 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Tale of Two-Timescale Reinforcement Learning with the Tightest Finite-Time Bound
Nov 20, 2019



Policy evaluation in reinforcement learning is often conducted using two-timescale stochastic approximation, which results in various gradient temporal difference methods such as GTD(0), GTD2, and TDC. Here, we provide convergence rate bounds for this suite of algorithms. Algorithms such as these have two iterates, $\theta_n$ and $w_n,$ which are updated using two distinct stepsize sequences, $\alpha_n$ and $\beta_n,$ respectively. Assuming $\alpha_n = n^{-\alpha}$ and $\beta_n = n^{-\beta}$ with $1 > \alpha > \beta > 0,$ we show that, with high probability, the two iterates converge to their respective solutions $\theta^*$ and $w^*$ at rates given by $\|\theta_n - \theta^*\| = \tilde{O}( n^{-\alpha/2})$ and $\|w_n - w^*\| = \tilde{O}(n^{-\beta/2});$ here, $\tilde{O}$ hides logarithmic terms. Via comparable lower bounds, we show that these bounds are, in fact, tight. To the best of our knowledge, ours is the first finite-time analysis which achieves these rates. While it was known that the two timescale components decouple asymptotically, our results depict this phenomenon more explicitly by showing that it in fact happens from some finite time onwards. Lastly, compared to existing works, our result applies to a broader family of stepsizes, including non-square summable ones.
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021
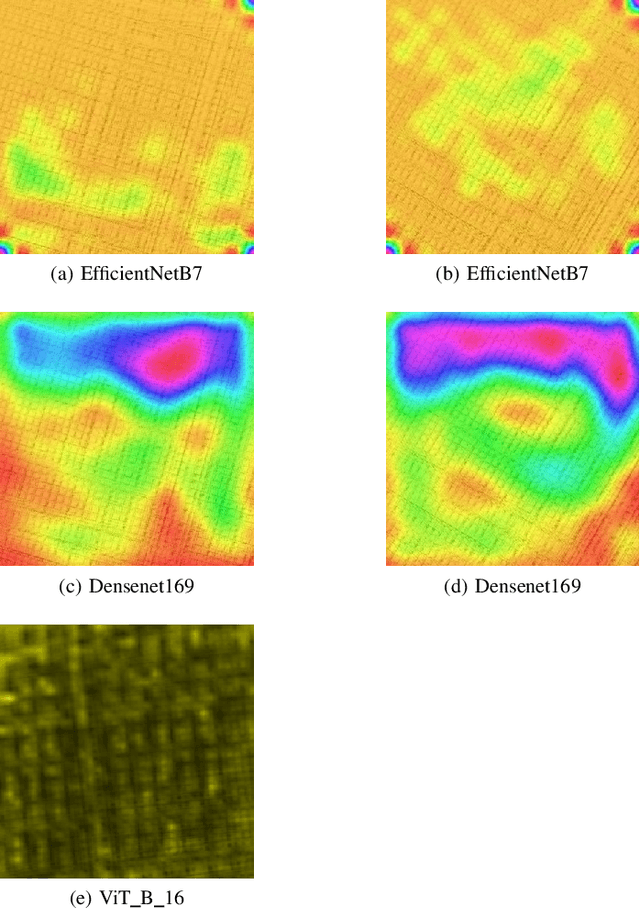

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.
