 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Transformations of Hamiltonian Shapes based on Line Moves
Aug 24, 2021
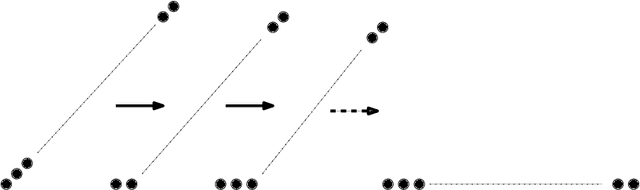
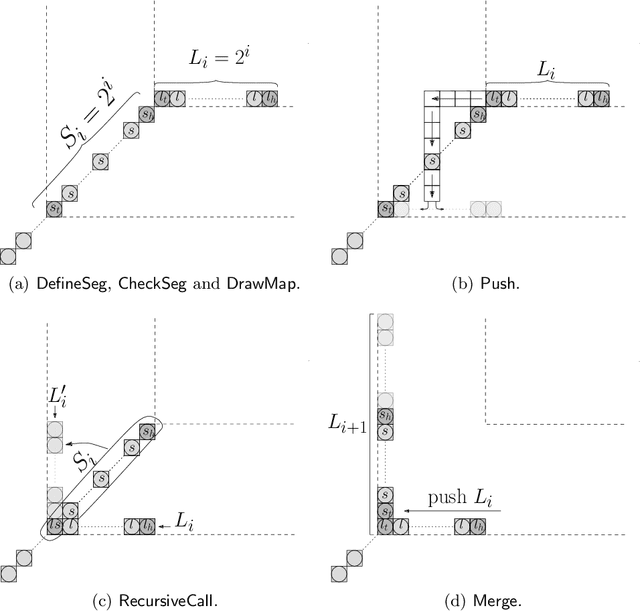
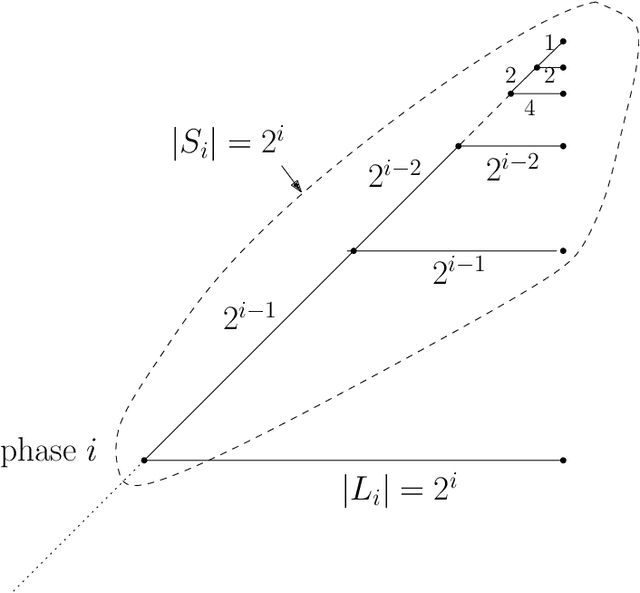

We consider a discrete system of $n$ simple indistinguishable devices, called \emph{agents}, forming a \emph{connected} shape $S_I$ on a two-dimensional square grid. Agents are equipped with a linear-strength mechanism, called a \emph{line move}, by which an agent can push a whole line of consecutive agents in one of the four directions in a single time-step. We study the problem of transforming an initial shape $S_I$ into a given target shape $S_F$ via a finite sequence of line moves in a distributed model, where each agent can observe the states of nearby agents in a Moore neighbourhood. Our main contribution is the first distributed connectivity-preserving transformation that exploits line moves within a total of $O(n \log_2 n)$ moves, which is asymptotically equivalent to that of the best-known centralised transformations. The algorithm solves the \emph{line formation problem} that allows agents to form a final straight line $S_L$, starting from any shape $ S_I $, whose \emph{associated graph} contains a Hamiltonian path.
FNetAR: Mixing Tokens with Autoregressive Fourier Transforms
Jul 22, 2021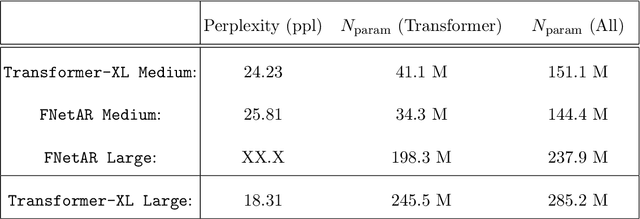
In this note we examine the autoregressive generalization of the FNet algorithm, in which self-attention layers from the standard Transformer architecture are substituted with a trivial sparse-uniformsampling procedure based on Fourier transforms. Using the Wikitext-103 benchmark, we demonstratethat FNetAR retains state-of-the-art performance (25.8 ppl) on the task of causal language modelingcompared to a Transformer-XL baseline (24.2 ppl) with only half the number self-attention layers,thus providing further evidence for the superfluity of deep neural networks with heavily compoundedattention mechanisms. The autoregressive Fourier transform could likely be used for parameterreduction on most Transformer-based time-series prediction models.
