 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable and Efficient MoE Training for Multitask Multilingual Models
Sep 22, 2021

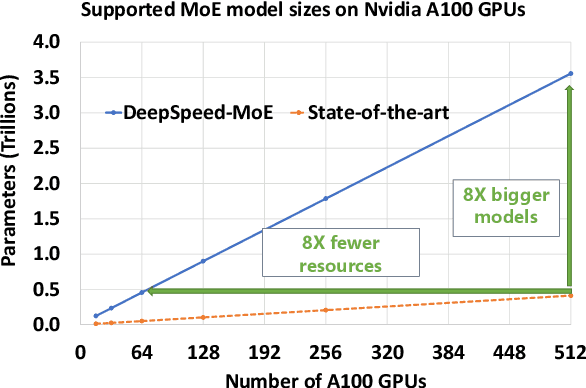

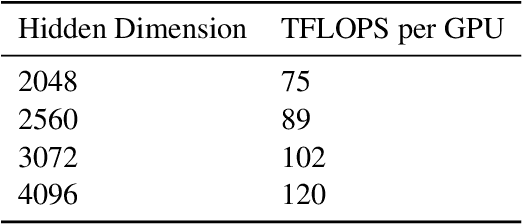
The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In contrast with dense models, the sparse architecture of MoE offers opportunities for drastically growing model size with significant accuracy gain while consuming much lower compute budget. However, supporting large scale MoE training also has its own set of system and modeling challenges. To overcome the challenges and embrace the opportunities of MoE, we first develop a system capable of scaling MoE models efficiently to trillions of parameters. It combines multi-dimensional parallelism and heterogeneous memory technologies harmoniously with MoE to empower 8x larger models on the same hardware compared with existing work. Besides boosting system efficiency, we also present new training methods to improve MoE sample efficiency and leverage expert pruning strategy to improve inference time efficiency. By combining the efficient system and training methods, we are able to significantly scale up large multitask multilingual models for language generation which results in a great improvement in model accuracy. A model trained with 10 billion parameters on 50 languages can achieve state-of-the-art performance in Machine Translation (MT) and multilingual natural language generation tasks. The system support of efficient MoE training has been implemented and open-sourced with the DeepSpeed library.
A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
Jul 11, 2021
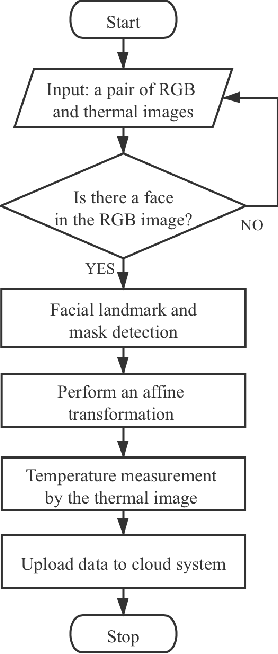
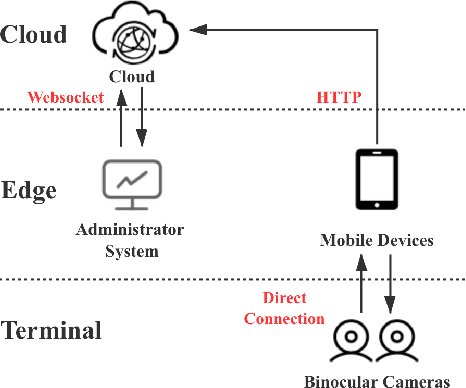

To prevent the spread of coronavirus disease 2019 (COVID-19), preliminary temperature measurement and mask detection in public areas are conducted. However, the existing temperature measurement methods face the problems of safety and deployment. In this paper, to realize safe and accurate temperature measurement even when a person's face is partially obscured, we propose a cloud-edge-terminal collaborative system with a lightweight infrared temperature measurement model. A binocular camera with an RGB lens and a thermal lens is utilized to simultaneously capture image pairs. Then, a mobile detection model based on a multi-task cascaded convolutional network (MTCNN) is proposed to realize face alignment and mask detection on the RGB images. For accurate temperature measurement, we transform the facial landmarks on the RGB images to the thermal images by an affine transformation and select a more accurate temperature measurement area on the forehead. The collected information is uploaded to the cloud in real time for COVID-19 prevention. Experiments show that the detection model is only 6.1M and the average detection speed is 257ms. At a distance of 1m, the error of indoor temperature measurement is about 3%. That is, the proposed system can realize real-time temperature measurement in public areas.
