 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To be Critical: Self-Calibrated Weakly Supervised Learning for Salient Object Detection
Sep 04, 2021
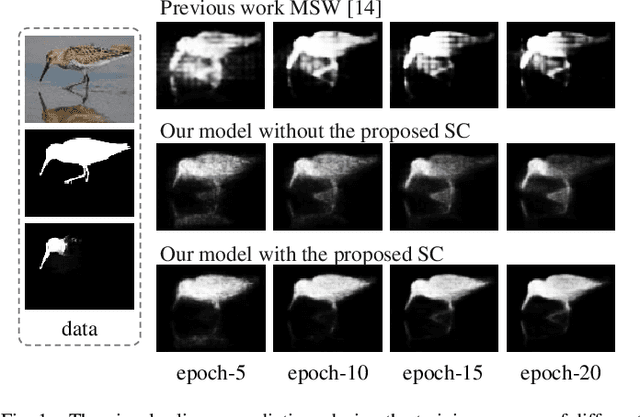
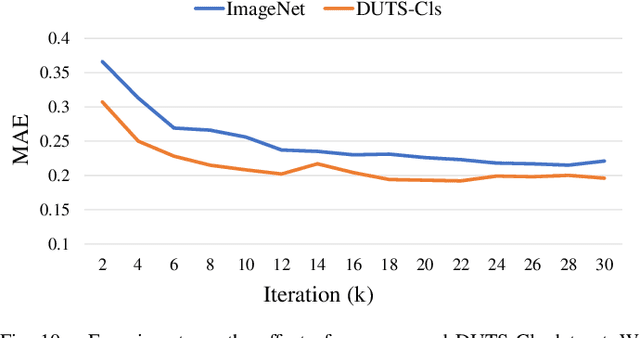
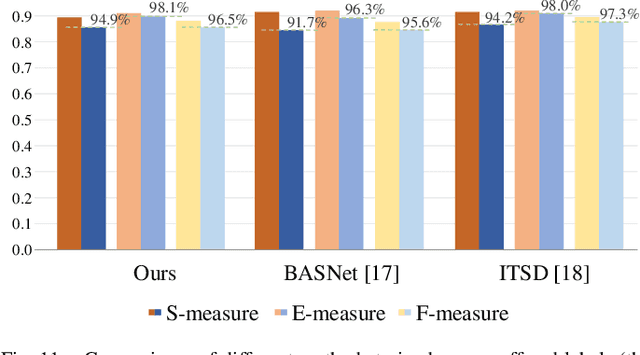
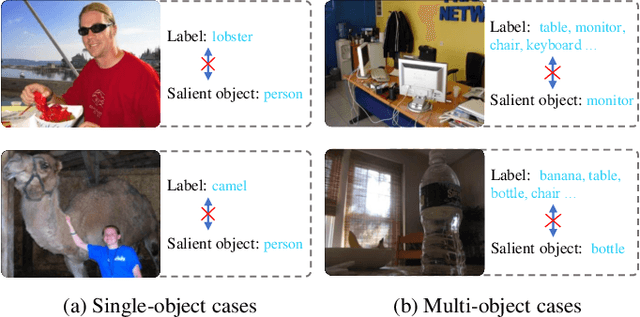
Weakly-supervised salient object detection (WSOD) aims to develop saliency models using image-level annotations. Despite of the success of previous works, explorations on an effective training strategy for the saliency network and accurate matches between image-level annotations and salient objects are still inadequate. In this work, 1) we propose a self-calibrated training strategy by explicitly establishing a mutual calibration loop between pseudo labels and network predictions, liberating the saliency network from error-prone propagation caused by pseudo labels. 2) we prove that even a much smaller dataset (merely 1.8% of ImageNet) with well-matched annotations can facilitate models to achieve better performance as well as generalizability. This sheds new light on the development of WSOD and encourages more contributions to the community. Comprehensive experiments demonstrate that our method outperforms all the existing WSOD methods by adopting the self-calibrated strategy only. Steady improvements are further achieved by training on the proposed dataset. Additionally, our method achieves 94.7% of the performance of fully-supervised methods on average. And what is more, the fully supervised models adopting our predicted results as "ground truths" achieve successful results (95.6% for BASNet and 97.3% for ITSD on F-measure), while costing only 0.32% of labeling time for pixel-level annotation.
