 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robotic Lime Picking by Considering Leaves as Permeable Obstacles
Aug 31, 2021

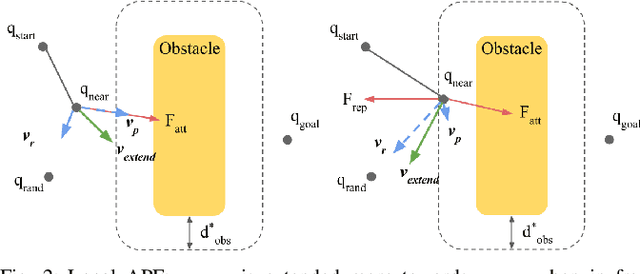
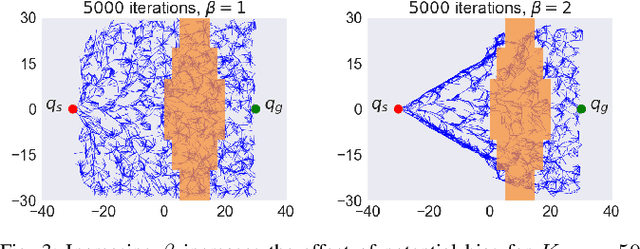
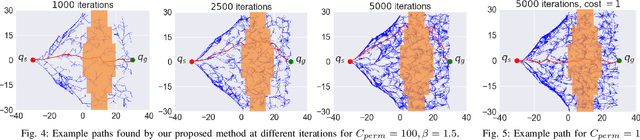
The problem of robotic lime picking is challenging; lime plants have dense foliage which makes it difficult for a robotic arm to grasp a lime without coming in contact with leaves. Existing approaches either do not consider leaves, or treat them as obstacles and completely avoid them, often resulting in undesirable or infeasible plans. We focus on reaching a lime in the presence of dense foliage by considering the leaves of a plant as 'permeable obstacles' with a collision cost. We then adapt the rapidly exploring random tree star (RRT*) algorithm for the problem of fruit harvesting by incorporating the cost of collision with leaves into the path cost. To reduce the time required for finding low-cost paths to goal, we bias the growth of the tree using an artificial potential field (APF). We compare our proposed method with prior work in a 2-D environment and a 6-DOF robot simulation. Our experiments and a real-world demonstration on a robotic lime picking task demonstrate the applicability of our approach.
Layer Pruning on Demand with Intermediate CTC
Jun 17, 2021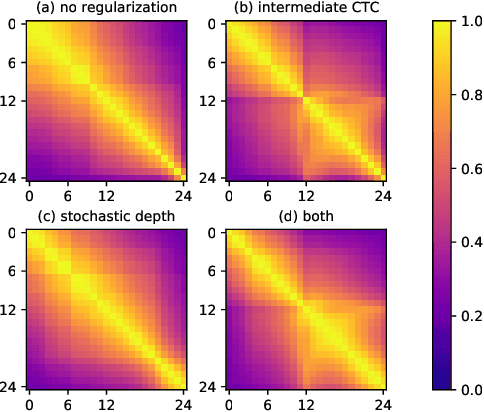
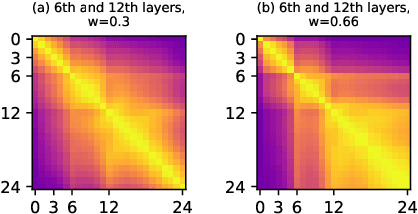
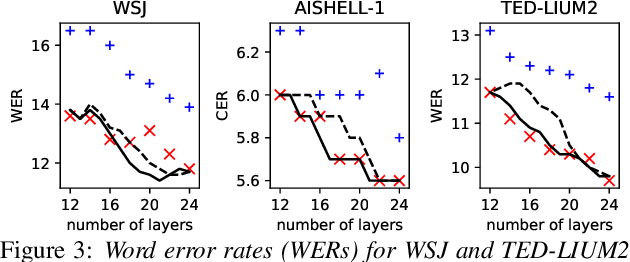
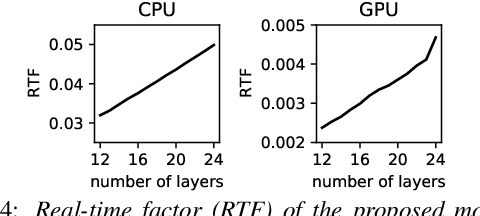
Deploying an end-to-end automatic speech recognition (ASR) model on mobile/embedded devices is a challenging task, since the device computational power and energy consumption requirements are dynamically changed in practice. To overcome the issue, we present a training and pruning method for ASR based on the connectionist temporal classification (CTC) which allows reduction of model depth at run-time without any extra fine-tuning. To achieve the goal, we adopt two regularization methods, intermediate CTC and stochastic depth, to train a model whose performance does not degrade much after pruning. We present an in-depth analysis of layer behaviors using singular vector canonical correlation analysis (SVCCA), and efficient strategies for finding layers which are safe to prune. Using the proposed method, we show that a Transformer-CTC model can be pruned in various depth on demand, improving real-time factor from 0.005 to 0.002 on GPU, while each pruned sub-model maintains the accuracy of individually trained model of the same depth.