GalaxAI: Machine learning toolbox for interpretable analysis of spacecraft telemetry data
Aug 09, 2021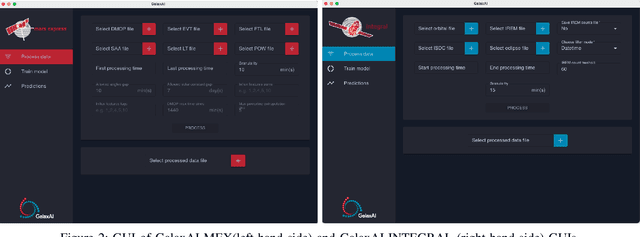
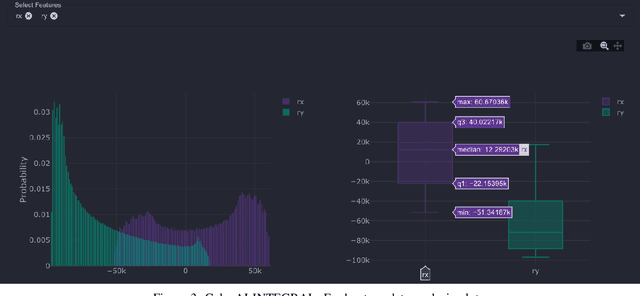
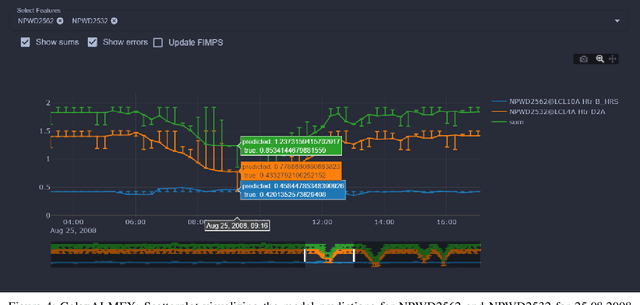
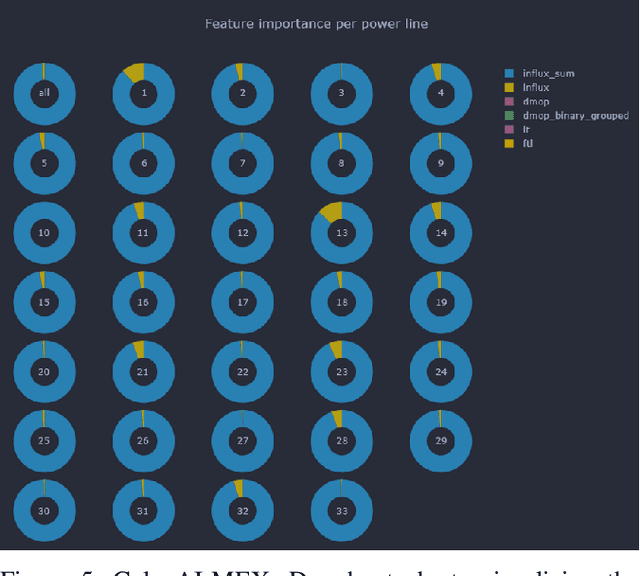
We present GalaxAI - a versatile machine learning toolbox for efficient and interpretable end-to-end analysis of spacecraft telemetry data. GalaxAI employs various machine learning algorithms for multivariate time series analyses, classification, regression and structured output prediction, capable of handling high-throughput heterogeneous data. These methods allow for the construction of robust and accurate predictive models, that are in turn applied to different tasks of spacecraft monitoring and operations planning. More importantly, besides the accurate building of models, GalaxAI implements a visualisation layer, providing mission specialists and operators with a full, detailed and interpretable view of the data analysis process. We show the utility and versatility of GalaxAI on two use-cases concerning two different spacecraft: i) analysis and planning of Mars Express thermal power consumption and ii) predicting of INTEGRAL's crossings through Van Allen belts.
