 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
StreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021
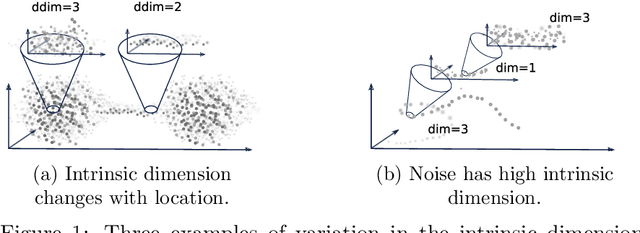
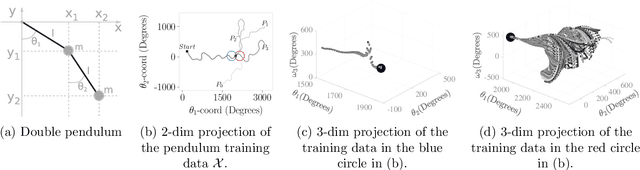
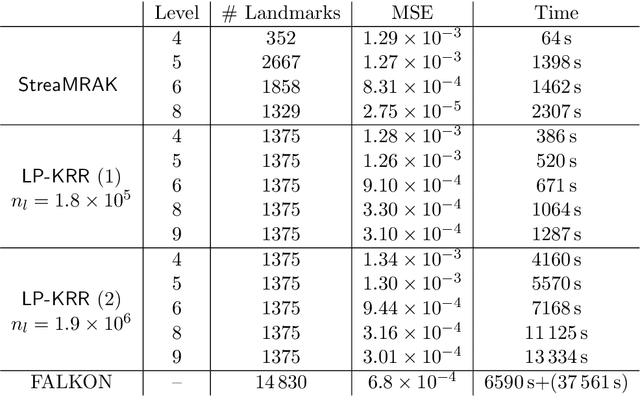
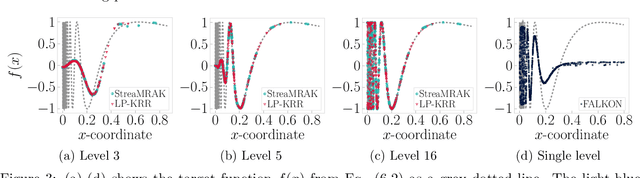
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.
Automata-based Optimal Planning with Relaxed Specifications
Jul 28, 2021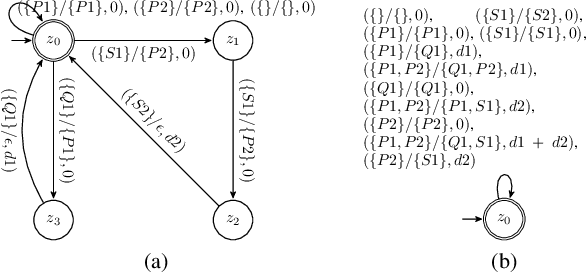
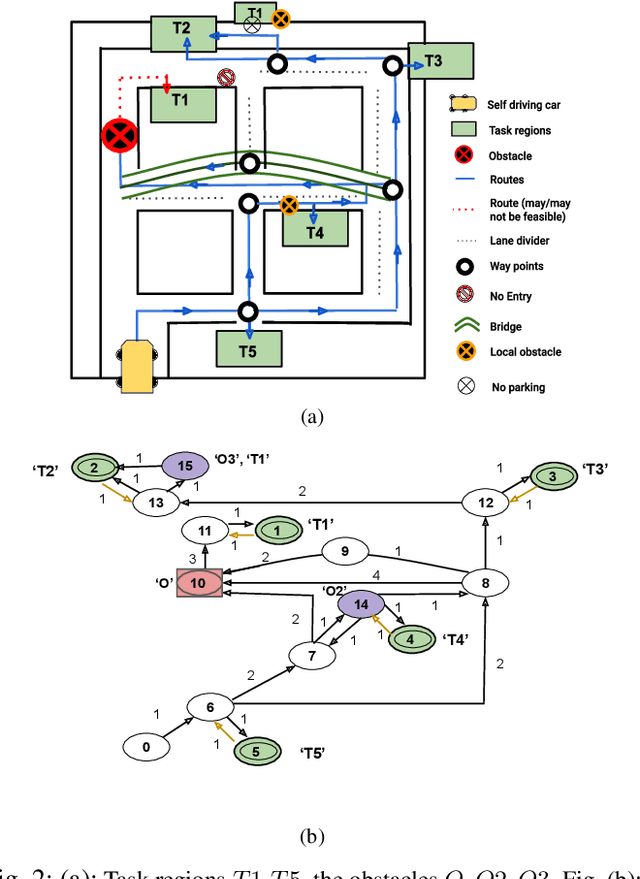
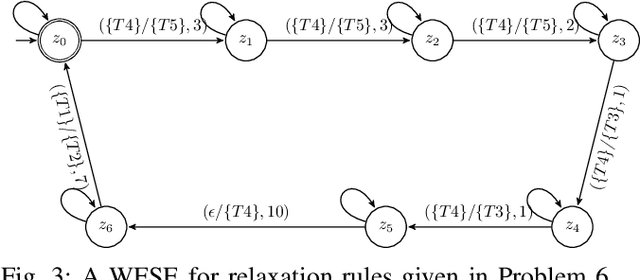
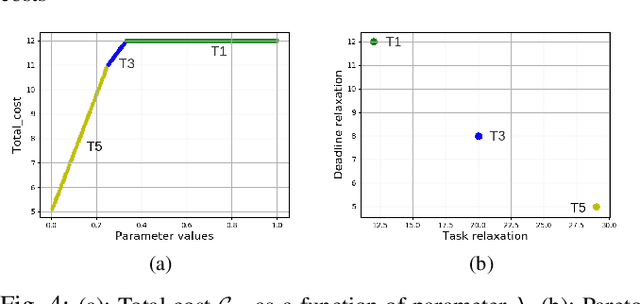
In this paper, we introduce an automata-based framework for planning with relaxed specifications. User relaxation preferences are represented as weighted finite state edit systems that capture permissible operations on the specification, substitution and deletion of tasks, with complex constraints on ordering and grouping. We propose a three-way product automaton construction method that allows us to compute minimal relaxation policies for the robots using standard shortest path algorithms. The three-way automaton captures the robot's motion, specification satisfaction, and available relaxations at the same time. Additionally, we consider a bi-objective problem that balances temporal relaxation of deadlines within specifications with changing and deleting tasks. Finally, we present the runtime performance and a case study that highlights different modalities of our framework.
Effective and interpretable dispatching rules for dynamic job shops via guided empirical learning
Sep 07, 2021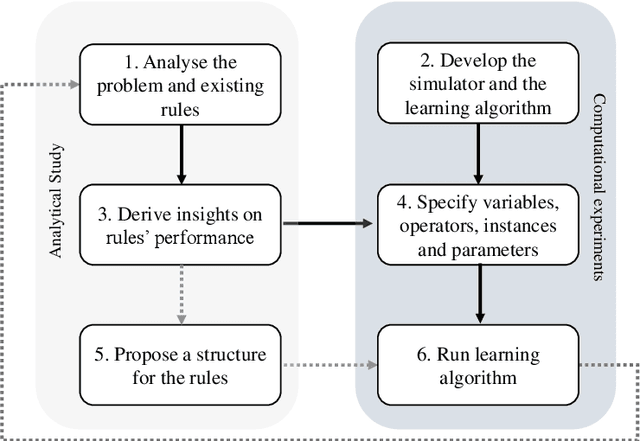
