 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DISCO : efficient unsupervised decoding for discrete natural language problems via convex relaxation
Jul 13, 2021

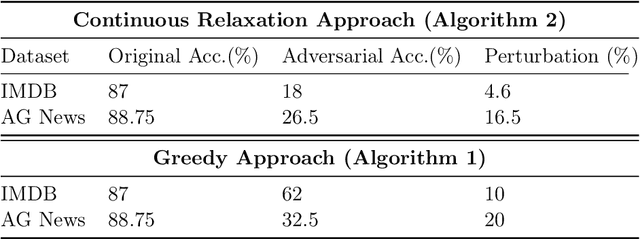
In this paper we study test time decoding; an ubiquitous step in almost all sequential text generation task spanning across a wide array of natural language processing (NLP) problems. Our main contribution is to develop a continuous relaxation framework for the combinatorial NP-hard decoding problem and propose Disco - an efficient algorithm based on standard first order gradient based. We provide tight analysis and show that our proposed algorithm linearly converges to within $\epsilon$ neighborhood of the optima. Finally, we perform preliminary experiments on the task of adversarial text generation and show superior performance of Disco over several popular decoding approaches.
Neural Fixed-Point Acceleration for Convex Optimization
Jul 23, 2021

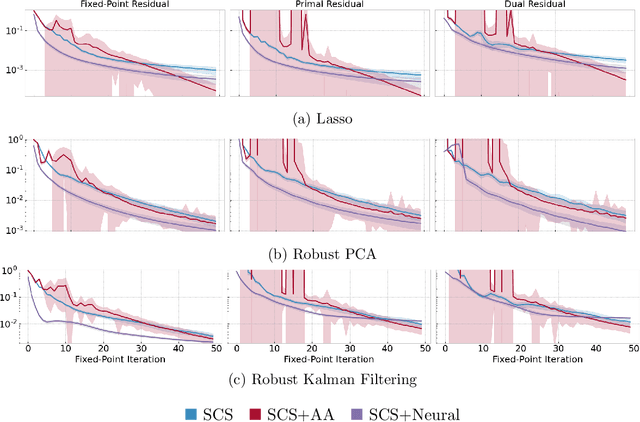

Fixed-point iterations are at the heart of numerical computing and are often a computational bottleneck in real-time applications that typically need a fast solution of moderate accuracy. We present neural fixed-point acceleration which combines ideas from meta-learning and classical acceleration methods to automatically learn to accelerate fixed-point problems that are drawn from a distribution. We apply our framework to SCS, the state-of-the-art solver for convex cone programming, and design models and loss functions to overcome the challenges of learning over unrolled optimization and acceleration instabilities. Our work brings neural acceleration into any optimization problem expressible with CVXPY. The source code behind this paper is available at https://github.com/facebookresearch/neural-scs
NetAdaptV2: Efficient Neural Architecture Search with Fast Super-Network Training and Architecture Optimization
Mar 31, 2021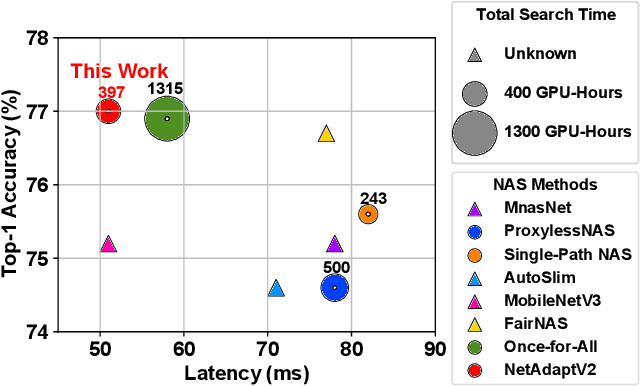
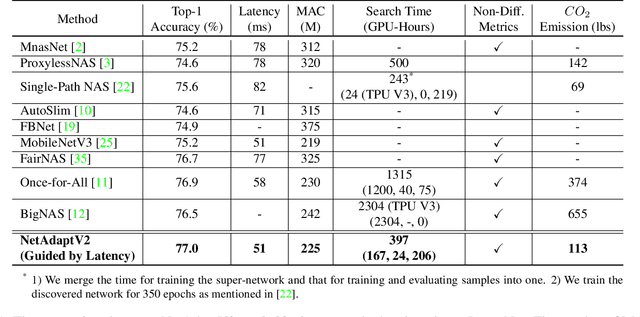

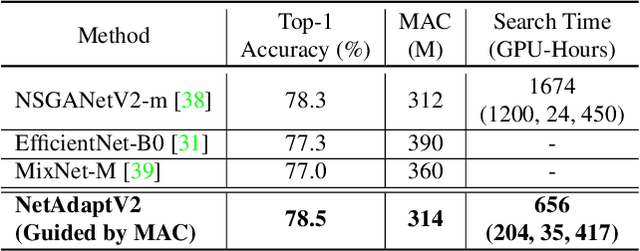