Optimal Status Update for Caching Enabled IoT Networks: A Dueling Deep R-Network Approach
Jun 13, 2021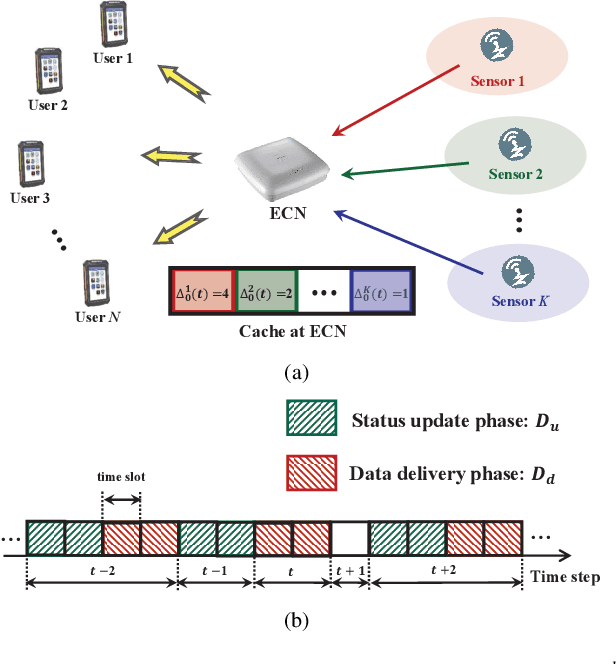
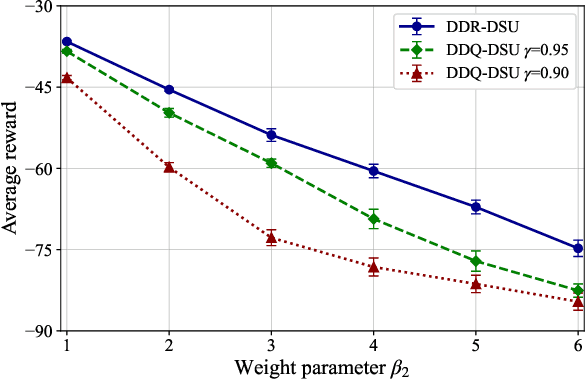
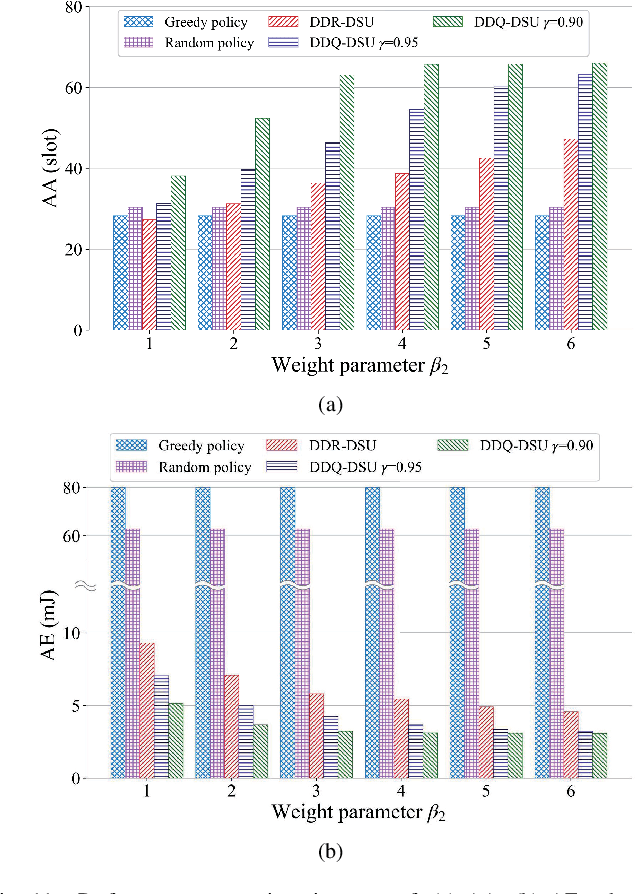
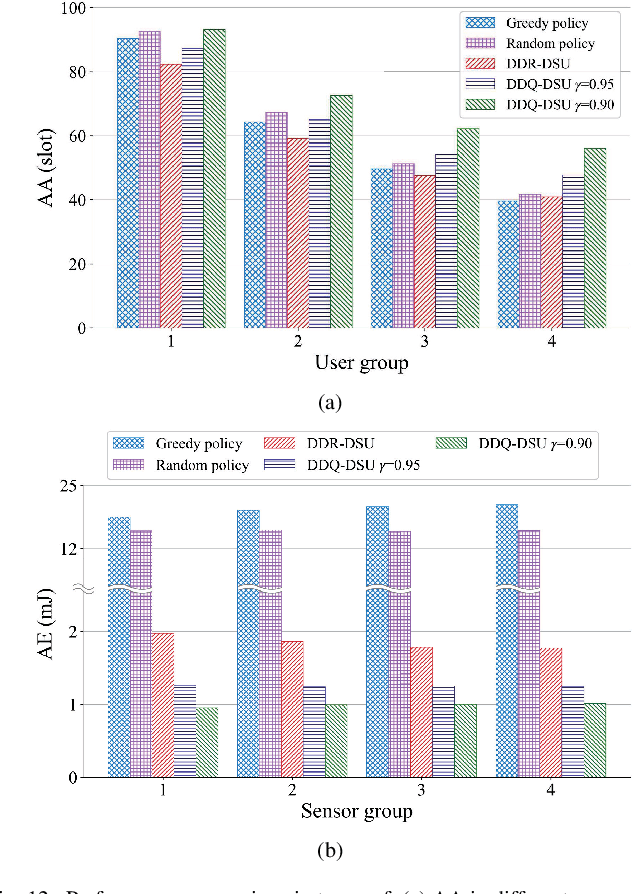
In the Internet of Things (IoT) networks, caching is a promising technique to alleviate energy consumption of sensors by responding to users' data requests with the data packets cached in the edge caching node (ECN). However, without an efficient status update strategy, the information obtained by users may be stale, which in return would inevitably deteriorate the accuracy and reliability of derived decisions for real-time applications. In this paper, we focus on striking the balance between the information freshness, in terms of age of information (AoI), experienced by users and energy consumed by sensors, by appropriately activating sensors to update their current status. Particularly, we first depict the evolutions of the AoI with each sensor from different users' perspective with time steps of non-uniform duration, which are determined by both the users' data requests and the ECN's status update decision. Then, we formulate a non-uniform time step based dynamic status update optimization problem to minimize the long-term average cost, jointly considering the average AoI and energy consumption. To this end, a Markov Decision Process is formulated and further, a dueling deep R-network based dynamic status update algorithm is devised by combining dueling deep Q-network and tabular R-learning, with which challenges from the curse of dimensionality and unknown of the environmental dynamics can be addressed. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithm by comparing it with five baseline deep reinforcement learning algorithms and policies.
