 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021
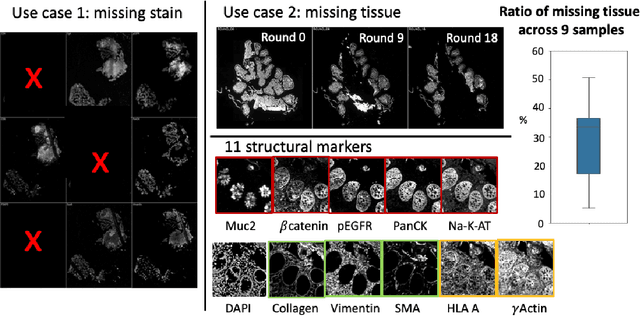
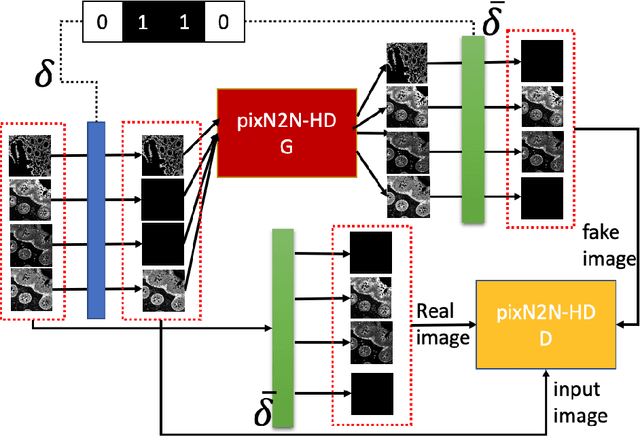
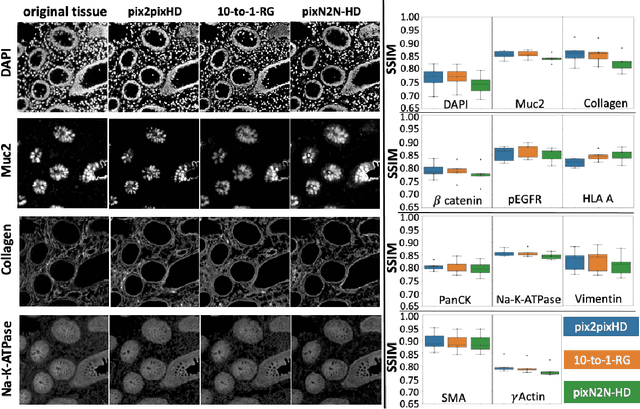
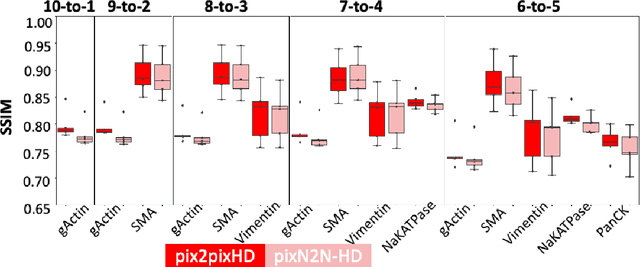
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.
First Order Methods take Exponential Time to Converge to Global Minimizers of Non-Convex Functions
Feb 28, 2020
Machine learning algorithms typically perform optimization over a class of non-convex functions. In this work, we provide bounds on the fundamental hardness of identifying the global minimizer of a non convex function. Specifically, we design a family of parametrized non-convex functions and employ statistical lower bounds for parameter estimation. We show that the parameter estimation problem is equivalent to the problem of function identification in the given family. We then claim that non convex optimization is at least as hard as function identification. Jointly, we prove that any first order method can take exponential time to converge to a global minimizer.