Neural architecture search (NAS) typically consists of three main steps: training a super-network, training and evaluating sampled deep neural networks (DNNs), and training the discovered DNN. Most of the existing efforts speed up some steps at the cost of a significant slowdown of other steps or sacrificing the support of non-differentiable search metrics. The unbalanced reduction in the time spent per step limits the total search time reduction, and the inability to support non-differentiable search metrics limits the performance of discovered DNNs. In this paper, we present NetAdaptV2 with three innovations to better balance the time spent for each step while supporting non-differentiable search metrics. First, we propose channel-level bypass connections that merge network depth and layer width into a single search dimension to reduce the time for training and evaluating sampled DNNs. Second, ordered dropout is proposed to train multiple DNNs in a single forward-backward pass to decrease the time for training a super-network. Third, we propose the multi-layer coordinate descent optimizer that considers the interplay of multiple layers in each iteration of optimization to improve the performance of discovered DNNs while supporting non-differentiable search metrics. With these innovations, NetAdaptV2 reduces the total search time by up to $5.8\times$ on ImageNet and $2.4\times$ on NYU Depth V2, respectively, and discovers DNNs with better accuracy-latency/accuracy-MAC trade-offs than state-of-the-art NAS works. Moreover, the discovered DNN outperforms NAS-discovered MobileNetV3 by 1.8% higher top-1 accuracy with the same latency. The project website is http://netadapt.mit.edu.
Learning to Prompt for Vision-Language Models
Sep 21, 2021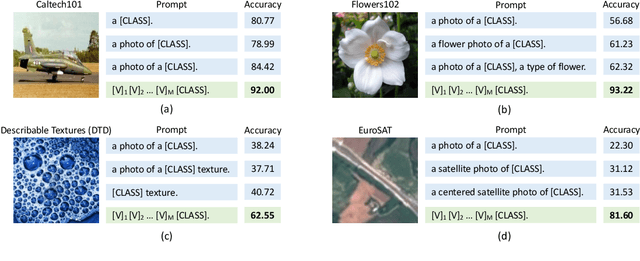
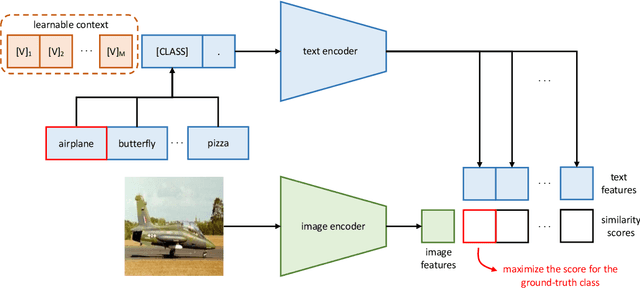
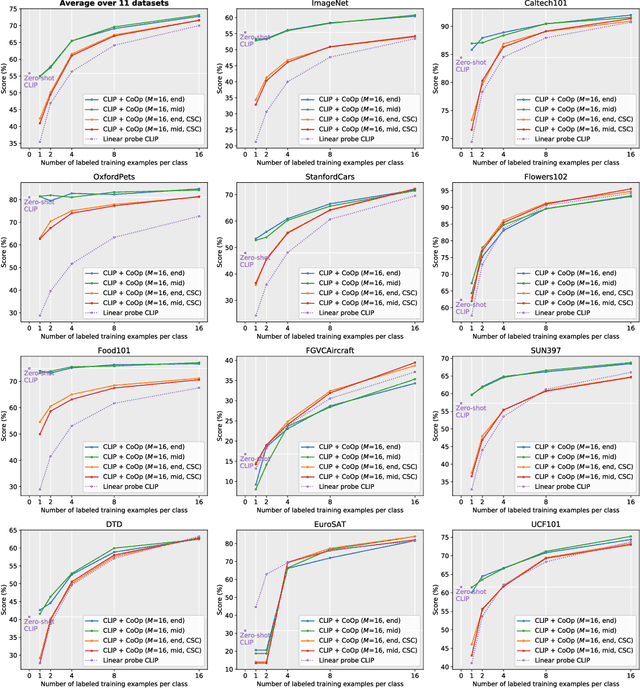
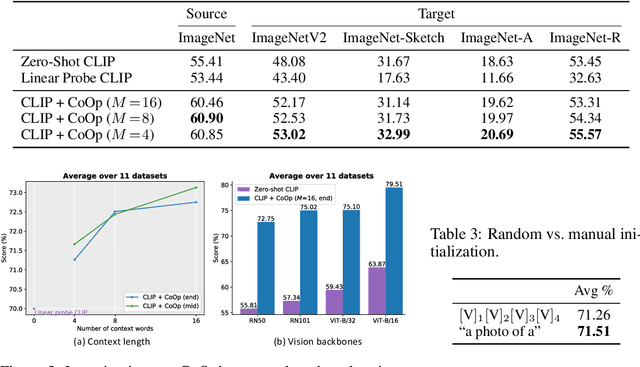
Vision-language pre-training has recently emerged as a promising alternative for representation learning. It shifts from the tradition of using images and discrete labels for learning a fixed set of weights, seen as visual concepts, to aligning images and raw text for two separate encoders. Such a paradigm benefits from a broader source of supervision and allows zero-shot transfer to downstream tasks since visual concepts can be diametrically generated from natural language, known as prompt. In this paper, we identify that a major challenge of deploying such models in practice is prompt engineering. This is because designing a proper prompt, especially for context words surrounding a