 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Surgery Scene Restoration for Robot Assisted Minimally Invasive Surgery
Sep 06, 2021
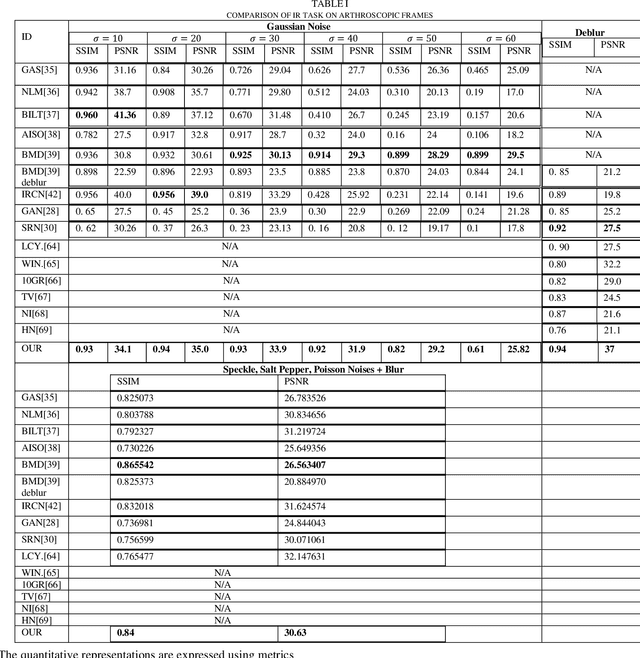
Minimally invasive surgery (MIS) offers several advantages including minimum tissue injury and blood loss, and quick recovery time, however, it imposes some limitations on surgeons ability. Among others such as lack of tactile or haptic feedback, poor visualization of the surgical site is one of the most acknowledged factors that exhibits several surgical drawbacks including unintentional tissue damage. To the context of robot assisted surgery, lack of frame contextual details makes vision task challenging when it comes to tracking tissue and tools, segmenting scene, and estimating pose and depth. In MIS the acquired frames are compromised by different noises and get blurred caused by motions from different sources. Moreover, when underwater environment is considered for instance knee arthroscopy, mostly visible noises and blur effects are originated from the environment, poor control on illuminations and imaging conditions. Additionally, in MIS, procedure like automatic white balancing and transformation between the raw color information to its standard RGB color space are often absent due to the hardware miniaturization. There is a high demand of an online preprocessing framework that can circumvent these drawbacks. Our proposed method is able to restore a latent clean and sharp image in standard RGB color space from its noisy, blur and raw observation in a single preprocessing stage.
Splitting EUD graphs into trees: A quick and clatty approach
Jul 18, 2021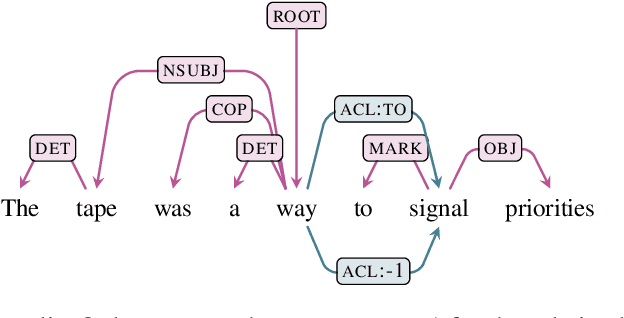
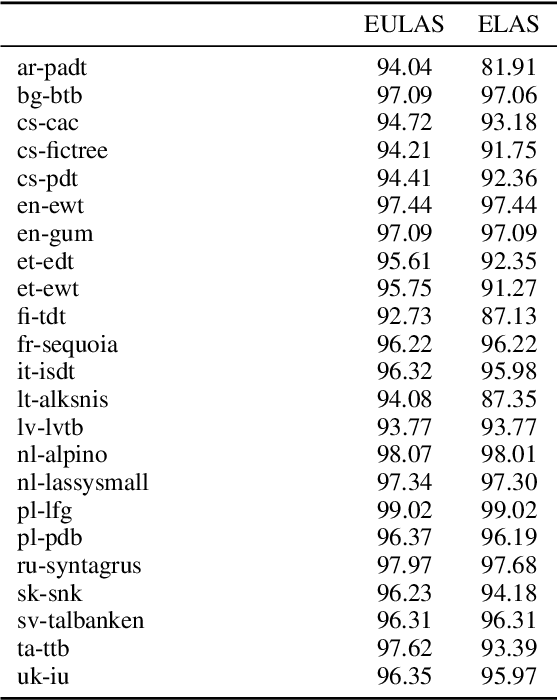
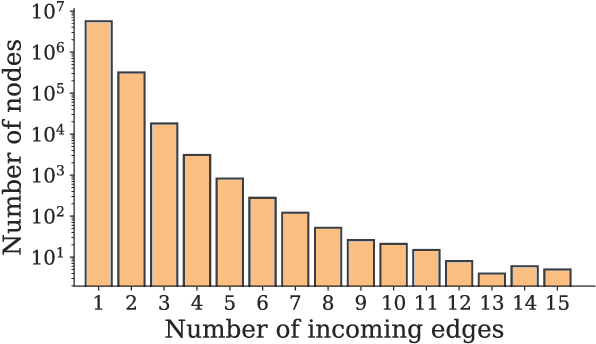
We present the system submission from the FASTPARSE team for the EUD Shared Task at IWPT 2021. We engaged in the task last year by focusing on efficiency. This year we have focused on experimenting with new ideas on a limited time budget. Our system is based on splitting the EUD graph into several trees, based on linguistic criteria. We predict these trees using a sequence-labelling parser and combine them into an EUD graph. The results were relatively poor, although not a total disaster and could probably be improved with some polishing of the system's rough edges.