Invariant Filtering for Bipedal Walking on Dynamic Rigid Surfaces with Orientation-based Measurement Model
Sep 02, 2021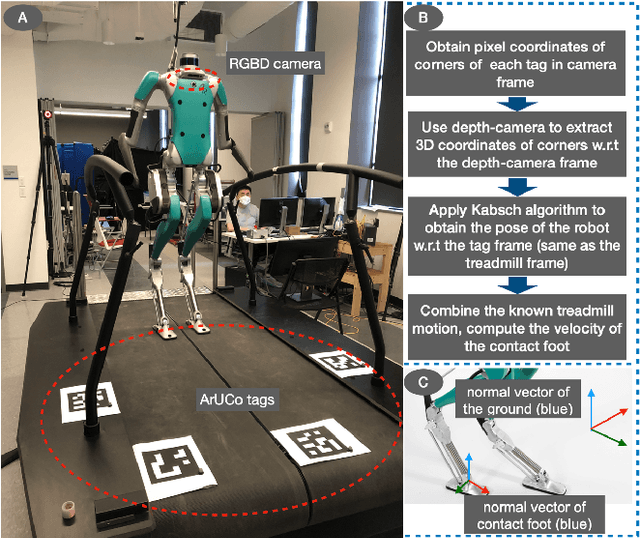
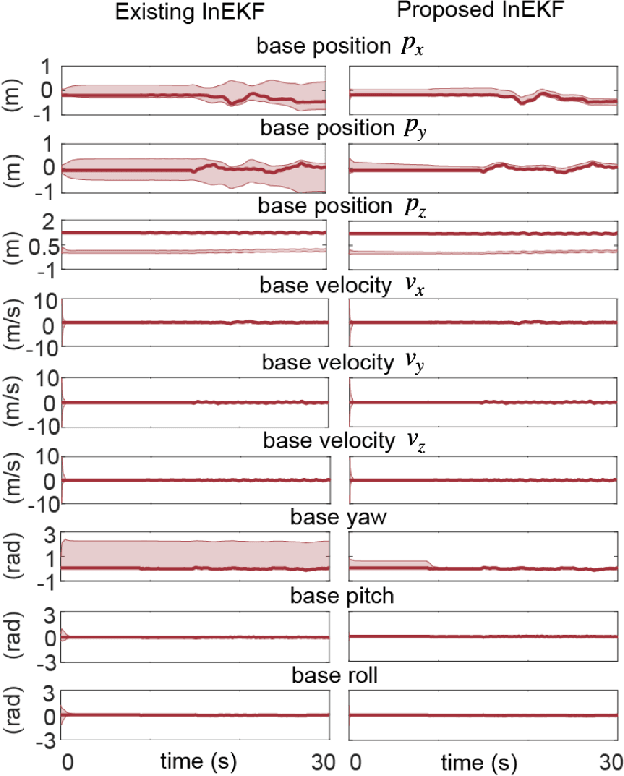
Real-world applications of bipedal robot walking require accurate, real-time state estimation. State estimation for locomotion over dynamic rigid surfaces (DRS), such as elevators, ships, public transport vehicles, and aircraft, remains under-explored, although state estimator designs for stationary rigid surfaces have been extensively studied. Addressing DRS locomotion in state estimation is a challenging problem mainly due to the nonlinear, hybrid nature of walking dynamics, the nonstationary surface-foot contact points, and hardware imperfections (e.g., limited availability, noise, and drift of onboard sensors). Towards solving this problem, we introduce an Invariant Extended Kalman Filter (InEKF) whose process and measurement models explicitly consider the DRS movement and hybrid walking behaviors while respectively satisfying the group-affine condition and invariant form. Due to these attractive properties, the estimation error convergence of the filter is provably guaranteed for hybrid DRS locomotion. The measurement model of the filter also exploits the holonomic constraint associated with the support-foot and surface orientations, under which the robot's yaw angle in the world becomes observable in the presence of general DRS movement. Experimental results of bipedal walking on a rocking treadmill demonstrate the proposed filter ensures the rapid error convergence and observable base yaw angle.
