 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 11, 2021
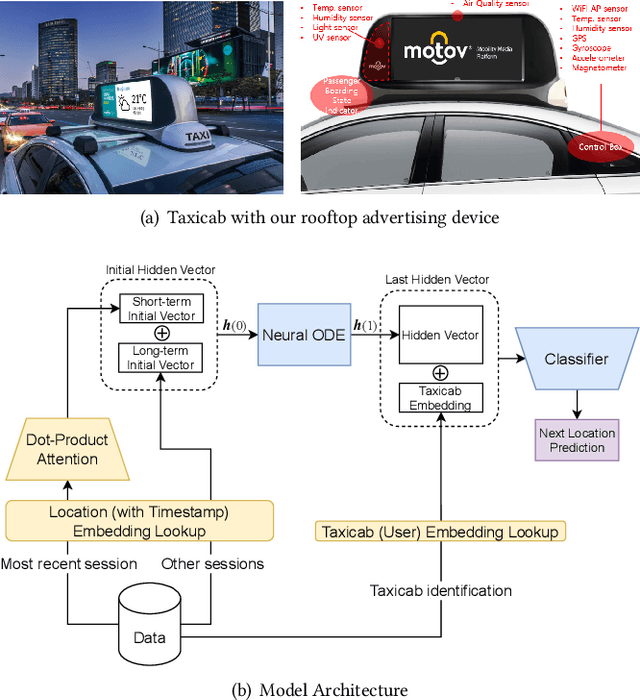

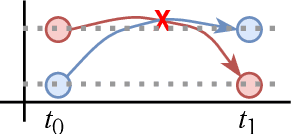
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
Simulating Execution Time of Tensor Programs using Graph Neural Networks
Apr 26, 2019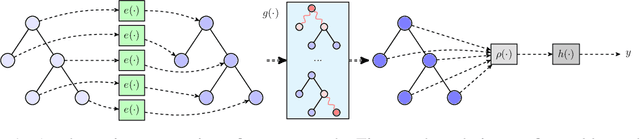
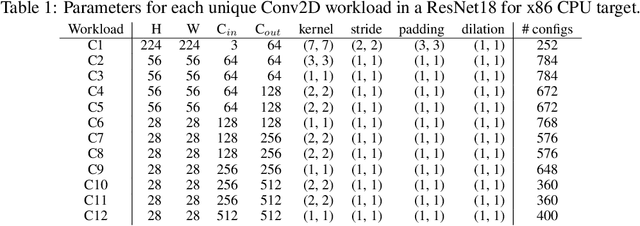
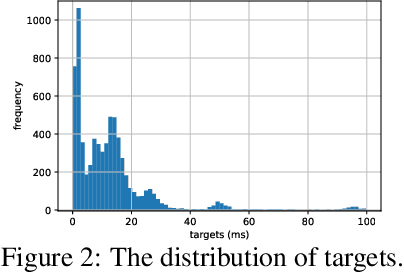
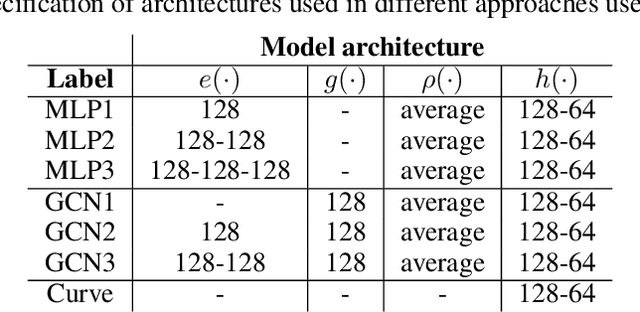
Optimizing the execution time of tensor program, e.g., a convolution, involves finding its optimal configuration. Searching the configuration space exhaustively is typically infeasible in practice. In line with recent research using TVM, we propose to learn a surrogate model to overcome this issue. The model is trained on an acyclic graph called an abstract syntax tree, and utilizes a graph convolutional network to exploit structure in the graph. We claim that a learnable graph-based data processing is a strong competitor to heuristic-based feature extraction. We present a new dataset of graphs corresponding to configurations and their execution time for various tensor programs. We provide baselines for a runtime prediction task.
