 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Focus on Impact: Indoor Exploration with Intrinsic Motivation
Sep 14, 2021
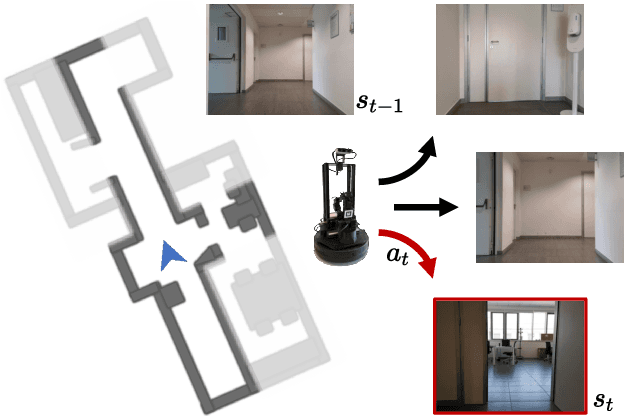
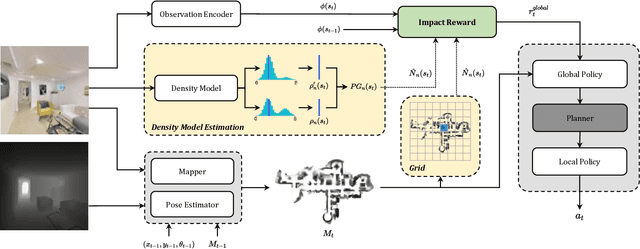

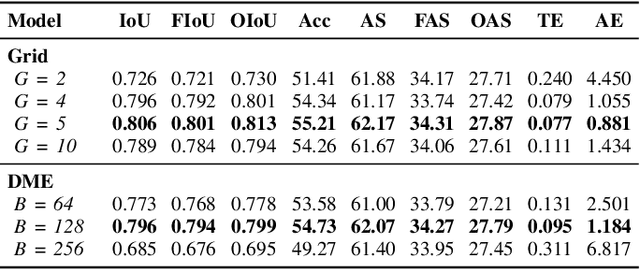
Exploration of indoor environments has recently experienced a significant interest, also thanks to the introduction of deep neural agents built in a hierarchical fashion and trained with Deep Reinforcement Learning (DRL) on simulated environments. Current state-of-the-art methods employ a dense extrinsic reward that requires the complete a priori knowledge of the layout of the training environment to learn an effective exploration policy. However, such information is expensive to gather in terms of time and resources. In this work, we propose to train the model with a purely intrinsic reward signal to guide exploration, which is based on the impact of the robot's actions on the environment. So far, impact-based rewards have been employed for simple tasks and in procedurally generated synthetic environments with countable states. Since the number of states observable by the agent in realistic indoor environments is non-countable, we include a neural-based density model and replace the traditional count-based regularization with an estimated pseudo-count of previously visited states. The proposed exploration approach outperforms DRL-based competitors relying on intrinsic rewards and surpasses the agents trained with a dense extrinsic reward computed with the environment layouts. We also show that a robot equipped with the proposed approach seamlessly adapts to point-goal navigation and real-world deployment.
Probabilistic Bearing Fault Diagnosis Using Gaussian Process with Tailored Feature Extraction
Sep 19, 2021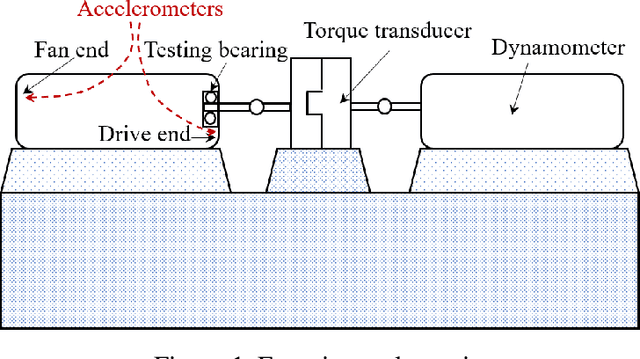
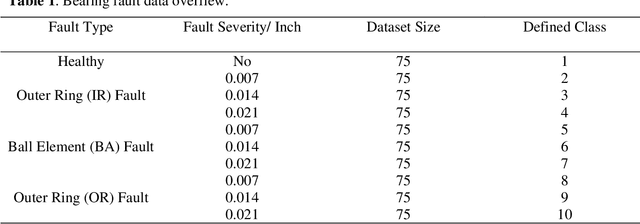
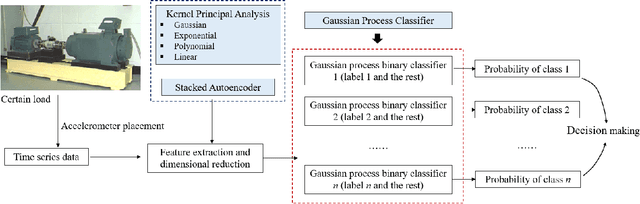

Rolling bearings are subject to various faults due to its long-time operation under harsh environment, which will lead to unexpected breakdown of machinery system and cause severe accidents. Deep learning methods recently have gained growing interests and extensively applied in the data-driven bearing fault diagnosis. However, current deep learning methods perform the bearing fault diagnosis in the form of deterministic classification, which overlook the uncertainties that inevitably exist in actual practice. To tackle this issue, in this research we develop a probabilistic fault diagnosis framework that can account for the uncertainty effect