Learning from Peers: Transfer Reinforcement Learning for Joint Radio and Cache Resource Allocation in 5G Network Slicing
Sep 16, 2021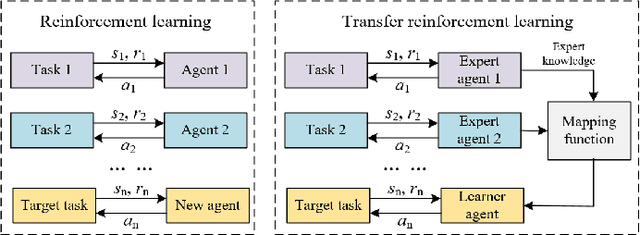
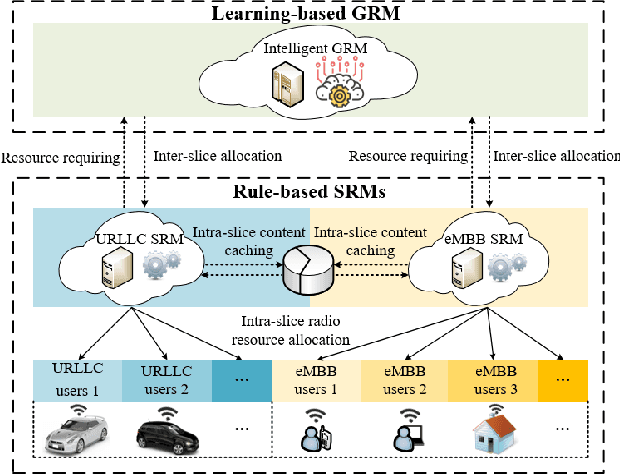
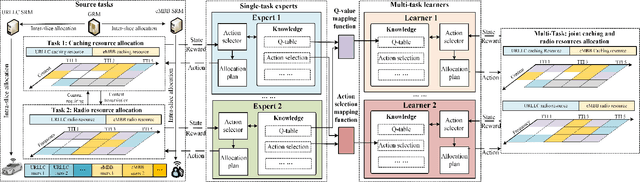

Radio access network (RAN) slicing is an important part of network slicing in 5G. The evolving network architecture requires the orchestration of multiple network resources such as radio and cache resources. In recent years, machine learning (ML) techniques have been widely applied for network slicing. However, most existing works do not take advantage of the knowledge transfer capability in ML. In this paper, we propose a transfer reinforcement learning (TRL) scheme for joint radio and cache resources allocation to serve 5G RAN slicing.We first define a hierarchical architecture for the joint resources allocation. Then we propose two TRL algorithms: Q-value transfer reinforcement learning (QTRL) and action selection transfer reinforcement learning (ASTRL). In the proposed schemes, learner agents utilize the expert agents' knowledge to improve their performance on target tasks. The proposed algorithms are compared with both the model-free Q-learning and the model-based priority proportional fairness and time-to-live (PPF-TTL) algorithms. Compared with Q-learning, QTRL and ASTRL present 23.9% lower delay for Ultra Reliable Low Latency Communications slice and 41.6% higher throughput for enhanced Mobile Broad Band slice, while achieving significantly faster convergence than Q-learning. Moreover, 40.3% lower URLLC delay and almost twice eMBB throughput are observed with respect to PPF-TTL.
