 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Semantics for Hybrid ASP systems
Aug 06, 2021
Over the last decades the development of ASP has brought about an expressive modeling language powered by highly performant systems. At the same time, it gets more and more difficult to provide semantic underpinnings capturing the resulting constructs and inferences. This is even more severe when it comes to hybrid ASP languages and systems that are often needed to handle real-world applications. We address this challenge and introduce the concept of abstract and structured theories that allow us to formally elaborate upon their integration with ASP. We then use this concept to make precise the semantic characterization of CLINGO's theory-reasoning framework and establish its correspondence to the logic of Here-and-there with constraints. This provides us with a formal framework in which we can elaborate formal properties of existing hybridizations of CLINGO such as CLINGCON, CLINGOM[DL], and CLINGO[LP].
Angle Estimation for Terahertz Ultra-Massive MIMO-Based Space-to-Air Communications
Aug 02, 2021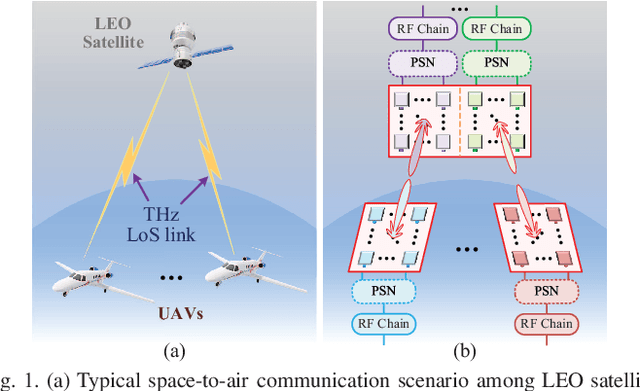
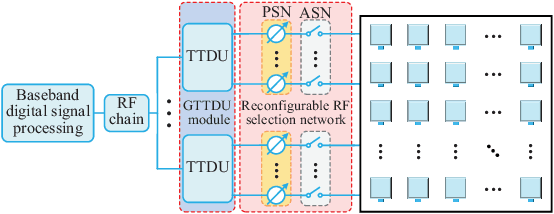
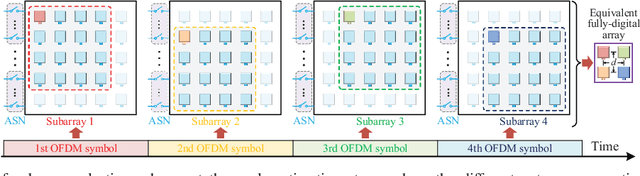
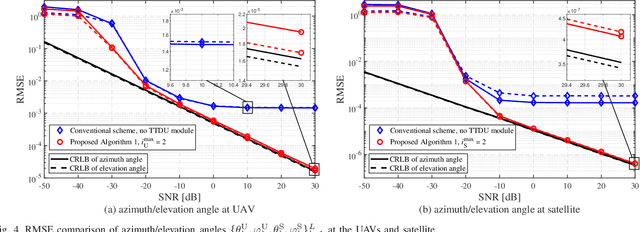
This paper investigates terahertz ultra-massive (UM)-MIMO-based angle estimation for space-to-air communications, which can solve the performance degradation problem caused by the dual delay-beam squint effects of terahertz UM-MIMO channels. Specifically, we first design a grouping true-time delay unit module that can significantly mitigate the impact of delay-beam squint effects to establish the space-to-air THz link. Based on the subarray selection scheme, the UM hybrid array can be equivalently considered as a low-dimensional fully-digital array, and then the fine estimates of azimuth/elevation angles at both UAVs and satellite can be separately acquired using the proposed prior-aided iterative angle estimation algorithm. The simulation results that close to Cram\'{e}r-Rao lower bounds verify the effectiveness of our solution.