Time-aware Gradient Attack on Dynamic Network Link Prediction
Nov 24, 2019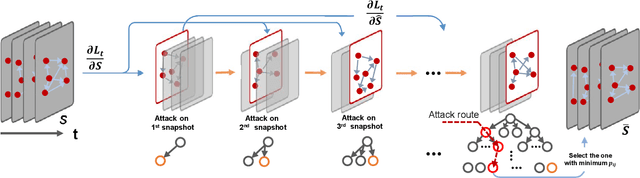

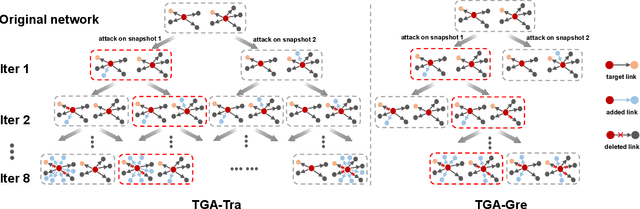
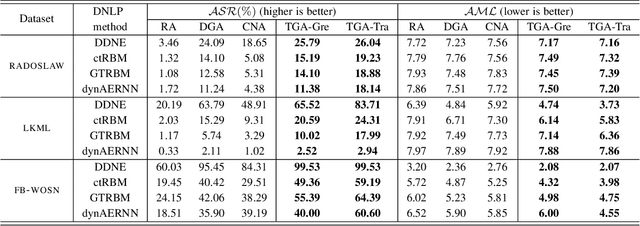
In network link prediction, it is possible to hide a target link from being predicted with a small perturbation on network structure. This observation may be exploited in many real world scenarios, for example, to preserve privacy, or to exploit financial security. There have been many recent studies to generate adversarial examples to mislead deep learning models on graph data. However, none of the previous work has considered the dynamic nature of real-world systems. In this work, we present the first study of adversarial attack on dynamic network link prediction (DNLP). The proposed attack method, namely time-aware gradient attack (TGA), utilizes the gradient information generated by deep dynamic network embedding (DDNE) across different snapshots to rewire a few links, so as to make DDNE fail to predict target links. We implement TGA in two ways: one is based on traversal search, namely TGA-Tra; and the other is simplified with greedy search for efficiency, namely TGA-Gre. We conduct comprehensive experiments which show the outstanding performance of TGA in attacking DNLP algorithms.
Metric Entropy Limits on Recurrent Neural Network Learning of Linear Dynamical Systems
May 06, 2021One of the most influential results in neural network theory is the universal approximation theorem [1, 2, 3] which states that continuous functions can be approximated to within arbitrary accuracy by single-hidden-layer feedforward neural networks. The purpose of this paper is to establish a result in this spirit for the approximation of general discrete-time linear dynamical systems - including time-varying systems - by recurrent neural networks (RNNs). For the subclass of linear time-invariant (LTI) systems, we devise a quantitative version of this statement. Specifically, measuring the complexity of the considered class of LTI systems through metric entropy according to [4], we show that RNNs can optimally learn - or identify in system-theory parlance - stable LTI systems. For LTI systems whose input-output relation is characterized through a difference equation, this means that RNNs can learn the difference equation from input-output traces in a metric-entropy optimal manner.
