 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Estimation of Diameter at Breast Height (DBH) of Forest Trees Using a Handheld LiDAR
Aug 03, 2021
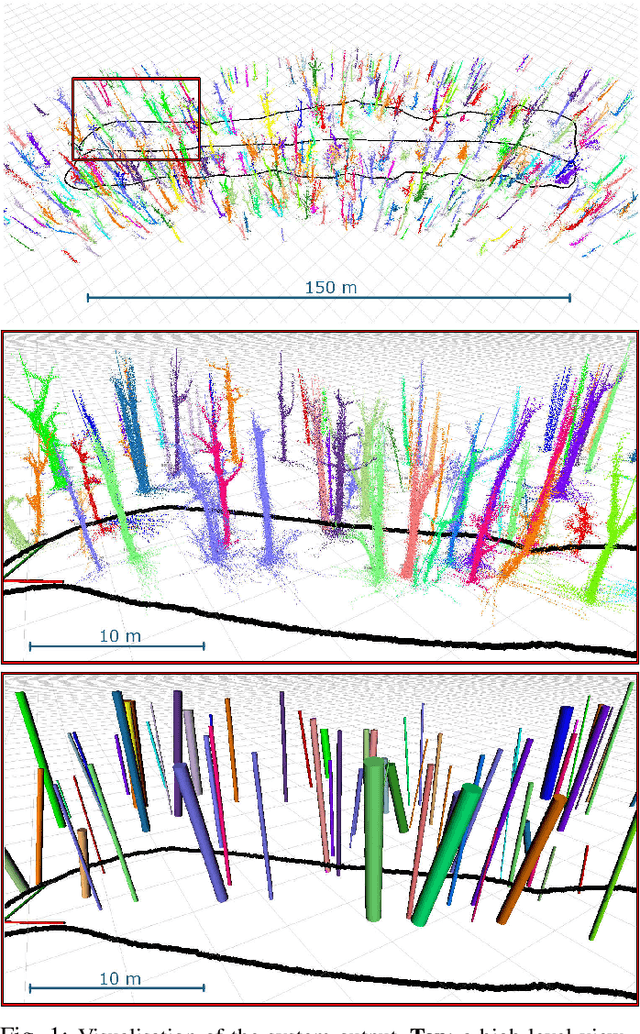
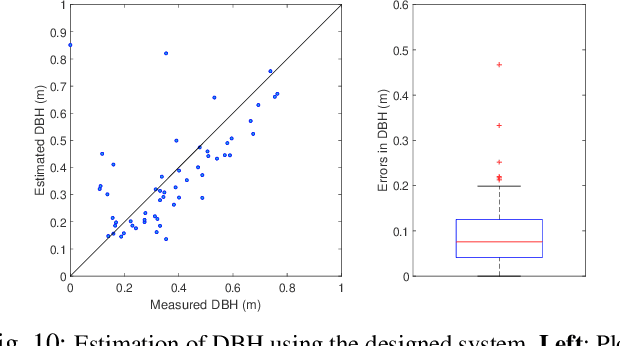

While mobile LiDAR sensors are increasingly used to scan in ecology and forestry applications, reconstruction and characterisation are typically carried out offline (to the best of our knowledge). Motivated by this, we present an online LiDAR system which can run on a handheld device to segment and track individual trees and identify them in a fixed coordinate system. Segments relating to each tree are accumulated over time, and tree models are completed as more scans are captured from different perspectives. Using this reconstruction we then fit a cylinder model to each tree trunk by solving a least-squares optimisation over the points to estimate the Diameter at Breast Height (DBH) of the trees. Experimental results demonstrate that our system can estimate DBH to within $\sim$7 cm accuracy for 90% of individual trees in a forest (Wytham Woods, Oxford)
Global Built-up and Population Maps: Which ones should you use for India?