MACRPO: Multi-Agent Cooperative Recurrent Policy Optimization
Sep 02, 2021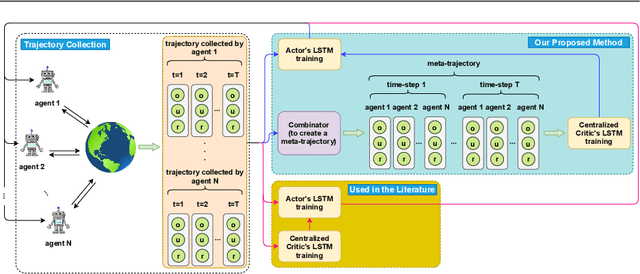
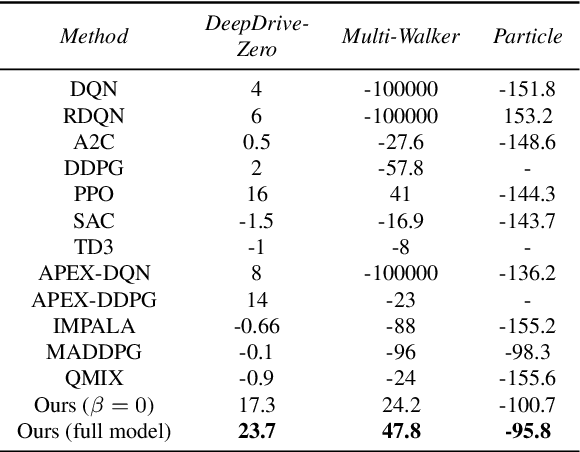
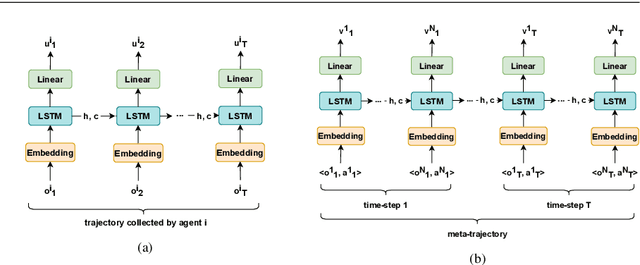
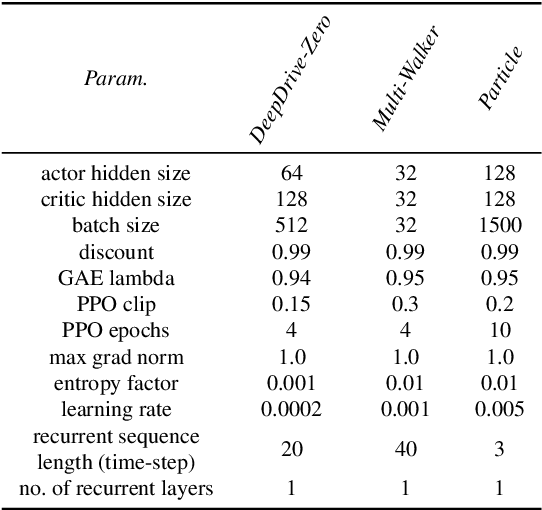
This work considers the problem of learning cooperative policies in multi-agent settings with partially observable and non-stationary environments without a communication channel. We focus on improving information sharing between agents and propose a new multi-agent actor-critic method called \textit{Multi-Agent Cooperative Recurrent Proximal Policy Optimization} (MACRPO). We propose two novel ways of integrating information across agents and time in MACRPO: First, we use a recurrent layer in critic's network architecture and propose a new framework to use a meta-trajectory to train the recurrent layer. This allows the network to learn the cooperation and dynamics of interactions between agents, and also handle partial observability. Second, we propose a new advantage function that incorporates other agents' rewards and value functions. We evaluate our algorithm on three challenging multi-agent environments with continuous and discrete action spaces, Deepdrive-Zero, Multi-Walker, and Particle environment. We compare the results with several ablations and state-of-the-art multi-agent algorithms such as QMIX and MADDPG and also single-agent methods with shared parameters between agents such as IMPALA and APEX. The results show superior performance against other algorithms. The code is available online at https://github.com/kargarisaac/macrpo.
