR learns and plans using a learned model, critic, and success classifier, where the success classifier serves both as a reward function for RL and as a grounding mechanism to continuously detect if the robot should retry a skill when unsuccessful or under perturbations. Further, the learned model is task-agnostic and trained using data from all skills, enabling the robot to efficiently learn a number of distinct primitives. These visuomotor primitive skills and their associated pre- and post-conditions can then be directly combined with off-the-shelf symbolic planners to complete long-horizon tasks. On a Franka Emika robot arm, we find that EMBR enables the robot to complete three long-horizon visuomotor tasks at 85% success rate, such as organizing an office desk, a file cabinet, and drawers, which require sequencing up to 12 skills, involve 14 unique learned primitives, and demand generalization to novel objects.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
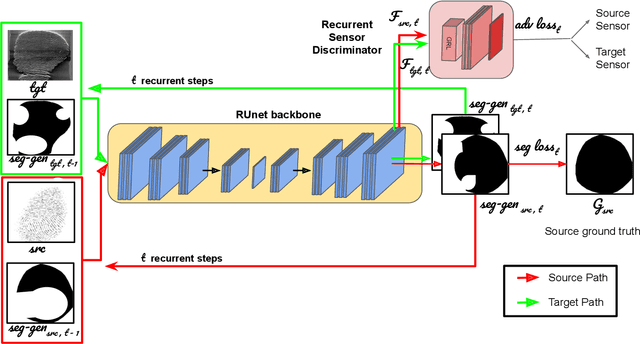

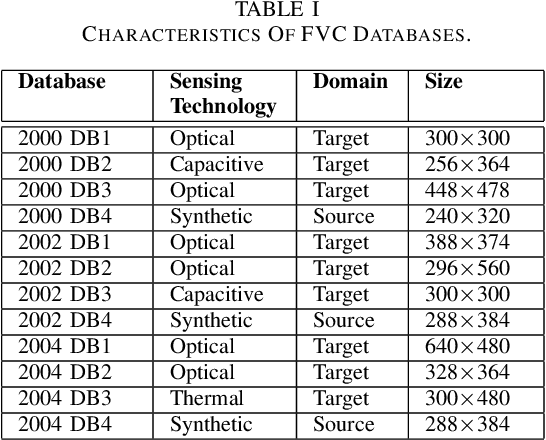
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)
An Effective Non-Autoregressive Model for Spoken Language Understanding
Aug 16, 2021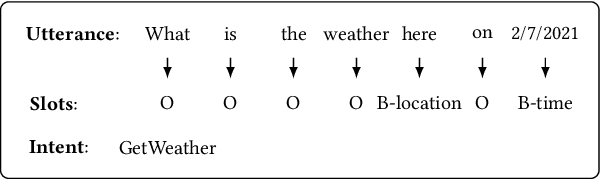
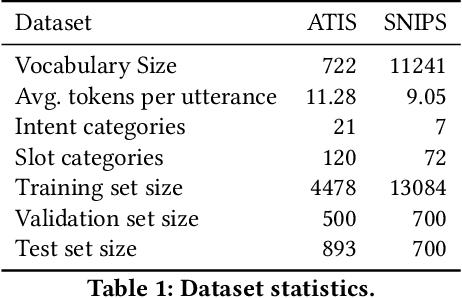
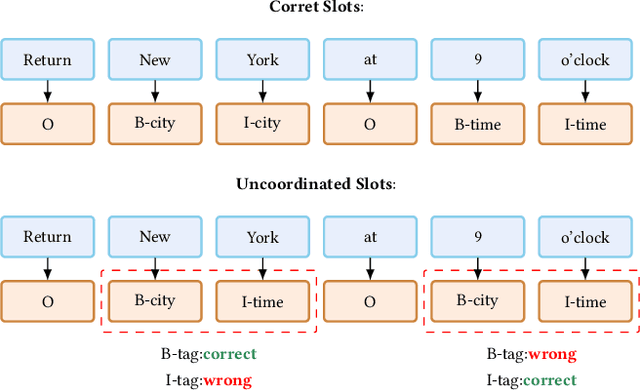
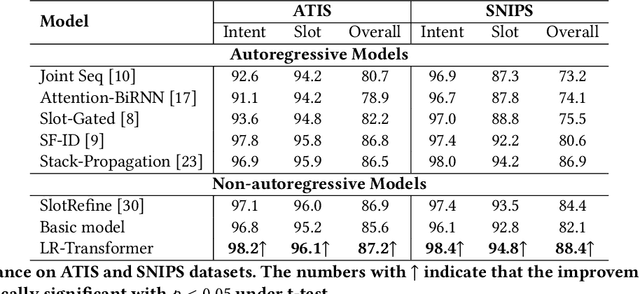
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference latency due to the impatience of humans. Non-autoregressive SLU models clearly increase the inference speed but suffer uncoordinated-slot problems caused by the lack of sequential dependency information among each slot chunk. To gap this shortcoming, in this paper, we propose a novel non-autoregressive SLU model named Layered-Refine Transformer, which contains a Slot Label Generation (SLG) task and a Layered Refine Mechanism (LRM). SLG is defined as generating the next slot label with the token sequence and generated slot labels. With SLG, the non-autoregressive model can efficiently obtain dependency information during training and spend no extra time in inference. LRM predicts the preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction. Experiments on two public datasets indicate that our model significantly improves SLU performance (1.5\% on Overall accuracy) while substantially speed up (more than 10 times) the inference process over the state-of-the-art baseline.
