 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Evolutionary Batch Size Orchestration for Scheduling Deep Learning Workloads in GPU Clusters
Aug 08, 2021

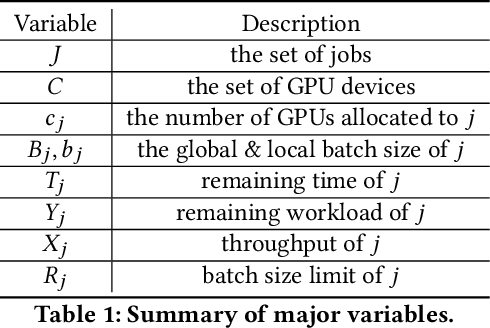
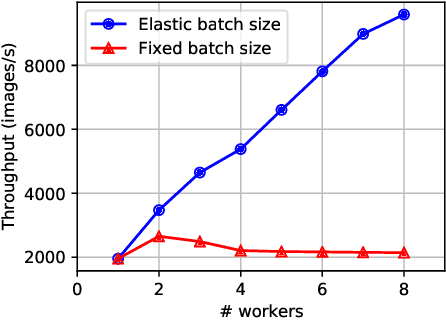
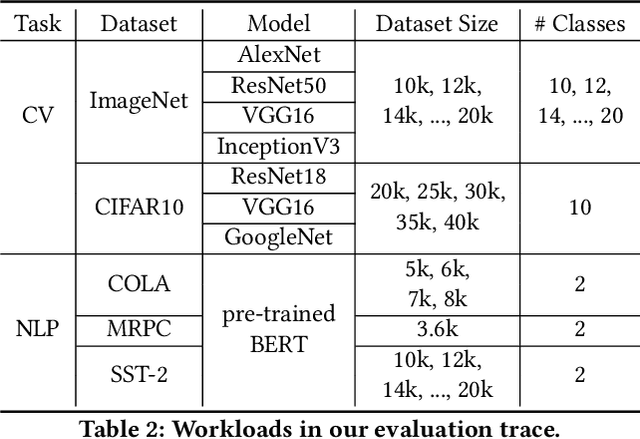
Efficient GPU resource scheduling is essential to maximize resource utilization and save training costs for the increasing amount of deep learning workloads in shared GPU clusters. Existing GPU schedulers largely rely on static policies to leverage the performance characteristics of deep learning jobs. However, they can hardly reach optimal efficiency due to the lack of elasticity. To address the problem, we propose ONES, an ONline Evolutionary Scheduler for elastic batch size orchestration. ONES automatically manages the elasticity of each job based on the training batch size, so as to maximize GPU utilization and improve scheduling efficiency. It determines the batch size for each job through an online evolutionary search that can continuously optimize the scheduling decisions. We evaluate the effectiveness of ONES with 64 GPUs on TACC's Longhorn supercomputers. The results show that ONES can outperform the prior deep learning schedulers with a significantly shorter average job completion time.
