 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Testing Directed Acyclic Graph via Structural, Supervised and Generative Adversarial Learning
Jun 02, 2021
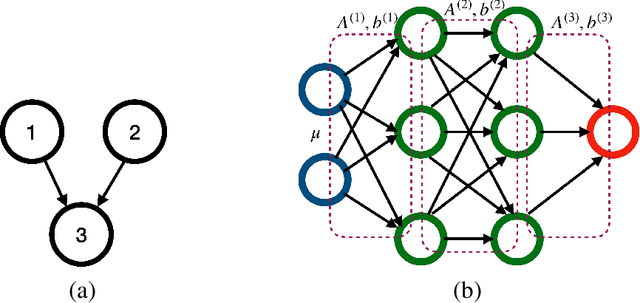
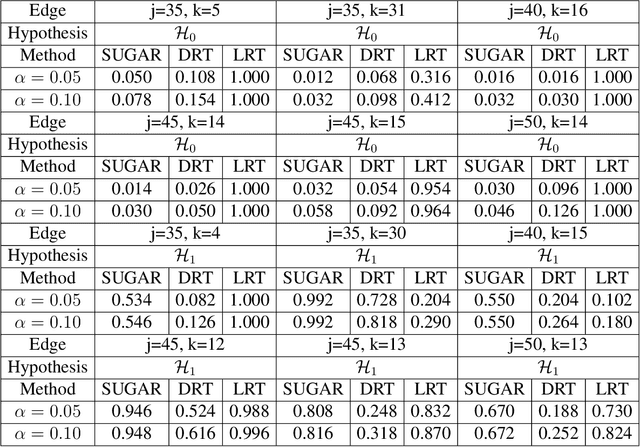
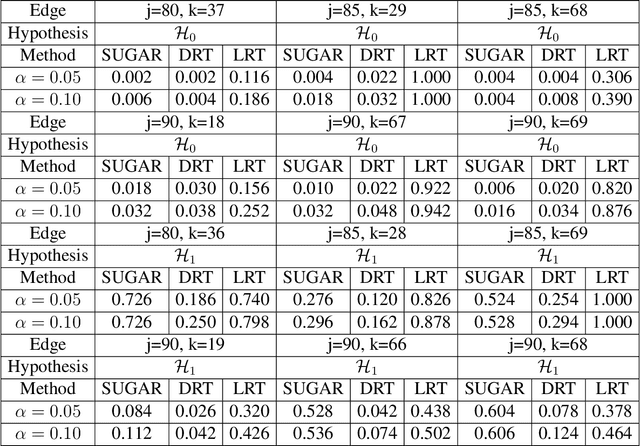
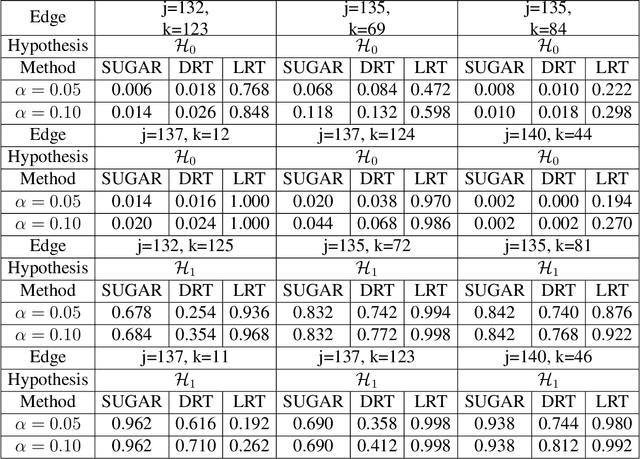
In this article, we propose a new hypothesis testing method for directed acyclic graph (DAG). While there is a rich class of DAG estimation methods, there is a relative paucity of DAG inference solutions. Moreover, the existing methods often impose some specific model structures such as linear models or additive models, and assume independent data observations. Our proposed test instead allows the associations among the random variables to be nonlinear and the data to be time-dependent. We build the test based on some highly flexible neural networks learners. We establish the asymptotic guarantees of the test, while allowing either the number of subjects or the number of time points for each subject to diverge to infinity. We demonstrate the efficacy of the test through simulations and a brain connectivity network analysis.