Learning to Associate Every Segment for Video Panoptic Segmentation
Jun 17, 2021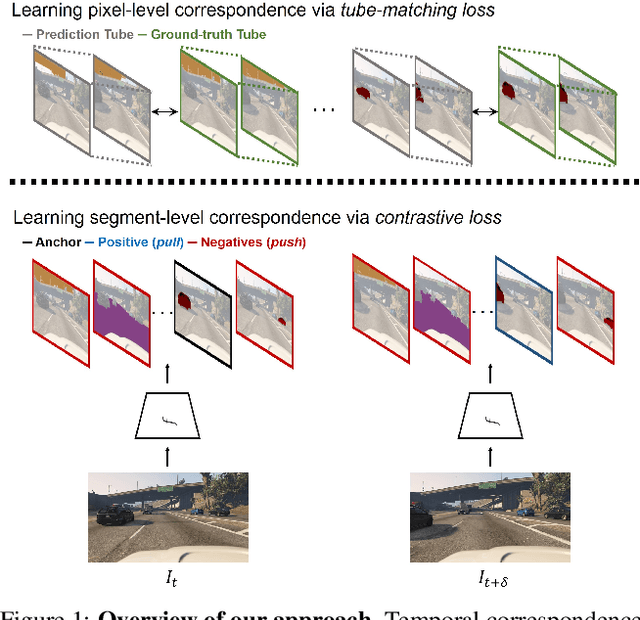
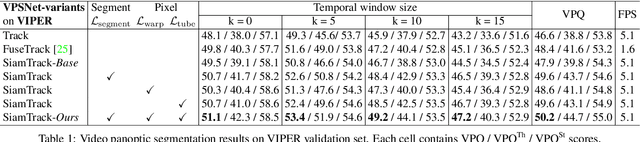
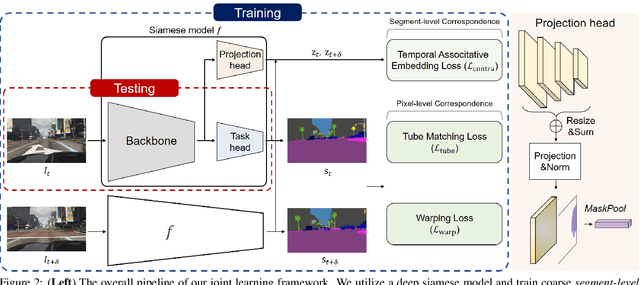
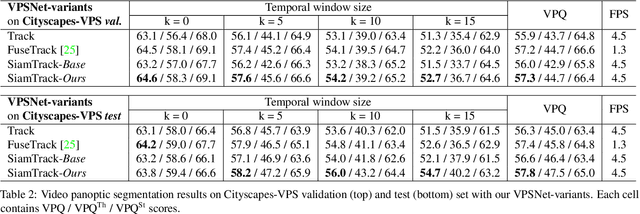
Temporal correspondence - linking pixels or objects across frames - is a fundamental supervisory signal for the video models. For the panoptic understanding of dynamic scenes, we further extend this concept to every segment. Specifically, we aim to learn coarse segment-level matching and fine pixel-level matching together. We implement this idea by designing two novel learning objectives. To validate our proposals, we adopt a deep siamese model and train the model to learn the temporal correspondence on two different levels (i.e., segment and pixel) along with the target task. At inference time, the model processes each frame independently without any extra computation and post-processing. We show that our per-frame inference model can achieve new state-of-the-art results on Cityscapes-VPS and VIPER datasets. Moreover, due to its high efficiency, the model runs in a fraction of time (3x) compared to the previous state-of-the-art approach.