PTT: Point-Track-Transformer Module for 3D Single Object Tracking in Point Clouds
Aug 14, 2021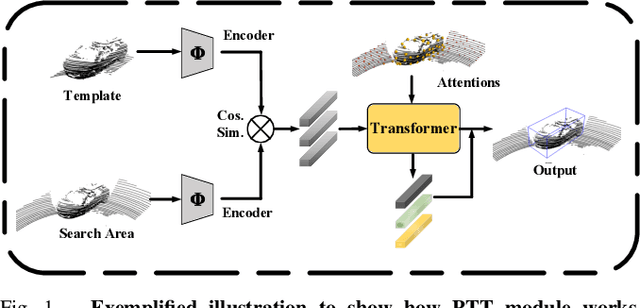
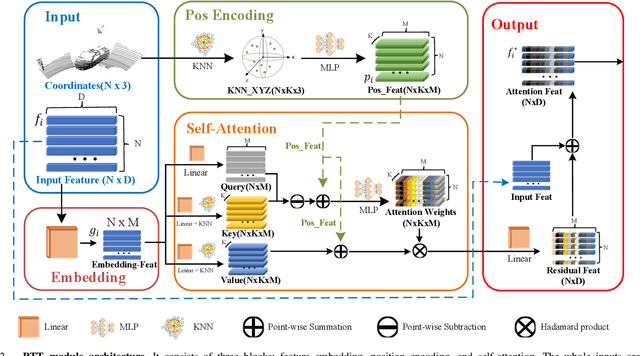
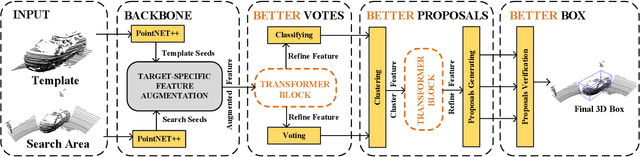
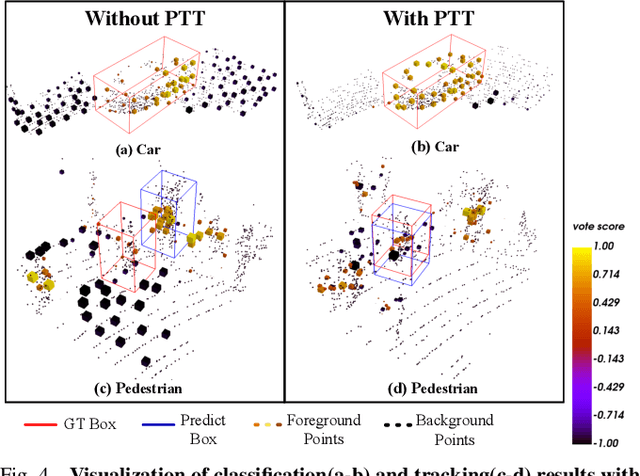
3D single object tracking is a key issue for robotics. In this paper, we propose a transformer module called Point-Track-Transformer (PTT) for point cloud-based 3D single object tracking. PTT module contains three blocks for feature embedding, position encoding, and self-attention feature computation. Feature embedding aims to place features closer in the embedding space if they have similar semantic information. Position encoding is used to encode coordinates of point clouds into high dimension distinguishable features. Self-attention generates refined attention features by computing attention weights. Besides, we embed the PTT module into the open-source state-of-the-art method P2B to construct PTT-Net. Experiments on the KITTI dataset reveal that our PTT-Net surpasses the state-of-the-art by a noticeable margin (~10\%). Additionally, PTT-Net could achieve real-time performance (~40FPS) on NVIDIA 1080Ti GPU. Our code is open-sourced for the robotics community at https://github.com/shanjiayao/PTT.
Allocating Indivisible Goods to Strategic Agents: Pure Nash Equilibria and Fairness
Sep 17, 2021We consider the problem of fairly allocating a set of indivisible goods to a set of strategic agents with additive valuation functions. We assume no monetary transfers and, therefore, a mechanism in our setting is an algorithm that takes as input the reported -- rather than the true -- values of the agents. Our main goal is to explore whether there exist mechanisms that have pure Nash equilibria for every instance and, at the same time, provide fairness guarantees for the allocations that correspond to these equilibria. We focus on two relaxations of envy-freeness, namely envy-freeness up to one good (EF1), and envy-freeness up to any good (EFX), and we positively answer the above question. In particular, we study two algorithms that are known to produce such allocations in the non-strategic setting: Round-Robin (EF1 allocations for any number of agents) and a cut-and-choose algorithm of Plaut and Roughgarden [SIAM Journal of Discrete Mathematics, 2020] (EFX allocations for two agents). For Round-Robin we show that all of its pure Nash equilibria induce allocations that are EF1 with respect to the underlying true values, while for the algorithm of Plaut and Roughgarden we show that the corresponding allocations not only are EFX but also satisfy maximin share fairness, something that is not true for this algorithm in the non-strategic setting! Further, we show that a weaker version of the latter result holds for any mechanism for two agents that always has pure Nash equilibria which all induce EFX allocations.