DEMix Layers: Disentangling Domains for Modular Language Modeling
Aug 20, 2021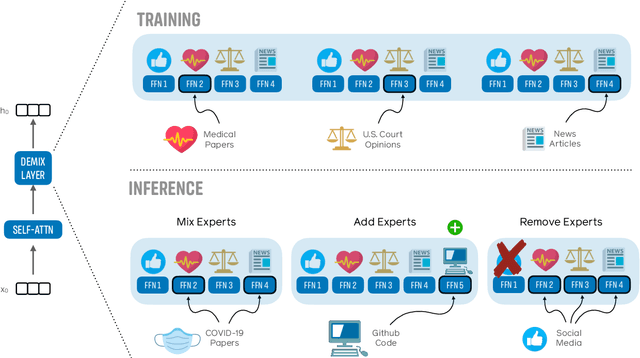
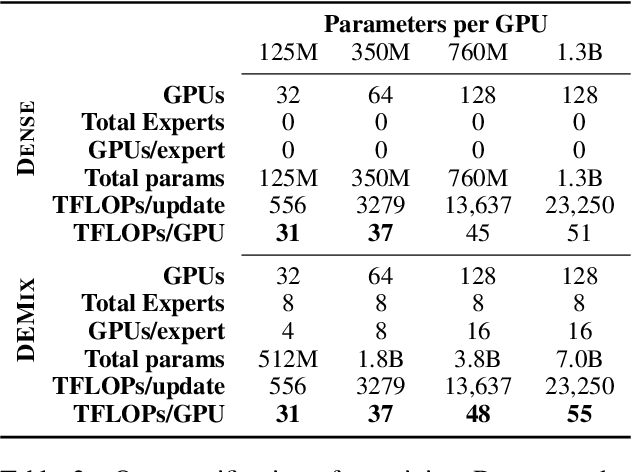
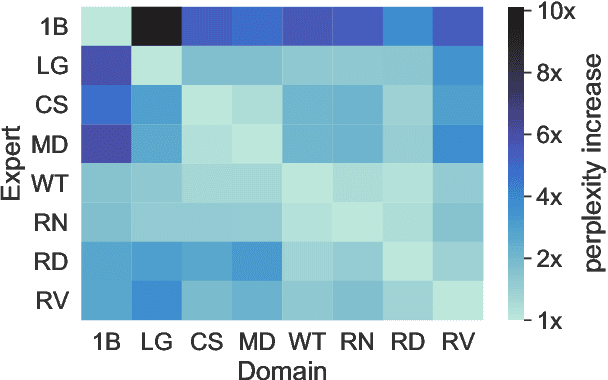
We introduce a new domain expert mixture (DEMix) layer that enables conditioning a language model (LM) on the domain of the input text. A DEMix layer is a collection of expert feedforward networks, each specialized to a domain, that makes the LM modular: experts can be mixed, added or removed after initial training. Extensive experiments with autoregressive transformer LMs (up to 1.3B parameters) show that DEMix layers reduce test-time perplexity, increase training efficiency, and enable rapid adaptation with little overhead. We show that mixing experts during inference, using a parameter-free weighted ensemble, allows the model to better generalize to heterogeneous or unseen domains. We also show that experts can be added to iteratively incorporate new domains without forgetting older ones, and that experts can be removed to restrict access to unwanted domains, without additional training. Overall, these results demonstrate benefits of explicitly conditioning on textual domains during language modeling.
Proposing a System Level Machine Learning Hybrid Architecture and Approach for a Comprehensive Autism Spectrum Disorder Diagnosis
Sep 18, 2021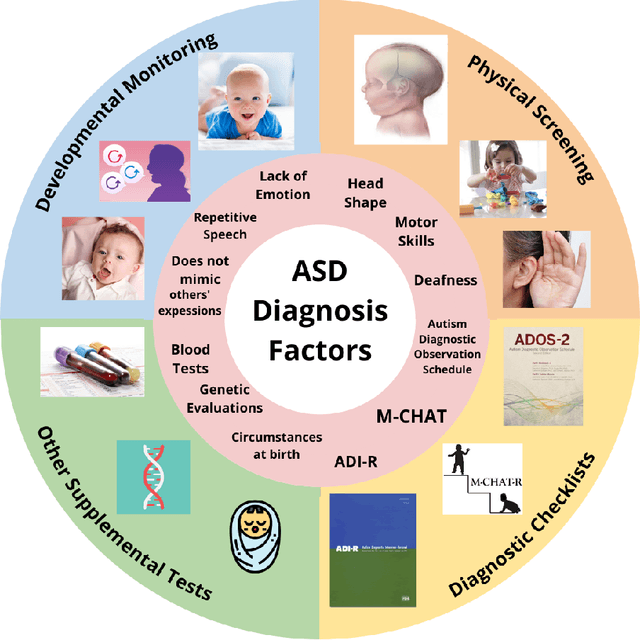
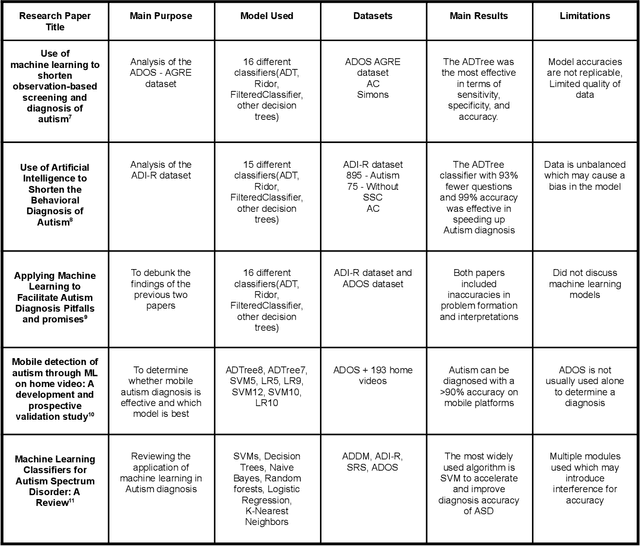
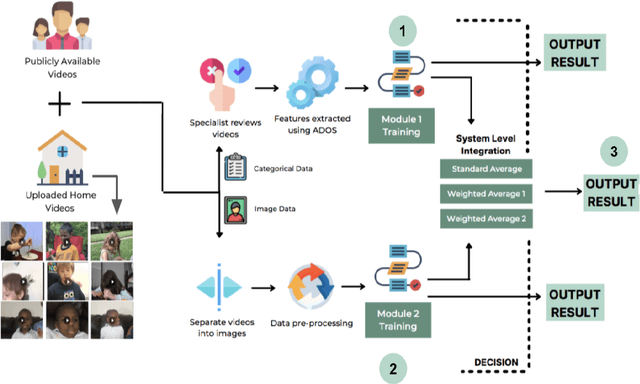
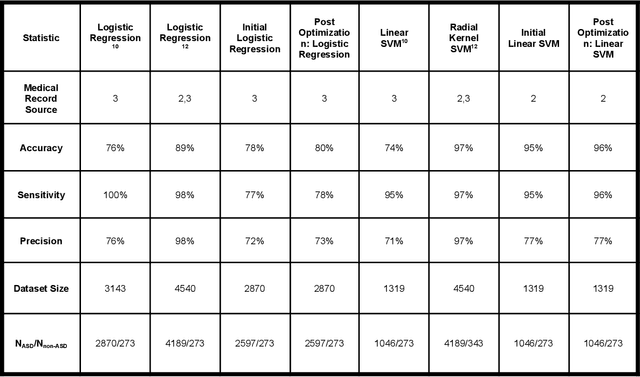
Autism Spectrum Disorder (ASD) is a severe neuropsychiatric disorder that affects intellectual development, social behavior, and facial features, and the number of cases is still significantly increasing. Due to the variety of symptoms ASD displays, the diagnosis process remains challenging, with numerous misdiagnoses as well as lengthy and expensive diagnoses. Fortunately, if ASD is diagnosed and treated early, then the patient will have a much higher chance of developing normally. For an ASD diagnosis, machine learning algorithms can analyze both social behavior and facial features accurately and efficiently, providing an ASD diagnosis in a drastically shorter amount of time than through current clinical diagnosis processes. Therefore, we propose to develop a hybrid architecture fully utilizing both social behavior and facial feature data to improve the accuracy of diagnosing ASD. We first developed a Linear Support Vector Machine for the social behavior based module, which analyzes Autism Diagnostic Observation Schedule (ADOS) social behavior data. For the facial feature based module, a DenseNet model was utilized to analyze facial feature image data. Finally, we implemented our hybrid model by incorporating different features of the Support Vector Machine and the DenseNet into one model. Our results show that the highest accuracy of 87% for ASD diagnosis has been achieved by our proposed hybrid model. The pros and cons of each module will be discussed in this paper.