Criticality and Utility-aware Fog Computing System for Remote Health Monitoring
May 24, 2021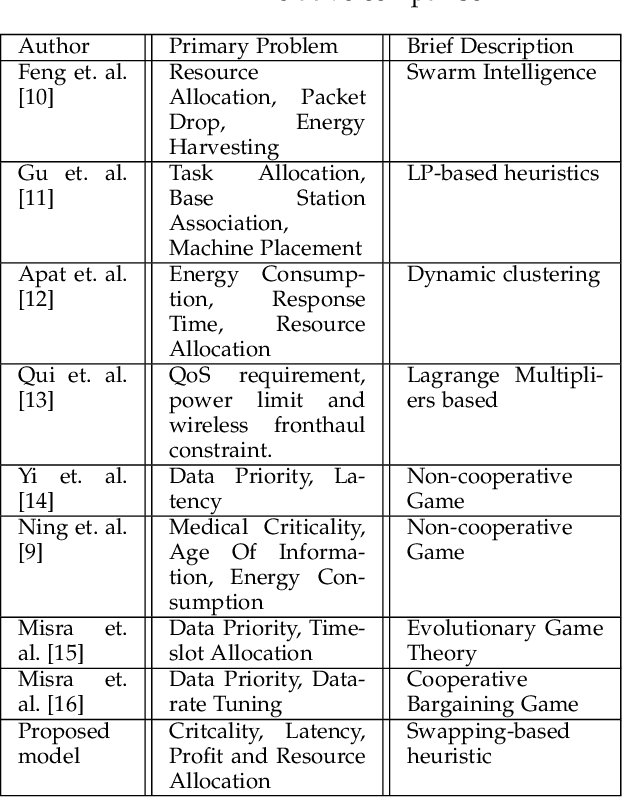
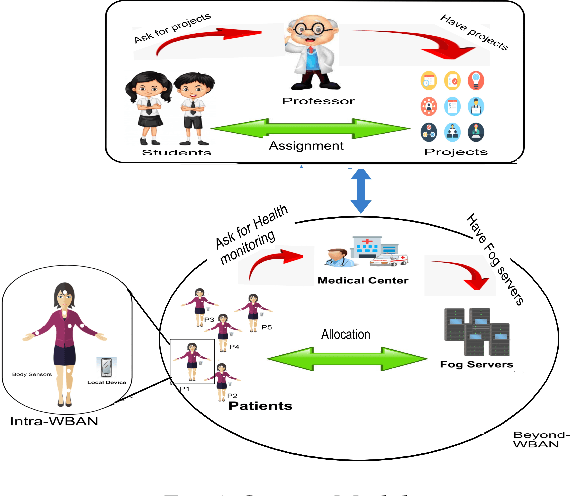

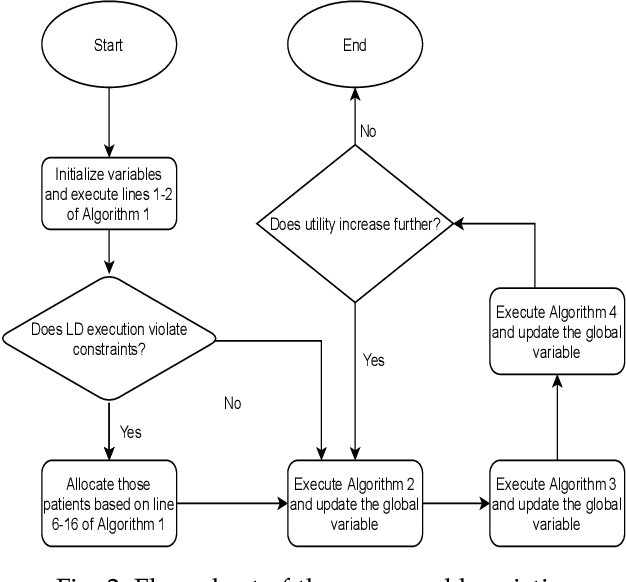
Growing remote health monitoring system allows constant monitoring of the patient's condition and performance of preventive and control check-ups outside medical facilities. However, the real-time smart-healthcare application poses a delay constraint that has to be solved efficiently. Fog computing is emerging as an efficient solution for such real-time applications. Moreover, different medical centers are getting attracted to the growing IoT-based remote healthcare system in order to make a profit by hiring Fog computing resources. However, there is a need for an efficient algorithmic model for allocation of limited fog computing resources in the criticality-aware smart-healthcare system considering the profit of medical centers. Thus, the objective of this work is to maximize the system utility calculated as a linear combination of the profit of the medical center and the loss of patients. To measure profit, we propose a flat-pricing-based model. Further, we propose a swapping-based heuristic to maximize the system utility. The proposed heuristic is tested on various parameters and shown to perform close to the optimal with criticality-awareness in its core. Through extensive simulations, we show that the proposed heuristic achieves an average utility of $96\%$ of the optimal, in polynomial time complexity.
