 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable Identification of Dementia from Transcripts using Transformer Networks
Sep 14, 2021
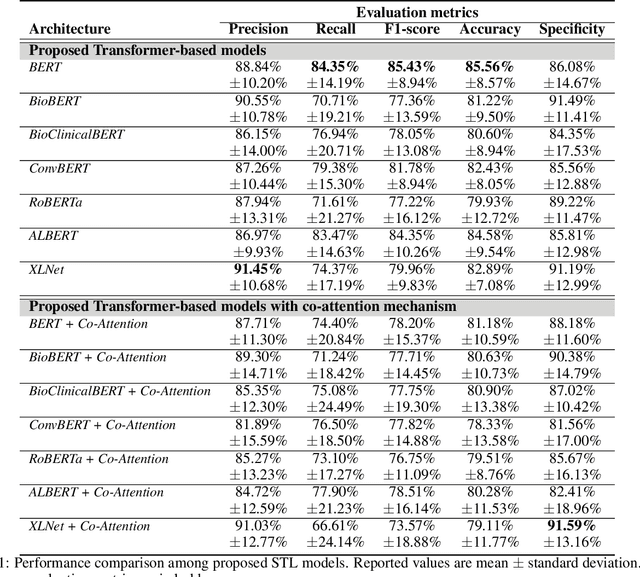
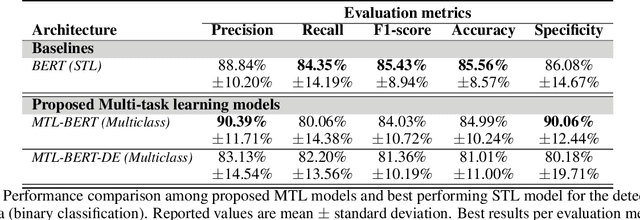
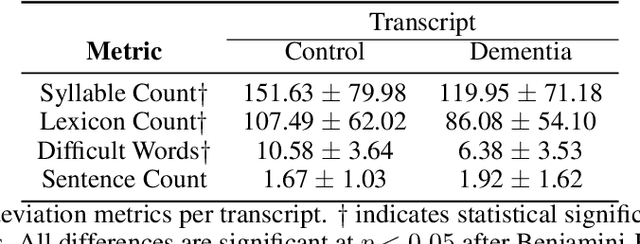

Alzheimer's disease (AD) is the main cause of dementia which is accompanied by loss of memory and may lead to severe consequences in peoples' everyday life if not diagnosed on time. Very few works have exploited transformer-based networks and despite the high accuracy achieved, little work has been done in terms of model interpretability. In addition, although Mini-Mental State Exam (MMSE) scores are inextricably linked with the identification of dementia, research works face the task of dementia identification and the task of the prediction of MMSE scores as two separate tasks. In order to address these limitations, we employ several transformer-based models, with BERT achieving the highest accuracy accounting for 85.56%. Concurrently, we propose an interpretable method to detect AD patients based on siamese networks reaching accuracy up to 81.18%. Next, we introduce two multi-task learning models, where the main task refers to the identification of dementia (binary classification), while the auxiliary one corresponds to the identification of the severity of dementia (multiclass classification). Our model obtains accuracy equal to 84.99% on the detection of AD patients in the multi-task learning setting. Finally, we