in prediction, which bears practical significance. This framework fully leverages the probabilistic feature of Gaussian process classifier (GPC). To facilitate the establishment of high-fidelity GPC, the tailored feature extraction with dimensionality reduction method can be optimally determined through the cross validation-based grid search upon a prespecified method pool consisting of various kernel principal component analysis (KPCA) methods and stacked autoencoder. This strategy can ensure the complex nonlinear relations between the features and faults to be adequately characterized. Furthermore, the sensor fusion concept is adopted to enhance the diagnosis performance. As compared with the traditional deep learning methods, this proposed framework usually requires less labeled data and less effort for parameter tuning. Systematic case studies using the publicly accessible experimental rolling bearing dataset are carried out to validate this new framework. Various influencing factors on fault diagnosis performance also are thoroughly investigated.
Ghost Projection
Sep 03, 2021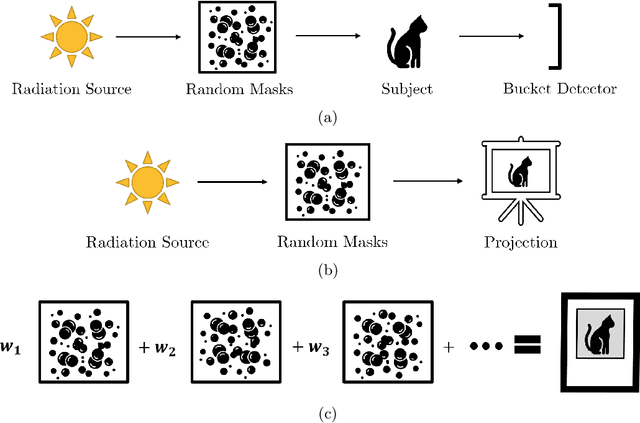
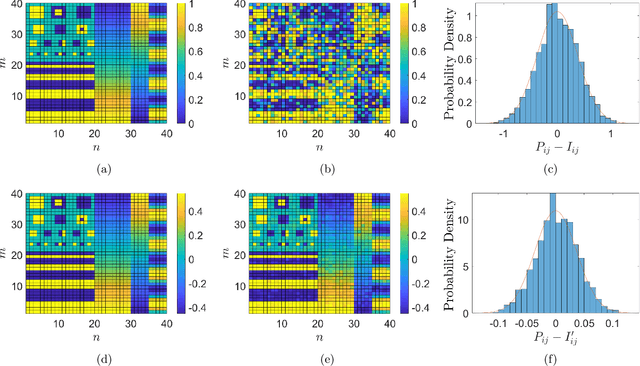
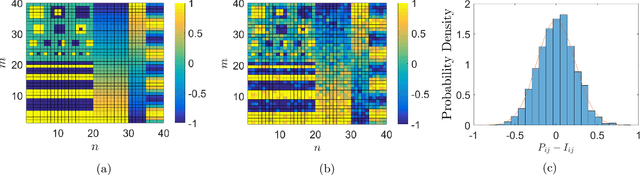
Ghost imaging is a developing imaging technique that employs random masks to image a sample. Ghost projection utilizes ghost-imaging concepts to perform the complementary procedure of projection of a desired image. The key idea underpinning ghost projection is that any desired spatial distribution of radiant exposure may be produced, up to an additive constant, by spatially-uniformly illuminating a set of random masks in succession. We explore three means of achieving ghost projection: (i) weighting each random mask, namely selecting its exposure time, according to its correlation with a desired image, (ii) selecting a subset of random masks according to their correlation with a desired image, and (iii) numerically optimizing a projection for a given set of random masks and desired image. The first two protocols are analytically tractable and conceptually transparent. The third is more efficient but less amenable to closed-form analytical expressions. A comparison with existing image-projection techniques is drawn and possible applications are discussed. These potential applications include: (i) a data projector for matter and radiation fields for which no current data projectors exist, (ii) a universal-mask approach to lithography, (iii) tomographic volumetric additive manufacturing, and (iv) a ghost-projection photocopier.