Dynamic Real-time Multimodal Routing with Hierarchical Hybrid Planning
Feb 05, 2019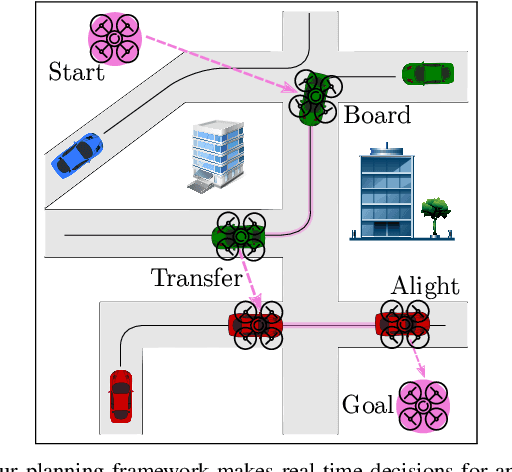
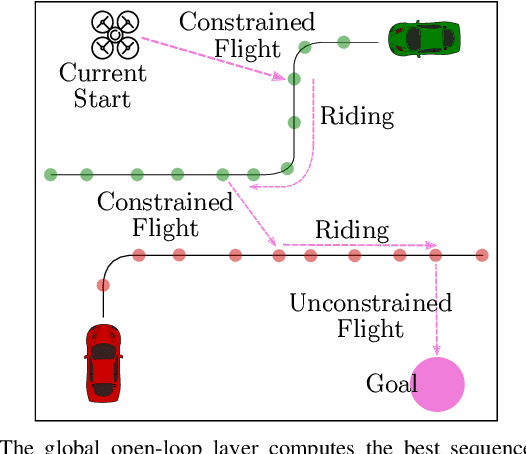
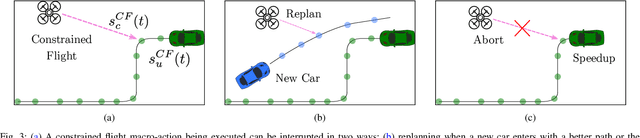
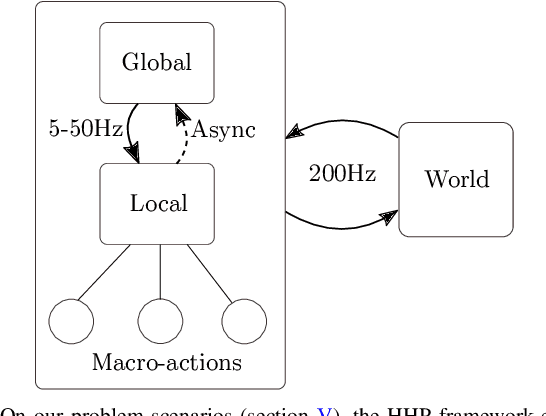
We introduce the problem of Dynamic Real-time Multimodal Routing (DREAMR), which requires planning and executing routes under uncertainty for an autonomous agent. The agent has access to a time-varying transit vehicle network in which it can use multiple modes of transportation. For instance, a drone can either fly or ride on terrain vehicles for segments of their routes. DREAMR is a difficult problem of sequential decision making under uncertainty with both discrete and continuous variables. We design a novel hierarchical hybrid planning framework to solve the DREAMR problem that exploits its structural decomposability. Our framework consists of a global open-loop planning layer that invokes and monitors a local closed-loop execution layer. Additional abstractions allow efficient and seamless interleaving of planning and execution. We create a large-scale simulation for DREAMR problems, with each scenario having hundreds of transportation routes and thousands of connection points. Our algorithmic framework significantly outperforms a receding horizon control baseline, in terms of elapsed time to reach the destination and energy expended by the agent.