Automata-based Optimal Planning with Relaxed Specifications
Jul 28, 2021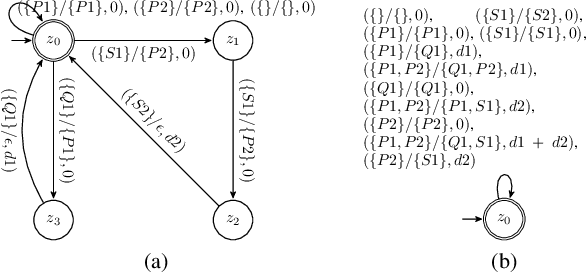
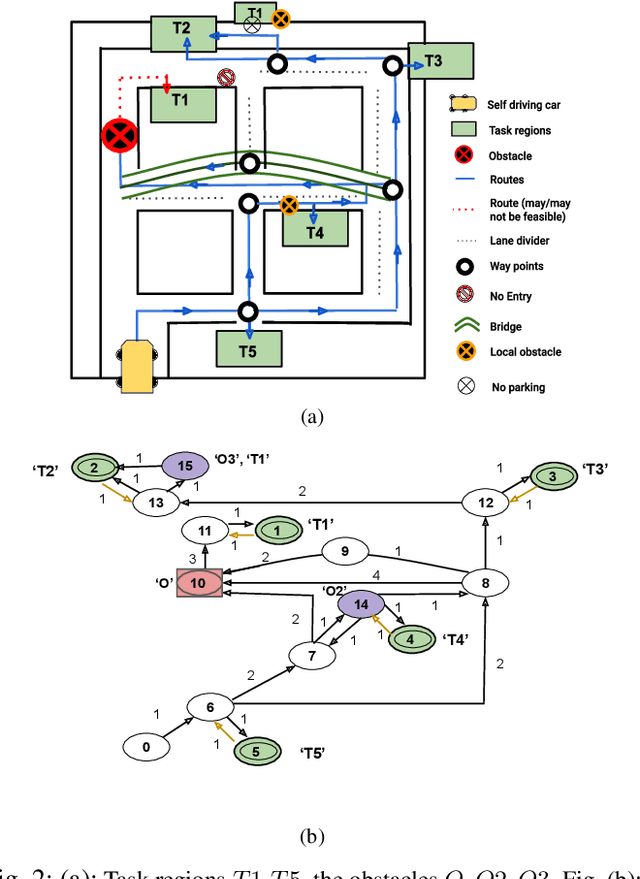
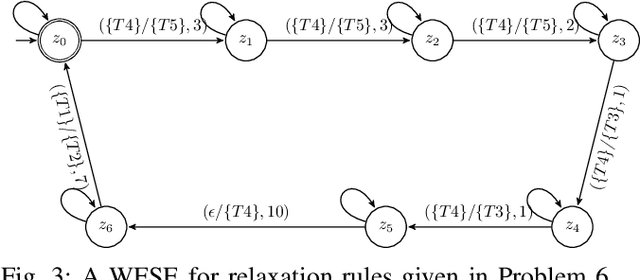
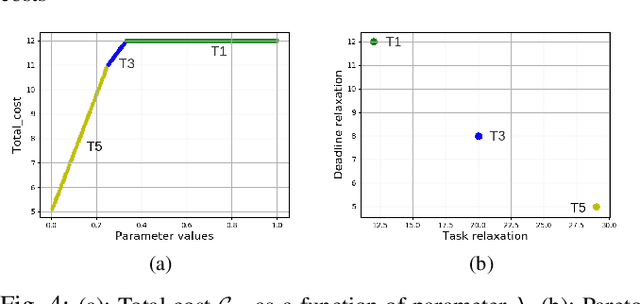
In this paper, we introduce an automata-based framework for planning with relaxed specifications. User relaxation preferences are represented as weighted finite state edit systems that capture permissible operations on the specification, substitution and deletion of tasks, with complex constraints on ordering and grouping. We propose a three-way product automaton construction method that allows us to compute minimal relaxation policies for the robots using standard shortest path algorithms. The three-way automaton captures the robot's motion, specification satisfaction, and available relaxations at the same time. Additionally, we consider a bi-objective problem that balances temporal relaxation of deadlines within specifications with changing and deleting tasks. Finally, we present the runtime performance and a case study that highlights different modalities of our framework.
