 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep SIMBAD: Active Landmark-based Self-localization Using Ranking -based Scene Descriptor
Sep 06, 2021

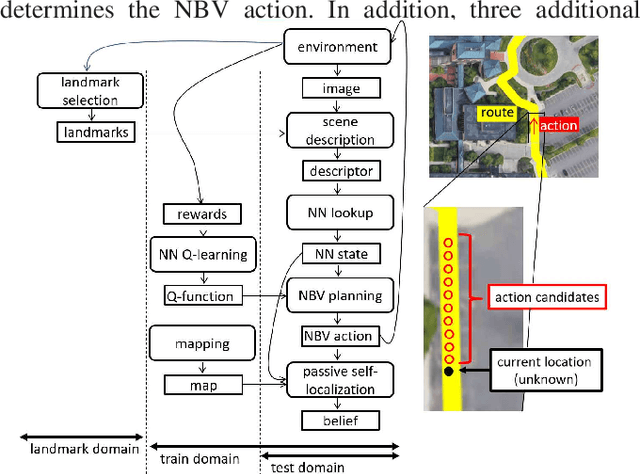
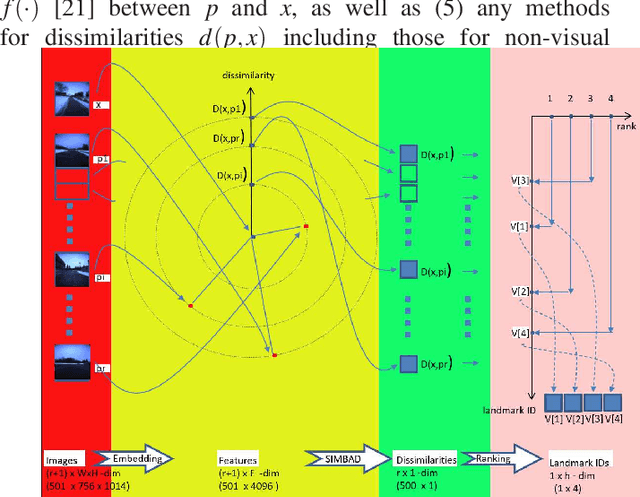
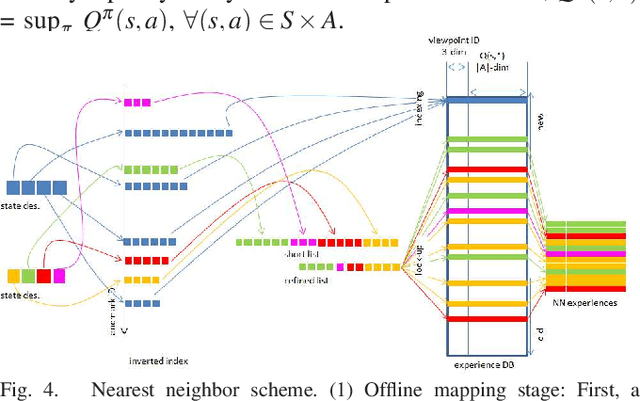
Landmark-based robot self-localization has recently garnered interest as a highly-compressive domain-invariant approach for performing visual place recognition (VPR) across domains (e.g., time of day, weather, and season). However, landmark-based self-localization can be an ill-posed problem for a passive observer (e.g., manual robot control), as many viewpoints may not provide an effective landmark view. In this study, we consider an active self-localization task by an active observer and present a novel reinforcement learning (RL)-based next-best-view (NBV) planner. Our contributions are as follows. (1) SIMBAD-based VPR: We formulate the problem of landmark-based compact scene description as SIMBAD (similarity-based pattern recognition) and further present its deep learning extension. (2) VPR-to-NBV knowledge transfer: We address the challenge of RL under uncertainty (i.e., active self-localization) by transferring the state recognition ability of VPR to the NBV. (3) NNQL-based NBV: We regard the available VPR as the experience database by adapting nearest-neighbor approximation of Q-learning (NNQL). The result shows an extremely compact data structure that compresses both the VPR and NBV into a single incremental inverted index. Experiments using the public NCLT dataset validated the effectiveness of the proposed approach.