NeuroPod: a real-time neuromorphic spiking CPG applied to robotics
Apr 25, 2019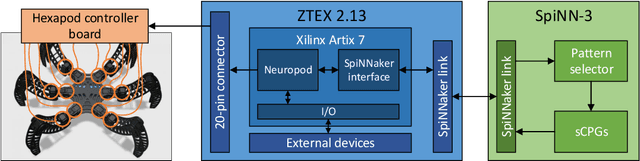

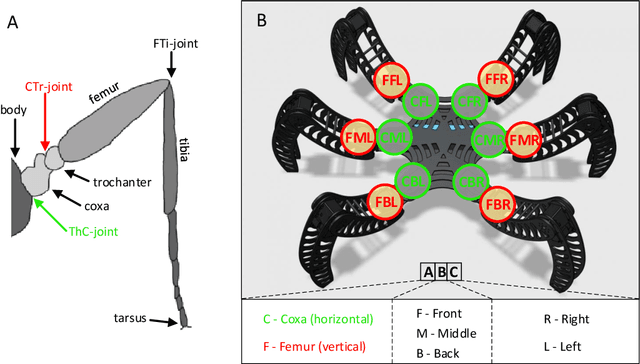
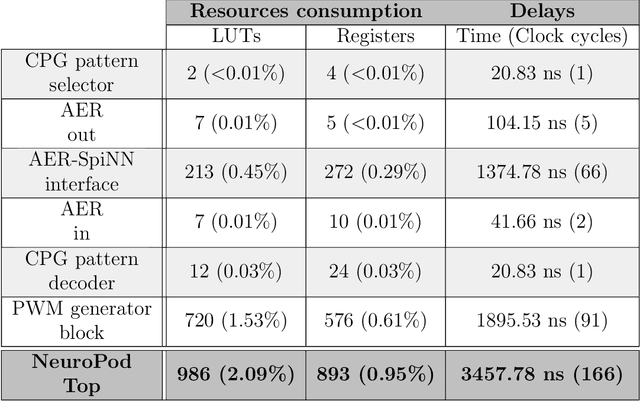
Initially, robots were developed with the aim of making our life easier, carrying out repetitive or dangerous tasks for humans. Although they were able to perform these tasks, the latest generation of robots are being designed to take a step further, by performing more complex tasks that have been carried out by smart animals or humans up to date. To this end, inspiration needs to be taken from biological examples. For instance, insects are able to optimally solve complex environment navigation problems, and many researchers have started to mimic how these insects behave. Recent interest in neuromorphic engineering has motivated us to present a real-time, neuromorphic, spike-based Central Pattern Generator of application in neurorobotics, using an arthropod-like robot. A Spiking Neural Network was designed and implemented on SpiNNaker. The network models a complex, online-change capable Central Pattern Generator which generates three gaits for a hexapod robot locomotion. Reconfigurable hardware was used to manage both the motors of the robot and the real-time communication interface with the Spiking Neural Networks. Real-time measurements confirm the simulation results, and locomotion tests show that NeuroPod can perform the gaits without any balance loss or added delay.
