 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Jul 07, 2021
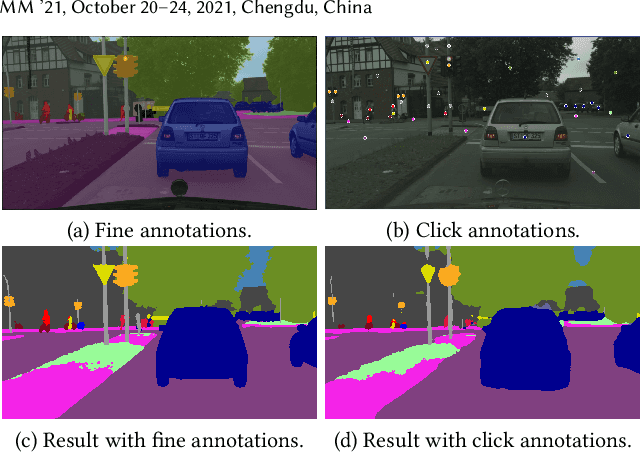
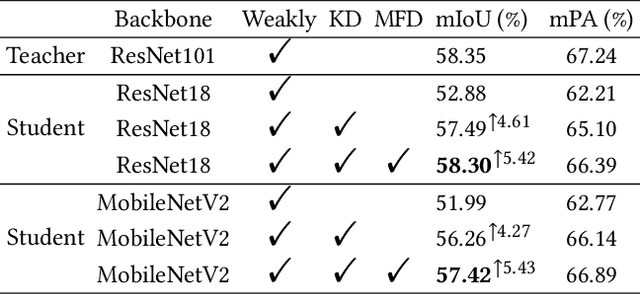
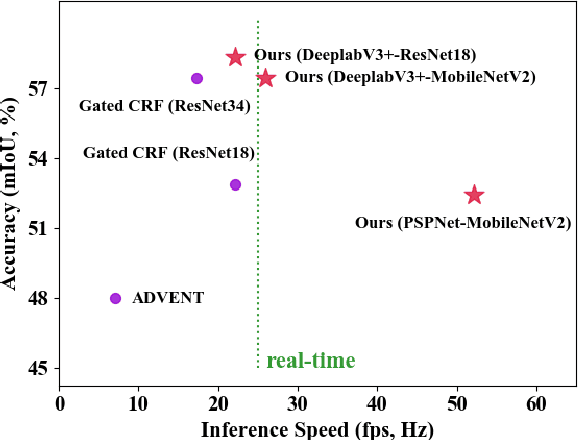
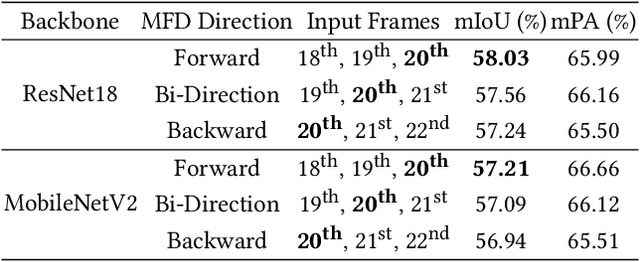
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Towards Adversarial Robustness via Transductive Learning
Jun 15, 2021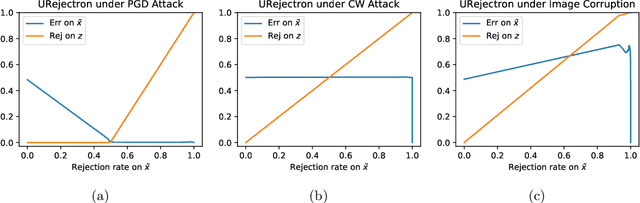
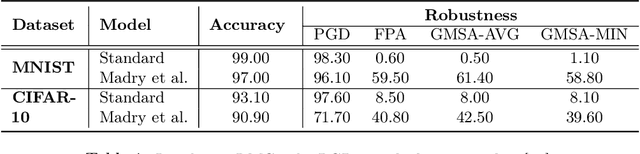
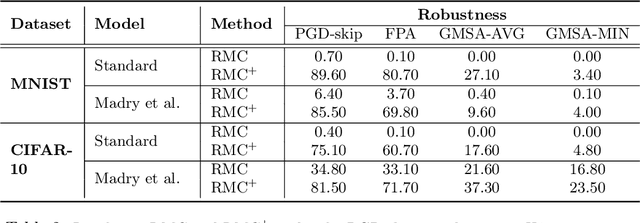
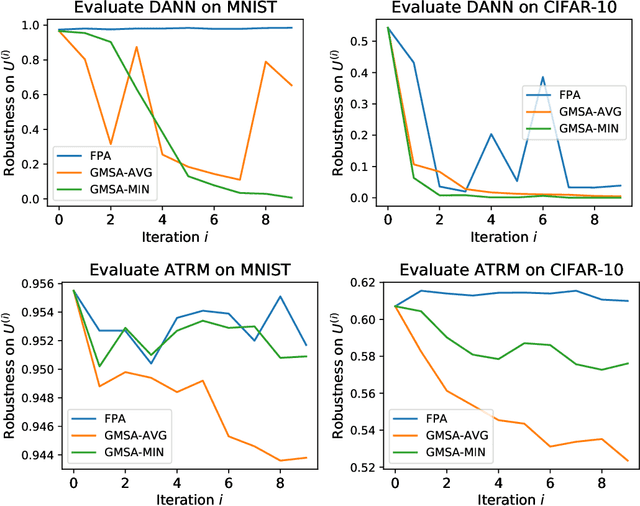
There has been emerging interest to use transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020). Compared to traditional "test-time" defenses, these defense mechanisms "dynamically retrain" the model based on test time input via transductive learning; and theoretically, attacking these defenses boils down to bilevel optimization, which seems to raise the difficulty for adaptive attacks. In this paper, we first formalize and analyze modeling aspects of transductive robustness. Then, we propose the principle of attacking model space for solving bilevel attack objectives, and present an instantiation of the principle which breaks previous transductive defenses. These attacks thus point to significant difficulties in the use of transductive learning to improve adversarial robustness. To this end, we present new theoretical and empirical evidence in support of the utility of transductive learning.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021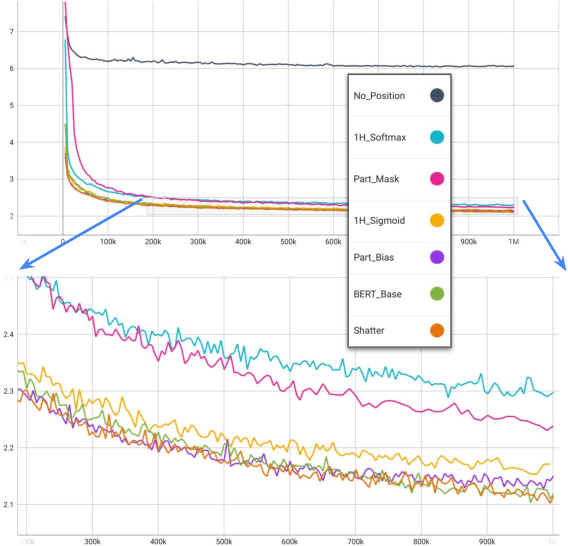
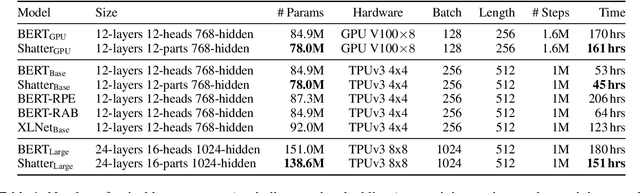

