 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simulating Execution Time of Tensor Programs using Graph Neural Networks
Apr 26, 2019
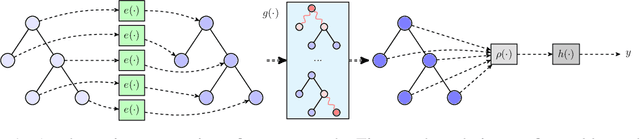
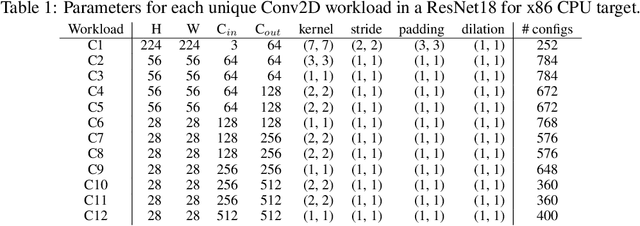
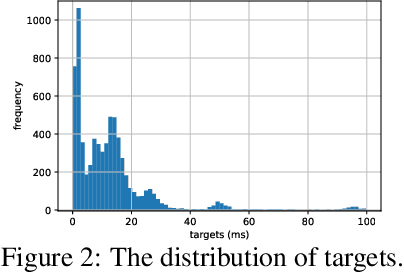
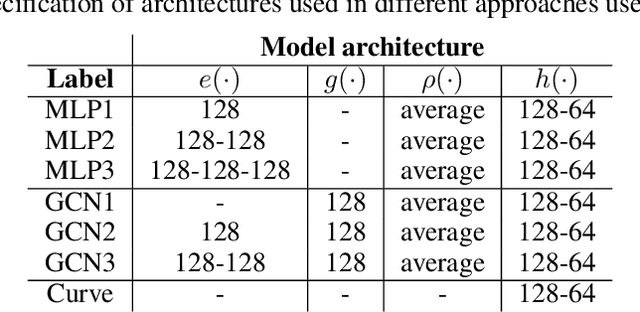
Optimizing the execution time of tensor program, e.g., a convolution, involves finding its optimal configuration. Searching the configuration space exhaustively is typically infeasible in practice. In line with recent research using TVM, we propose to learn a surrogate model to overcome this issue. The model is trained on an acyclic graph called an abstract syntax tree, and utilizes a graph convolutional network to exploit structure in the graph. We claim that a learnable graph-based data processing is a strong competitor to heuristic-based feature extraction. We present a new dataset of graphs corresponding to configurations and their execution time for various tensor programs. We provide baselines for a runtime prediction task.
Incrementally Stochastic and Accelerated Gradient Information mixed Optimization for Manipulator Motion Planning
Aug 21, 2021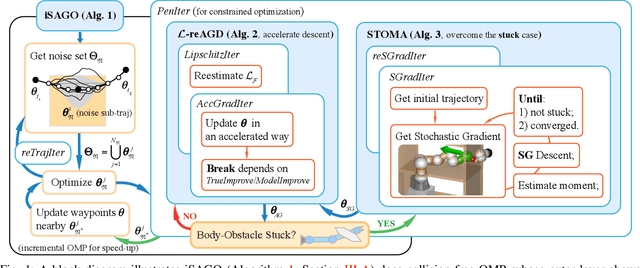
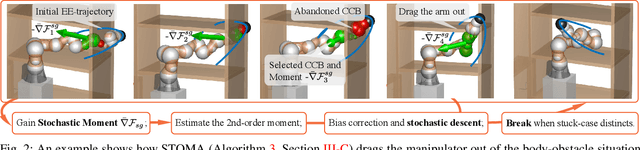

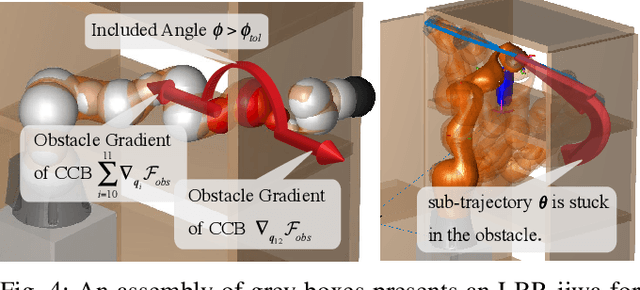
This paper introduces a novel motion planning algorithm, incrementally stochastic and accelerated gradient information mixed optimization (iSAGO), for robotic manipulators in a narrow workspace. Primarily, we propose the overall scheme of iSAGO integrating the accelerated and stochastic gradient information for efficient descent in the penalty method. In the stochastic part, we generate the adaptive stochastic moment via the random selection of collision checkboxes, interval time-series, and penalty factor based on Adam to solve the body-obstacle stuck case. Due to the slow convergence of STOMA, we integrate the accelerated gradient and stimulate the descent rate in a Lipschitz constant reestimation framework. Moreover, we introduce the Bayesian tree inference (BTI) method, transforming the whole trajectory optimization (SAGO) into an incremental sub-trajectory optimization (iSAGO) to improve the computational efficiency and success rate. Finally, we demonstrate the key coefficient tuning, benchmark iSAGO against other planners (CHOMP, GPMP2, TrajOpt, STOMP, and RRT-Connect), and implement iSAGO on AUBO-i5 in a storage shelf. The result shows the highest success rate and moderate solving efficiency of iSAGO.