Model-based Decision Making with Imagination for Autonomous Parking
Aug 25, 2021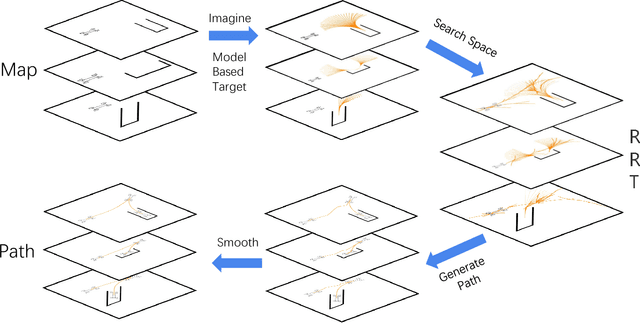
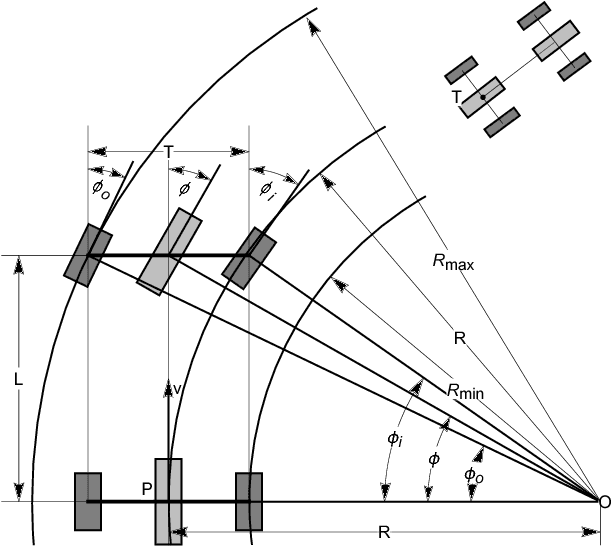
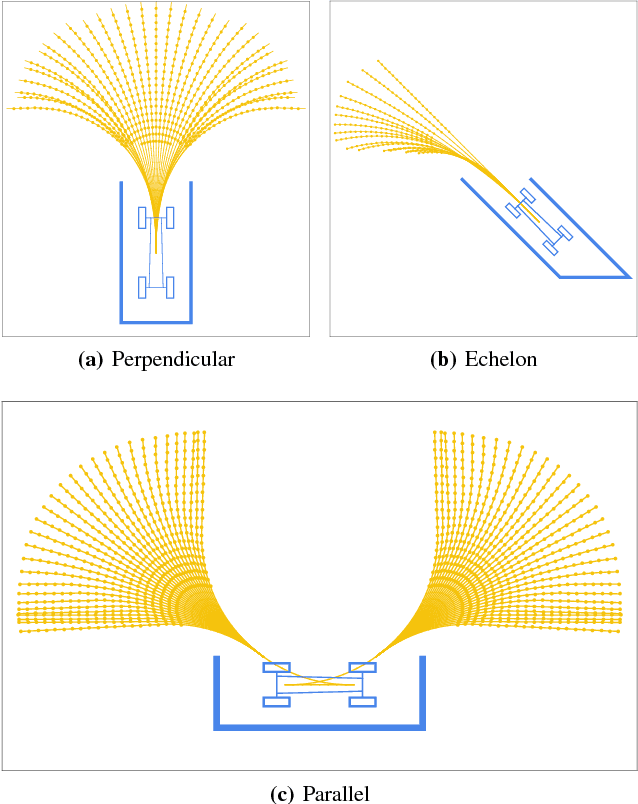
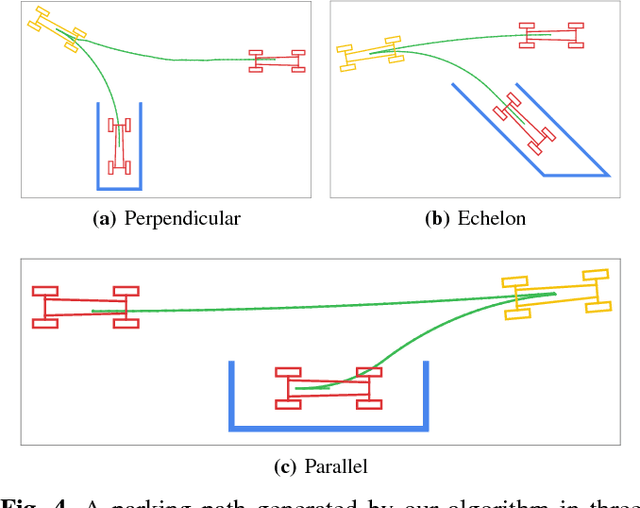
Autonomous parking technology is a key concept within autonomous driving research. This paper will propose an imaginative autonomous parking algorithm to solve issues concerned with parking. The proposed algorithm consists of three parts: an imaginative model for anticipating results before parking, an improved rapid-exploring random tree (RRT) for planning a feasible trajectory from a given start point to a parking lot, and a path smoothing module for optimizing the efficiency of parking tasks. Our algorithm is based on a real kinematic vehicle model; which makes it more suitable for algorithm application on real autonomous cars. Furthermore, due to the introduction of the imagination mechanism, the processing speed of our algorithm is ten times faster than that of traditional methods, permitting the realization of real-time planning simultaneously. In order to evaluate the algorithm's effectiveness, we have compared our algorithm with traditional RRT, within three different parking scenarios. Ultimately, results show that our algorithm is more stable than traditional RRT and performs better in terms of efficiency and quality.