Quantifying the Reproducibility of Graph Neural Networks using Multigraph Brain Data
Sep 06, 2021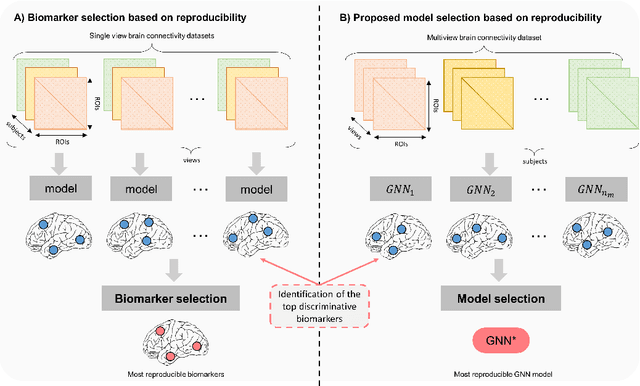
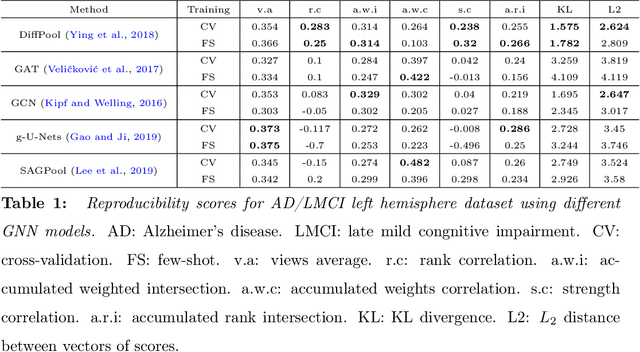
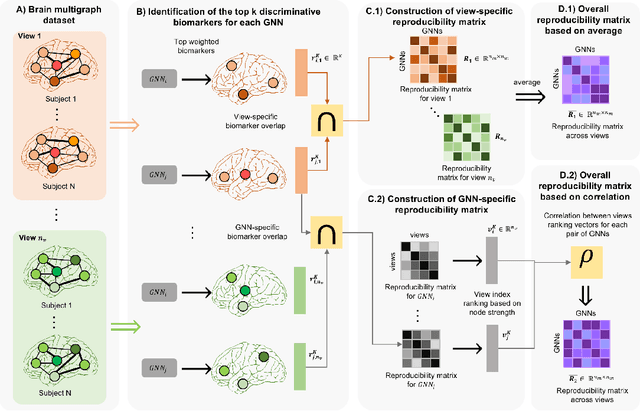
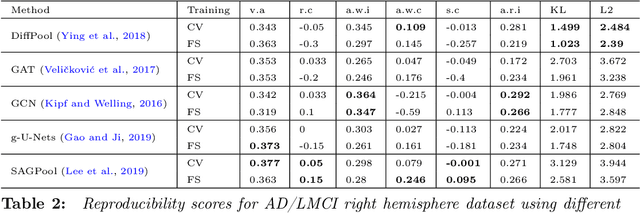
Graph neural networks (GNNs) have witnessed an unprecedented proliferation in tackling several problems in computer vision, computer-aided diagnosis, and related fields. While prior studies have focused on boosting the model accuracy, quantifying the reproducibility of the most discriminative features identified by GNNs is still an intact problem that yields concerns about their reliability in clinical applications in particular. Specifically, the reproducibility of biological markers across clinical datasets and distribution shifts across classes (e.g., healthy and disordered brains) is of paramount importance in revealing the underpinning mechanisms of diseases as well as propelling the development of personalized treatment. Motivated by these issues, we propose, for the first time, reproducibility-based GNN selection (RG-Select), a framework for GNN reproducibility assessment via the quantification of the most discriminative features (i.e., biomarkers) shared between different models. To ascertain the soundness of our framework, the reproducibility assessment embraces variations of different factors such as training strategies and data perturbations. Despite these challenges, our framework successfully yielded replicable conclusions across different training strategies and various clinical datasets. Our findings could thus pave the way for the development of biomarker trustworthiness and reliability assessment methods for computer-aided diagnosis and prognosis tasks. RG-Select code is available on GitHub at https://github.com/basiralab/RG-Select.