Tracking Cells and their Lineages via Labeled Random Finite Sets
Apr 22, 2021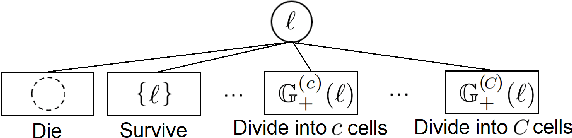
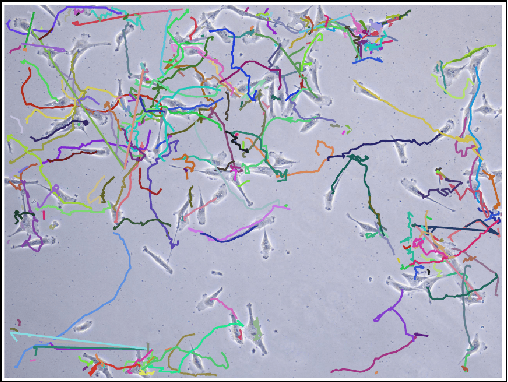
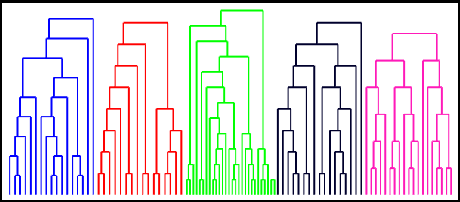
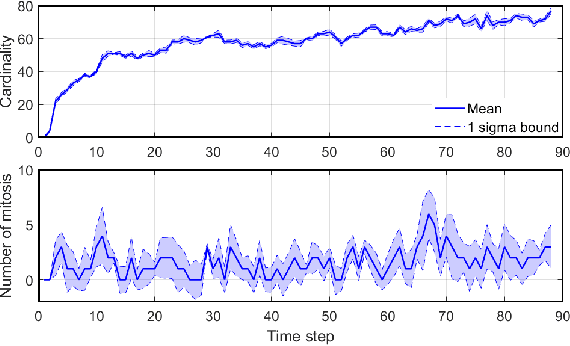
Determining the trajectories of cells and their lineages or ancestries in live-cell experiments are fundamental to the understanding of how cells behave and divide. This paper proposes novel online algorithms for jointly tracking and resolving lineages of an unknown and time-varying number of cells from time-lapse video data. Our approach involves modeling the cell ensemble as a labeled random finite set with labels representing cell identities and lineages. A spawning model is developed to take into account cell lineages and changes in cell appearance prior to division. We then derive analytic filters to propagate multi-object distributions that contain information on the current cell ensemble including their lineages. We also develop numerical implementations of the resulting multi-object filters. Experiments using simulation, synthetic cell migration video, and real time-lapse sequence, are presented to demonstrate the capability of the solutions.
Balancing the Budget: Feature Selection and Tracking for Multi-Camera Visual-Inertial Odometry
Sep 13, 2021
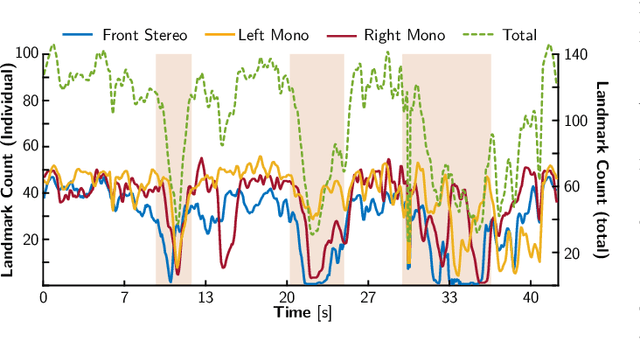
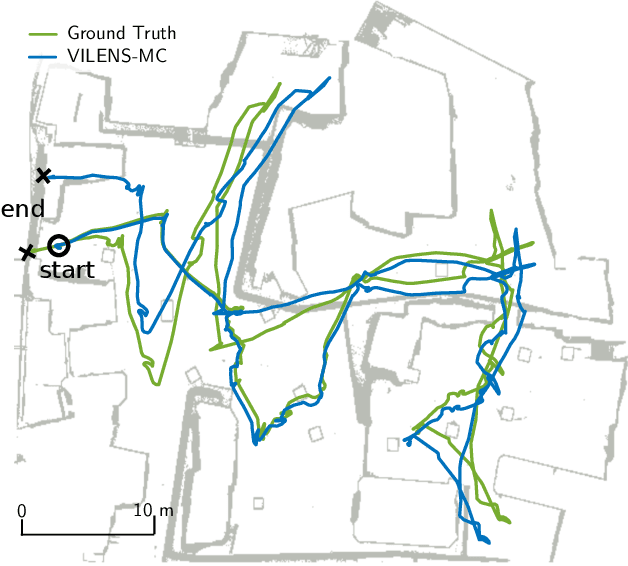
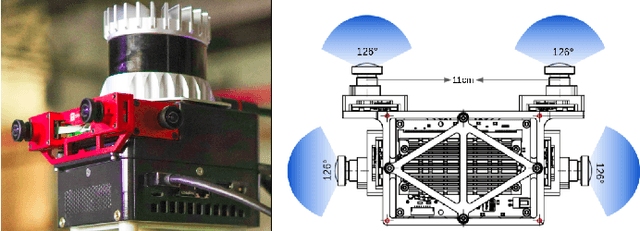
We present a multi-camera visual-inertial odometry system based on factor graph optimization which estimates motion by using all cameras simultaneously while retaining a fixed overall feature budget. We focus on motion tracking in challenging environments such as in narrow corridors and dark spaces with aggressive motions and abrupt lighting changes. These scenarios cause traditional monocular or stereo odometry to fail. While tracking motion across extra cameras should theoretically prevent failures, it causes additional complexity and computational burden. To overcome these challenges, we introduce two novel methods to improve multi-camera feature tracking. First, instead of tracking features separately in each camera, we track features continuously as they move from one camera to another. This increases accuracy and achieves a more compact factor graph representation. Second, we select a fixed budget of tracked features which are spread across the cameras to ensure that the limited computational budget is never exceeded. We have found that using a smaller set of informative features can maintain the same tracking