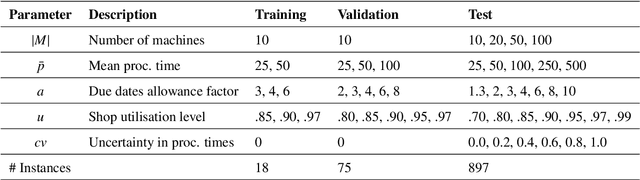
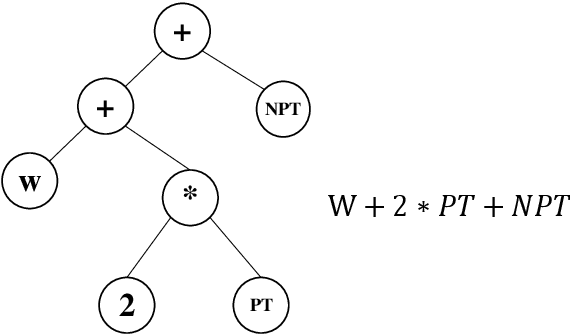
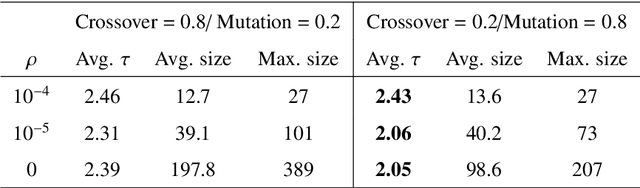
The emergence of Industry 4.0 is making production systems more flexible and also more dynamic. In these settings, schedules often need to be adapted in real-time by dispatching rules. Although substantial progress was made until the '90s, the performance of these rules is still rather limited. The machine learning literature is developing a variety of methods to improve them, but the resulting rules are difficult to interpret and do not generalise well for a wide range of settings. This paper is the first major attempt at combining machine learning with domain problem reasoning for scheduling. The idea consists of using the insights obtained with the latter to guide the empirical search of the former. Our hypothesis is that this guided empirical learning process should result in dispatching rules that are effective and interpretable and which generalise well to different instance classes. We test our approach in the classical dynamic job shop scheduling problem minimising tardiness, which is one of the most well-studied scheduling problems. Nonetheless, results suggest that our approach was able to find new state-of-the-art rules, which significantly outperform the existing literature in the vast majority of settings, from loose to tight due dates and from low utilisation conditions to congested shops. Overall, the average improvement is 19%. Moreover, the rules are compact, interpretable, and generalise well to extreme, unseen scenarios.
