 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Normal Learning in Videos with Attention Prototype Network
Aug 25, 2021
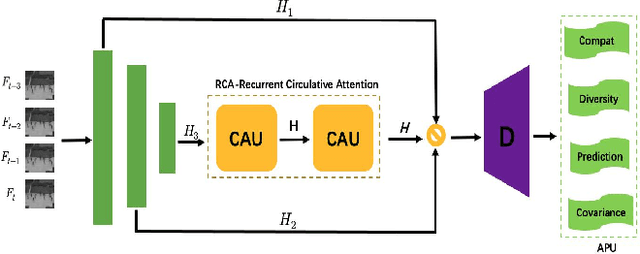
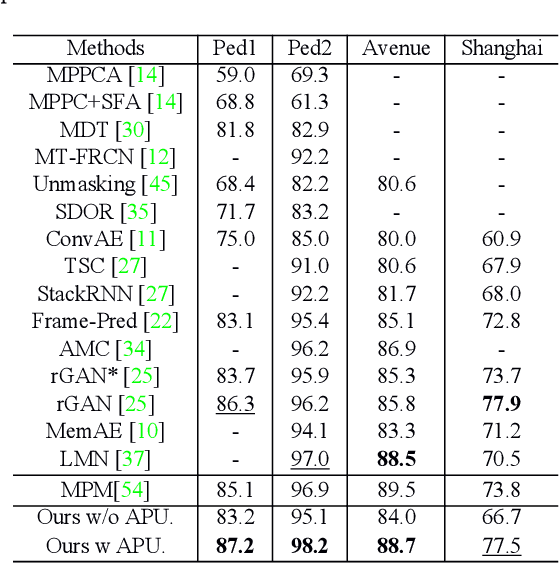
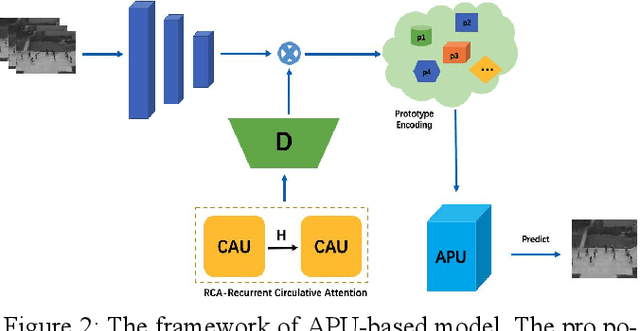
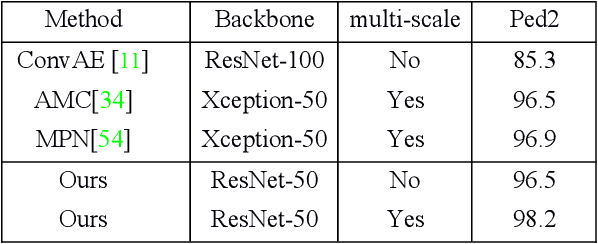
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a self-attention prototype unit (APU) to encode the normal latent space as prototypes in real time, free from extra memory cost. In addition, we introduce circulative attention mechanism to our backbone to form a novel feature extracting learner, namely Circulative Attention Unit (CAU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method. Our code is available at https://github.com/huchao-AI/APN/.