No more glowing in the dark: How deep learning improves exposure date estimation in thermoluminescence dosimetry
Jun 14, 2021
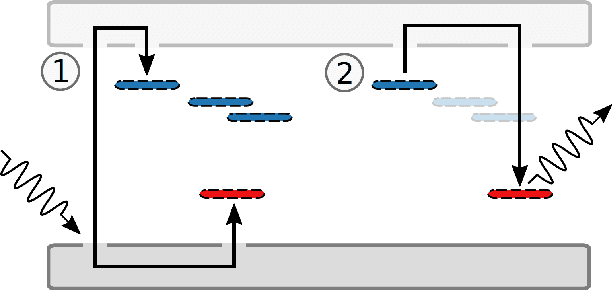
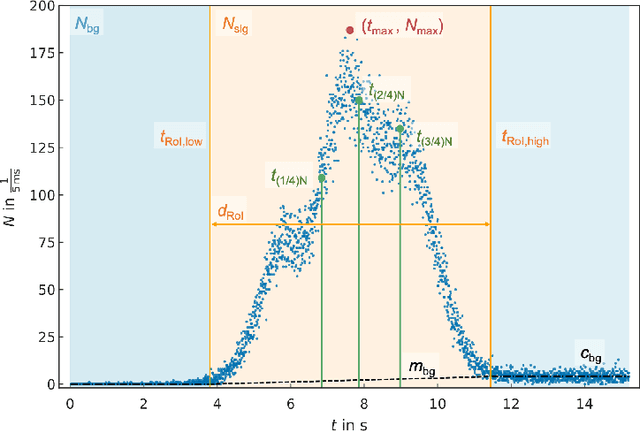
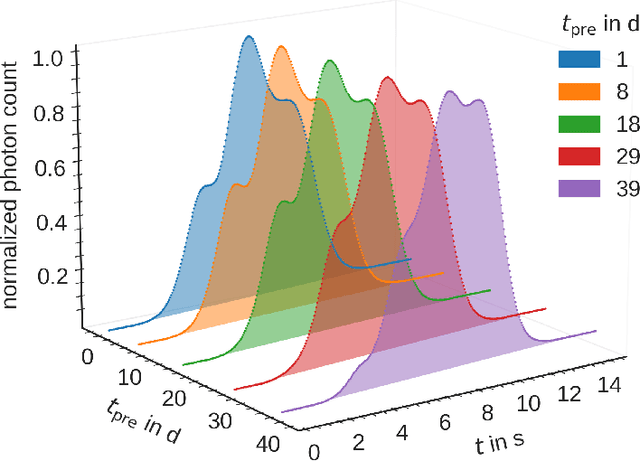
The time- or temperature-resolved detector signal from a thermoluminescence dosimeter can reveal additional information about circumstances of an exposure to ionizing irradiation. We present studies using deep neural networks to estimate the date of a single irradiation with 12 mSv within a monitoring interval of 42 days from glow curves of novel TL-DOS personal dosimeters developed by the Materialpr\"ufungsamt NRW in cooperation with TU Dortmund University. Using a deep convolutional network, the irradiation date can be predicted from raw time-resolved glow curve data with an uncertainty of roughly 1-2 days on a 68% confidence level without the need for a prior transformation into temperature space and a subsequent glow curve deconvolution. This corresponds to a significant improvement in prediction accuracy compared to a prior publication, which yielded a prediction uncertainty of 2-4 days using features obtained from a glow curve deconvolution as input to a neural network.
Towards Understanding Trends Manipulation in Pakistan Twitter
Sep 30, 2021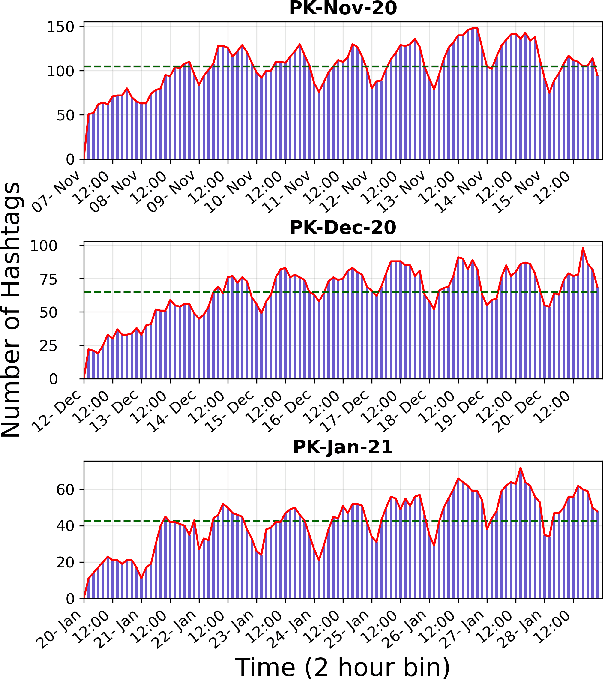
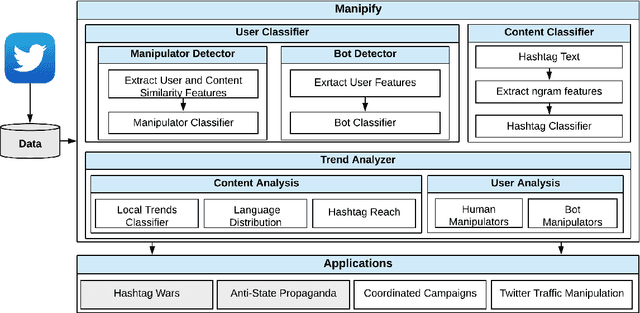
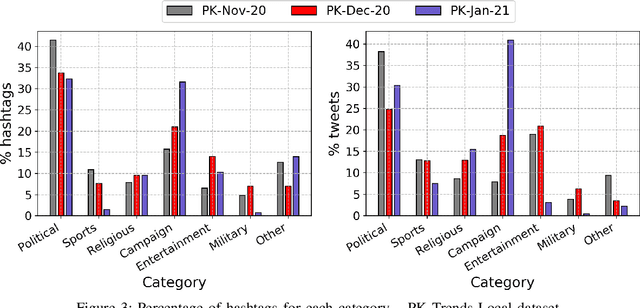
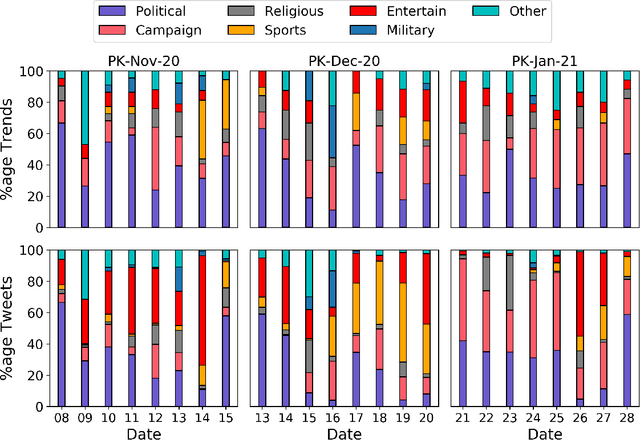