pAElla: Edge-AI based Real-Time Malware Detection in Data Centers
Apr 07, 2020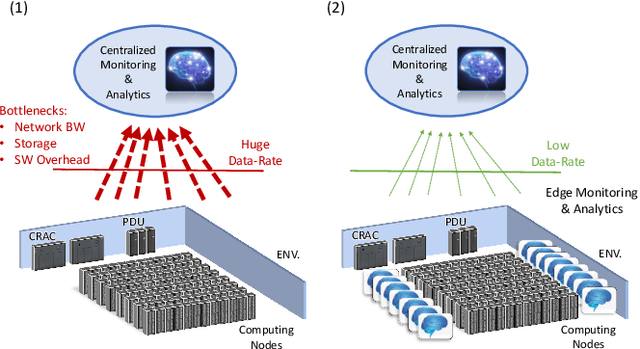
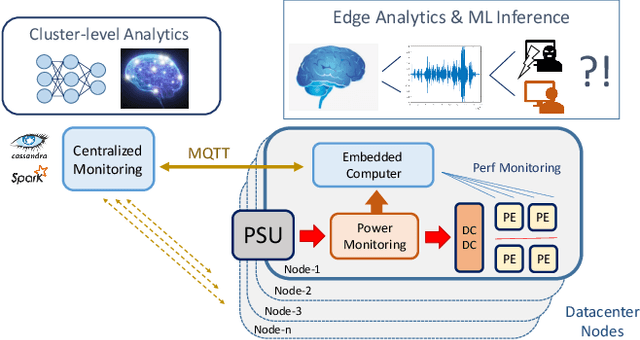
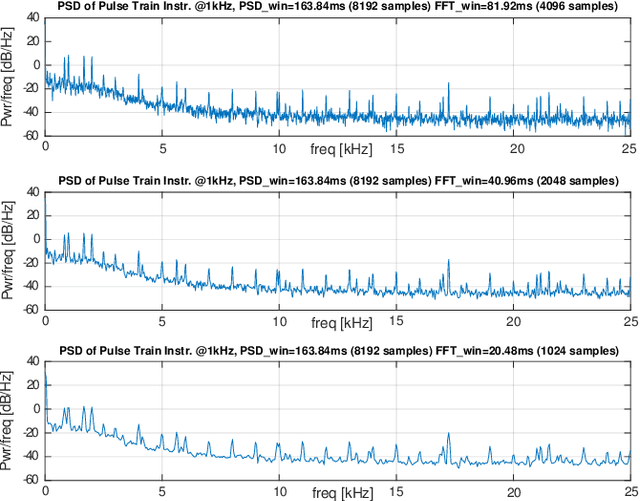
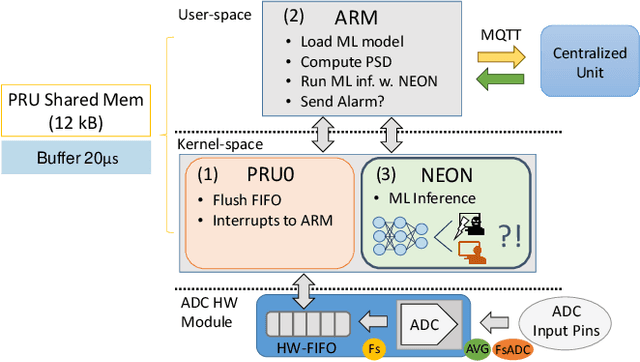
The increasing use of Internet-of-Things (IoT) devices for monitoring a wide spectrum of applications, along with the challenges of "big data" streaming support they often require for data analysis, is nowadays pushing for an increased attention to the emerging edge computing paradigm. In particular, smart approaches to manage and analyze data directly on the network edge, are more and more investigated, and Artificial Intelligence (AI) powered edge computing is envisaged to be a promising direction. In this paper, we focus on Data Centers (DCs) and Supercomputers (SCs), where a new generation of high-resolution monitoring systems is being deployed, opening new opportunities for analysis like anomaly detection and security, but introducing new challenges for handling the vast amount of data it produces. In detail, we report on a novel lightweight and scalable approach to increase the security of DCs/SCs, that involves AI-powered edge computing on high-resolution power consumption. The method -- called pAElla -- targets real-time Malware Detection (MD), it runs on an out-of-band IoT-based monitoring system for DCs/SCs, and involves Power Spectral Density of power measurements, along with AutoEncoders. Results are promising, with an F1-score close to 1, and a False Alarm and Malware Miss rate close to 0%. We compare our method with State-of-the-Art MD techniques and show that, in the context of DCs/SCs, pAElla can cover a wider range of malware, significantly outperforming SoA approaches in terms of accuracy. Moreover, we propose a methodology for online training suitable for DCs/SCs in production, and release open dataset and code.