Aug 18, 2021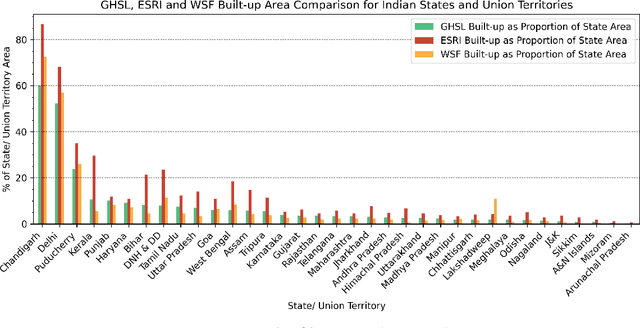
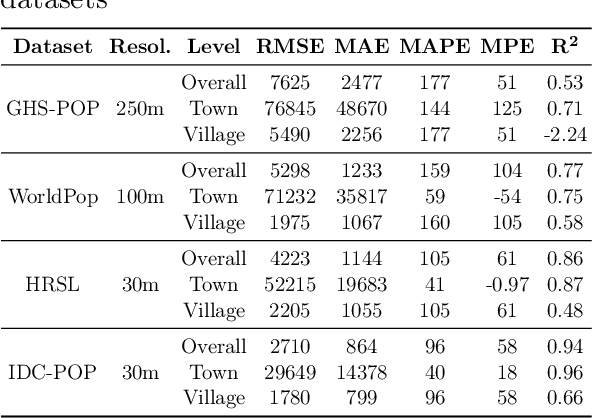
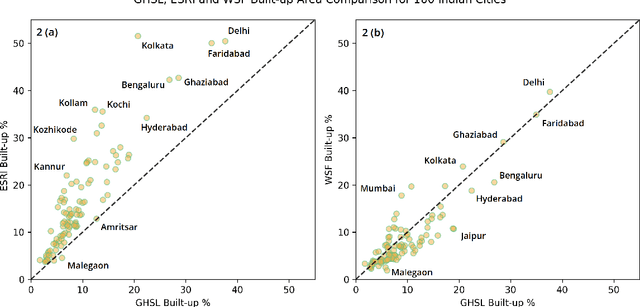
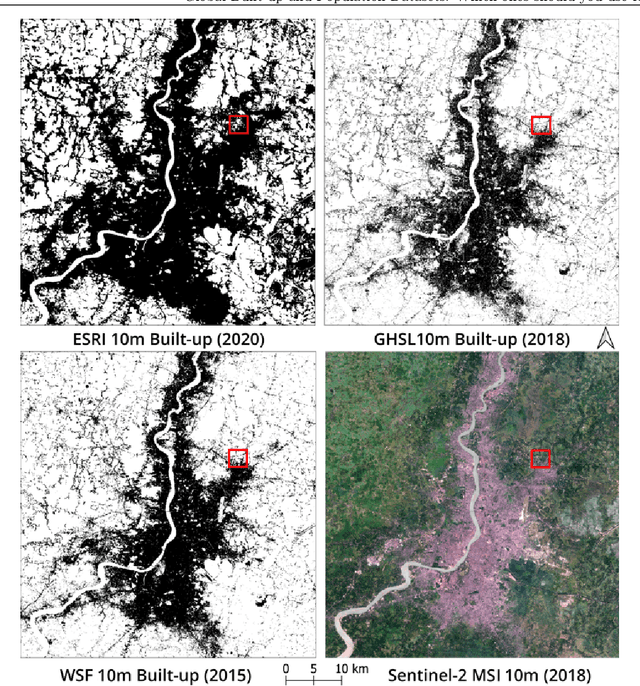
Multiple global land cover and population distribution datasets are currently available in the public domain. Given the differences between these datasets and the possibility that their accuracy may vary across countries, it is imperative that users have clear guidance on which datasets are appropriate for specific settings and objectives. Here we assess the accuracy of three global 10m resolution built-up datasets (ESRI, GHSL-BUILT-S2 and WSF) and three population distribution datasets (HRSL 30m, WorldPop 100m, GHS-POP 250m) for India. Among built-up datasets, the GHSL-BUILT-S2 is the most suitable for India for the 2015-2020 time period. To assess accuracy of population distribution datasets we use data from the 2011 Census of India at the level of 37,137 village and town polygons for the state of Bihar in India. Among the global datasets, HRSL has the best results. We also compute error metrics for the IDC-POP layer, a 30m resolution population dataset generated by us at the Indian Institute for Human Settlements. For Bihar, the IDC-POP population map outperforms all three global datasets.