accuracy while reducing back-end optimization time. Our proposed method was extensively tested using a hardware-synchronized device containing an IMU and four cameras (a front stereo pair and two lateral) in scenarios including an underground mine, large open spaces, and building interiors with narrow stairs and corridors. Compared to stereo-only state-of-the-art VIO methods, our approach reduces the drift rate (RPE) by up to 80% in translation and 39% in rotation.
Decision Making For Celebrity Branding: An Opinion Mining Approach Based On Polarity And Sentiment Analysis Using Twitter Consumer-Generated Content (CGC)
Sep 26, 2021

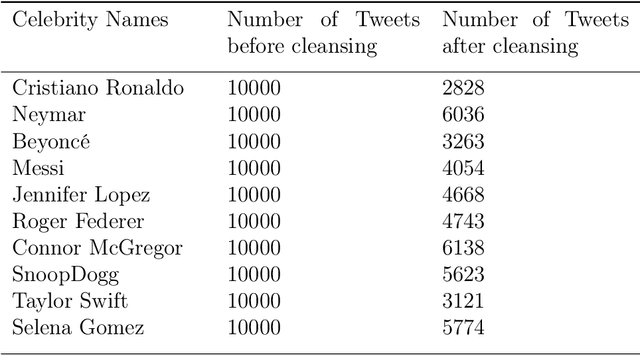
The volume of discussions concerning brands within social media provides digital marketers with great opportunities for tracking and analyzing the feelings and views of consumers toward brands, products, influencers, services, and ad campaigns in CGC. The present study aims to assess and compare the performance of firms and celebrities (i.e., influencers that with the experience of being in an ad campaign of those companies) with the automated sentiment analysis that was employed for CGC at social media while exploring the feeling of the consumers toward them to observe which influencer (of two for each company) had a closer effect with the corresponding corporation on consumer minds. For this purpose, several consumer tweets from the pages of brands and influencers were utilized to make a comparison of machine learning and lexicon-based approaches to the sentiment analysis through the Naive algorithm (lexicon-based) and Naive Bayes algorithm (machine learning method) and obtain the desired results to assess the campaigns. The findings suggested that the approaches were dissimilar in terms of accuracy; the machine learning method yielded higher accuracy. Finally, the results showed which influencer was more appropriate according to their existence in previous campaigns and helped choose the right influencer in the future for our company and have a better, more appropriate, and more efficient ad campaign subsequently. It is required to conduct further studies on the accuracy improvement of the sentiment classification. This approach should be employed for other social media CGC types. The results revealed decision-making for which sentiment analysis methods are the best approaches for the analysis of social media. It was also found that companies should be aware of their consumers' sentiments and choose the right person every time they think of a campaign.