Improving Clinical Predictions through Unsupervised Time Series Representation Learning
Dec 02, 2018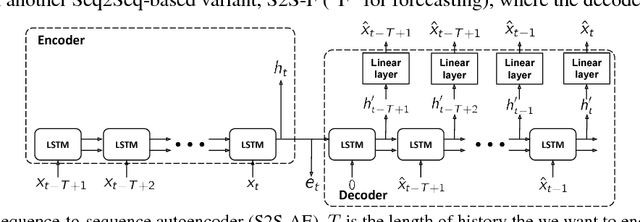

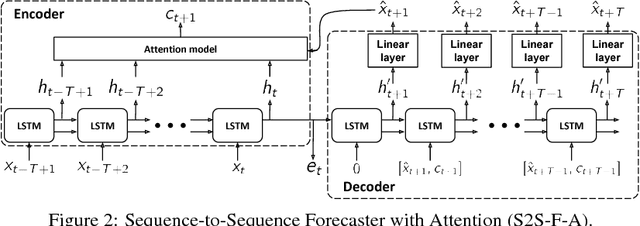
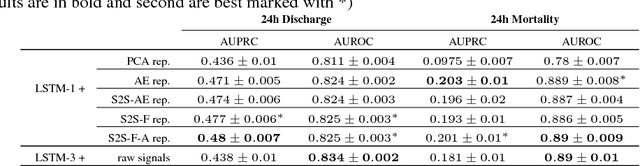
In this work, we investigate unsupervised representation learning on medical time series, which bears the promise of leveraging copious amounts of existing unlabeled data in order to eventually assist clinical decision making. By evaluating on the prediction of clinically relevant outcomes, we show that in a practical setting, unsupervised representation learning can offer clear performance benefits over end-to-end supervised architectures. We experiment with using sequence-to-sequence (Seq2Seq) models in two different ways, as an autoencoder and as a forecaster, and show that the best performance is achieved by a forecasting Seq2Seq model with an integrated attention mechanism, proposed here for the first time in the setting of unsupervised learning for medical time series.
The Role of "Live" in Livestreaming Markets: Evidence Using Orthogonal Random Forest
Jul 04, 2021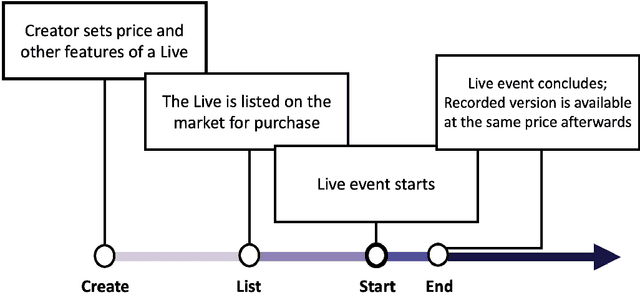
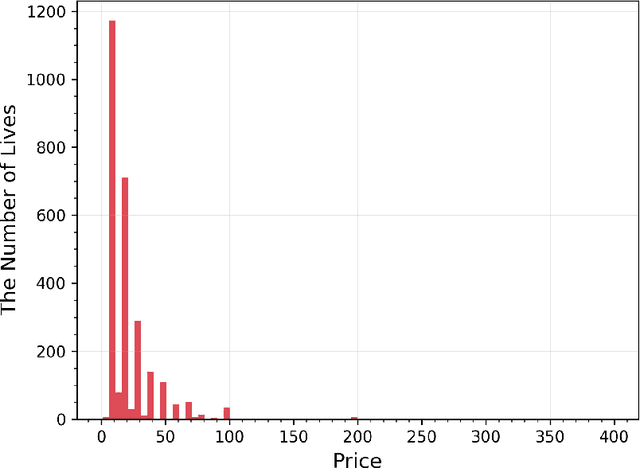
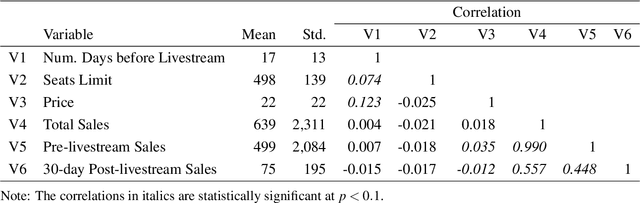
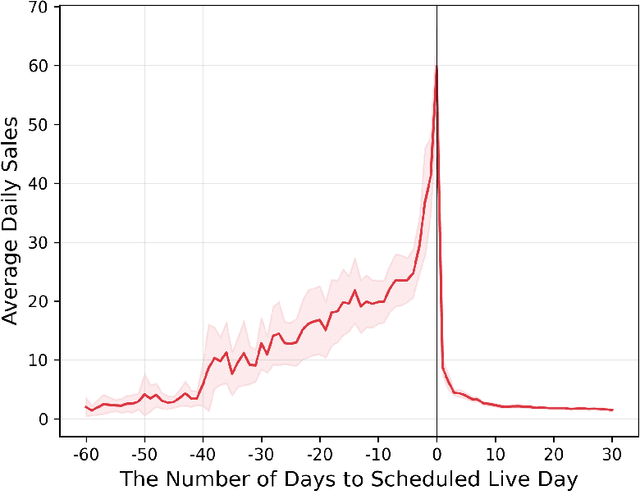
The common belief about the growing medium of livestreaming is that its value lies in its "live" component. In this paper, we leverage data from a large livestreaming platform to examine this belief. We are able to do this as this platform also allows viewers to purchase the recorded version of the livestream. We summarize the value of livestreaming content by estimating how demand responds to price before, on the day of, and after the livestream. We do this by proposing a generalized Orthogonal Random Forest framework. This framework allows us to estimate heterogeneous treatment effects in the presence of high-dimensional confounders whose relationships with the treatment policy (i.e., price) are complex but partially known. We find significant dynamics in the price elasticity of demand over the temporal distance to the scheduled livestreaming day and after. Specifically, demand gradually becomes less price sensitive over time to the livestreaming