Non-intrusive load decomposition based on CNN-LSTM hybrid deep learning model
Sep 02, 2021
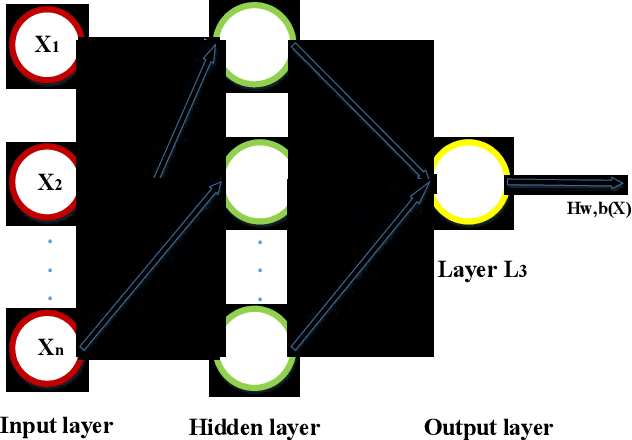
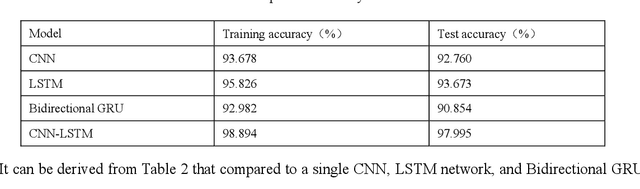
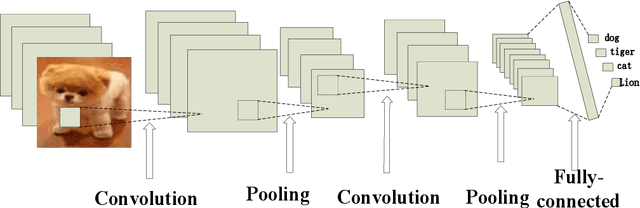
With the rapid development of science and technology, the problem of energy load monitoring and decomposition of electrical equipment has been receiving widespread attention from academia and industry. For the purpose of improving the performance of non-intrusive load decomposition, a non-intrusive load decomposition method based on a hybrid deep learning model is proposed. In this method, first of all, the data set is normalized and preprocessed. Secondly, a hybrid deep learning model integrating convolutional neural network (CNN) with long short-term memory network (LSTM) is constructed to fully excavate the spatial and temporal characteristics of load data. Finally, different evaluation indicators are used to analyze the mixture. The model is fully evaluated, and contrasted with the traditional single deep learning model. Experimental results on the open dataset UK-DALE show that the proposed algorithm improves the performance of the whole network system. In this paper, the proposed decomposition method is compared with the existing traditional deep learning load decomposition method. At the same time, compared with the obtained methods: spectral decomposition, EMS, LSTM-RNN, and other algorithms, the accuracy of load decomposition is significantly improved, and the test accuracy reaches 98%.