* Published by IEEE IV 2018
On Designing Good Representation Learning Models
Jul 13, 2021
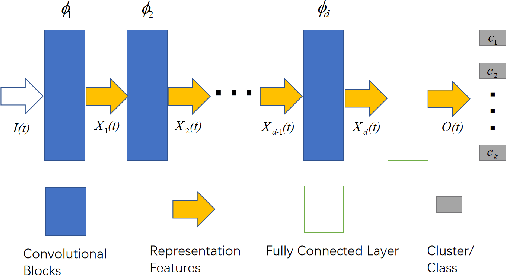
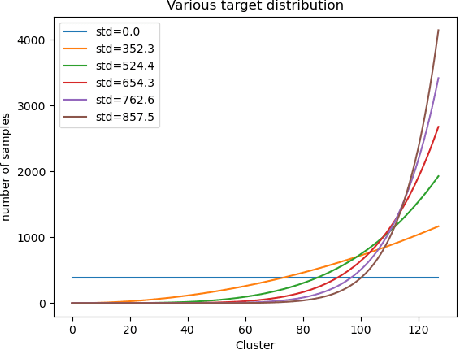
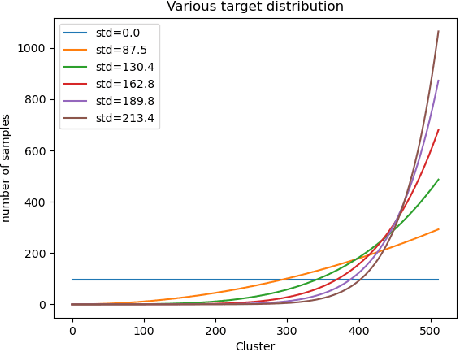
The goal of representation learning is different from the ultimate objective of machine learning such as decision making, it is therefore very difficult to establish clear and direct objectives for training representation learning models. It has been argued that a good representation should disentangle the underlying variation factors, yet how to translate this into training objectives remains unknown. This paper presents an attempt to establish direct training criterions and design principles for developing good representation learning models. We propose that a good representation learning model should be maximally expressive, i.e., capable of distinguishing the maximum number of input configurations. We formally define expressiveness and introduce the maximum expressiveness (MEXS) theorem of a general learning model. We propose to train a model by maximizing its expressiveness while at the same time incorporating general priors such as model smoothness. We present a conscience competitive learning algorithm which encourages the model to reach its MEXS whilst at the same time adheres to model smoothness prior. We also introduce a label consistent training (LCT) technique to boost model smoothness by encouraging it to assign consistent labels to similar samples. We present extensive experimental results to show that our method can indeed design representation learning models capable of developing representations that are as good as or better than state of the art. We also show that our technique is computationally efficient, robust against different parameter settings and can work effectively on a variety of datasets.