Real-time monitoring of driver drowsiness on mobile platforms using 3D neural networks
Oct 15, 2019

Driver drowsiness increases crash risk, leading to substantial road trauma each year. Drowsiness detection methods have received considerable attention, but few studies have investigated the implementation of a detection approach on a mobile phone. Phone applications reduce the need for specialised hardware and hence, enable a cost-effective roll-out of the technology across the driving population. While it has been shown that three-dimensional (3D) operations are more suitable for spatiotemporal feature learning, current methods for drowsiness detection commonly use frame-based, multi-step approaches. However, computationally expensive techniques that achieve superior results on action recognition benchmarks (e.g. 3D convolutions, optical flow extraction) create bottlenecks for real-time, safety-critical applications on mobile devices. Here, we show how depthwise separable 3D convolutions, combined with an early fusion of spatial and temporal information, can achieve a balance between high prediction accuracy and real-time inference requirements. In particular, increased accuracy is achieved when assessment requires motion information, for example, when sunglasses conceal the eyes. Further, a custom TensorFlow-based smartphone application shows the true impact of various approaches on inference times and demonstrates the effectiveness of real-time monitoring based on out-of-sample data to alert a drowsy driver. Our model is pre-trained on ImageNet and Kinetics and fine-tuned on a publicly available Driver Drowsiness Detection dataset. Fine-tuning on large naturalistic driving datasets could further improve accuracy to obtain robust in-vehicle performance. Overall, our research is a step towards practical deep learning applications, potentially preventing micro-sleeps and reducing road trauma.
* 13 pages, 2 figures, 'Online First' version. For associated mp4 files, see journal website
Image Complexity Guided Network Compression for Biomedical Image Segmentation
Jul 06, 2021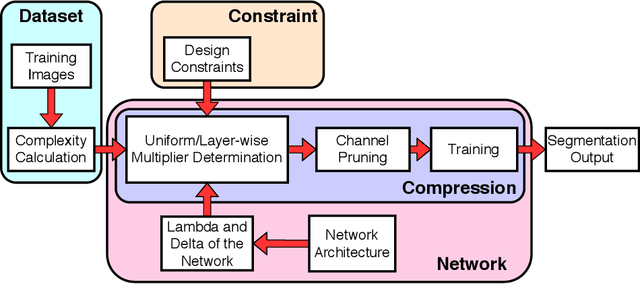
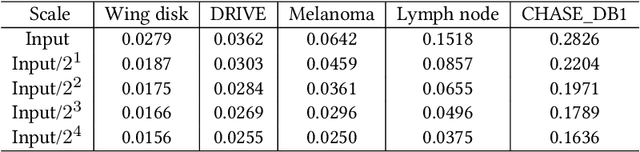
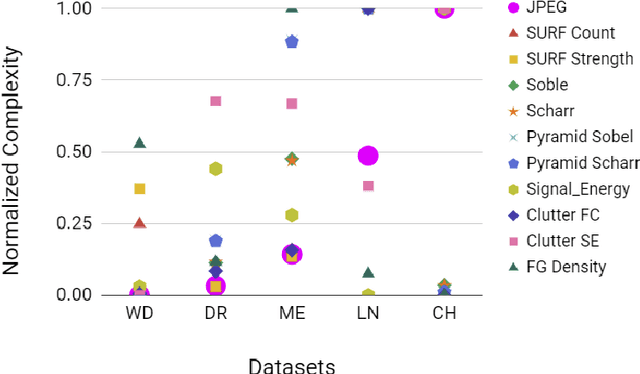
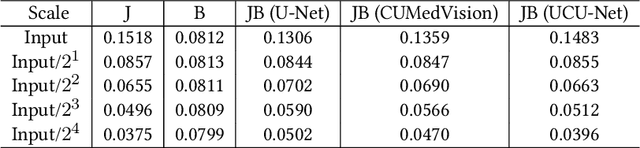