Faster and Simpler Siamese Network for Single Object Tracking
May 07, 2021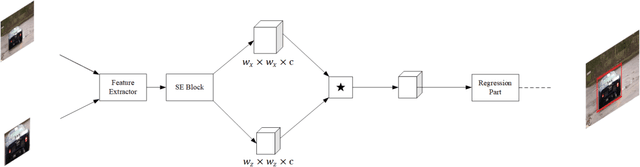
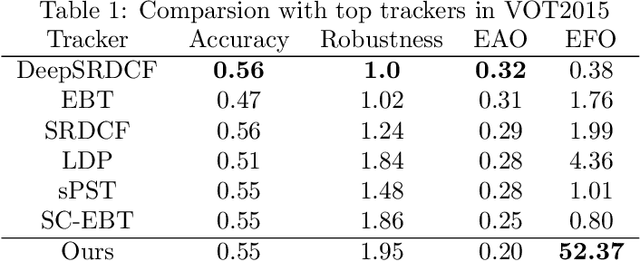
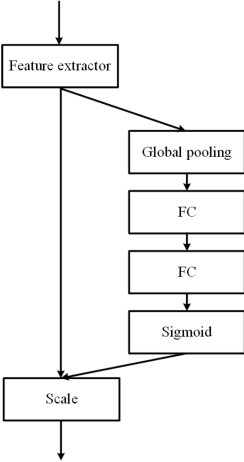
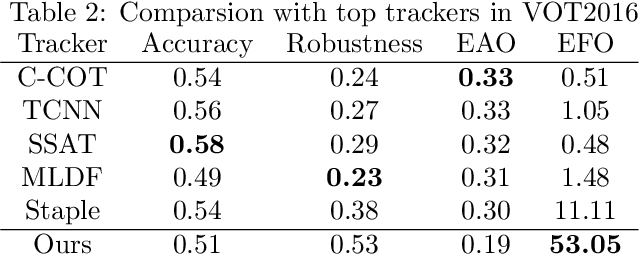
Single object tracking (SOT) is currently one of the most important tasks in computer vision. With the development of the deep network and the release for a series of large scale datasets for single object tracking, siamese networks have been proposed and perform better than most of the traditional methods. However, recent siamese networks get deeper and slower to obtain better performance. Most of these methods could only meet the needs of real-time object tracking in ideal environments. In order to achieve a better balance between efficiency and accuracy, we propose a simpler siamese network for single object tracking, which runs fast in poor hardware configurations while remaining an excellent accuracy. We use a more efficient regression method to compute the location of the tracked object in a shorter time without losing much precision. For improving the accuracy and speeding up the training progress, we introduce the Squeeze-and-excitation (SE) network into the feature extractor. In this paper, we compare the proposed method with some state-of-the-art trackers and analysis their performances. Using our method, a siamese network could be trained with shorter time and less data. The fast processing speed enables combining object tracking with object detection or other tasks in real time.
Physics-Informed Neural Networks for Minimising Worst-Case Violations in DC Optimal Power Flow
Jun 28, 2021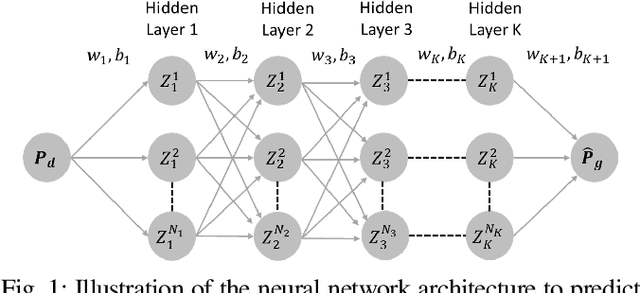
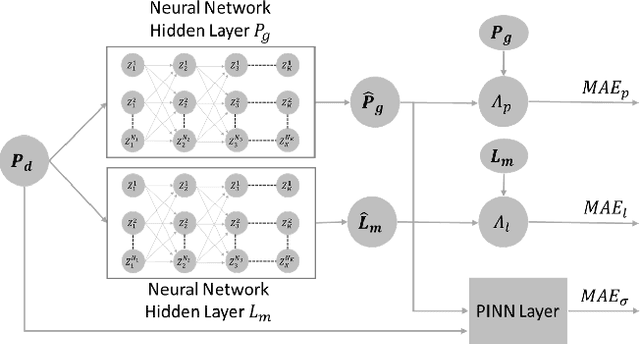
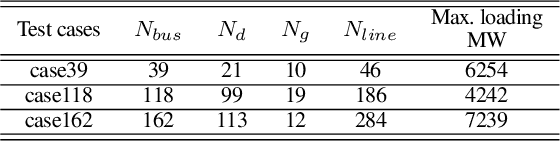
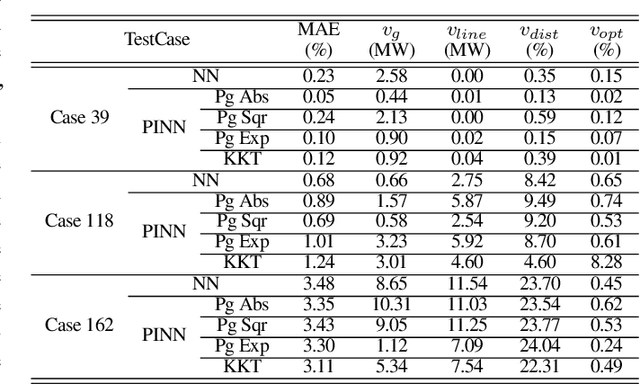
Physics-informed neural networks exploit the existing models of the underlying physical systems to generate higher accuracy results with fewer data. Such approaches can help drastically reduce the computation time and generate a good estimate of computationally intensive processes in power systems, such as dynamic security assessment or optimal power flow. Combined with the extraction of worst-case guarantees for the neural network performance, such neural networks can be applied in safety-critical applications in power systems and build a high level of trust among power system operators. This paper takes the first step and applies, for the first time to our knowledge, Physics-Informed