STRIVE: Scene Text Replacement In Videos
Sep 06, 2021
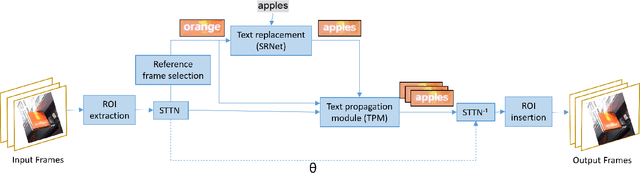
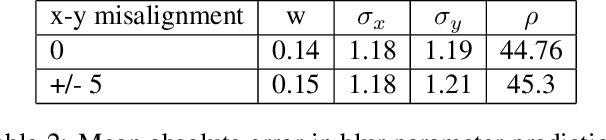
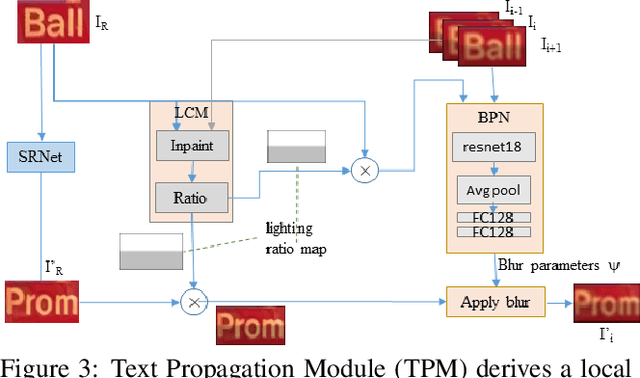
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
Towards Automatic Instrumentation by Learning to Separate Parts in Symbolic Multitrack Music
Jul 13, 2021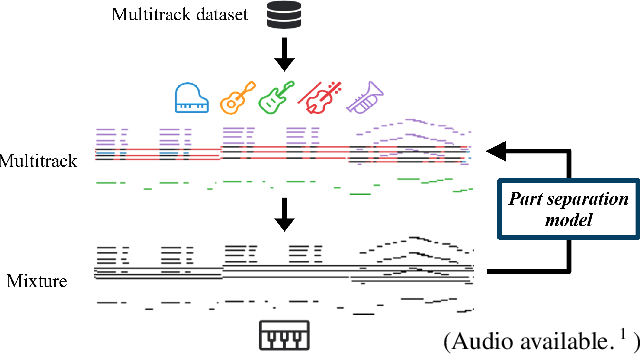


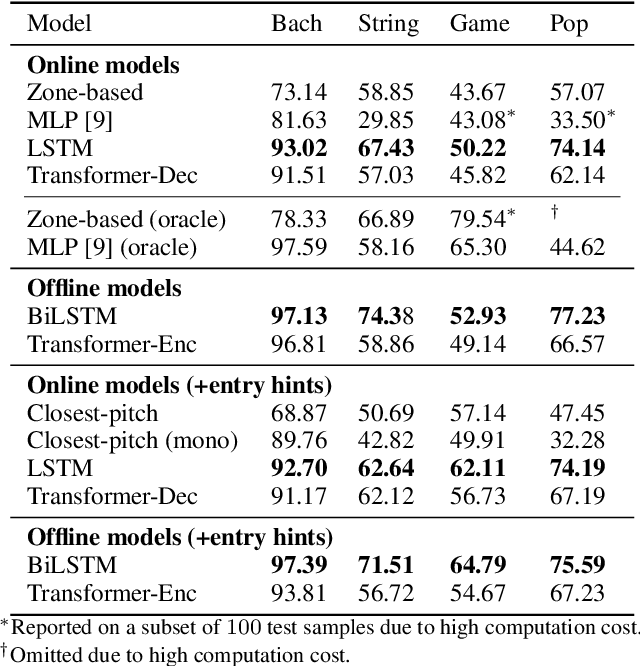
Modern keyboards allow a musician to play multiple instruments at the same time by assigning zones -- fixed pitch ranges of the keyboard -- to different instruments. In this paper, we aim to further extend this idea and examine the feasibility of automatic instrumentation -- dynamically assigning instruments to notes in solo music during performance. In addition to the online, real-time-capable setting for performative use cases, automatic instrumentation can also find applications in assistive composing tools in an offline setting. Due to the lack of paired data of original solo music and their full arrangements, we approach automatic instrumentation by learning to separate parts (e.g., voices, instruments and tracks) from their mixture in symbolic multitrack music, assuming that the mixture is to be played on a keyboard. We frame the task of part separation as a sequential multi-class classification problem and adopt machine learning to map sequences of notes into sequences of part labels. To examine the effectiveness of our proposed models, we conduct a comprehensive empirical evaluation over four diverse datasets of different genres and ensembles -- Bach chorales, string quartets, game music and pop music. Our experiments show that the proposed models outperform various baselines. We also demonstrate the potential for our proposed models to produce alternative convincing instrumentations for an existing arrangement by separating its mixture into parts. All source code and audio samples can be found at https://salu133445.github.io/arranger/ .