LoRa-RL: Deep Reinforcement Learning for Resource Management in Hybrid Energy LoRa Wireless Networks
Sep 06, 2021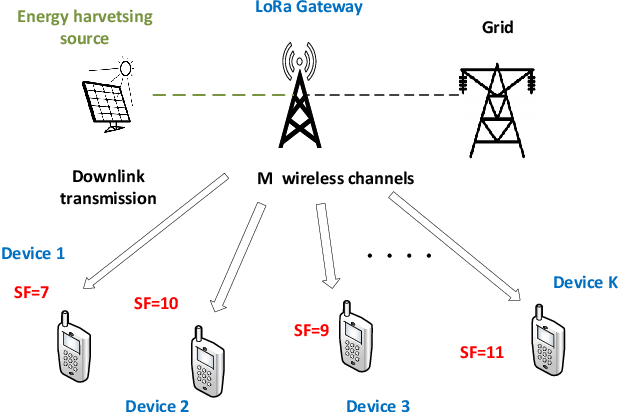
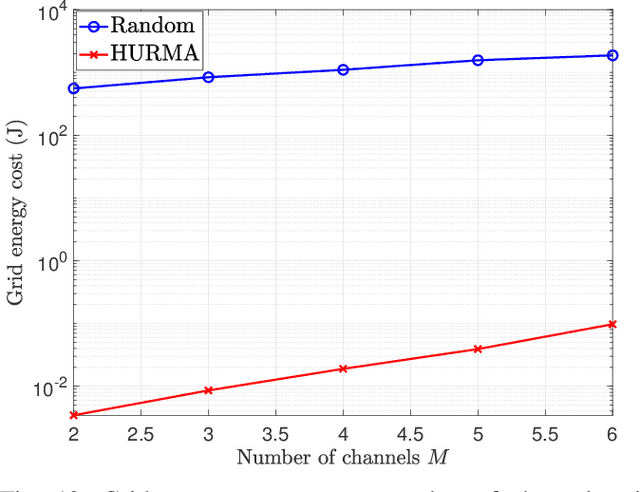
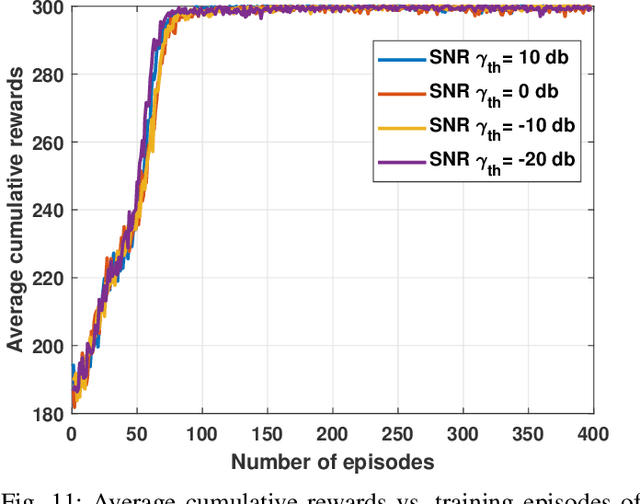
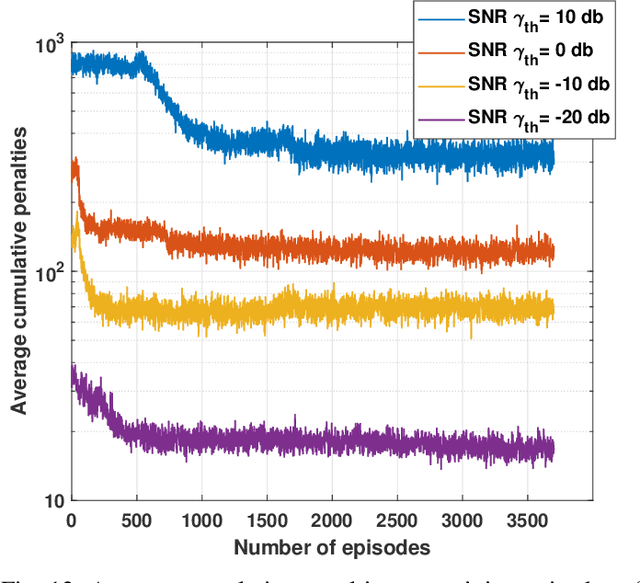
LoRa wireless networks are considered as a key enabling technology for next generation internet of things (IoT) systems. New IoT deployments (e.g., smart city scenarios) can have thousands of devices per square kilometer leading to huge amount of power consumption to provide connectivity. In this paper, we investigate green LoRa wireless networks powered by a hybrid of the grid and renewable energy sources, which can benefit from harvested energy while dealing with the intermittent supply. This paper proposes resource management schemes of the limited number of channels and spreading factors (SFs) with the objective of improving the LoRa gateway energy efficiency. First, the problem of grid power consumption minimization while satisfying the system's quality of service demands is formulated. Specifically, both scenarios the uncorrelated and time-correlated channels are investigated. The optimal resource management problem is solved by decoupling the formulated problem into two sub-problems: channel and SF assignment problem and energy management problem. Since the optimal solution is obtained with high complexity, online resource management heuristic algorithms that minimize the grid energy consumption are proposed. Finally, taking into account the channel and energy correlation, adaptable resource management schemes based on Reinforcement Learning (RL), are developed. Simulations results show that the proposed resource management schemes offer efficient use of renewable energy in LoRa wireless networks.