Robust Physics-Based Manipulation by Interleaving Open and Closed-Loop Execution
May 18, 2021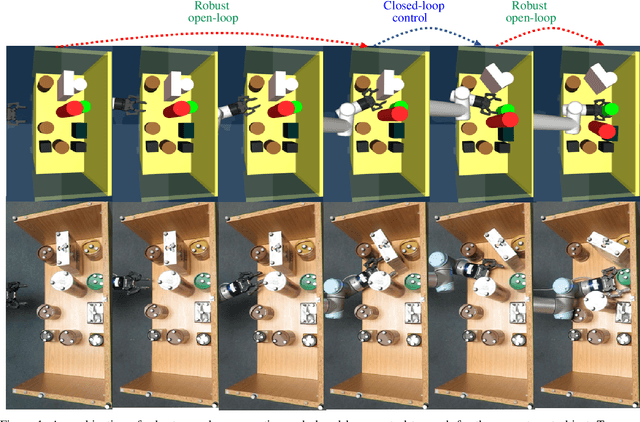

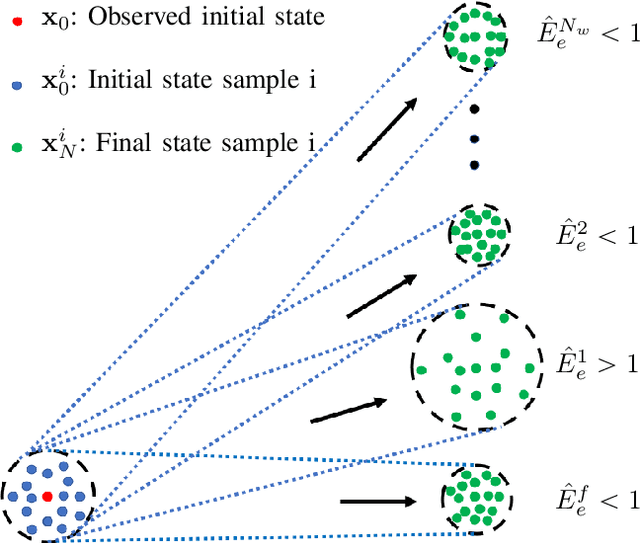
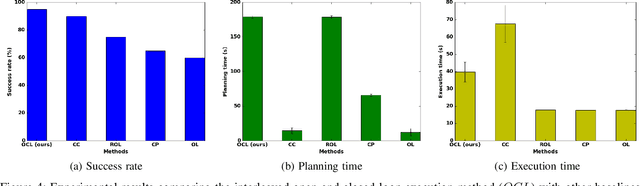
We present a planning and control framework for physics-based manipulation under uncertainty. The key idea is to interleave robust open-loop execution with closed-loop control. We derive robustness metrics through contraction theory. We use these metrics to plan trajectories that are robust to both state uncertainty and model inaccuracies. However, fully robust trajectories are extremely difficult to find or may not exist for many multi-contact manipulation problems. We separate a trajectory into robust and non-robust segments through a minimum cost path search on a robustness graph. Robust segments are executed open-loop and non-robust segments are executed with model-predictive control. We conduct experiments on a real robotic system for reaching in clutter. Our results suggest that the open and closed-loop approach results in up to 35% more real-world success compared to open-loop baselines and a 40% reduction in execution time compared to model-predictive control. We show for the first time that partially open-loop manipulation plans generated with our approach reach similar success rates to model-predictive control, while achieving a more fluent/real-time execution. A video showing real-robot executions can be found at https://youtu.be/rPOPCwHfV4g.