day and is inelastic on the livestreaming day. Over the post-livestream period, demand is still sensitive to price, but much less than the pre-livestream period. This indicates that the vlaue of livestreaming persists beyond the live component. Finally, we provide suggestive evidence for the likely mechanisms driving our results. These are quality uncertainty reduction for the patterns pre- and post-livestream and the potential of real-time interaction with the creator on the day of the livestream.
PIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
Sep 09, 2021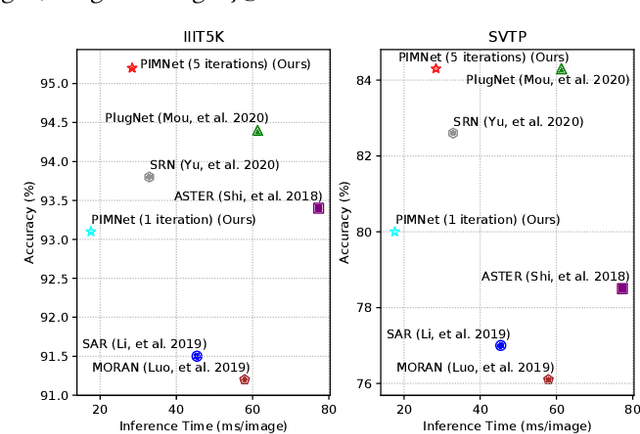
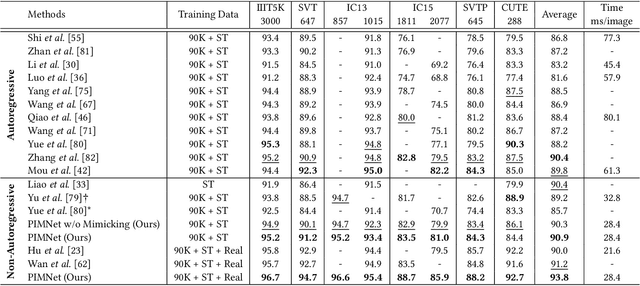
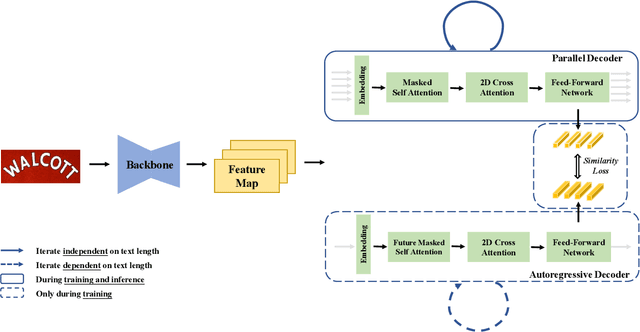

Nowadays, scene text recognition has attracted more and more attention due to its various applications. Most state-of-the-art methods adopt an encoder-decoder framework with attention mechanism, which generates text autoregressively from left to right. Despite the convincing performance, the speed is limited because of the one-by-one decoding strategy. As opposed to autoregressive models, non-autoregressive models predict the results in parallel with a much shorter inference time, but the accuracy falls behind the autoregressive counterpart considerably. In this paper, we propose a Parallel, Iterative and Mimicking Network (PIMNet) to balance accuracy and efficiency. Specifically, PIMNet adopts a parallel attention mechanism to predict the text faster and an iterative generation mechanism to make the predictions more accurate. In each iteration, the context information is fully explored. To improve learning of the hidden layer, we exploit the mimicking learning in the training phase, where an additional autoregressive decoder is adopted and the parallel decoder mimics the autoregressive decoder with fitting outputs of the hidden layer. With the shared backbone between the two decoders, the proposed PIMNet can be trained end-to-end without pre-training. During inference, the branch of the autoregressive decoder is removed for a faster speed. Extensive experiments on public benchmarks demonstrate the effectiveness and efficiency of PIMNet. Our code will be available at https://github.com/Pay20Y/PIMNet.