Continuous-Time Mean-Variance Portfolio Selection: A Reinforcement Learning Framework
May 05, 2019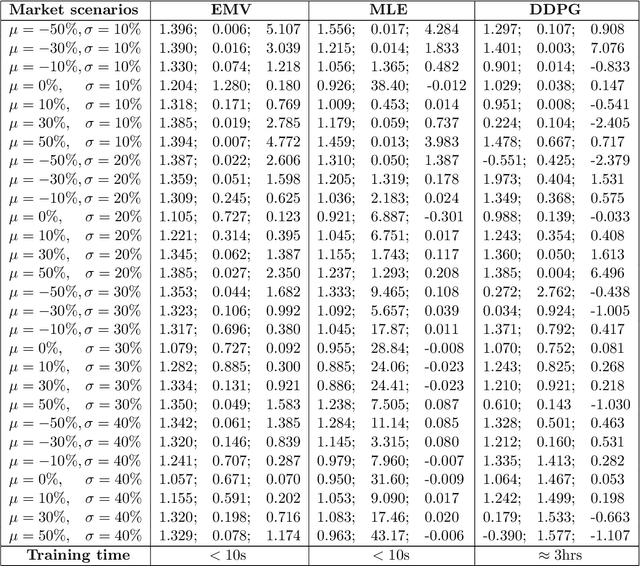
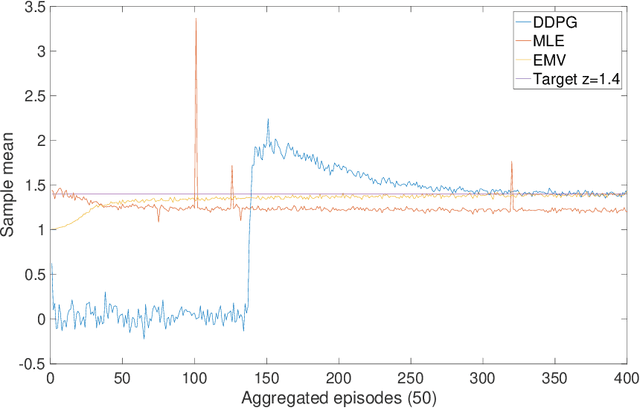
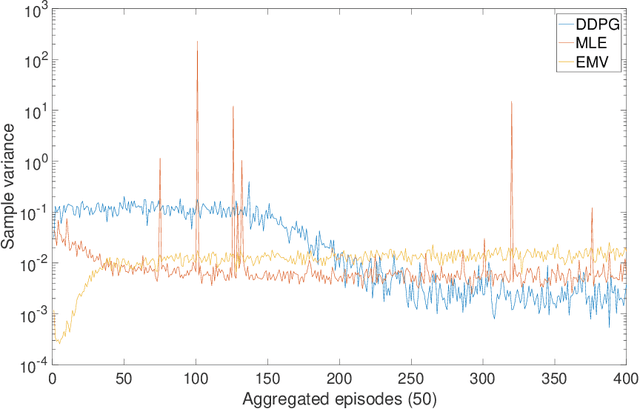
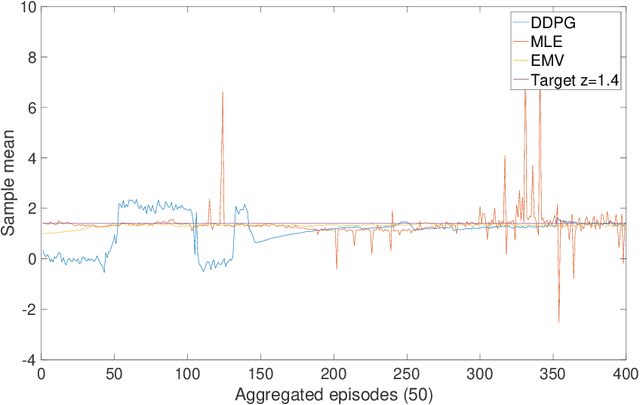
We approach the continuous-time mean-variance (MV) portfolio selection with reinforcement learning (RL). The problem is to achieve the best tradeoff between exploration and exploitation, and is formulated as an entropy-regularized, relaxed stochastic control problem. We prove that the optimal feedback policy for this problem must be Gaussian, with time-decaying variance. We then establish connections between the entropy-regularized MV and the classical MV, including the solvability equivalence and the convergence as exploration weighting parameter decays to zero. Finally, we prove a policy improvement theorem, based on which we devise an implementable RL algorithm. We find that our algorithm outperforms both an adaptive control based method and a deep neural networks based algorithm by a large margin in our simulations.