The rapid adoption of online social media platforms has transformed the way of communication and interaction. On these platforms, discussions in the form of trending topics provide a glimpse of events happening around the world in real-time. Also, these trends are used for political campaigns, public awareness, and brand promotions. Consequently, these trends are sensitive to manipulation by malicious users who aim to mislead the mass audience. In this article, we identify and study the characteristics of users involved in the manipulation of Twitter trends in Pakistan. We propose 'Manipify', a framework for automatic detection and analysis of malicious users for Twitter trends. Our framework consists of three distinct modules: i) user classifier, ii) hashtag classifier, and ii) trend analyzer. The user classifier introduces a novel approach to automatically detect manipulators using tweet content and user behaviour features. Also, the module classifies human and bot users. Next, the hashtag classifier categorizes trending hashtags into six categories assisting in examining manipulators behaviour across different categories. Finally, the trend analyzer module examines users, hashtags, and tweets for hashtag reach, linguistic features and user behaviour. Our user classifier module achieves 0.91 accuracy in classifying the manipulators. We further test Manipify on the dataset comprising of 665 trending hashtags with 5.4 million tweets and 1.9 million users. The analysis of trends reveals that the trending panel is mostly dominated by political hashtags. In addition, our results show a higher contribution of human accounts in trend manipulation as compared to bots. Furthermore, we present two case studies of hashtag-wars and anti-state propaganda to implicate the real-world application of our research.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021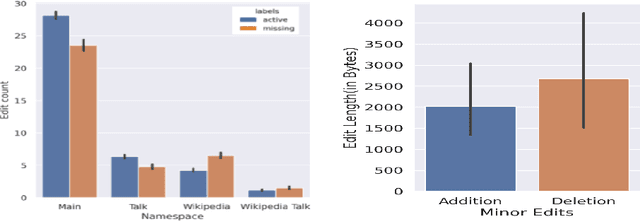

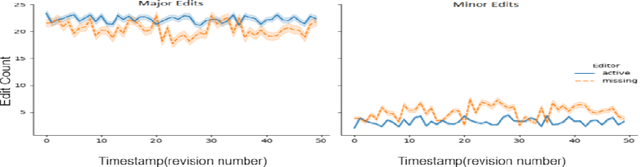

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
Multivariate Time Series Imputation with Variational Autoencoders
Jul 12, 2019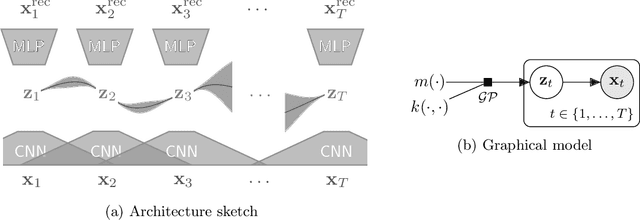

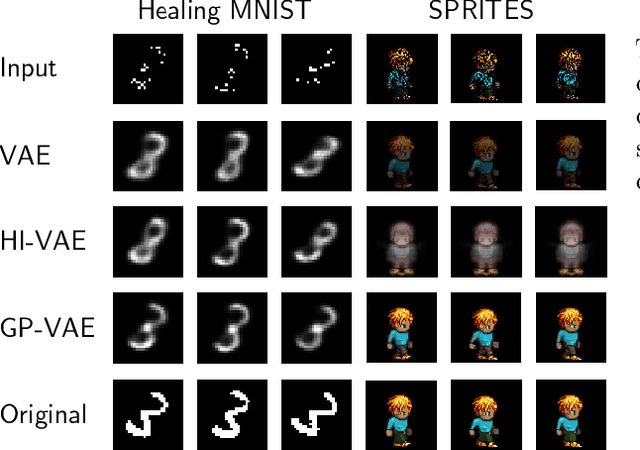
Multivariate time series with missing values are common in many areas, for instance in healthcare and finance. To face this problem, modern data imputation approaches should (a) be tailored to sequential data, (b) deal with high dimensional and complex data distributions, and (c) be based on the probabilistic modeling paradigm for interpretability and confidence assessment. However, many current approaches fall short in at least one of these aspects. Drawing on advances in deep learning and scalable probabilistic modeling, we propose a new deep sequential variational autoencoder approach for dimensionality reduction and data imputation. Temporal dependencies are modeled with a Gaussian process prior and a Cauchy kernel to reflect multi-scale dynamics in the latent space. We furthermore