Automatic Online Multi-Source Domain Adaptation
Sep 05, 2021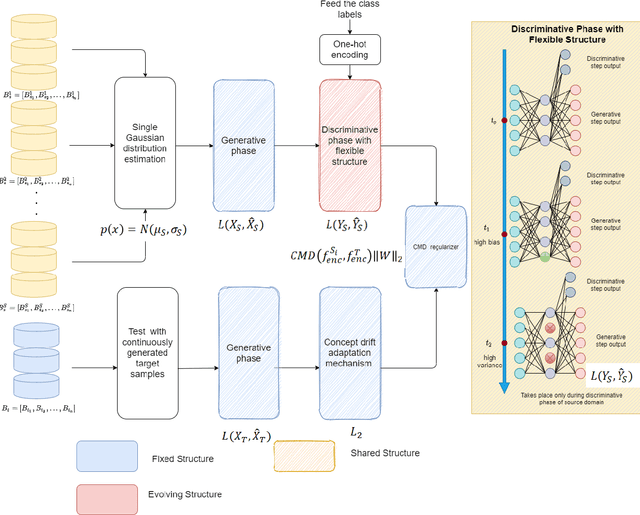
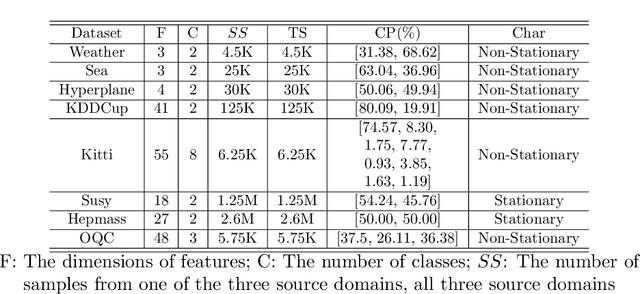
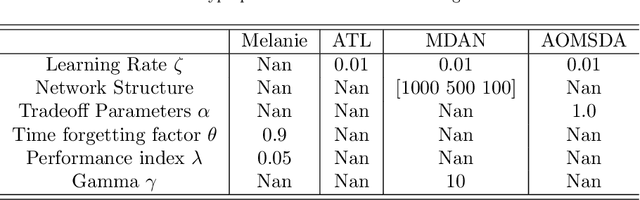
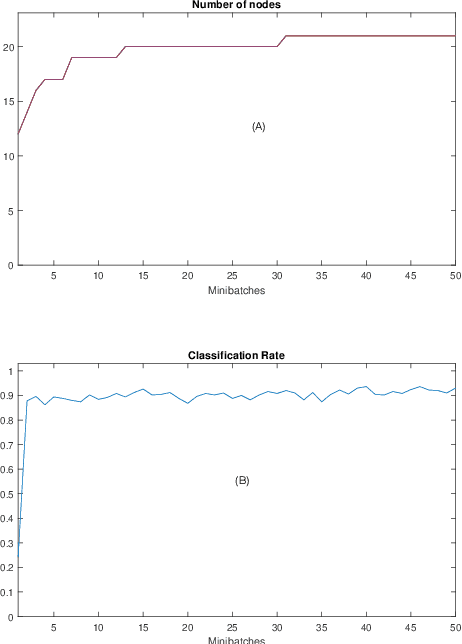
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.
Survival Prediction of Heart Failure Patients using Stacked Ensemble Machine Learning Algorithm
Aug 30, 2021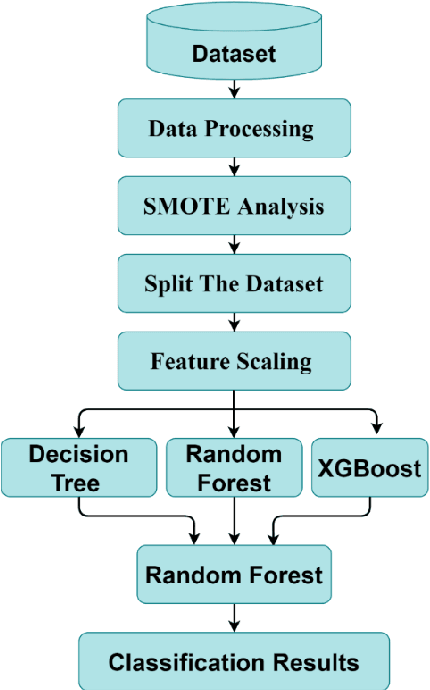
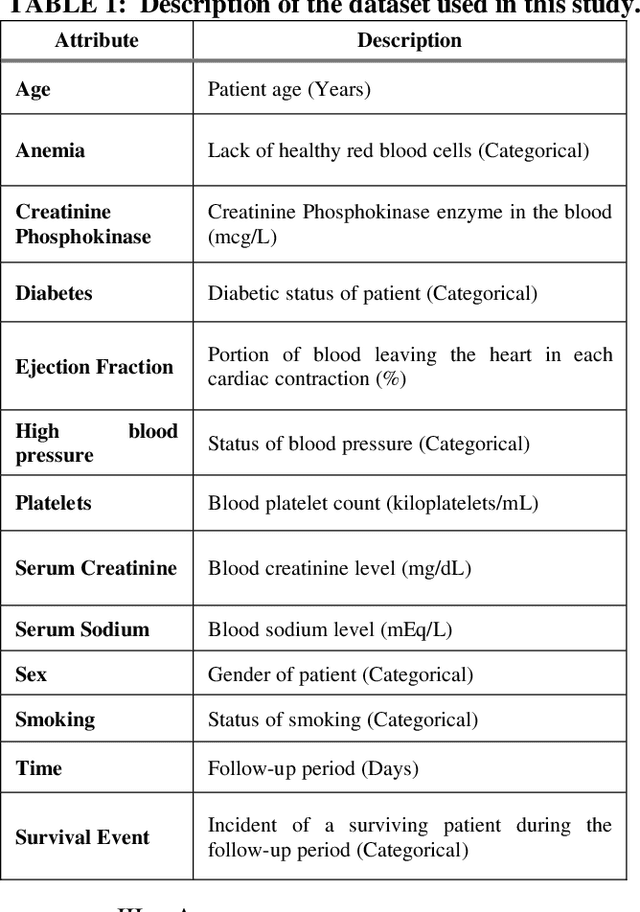
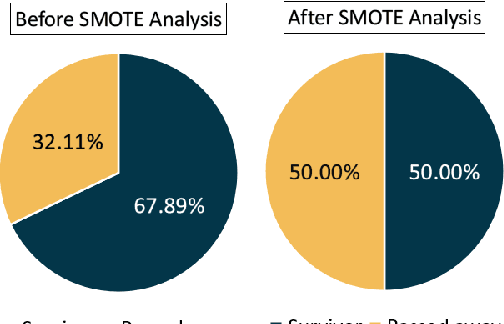
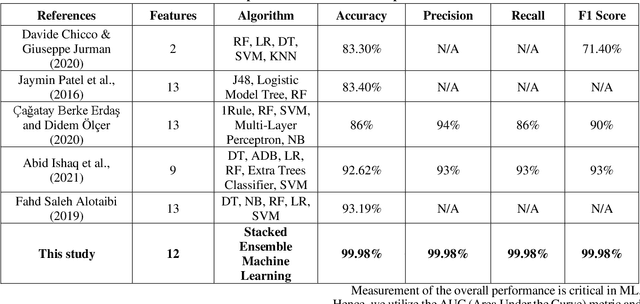
Cardiovascular disease, especially heart failure is one of the major health hazard issues of our time and is a leading cause of death worldwide. Advancement in data mining techniques using machine learning (ML) models is paving promising prediction approaches. Data mining is the process of converting massive volumes of raw data created by the healthcare institutions into meaningful information that can aid in making predictions and crucial decisions. Collecting various follow-up data from patients who have had heart failures, analyzing those data, and utilizing several ML models to predict the survival possibility of cardiovascular patients is the key aim of this study. Due to the imbalance of the classes in the dataset, Synthetic Minority Oversampling Technique (SMOTE) has been implemented. Two unsupervised models (K-Means and Fuzzy C-Means clustering) and three supervised classifiers (Random Forest, XGBoost and Decision Tree) have been used in our study. After