Federated Learning for Internet of Things: A Federated Learning Framework for On-device Anomaly Data Detection
Jun 15, 2021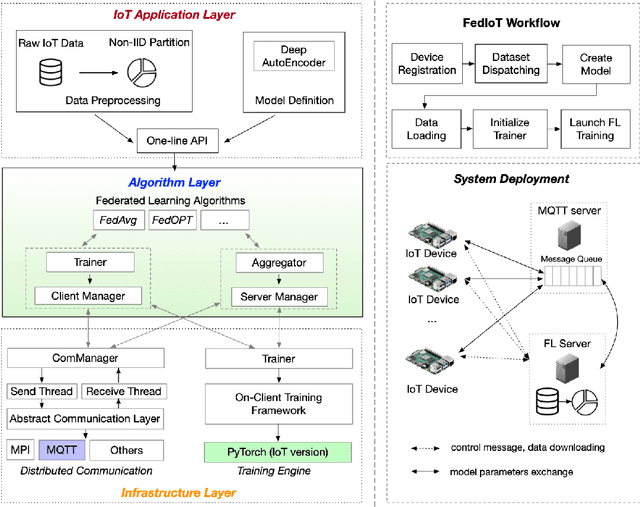
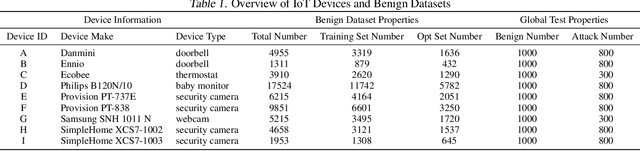

Federated learning can be a promising solution for enabling IoT cybersecurity (i.e., anomaly detection in the IoT environment) while preserving data privacy and mitigating the high communication/storage overhead (e.g., high-frequency data from time-series sensors) of centralized over-the-cloud approaches. In this paper, to further push forward this direction with a comprehensive study in both algorithm and system design, we build FedIoT platform that contains a synthesized dataset using N-BaIoT, FedDetect algorithm, and a system design for IoT devices. Furthermore, the proposed FedDetect learning framework improves the performance by utilizing an adaptive optimizer (e.g., Adam) and a cross-round learning rate scheduler. In a network of realistic IoT devices (Raspberry PI), we evaluate FedIoT platform and FedDetect algorithm in both model and system performance. Our results demonstrate the efficacy of federated learning in detecting a large range of attack types. The system efficiency analysis indicates that both end-to-end training time and memory cost are affordable and promising for resource-constrained IoT devices. The source code is publicly available.