class name, requires domain expertise and typically takes a significant amount of time for words tuning since a slight change in wording could have a huge impact on performance. Moreover, different downstream tasks require specific designs, further hampering the efficiency of deployment. To overcome this challenge, we propose a novel approach named context optimization (CoOp). The main idea is to model context in prompts using continuous representations and perform end-to-end learning from data while keeping the pre-trained parameters fixed. In this way, the design of task-relevant prompts can be fully automated. Experiments on 11 datasets show that CoOp effectively turns pre-trained vision-language models into data-efficient visual learners, requiring as few as one or two shots to beat hand-crafted prompts with a decent margin and able to gain significant improvements when using more shots (e.g., at 16 shots the average gain is around 17% with the highest reaching over 50%). CoOp also exhibits strong robustness to distribution shift.
Deep Reinforcement Learning for Dynamic Band Switch in Cellular-Connected UAV
Aug 26, 2021The choice of the transmitting frequency to provide cellular-connected Unmanned Aerial Vehicle (UAV) reliable connectivity and mobility support introduce several challenges. Conventional sub-6 GHz networks are optimized for ground Users (UEs). Operating at the millimeter Wave (mmWave) band would provide high-capacity but highly intermittent links. To reach the destination while minimizing a weighted function of traveling time and number of radio failures, we propose in this paper a UAV joint trajectory and band switch approach. By leveraging Double Deep Q-Learning we develop two different approaches to learn a trajectory besides managing the band switch. A first blind approach switches the band along the trajectory anytime the UAV-UE throughput is below a predefined threshold. In addition, we propose a smart approach for simultaneous learning-based path planning of UAV and band switch. The two approaches are compared with an optimal band switch strategy in terms of radio failure and band switches for different thresholds. Results reveal that the smart approach is able in a high threshold regime to reduce the number of radio failures and band switches while reaching the desired destination.