Real-time QoS Routing Scheme in SDN-based Robotic Cyber-Physical Systems
Apr 09, 2020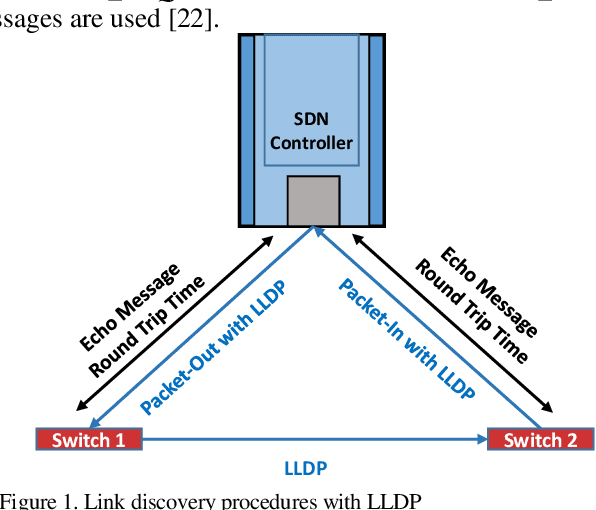
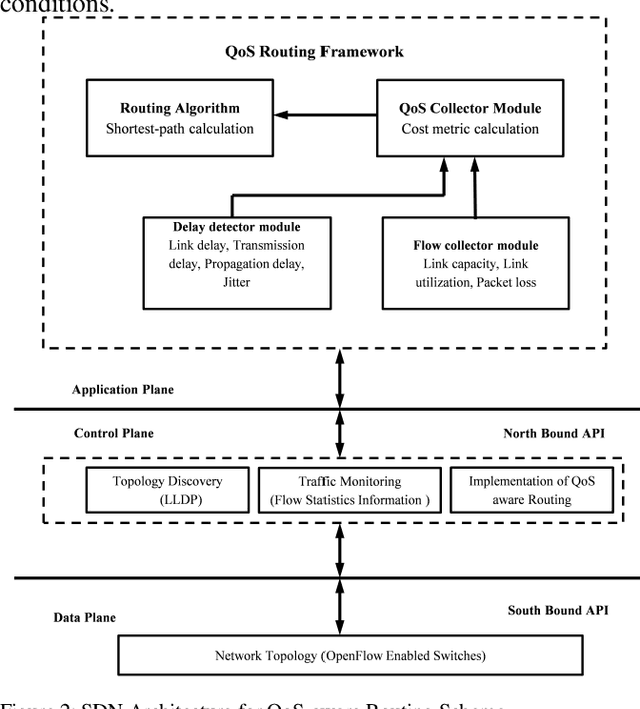
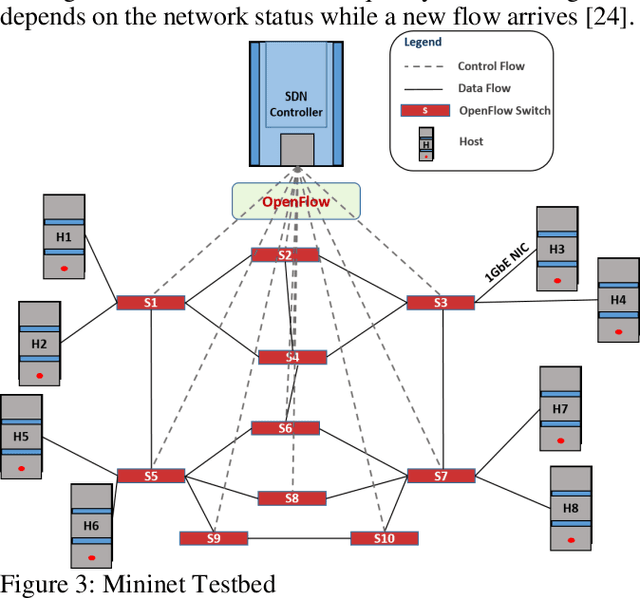
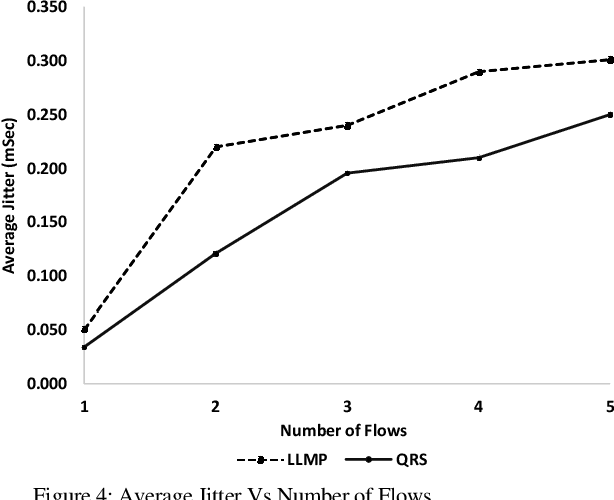
Industrial cyber-physical systems (CPS) have gained enormous attention of manufacturers in recent years due to their automation and cost reduction capabilities in the fourth industrial revolution (Industry 4.0). Such an industrial network of connected cyber and physical components may consist of highly expensive components such as robots. In order to provide efficient communication in such a network, it is imperative to improve the Quality-of-Service (QoS). Software Defined Networking (SDN) has become a key technology in realizing QoS concepts in a dynamic fashion by allowing a centralized controller to program each flow with a unified interface. However, state-of-the-art solutions do not effectively use the centralized visibility of SDN to fulfill QoS requirements of such industrial networks. In this paper, we propose an SDN-based routing mechanism which attempts to improve QoS in robotic cyber-physical systems which have hard real-time requirements. We exploit the SDN capabilities to dynamically select paths based on current link parameters in order to improve the QoS in such delay-constrained networks. We verify the efficiency of the proposed approach on a realistic industrial OpenFlow topology. Our experiments reveal that the proposed approach significantly outperforms an existing delay-based routing mechanism in terms of average throughput, end-to-end delay and jitter. The proposed solution would prove to be significant for the industrial applications in robotic cyber-physical systems.