A Comparative Study of Machine Learning Methods for Predicting the Evolution of Brain Connectivity from a Baseline Timepoint
Sep 16, 2021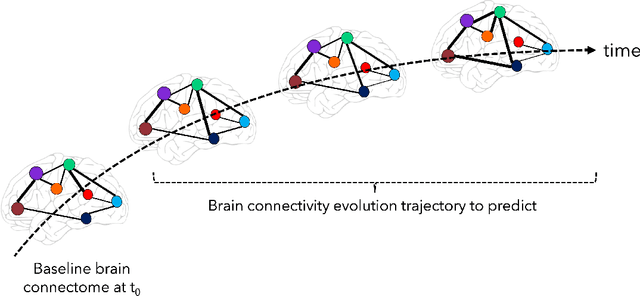
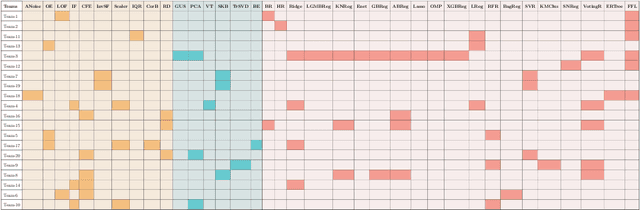
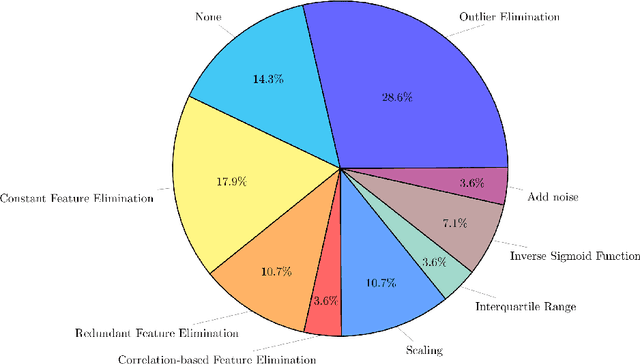
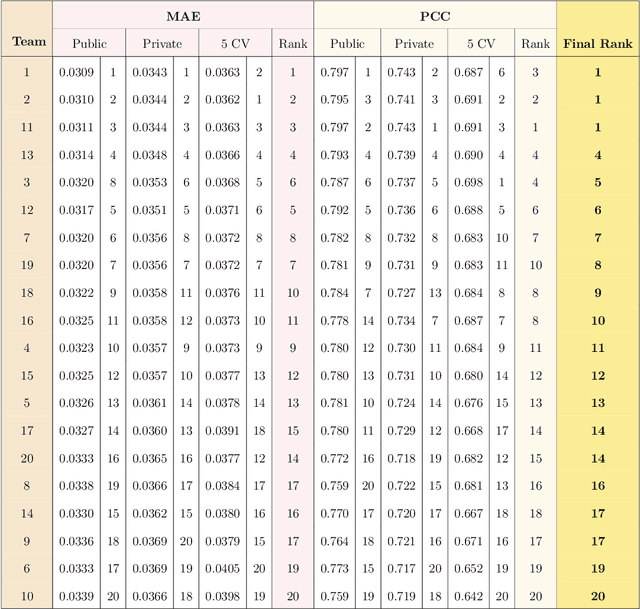
Predicting the evolution of the brain network, also called connectome, by foreseeing changes in the connectivity weights linking pairs of anatomical regions makes it possible to spot connectivity-related neurological disorders in earlier stages and detect the development of potential connectomic anomalies. Remarkably, such a challenging prediction problem remains least explored in the predictive connectomics literature. It is a known fact that machine learning (ML) methods have proven their predictive abilities in a wide variety of computer vision problems. However, ML techniques specifically tailored for the prediction of brain connectivity evolution trajectory from a single timepoint are almost absent. To fill this gap, we organized a Kaggle competition where 20 competing teams designed advanced machine learning pipelines for predicting the brain connectivity evolution from a single timepoint. The competing teams developed their ML pipelines with a combination of data pre-processing, dimensionality reduction, and learning methods. Utilizing an inclusive evaluation approach, we ranked the methods based on two complementary evaluation metrics (mean absolute error (MAE) and Pearson Correlation Coefficient (PCC)) and their performances using different training and testing data perturbation strategies (single random split and cross-validation). The final rank was calculated using the rank product for each competing team across all evaluation measures and validation strategies. In support of open science, the developed 20 ML pipelines along with the connectomic dataset are made available on GitHub. The outcomes of this competition are anticipated to lead to the further development of predictive models that can foresee the evolution of brain connectivity over time, as well as other types of networks (e.g., genetic networks).
AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba
Jun 03, 2021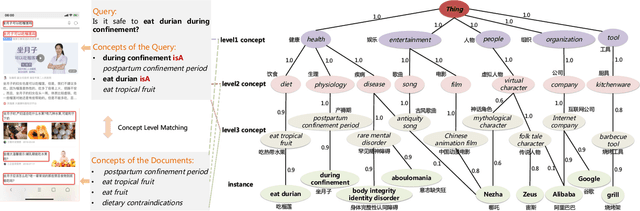
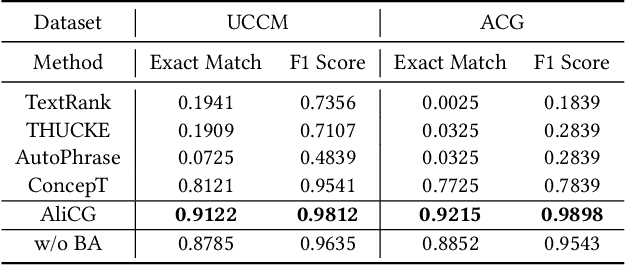
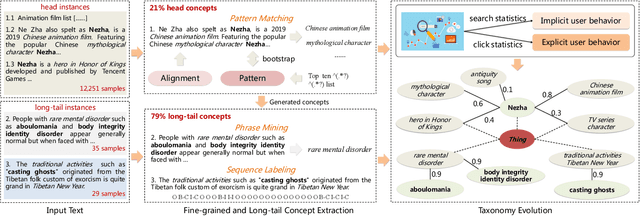

Conceptual graphs, which is a particular type of Knowledge Graphs, play an essential role in semantic search. Prior conceptual graph construction approaches typically extract high-frequent, coarse-grained, and time-invariant concepts from formal texts. In real applications, however, it is necessary to extract less-frequent, fine-grained, and time-varying conceptual knowledge and build taxonomy in an evolving manner. In this paper, we introduce an approach to implementing and deploying the conceptual graph at Alibaba. Specifically, We propose a framework called AliCG which is capable of a) extracting fine-grained concepts by a novel bootstrapping with alignment consensus approach, b) mining long-tail concepts with a novel low-resource phrase mining approach, c) updating the graph dynamically via a concept distribution estimation method based on implicit and explicit user behaviors. We have deployed the framework at Alibaba UC Browser. Extensive offline evaluation as well as online A/B testing demonstrate the efficacy of our approach.