Model-free inference of unseen attractors: Reconstructing phase space features from a single noisy trajectory using reservoir computing
Aug 06, 2021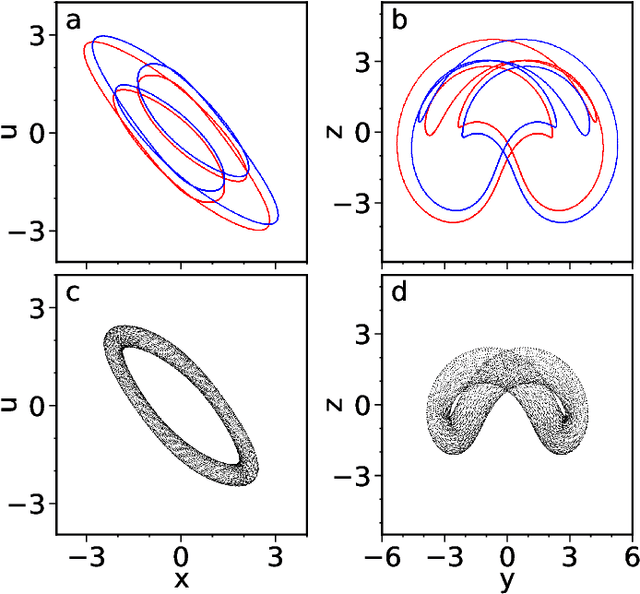
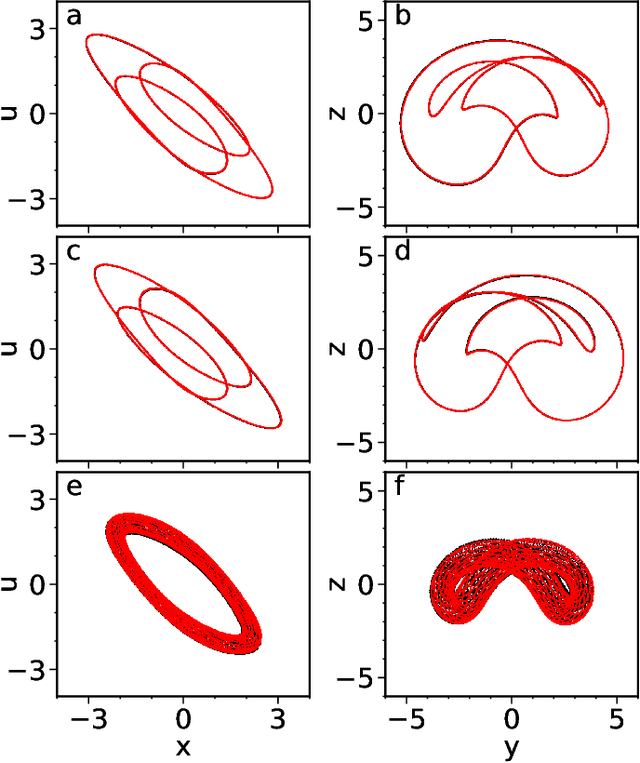
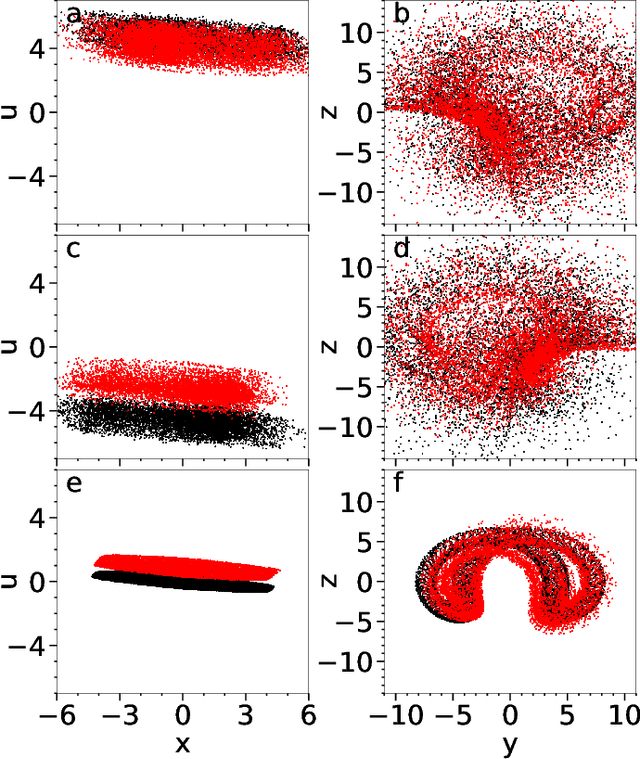
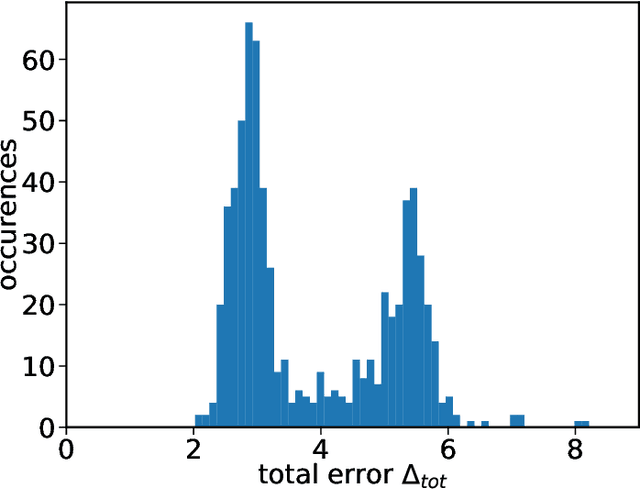
Reservoir computers are powerful tools for chaotic time series prediction. They can be trained to approximate phase space flows and can thus both predict future values to a high accuracy, as well as reconstruct the general properties of a chaotic attractor without requiring a model. In this work, we show that the ability to learn the dynamics of a complex system can be extended to systems with co-existing attractors, here a 4-dimensional extension of the well-known Lorenz chaotic system. We demonstrate that a reservoir computer can infer entirely unexplored parts of the phase space: a properly trained reservoir computer can predict the existence of attractors that were never approached during training and therefore are labelled as unseen. We provide examples where attractor inference is achieved after training solely on a single noisy trajectory.
Unsupervised Spoken Utterance Classification
Jul 02, 2021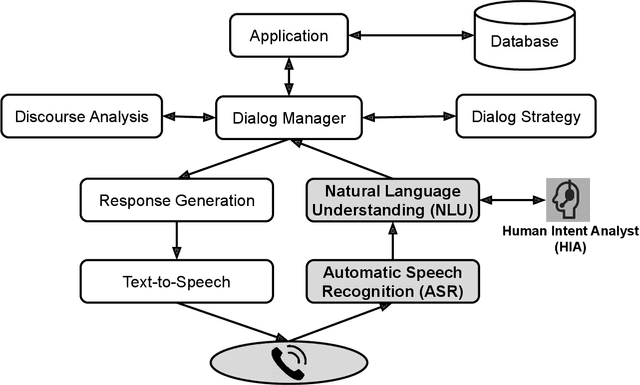
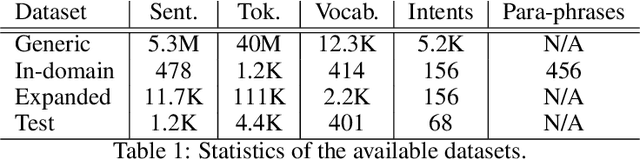
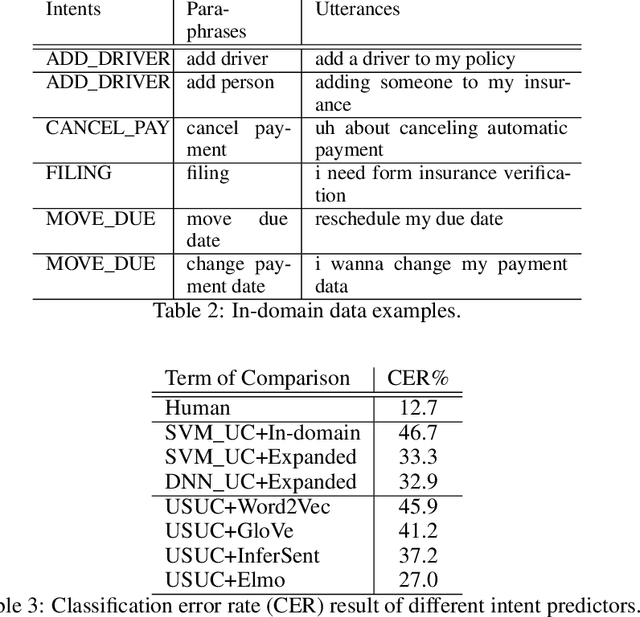

An intelligent virtual assistant (IVA) enables effortless conversations in call routing through spoken utterance classification (SUC) which is a special form of spoken language understanding (SLU). Building a SUC system requires a large amount of supervised in-domain data that is not always available. In this paper, we introduce an unsupervised spoken utterance classification approach (USUC) that does not require any in-domain data except for the intent labels and a few para-phrases per intent. USUC is consisting of a KNN classifier (K=1) and a complex embedding model trained on a large amount of unsupervised customer service corpus. Among all embedding models, we demonstrate that Elmo works best for USUC. However, an Elmo model is too slow to be used at run-time for call routing. To resolve this issue, first, we compute the uni- and bi-gram embedding vectors offline and we build a lookup table of n-grams and their corresponding embedding vector. Then we use this table to compute sentence embedding vectors at run-time, along with back-off techniques for unseen n-grams. Experiments show that USUC outperforms the traditional utterance classification methods by reducing the classification error rate from 32.9% to 27.0% without requiring supervised data. Moreover, our lookup and back-off technique increases the processing speed from 16 utterances per second to 118 utterances per second.