use a structured variational inference distribution that improves the scalability of the approach. We demonstrate that our model exhibits superior imputation performance on benchmark tasks and challenging real-world medical data.
Latency-Constrained Prediction of mmWave/THz Link Blockages through Meta-Learning
Jun 14, 2021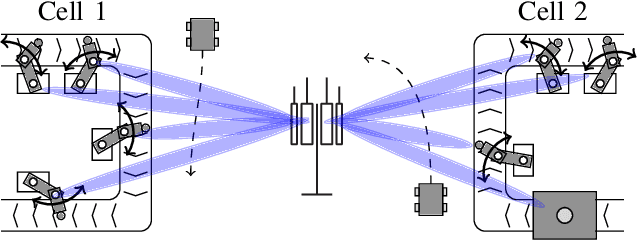
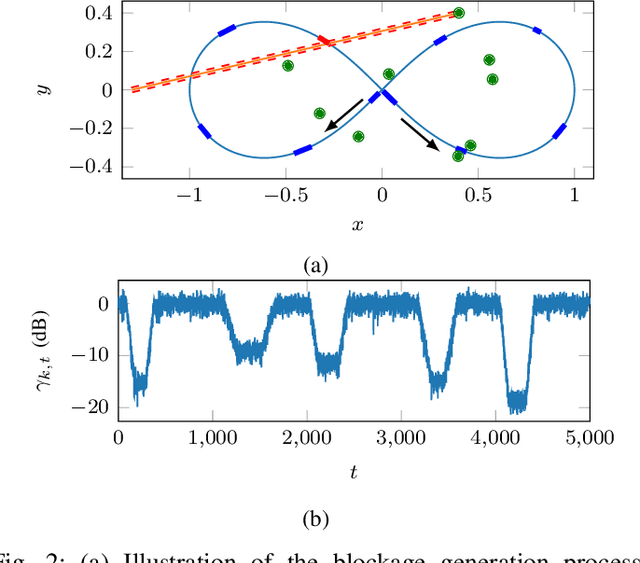
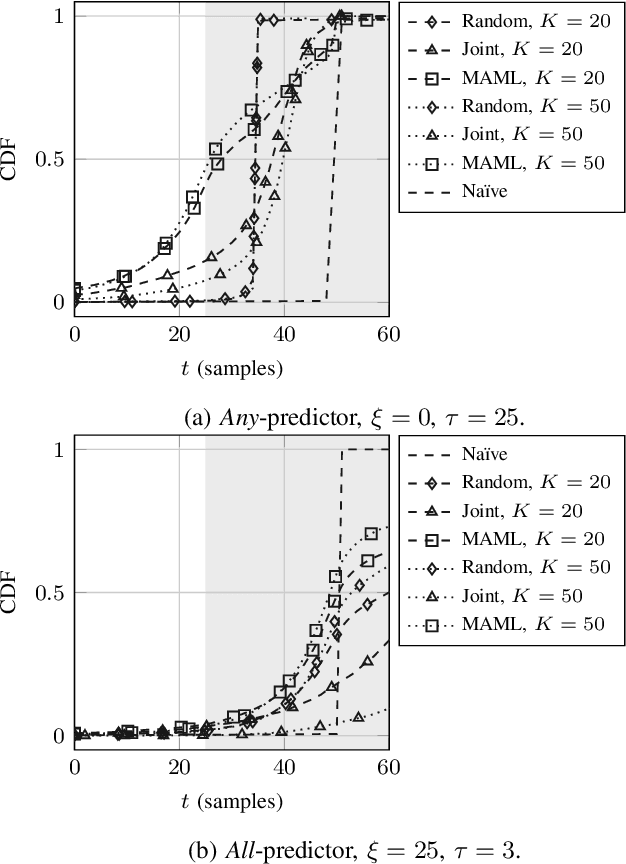
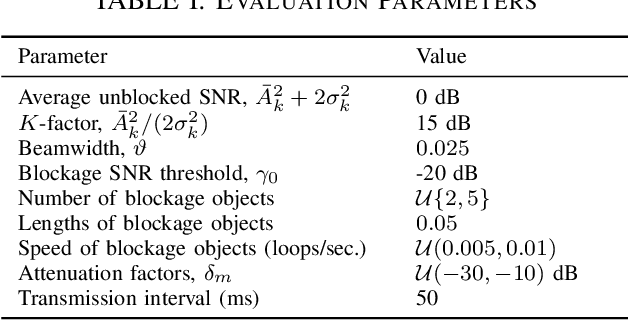
Wireless applications that use high-reliability low-latency links depend critically on the capability of the system to predict link quality. This dependence is especially acute at the high carrier frequencies used by mmWave and THz systems, where the links are susceptible to blockages. Predicting blockages with high reliability requires a large number of data samples to train effective machine learning modules. With the aim of mitigating data requirements, we introduce a framework based on meta-learning, whereby data from distinct deployments are leveraged to optimize a shared initialization that decreases the data set size necessary for any new deployment. Predictors of two different events are studied: (1) at least one blockage occurs in a time window, and (2) the link is blocked for the entire time window. The results show that an RNN-based predictor trained using meta-learning is able to predict blockages after observing fewer samples than predictors trained using standard methods.