Automatic Online Multi-Source Domain Adaptation
Sep 12, 2021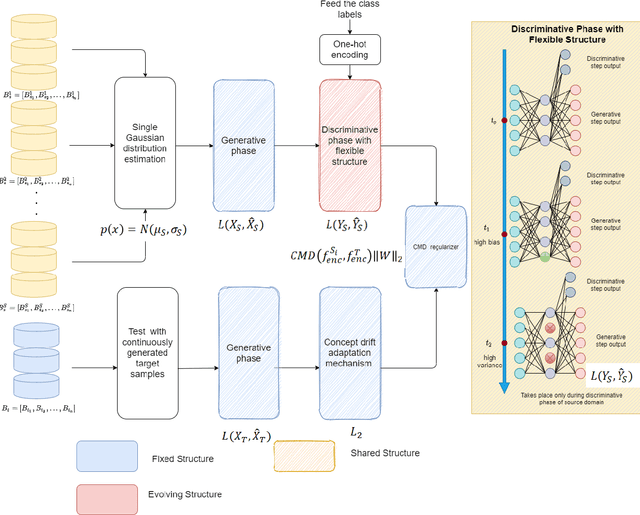
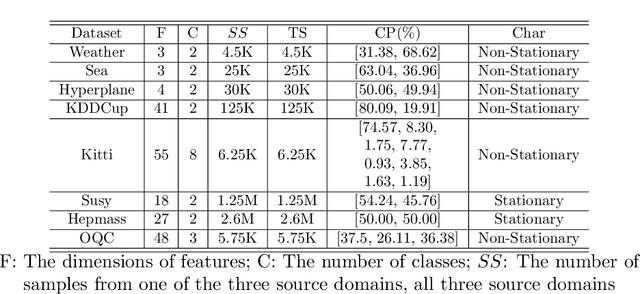
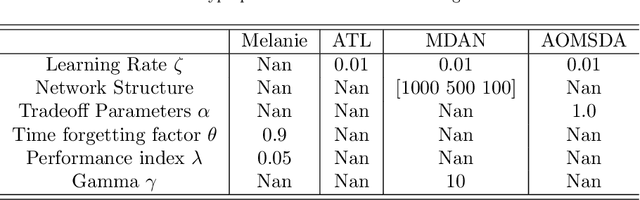
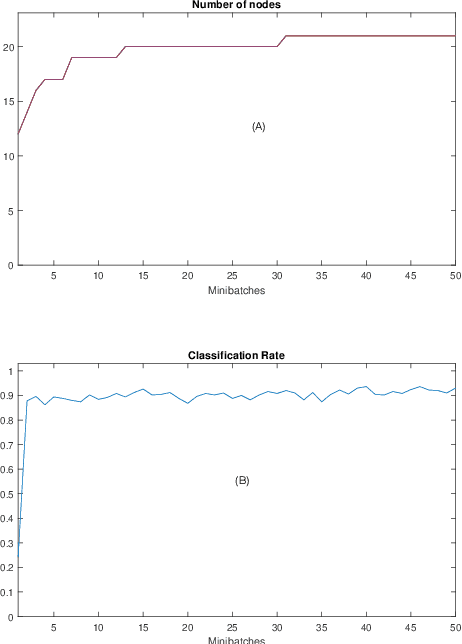
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.
Malware Classification Using Transfer Learning
Jul 29, 2021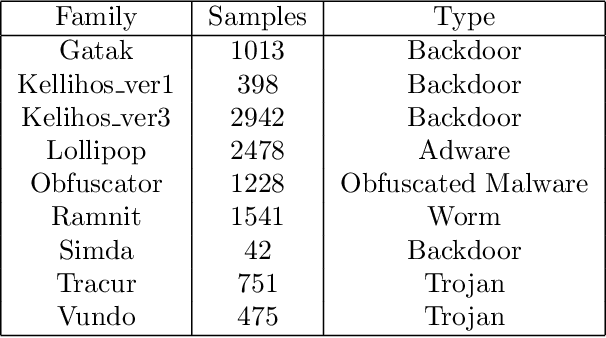

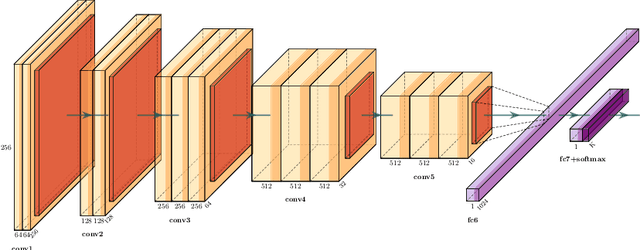
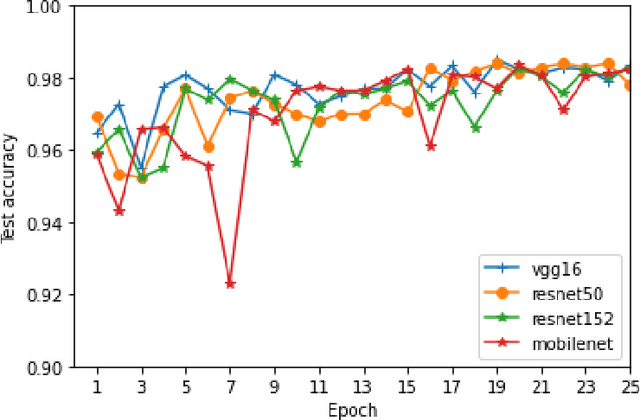
With the rapid growth of the number of devices on the Internet, malware poses a threat not only to the affected devices but also their ability to use said devices to launch attacks on the Internet ecosystem. Rapid malware classification is an important tools to combat that threat. One of the successful approaches to classification is based on malware images and deep learning. While many deep learning architectures are very accurate they usually take a long time to train. In this work we perform experiments on multiple well known, pre-trained, deep network architectures in the context of transfer learning. We show that almost all them classify malware accurately with a very short training period.