One-shot Key Information Extraction from Document with Deep Partial Graph Matching
Sep 26, 2021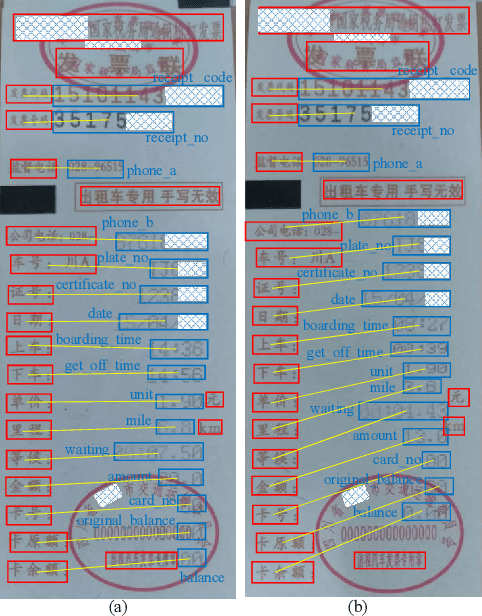
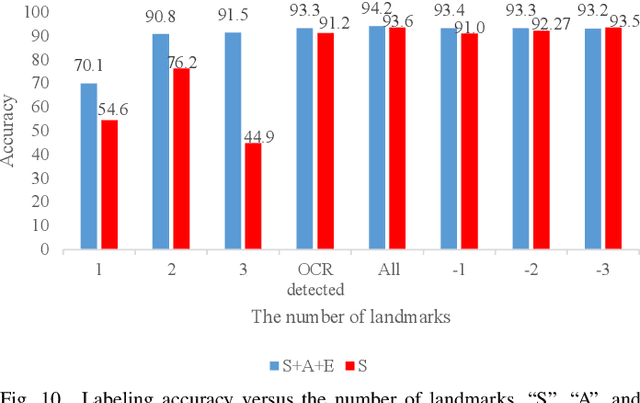
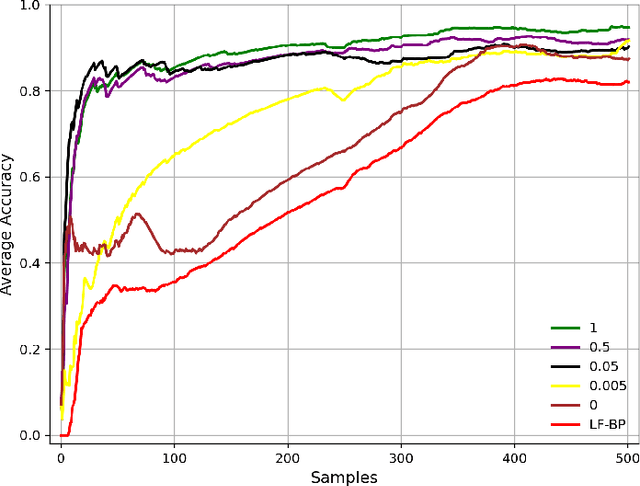
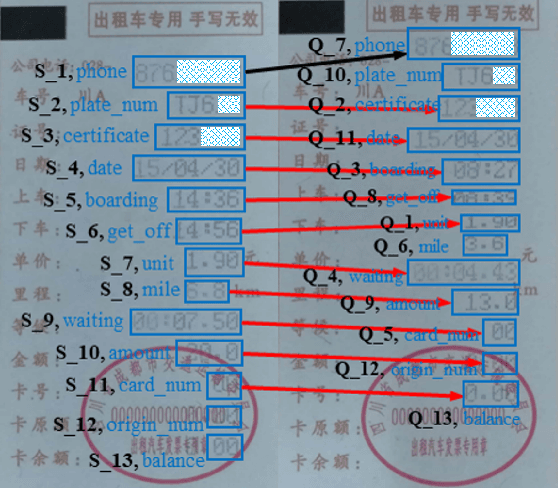
Automating the Key Information Extraction (KIE) from documents improves efficiency, productivity, and security in many industrial scenarios such as rapid indexing and archiving. Many existing supervised learning methods for the KIE task need to feed a large number of labeled samples and learn separate models for different types of documents. However, collecting and labeling a large dataset is time-consuming and is not a user-friendly requirement for many cloud platforms. To overcome these challenges, we propose a deep end-to-end trainable network for one-shot KIE using partial graph matching. Contrary to previous methods that the learning of similarity and solving are optimized separately, our method enables the learning of the two processes in an end-to-end framework. Existing one-shot KIE methods are either template or simple attention-based learning approach