Point-of-Interest Type Prediction using Text and Images
Sep 01, 2021
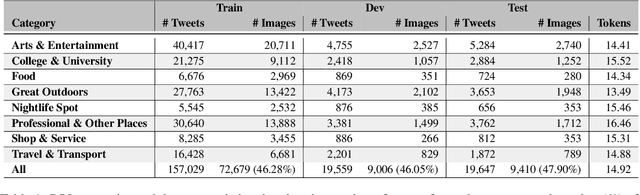
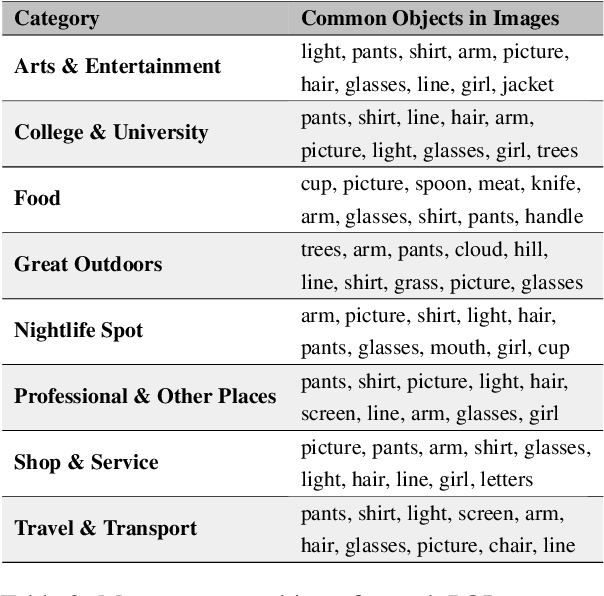
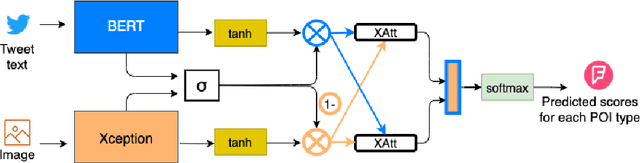
Point-of-interest (POI) type prediction is the task of inferring the type of a place from where a social media post was shared. Inferring a POI's type is useful for studies in computational social science including sociolinguistics, geosemiotics, and cultural geography, and has applications in geosocial networking technologies such as recommendation and visualization systems. Prior efforts in POI type prediction focus solely on text, without taking visual information into account. However in reality, the variety of modalities, as well as their semiotic relationships with one another, shape communication and interactions in social media. This paper presents a study on POI type prediction using multimodal information from text and images available at posting time. For that purpose, we enrich a currently available data set for POI type prediction with the images that accompany the text messages. Our proposed method extracts relevant information from each modality to effectively capture interactions between text and image achieving a macro F1 of 47.21 across eight categories significantly outperforming the state-of-the-art method for POI type prediction based on text-only methods. Finally, we provide a detailed analysis to shed light on cross-modal interactions and the limitations of our best performing model.