Stock price prediction using BERT and GAN
Jul 18, 2021
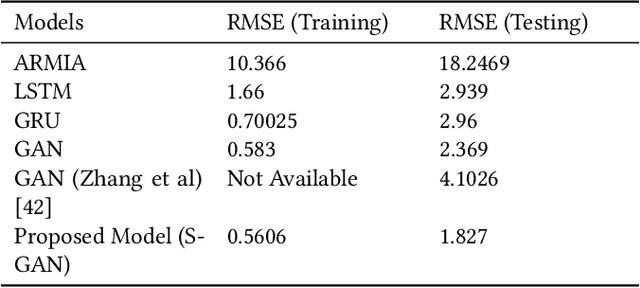
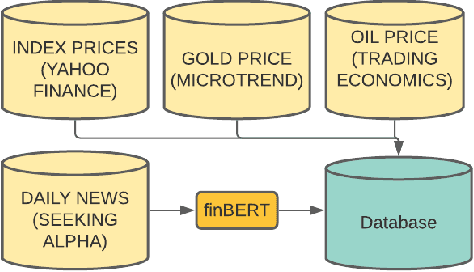
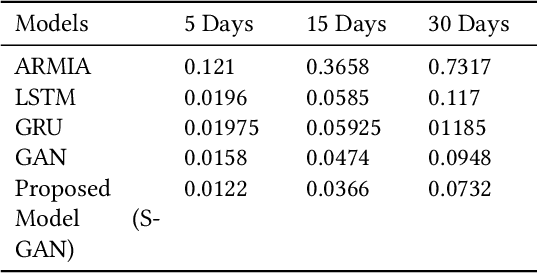
The stock market has been a popular topic of interest in the recent past. The growth in the inflation rate has compelled people to invest in the stock and commodity markets and other areas rather than saving. Further, the ability of Deep Learning models to make predictions on the time series data has been proven time and again. Technical analysis on the stock market with the help of technical indicators has been the most common practice among traders and investors. One more aspect is the sentiment analysis - the emotion of the investors that shows the willingness to invest. A variety of techniques have been used by people around the globe involving basic Machine Learning and Neural Networks. Ranging from the basic linear regression to the advanced neural networks people have experimented with all possible techniques to predict the stock market. It's evident from recent events how news and headlines affect the stock markets and cryptocurrencies. This paper proposes an ensemble of state-of-the-art methods for predicting stock prices. Firstly sentiment analysis of the news and the headlines for the company Apple Inc, listed on the NASDAQ is performed using a version of BERT, which is a pre-trained transformer model by Google for Natural Language Processing (NLP). Afterward, a Generative Adversarial Network (GAN) predicts the stock price for Apple Inc using the technical indicators, stock indexes of various countries, some commodities, and historical prices along with the sentiment scores. Comparison is done with baseline models like - Long Short Term Memory (LSTM), Gated Recurrent Units (GRU), vanilla GAN, and Auto-Regressive Integrated Moving Average (ARIMA) model.