Scorpiano -- A System for Automatic Music Transcription for Monophonic Piano Music
Aug 24, 2021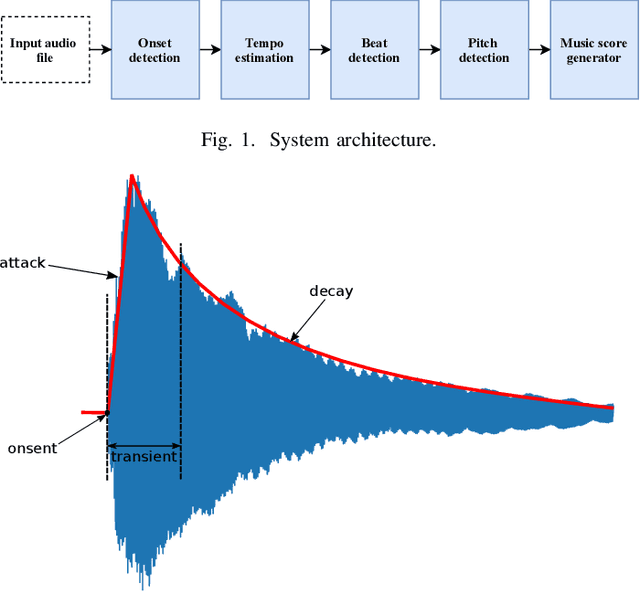
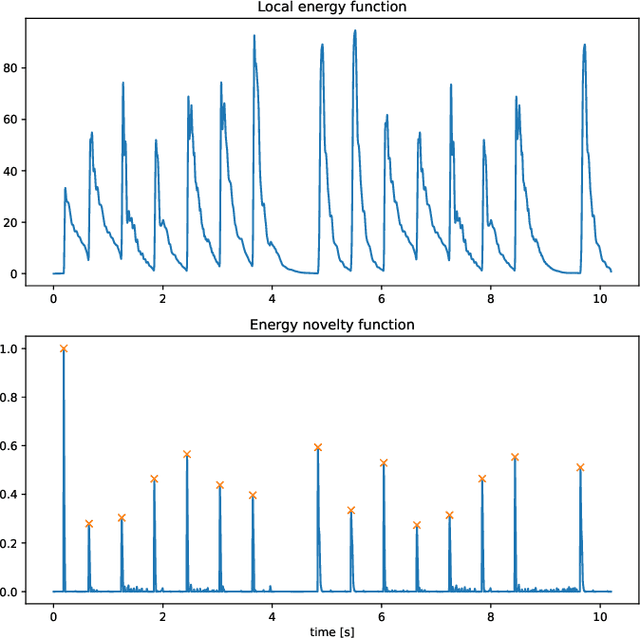
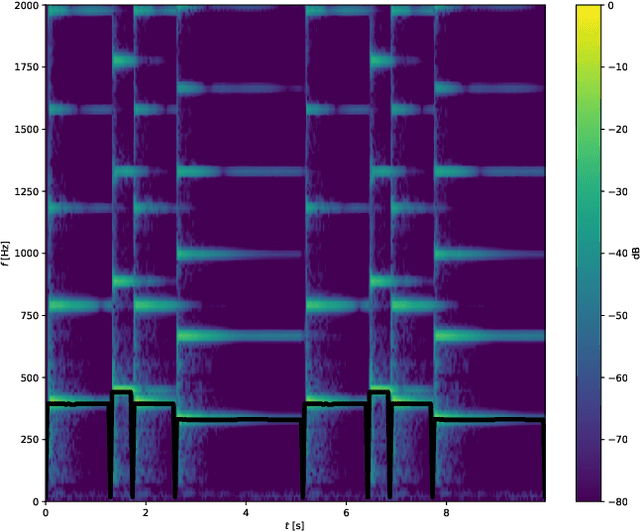

Music transcription is the process of transcribing music audio into music notation. It is a field in which the machines still cannot beat human performance. The main motivation for automatic music transcription is to make it possible for anyone playing a musical instrument, to be able to generate the music notes for a piece of music quickly and accurately. It does not matter if the person is a beginner and simply struggles to find the music score by searching, or an expert who heard a live jazz improvisation and would like to reproduce it without losing time doing manual transcription. We propose Scorpiano -- a system that can automatically generate a music score for simple monophonic piano melody tracks using digital signal processing. The system integrates multiple digital audio processing methods: notes onset detection, tempo estimation, beat detection, pitch detection and finally generation of the music score. The system has proven to give good results for simple piano melodies, comparable to commercially available neural network based systems.