that struggle to handle texts that are shifted beyond their desired positions caused by printers, as illustrated in Fig.1. To solve this problem, we add one-to-(at most)-one constraint such that we will find the globally optimized solution even if some texts are drifted. Further, we design a multimodal context ensemble block to boost the performance through fusing features of spatial, textual, and aspect representations. To promote research of KIE, we collected and annotated a one-shot document KIE dataset named DKIE with diverse types of images. The DKIE dataset consists of 2.5K document images captured by mobile phones in natural scenes, and it is the largest available one-shot KIE dataset up to now. The results of experiments on DKIE show that our method achieved state-of-the-art performance compared with recent one-shot and supervised learning approaches. The dataset and proposed one-shot KIE model will be released soo
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 26, 2021

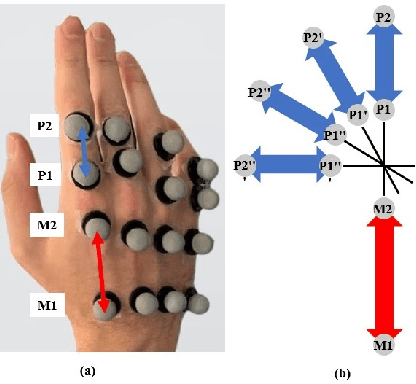
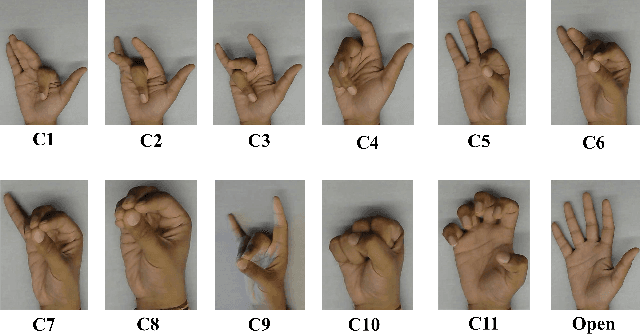
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.