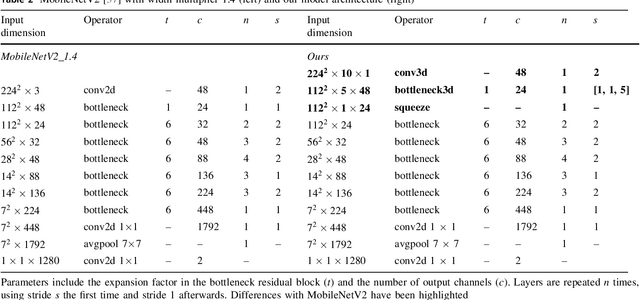
Compression is a standard procedure for making convolutional neural networks (CNNs) adhere to some specific computing resource constraints. However, searching for a compressed architecture typically involves a series of time-consuming training/validation experiments to determine a good compromise between network size and performance accuracy. To address this, we propose an image complexity-guided network compression technique for biomedical image segmentation. Given any resource constraints, our framework utilizes data complexity and network architecture to quickly estimate a compressed model which does not require network training. Specifically, we map the dataset complexity to the target network accuracy degradation caused by compression. Such mapping enables us to predict the final accuracy for different network sizes, based on the computed dataset complexity. Thus, one may choose a solution that meets both the network size and segmentation accuracy requirements. Finally, the mapping is used to determine the convolutional layer-wise multiplicative factor for generating a compressed network. We conduct experiments using 5 datasets, employing 3 commonly-used CNN architectures for biomedical image segmentation as representative networks. Our proposed framework is shown to be effective for generating compressed segmentation networks, retaining up to $\approx 95\%$ of the full-sized network segmentation accuracy, and at the same time, utilizing $\approx 32x$ fewer network trainable weights (average reduction) of the full-sized networks.
Improved Image Matting via Real-time User Clicks and Uncertainty Estimation
Dec 15, 2020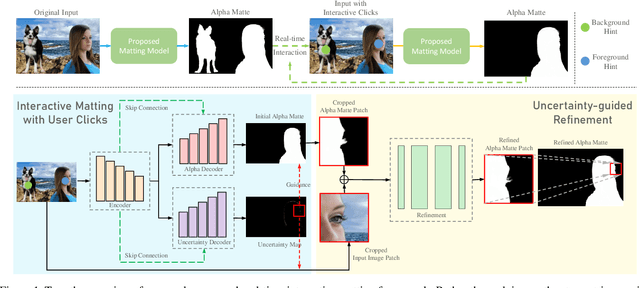
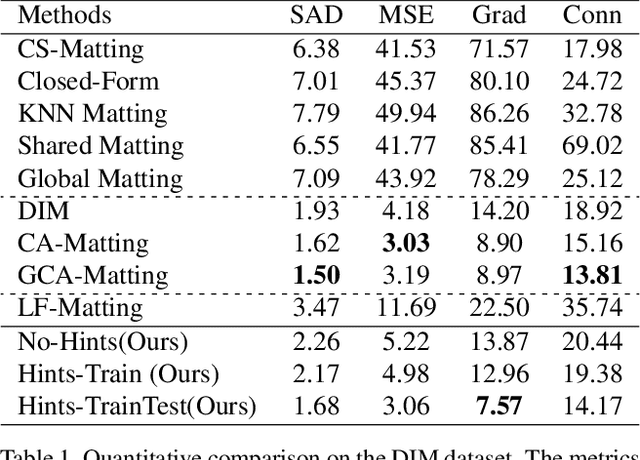

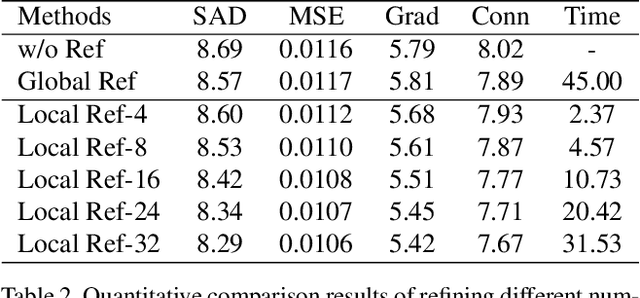
Image matting is a fundamental and challenging problem in computer vision and graphics. Most existing matting methods leverage a user-supplied trimap as an auxiliary input to produce good alpha matte. However, obtaining high-quality trimap itself is arduous, thus restricting the application of these methods. Recently, some trimap-free methods have emerged, however, the matting quality is still far behind the trimap-based methods. The main reason is that, without the