An Optimization-Based Meta-Learning Model for MRI Reconstruction with Diverse Dataset
Oct 02, 2021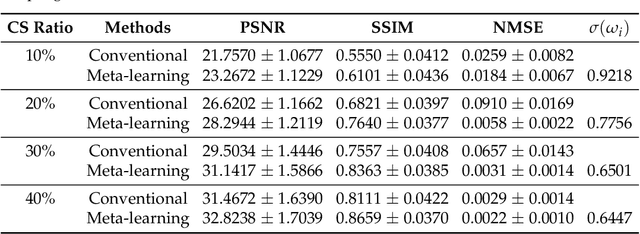
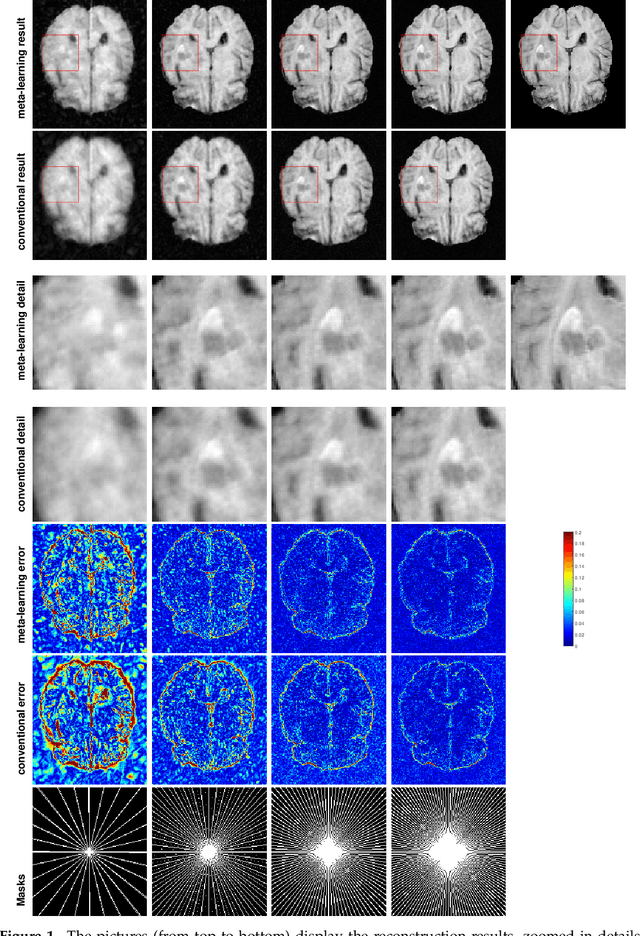
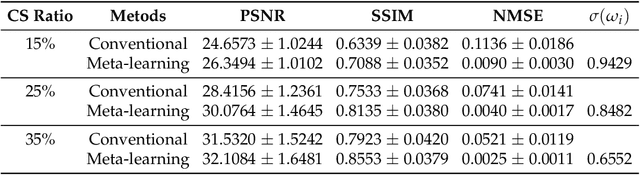
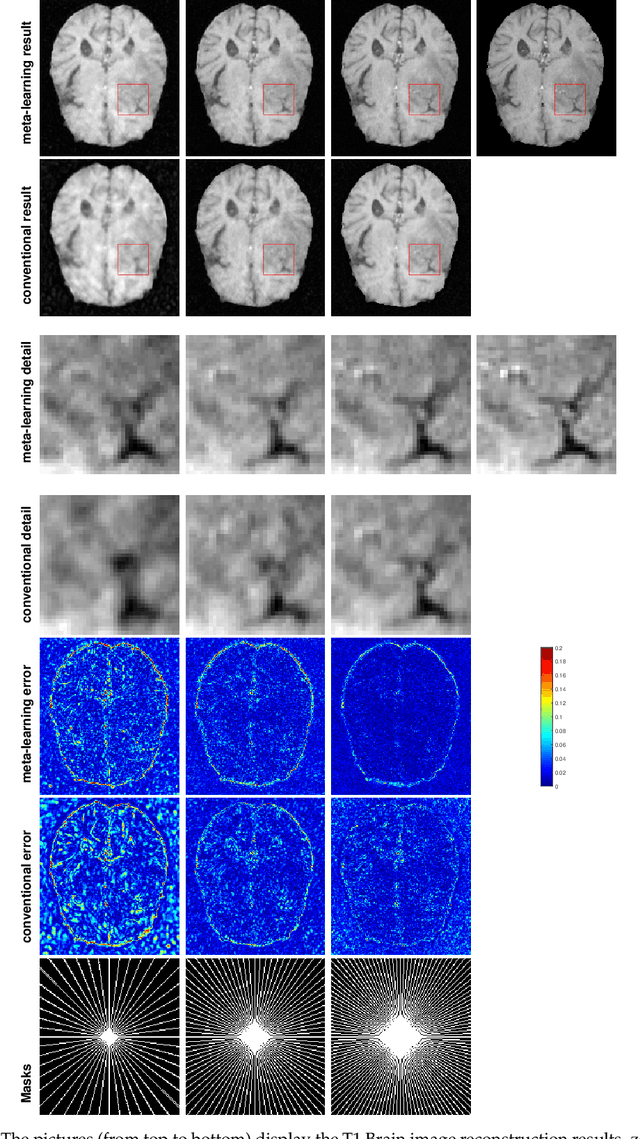
Purpose: This work aims at developing a generalizable MRI reconstruction model in the meta-learning framework. The standard benchmarks in meta-learning are challenged by learning on diverse task distributions. The proposed network learns the regularization function in a variational model and reconstructs MR images with various under-sampling ratios or patterns that may or may not be seen in the training data by leveraging a heterogeneous dataset. Methods: We propose an unrolling network induced by learnable optimization algorithms (LOA) for solving our nonconvex nonsmooth variational model for MRI reconstruction. In this model, the learnable regularization function contains a task-invariant common feature encoder and task-specific learner represented by a shallow network. To train the network we split the training data into two parts: training and validation, and introduce a bilevel optimization algorithm. The lower-level optimization trains task-invariant parameters for the feature encoder with fixed parameters of the task-specific learner on the training dataset, and the upper-level optimizes the parameters of the task-specific learner on the validation dataset. Results: The average PSNR increases significantly compared to the network trained through conventional supervised learning on the seen CS ratios. We test the result of quick adaption on the unseen tasks after meta-training and in the meanwhile saving half of the training time; Conclusion: We proposed a meta-learning framework consisting of the base network architecture, design of regularization, and bi-level optimization-based training. The network inherits the convergence property of the LOA and interpretation of the variational model. The generalization ability is improved by the designated regularization and bilevel optimization-based training algorithm.