About Explicit Variance Minimization: Training Neural Networks for Medical Imaging With Limited Data Annotations
Jun 03, 2021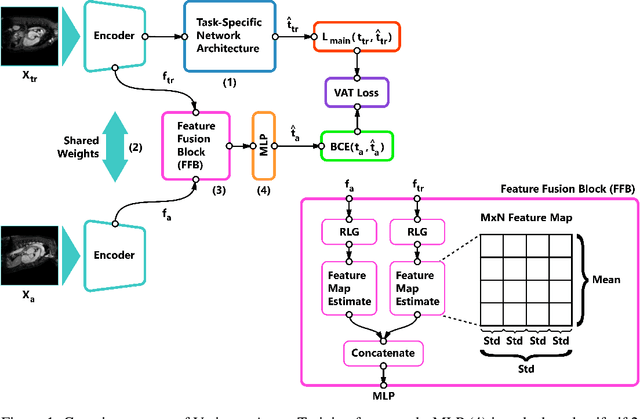
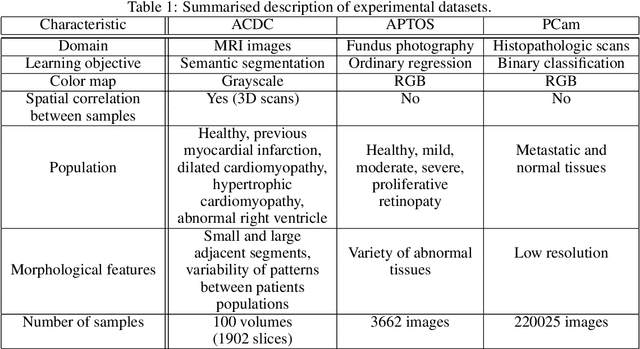
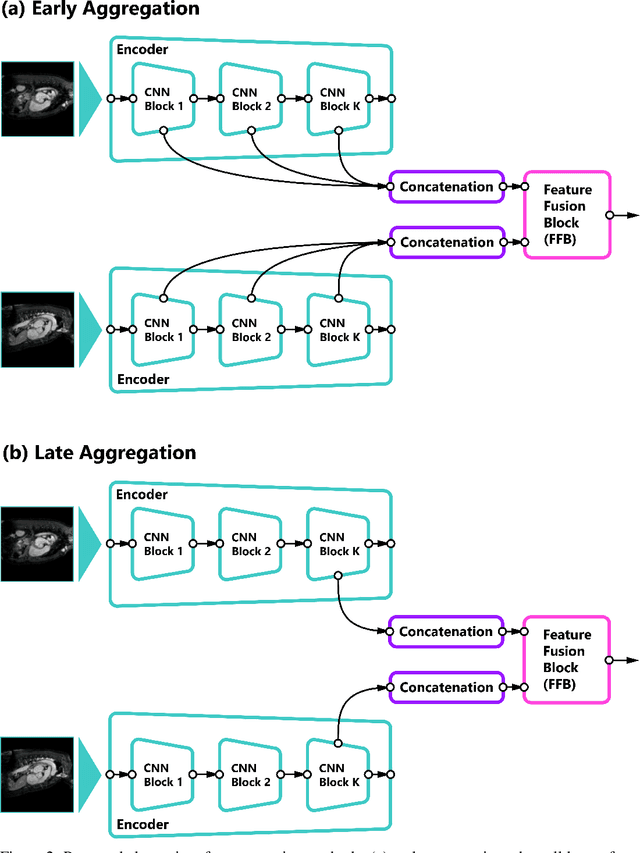
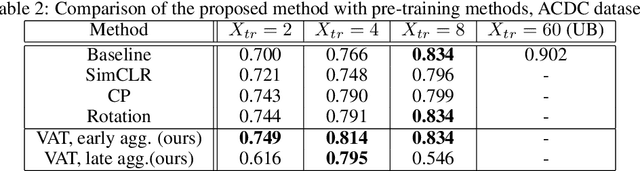
Self-supervised learning methods for computer vision have demonstrated the effectiveness of pre-training feature representations, resulting in well-generalizing Deep Neural Networks, even if the annotated data are limited. However, representation learning techniques require a significant amount of time for model training, with most of it time spent on precise hyper-parameter optimization and selection of augmentation techniques. We hypothesized that if the annotated dataset has enough morphological diversity to capture the general population's as is common in medical imaging, for example, due to conserved similarities of tissue mythologies, the variance error of the trained model is the prevalent component of the Bias-Variance Trade-off. We propose the Variance Aware Training (VAT) method that exploits this property by introducing the variance error into the model loss function, i.e., enabling minimizing the variance explicitly. Additionally, we provide the theoretical formulation and proof of the proposed method to aid in interpreting the approach. Our method requires selecting only one hyper-parameter and was able to match or improve the state-of-the-art performance of self-supervised methods while achieving an order of magnitude reduction in the GPU training time. We validated VAT on three medical imaging datasets from diverse domains and various learning objectives. These included a Magnetic Resonance Imaging (MRI) dataset for the heart semantic segmentation (MICCAI 2017 ACDC challenge), fundus photography dataset for ordinary regression of diabetic retinopathy progression (Kaggle 2019 APTOS Blindness Detection challenge), and classification of histopathologic scans of lymph node sections (PatchCamelyon dataset).