trimap guidance in some cases, the target network is ambiguous about which is the foreground target. In fact, choosing the foreground is a subjective procedure and depends on the user's intention. To this end, this paper proposes an improved deep image matting framework which is trimap-free and only needs several user click interactions to eliminate the ambiguity. Moreover, we introduce a new uncertainty estimation module that can predict which parts need polishing and a following local refinement module. Based on the computation budget, users can choose how many local parts to improve with the uncertainty guidance. Quantitative and qualitative results show that our method performs better than existing trimap-free methods and comparably to state-of-the-art trimap-based methods with minimal user effort.
Always Be Dreaming: A New Approach for Data-Free Class-Incremental Learning
Jun 17, 2021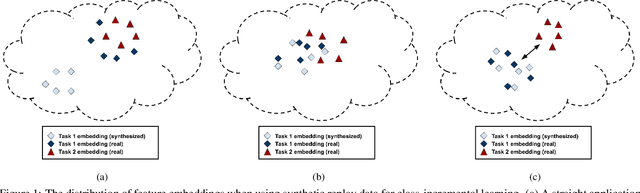
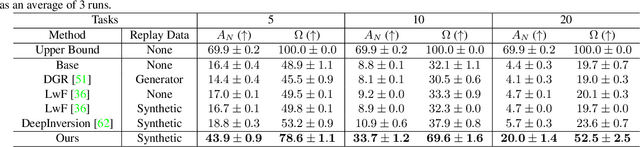
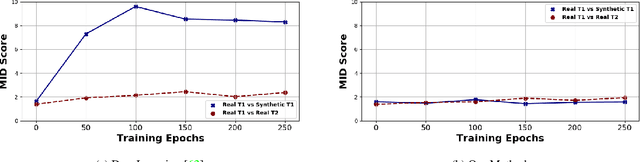

Modern computer vision applications suffer from catastrophic forgetting when incrementally learning new concepts over time. The most successful approaches to alleviate this forgetting require extensive replay of previously seen data, which is problematic when memory constraints or data legality concerns exist. In this work, we consider the high-impact problem of Data-Free Class-Incremental Learning (DFCIL), where an incremental learning agent must learn new concepts over time without storing generators or training data from past tasks. One approach for DFCIL is to replay synthetic images produced by inverting a frozen copy of the learner's classification model, but we show this approach fails for common class-incremental benchmarks when using standard distillation strategies. We diagnose the cause of this failure and propose a novel incremental distillation strategy for DFCIL, contributing a modified cross-entropy training and importance-weighted feature distillation, and show that our method results in up to a 25.1% increase in final task accuracy (absolute difference) compared to SOTA DFCIL methods for common class-incremental benchmarks. Our method even outperforms several standard replay based methods which store a coreset of images.