present some new methods to identify the linguistic patterns used by AD patients and non-AD ones, including text statistics, vocabulary uniqueness, word usage, correlations via a detailed linguistic analysis, and explainability techniques (LIME). Findings indicate significant differences in language between AD and non-AD patients.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jun 15, 2021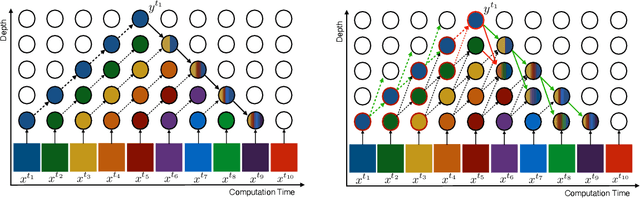
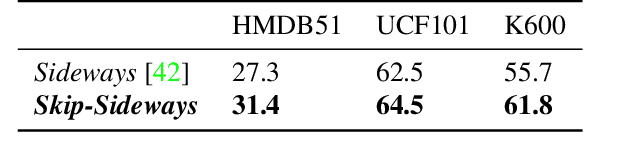
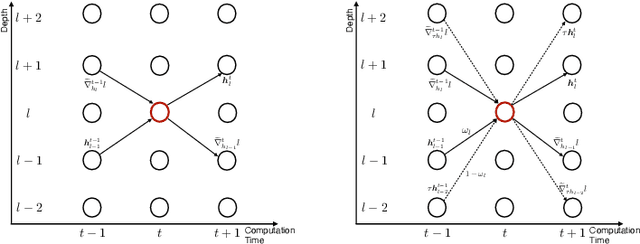

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Parallel Multi-Graph Convolution Network For Metro Passenger Volume Prediction
Aug 29, 2021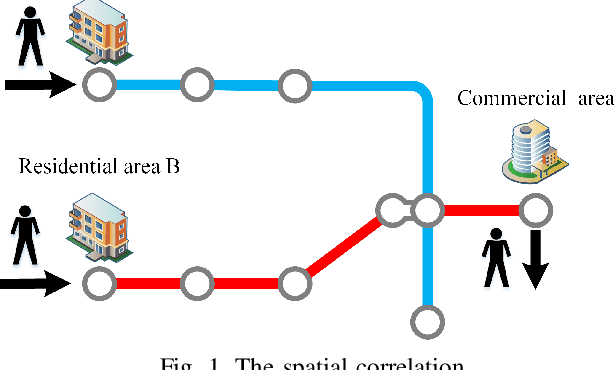
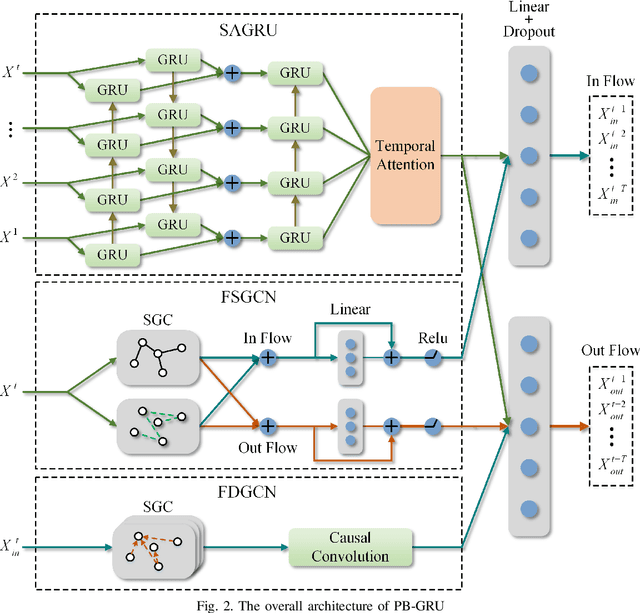
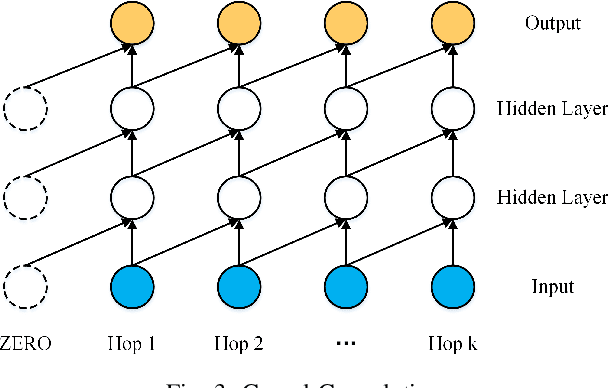
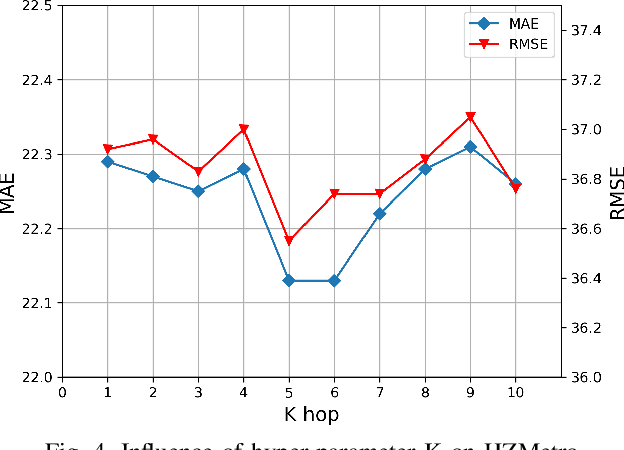
Accurate prediction of metro passenger volume (number of passengers) is valuable to realize real-time metro system management, which is a pivotal yet challenging task in intelligent transportation. Due to the complex spatial correlation and temporal variation of urban subway ridership behavior, deep learning has been widely used to capture non-linear spatial-temporal dependencies. Unfortunately, the current deep learning methods only adopt graph convolutional network as a component to model spatial relationship, without making full use of the different spatial correlation patterns between stations. In order to further improve the accuracy of metro passenger