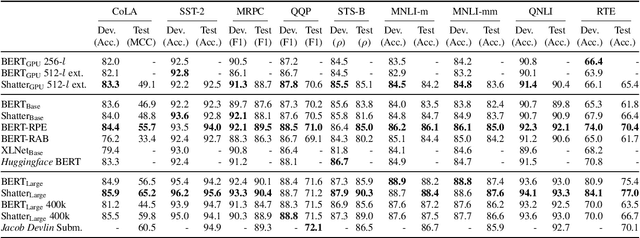
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Automatic Recall of Software Lessons Learned for Software Project Managers
Oct 11, 2021
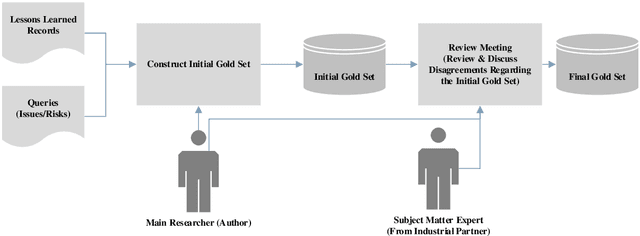

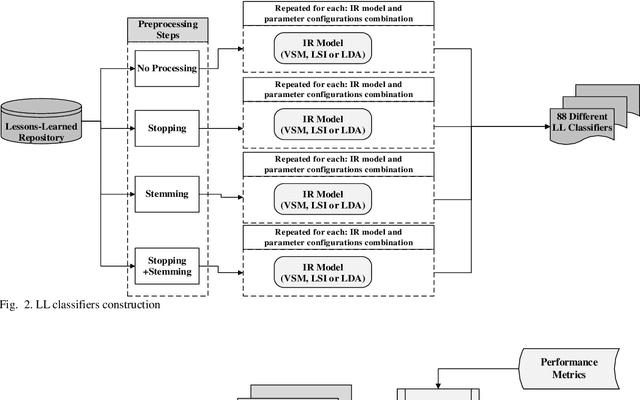
Lessons learned (LL) records constitute the software organization memory of successes and failures. LL are recorded within the organization repository for future reference to optimize planning, gain experience, and elevate market competitiveness. However, manually searching this repository is a daunting task, so it is often disregarded. This can lead to the repetition of previous mistakes or even missing potential opportunities. This, in turn, can negatively affect the profitability and competitiveness of organizations. We aim to present a novel solution that provides an automatic process to recall relevant LL and to push those LL to project managers. This will dramatically save the time and effort of manually searching the unstructured LL repositories and thus encourage the LL exploitation. We exploit existing project artifacts to build the LL search queries on-the-fly in order to bypass the tedious manual searching. An empirical case study is conducted to build the automatic LL recall solution and evaluate its effectiveness. The study employs three of the most popular information retrieval models to construct the solution. Furthermore, a real-world dataset of 212 LL records from 30 different software projects is used for validation. Top-k and MAP well-known accuracy metrics are used as well. Our case study results confirm