thorough investigation, our results demonstrate a superior performance of the supervised ML algorithms over unsupervised models. Moreover, we designed and propose a supervised stacked ensemble learning model that can achieve an accuracy, precision, recall and F1 score of 99.98%. Our study shows that only certain attributes collected from the patients are imperative to successfully predict the surviving possibility post heart failure, using supervised ML algorithms.
H-Transformer-1D: Fast One-Dimensional Hierarchical Attention for Sequences
Jul 25, 2021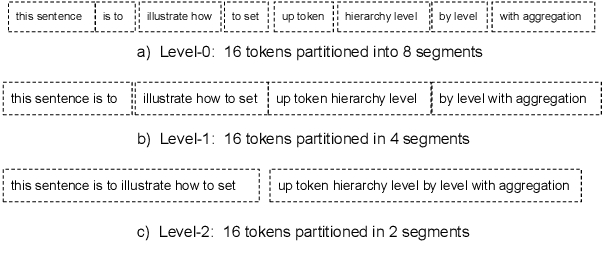
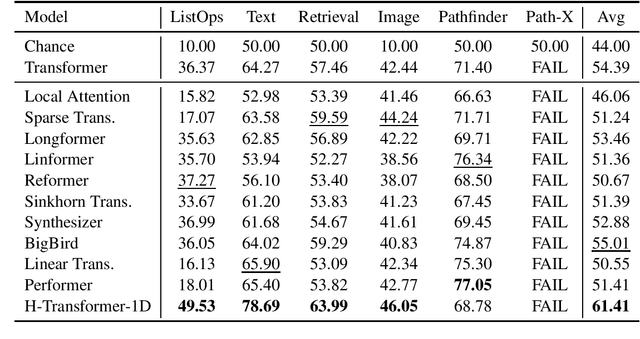
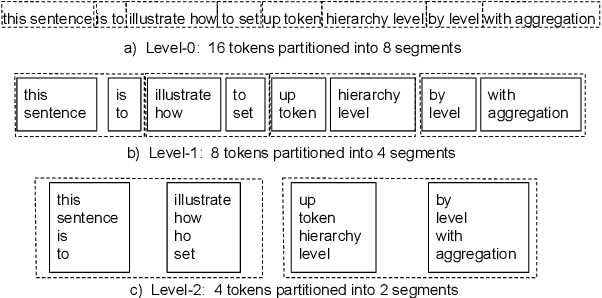
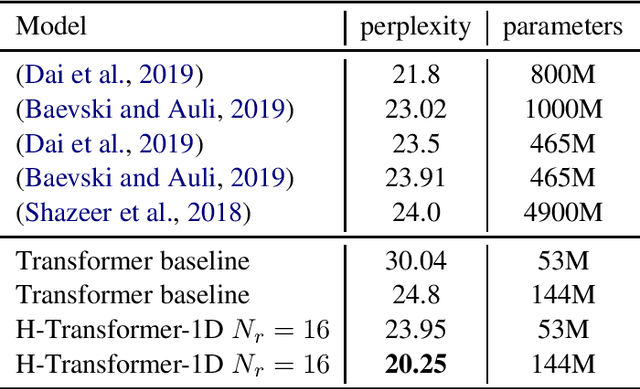
We describe an efficient hierarchical method to compute attention in the Transformer architecture. The proposed attention mechanism exploits a matrix structure similar to the Hierarchical Matrix (H-Matrix) developed by the numerical analysis community, and has linear run time and memory complexity. We perform extensive experiments to show that the inductive bias embodied by our hierarchical attention is effective in capturing the hierarchical structure in the sequences typical for natural language and vision tasks. Our method is superior to alternative sub-quadratic proposals by over +6 points on average on the Long Range Arena benchmark. It also sets a new SOTA test perplexity on One-Billion Word dataset with 5x fewer model parameters than that of the previous-best Transformer-based models.