FDN: Finite Difference Network with Hierachical Convolutional Features for Text-independent Speaker verification
Aug 18, 2021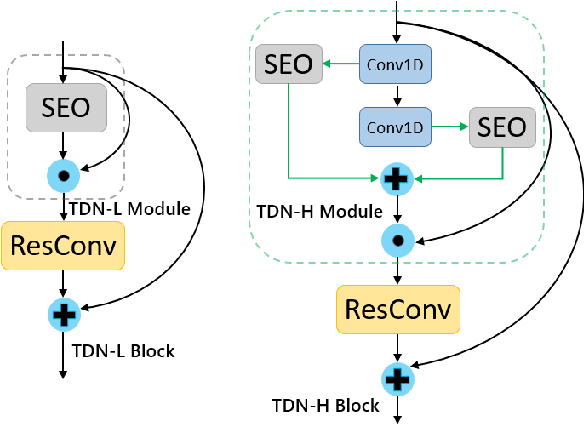
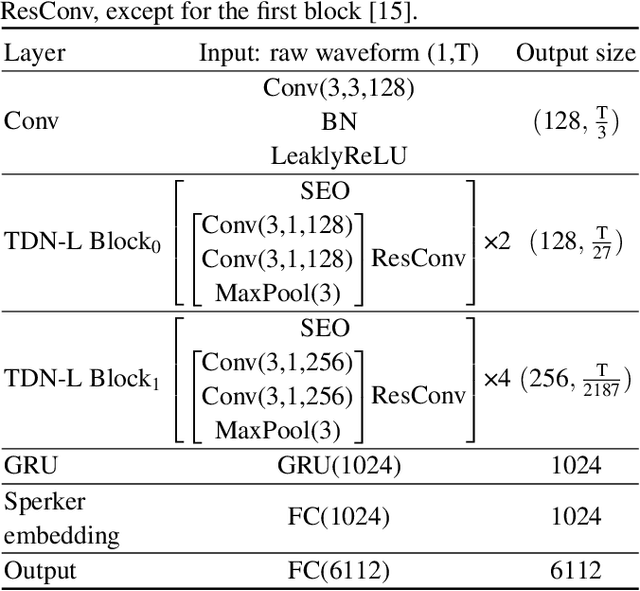
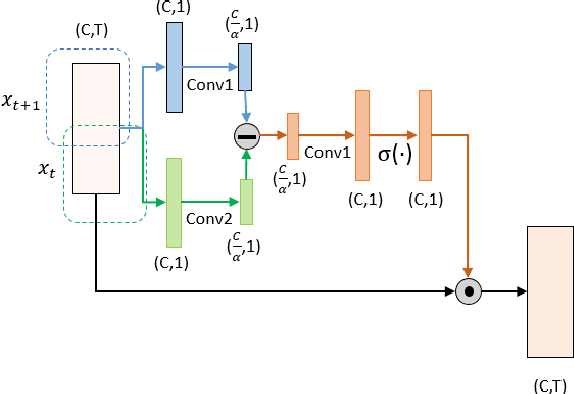
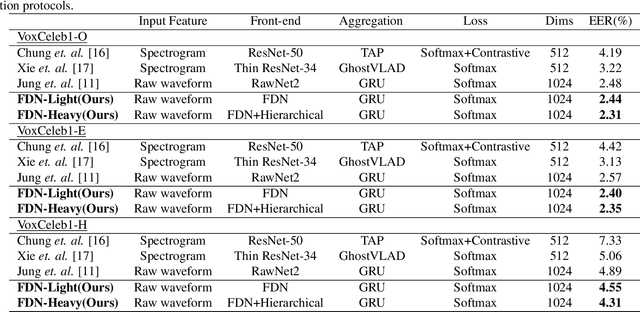
Recently, directly utilize raw waveforms as input is widely explored for the speaker verification system. For example, RawNet [1] and RawNet2 [2] extract feature embeddings from raw waveforms, which largely reduce the front-end computation and achieve state-of-the-art performance. However, they do not consider the speech speed influence which is different from person to person. In this paper, we propose a novel finite-difference network to obtain speaker embeddings. It incorporates speaker speech speed by computing the finite difference between adjacent time speech pieces. Furthermore, we design a hierarchical layer to capture multiscale speech speed features to improve the system accuracy. The speaker embeddings is then input into the GRU to aggregate utterance-level features before the softmax loss. Experiment results on official VoxCeleb1 test data and expanded evaluation on VoxCeleb1-E and VoxCeleb-H protocols show our method outperforms existing state-of-the-art systems. To facilitate further research, code is available at https://github.com/happyjin/FDN
Scalable regret for learning to control network-coupled subsystems with unknown dynamics
Aug 18, 2021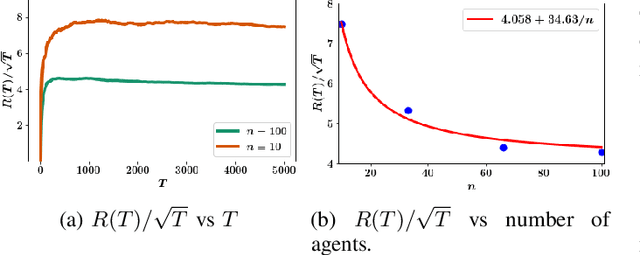
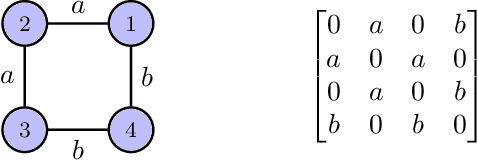
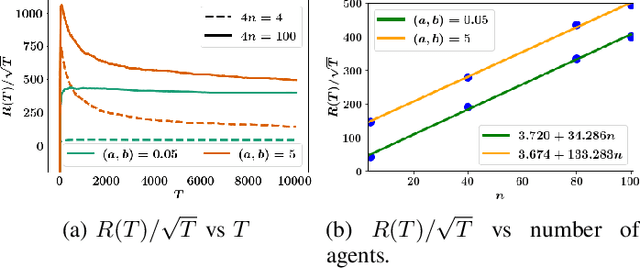