volume prediction, a deep learning model composed of Parallel multi-graph convolution and stacked Bidirectional unidirectional Gated Recurrent Unit (PB-GRU) was proposed in this paper. The parallel multi-graph convolution captures the origin-destination (OD) distribution and similar flow pattern between the metro stations, while bidirectional gated recurrent unit considers the passenger volume sequence in forward and backward directions and learns complex temporal features. Extensive experiments on two real-world datasets of subway passenger flow show the efficacy of the model. Surprisingly, compared with the existing methods, PB-GRU achieves much lower prediction error.
Deep Learning to Ternary Hash Codes by Continuation
Jul 16, 2021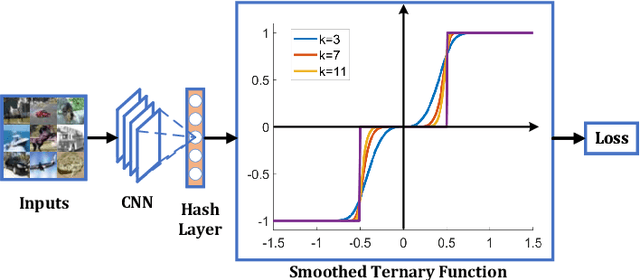
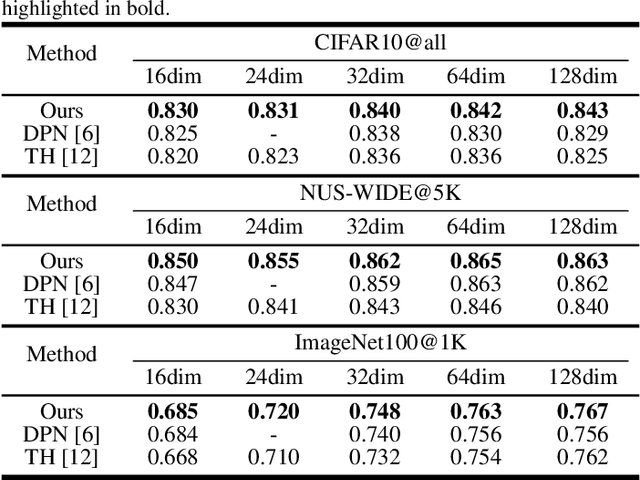
Recently, it has been observed that {0,1,-1}-ternary codes which are simply generated from deep features by hard thresholding, tend to outperform {-1,1}-binary codes in image retrieval. To obtain better ternary codes, we for the first time propose to jointly learn the features with the codes by appending a smoothed function to the networks. During training, the function could evolve into a non-smoothed ternary function by a continuation method. The method circumvents the difficulty of directly training discrete functions and reduces the quantization errors of ternary codes. Experiments show that the generated codes indeed could achieve higher retrieval accuracy.