Temporal Information Extraction by Predicting Relative Time-lines
Aug 28, 2018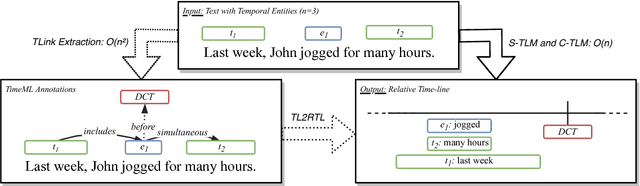
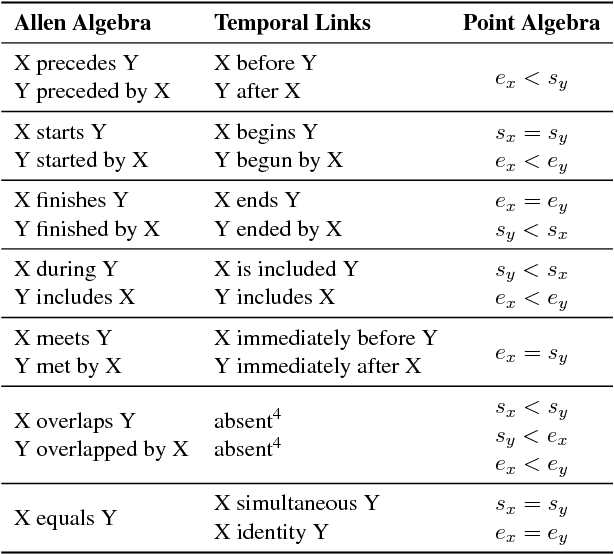
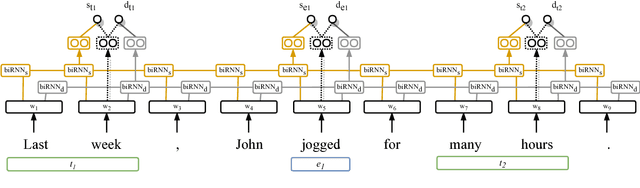

The current leading paradigm for temporal information extraction from text consists of three phases: (1) recognition of events and temporal expressions, (2) recognition of temporal relations among them, and (3) time-line construction from the temporal relations. In contrast to the first two phases, the last phase, time-line construction, received little attention and is the focus of this work. In this paper, we propose a new method to construct a linear time-line from a set of (extracted) temporal relations. But more importantly, we propose a novel paradigm in which we directly predict start and end-points for events from the text, constituting a time-line without going through the intermediate step of prediction of temporal relations as in earlier work. Within this paradigm, we propose two models that predict in linear complexity, and a new training loss using TimeML-style annotations, yielding promising results.