Semi-supervised Network Embedding with Differentiable Deep Quantisation
Aug 20, 2021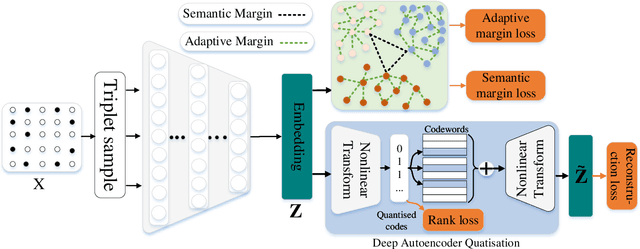
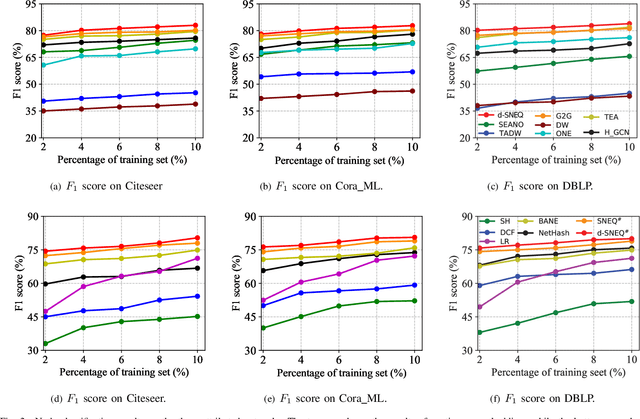
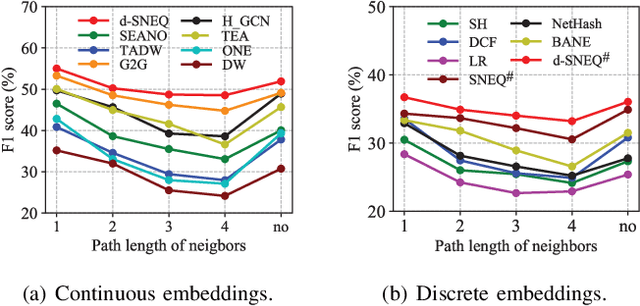
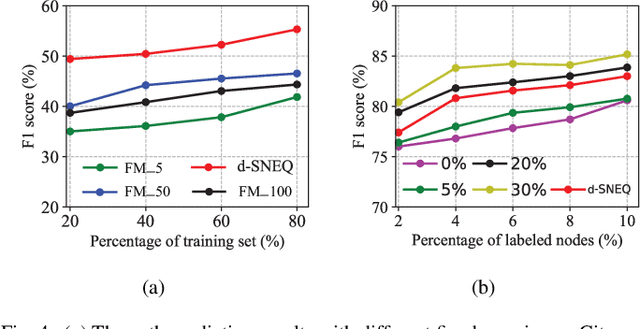
Learning accurate low-dimensional embeddings for a network is a crucial task as it facilitates many downstream network analytics tasks. For large networks, the trained embeddings often require a significant amount of space to store, making storage and processing a challenge. Building on our previous work on semi-supervised network embedding, we develop d-SNEQ, a differentiable DNN-based quantisation method for network embedding. d-SNEQ incorporates a rank loss to equip the learned quantisation codes with rich high-order information and is able to substantially compress the size of trained embeddings, thus reducing storage footprint and accelerating retrieval speed. We also propose a new evaluation metric, path prediction, to fairly and more directly evaluate model performance on the preservation of high-order information. Our evaluation on four real-world networks of diverse characteristics shows that d-SNEQ outperforms a number of state-of-the-art embedding methods in link prediction, path prediction, node classification, and node recommendation while being far more space- and time-efficient.