More but Correct: Generating Diversified and Entity-revised Medical Response
Aug 19, 2021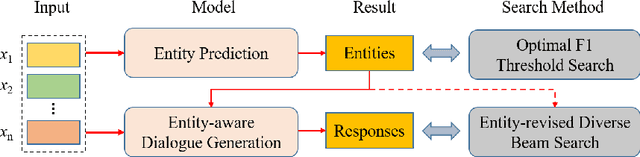
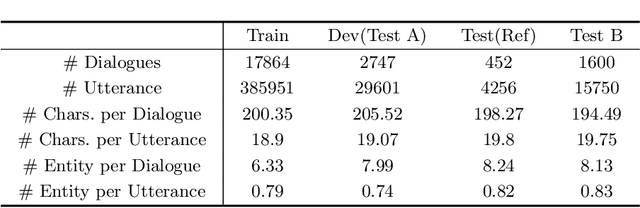
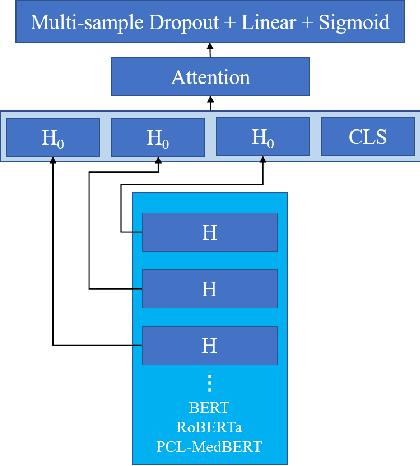
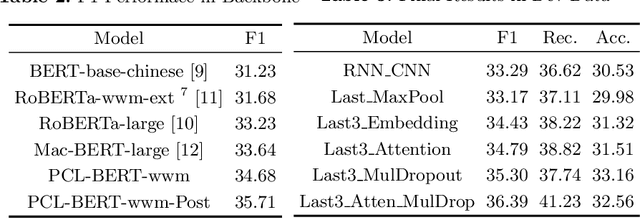
Medical Dialogue Generation (MDG) is intended to build a medical dialogue system for intelligent consultation, which can communicate with patients in real-time, thereby improving the efficiency of clinical diagnosis with broad application prospects. This paper presents our proposed framework for the Chinese MDG organized by the 2021 China conference on knowledge graph and semantic computing (CCKS) competition, which requires generating context-consistent and medically meaningful responses conditioned on the dialogue history. In our framework, we propose a pipeline system composed of entity prediction and entity-aware dialogue generation, by adding predicted entities to the dialogue model with a fusion mechanism, thereby utilizing information from different sources. At the decoding stage, we propose a new decoding mechanism named Entity-revised Diverse Beam Search (EDBS) to improve entity correctness and promote the length and quality of the final response. The proposed method wins both the CCKS and the International Conference on Learning Representations (ICLR) 2021 Workshop Machine Learning for Preventing and Combating Pandemics (MLPCP) Track 1 Entity-aware MED competitions, which demonstrate the practicality and effectiveness of our method.
Lifelong Infinite Mixture Model Based on Knowledge-Driven Dirichlet Process
Aug 25, 2021
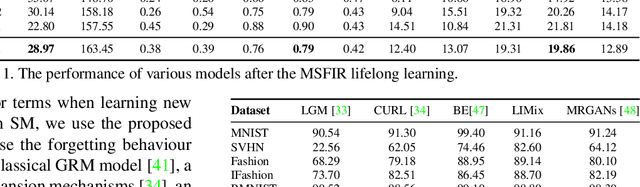
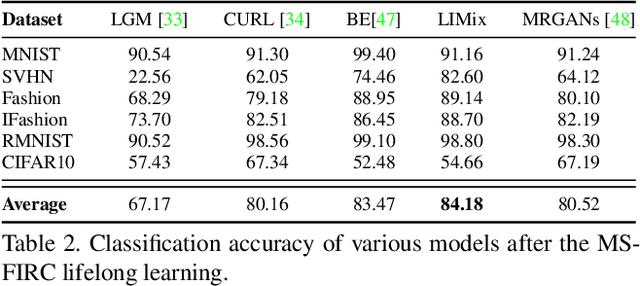

Recent research efforts in lifelong learning propose to grow a mixture of models to adapt to an increasing number of tasks. The proposed methodology shows promising results in overcoming catastrophic forgetting. However, the theory behind these successful models is still not well understood. In this paper, we perform the theoretical analysis for lifelong learning models by deriving the risk bounds based on the discrepancy distance between the probabilistic representation of data generated by the model and that corresponding to the target dataset. Inspired by the theoretical analysis, we introduce a new lifelong learning approach, namely the Lifelong Infinite Mixture (LIMix) model, which can automatically expand its network architectures or choose an appropriate component to adapt its parameters for learning a new task, while preserving its previously learnt information. We propose to incorporate the knowledge by means of Dirichlet processes by using a gating mechanism which computes the dependence between the knowledge learnt previously and stored in each component, and a new set of data. Besides, we train a compact Student model which can accumulate cross-domain representations over time and make quick inferences. The code is available at https://github.com/dtuzi123/Lifelong-infinite-mixture-model.