Path Planning With Naive-Valley-Path Obstacle Avoidance and Global Map-Free
Aug 20, 2021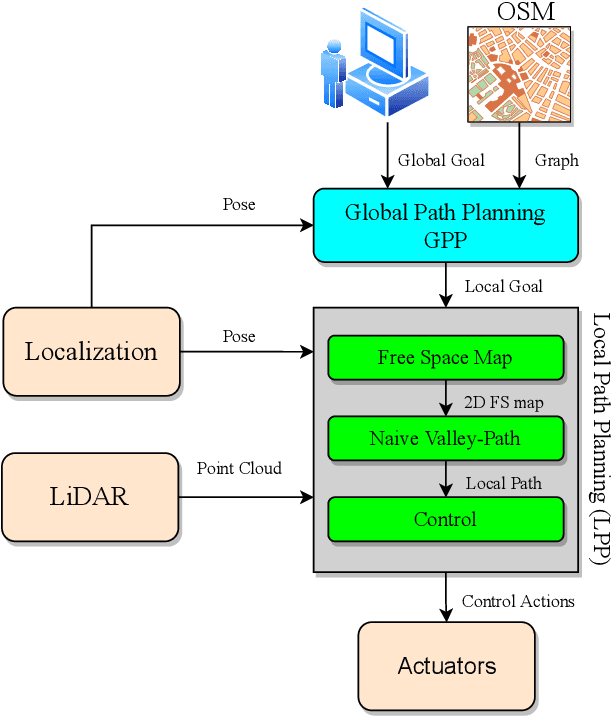
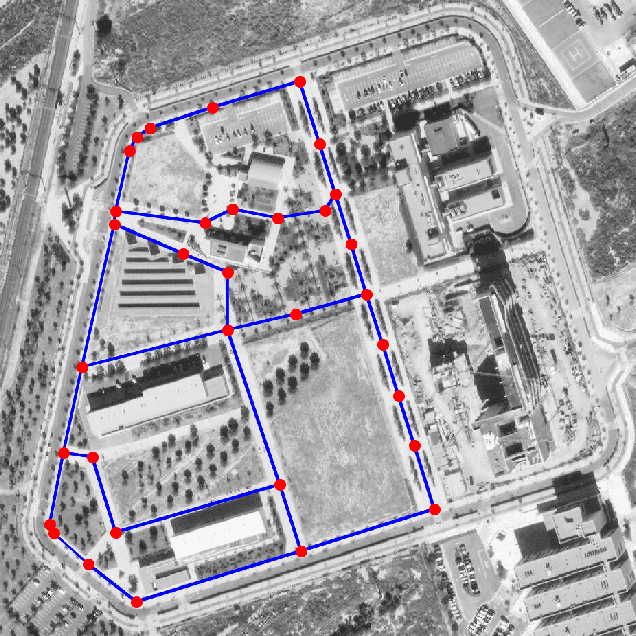
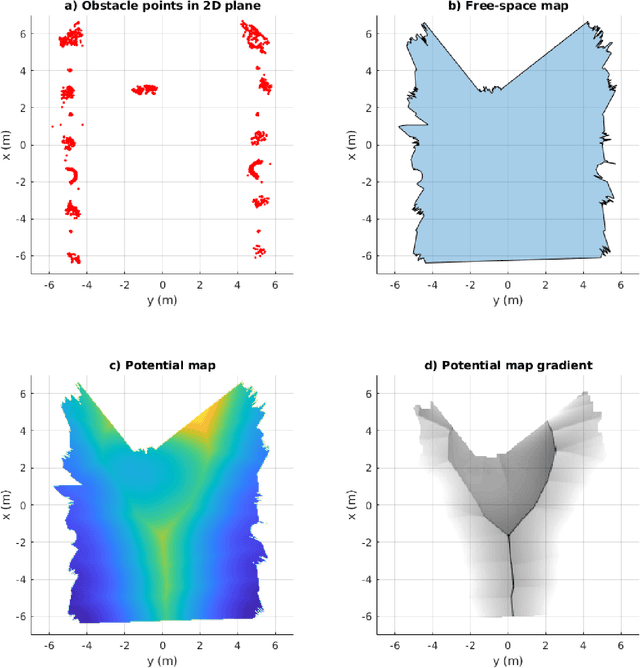
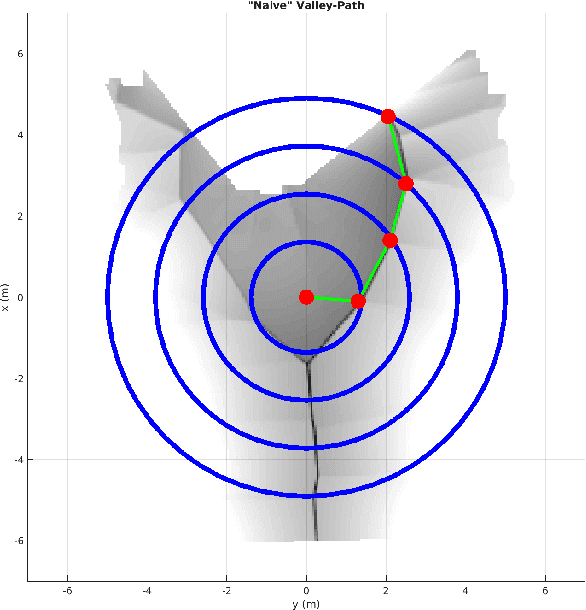
In this paper, we present a complete Path Planning approach divided into two main categories: Global Path Planning (GPP) and Local Path Planning (LPP). Unlike most other works, the GPP layer, instead of complex and heavy maps, uses road and intersections graphs obtained directly from internet applications like OpenStreetMaps (OSM). This map-free GPP frees us from the common area-size restrictions. In the LPP layer, we use a novel Naive-Valley-Path method (NVP) to generate a local path avoiding obstacles in the road in an extremely-low execution time period. This approach exploits the concept of valley areas around local minima, i.e., the ones always away from obstacles. We demonstrate the robustness of the system in our research platform BLUE, driving autonomously across the University of Alicante Scientific Park for more than 20 km in a 12.33 ha area. Our vehicle avoids different static persistent and non-persistent obstacles in the road and even dynamic ones, such as vehicles and pedestrians. Code is available at https://github.com/AUROVA-LAB/lib_planning.