PQ-Transformer: Jointly Parsing 3D Objects and Layouts from Point Clouds
Sep 12, 2021
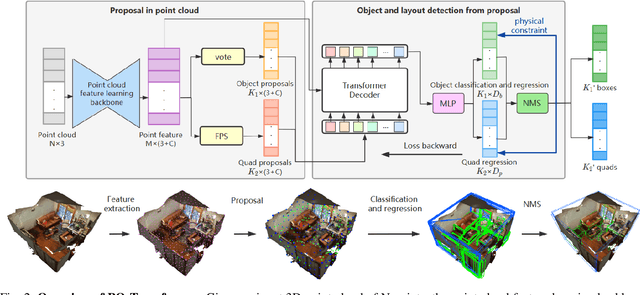
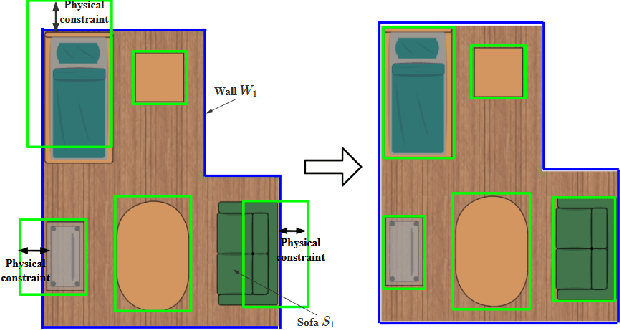
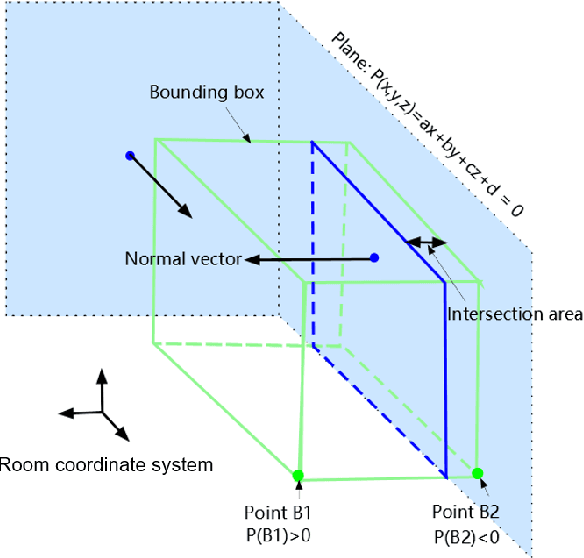
3D scene understanding from point clouds plays a vital role for various robotic applications. Unfortunately, current state-of-the-art methods use separate neural networks for different tasks like object detection or room layout estimation. Such a scheme has two limitations: 1) Storing and running several networks for different tasks are expensive for typical robotic platforms. 2) The intrinsic structure of separate outputs are ignored and potentially violated. To this end, we propose the first transformer architecture that predicts 3D objects and layouts simultaneously, using point cloud inputs. Unlike existing methods that either estimate layout keypoints or edges, we directly parameterize room layout as a set of quads. As such, the proposed architecture is termed as P(oint)Q(uad)-Transformer. Along with the novel quad representation, we propose a tailored physical constraint loss function that discourages object-layout interference. The quantitative and qualitative evaluations on the public benchmark ScanNet show that the proposed PQ-Transformer succeeds to jointly parse 3D objects and layouts, running at a quasi-real-time (8.91 FPS) rate without efficiency-oriented optimization. Moreover, the new physical constraint loss can improve strong baselines, and the F1-score of the room layout is significantly promoted from 37.9% to 57.9%.