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 19, 2021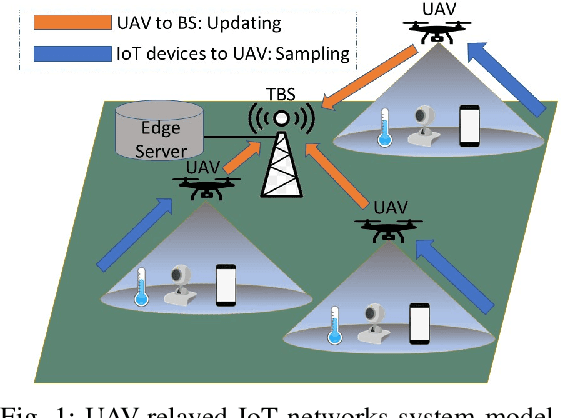
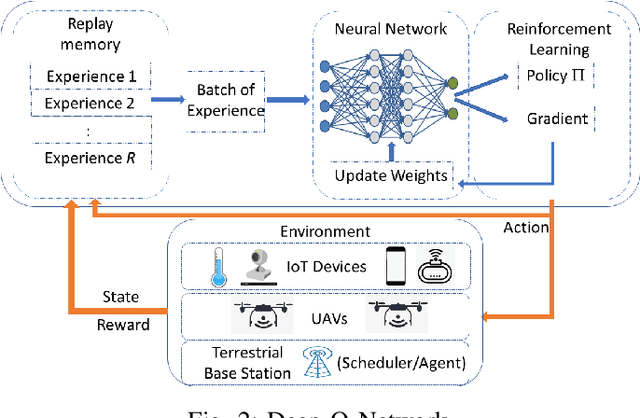
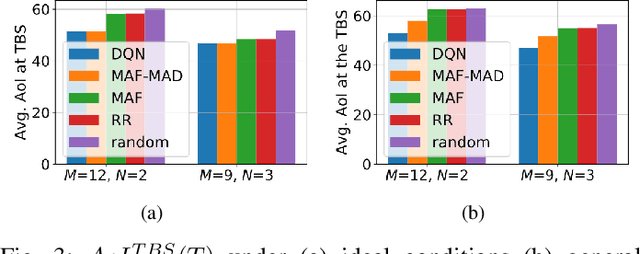
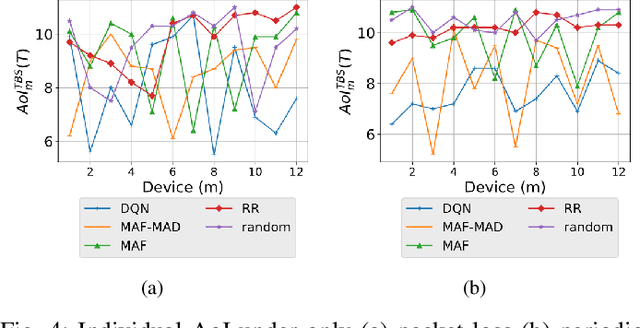
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.