SurpriseNet: Melody Harmonization Conditioning on User-controlled Surprise Contours
Aug 24, 2021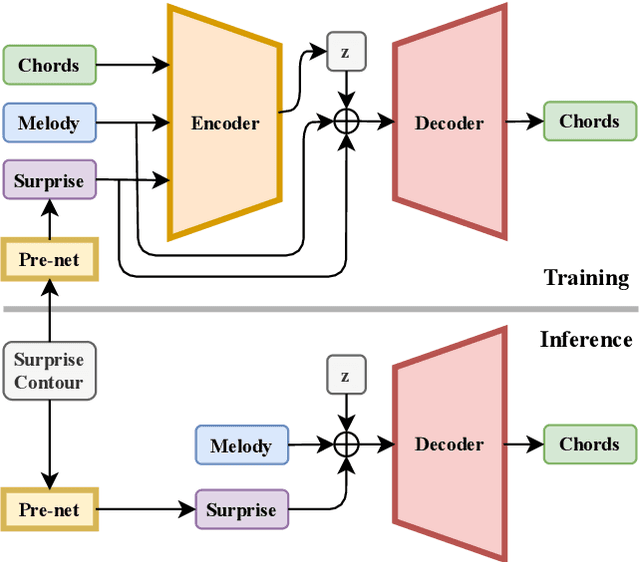
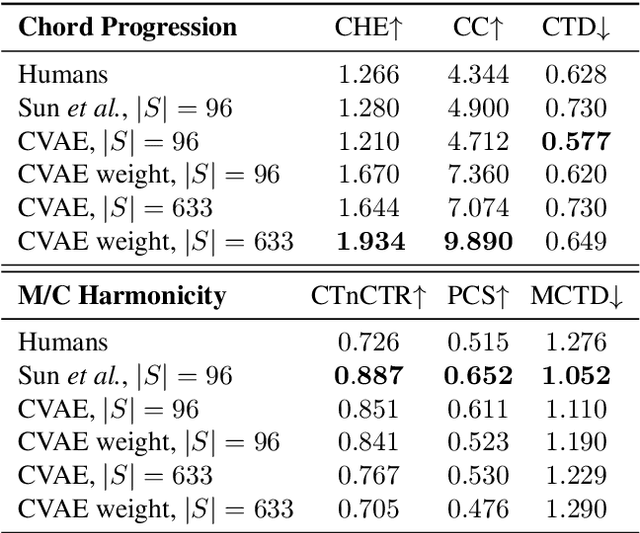
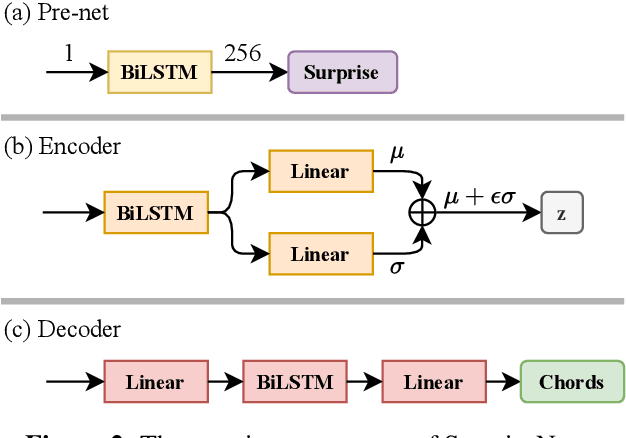

The surprisingness of a song is an essential and seemingly subjective factor in determining whether the listener likes it. With the help of information theory, it can be described as the transition probability of a music sequence modeled as a Markov chain. In this study, we introduce the concept of deriving entropy variations over time, so that the surprise contour of each chord sequence can be extracted. Based on this, we propose a user-controllable framework that uses a conditional variational autoencoder (CVAE) to harmonize the melody based on the given chord surprise indication. Through explicit conditions, the model can randomly generate various and harmonic chord progressions for a melody, and the Spearman's correlation and p-value significance show that the resulting chord progressions match the given surprise contour quite well. The vanilla CVAE model was evaluated in a basic melody harmonization task (no surprise control) in terms of six objective metrics. The results of experiments on the Hooktheory Lead Sheet Dataset show that our model achieves performance comparable to the state-of-the-art melody harmonization model.
Improving Clinical Predictions through Unsupervised Time Series Representation Learning
Dec 02, 2018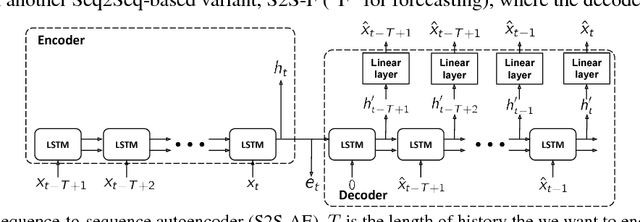

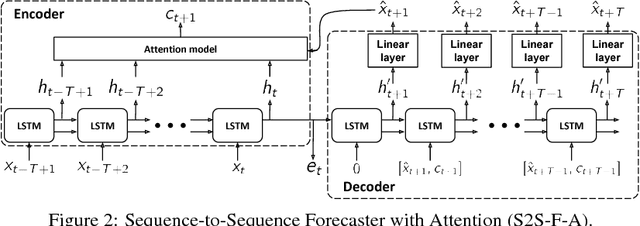
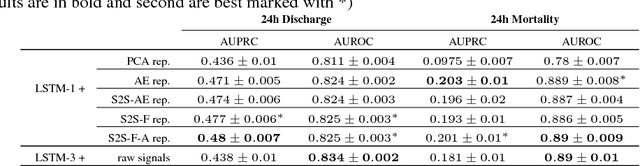
In this work, we investigate unsupervised representation learning on medical time series, which bears the promise of leveraging copious amounts of existing unlabeled data in order to eventually assist clinical decision making. By evaluating on the prediction of clinically relevant outcomes, we show that in a practical setting, unsupervised representation learning can offer clear performance benefits over end-to-end supervised architectures. We experiment with using sequence-to-sequence (Seq2Seq) models in two different ways, as an autoencoder and as a forecaster, and show that the best performance is achieved by a forecasting Seq2Seq model with an integrated attention mechanism, proposed here for the first time in the setting of unsupervised learning for medical time series.