Accelerating Recurrent Neural Networks for Gravitational Wave Experiments
Jun 26, 2021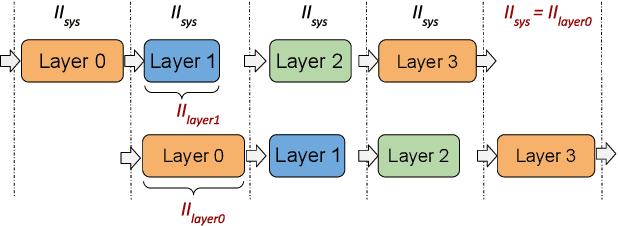
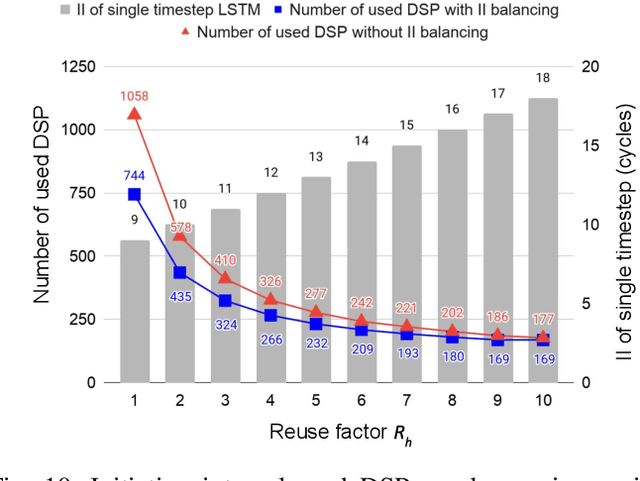
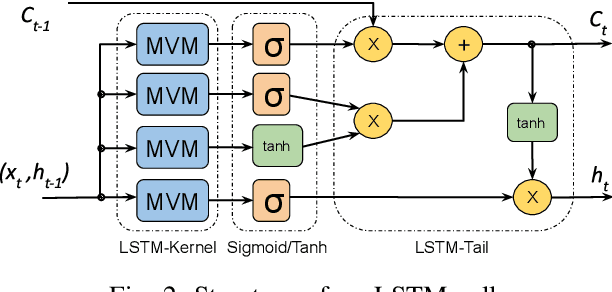
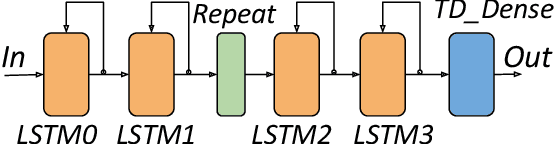
This paper presents novel reconfigurable architectures for reducing the latency of recurrent neural networks (RNNs) that are used for detecting gravitational waves. Gravitational interferometers such as the LIGO detectors capture cosmic events such as black hole mergers which happen at unknown times and of varying durations, producing time-series data. We have developed a new architecture capable of accelerating RNN inference for analyzing time-series data from LIGO detectors. This architecture is based on optimizing the initiation intervals (II) in a multi-layer LSTM (Long Short-Term Memory) network, by identifying appropriate reuse factors for each layer. A customizable template for this architecture has been designed, which enables the generation of low-latency FPGA designs with efficient resource utilization using high-level synthesis tools. The proposed approach has been evaluated based on two LSTM models, targeting a ZYNQ 7045 FPGA and a U250 FPGA. Experimental results show that with balanced II, the number of DSPs can be reduced up to 42% while achieving the same IIs. When compared to other FPGA-based LSTM designs, our design can achieve about 4.92 to 12.4 times lower latency.
Criticality and Utility-aware Fog Computing System for Remote Health Monitoring
May 24, 2021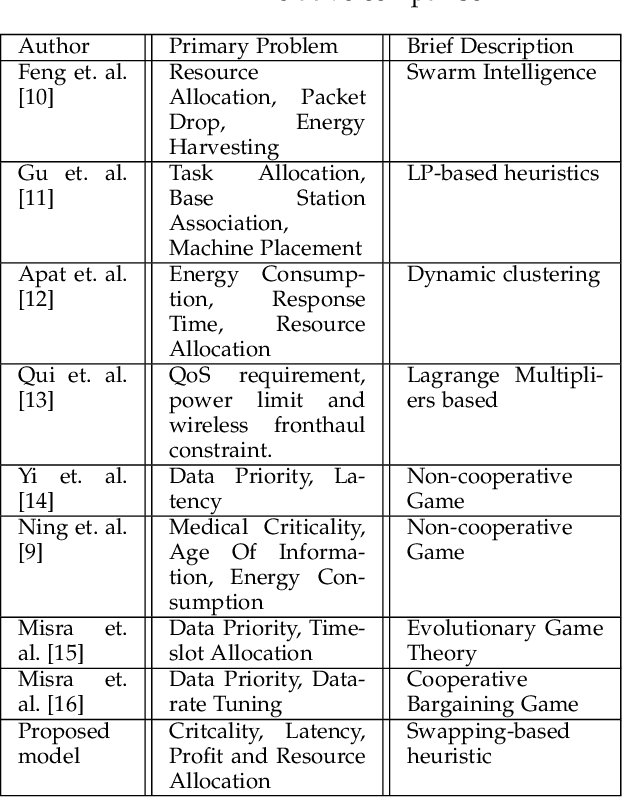
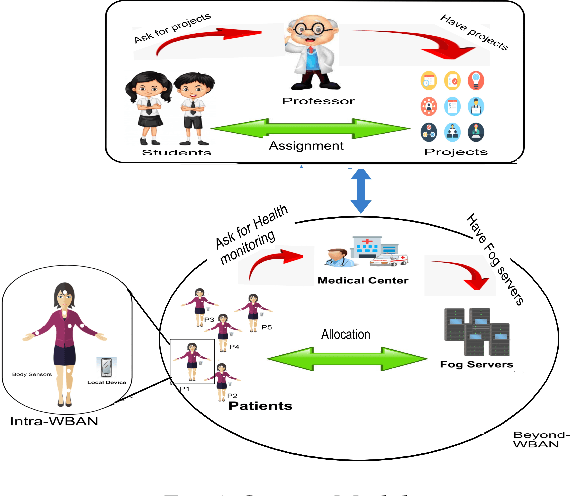

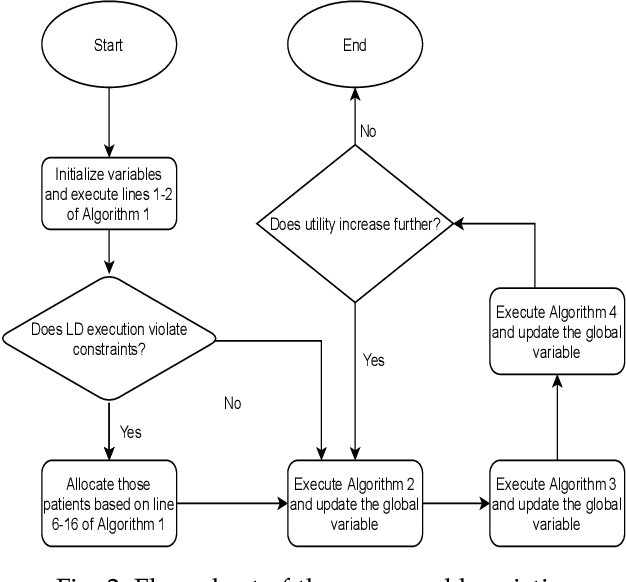
Growing remote health monitoring system allows constant monitoring of the patient's condition and performance of preventive and control check-ups outside medical facilities. However, the real-time smart-healthcare application poses a delay constraint that has to be solved efficiently. Fog computing is emerging as an efficient