A comprehensive deep learning-based approach to reduced order modeling of nonlinear time-dependent parametrized PDEs
Jan 12, 2020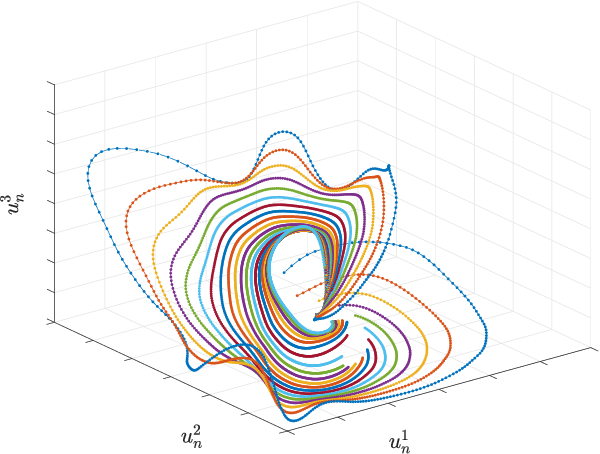
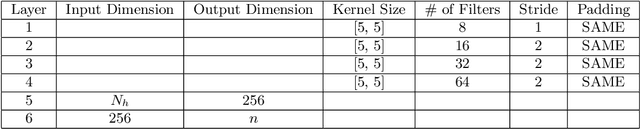
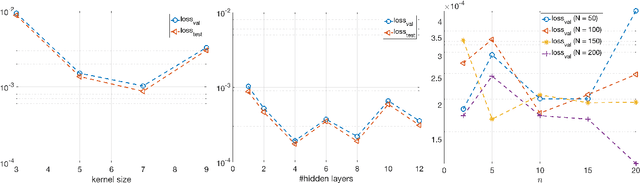
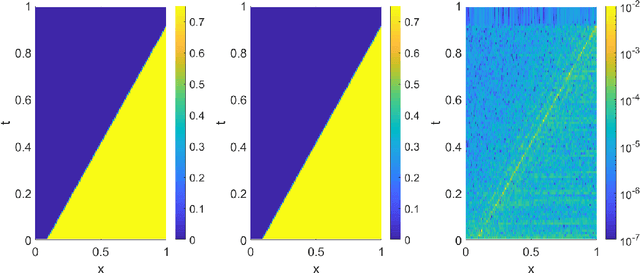
Traditional reduced order modeling techniques such as the reduced basis (RB) method (relying, e.g., on proper orthogonal decomposition (POD)) suffer from severe limitations when dealing with nonlinear time-dependent parametrized PDEs, because of the fundamental assumption of linear superimposition of modes they are based on. For this reason, in the case of problems featuring coherent structures that propagate over time such as transport, wave, or convection-dominated phenomena, the RB method usually yields inefficient reduced order models (ROMs) if one aims at obtaining reduced order approximations sufficiently accurate compared to the high-fidelity, full order model (FOM) solution. To overcome these limitations, in this work, we propose a new nonlinear approach to set reduced order models by exploiting deep learning (DL) algorithms. In the resulting nonlinear ROM, which we refer to as DL-ROM, both the nonlinear trial manifold (corresponding to the set of basis functions in a linear ROM) as well as the nonlinear reduced dynamics (corresponding to the projection stage in a linear ROM) are learned in a non-intrusive way by relying on DL algorithms; the latter are trained on a set of FOM solutions obtained for different parameter values. In this paper, we show how to construct a DL-ROM for both linear and nonlinear time-dependent parametrized PDEs; moreover, we assess its accuracy on test cases featuring different parametrized PDE problems. Numerical results indicate that DL-ROMs whose dimension is equal to the intrinsic dimensionality of the PDE solutions manifold are able to approximate the solution of parametrized PDEs in situations where a huge number of POD modes would be necessary to achieve the same degree of accuracy.