Iterative Pseudo-Labeling with Deep Feature Annotation and Confidence-Based Sampling
Sep 06, 2021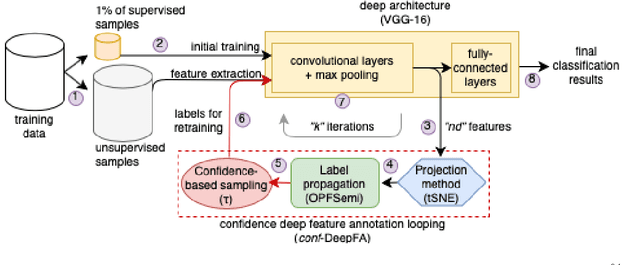

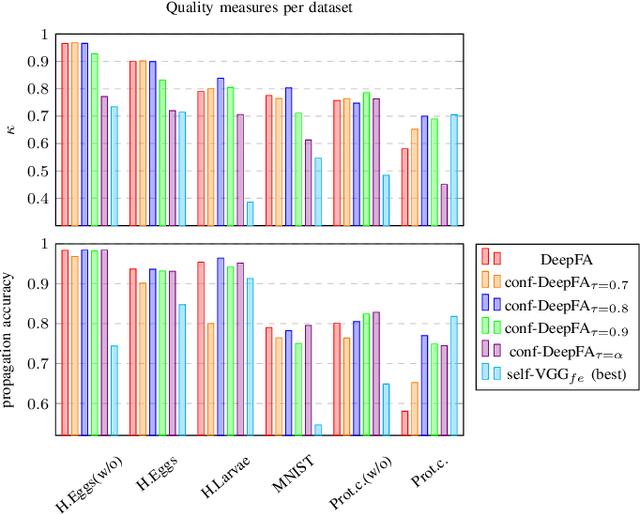
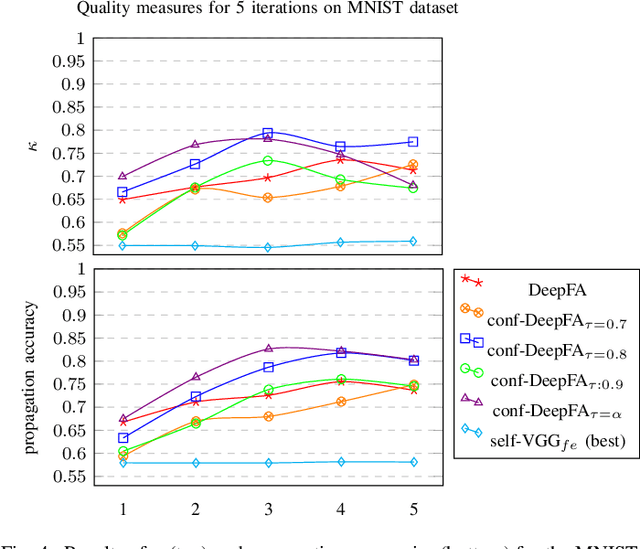
Training deep neural networks is challenging when large and annotated datasets are unavailable. Extensive manual annotation of data samples is time-consuming, expensive, and error-prone, notably when it needs to be done by experts. To address this issue, increased attention has been devoted to techniques that propagate uncertain labels (also called pseudo labels) to large amounts of unsupervised samples and use them for training the model. However, these techniques still need hundreds of supervised samples per class in the training set and a validation set with extra supervised samples to tune the model. We improve a recent iterative pseudo-labeling technique, Deep Feature Annotation (DeepFA), by selecting the most confident unsupervised samples to iteratively train a deep neural network. Our confidence-based sampling strategy relies on only dozens of annotated training samples per class with no validation set, considerably reducing user effort in data annotation. We first ascertain the best configuration for the baseline -- a self-trained deep neural network -- and then evaluate our confidence DeepFA for different confidence thresholds. Experiments on six datasets show that DeepFA already outperforms the self-trained baseline, but confidence DeepFA can considerably outperform the original DeepFA and the baseline.