solution for such real-time applications. Moreover, different medical centers are getting attracted to the growing IoT-based remote healthcare system in order to make a profit by hiring Fog computing resources. However, there is a need for an efficient algorithmic model for allocation of limited fog computing resources in the criticality-aware smart-healthcare system considering the profit of medical centers. Thus, the objective of this work is to maximize the system utility calculated as a linear combination of the profit of the medical center and the loss of patients. To measure profit, we propose a flat-pricing-based model. Further, we propose a swapping-based heuristic to maximize the system utility. The proposed heuristic is tested on various parameters and shown to perform close to the optimal with criticality-awareness in its core. Through extensive simulations, we show that the proposed heuristic achieves an average utility of $96\%$ of the optimal, in polynomial time complexity.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Aug 27, 2021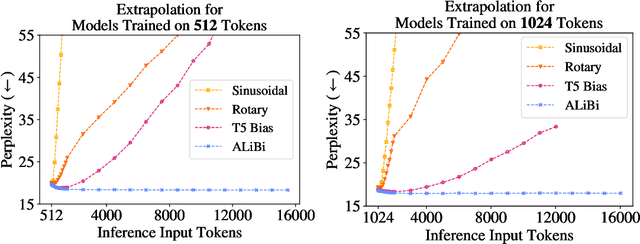
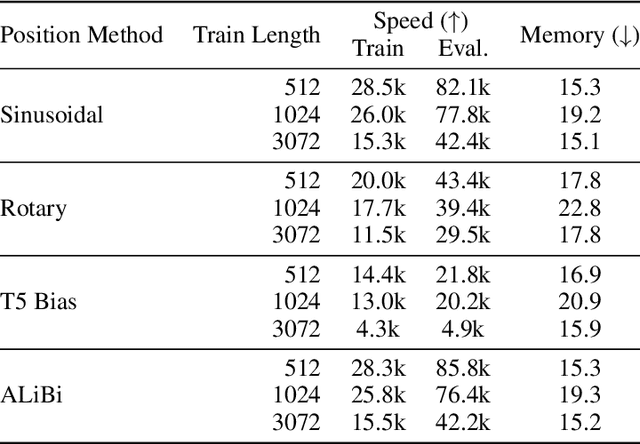

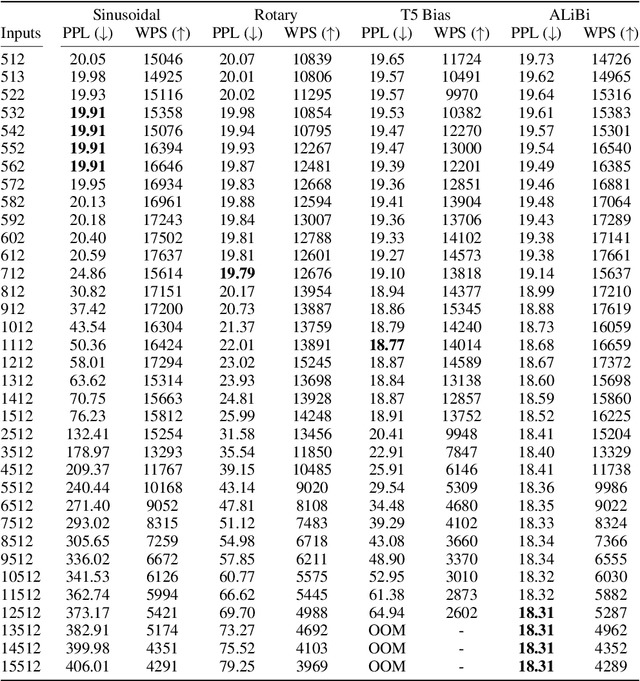
Since the introduction of the transformer model by Vaswani et al. (2017), a fundamental question remains open: how to achieve extrapolation at inference time to longer sequences than seen during training? We first show that extrapolation can be improved by changing the position representation method, though we find that existing proposals do not allow efficient extrapolation. We introduce a simple and efficient method, Attention with Linear Biases (ALiBi), that allows for extrapolation. ALiBi does not add positional embeddings to the word embeddings; instead, it biases the query-key attention scores with a term that is proportional to their distance. We show that this method allows training a 1.3 billion parameter model on input sequences of length 1024 that extrapolates to input sequences of length 