Person Entity Profiling Framework: Identifying, Integrating and Visualizing Online Freely Available Entity-Related Information
Oct 02, 2021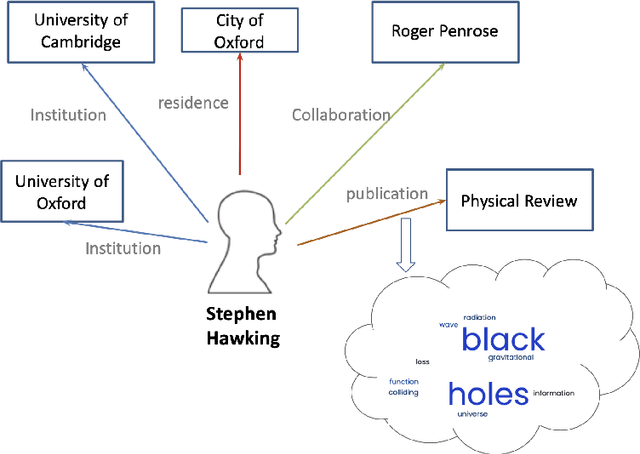
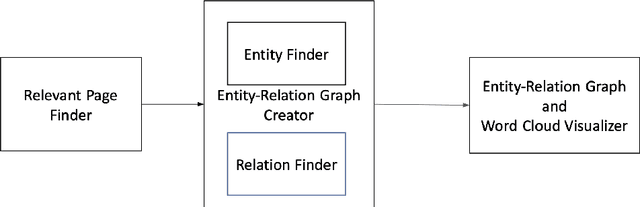

When we consider our CV, it is full of entities that we are or were associated with and that define us in some way(s). Such entities include where we studied, where we worked, who we collaborated with on a project or on a paper etc. Entities we are linked to are part of who we are and may reveal about what we are interested in. Hence, we can view any CV as a graph of interlinked entities, where nodes are entities and edges are relations between them. This study proposes a novel entity search framework that in response to a real-time query about an entity, searches, crawls, analyzes and consolidates relevant information that is freely available on the Web about the entity of interest, culminating in the generation a profile of the searched entity. Unlike typical entity search settings, in which a ranked list of entities related to the target entity over a pre-specified relation is processed, we present and visualize rich information about the entity of interest as a typed entity-relation graph without an apriori definition of the types of related entities and relations. This view is structured and compact, making it easy to understand as well as interpret. It enables the user to learn not only about the entity in question, but also about related entities, thereby obtaining a better understanding of the entity in question. We evaluated each of the frameworks components separately and then performed an overall evaluation of the framework, its visualization and the interest of users in the results. The results show that the proposed framework performs entity searches, related entity identification and relation identification very well and that it satisfies users needs.
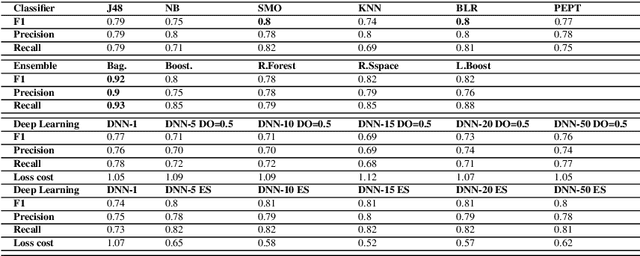
A multi-stage semi-supervised improved deep embedded clustering (MS-SSIDEC) method for bearing fault diagnosis under the situation of insufficient labeled samples