Generating multi-type sequences of temporal events to improve fraud detection in game advertising
Apr 07, 2021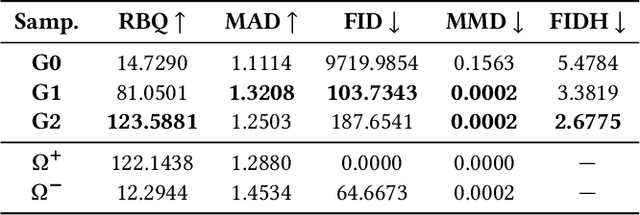
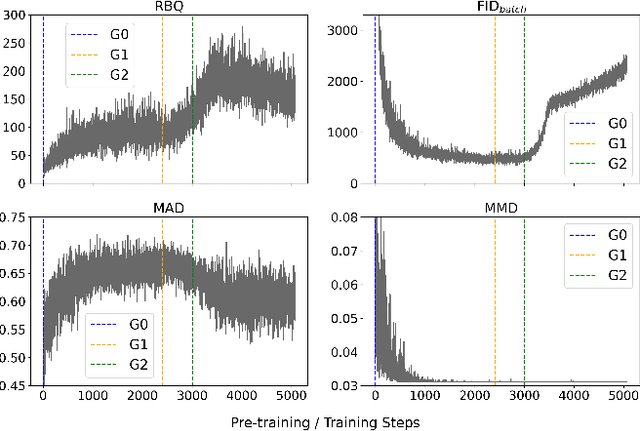
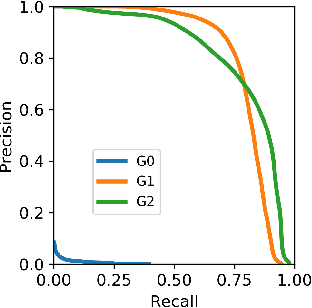
Fraudulent activities related to online advertising can potentially harm the trust advertisers put in advertising networks and sour the gaming experience for users. Pay-Per-Click/Install (PPC/I) advertising is one of the main revenue models in game monetization. Widespread use of the PPC/I model has led to a rise in click/install fraud events in games. The majority of traffic in ad networks is non-fraudulent, which imposes difficulties on machine learning based fraud detection systems to deal with highly skewed labels. From the ad network standpoint, user activities are multi-type sequences of temporal events consisting of event types and corresponding time intervals. Time Long Short-Term Memory (Time-LSTM) network cells have been proved effective in modeling intrinsic hidden patterns with non-uniform time intervals. In this study, we propose using a variant of Time-LSTM cells in combination with a modified version of Sequence Generative Adversarial Generative (SeqGAN)to generate artificial sequences to mimic the fraudulent user patterns in ad traffic. We also propose using a Critic network instead of Monte-Carlo (MC) roll-out in training SeqGAN to reduce computational costs. The GAN-generated sequences can be used to enhance the classification ability of event-based fraud detection classifiers. Our extensive experiments based on synthetic data have shown the trained generator has the capability to generate sequences with desired properties measured by multiple criteria.
ELSED: Enhanced Line SEgment Drawing
Aug 06, 2021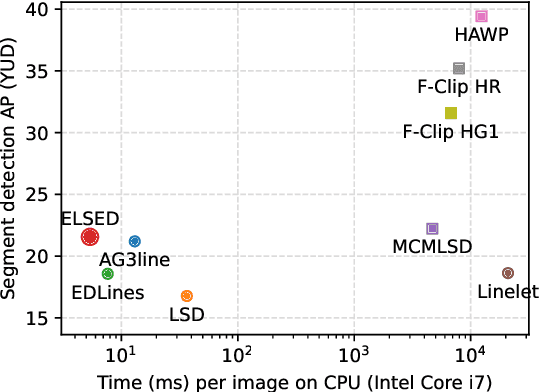
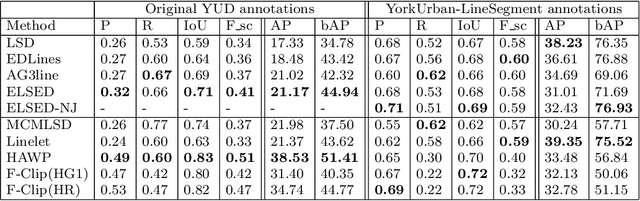
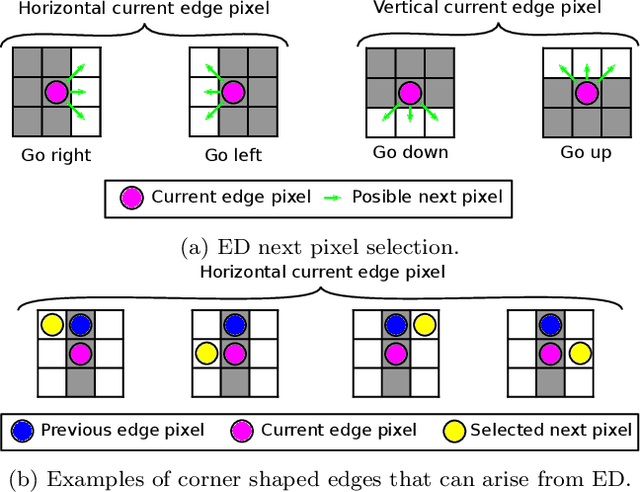
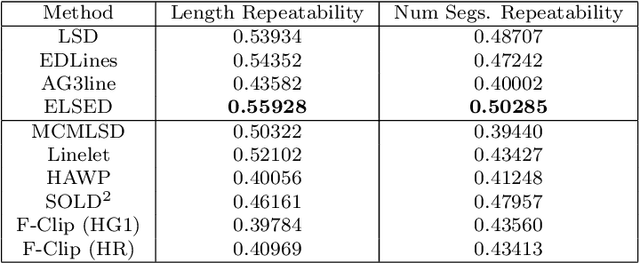
Detecting local features, such as corners, segments or blobs, is the first step in the pipeline of many Computer Vision applications. Its speed is crucial for real time applications. In this paper we present ELSED, the fastest line segment detector in the literature. The key for its efficiency is a local segment growing algorithm that connects gradient aligned pixels in presence of small discontinuities. The proposed algorithm not only runs in devices with very low end hardware, but may also be parametrized to foster the detection of short or longer segments, depending on the task at hand. We also introduce new metrics to evaluate the accuracy and repeatability of segment detectors. In our experiments with different public benchmarks we prove that our method is the most efficient in the literature and quantify the accuracy traded for such gain.