A Power-Efficient Binary-Weight Spiking Neural Network Architecture for Real-Time Object Classification
Mar 12, 2020
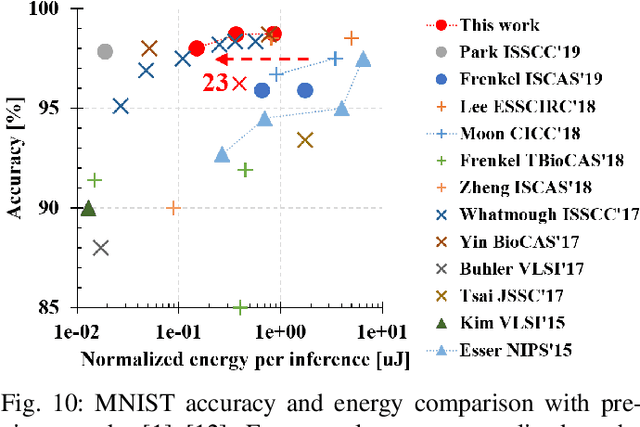
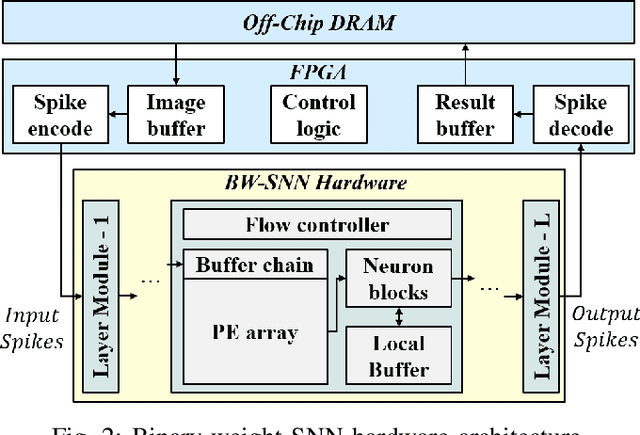
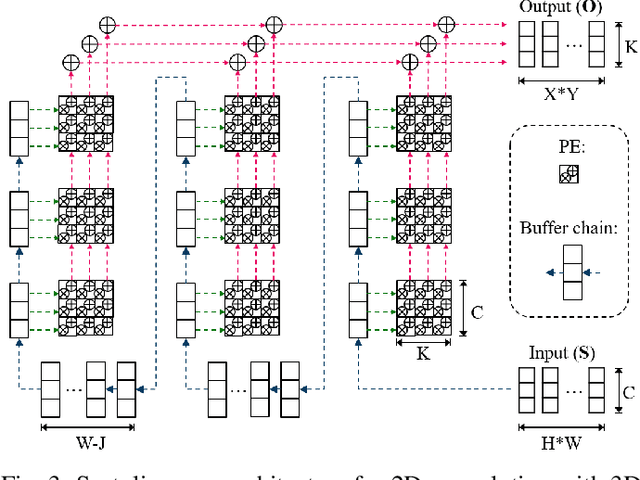
Neural network hardware is considered an essential part of future edge devices. In this paper, we propose a binary-weight spiking neural network (BW-SNN) hardware architecture for low-power real-time object classification on edge platforms. This design stores a full neural network on-chip, and hence requires no off-chip bandwidth. The proposed systolic array maximizes data reuse for a typical convolutional layer. A 5-layer convolutional BW-SNN hardware is implemented in 90nm CMOS. Compared with state-of-the-art designs, the area cost and energy per classification are reduced by 7$\times$ and 23$\times$, respectively, while also achieving a higher accuracy on the MNIST benchmark. This is also a pioneering SNN hardware architecture that supports advanced CNN architectures.