A fast asynchronous MCMC sampler for sparse Bayesian inference
Aug 14, 2021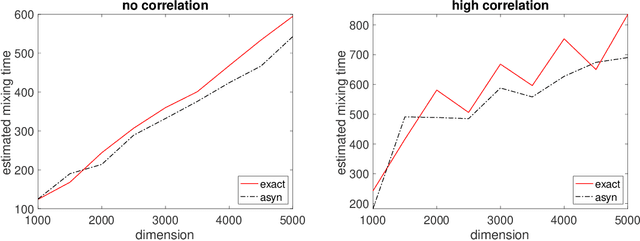

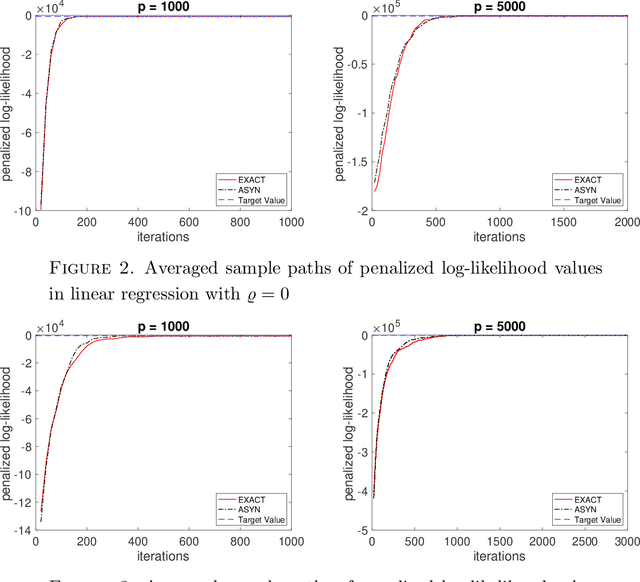
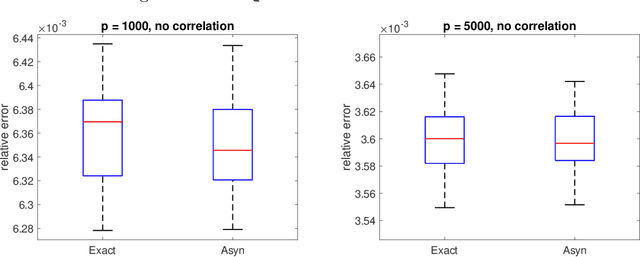
We propose a very fast approximate Markov Chain Monte Carlo (MCMC) sampling framework that is applicable to a large class of sparse Bayesian inference problems, where the computational cost per iteration in several models is of order $O(ns)$, where $n$ is the sample size, and $s$ the underlying sparsity of the model. This cost can be further reduced by data sub-sampling when stochastic gradient Langevin dynamics are employed. The algorithm is an extension of the asynchronous Gibbs sampler of Johnson et al. (2013), but can be viewed from a statistical perspective as a form of Bayesian iterated sure independent screening (Fan et al. (2009)). We show that in high-dimensional linear regression problems, the Markov chain generated by the proposed algorithm admits an invariant distribution that recovers correctly the main signal with high probability under some statistical assumptions. Furthermore we show that its mixing time is at most linear in the number of regressors. We illustrate the algorithm with several models.