GalaxAI: Machine learning toolbox for interpretable analysis of spacecraft telemetry data
Aug 03, 2021
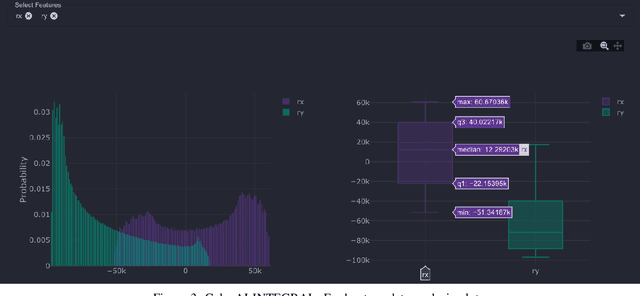
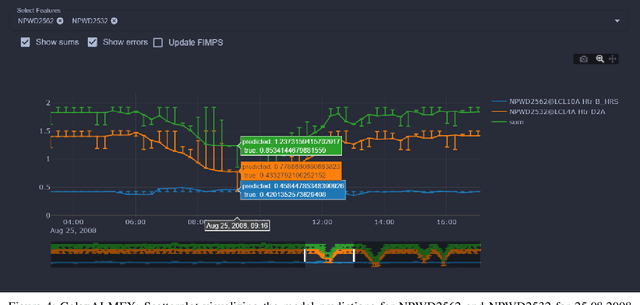
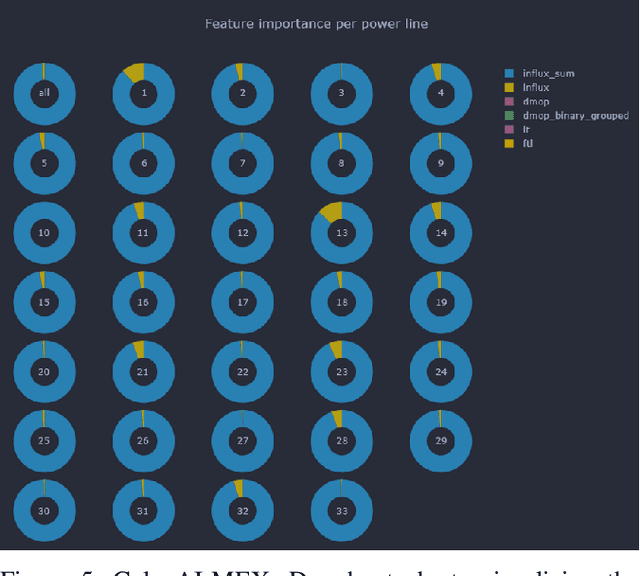
We present GalaxAI - a versatile machine learning toolbox for efficient and interpretable end-to-end analysis of spacecraft telemetry data. GalaxAI employs various machine learning algorithms for multivariate time series analyses, classification, regression and structured output prediction, capable of handling high-throughput heterogeneous data. These methods allow for the construction of robust and accurate predictive models, that are in turn applied to different tasks of spacecraft monitoring and operations planning. More importantly, besides the accurate building of models, GalaxAI implements a visualisation layer, providing mission specialists and operators with a full, detailed and interpretable view of the data analysis process. We show the utility and versatility of GalaxAI on two use-cases concerning two different spacecraft: i) analysis and planning of Mars Express thermal power consumption and ii) predicting of INTEGRAL's crossings through Van Allen belts.