A Frequency Domain Constraint for Synthetic X-ray Image Super Resolution
May 14, 2021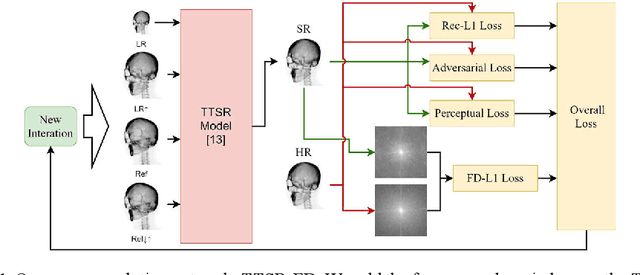

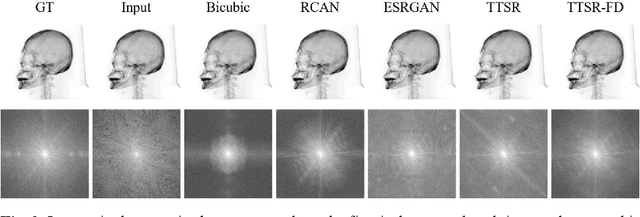

Synthetic X-ray images can be helpful for image guiding systems and VR simulations. However, it is difficult to produce high-quality arbitrary view synthetic X-ray images in real-time due to limited CT scanning resolution, high computation resource demand or algorithm complexity. Our goal is to generate high-resolution synthetic X-ray images in real-time by upsampling low-resolution im-ages. Reference-based Super Resolution (RefSR) has been well studied in recent years and has been proven to be more powerful than traditional Single Image Su-per-Resolution (SISR). RefSR can produce fine details by utilizing the reference image but it still inevitably generates some artifacts and noise. In this paper, we propose texture transformer super-resolution with frequency domain (TTSR-FD). We introduce frequency domain loss as a constraint to further improve the quality of the RefSR results with fine details and without obvious artifacts. This makes a real-time synthetic X-ray image-guided procedure VR simulation system possible. To the best of our knowledge, this is the first paper utilizing the frequency domain as part of the loss functions in the field of super-resolution. We evaluated TTSR-FD on our synthetic X-ray image dataset and achieved state-of-the-art results.