Sep 28, 2021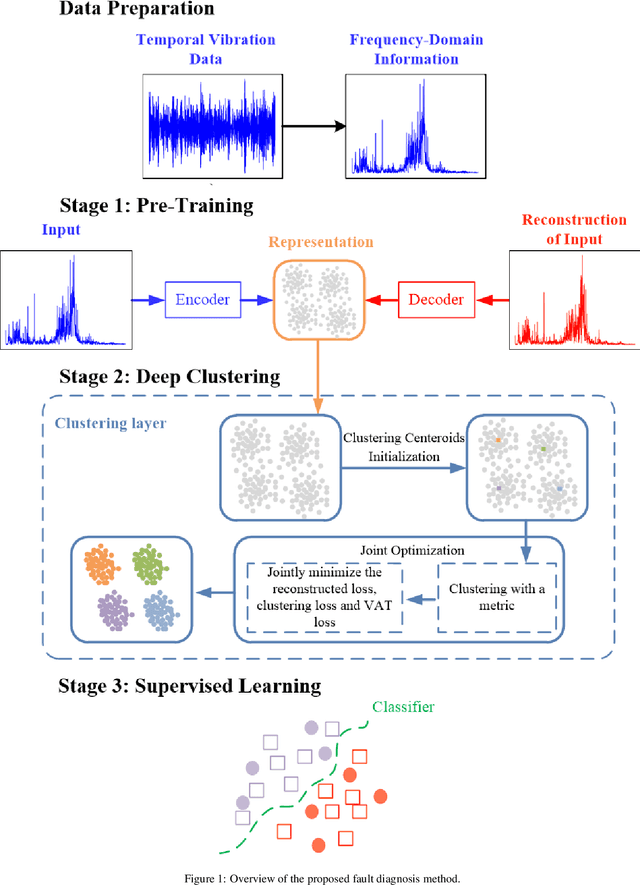
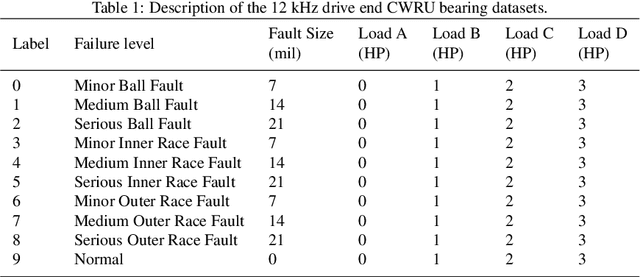
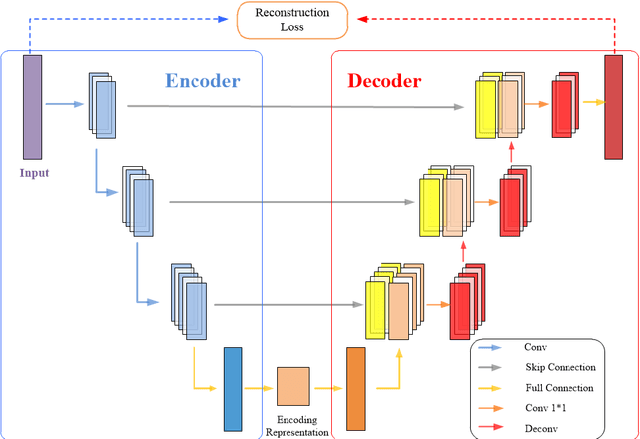
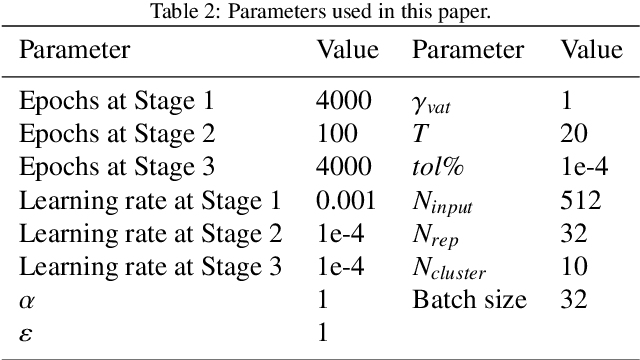
Intelligent data-driven fault diagnosis methods have been widely applied, but most of these methods need a large number of high-quality labeled samples. It costs a lot of labor and time to label data in actual industrial processes, which challenges the application of intelligent fault diagnosis methods. To solve this problem, a multi-stage semi-supervised improved deep embedded clustering (MS-SSIDEC) method is proposed for the bearing fault diagnosis under the insufficient labeled samples situation. This method includes three stages: pre-training, deep clustering and enhanced supervised learning. In the first stage, a skip-connection based convolutional auto-encoder (SCCAE) is proposed and pre-trained to automatically learn low-dimensional representations. In the second stage, a semi-supervised improved deep embedded clustering (SSIDEC) model that integrates the pre-trained auto-encoder with a clustering layer is proposed for deep clustering. Additionally, virtual adversarial training (VAT) is introduced as a regularization term to overcome the overfitting in the model's training. In the third stage, high-quality clustering results obtained in the second stage are assigned to unlabeled samples as pseudo labels. The labeled dataset is augmented by those pseudo-labeled samples and used to train a bearing fault discriminative model. The effectiveness of the method is evaluated on the Case Western Reserve University (CWRU) bearing dataset. The results show that the method can not only satisfy the semi-supervised learning under a small number of labeled samples, but also solve the problem of unsupervised learning, and has achieved better results than traditional diagnosis methods. This method provides a new research idea for fault diagnosis with limited labeled samples by effectively using unsupervised data.