Streaming data preprocessing via online tensor recovery for large environmental sensor networks
Sep 01, 2021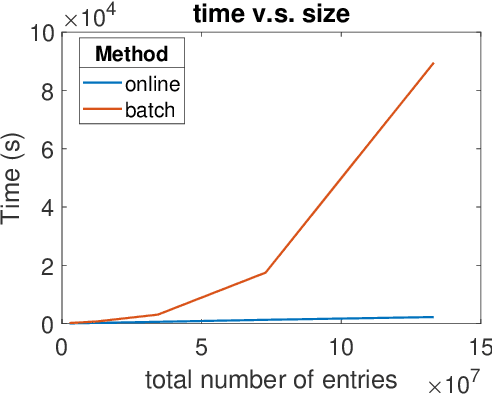
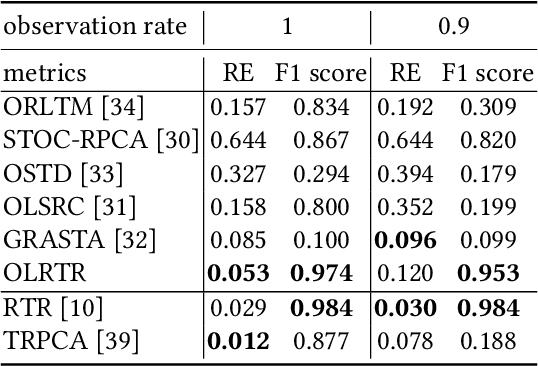
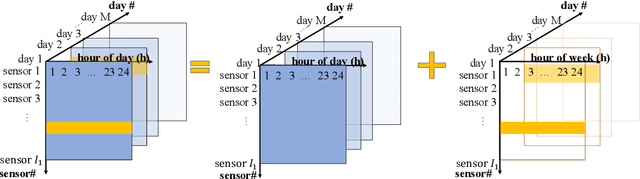
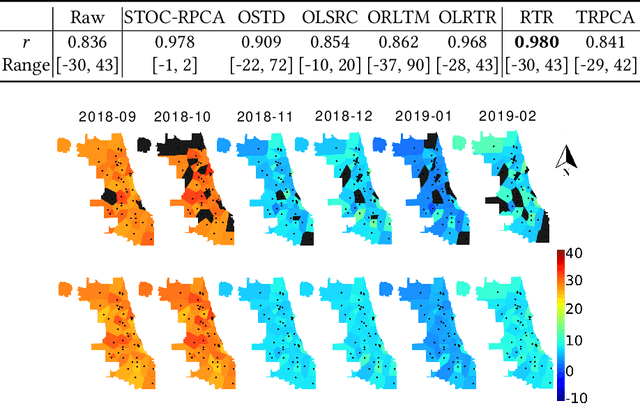
Measuring the built and natural environment at a fine-grained scale is now possible with low-cost urban environmental sensor networks. However, fine-grained city-scale data analysis is complicated by tedious data cleaning including removing outliers and imputing missing data. While many methods exist to automatically correct anomalies and impute missing entries, challenges still exist on data with large spatial-temporal scales and shifting patterns. To address these challenges, we propose an online robust tensor recovery (OLRTR) method to preprocess streaming high-dimensional urban environmental datasets. A small-sized dictionary that captures the underlying patterns of the data is computed and constantly updated with new data. OLRTR enables online recovery for large-scale sensor networks that provide continuous data streams, with a lower computational memory usage compared to offline batch counterparts. In addition, we formulate the objective function so that OLRTR can detect structured outliers, such as faulty readings over a long period of time. We validate OLRTR on a synthetically degraded National Oceanic and Atmospheric Administration temperature dataset, with a recovery error of 0.05, and apply it to the Array of Things city-scale sensor network in Chicago, IL, showing superior results compared with several established online and batch-based low rank decomposition methods.