Machine Learning-Based Estimation and Goodness-of-Fit for Large-Scale Confirmatory Item Factor Analysis
Sep 20, 2021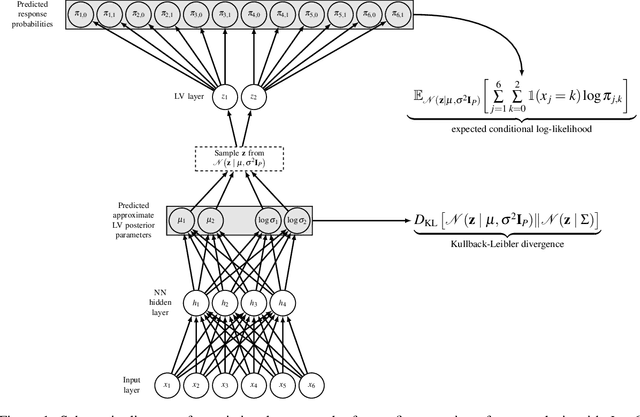
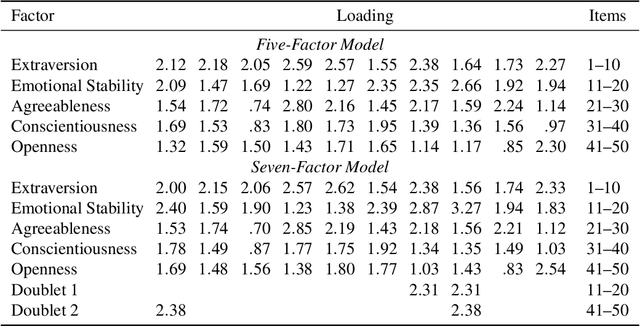
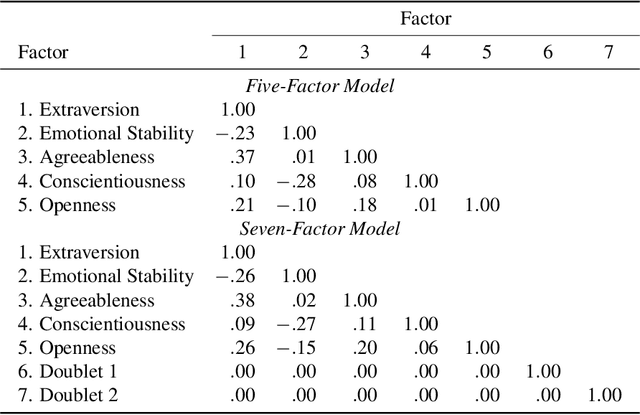
We investigate novel parameter estimation and goodness-of-fit (GOF) assessment methods for large-scale confirmatory item factor analysis (IFA) with many respondents, items, and latent factors. For parameter estimation, we extend Urban and Bauer's (2021) deep learning algorithm for exploratory IFA to the confirmatory setting by showing how to handle user-defined constraints on loadings and factor correlations. For GOF assessment, we explore new simulation-based tests and indices. In particular, we consider extensions of the classifier two-sample test (C2ST), a method that tests whether a machine learning classifier can distinguish between observed data and synthetic data sampled from a fitted IFA model. The C2ST provides a flexible framework that integrates overall model fit, piece-wise fit, and person fit. Proposed extensions include a C2ST-based test of approximate fit in which the user specifies what percentage of observed data can be distinguished from synthetic data as well as a C2ST-based relative fit index that is similar in spirit to the relative fit indices used in structural equation modeling. Via simulation studies, we first show that the confirmatory extension of Urban and Bauer's (2021) algorithm produces more accurate parameter estimates as the sample size increases and obtains comparable estimates to a state-of-the-art confirmatory IFA estimation procedure in less time. We next show that the C2ST-based test of approximate fit controls the empirical type I error rate and detects when the number of latent factors is misspecified. Finally, we empirically investigate how the sampling distribution of the C2ST-based relative fit index depends on the sample size.