Debiasing a First-order Heuristic for Approximate Bi-level Optimization
Jun 08, 2021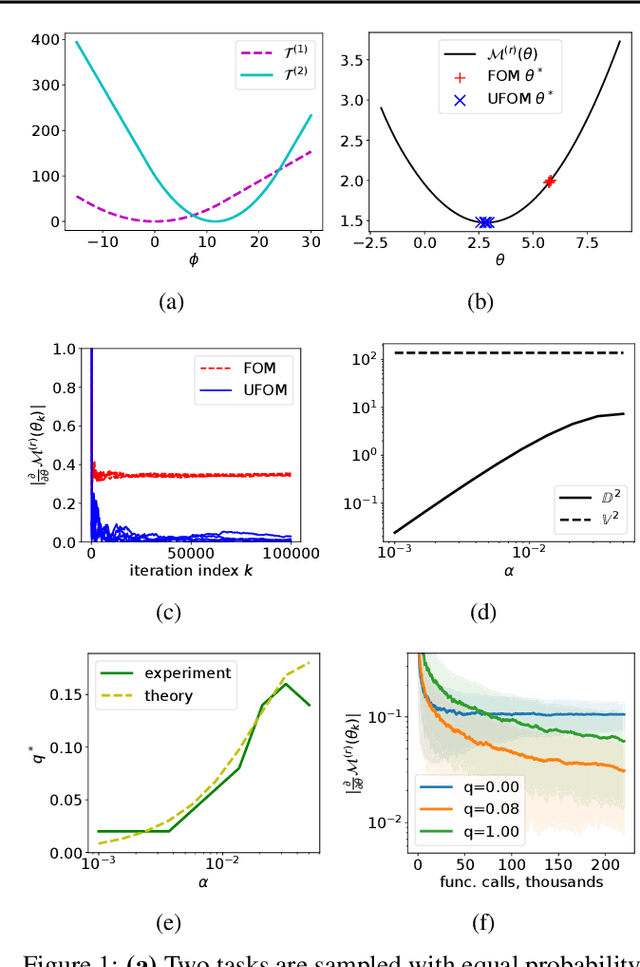
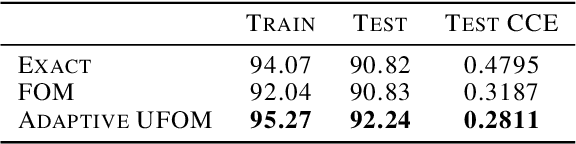
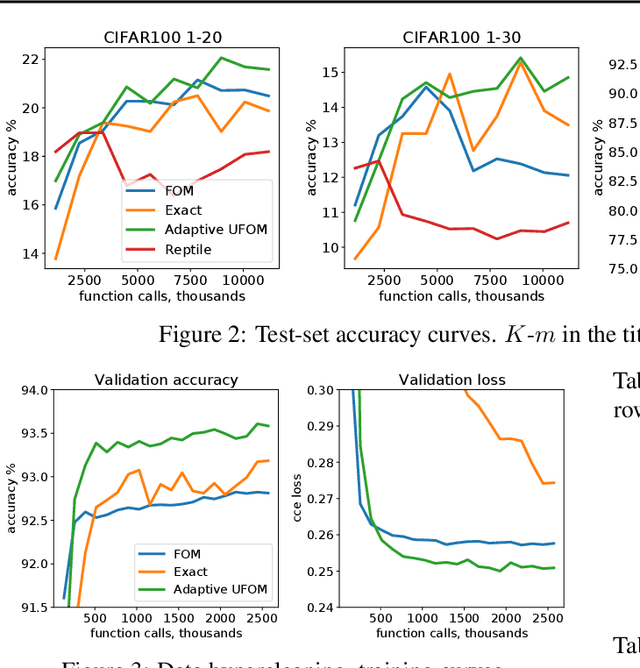
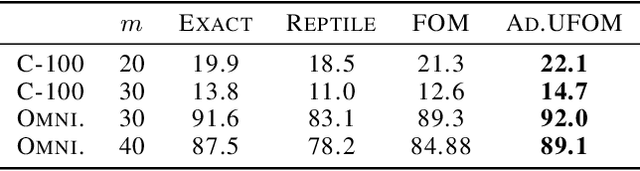
Approximate bi-level optimization (ABLO) consists of (outer-level) optimization problems, involving numerical (inner-level) optimization loops. While ABLO has many applications across deep learning, it suffers from time and memory complexity proportional to the length $r$ of its inner optimization loop. To address this complexity, an earlier first-order method (FOM) was proposed as a heuristic that omits second derivative terms, yielding significant speed gains and requiring only constant memory. Despite FOM's popularity, there is a lack of theoretical understanding of its convergence properties. We contribute by theoretically characterizing FOM's gradient bias under mild assumptions. We further demonstrate a rich family of examples where FOM-based SGD does not converge to a stationary point of the ABLO objective. We address this concern by proposing an unbiased FOM (UFOM) enjoying constant memory complexity as a function of $r$. We characterize the introduced time-variance tradeoff, demonstrate convergence bounds, and find an optimal UFOM for a given ABLO problem. Finally, we propose an efficient adaptive UFOM scheme.
Excess Capacity and Backdoor Poisoning
Sep 14, 2021

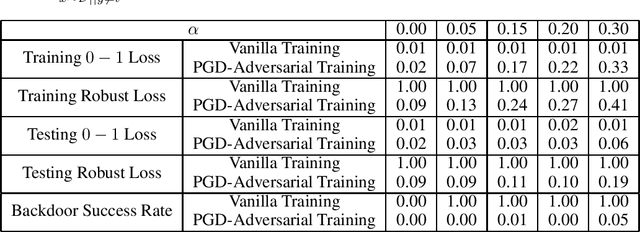
A backdoor data poisoning attack is an adversarial attack wherein the attacker injects several watermarked, mislabeled training examples into a training set. The watermark does not impact the test-time performance of the model on typical data; however, the model reliably errs on watermarked examples. To gain a better foundational understanding of backdoor data poisoning attacks, we present a formal theoretical framework within which one can discuss backdoor data poisoning attacks for classification problems. We then use this to analyze important statistical and computational issues surrounding these attacks. On the statistical front, we identify a parameter we call the memorization capacity that captures the intrinsic vulnerability of a learning problem to a backdoor attack. This allows us to argue about the robustness of several natural learning problems to backdoor attacks. Our results favoring the attacker involve presenting explicit constructions of backdoor attacks, and our robustness results show that some natural problem settings cannot yield successful backdoor attacks. From a computational standpoint, we show that under certain assumptions, adversarial training can detect the presence of backdoors in a training set. We then show that under similar assumptions, two closely related problems we call backdoor filtering and robust generalization are nearly equivalent. This implies that it is both asymptotically necessary and sufficient to design algorithms that can identify watermarked examples in the training set in order to obtain a learning algorithm that both generalizes well to unseen data and is robust to backdoors.