FOX-NAS: Fast, On-device and Explainable Neural Architecture Search
Aug 14, 2021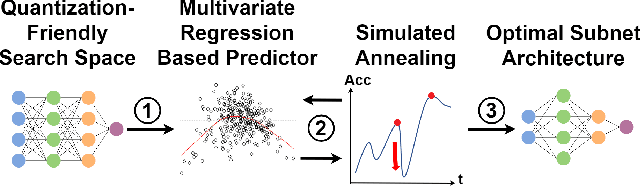
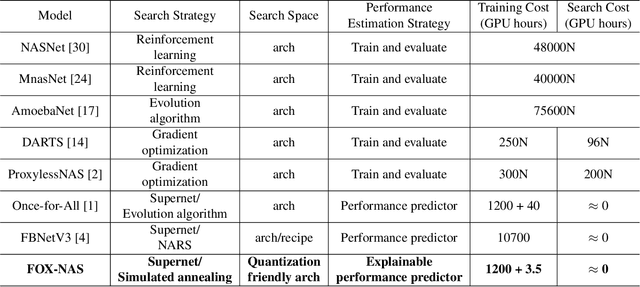
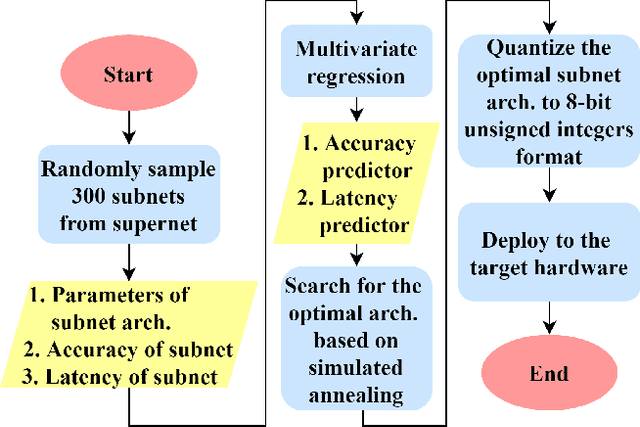
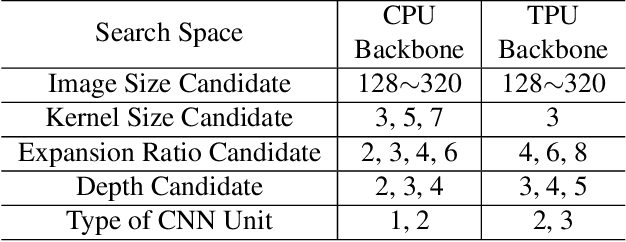
Neural architecture search can discover neural networks with good performance, and One-Shot approaches are prevalent. One-Shot approaches typically require a supernet with weight sharing and predictors that predict the performance of architecture. However, the previous methods take much time to generate performance predictors thus are inefficient. To this end, we propose FOX-NAS that consists of fast and explainable predictors based on simulated annealing and multivariate regression. Our method is quantization-friendly and can be efficiently deployed to the edge. The experiments on different hardware show that FOX-NAS models outperform some other popular neural network architectures. For example, FOX-NAS matches MobileNetV2 and EfficientNet-Lite0 accuracy with 240% and 40% less latency on the edge CPU. FOX-NAS is the 3rd place winner of the 2020 Low-Power Computer Vision Challenge (LPCVC), DSP classification track. See all evaluation results at https://lpcv.ai/competitions/2020. Search code and pre-trained models are released at https://github.com/great8nctu/FOX-NAS.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021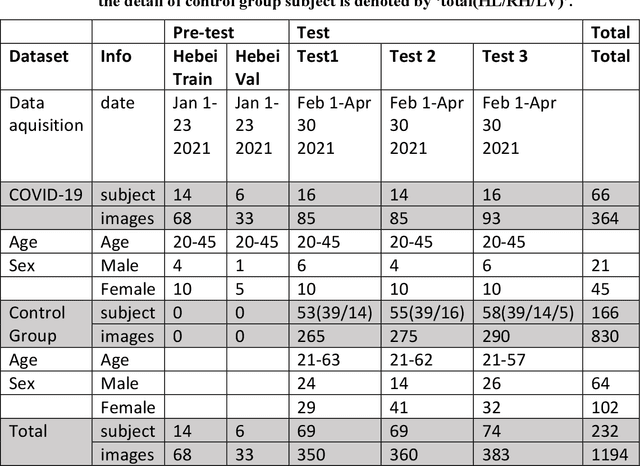

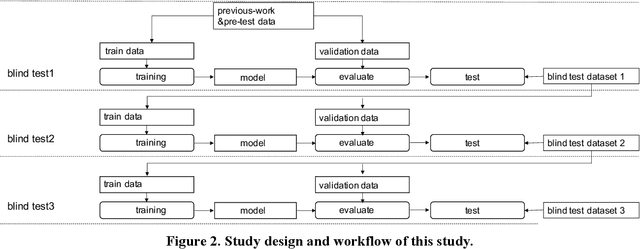