Maximizing the Set Cardinality of Users Scheduled for Ultra-dense uRLLC Networks
Jul 21, 2021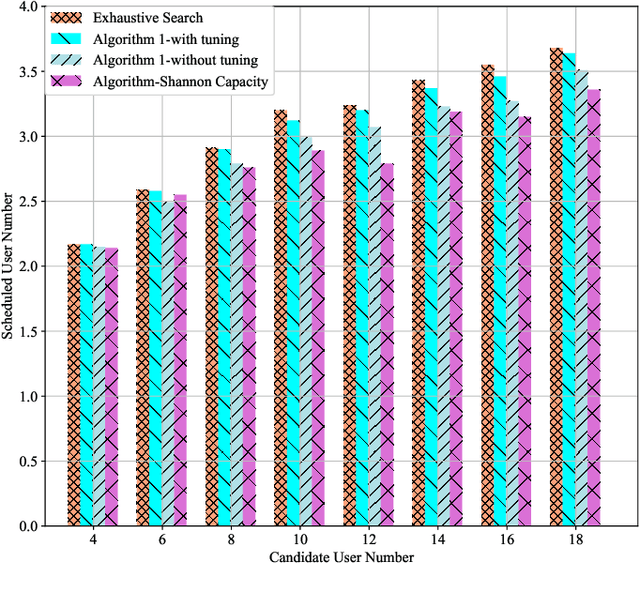
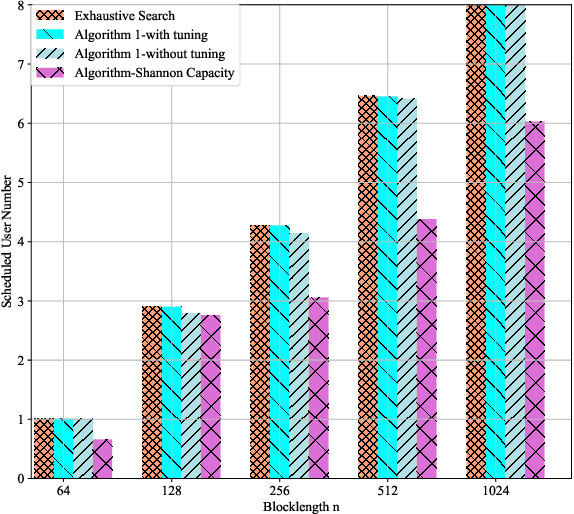
Ultra-reliability and low latency communication plays an important role in the fifth and sixth generation communication systems. Among the different research issues, scheduling as many users as possible to serve on the limited time-frequency resource is a crucial topic, with requirement of the maximum allowable transmission power and the minimum rate requirement of each user.We address it by proposing a mixed integer programming model, with objective function is maximizing the set cardinality of users instead of maximizing the system sum rate. Mathematical transformations and successive convex approximation are combined to solve the problem. Numerical results show that the proposed method achieves a considerable performance compared with exhaustive search method, but with lower computational complexity.
A contextual analysis of multi-layer perceptron models in classifying hand-written digits and letters: limited resources
Jul 05, 2021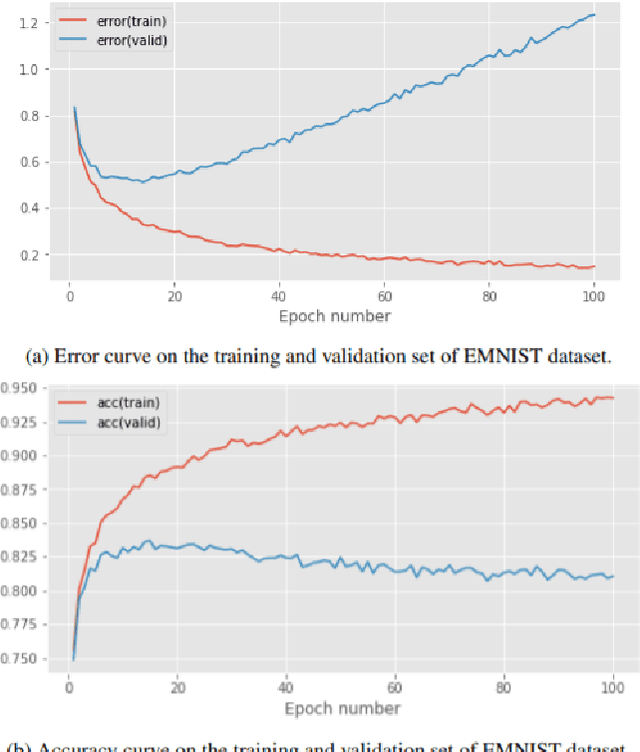
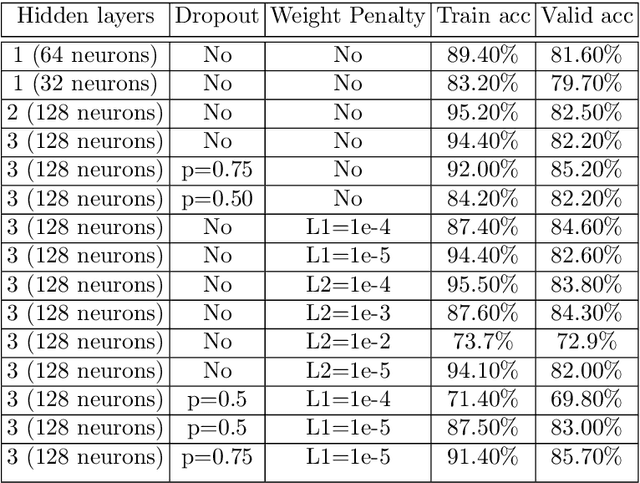
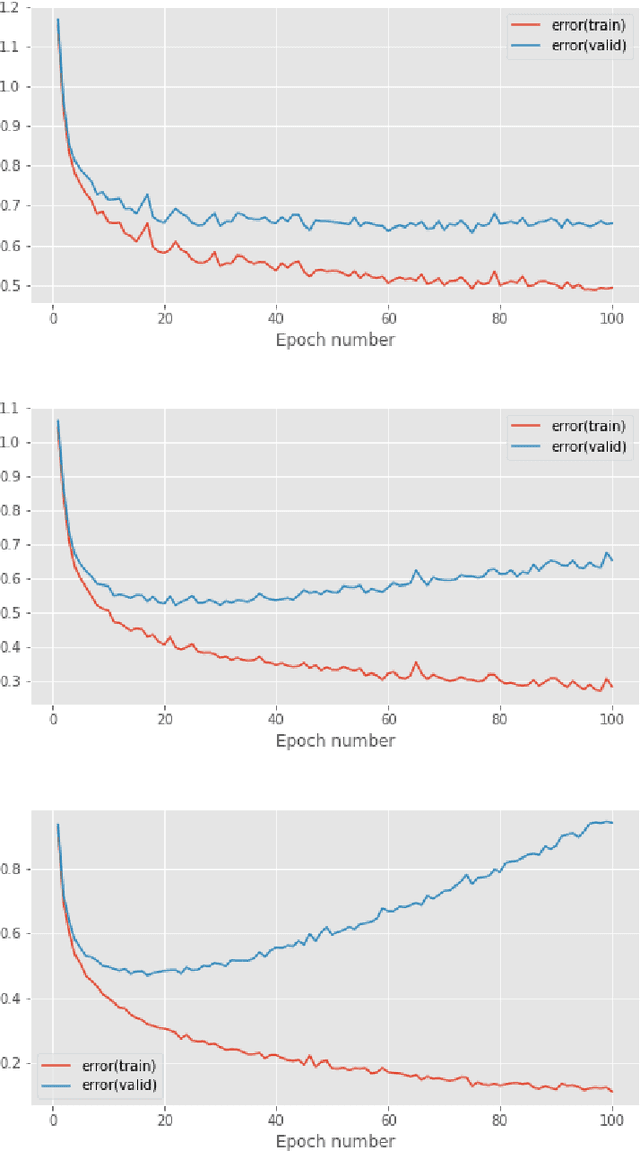
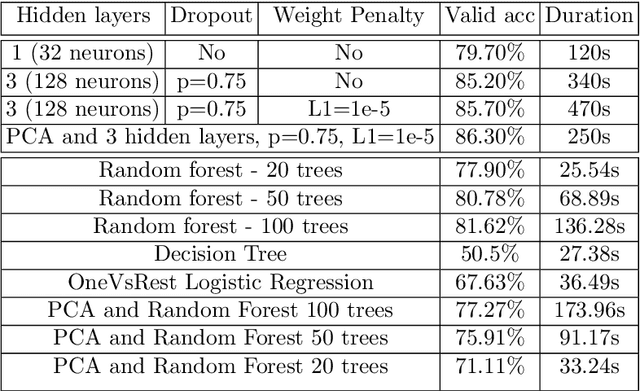
Classifying hand-written digits and letters has taken a big leap with the introduction of ConvNets. However, on very constrained hardware the time necessary to train such models would be high. Our main contribution is twofold. First, we extensively test an end-to-end vanilla neural network (MLP) approach in pure numpy without any pre-processing or feature extraction done beforehand. Second, we show that basic data mining operations can significantly improve the performance of the models in terms of computational time, without sacrificing much accuracy. We illustrate our claims on a simpler variant of the Extended MNIST dataset, called Balanced EMNIST dataset. Our experiments show that, without any data mining, we get increased generalization performance when using more hidden layers and regularization techniques, the best model achieving 84.83% accuracy on a test dataset. Using dimensionality reduction done by PCA we were able to increase that figure to 85.08% with only 10% of the original feature space, reducing the memory size needed by 64%. Finally, adding methods to remove possibly harmful training samples like deviation from the mean helped us to still achieve over 84% test accuracy but with only 32.8% of the original memory size for the training set. This compares favorably to the majority of literature results obtained through similar architectures. Although this approach gets outshined by state-of-the-art models, it does scale to some (AlexNet, VGGNet) trained on 50% of the same dataset.