Learning Interpretable Shapelets for Time Series Classification through Adversarial Regularization
Jun 03, 2019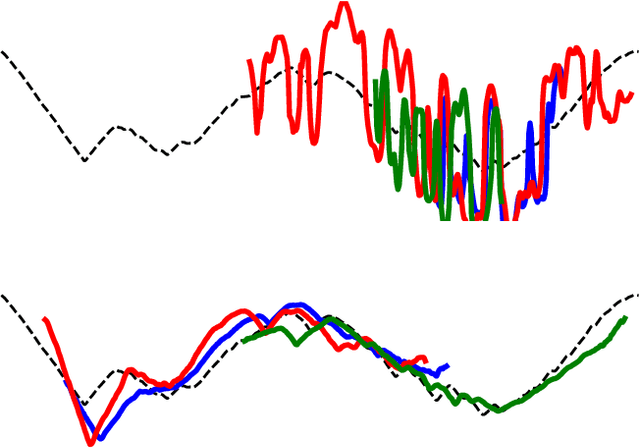
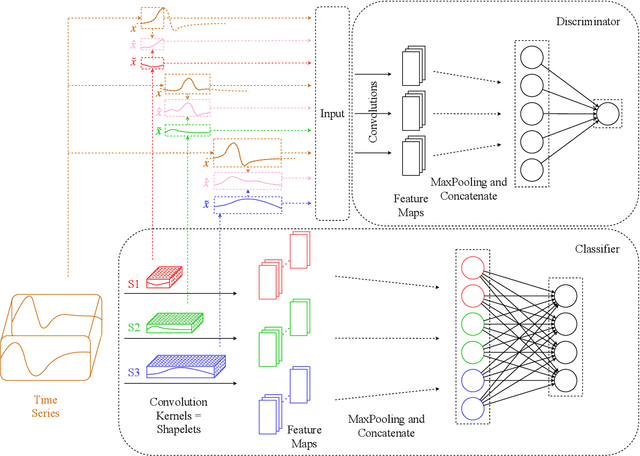
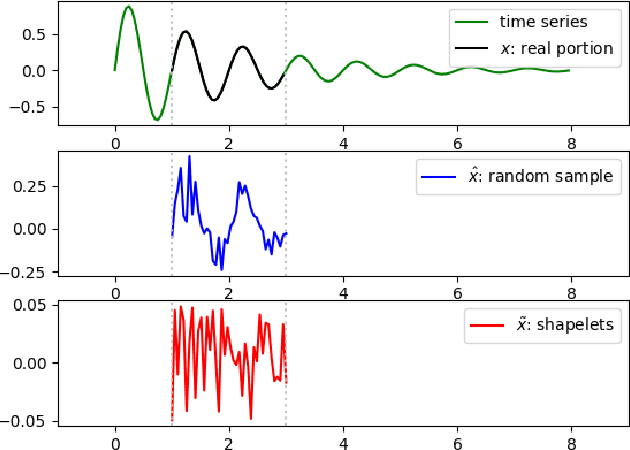
Times series classification can be successfully tackled by jointly learning a shapelet-based representation of the series in the dataset and classifying the series according to this representation. However, although the learned shapelets are discriminative, they are not always similar to pieces of a real series in the dataset. This makes it difficult to interpret the decision, i.e. difficult to analyze if there are particular behaviors in a series that triggered the decision. In this paper, we make use of a simple convolutional network to tackle the time series classification task and we introduce an adversarial regularization to constrain the model to learn more interpretable shapelets. Our classification results on all the usual time series benchmarks are comparable with the results obtained by similar state-of-the-art algorithms but our adversarially regularized method learns shapelets that are, by design, interpretable.
Fighting Gradients with Gradients: Dynamic Defenses against Adversarial Attacks
May 18, 2021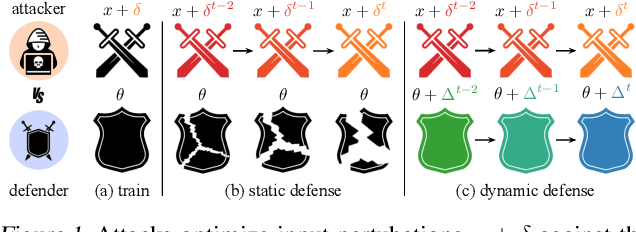
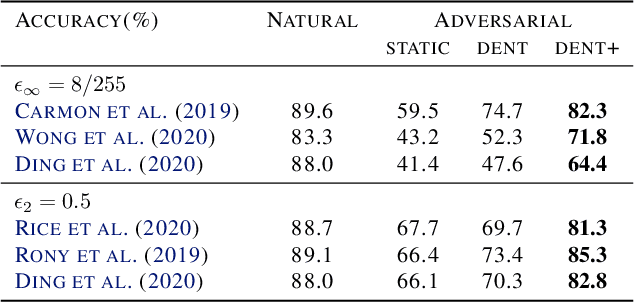


Adversarial attacks optimize against models to defeat defenses. Existing defenses are static, and stay the same once trained, even while attacks change. We argue that models should fight back, and optimize their defenses against attacks at test time. We propose dynamic defenses, to adapt the model and input during testing, by defensive entropy minimization (dent). Dent alters testing, but not training, for compatibility with existing models and train-time defenses. Dent improves the robustness of adversarially-trained defenses and nominally-trained models against white-box, black-box, and adaptive attacks on CIFAR-10/100 and ImageNet. In particular, dent boosts state-of-the-art defenses by 20+ points absolute against AutoAttack on CIFAR-10 at $\epsilon_\infty$ = 8/255.