Visual Representation Learning for Preference-Aware Path Planning
Sep 18, 2021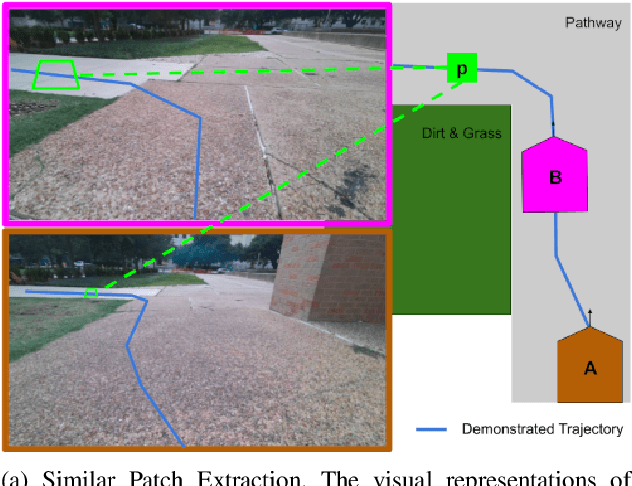

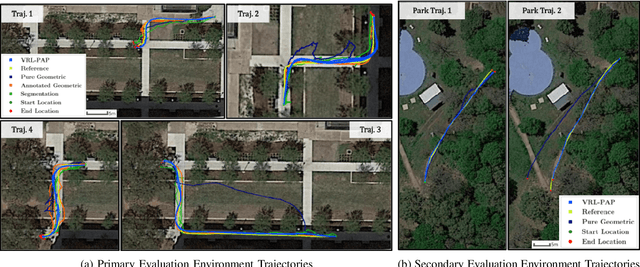
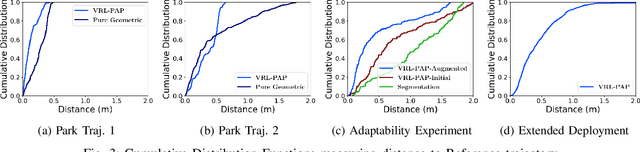
Autonomous mobile robots deployed in outdoor environments must reason about different types of terrain for both safety (e.g., prefer dirt over mud) and deployer preferences (e.g., prefer dirt path over flower beds). Most existing solutions to this preference-aware path planning problem use semantic segmentation to classify terrain types from camera images, and then ascribe costs to each type. Unfortunately, there are three key limitations of such approaches -- they 1) require pre-enumeration of the discrete terrain types, 2) are unable to handle hybrid terrain types (e.g., grassy dirt), and 3) require expensive labelled data to train visual semantic segmentation. We introduce Visual Representation Learning for Preference-Aware Path Planning (VRL-PAP), an alternative approach that overcomes all three limitations: VRL-PAP leverages unlabeled human demonstrations of navigation to autonomously generate triplets for learning visual representations of terrain that are viewpoint invariant and encode terrain types in a continuous representation space. The learned representations are then used along with the same unlabeled human navigation demonstrations to learn a mapping from the representation space to terrain costs. At run time, VRL-PAP maps from images to representations and then representations to costs to perform preference-aware path planning. We present empirical results from challenging outdoor settings that demonstrate VRL-PAP 1) is successfully able to pick paths that reflect demonstrated preferences, 2) is comparable in execution to geometric navigation with a highly detailed manually annotated map (without requiring such annotations), 3) is able to generalize to novel terrain types with minimal additional unlabeled demonstrations.
Weak Form Generalized Hamiltonian Learning
Apr 11, 2021
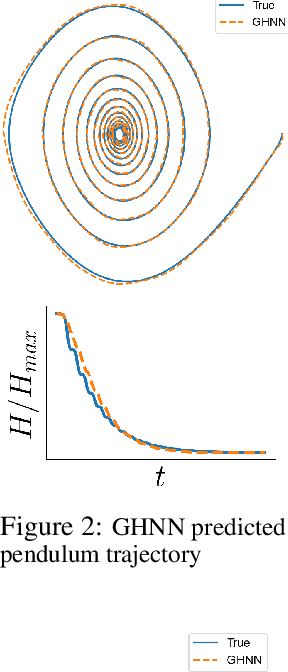


We present a method for learning generalized Hamiltonian decompositions of ordinary differential equations given a set of noisy time series measurements. Our method simultaneously learns a continuous time model and a scalar energy function for a general dynamical system. Learning predictive models in this form allows one to place strong, high-level, physics inspired priors onto the form of the learnt governing equations for general dynamical systems. Moreover, having shown how our method extends and unifies some previous work in deep learning with physics inspired priors, we present a novel method for learning continuous time models from the weak form of the governing equations which is less computationally taxing than standard adjoint methods.