Learning Representations from Imperfect Time Series Data via Tensor Rank Regularization
Jul 01, 2019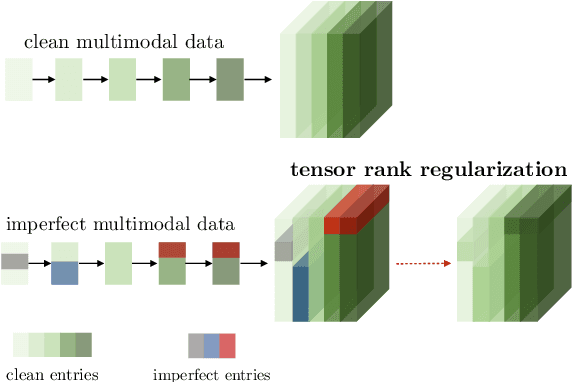
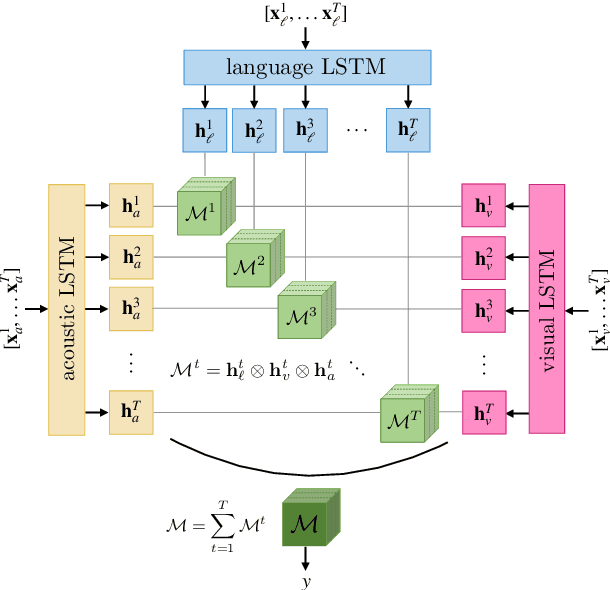
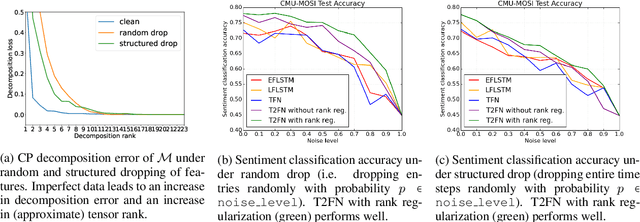
There has been an increased interest in multimodal language processing including multimodal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often imperfect as a result of imperfect modalities, missing entries or noise corruption. To address these concerns, we present a regularization method based on tensor rank minimization. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor representations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfection.
Unsupervised Place Recognition with Deep Embedding Learning over Radar Videos