Smooth Mesh Estimation from Depth Data using Non-Smooth Convex Optimization
Aug 06, 2021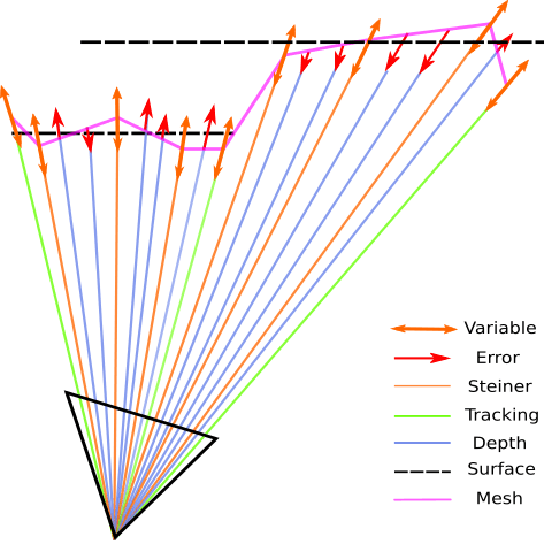
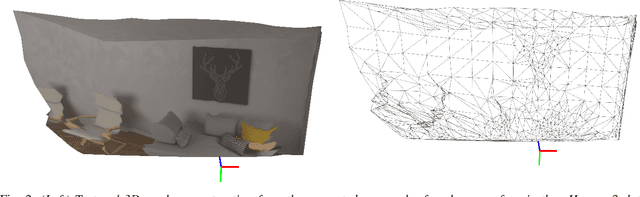
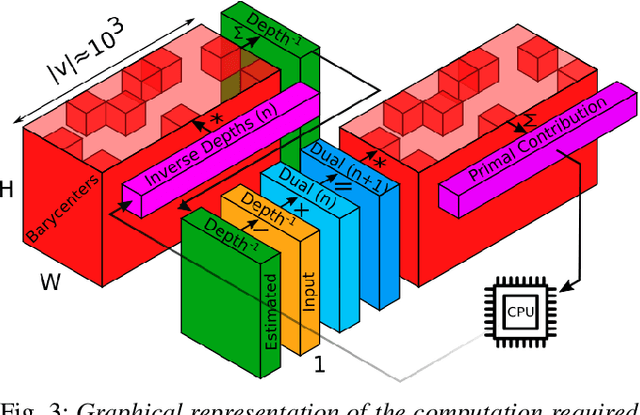
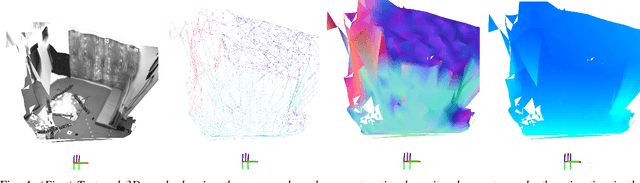
Meshes are commonly used as 3D maps since they encode the topology of the scene while being lightweight. Unfortunately, 3D meshes are mathematically difficult to handle directly because of their combinatorial and discrete nature. Therefore, most approaches generate 3D meshes of a scene after fusing depth data using volumetric or other representations. Nevertheless, volumetric fusion remains computationally expensive both in terms of speed and memory. In this paper, we leapfrog these intermediate representations and build a 3D mesh directly from a depth map and the sparse landmarks triangulated with visual odometry. To this end, we formulate a non-smooth convex optimization problem that we solve using a primal-dual method. Our approach generates a smooth and accurate 3D mesh that substantially improves the state-of-the-art on direct mesh reconstruction while running in real-time.
Deep Personalized Glucose Level Forecasting Using Attention-based Recurrent Neural Networks
Jun 02, 2021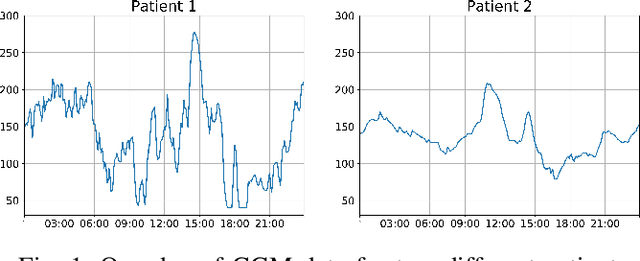
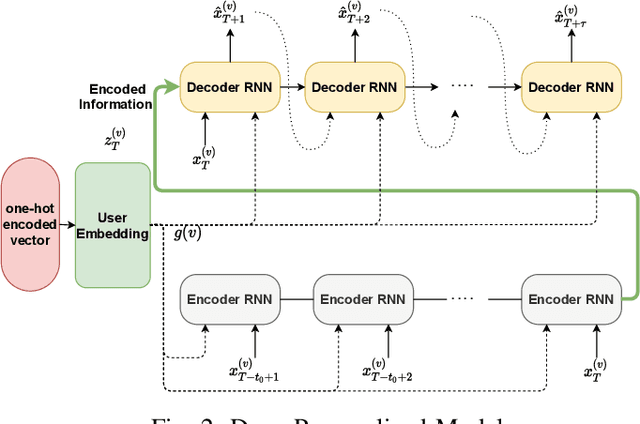
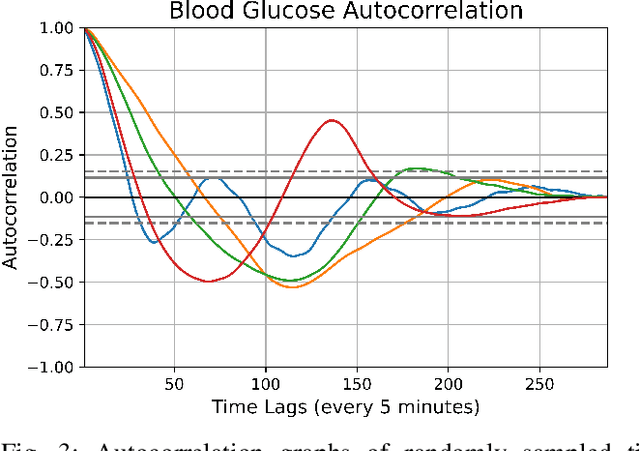
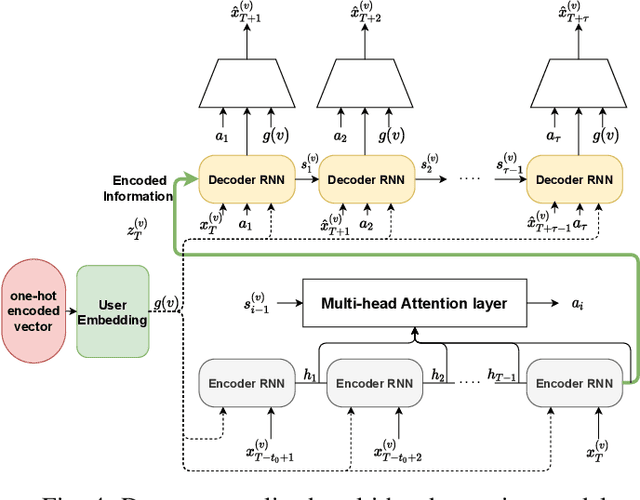
In this paper, we study the problem of blood glucose forecasting and provide a deep personalized solution. Predicting blood glucose level in people with diabetes has significant value because health complications of abnormal glucose level are serious, sometimes even leading to death. Therefore, having a model that can accurately and quickly warn patients of potential problems is essential. To develop a better deep model for blood glucose forecasting, we analyze the data and detect