Neural Networks with Worst-Case Guarantees for the DC Optimal Power Flow problem. We look for guarantees related to (i) maximum constraint violations, (ii) maximum distance between predicted and optimal decision variables, and (iii) maximum sub-optimality in the entire input domain. In a range of PGLib-OPF networks, we demonstrate how physics-informed neural networks can be supplied with worst-case guarantees and how they can lead to reduced worst-case violations compared with conventional neural networks.
Credit Assignment Safety Learning from Human Demonstrations
Oct 09, 2021
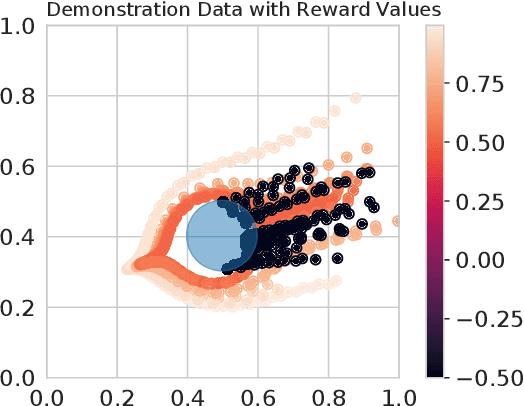
A critical need in assistive robotics, such as assistive wheelchairs for navigation, is a need to learn task intent and safety guarantees through user interactions in order to ensure safe task performance. For tasks where the objectives from the user are not easily defined, learning from user demonstrations has been a key step in enabling learning. However, most robot learning from demonstration (LfD) methods primarily rely on optimal demonstration in order to successfully learn a control policy, which can be challenging to acquire from novice users. Recent work does use suboptimal and failed demonstrations to learn about task intent; few focus on learning safety guarantees to prevent repeat failures experienced, essential for assistive robots. Furthermore, interactive human-robot learning aims to minimize effort from the human user to facilitate deployment in the real-world. As such, requiring users to label the unsafe states or keyframes from the demonstrations should not be a necessary requirement for learning. Here, we propose an algorithm to learn a safety value function from a set of suboptimal and failed demonstrations that is used to generate a real-time safety control filter. Importantly, we develop a credit assignment method that extracts the failure states from the failed demonstrations without requiring human labelling or prespecified knowledge of unsafe regions. Furthermore, we extend our formulation to allow for user-specific safety functions, by incorporating user-defined safety rankings from which we can generate safety level sets according to the users' preferences. By using both suboptimal and failed demonstrations and the developed credit assignment formulation, we enable learning a safety value function with minimal effort needed from the user, making it more feasible for widespread use in human-robot interactive learning tasks.