R-PCC: A Baseline for Range Image-based Point Cloud Compression
Sep 16, 2021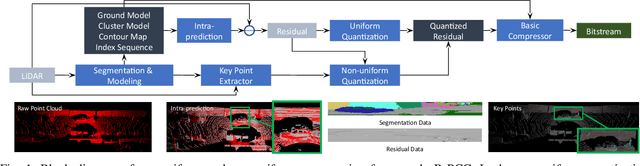
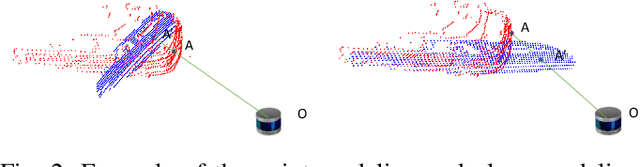

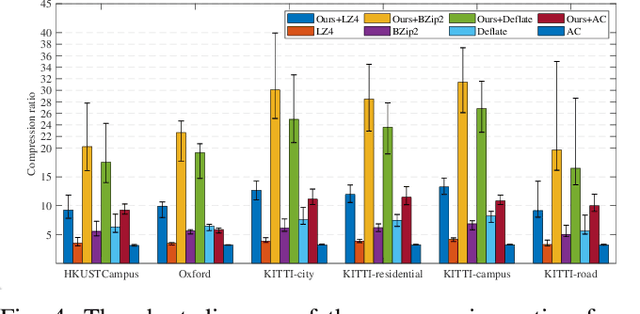
In autonomous vehicles or robots, point clouds from LiDAR can provide accurate depth information of objects compared with 2D images, but they also suffer a large volume of data, which is inconvenient for data storage or transmission. In this paper, we propose a Range image-based Point Cloud Compression method, R-PCC, which can reconstruct the point cloud with uniform or non-uniform accuracy loss. We segment the original large-scale point cloud into small and compact regions for spatial redundancy and salient region classification. Compared with other voxel-based or image-based compression methods, our method can keep and align all points from the original point cloud in the reconstructed point cloud. It can also control the maximum reconstruction error for each point through a quantization module. In the experiments, we prove that our easier FPS-based segmentation method can achieve better performance than instance-based segmentation methods such as DBSCAN. To verify the advantages of our proposed method, we evaluate the reconstruction quality and fidelity for 3D object detection and SLAM, as the downstream tasks. The experimental results show that our elegant framework can achieve 30$\times$ compression ratio without affecting downstream tasks, and our non-uniform compression framework shows a great improvement on the downstream tasks compared with the state-of-the-art large-scale point cloud compression methods. Our real-time method is efficient and effective enough to act as a baseline for range image-based point cloud compression. The code is available on https://github.com/StevenWang30/R-PCC.git.
Data-Driven Reduced-Order Modeling of Spatiotemporal Chaos with Neural Ordinary Differential Equations
Aug 31, 2021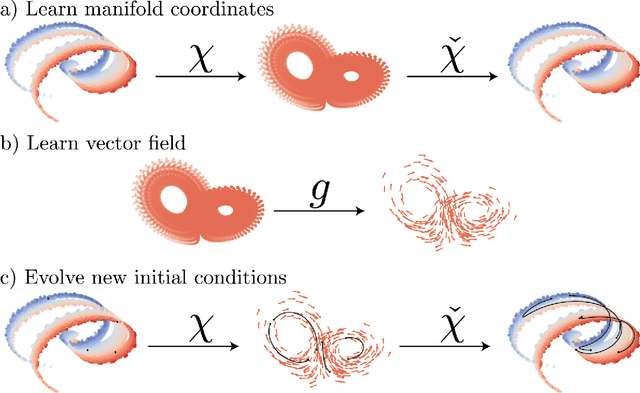
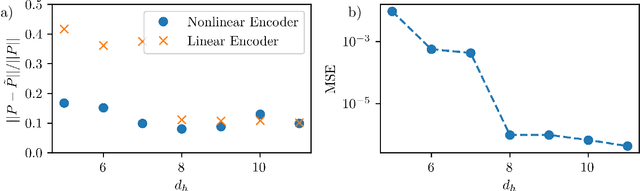
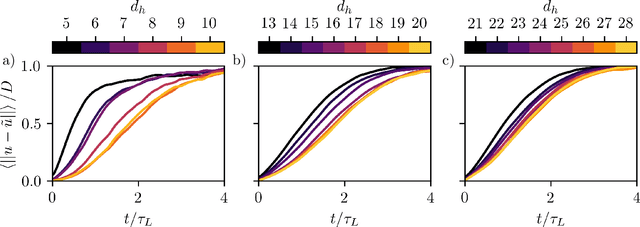
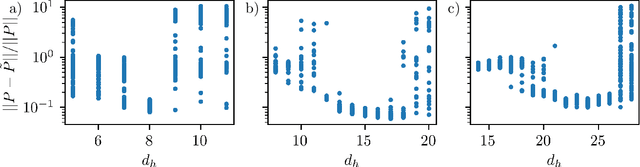
Dissipative partial differential equations that exhibit chaotic dynamics tend to evolve to attractors that exist on finite-dimensional manifolds. We present a data-driven reduced order modeling method that capitalizes on this fact by finding the coordinates of this manifold and finding an ordinary differential equation (ODE) describing the dynamics in this coordinate system. The manifold coordinates are discovered using an undercomplete autoencoder -- a neural network (NN) that reduces then expands dimension. Then the ODE, in these coordinates, is approximated by a NN using the neural ODE framework. Both of these methods only require snapshots of data to learn a model, and the data can be widely and/or unevenly spaced. We apply this framework to the Kuramoto-Sivashinsky for different domain sizes that exhibit chaotic dynamics. With this system, we find that dimension reduction improves performance relative to predictions in the ambient space, where artifacts arise. Then, with the low-dimensional model, we vary the training data spacing and find excellent short- and long-time statistical recreation of the true dynamics for widely spaced data (spacing of ~0.7 Lyapunov times). We end by comparing performance with various degrees of dimension reduction, and find a "sweet spot" in terms of performance vs. dimension.