Reward-Weighted Regression Converges to a Global Optimum
Jul 19, 2021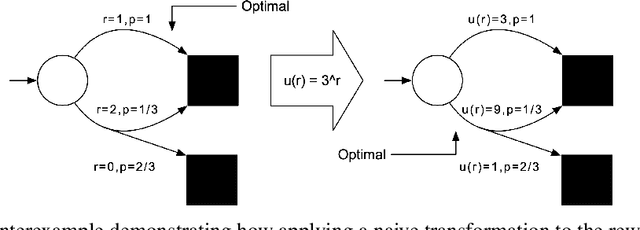
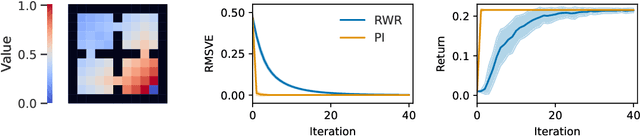
Reward-Weighted Regression (RWR) belongs to a family of widely known iterative Reinforcement Learning algorithms based on the Expectation-Maximization framework. In this family, learning at each iteration consists of sampling a batch of trajectories using the current policy and fitting a new policy to maximize a return-weighted log-likelihood of actions. Although RWR is known to yield monotonic improvement of the policy under certain circumstances, whether and under which conditions RWR converges to the optimal policy have remained open questions. In this paper, we provide for the first time a proof that RWR converges to a global optimum when no function approximation is used.
Lower Bounds from Fitness Levels Made Easy
Apr 07, 2021One of the first and easy to use techniques for proving run time bounds for evolutionary algorithms is the so-called method of fitness levels by Wegener. It uses a partition of the search space into a sequence of levels which are traversed by the algorithm in increasing order, possibly skipping levels. An easy, but often strong upper bound for the run time can then be derived by adding the reciprocals of the probabilities to leave the levels (or upper bounds for these). Unfortunately, a similarly effective method for proving lower bounds has not yet been established. The strongest such method, proposed by Sudholt (2013), requires a careful choice of the viscosity parameters $\gamma_{i,j}$, $0 \le i < j \le n$. In this paper we present two new variants of the method, one for upper and one for lower bounds. Besides the level leaving probabilities, they only rely on the probabilities that levels are visited at all. We show that these can be computed or estimated without greater difficulties and apply our method to reprove the following known results in an easy and natural way. (i) The precise run time of the \oea on \leadingones. (ii) A lower bound for the run time of the \oea on \onemax, tight apart from an $O(n)$ term. (iii) A lower bound for the run time of the \oea on long $k$-paths.