We consider the problem of controlling an unknown linear quadratic Gaussian (LQG) system consisting of multiple subsystems connected over a network. Our goal is to minimize and quantify the regret (i.e. loss in performance) of our strategy with respect to an oracle who knows the system model. Viewing the interconnected subsystems globally and directly using existing LQG learning algorithms for the global system results in a regret that increases super-linearly with the number of subsystems. Instead, we propose a new Thompson sampling based learning algorithm which exploits the structure of the underlying network. We show that the expected regret of the proposed algorithm is bounded by $\tilde{\mathcal{O}} \big( n \sqrt{T} \big)$ where $n$ is the number of subsystems, $T$ is the time horizon and the $\tilde{\mathcal{O}}(\cdot)$ notation hides logarithmic terms in $n$ and $T$. Thus, the regret scales linearly with the number of subsystems. We present numerical experiments to illustrate the salient features of the proposed algorithm.
Joint Multi-Object Detection and Tracking with Camera-LiDAR Fusion for Autonomous Driving
Aug 10, 2021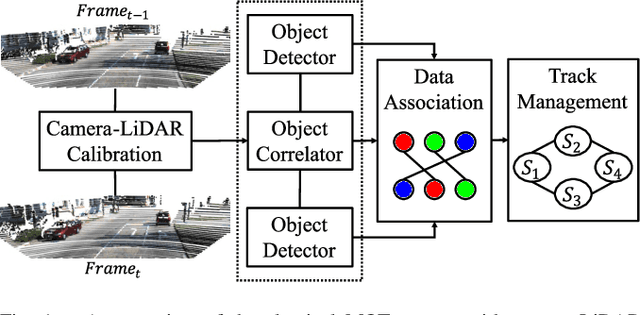
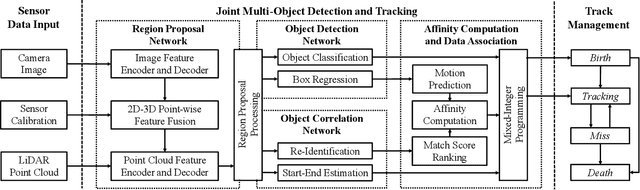
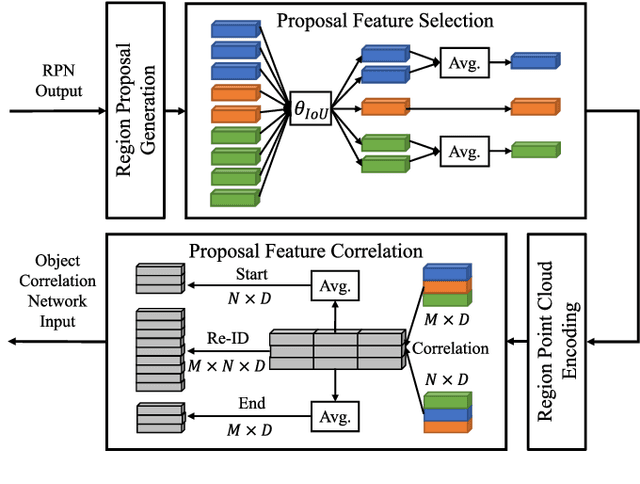
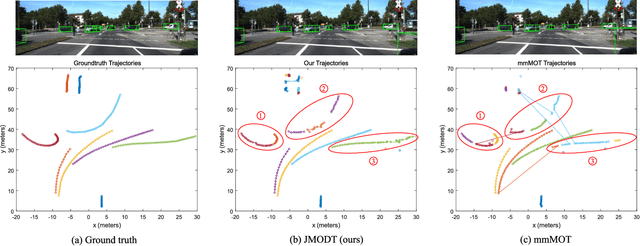
Multi-object tracking (MOT) with camera-LiDAR fusion demands accurate results of object detection, affinity computation and data association in real time. This paper presents an efficient multi-modal MOT framework with online joint detection and tracking schemes and robust data association for autonomous driving applications. The novelty of this work includes: (1) development of an end-to-end deep neural network for joint object detection and correlation using 2D and 3D measurements; (2) development of a robust affinity computation module to compute occlusion-aware