Learning Interpretable Shapelets for Time Series Classification through Adversarial Regularization
Jun 03, 2019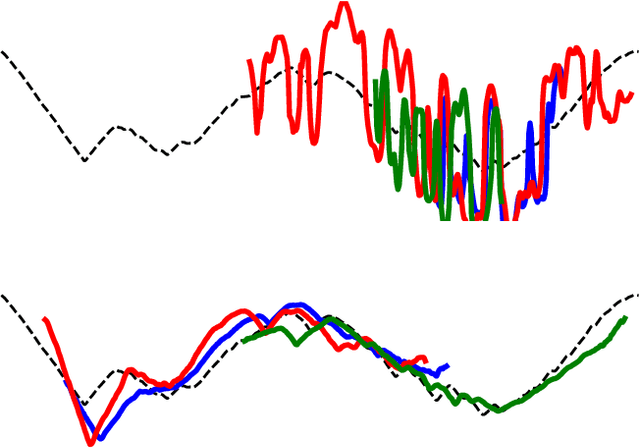
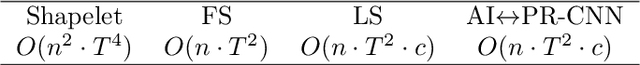
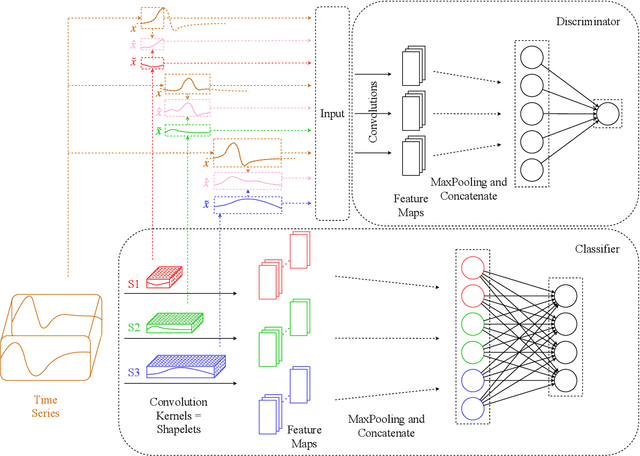
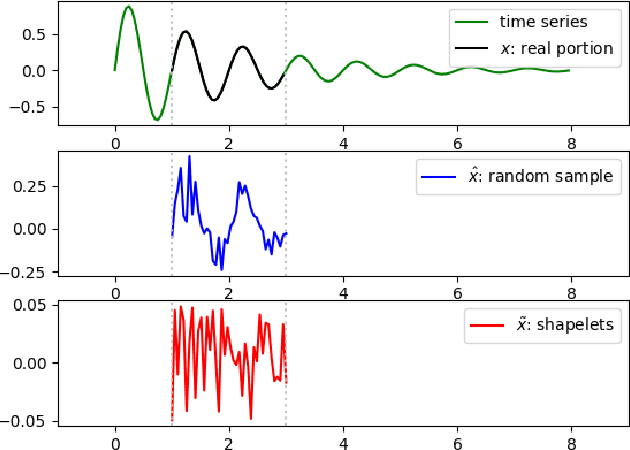
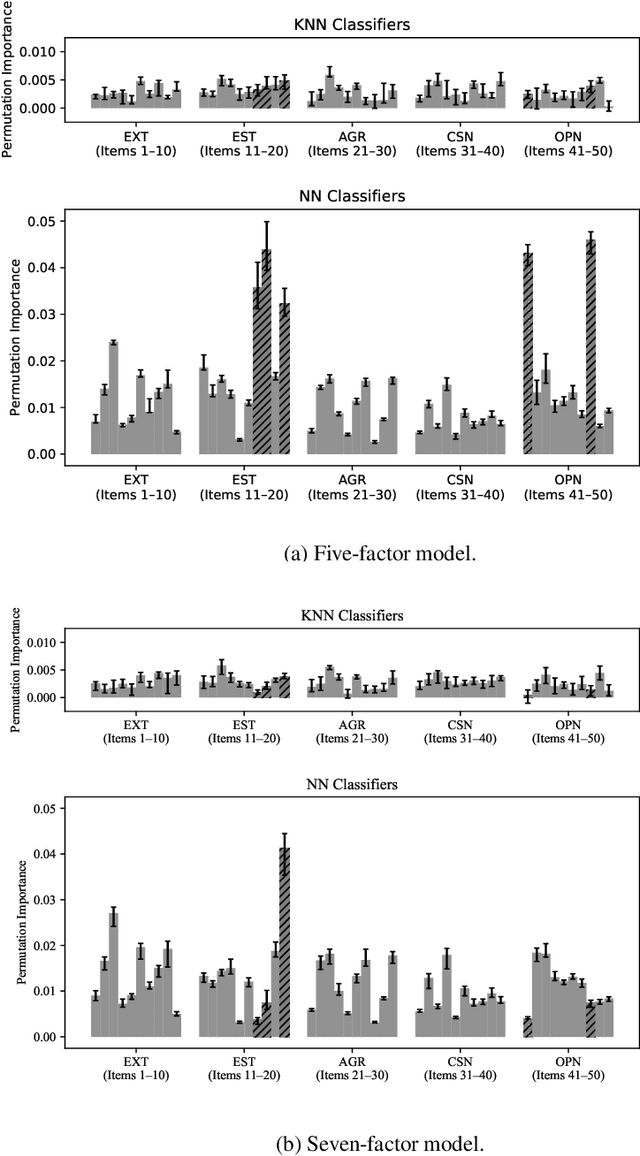
Times series classification can be successfully tackled by jointly learning a shapelet-based representation of the series in the dataset and classifying the series according to this representation. However, although the learned shapelets are discriminative, they are not always similar to pieces of a real series in the dataset. This makes it difficult to interpret the decision, i.e. difficult to analyze if there are particular behaviors in a series that triggered the decision. In this paper, we make use of a simple convolutional network to tackle the time series classification task and we introduce an adversarial regularization to constrain the model to learn more interpretable shapelets. Our classification results on all the usual time series benchmarks are comparable with the results obtained by similar state-of-the-art algorithms but our adversarially regularized method learns shapelets that are, by design, interpretable.