Economic Nowcasting with Long Short-Term Memory Artificial Neural Networks (LSTM)
Jun 15, 2021Artificial neural networks (ANNs) have been the catalyst to numerous advances in a variety of fields and disciplines in recent years. Their impact on economics, however, has been comparatively muted. One type of ANN, the long short-term memory network (LSTM), is particularly wellsuited to deal with economic time-series. Here, the architecture's performance and characteristics are evaluated in comparison with the dynamic factor model (DFM), currently a popular choice in the field of economic nowcasting. LSTMs are found to produce superior results to DFMs in the nowcasting of three separate variables; global merchandise export values and volumes, and global services exports. Further advantages include their ability to handle large numbers of input features in a variety of time frequencies. A disadvantage is the inability to ascribe contributions of input features to model outputs, common to all ANNs. In order to facilitate continued applied research of the methodology by avoiding the need for any knowledge of deep-learning libraries, an accompanying Python library was developed using PyTorch, https://pypi.org/project/nowcast-lstm/.
Cine-MRI detection of abdominal adhesions with spatio-temporal deep learning
Jun 15, 2021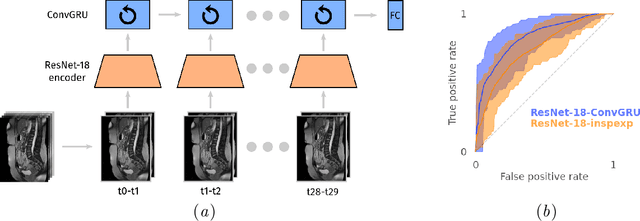
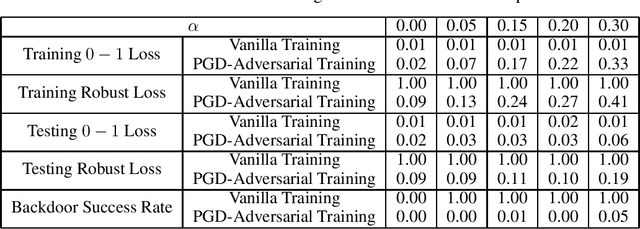
Adhesions are an important cause of chronic pain following abdominal surgery. Recent developments in abdominal cine-MRI have enabled the non-invasive diagnosis of adhesions. Adhesions are identified on cine-MRI by the absence of sliding motion during movement. Diagnosis and mapping of adhesions improves the management of patients with pain. Detection of abdominal adhesions on cine-MRI is challenging from both a radiological and deep learning perspective. We focus on classifying presence or absence of adhesions in sagittal abdominal cine-MRI series. We experimented with spatio-temporal deep learning architectures centered around a ConvGRU architecture. A hybrid architecture comprising a ResNet followed by a ConvGRU model allows to classify a whole time-series. Compared to a stand-alone ResNet with a two time-point (inspiration/expiration) input, we show an increase in classification performance (AUROC) from 0.74 to 0.83 ($p<0.05$). Our full temporal classification approach adds only a small amount (5%) of parameters to the entire architecture, which may be useful for other medical imaging problems with a temporal dimension.