appearance and motion affinities in 3D space; (3) development of a comprehensive data association module for joint optimization among detection confidences, affinities and start-end probabilities. The experiment results on the KITTI tracking benchmark demonstrate the superior performance of the proposed method in terms of both tracking accuracy and processing speed.
One-shot domain adaptation for semantic face editing of real world images using StyleALAE
Aug 31, 2021

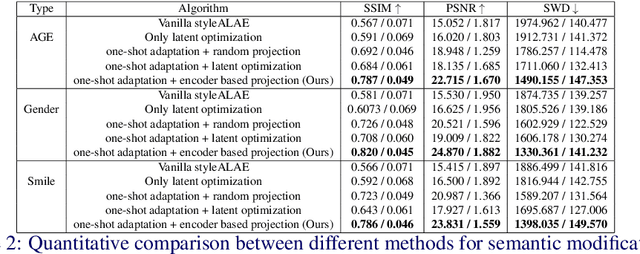

Semantic face editing of real world facial images is an important application of generative models. Recently, multiple works have explored possible techniques to generate such modifications using the latent structure of pre-trained GAN models. However, such approaches often require training an encoder network and that is typically a time-consuming and resource intensive process. A possible alternative to such a GAN-based architecture can be styleALAE, a latent-space based autoencoder that can generate photo-realistic images of high quality. Unfortunately, the reconstructed image in styleALAE does not preserve the identity of the input facial image. This limits the application of styleALAE for semantic face editing of images with known identities. In our work, we use a recent advancement in one-shot domain adaptation to address this problem. Our work ensures that the identity of the reconstructed image is the same as the given input image. We further generate semantic modifications over the reconstructed image by using the latent space of the pre-trained styleALAE model. Results show that our approach can generate semantic modifications on any real world facial image while preserving the identity.