MS-KD: Multi-Organ Segmentation with Multiple Binary-Labeled Datasets
Aug 05, 2021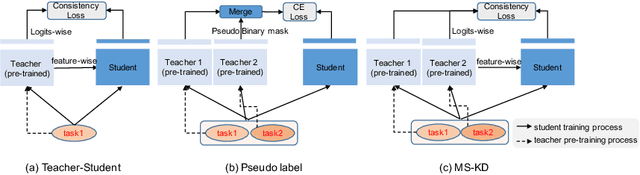
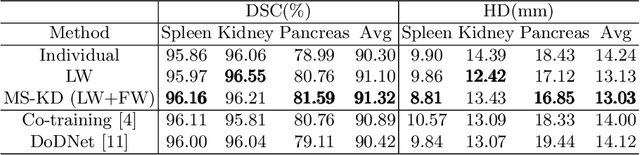
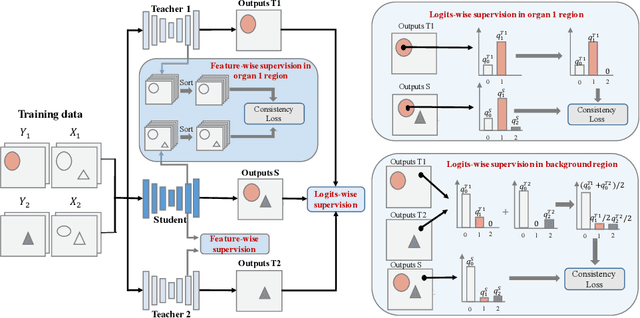
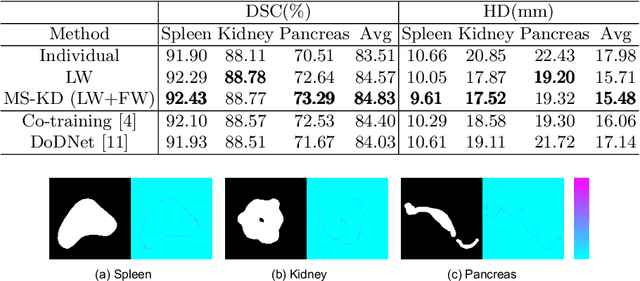
Annotating multiple organs in 3D medical images is time-consuming and costly. Meanwhile, there exist many single-organ datasets with one specific organ annotated. This paper investigates how to learn a multi-organ segmentation model leveraging a set of binary-labeled datasets. A novel Multi-teacher Single-student Knowledge Distillation (MS-KD) framework is proposed, where the teacher models are pre-trained single-organ segmentation networks, and the student model is a multi-organ segmentation network. Considering that each teacher focuses on different organs, a region-based supervision method, consisting of logits-wise supervision and feature-wise supervision, is proposed. Each teacher supervises the student in two regions, the organ region where the teacher is considered as an expert and the background region where all teachers agree. Extensive experiments on three public single-organ datasets and a multi-organ dataset have demonstrated the effectiveness of the proposed MS-KD framework.