Continual Novelty Detection
Jun 24, 2021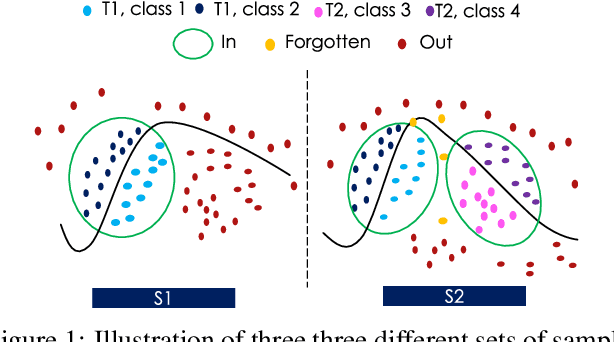

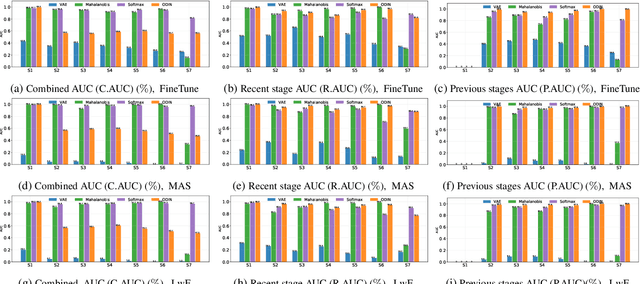

Novelty Detection methods identify samples that are not representative of a model's training set thereby flagging misleading predictions and bringing a greater flexibility and transparency at deployment time. However, research in this area has only considered Novelty Detection in the offline setting. Recently, there has been a growing realization in the computer vision community that applications demand a more flexible framework - Continual Learning - where new batches of data representing new domains, new classes or new tasks become available at different points in time. In this setting, Novelty Detection becomes more important, interesting and challenging. This work identifies the crucial link between the two problems and investigates the Novelty Detection problem under the Continual Learning setting. We formulate the Continual Novelty Detection problem and present a benchmark, where we compare several Novelty Detection methods under different Continual Learning settings. We show that Continual Learning affects the behaviour of novelty detection algorithms, while novelty detection can pinpoint insights in the behaviour of a continual learner. We further propose baselines and discuss possible research directions. We believe that the coupling of the two problems is a promising direction to bring vision models into practice.
Planning Jerk-Optimized Trajectory with Discrete-Time Constraints for Redundant Robots
Sep 14, 2019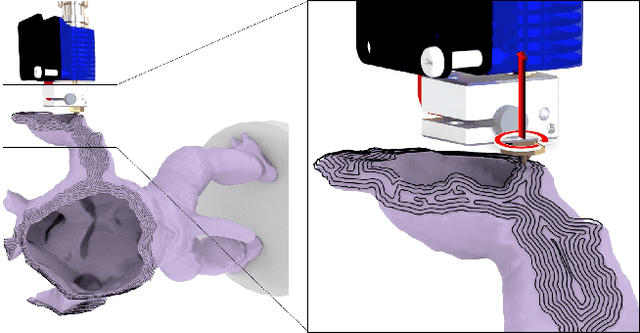
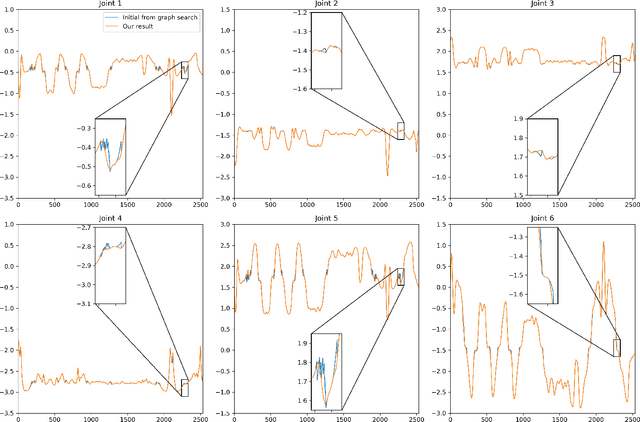