End-to-end Neural Information Status Classification
Sep 06, 2021
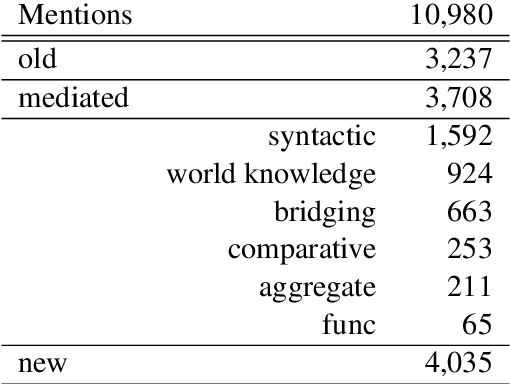
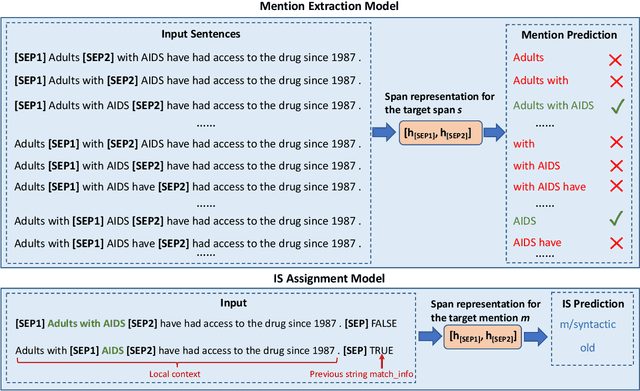
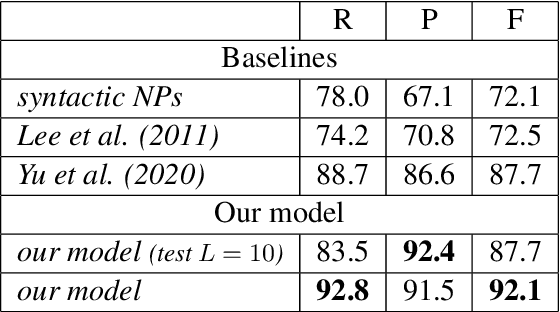
Most previous studies on information status (IS) classification and bridging anaphora recognition assume that the gold mention or syntactic tree information is given (Hou et al., 2013; Roesiger et al., 2018; Hou, 2020; Yu and Poesio, 2020). In this paper, we propose an end-to-end neural approach for information status classification. Our approach consists of a mention extraction component and an information status assignment component. During the inference time, our system takes a raw text as the input and generates mentions together with their information status. On the ISNotes corpus (Markert et al., 2012), we show that our information status assignment component achieves new state-of-the-art results on fine-grained IS classification based on gold mentions. Furthermore, our system performs significantly better than other baselines for both mention extraction and fine-grained IS classification in the end-to-end setting. Finally, we apply our system on BASHI (Roesiger, 2018) and SciCorp (Roesiger, 2016) to recognize referential bridging anaphora. We find that our end-to-end system trained on ISNotes achieves competitive results on bridging anaphora recognition compared to the previous state-of-the-art system that relies on syntactic information and is trained on the in-domain datasets (Yu and Poesio, 2020).