important patterns. These observations helped us to propose a method that has several key advantages over existing methods: 1- it learns a personalized model for each patient as well as a global model; 2- it uses an attention mechanism and extracted time features to better learn long-term dependencies in the data; 3- it introduces a new, robust training procedure for time series data. We empirically show the efficacy of our model on a real dataset.
Computing Graph Descriptors on Edge Streams
Sep 02, 2021
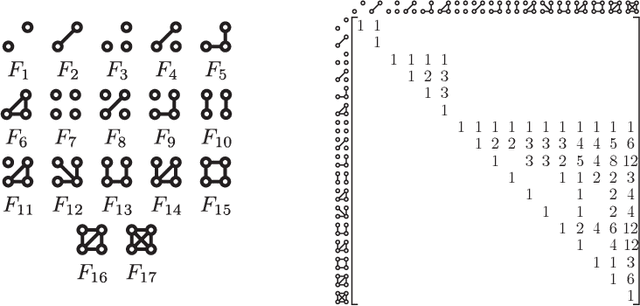

Graph feature extraction is a fundamental task in graphs analytics. Using feature vectors (graph descriptors) in tandem with data mining algorithms that operate on Euclidean data, one can solve problems such as classification, clustering, and anomaly detection on graph-structured data. This idea has proved fruitful in the past, with spectral-based graph descriptors providing state-of-the-art classification accuracy on benchmark datasets. However, these algorithms do not scale to large graphs since: 1) they require storing the entire graph in memory, and 2) the end-user has no control over the algorithm's runtime. In this paper, we present single-pass streaming algorithms to approximate structural features of graphs (counts of subgraphs of order $k \geq 4$). Operating on edge streams allows us to avoid keeping the entire graph in memory, and controlling the sample size enables us to control the time taken by the algorithm. We demonstrate the efficacy of our descriptors by analyzing the approximation error, classification accuracy, and scalability to massive graphs. Our experiments showcase the effect of the sample size on approximation error and predictive accuracy. The proposed descriptors are applicable on graphs with millions of edges within minutes and outperform the state-of-the-art descriptors in classification accuracy.