A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the United States
Sep 24, 2021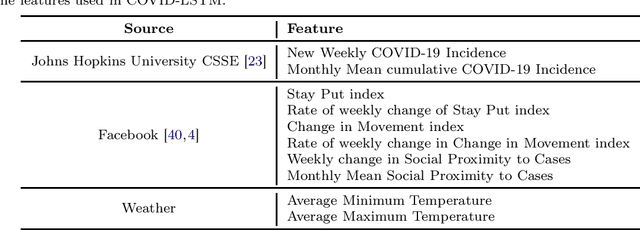
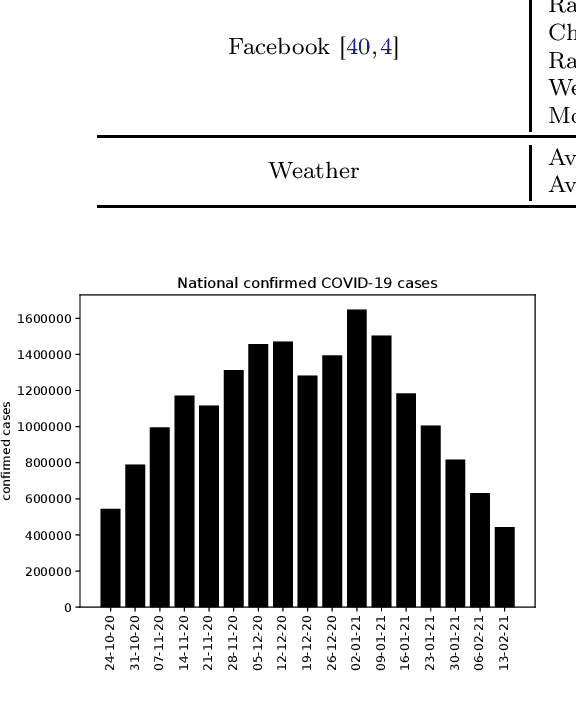
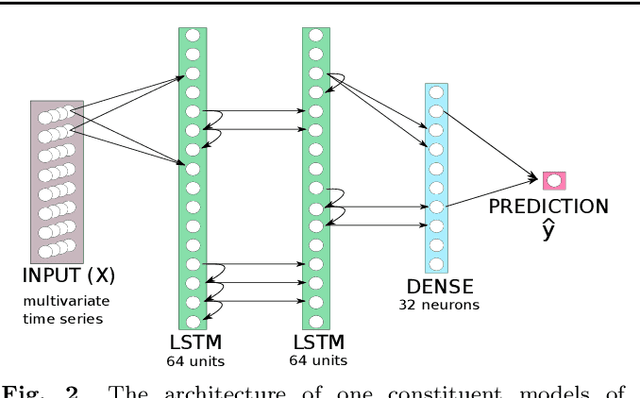
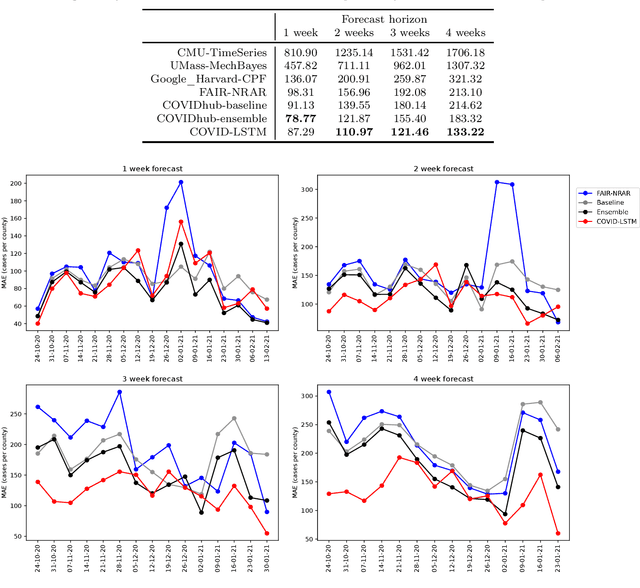
With COVID-19 affecting every country globally and changing everyday life, the ability to forecast the spread of the disease is more important than any previous epidemic. The conventional methods of disease-spread modeling, compartmental models, are based on the assumption of spatiotemporal homogeneity of the spread of the virus, which may cause forecasting to underperform, especially at high spatial resolutions. In this paper we approach the forecasting task with an alternative technique -- spatiotemporal machine learning. We present COVID-LSTM, a data-driven model based on a Long Short-term Memory deep learning architecture for forecasting COVID-19 incidence at the county-level in the US. We use the weekly number of new positive cases as temporal input, and hand-engineered spatial features from Facebook movement and connectedness datasets to capture the spread of the disease in time and space. COVID-LSTM outperforms the COVID-19 Forecast Hub's Ensemble model (COVIDhub-ensemble) on our 17-week evaluation period, making it the first model to be more accurate than the COVIDhub-ensemble over one or more forecast periods. Over the 4-week forecast horizon, our model is on average 50 cases per county more accurate than the COVIDhub-ensemble. We highlight that the underutilization of data-driven forecasting of disease