Partial Symbol Recovery for Interference Resilience in Low-Power Wide Area Networks
Sep 08, 2021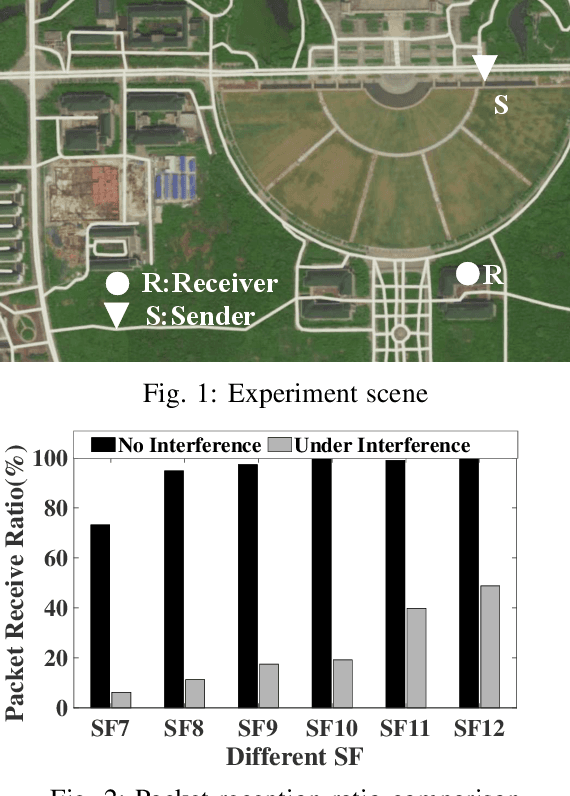
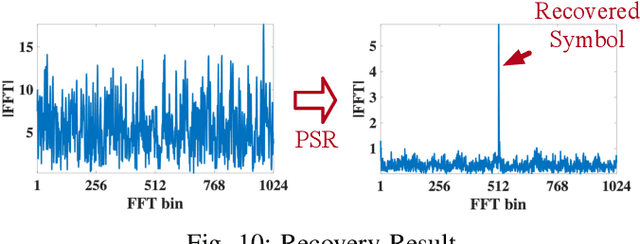

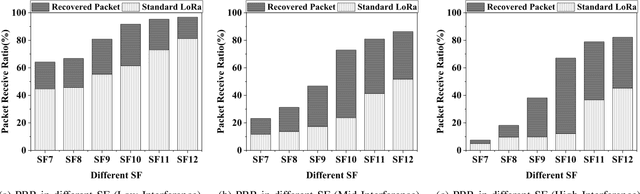
Recent years have witnessed the proliferation of Low-power Wide Area Networks (LPWANs) in the unlicensed band for various Internet-of-Things (IoT) applications. Due to the ultra-low transmission power and long transmission duration, LPWAN devices inevitably suffer from high power Cross Technology Interference (CTI), such as interference from Wi-Fi, coexisting in the same spectrum. To alleviate this issue, this paper introduces the Partial Symbol Recovery (PSR) scheme for improving the CTI resilience of LPWAN. We verify our idea on LoRa, a widely adopted LPWAN technique, as a proof of concept. At the PHY layer, although CTI has much higher power, its duration is relatively shorter compared with LoRa symbols, leaving part of a LoRa symbol uncorrupted. Moreover, due to its high redundancy, LoRa chips within a symbol are highly correlated. This opens the possibility of detecting a LoRa symbol with only part of the chips. By examining the unique frequency patterns in LoRa symbols with time-frequency analysis, our design effectively detects the clean LoRa chips that are free of CTI. This enables PSR to only rely on clean LoRa chips for successfully recovering from communication failures. We evaluate our PSR design with real-world testbeds, including SX1280 LoRa chips and USRP B210, under Wi-Fi interference in various scenarios. Extensive experiments demonstrate that our design offers reliable packet recovery performance, successfully boosting the LoRa packet reception ratio from 45.2% to 82.2% with a performance gain of 1.8 times.
High-Dimensional Robust Mean Estimation in Nearly-Linear Time
Nov 23, 2018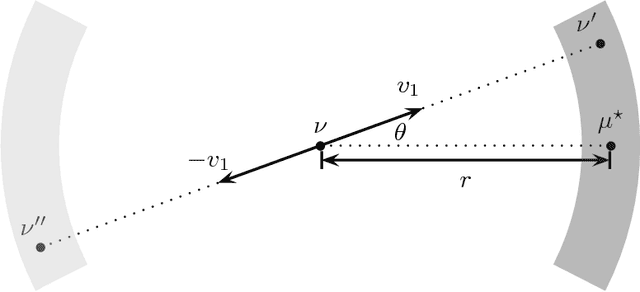
We study the fundamental problem of high-dimensional mean estimation in a robust model where a constant fraction of the samples are adversarially corrupted. Recent work gave the first polynomial time algorithms for this problem with dimension-independent error guarantees for several families of structured distributions. In this work, we give the first nearly-linear time algorithms for high-dimensional robust mean estimation. Specifically, we focus on distributions with (i) known covariance and sub-gaussian tails, and (ii) unknown bounded covariance. Given $N$ samples on $\mathbb{R}^d$, an $\epsilon$-fraction of which may be arbitrarily corrupted, our algorithms run in time $\tilde{O}(Nd) / \mathrm{poly}(\epsilon)$ and approximate the true mean within the information-theoretically optimal error, up to constant factors. Previous robust algorithms with comparable error guarantees have running times $\tilde{\Omega}(N d^2)$, for $\epsilon = \Omega(1)$. Our algorithms rely on a natural family of SDPs parameterized by our current guess $\nu$ for the unknown mean $\mu^\star$. We give a win-win analysis establishing the following: either a near-optimal solution to the primal SDP yields a good candidate for $\mu^\star$ -- independent of our current guess $\nu$ -- or the dual SDP yields a new guess $\nu'$ whose distance from $\mu^\star$ is smaller by a constant factor. We exploit the special structure of the corresponding SDPs to show that they are approximately solvable in nearly-linear time. Our approach is quite general, and we believe it can also be applied to obtain nearly-linear time algorithms for other high-dimensional robust learning problems.