Learned super resolution ultrasound for improved breast lesion characterization
Jul 12, 2021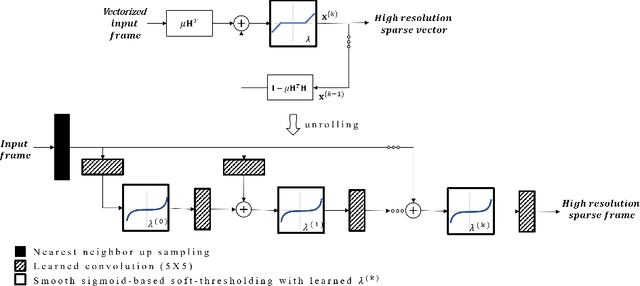
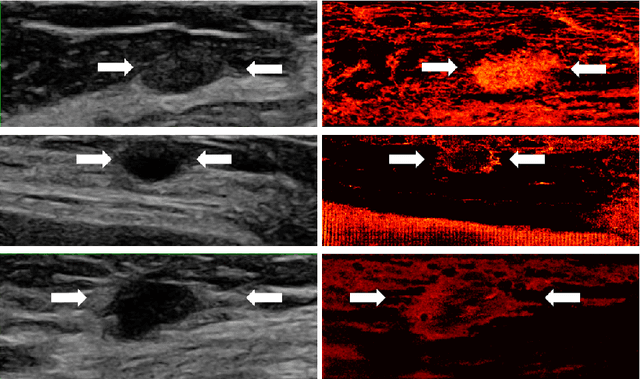

Breast cancer is the most common malignancy in women. Mammographic findings such as microcalcifications and masses, as well as morphologic features of masses in sonographic scans, are the main diagnostic targets for tumor detection. However, improved specificity of these imaging modalities is required. A leading alternative target is neoangiogenesis. When pathological, it contributes to the development of numerous types of tumors, and the formation of metastases. Hence, demonstrating neoangiogenesis by visualization of the microvasculature may be of great importance. Super resolution ultrasound localization microscopy enables imaging of the microvasculature at the capillary level. Yet, challenges such as long reconstruction time, dependency on prior knowledge of the system Point Spread Function (PSF), and separability of the Ultrasound Contrast Agents (UCAs), need to be addressed for translation of super-resolution US into the clinic. In this work we use a deep neural network architecture that makes effective use of signal structure to address these challenges. We present in vivo human results of three different breast lesions acquired with a clinical US scanner. By leveraging our trained network, the microvasculature structure is recovered in a short time, without prior PSF knowledge, and without requiring separability of the UCAs. Each of the recoveries exhibits a different structure that corresponds with the known histological structure. This study demonstrates the feasibility of in vivo human super resolution, based on a clinical scanner, to increase US specificity for different breast lesions and promotes the use of US in the diagnosis of breast pathologies.
Adversarial Generation of Time-Frequency Features with application in audio synthesis
Feb 11, 2019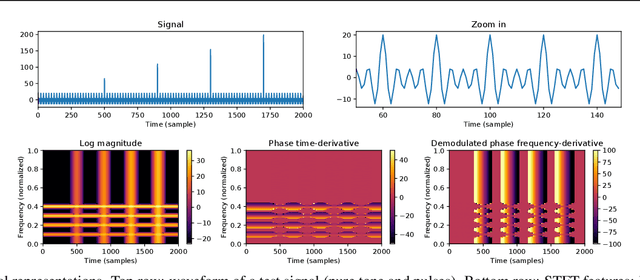

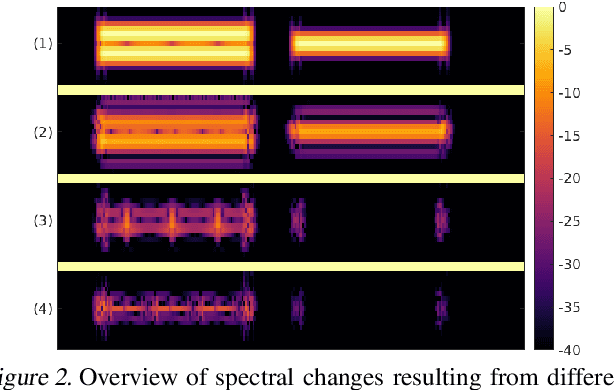
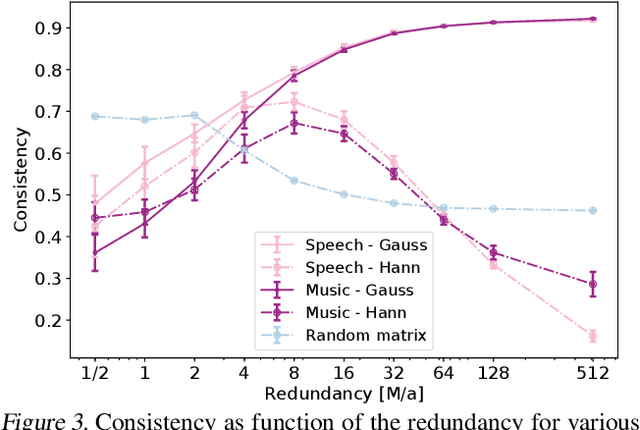
Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them. We demonstrate the potential of deliberate generative TF modeling by training a generative adversarial network (GAN) on short-time Fourier features. We show that our TF-based network was able to outperform the state-of-the-art GAN generating waveform, despite the similar architecture in the two networks.
An Approach for Time-aware Domain-based Social Influence Prediction
Jan 19, 2020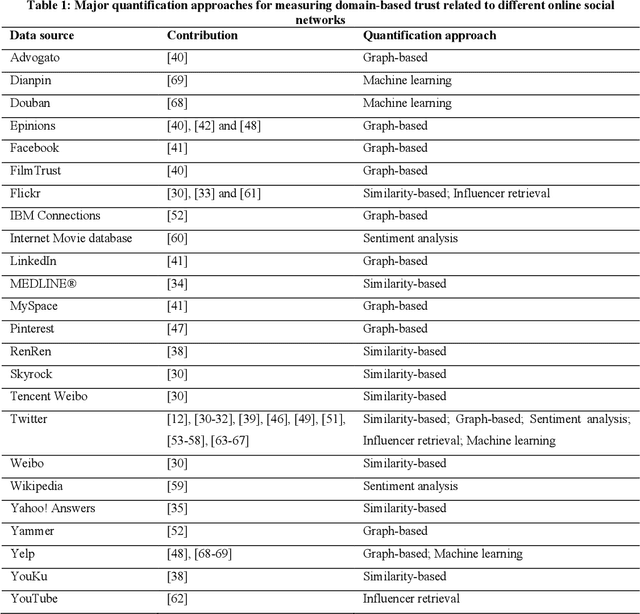
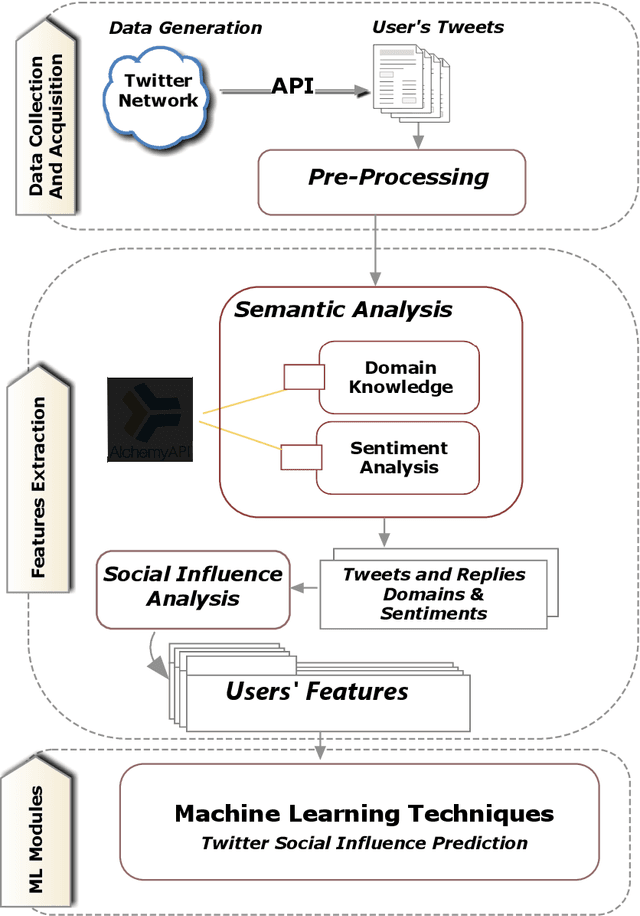

Online Social Networks(OSNs) have established virtual platforms enabling people to express their opinions, interests and thoughts in a variety of contexts and domains, allowing legitimate users as well as spammers and other untrustworthy users to publish and spread their content. Hence, the concept of social trust has attracted the attention of information processors/data scientists and information consumers/business firms. One of the main reasons for acquiring the value of Social Big Data (SBD) is to provide frameworks and methodologies using which the credibility of OSNs users can be evaluated. These approaches should be scalable to accommodate large-scale social data. Hence, there is a need for well comprehending of social trust to improve and expand the analysis process and inferring the credibility of SBD. Given the exposed environment's settings and fewer limitations related to OSNs, the medium allows legitimate and genuine users as well as spammers and other low trustworthy users to publish and spread their content. Hence, this paper presents an approach incorporates semantic analysis and machine learning modules to measure and predict users' trustworthiness in numerous domains in different time periods. The evaluation of the conducted experiment validates the applicability of the incorporated machine learning techniques to predict highly trustworthy domain-based users.
Contributions to Large Scale Bayesian Inference and Adversarial Machine Learning
Sep 25, 2021
The rampant adoption of ML methodologies has revealed that models are usually adopted to make decisions without taking into account the uncertainties in their predictions. More critically, they can be vulnerable to adversarial examples. Thus, we believe that developing ML systems that take into account predictive uncertainties and are robust against adversarial examples is a must for critical, real-world tasks. We start with a