* 34th Conference on Neural Information Processing Systems, 18 pages
luvHarris: A Practical Corner Detector for Event-cameras
May 24, 2021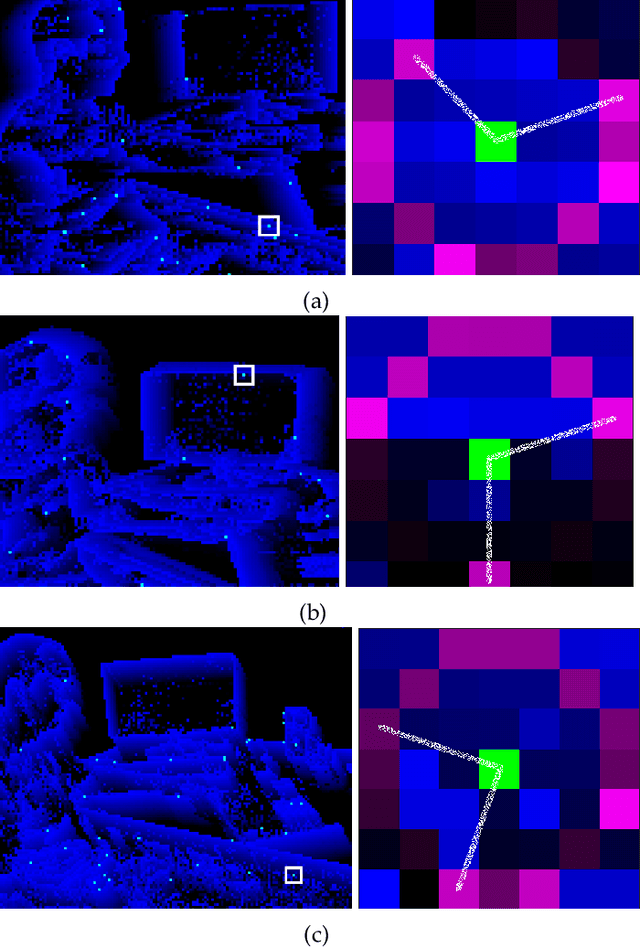
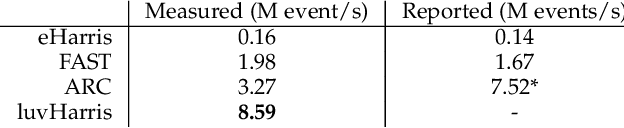
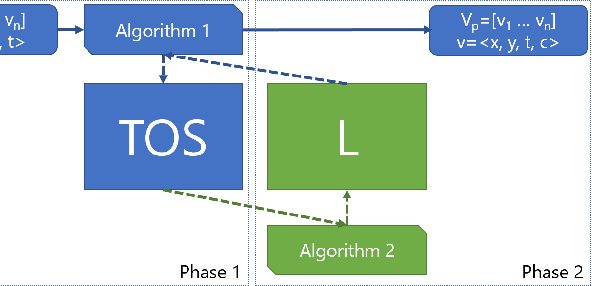

There have been a number of corner detection methods proposed for event cameras in the last years, since event-driven computer vision has become more accessible. Current state-of-the-art have either unsatisfactory accuracy or real-time performance when considered for practical use; random motion using a live camera in an unconstrained environment. In this paper, we present yet another method to perform corner detection, dubbed look-up event-Harris (luvHarris), that employs the Harris algorithm for high accuracy but manages an improved event throughput. Our method has two major contributions, 1. a novel "threshold ordinal event-surface" that removes certain tuning parameters and is well suited for Harris operations, and 2. an implementation of the Harris algorithm such that the computational load per-event is minimised and computational heavy convolutions are performed only 'as-fast-as-possible', i.e. only as computational resources are available. The result is a practical, real-time, and robust corner detector that runs more than $2.6\times$ the speed of current state-of-the-art; a necessity when using high-resolution event-camera in real-time. We explain the considerations taken for the approach, compare the algorithm to current state-of-the-art in terms of computational performance and detection accuracy, and discuss the validity of the proposed approach for event cameras.