A Morphing Quadrotor that Can Optimize Morphology for Transportation
Aug 15, 2021
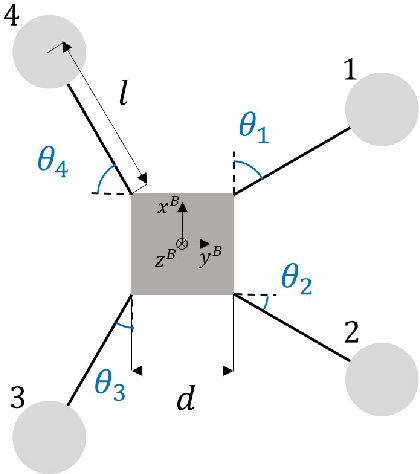
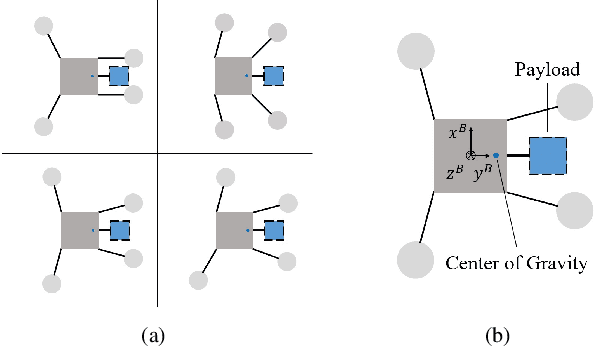
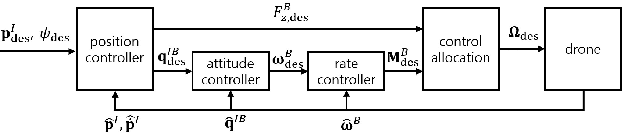
Multirotors can be effectively applied to various tasks, such as transportation, investigation, exploration, and lifesaving, depending on the type of payload. However, due to the nature of multirotors, the payload loaded on the multirotor is limited in its position and weight, which presents a major disadvantage when the multirotor is used in various fields. In this paper, we propose a novel method that greatly improves the restrictions on payload position and weight using a morphing quadrotor system. Our method can estimate the drone's weight, center of gravity position, and inertia tensor in real-time, which change depending on payload, and determine the optimal morphology for efficient and stable flight. An adaptive control method that can reflect the change in flight dynamics by payload and morphing is also presented. Experiments were conducted to confirm that the proposed morphing quadrotor improves the stability and efficiency in various situations of transporting payloads compared with the conventional quadrotor systems.
The IDLAB VoxCeleb Speaker Recognition Challenge 2021 System Description
Sep 09, 2021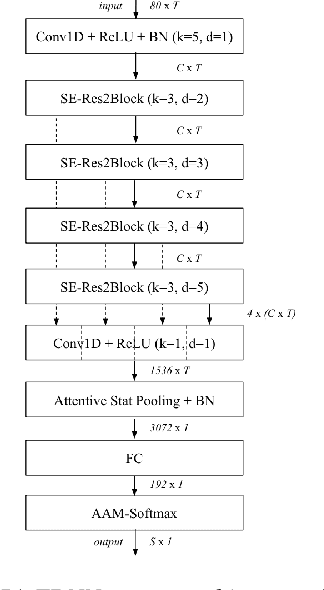
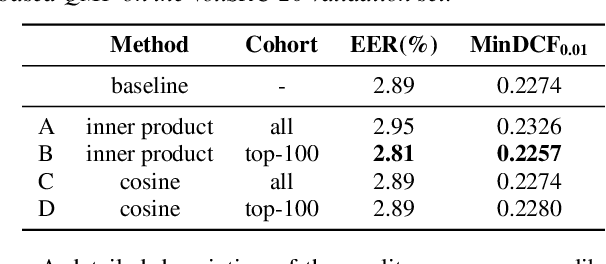
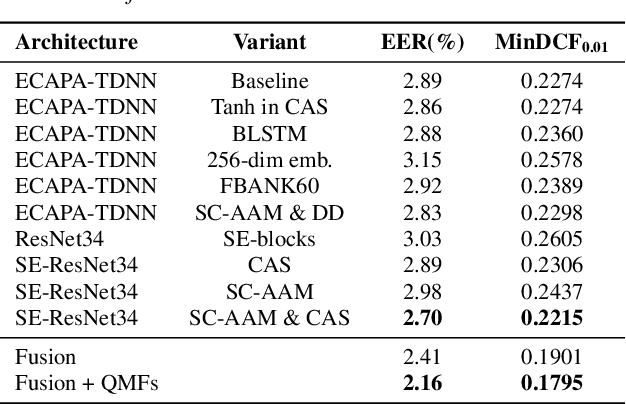
This technical report describes the IDLab submission for track 1 and 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. We opt to use a system fusion of hybrid architectures in our final submission. An ECAPA-TDNN baseline is enhanced with a 2D convolutional stem to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional information in the SE-ResNet architectures. All models are trained with a special mini-batch data sampling technique which constructs mini-batches with data that is the most challenging for the system on the level of intra-speaker variability. This intra-speaker variability is mainly caused by differences in language and background conditions between the speaker's utterances. The cross-lingual effects on the speaker verification scores are further compensated by introducing a binary cross-linguality trial feature in the logistic regression based system calibration. The final system fusion with two ECAPA CNN-TDNNs and three SE-ResNets enhanced with frequency positional information achieved a third place on the VoxSRC-21 leaderboard for both track 1 and 2 with a minDCF of 0.1291 and 0.1313 respectively.