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Jun 29, 2019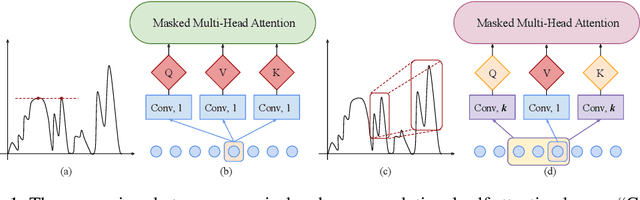
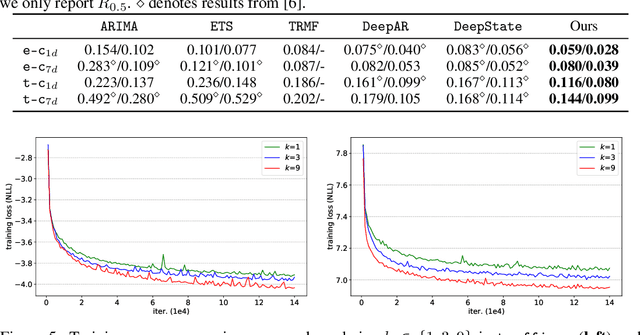
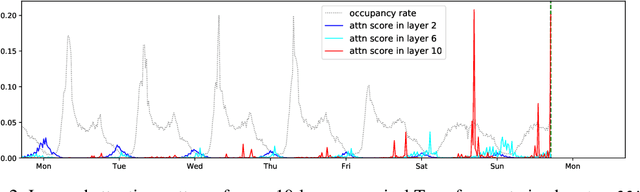

Time series forecasting is an important problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. In this paper, we propose to tackle such forecasting problem with Transformer. Although impressed by its performance in our preliminary study, we found its two major weaknesses: (1) locality-agnostics: the point-wise dot-product self attention in canonical Transformer architecture is insensitive to local context, which can make the model prone to anomalies in time series; (2) memory bottleneck: space complexity of canonical Transformer grows quadratically with sequence length $L$, making modeling long time series infeasible. In order to solve these two issues, we first propose convolutional self attention by producing queries and keys with causal convolution so that local context can be better incorporated into attention mechanism. Then, we propose LogSparse Transformer with only $O(L(\log L)^{2})$ memory cost, improving the time series forecasting in finer granularity under constrained memory budget. Our experiments on both synthetic data and real-world datasets show that it compares favorably to the state-of-the-art.
ConveRT for FAQ Answering
Aug 03, 2021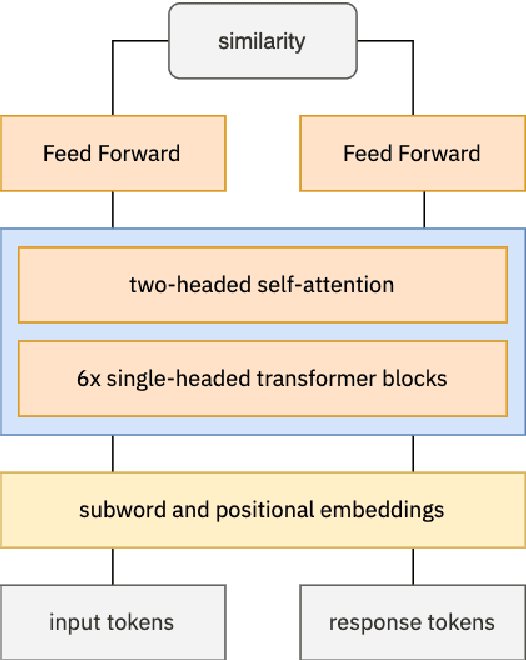
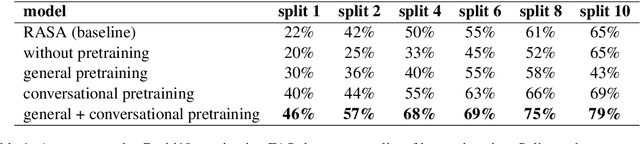
Knowledgeable FAQ chatbots are a valuable resource to any organization. Unlike traditional call centers or FAQ web pages, they provide instant responses and are always available. Our experience running a COVID19 chatbot revealed the lack of resources available for FAQ answering in non-English languages. While powerful and efficient retrieval-based models exist for English, it is rarely the case for other languages which do not have the same amount of training data available. In this work, we propose a novel pretaining procedure to adapt ConveRT, an English SOTA conversational agent, to other languages with less training data available. We apply it for the first time to the task of Dutch FAQ answering related to the COVID19 vaccine. We show it performs better than an open-source alternative in a low-data regime and high-data regime.