case study in retailing. We propose a robust implementation of the Nerlove-Arrow model using a Bayesian structural time series model. Its Bayesian nature facilitates incorporating prior information reflecting the manager's views, which can be updated with relevant data. However, this case adopted classical Bayesian techniques, such as the Gibbs sampler. Nowadays, the ML landscape is pervaded with neural networks and this chapter also surveys current developments in this sub-field. Then, we tackle the problem of scaling Bayesian inference to complex models and large data regimes. In the first part, we propose a unifying view of two different Bayesian inference algorithms, Stochastic Gradient Markov Chain Monte Carlo (SG-MCMC) and Stein Variational Gradient Descent (SVGD), leading to improved and efficient novel sampling schemes. In the second part, we develop a framework to boost the efficiency of Bayesian inference in probabilistic models by embedding a Markov chain sampler within a variational posterior approximation. After that, we present an alternative perspective on adversarial classification based on adversarial risk analysis, and leveraging the scalable Bayesian approaches from chapter 2. In chapter 4 we turn to reinforcement learning, introducing Threatened Markov Decision Processes, showing the benefits of accounting for adversaries in RL while the agent learns.
Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations
Aug 01, 2021We present polynomial time and sample efficient algorithms for learning an unknown depth-2 feedforward neural network with general ReLU activations, under mild non-degeneracy assumptions. In particular, we consider learning an unknown network of the form $f(x) = {a}^{\mathsf{T}}\sigma({W}^\mathsf{T}x+b)$, where $x$ is drawn from the Gaussian distribution, and $\sigma(t) := \max(t,0)$ is the ReLU activation. Prior works for learning networks with ReLU activations assume that the bias $b$ is zero. In order to deal with the presence of the bias terms, our proposed algorithm consists of robustly decomposing multiple higher order tensors arising from the Hermite expansion of the function $f(x)$. Using these ideas we also establish identifiability of the network parameters under minimal assumptions.