Allocating Indivisible Goods to Strategic Agents: Pure Nash Equilibria and Fairness
Sep 17, 2021We consider the problem of fairly allocating a set of indivisible goods to a set of strategic agents with additive valuation functions. We assume no monetary transfers and, therefore, a mechanism in our setting is an algorithm that takes as input the reported -- rather than the true -- values of the agents. Our main goal is to explore whether there exist mechanisms that have pure Nash equilibria for every instance and, at the same time, provide fairness guarantees for the allocations that correspond to these equilibria. We focus on two relaxations of envy-freeness, namely envy-freeness up to one good (EF1), and envy-freeness up to any good (EFX), and we positively answer the above question. In particular, we study two algorithms that are known to produce such allocations in the non-strategic setting: Round-Robin (EF1 allocations for any number of agents) and a cut-and-choose algorithm of Plaut and Roughgarden [SIAM Journal of Discrete Mathematics, 2020] (EFX allocations for two agents). For Round-Robin we show that all of its pure Nash equilibria induce allocations that are EF1 with respect to the underlying true values, while for the algorithm of Plaut and Roughgarden we show that the corresponding allocations not only are EFX but also satisfy maximin share fairness, something that is not true for this algorithm in the non-strategic setting! Further, we show that a weaker version of the latter result holds for any mechanism for two agents that always has pure Nash equilibria which all induce EFX allocations.
Output Randomization: A Novel Defense for both White-box and Black-box Adversarial Models
Jul 08, 2021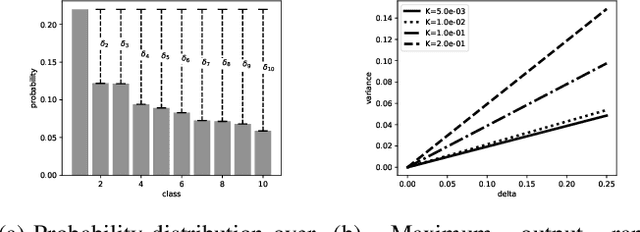
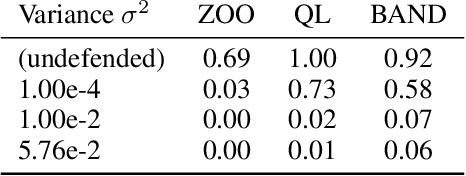
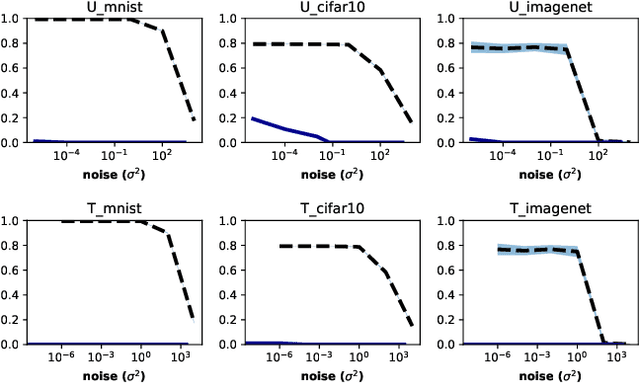
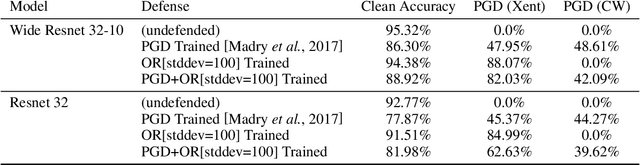
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model in a "white box" setting and to the opposite in a "black box" setting. In this paper, we explore the use of output randomization as a defense against attacks in both the black box and white box models and propose two defenses. In the first defense, we propose output randomization at test time to thwart finite difference attacks in black box settings. Since this type of attack relies on repeated queries to the model to estimate gradients, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. We empirically show that this defense can limit the success rate of a black box adversary using the Zeroth Order Optimization attack to 0%. Secondly, we propose output randomization training as a defense against white box adversaries. Unlike prior approaches that use randomization, our defense does not require its use at test time, eliminating the Backward Pass Differentiable Approximation attack, which was shown to be effective against other randomization defenses. Additionally, this defense has low overhead and is easily implemented, allowing it to be used together with other defenses across various model architectures. We evaluate output randomization training against the Projected Gradient Descent attacker and show that the defense can reduce the PGD attack's success rate down to 12% when using cross-entropy loss.