2048, achieving the same perplexity as a sinusoidal position embedding model trained on inputs of length 2048, 11% faster and using 11% less memory. ALiBi's inductive bias towards recency allows it to outperform multiple strong position methods on the WikiText-103 benchmark. Finally, we provide analysis of ALiBi to understand why it leads to better performance.
Stationary Density Estimation of Itô Diffusions Using Deep Learning
Sep 09, 2021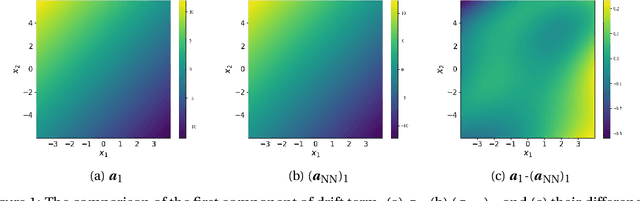
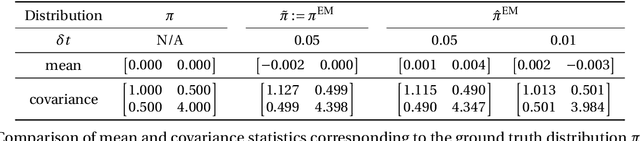
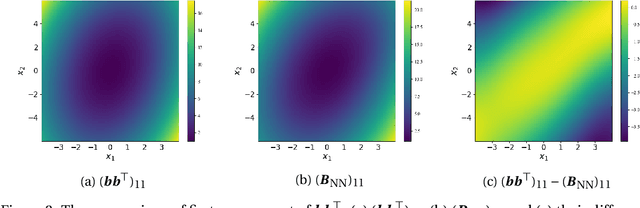
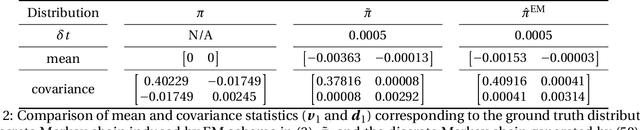
In this paper, we consider the density estimation problem associated with the stationary measure of ergodic It\^o diffusions from a discrete-time series that approximate the solutions of the stochastic differential equations. To take an advantage of the characterization of density function through the stationary solution of a parabolic-type Fokker-Planck PDE, we proceed as follows. First, we employ deep neural networks to approximate the drift and diffusion terms of the SDE by solving appropriate supervised learning tasks. Subsequently, we solve a steady-state Fokker-Plank equation associated with the estimated drift and diffusion coefficients with a neural-network-based least-squares method. We establish the convergence of the proposed scheme under appropriate mathematical assumptions, accounting for the generalization errors induced by regressing the drift and diffusion coefficients, and the PDE solvers. This theoretical study relies on a recent perturbation theory of Markov chain result that shows a linear dependence of the density estimation to the error in estimating the drift term, and generalization error results of nonparametric regression and of PDE regression solution obtained with neural-network models. The effectiveness of this method is reflected by numerical simulations of a two-dimensional Student's t distribution and a 20-dimensional Langevin dynamics.