Scalable Spatiotemporally Varying Coefficient Modeling with Bayesian Kernelized Tensor Regression
Aug 31, 2021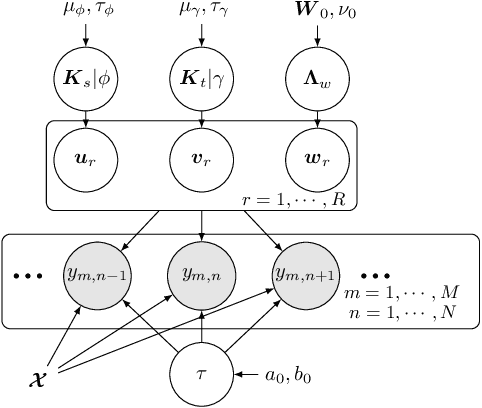
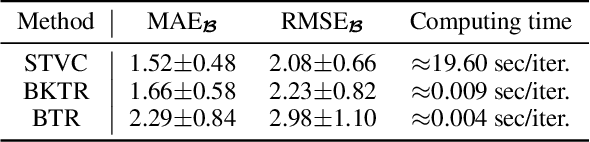
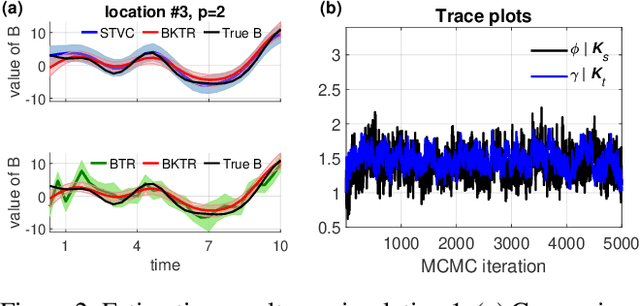

As a regression technique in spatial statistics, spatiotemporally varying coefficient model (STVC) is an important tool to discover nonstationary and interpretable response-covariate associations over both space and time. However, it is difficult to apply STVC for large-scale spatiotemporal analysis due to the high computational cost. To address this challenge, we summarize the spatiotemporally varying coefficients using a third-order tensor structure and propose to reformulate the spatiotemporally varying coefficient model as a special low-rank tensor regression problem. The low-rank decomposition can effectively model the global patterns of the large data with substantially reduced number of parameters. To further incorporate the local spatiotemporal dependencies among the samples, we place Gaussian process (GP) priors on the spatial and temporal factor matrices to better encode local spatial and temporal processes on each factor component. We refer to the overall framework as Bayesian Kernelized Tensor Regression (BKTR). For model inference, we develop an efficient Markov chain Monte Carlo (MCMC) algorithm, which uses Gibbs sampling to update factor matrices and slice sampling to update kernel hyperparameters. We conduct extensive experiments on both synthetic and real-world data sets, and our results confirm the superior performance and efficiency of BKTR for model estimation and parameter inference.