Robust Segmentation Models using an Uncertainty Slice Sampling Based Annotation Workflow
Sep 30, 2021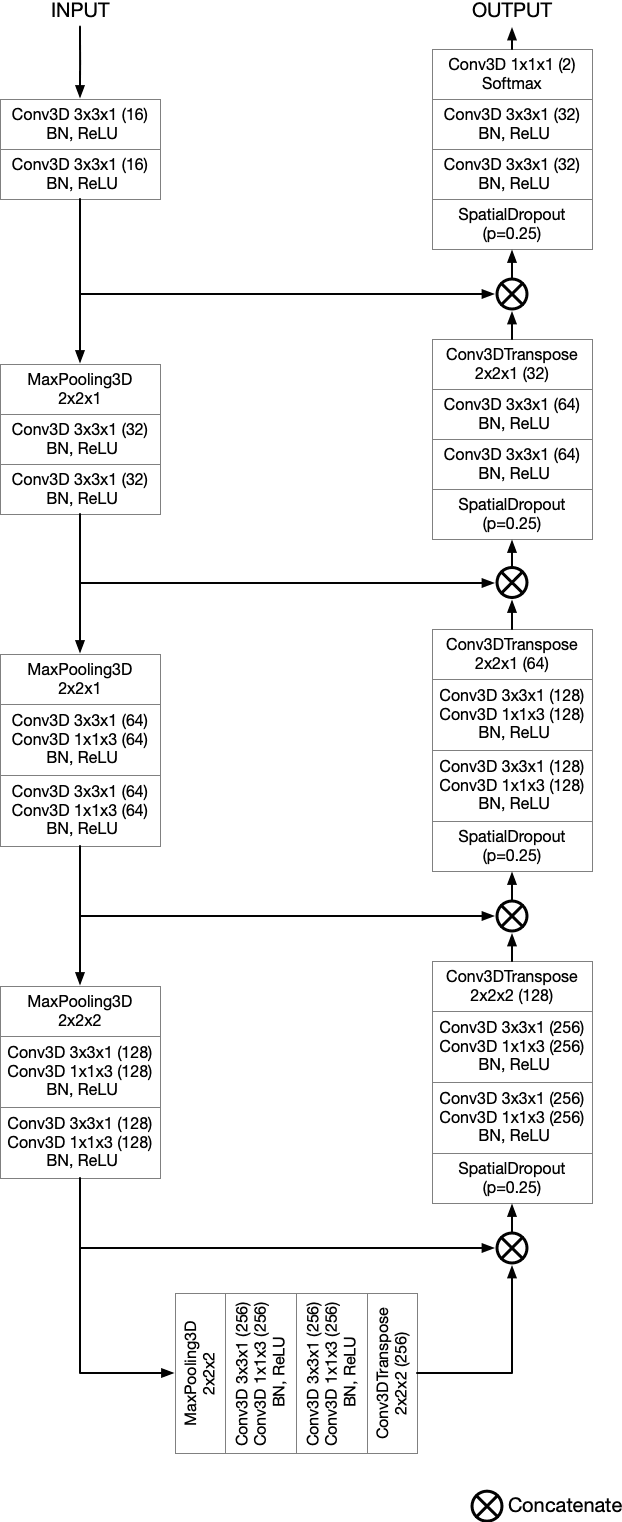
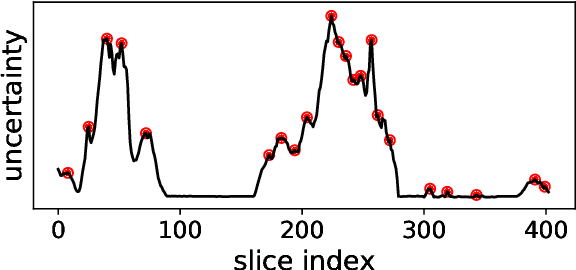
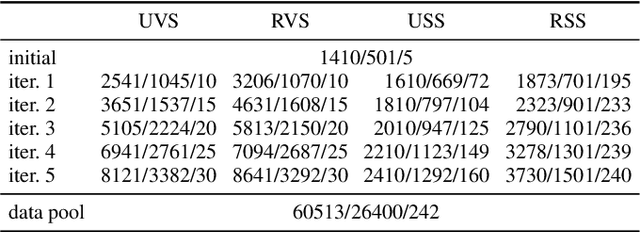
Semantic segmentation neural networks require pixel-level annotations in large quantities to achieve a good performance. In the medical domain, such annotations are expensive, because they are time-consuming and require expert knowledge. Active learning optimizes the annotation effort by devising strategies to select cases for labeling that are most informative to the model. In this work, we propose an uncertainty slice sampling (USS) strategy for semantic segmentation of 3D medical volumes that selects 2D image slices for annotation and compare it with various other strategies. We demonstrate the efficiency of USS on a CT liver segmentation task using multi-site data. After five iterations, the training data resulting from USS consisted of 2410 slices (4% of all slices in the data pool) compared to 8121 (13%), 8641 (14%), and 3730 (6%) for uncertainty volume (UVS), random volume (RVS), and random slice (RSS) sampling, respectively. Despite being trained on the smallest amount of data, the model based on the USS strategy evaluated on 234 test volumes significantly outperformed models trained according to other strategies and achieved a mean Dice index of 0.964, a relative volume error of 4.2%, a mean surface distance of 1.35 mm, and a Hausdorff distance of 23.4 mm. This was only slightly inferior to 0.967, 3.8%, 1.18 mm, and 22.9 mm achieved by a model trained on all available data, but the robustness analysis using the 5th percentile of Dice and the 95th percentile of the remaining metrics demonstrated that USS resulted not only in the most robust model compared to other sampling schemes, but also outperformed the model trained on all data according to Dice (0.946 vs. 0.945) and mean surface distance (1.92 mm vs. 2.03 mm).