Continuous-time Value Function Approximation in Reproducing Kernel Hilbert Spaces
Oct 26, 2018
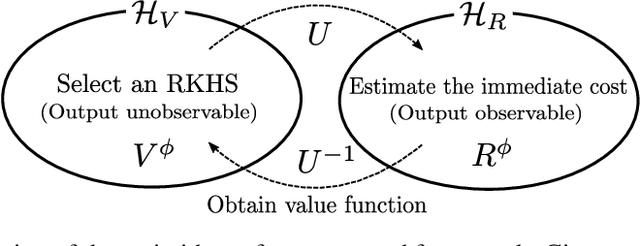

Motivated by the success of reinforcement learning (RL) for discrete-time tasks such as AlphaGo and Atari games, there has been a recent surge of interest in using RL for continuous-time control of physical systems (cf. many challenging tasks in OpenAI Gym and DeepMind Control Suite). Since discretization of time is susceptible to error, it is methodologically more desirable to handle the system dynamics directly in continuous time. However, very few techniques exist for continuous-time RL and they lack flexibility in value function approximation. In this paper, we propose a novel framework for model-based continuous-time value function approximation in reproducing kernel Hilbert spaces. The resulting framework is so flexible that it can accommodate any kind of kernel-based approach, such as Gaussian processes and kernel adaptive filters, and it allows us to handle uncertainties and nonstationarity without prior knowledge about the environment or what basis functions to employ. We demonstrate the validity of the presented framework through experiments.
Sequential Deconfounding for Causal Inference with Unobserved Confounders
Apr 16, 2021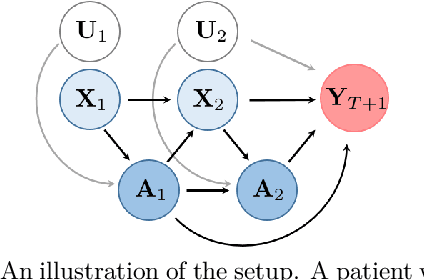
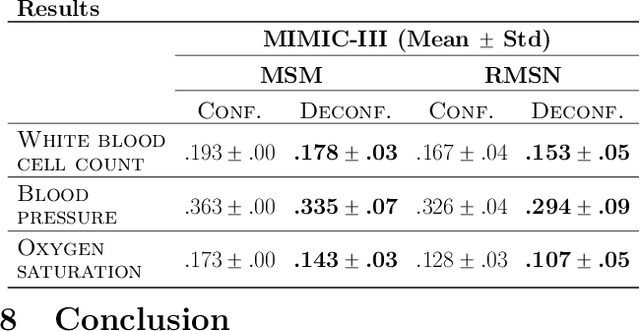
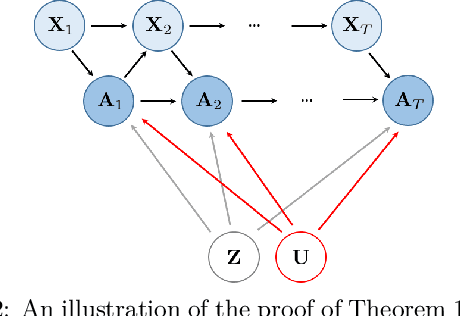

Using observational data to estimate the effect of a treatment is a powerful tool for decision-making when randomized experiments are infeasible or costly. However, observational data often yields biased estimates of treatment effects, since treatment assignment can be confounded by unobserved variables. A remedy is offered by deconfounding methods that adjust for such unobserved confounders. In this paper, we develop the Sequential Deconfounder, a method that enables estimating individualized treatment effects over time in presence of unobserved confounders. This is the first deconfounding method that can be used in a general sequential setting (i.e., with one or more treatments assigned at each timestep). The Sequential Deconfounder uses a novel Gaussian process latent variable model to infer substitutes for the unobserved confounders, which are then used in conjunction with an outcome model to estimate treatment effects over time. We prove that using our method yields unbiased estimates of individualized treatment responses over time. Using simulated and real medical data, we demonstrate the efficacy of our method in deconfounding the estimation of treatment responses over time.