Trajectory Design for UAV-Based Internet-of-Things Data Collection: A Deep Reinforcement Learning Approach
Jul 23, 2021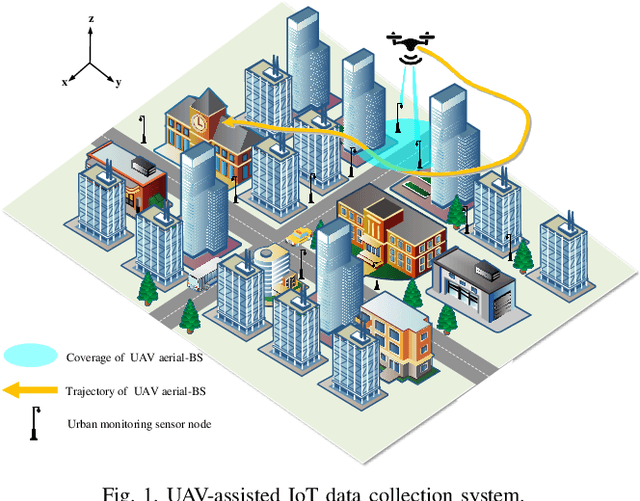
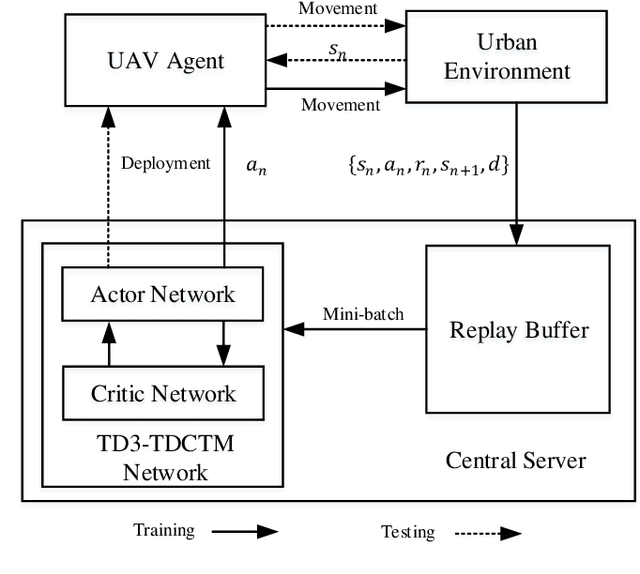
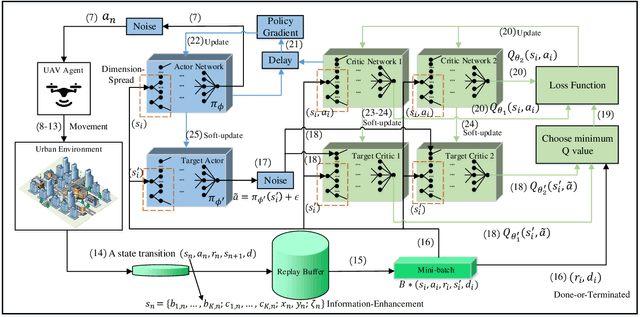
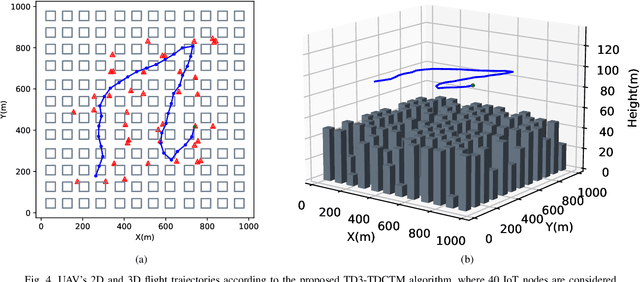
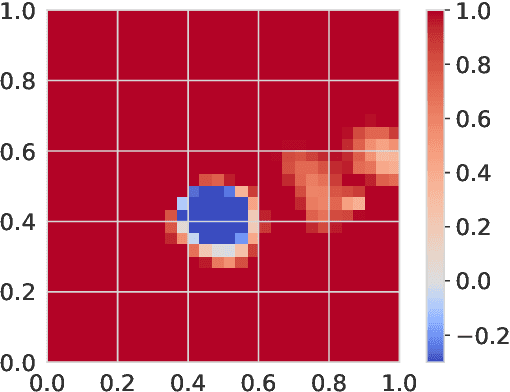
In this paper, we investigate an unmanned aerial vehicle (UAV)-assisted Internet-of-Things (IoT) system in a sophisticated three-dimensional (3D) environment, where the UAV's trajectory is optimized to efficiently collect data from multiple IoT ground nodes. Unlike existing approaches focusing only on a simplified two-dimensional scenario and the availability of perfect channel state information (CSI), this paper considers a practical 3D urban environment with imperfect CSI, where the UAV's trajectory is designed to minimize data collection completion time subject to practical throughput and flight movement constraints. Specifically, inspired from the state-of-the-art deep reinforcement learning approaches, we leverage the twin-delayed deep deterministic policy gradient (TD3) to design the UAV's trajectory and present a TD3-based trajectory design for completion time minimization (TD3-TDCTM) algorithm. In particular, we set an additional information, i.e., the merged pheromone, to represent the state information of UAV and environment as a reference of reward which facilitates the algorithm design. By taking the service statuses of IoT nodes, the UAV's position, and the merged pheromone as input, the proposed algorithm can continuously and adaptively learn how to adjust the UAV's movement strategy. By interacting with the external environment in the corresponding Markov decision process, the proposed algorithm can achieve a near-optimal navigation strategy. Our simulation results show the superiority of the proposed TD3-TDCTM algorithm over three conventional non-learning based baseline methods.