Continuous-Time Mean-Variance Portfolio Selection: A Reinforcement Learning Framework
May 05, 2019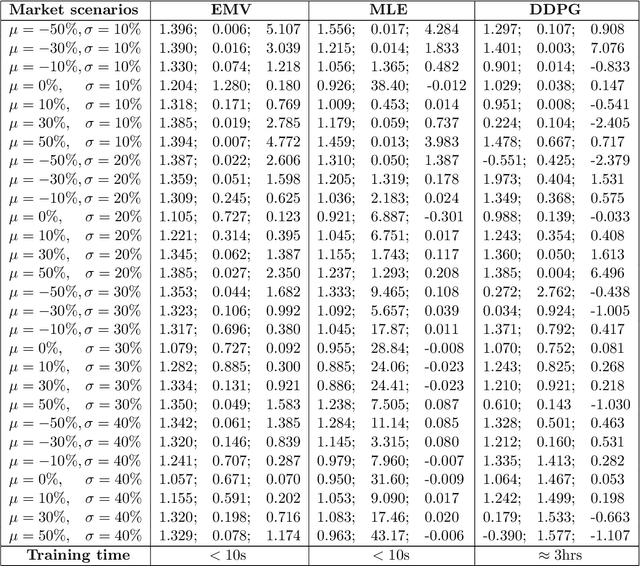
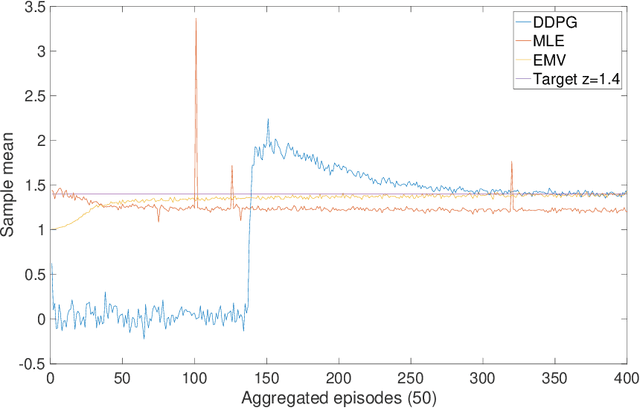
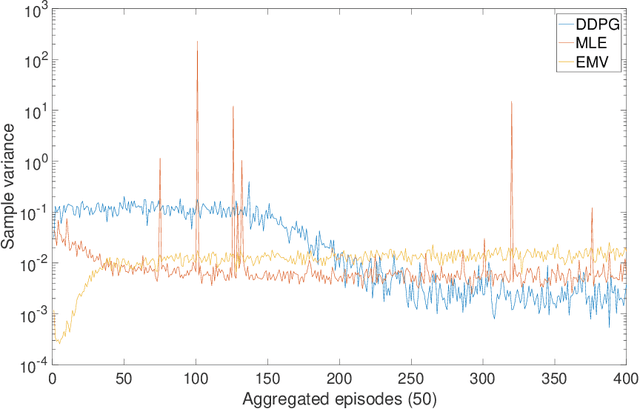
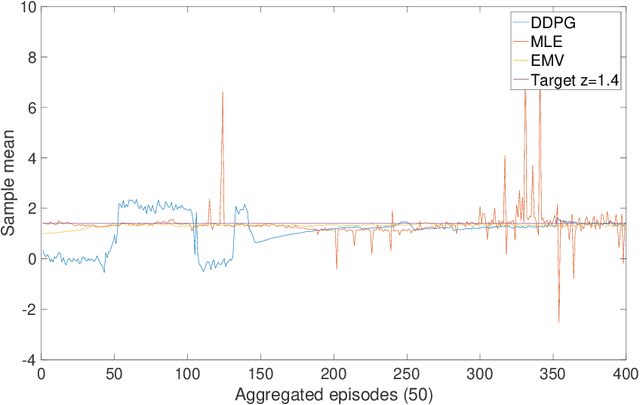
We approach the continuous-time mean-variance (MV) portfolio selection with reinforcement learning (RL). The problem is to achieve the best tradeoff between exploration and exploitation, and is formulated as an entropy-regularized, relaxed stochastic control problem. We prove that the optimal feedback policy for this problem must be Gaussian, with time-decaying variance. We then establish connections between the entropy-regularized MV and the classical MV, including the solvability equivalence and the convergence as exploration weighting parameter decays to zero. Finally, we prove a policy improvement theorem, based on which we devise an implementable RL algorithm. We find