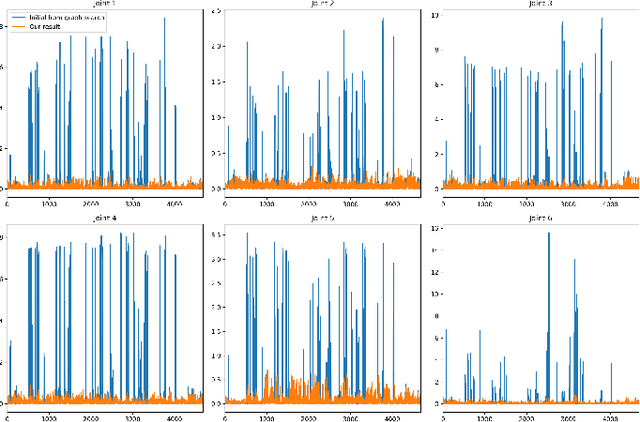
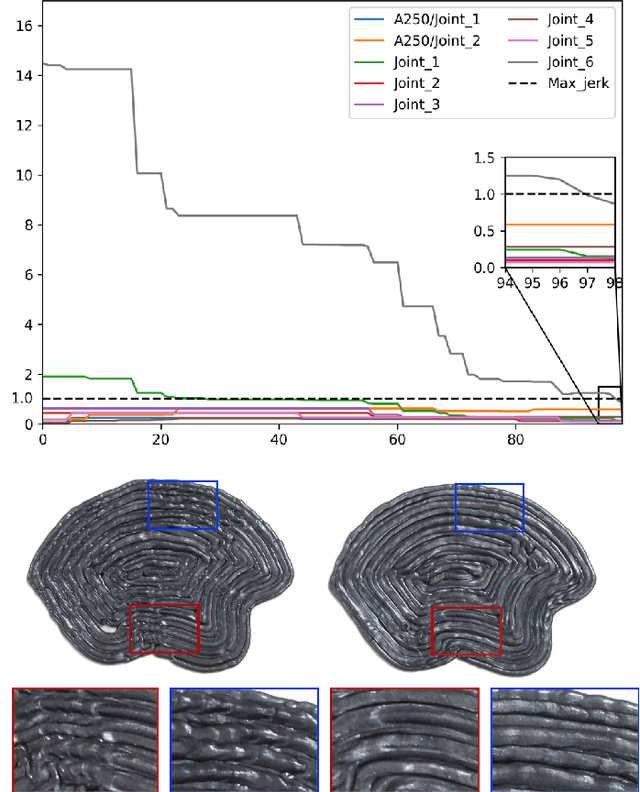
We present a method for effectively planning the motion trajectory of robots in manufacturing tasks, the tool-paths of which are usually complex and have a large number of discrete-time constraints as waypoints. Kinematic redundancy also exists in these robotic systems. The jerk of motion is optimized in our trajectory planning method at the meanwhile of fabrication process to improve the quality of fabrication.
Multivariate Time Series Imputation with Variational Autoencoders
Jul 11, 2019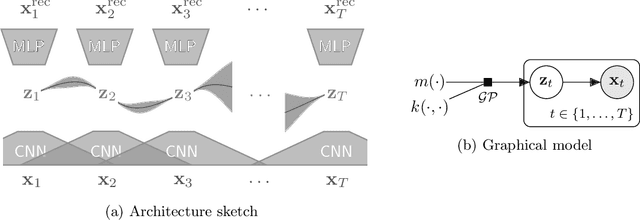

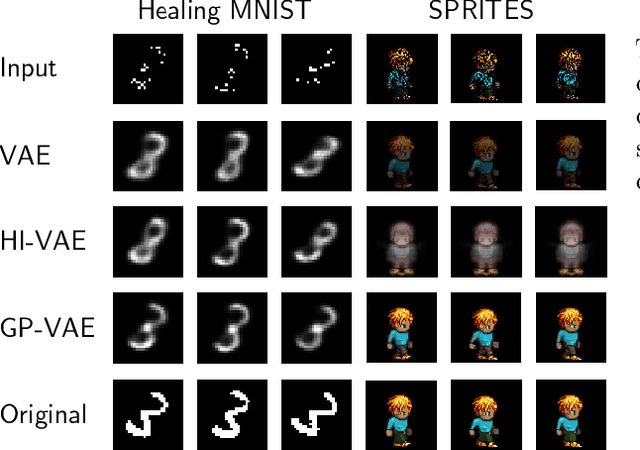
Multivariate time series with missing values are common in many areas, for instance in healthcare and finance. To face this problem, modern data imputation approaches should (a) be tailored to sequential data, (b) deal with high dimensional and complex data distributions, and (c) be based on the probabilistic modeling paradigm for interpretability and confidence assessment. However, many current approaches fall short in at least one of these aspects. Drawing on advances in deep learning and scalable probabilistic modeling, we propose a new deep sequential variational autoencoder approach for dimensionality reduction and data imputation. Temporal dependencies are modeled with a Gaussian process prior and a Cauchy kernel to reflect multi-scale dynamics in the latent space. We furthermore use a structured variational inference distribution that improves the scalability of the approach. We demonstrate that our model exhibits superior imputation performance on benchmark tasks and challenging real-world medical data.