Resistive Neural Hardware Accelerators
Sep 08, 2021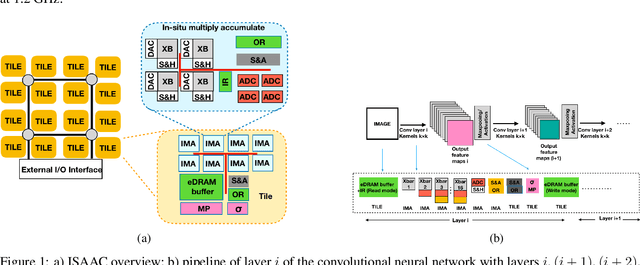
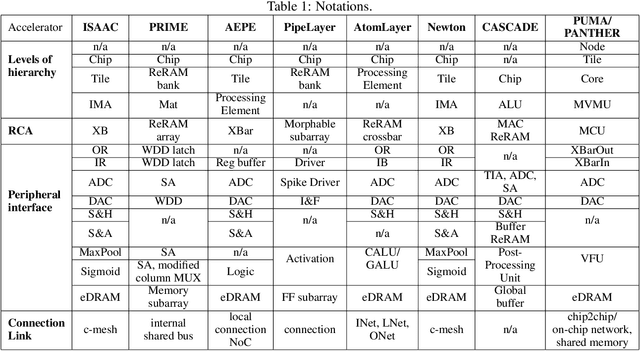
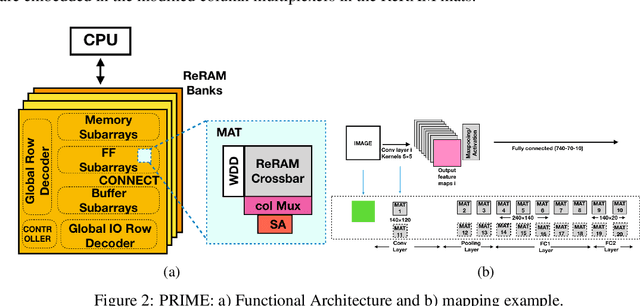
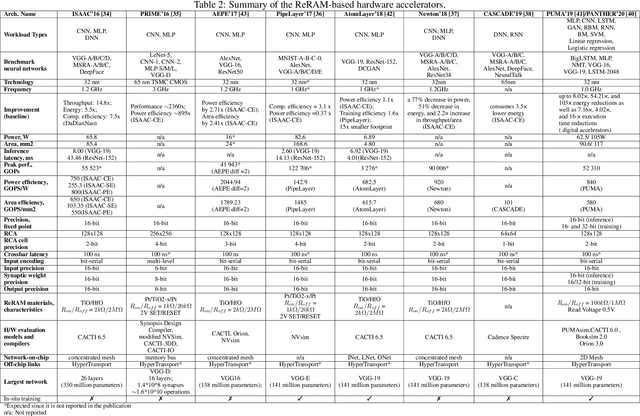
Deep Neural Networks (DNNs), as a subset of Machine Learning (ML) techniques, entail that real-world data can be learned and that decisions can be made in real-time. However, their wide adoption is hindered by a number of software and hardware limitations. The existing general-purpose hardware platforms used to accelerate DNNs are facing new challenges associated with the growing amount of data and are exponentially increasing the complexity of computations. An emerging non-volatile memory (NVM) devices and processing-in-memory (PIM) paradigm is creating a new hardware architecture generation with increased computing and storage capabilities. In particular, the shift towards ReRAM-based in-memory computing has great potential in the implementation of area and power efficient inference and in training large-scale neural network architectures. These can accelerate the process of the IoT-enabled AI technologies entering our daily life. In this survey, we review the state-of-the-art ReRAM-based DNN many-core accelerators, and their superiority compared to CMOS counterparts was shown. The review covers different aspects of hardware and software realization of DNN accelerators, their present limitations, and future prospectives. In particular, comparison of the accelerators shows the need for the introduction of new performance metrics and benchmarking standards. In addition, the major concerns regarding the efficient design of accelerators include a lack of accuracy in simulation tools for software and hardware co-design.