spread prior to COVID-19 is likely due to the lack of sufficient data available for previous diseases, in addition to the recent advances in machine learning methods for spatiotemporal forecasting. We discuss the impediments to the wider uptake of data-driven forecasting, and whether it is likely that more deep learning-based models will be used in the future.
Precision and accuracy of acoustic gunshot location in an urban environment
Aug 16, 2021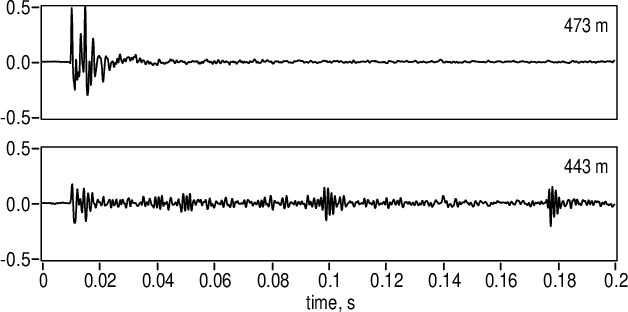

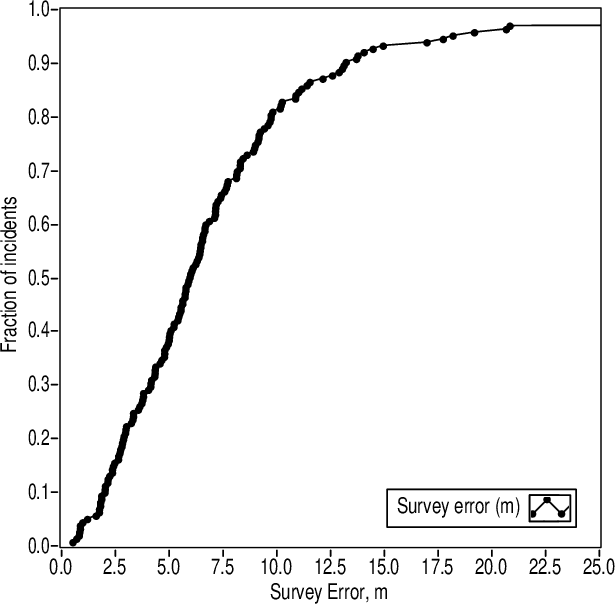
The muzzle blast caused by the discharge of a firearm generates a loud, impulsive sound that propagates away from the shooter in all directions. The location of the source can be computed from time-of-arrival measurements of the muzzle blast on multiple acoustic sensors at known locations, a technique known as multilateration. The multilateration problem is considerably simplified by assuming straight-line propagation in a homogeneous medium, a model for which there are multiple published solutions. Live-fire tests of the ShotSpotter gunshot location system in Pittsburgh, PA were analyzed off-line under several algorithms and geometric constraints to evaluate the accuracy of acoustic multilateration in a forensic context. Best results were obtained using the algorithm due to Mathias, Leonari and Galati under a two-dimensional geometric constraint. Multilateration on random subsets of the participating sensor array show that 96% of shots can be located to an accuracy of 15 m or better when six or more sensors participate in the solution.