Mispronunciation Detection and Correction via Discrete Acoustic Units
Aug 12, 2021
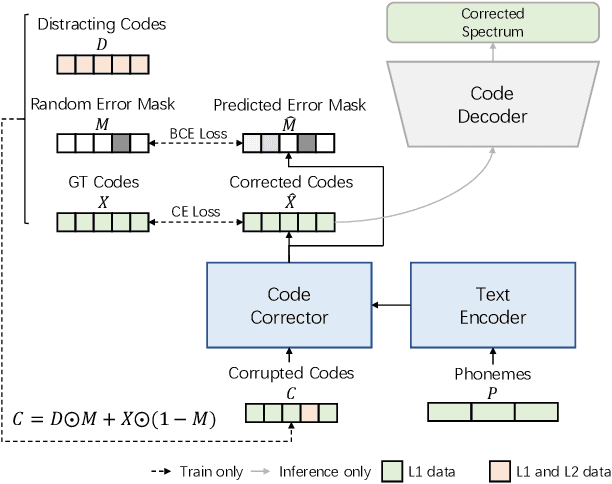
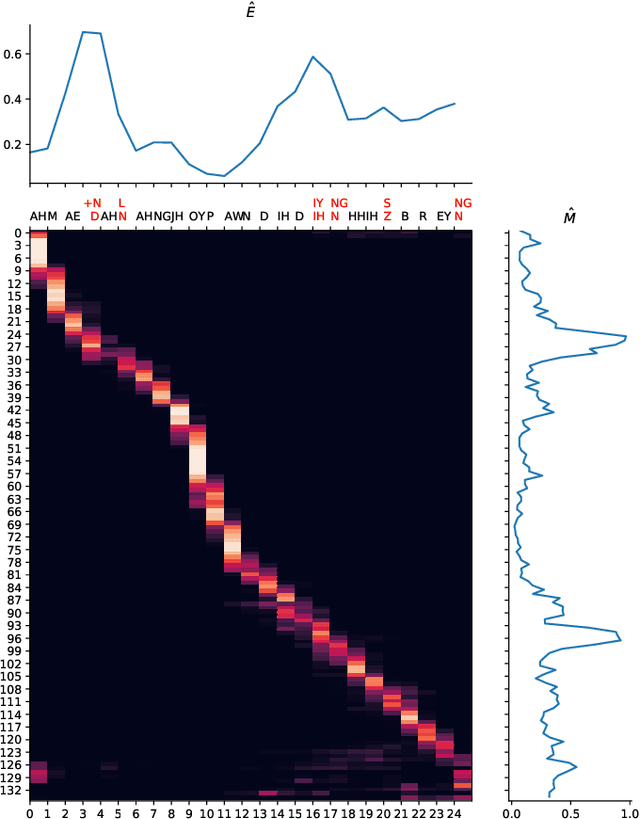
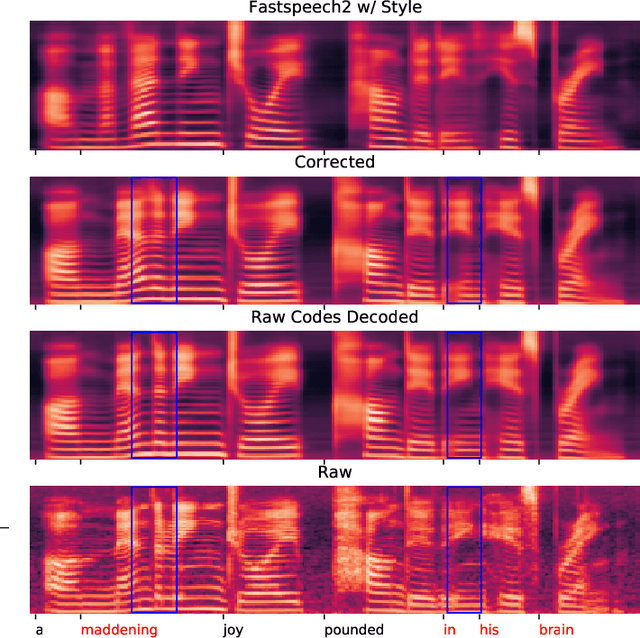
Computer-Assisted Pronunciation Training (CAPT) plays an important role in language learning. However, conventional CAPT methods cannot effectively use non-native utterances for supervised training because the ground truth pronunciation needs expensive annotation. Meanwhile, certain undefined nonnative phonemes cannot be correctly classified into standard phonemes. To solve these problems, we use the vector-quantized variational autoencoder (VQ-VAE) to encode the speech into discrete acoustic units in a self-supervised manner. Based on these units, we propose a novel method that integrates both discriminative and generative models. The proposed method can detect mispronunciation and generate the correct pronunciation at the same time. Experiments on the L2-Arctic dataset show that the detection F1 score is improved by 9.58% relatively compared with recognition-based methods. The proposed method also achieves a comparable word error rate (WER) and the best style preservation for mispronunciation correction compared with text-to-speech (TTS) methods.