A comprehensive deep learning-based approach to reduced order modeling of nonlinear time-dependent parametrized PDEs
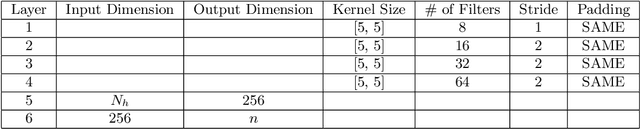
Jan 12, 2020
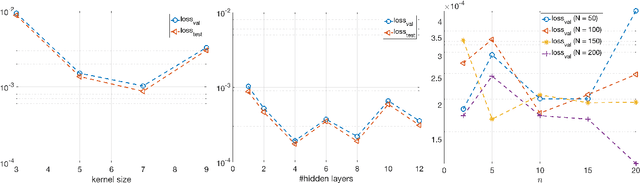
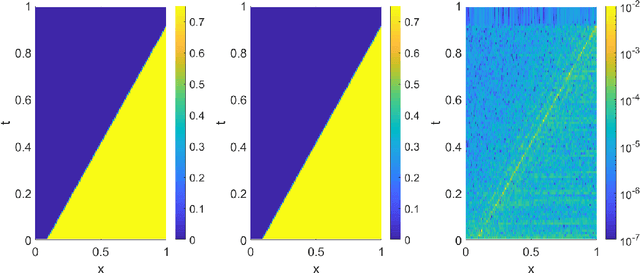
Traditional reduced order modeling techniques such as the reduced basis (RB) method (relying, e.g., on proper orthogonal decomposition (POD)) suffer from severe limitations when dealing with nonlinear time-dependent parametrized PDEs, because of the fundamental assumption of linear superimposition of modes they are based on. For this reason, in the case of problems featuring coherent structures that propagate over time such as transport, wave, or convection-dominated phenomena, the RB method usually yields inefficient reduced order models (ROMs) if one aims at obtaining reduced order approximations sufficiently accurate compared to the high-fidelity, full order model (FOM) solution. To overcome these limitations, in this work, we propose a new nonlinear approach to set reduced order models by exploiting deep learning (DL) algorithms. In the resulting nonlinear ROM, which we refer to as DL-ROM, both the nonlinear trial manifold (corresponding to the set of basis functions in a linear ROM) as well as the nonlinear reduced dynamics (corresponding to the projection stage in a linear ROM) are learned in a non-intrusive way by relying on DL algorithms; the latter are trained on a set of FOM solutions obtained for different parameter values. In this paper, we show how to construct a DL-ROM for both linear and nonlinear time-dependent parametrized PDEs; moreover, we assess its accuracy on test cases featuring different parametrized PDE problems. Numerical results indicate that DL-ROMs whose dimension is equal to the intrinsic dimensionality of the PDE solutions manifold are able to approximate the solution of parametrized PDEs in situations where a huge number of POD modes would be necessary to achieve the same degree of accuracy.