Scaling Vision with Sparse Mixture of Experts
Jun 10, 2021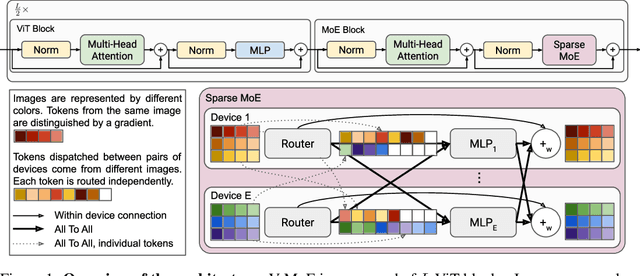
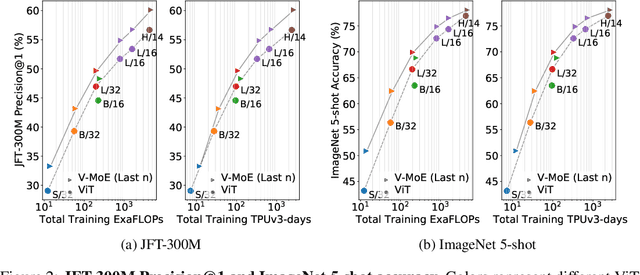

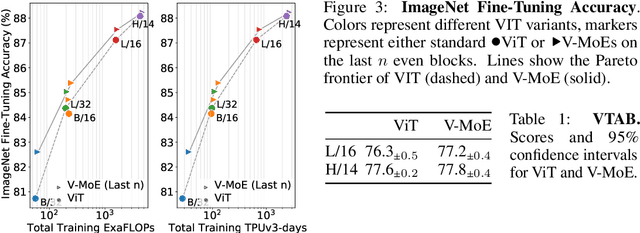
Sparsely-gated Mixture of Experts networks (MoEs) have demonstrated excellent scalability in Natural Language Processing. In Computer Vision, however, almost all performant networks are "dense", that is, every input is processed by every parameter. We present a Vision MoE (V-MoE), a sparse version of the Vision Transformer, that is scalable and competitive with the largest dense networks. When applied to image recognition, V-MoE matches the performance of state-of-the-art networks, while requiring as little as half of the compute at inference time. Further, we propose an extension to the routing algorithm that can prioritize subsets of each input across the entire batch, leading to adaptive per-image compute. This allows V-MoE to trade-off performance and compute smoothly at test-time. Finally, we demonstrate the potential of V-MoE to scale vision models, and train a 15B parameter model that attains 90.35% on ImageNet.
Attempt to Predict Failure Case Classification in a Failure Database by using Neural Network Models
Aug 29, 2021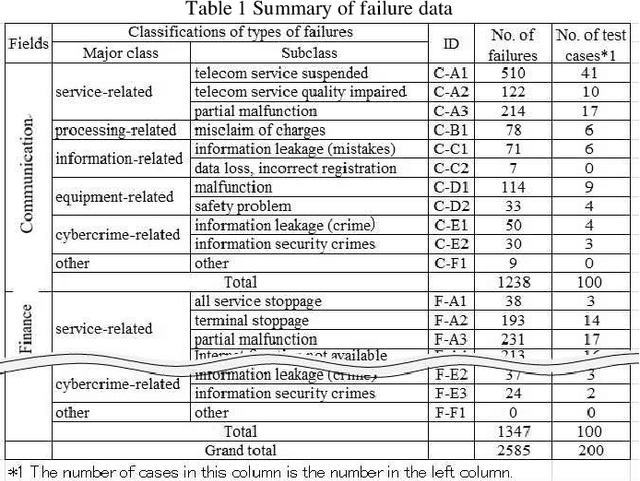
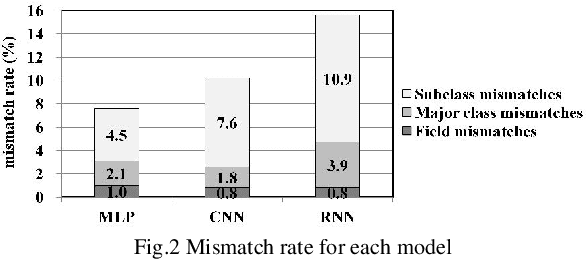
With the recent progress of information technology, the use of networked information systems has rapidly expanded. Electronic commerce and electronic payments between banks and companies, and online shopping and social networking services used by the general public are examples of such systems. Therefore, in order to maintain and improve the dependability of these systems, we are constructing a failure database from past failure cases. When importing new failure cases to the database, it is necessary to classify these cases according to failure type. The problems are the accuracy and efficiency of the classification. Especially when working with multiple individuals, unification of classification is required. Therefore, we are attempting to automate classification using machine learning. As evaluation models, we selected the multilayer perceptron (MLP), the convolutional neural network (CNN), and the recurrent neural network (RNN), which are models that use neural networks. As a result, the optimal model in terms of accuracy is first the MLP followed by the CNN, and the processing time of the classification is practical.