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
May 03, 2021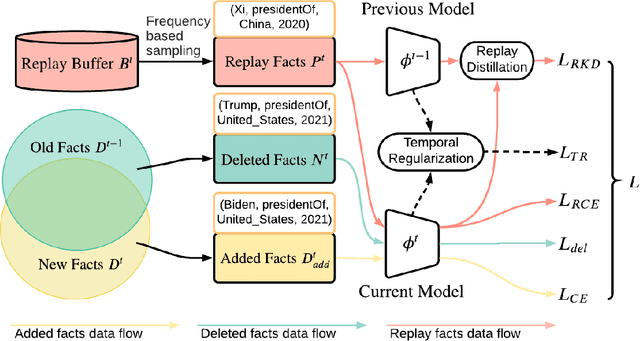

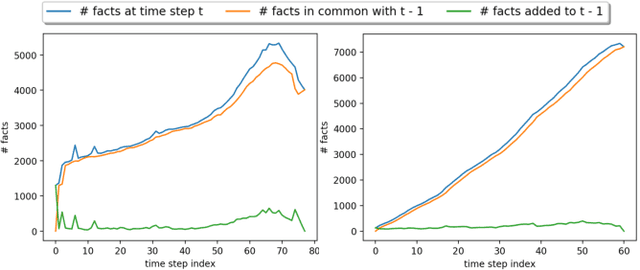
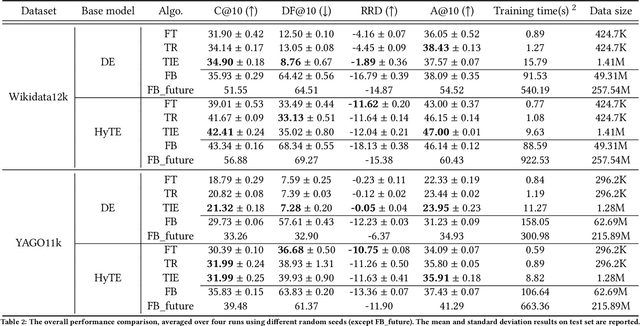
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
Quantum diffusion map for nonlinear dimensionality reduction
Jun 14, 2021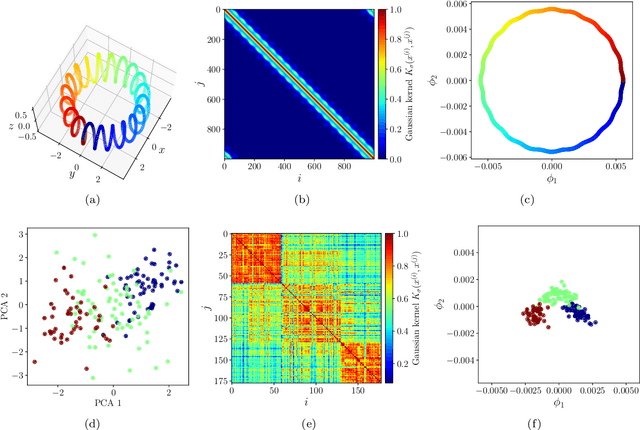
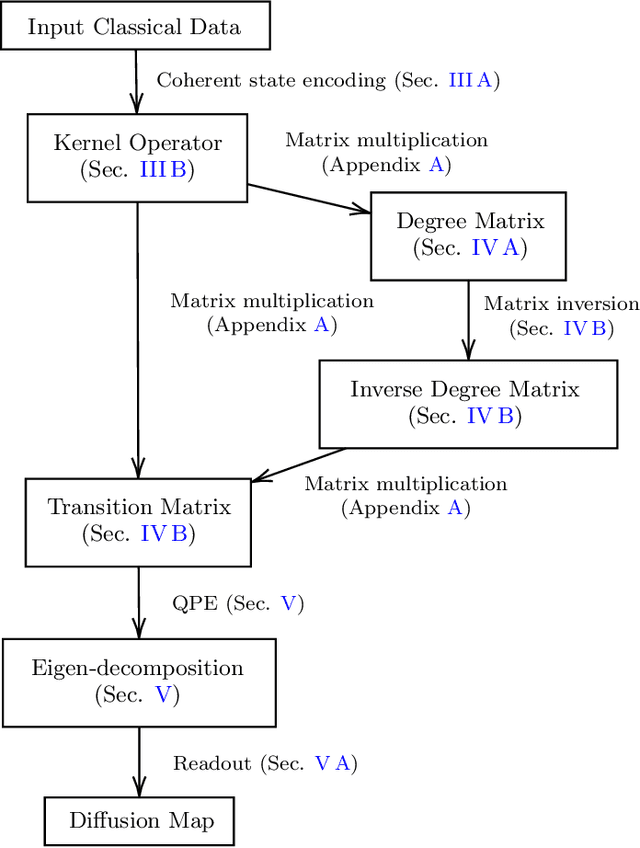
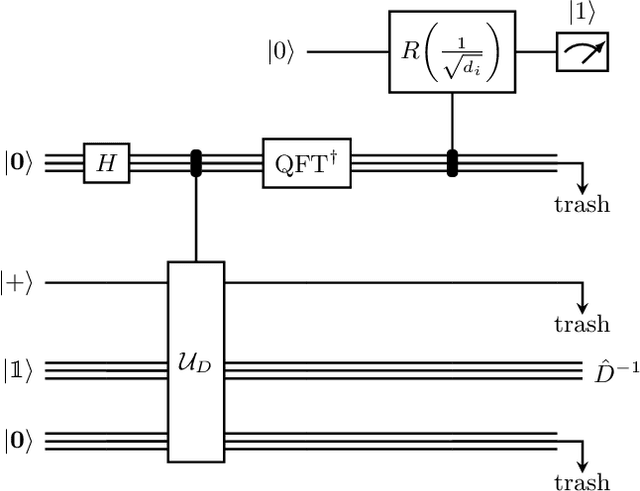
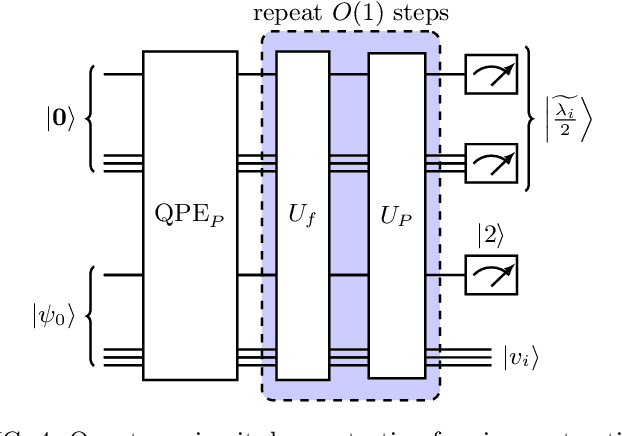
Inspired by random walk on graphs, diffusion map (DM) is a class of unsupervised machine learning that offers automatic identification of low-dimensional data structure hidden in a high-dimensional dataset. In recent years, among its many applications, DM has been successfully applied to discover relevant order parameters in many-body systems, enabling automatic classification of quantum phases of matter. However, classical DM algorithm is computationally prohibitive for a large dataset, and any reduction of the time complexity would be desirable. With a quantum computational speedup in mind, we propose a quantum algorithm for DM, termed quantum diffusion map (qDM). Our qDM takes as an input N classical data vectors, performs an eigen-decomposition of the Markov transition matrix in time $O(\log^3 N)$, and classically constructs the diffusion map via the readout (tomography) of the eigenvectors, giving a total runtime of $O(N^2 \text{polylog}\, N)$. Lastly, quantum subroutines in qDM for constructing a Markov transition operator, and for analyzing its spectral properties can also be useful for other random walk-based algorithms.