Mitigation of Diachronic Bias in Fake News Detection Dataset
Aug 28, 2021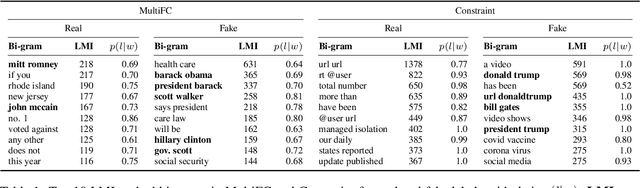
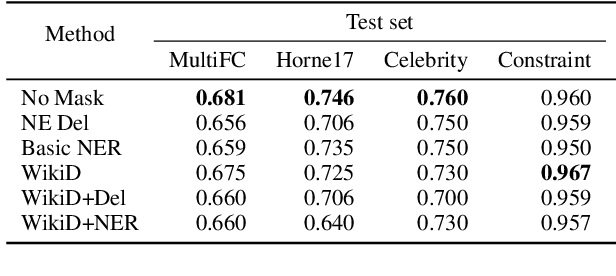
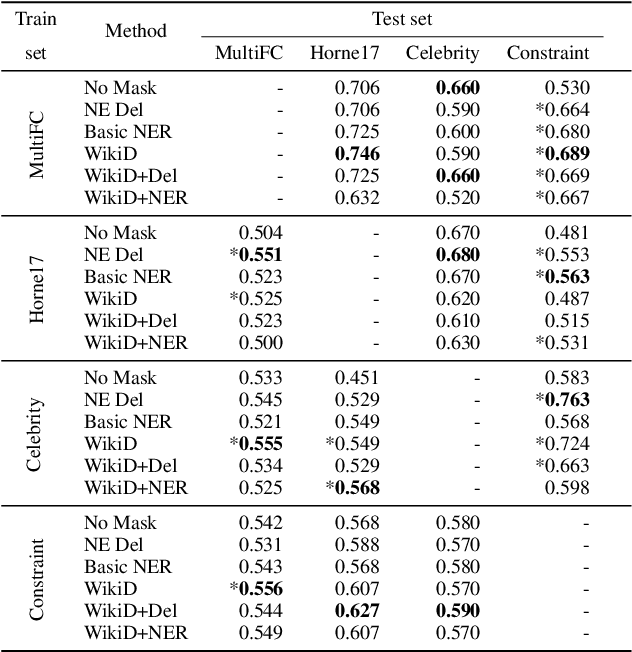
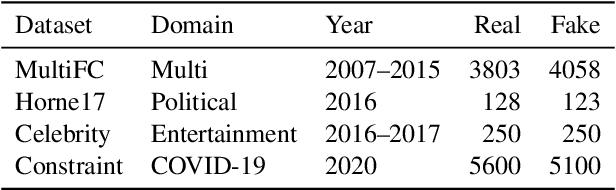
Fake news causes significant damage to society.To deal with these fake news, several studies on building detection models and arranging datasets have been conducted. Most of the fake news datasets depend on a specific time period. Consequently, the detection models trained on such a dataset have difficulty detecting novel fake news generated by political changes and social changes; they may possibly result in biased output from the input, including specific person names and organizational names. We refer to this problem as \textbf{Diachronic Bias} because it is caused by the creation date of news in each dataset. In this study, we confirm the bias, especially proper nouns including person names, from the deviation of phrase appearances in each dataset. Based on these findings, we propose masking methods using Wikidata to mitigate the influence of person names and validate whether they make fake news detection models robust through experiments with in-domain and out-of-domain data.