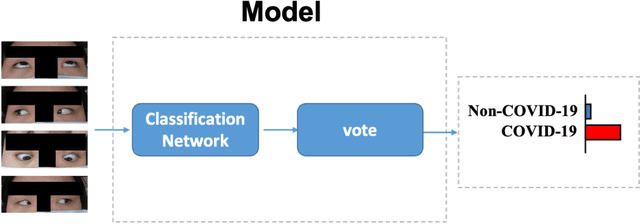
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent
A Novel 3D Non-Stationary GBSM for 6G THz Ultra-Massive MIMO Wireless Systems
Aug 14, 2021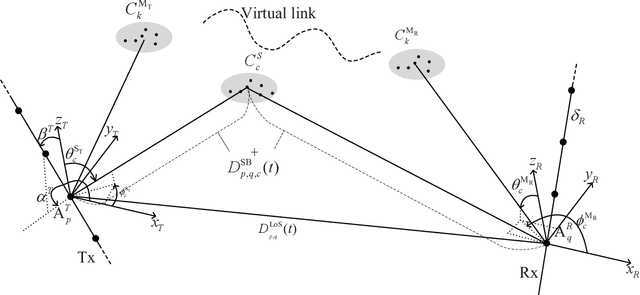
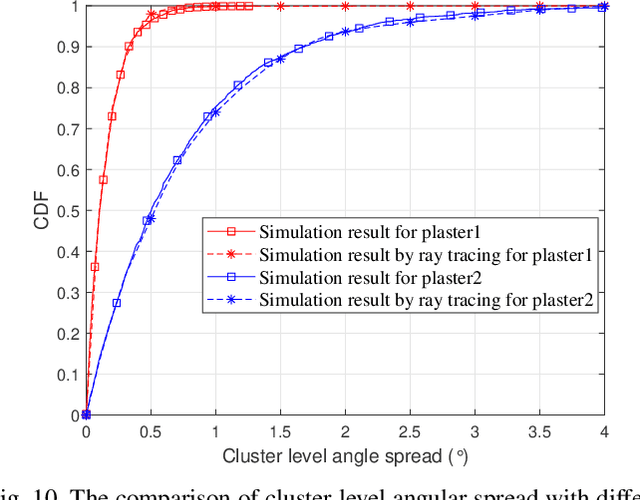
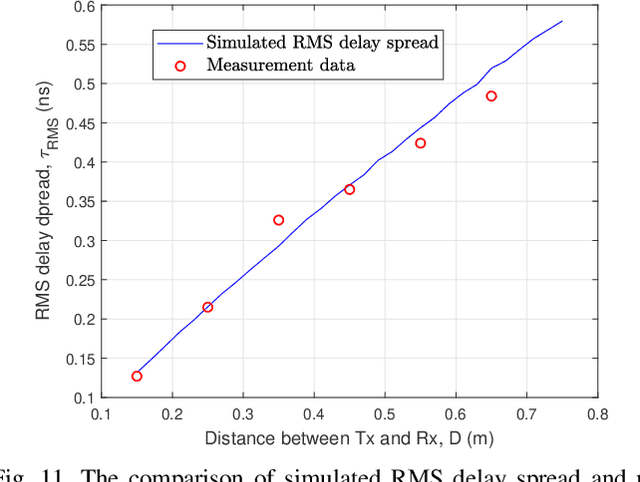

Terahertz (THz) communication is now being considered as one of possible technologies for the sixth generation (6G) wireless communication systems. In this paper, a novel three-dimensional (3D) space-time-frequency non-stationary theoretical channel model is first proposed for 6G THz wireless communication systems employing ultra-massive multiple-input multiple-output (MIMO) technologies with long traveling paths. Considering frequency-dependent diffuse scattering, which is a special property of THz channels different from millimeter wave (mmWave) channels, the relative angles and delays of rays within one cluster will evolve in the frequency domain. Then, a corresponding simulation model is proposed with discrete angles calculated using the method of equal area (MEA). The statistical properties of the proposed theoretical and simulation models are derived and compared, showing good agreements. The accuracy and flexibility of the proposed simulation model are demonstrated by comparing the simulation results of the relative angle spread and root mean square (RMS) delay spread with corresponding measurements.