Detection of data drift and outliers affecting machine learning model performance over time
Jan 20, 2021

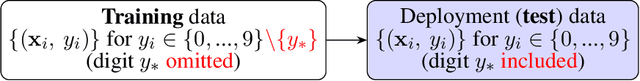
A trained ML model is deployed on another `test' dataset where target feature values (labels) are unknown. Drift is distribution change between the training and deployment data, which is concerning if model performance changes. For a cat/dog image classifier, for instance, drift during deployment could be rabbit images (new class) or cat/dog images with changed characteristics (change in distribution). We wish to detect these changes but can't measure accuracy without deployment data labels. We instead detect drift indirectly by nonparametrically testing the distribution of model prediction confidence for changes. This generalizes our method and sidesteps domain-specific feature representation. We address important statistical issues, particularly Type-1 error control in sequential testing, using Change Point Models (CPMs; see Adams and Ross 2012). We also use nonparametric outlier methods to show the user suspicious observations for model diagnosis, since the before/after change confidence distributions overlap significantly. In experiments to demonstrate robustness, we train on a subset of MNIST digit classes, then insert drift (e.g., unseen digit class) in deployment data in various settings (gradual/sudden changes in the drift proportion). A novel loss function is introduced to compare the performance (detection delay, Type-1 and 2 errors) of a drift detector under different levels of drift class contamination.