that our algorithm outperforms both an adaptive control based method and a deep neural networks based algorithm by a large margin in our simulations.
A Dataset and Method for Hallux Valgus Angle Estimation Based on Deep Learing
Jul 08, 2021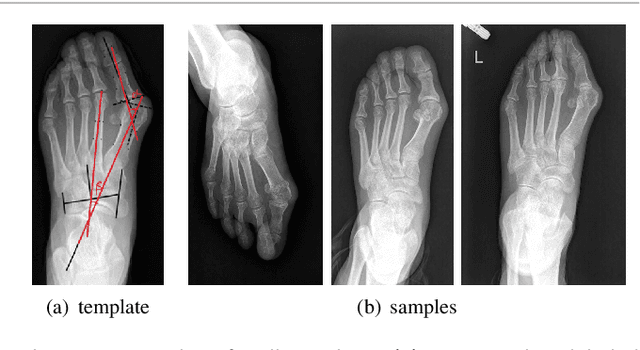

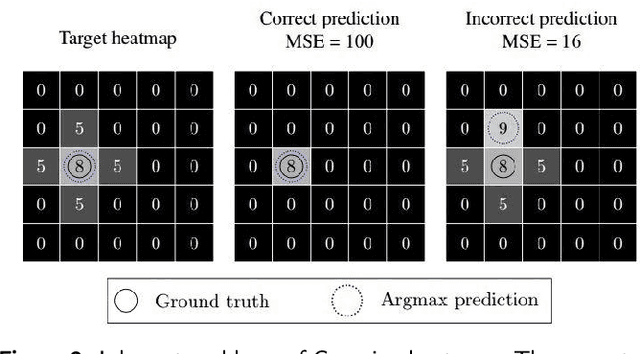
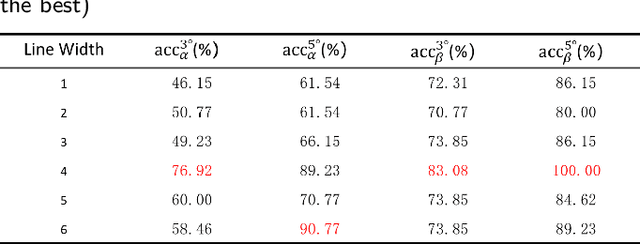
Angular measurements is essential to make a resonable treatment for Hallux valgus (HV), a common forefoot deformity. However, it still depends on manual labeling and measurement, which is time-consuming and sometimes unreliable. Automating this process is a thing of concern. However, it lack of dataset and the keypoints based method which made a great success in pose estimation is not suitable for this field.To solve the problems, we made a dataset and developed an algorithm based on deep learning and linear regression. It shows great fitting ability to the ground truth.