Jun 12, 2021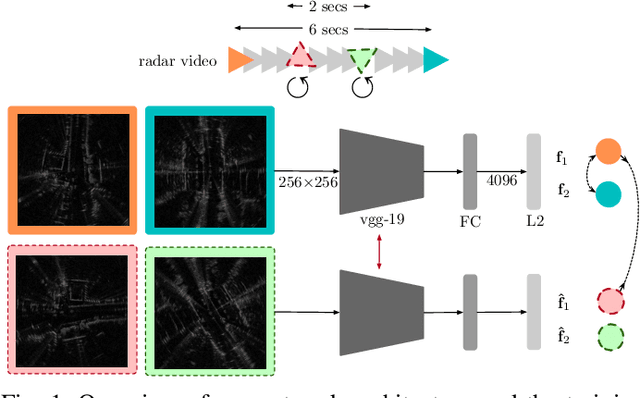
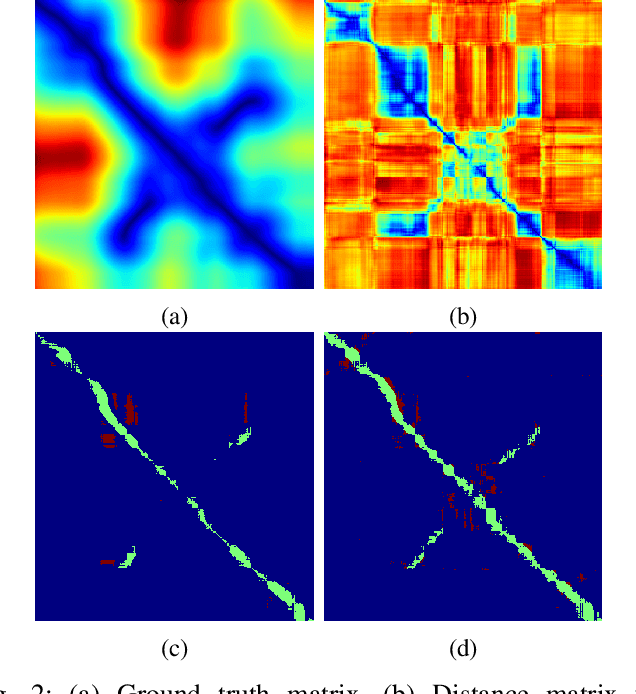
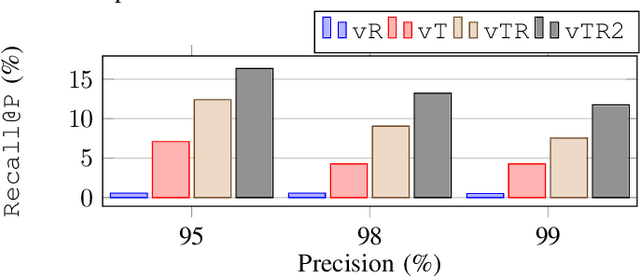
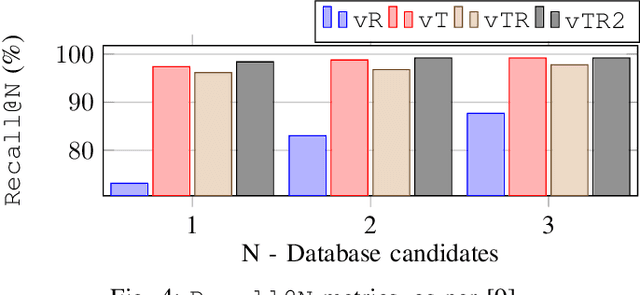
We learn, in an unsupervised way, an embedding from sequences of radar images that is suitable for solving place recognition problem using complex radar data. We experiment on 280 km of data and show performance exceeding state-of-the-art supervised approaches, localising correctly 98.38% of the time when using just the nearest database candidate.
StreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021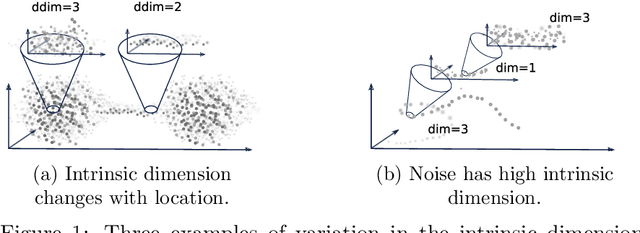
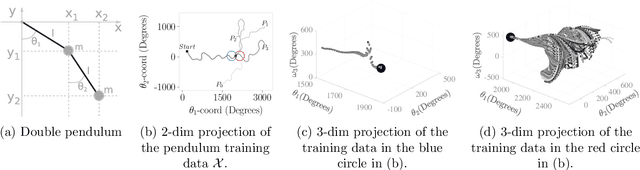
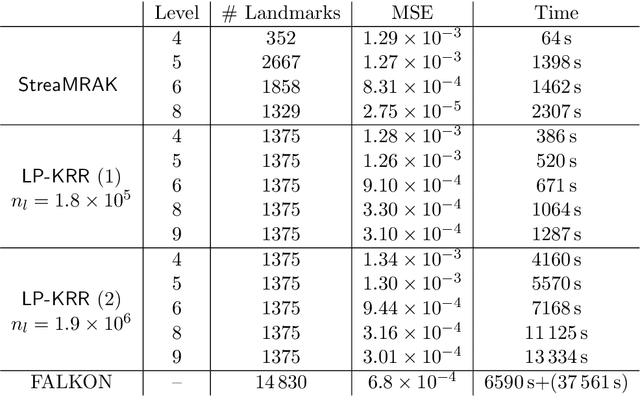
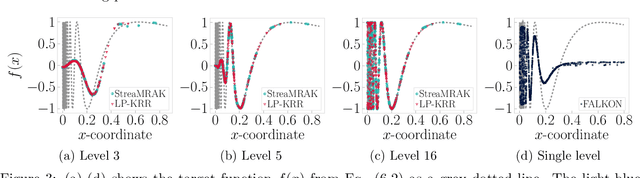
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.