Real-time Prediction of Segmentation Quality
Jun 16, 2018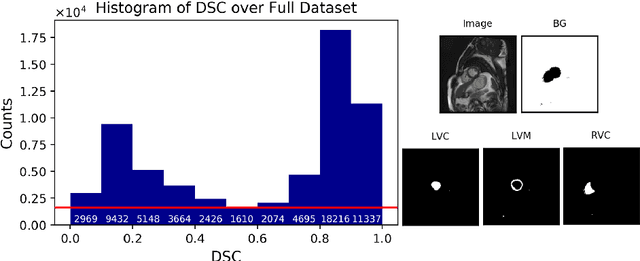
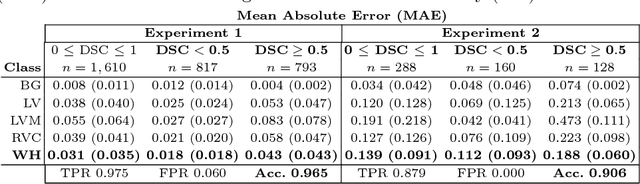
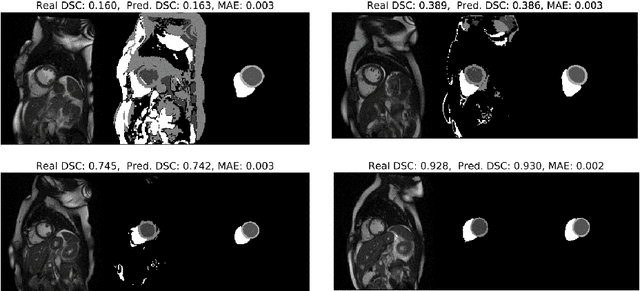
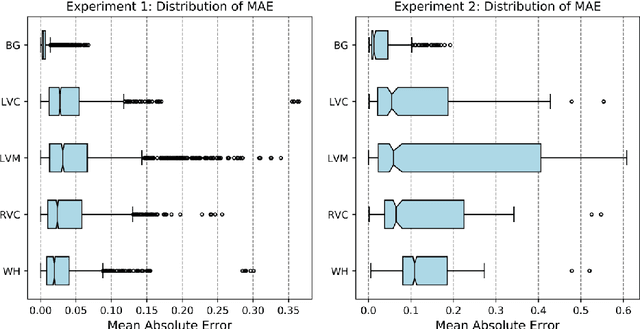
Recent advances in deep learning based image segmentation methods have enabled real-time performance with human-level accuracy. However, occasionally even the best method fails due to low image quality, artifacts or unexpected behaviour of black box algorithms. Being able to predict segmentation quality in the absence of ground truth is of paramount importance in clinical practice, but also in large-scale studies to avoid the inclusion of invalid data in subsequent analysis. In this work, we propose two approaches of real-time automated quality control for cardiovascular MR segmentations using deep learning. First, we train a neural network on 12,880 samples to predict Dice Similarity Coefficients (DSC) on a per-case basis. We report a mean average error (MAE) of 0.03 on 1,610 test samples and 97% binary classification accuracy for separating low and high quality segmentations. Secondly, in the scenario where no manually annotated data is available, we train a network to predict DSC scores from estimated quality obtained via a reverse testing strategy. We report an MAE=0.14 and 91% binary classification accuracy for this case. Predictions are obtained in real-time which, when combined with real-time segmentation methods, enables instant feedback on whether an acquired scan is analysable while the patient is still in the scanner. This further enables new applications of optimising image acquisition towards best possible analysis results.