Real-time Analysis of Privacy-(un)aware IoT Applications
Nov 24, 2019

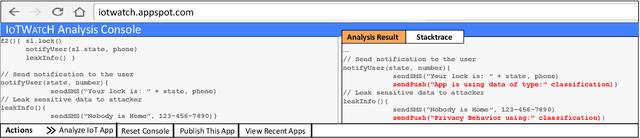
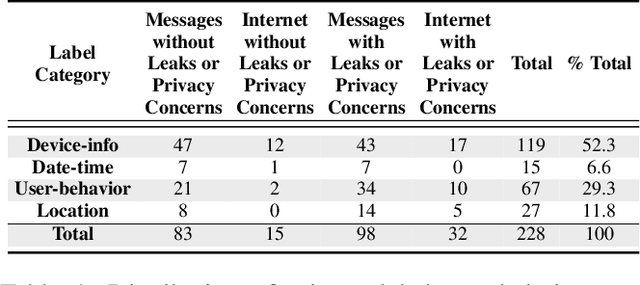
Users trust IoT apps to control and automate their smart devices. These apps necessarily have access to sensitive data to implement their functionality. However, users lack visibility into how their sensitive data is used (or leaked), and they often blindly trust the app developers. In this paper, we present IoTWatcH, a novel dynamic analysis tool that uncovers the privacy risks of IoT apps in real-time. We designed and built IoTWatcH based on an IoT privacy survey that considers the privacy needs of IoT users. IoTWatcH provides users with a simple interface to specify their privacy preferences with an IoT app. Then, in runtime, it analyzes both the data that is sent out of the IoT app and its recipients using Natural Language Processing (NLP) techniques. Moreover, IoTWatcH informs the users with its findings to make them aware of the privacy risks with the IoT app. We implemented IoTWatcH on real IoT applications. Specifically, we analyzed 540 IoT apps to train the NLP model and evaluate its effectiveness. IoTWatcH successfully classifies IoT app data sent to external parties to correct privacy labels with an average accuracy of 94.25%, and flags IoT apps that leak privacy data to unauthorized parties. Finally, IoTWatcH yields minimal overhead to an IoT app's execution, on average 105 ms additional latency.
Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network for Speech Enhancement
Apr 15, 2021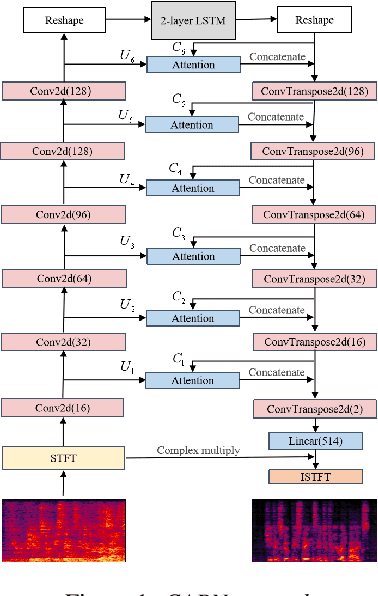
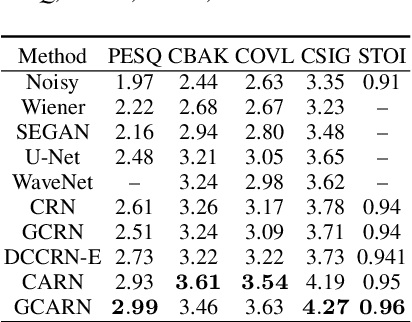
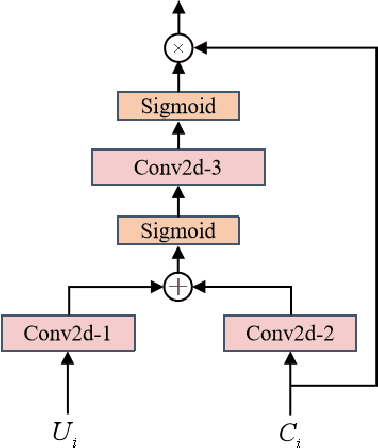
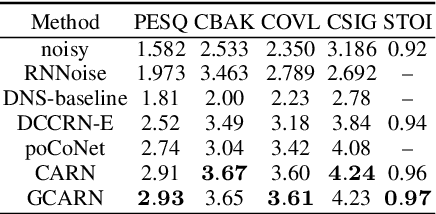
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.