the effectiveness of the automatic LL recall solution. Also, the results prove the success of using existing project artifacts to dynamically build the search query string. This is supported by a discerning accuracy of about 70% achieved in the case of top-k. The automatic LL recall solution is valid with high accuracy. It will eliminate the effort needed to manually search the LL repository. Therefore, this will positively encourage project managers to reuse the available LL knowledge, which will avoid old pitfalls and unleash hidden business opportunities.
Dynamic Error-bounded Lossy Compression (EBLC) to Reduce the Bandwidth Requirement for Real-time Vision-based Pedestrian Safety Applications
Jan 29, 2020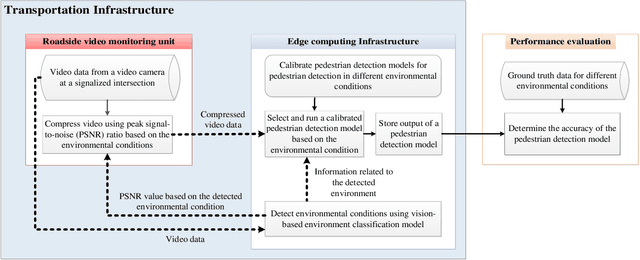
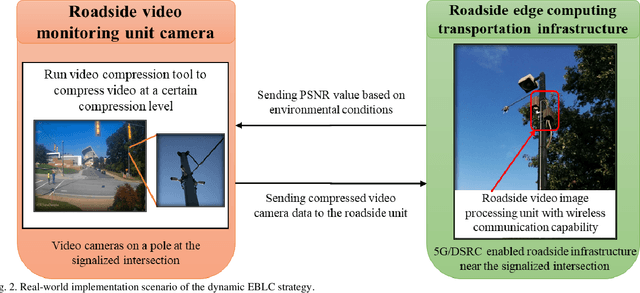
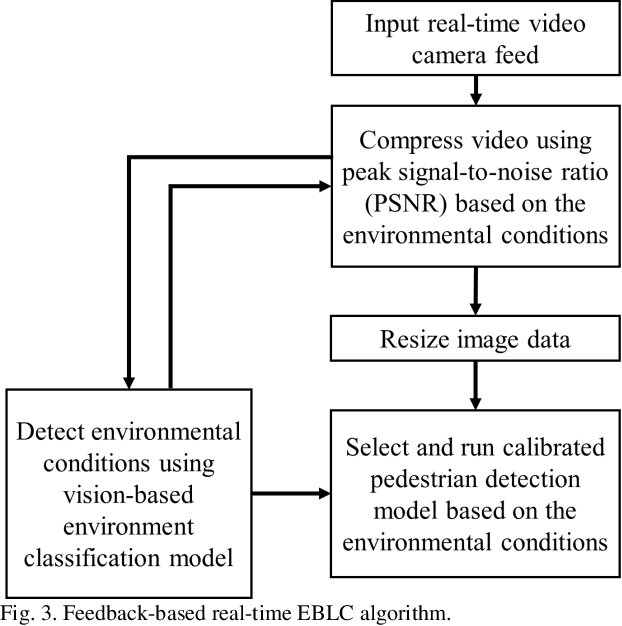

As camera quality improves and their deployment moves to areas with limited bandwidth, communication bottlenecks can impair real-time constraints of an ITS application, such as video-based real-time pedestrian detection. Video compression reduces the bandwidth requirement to transmit the video but degrades the video quality. As the quality level of the video decreases, it results in the corresponding decreases in the accuracy of the vision-based pedestrian detection model. Furthermore, environmental conditions (e.g., rain and darkness) alter the compression ratio and can make maintaining a high pedestrian detection accuracy more difficult. The objective of this study is to develop a real-time error-bounded lossy compression (EBLC) strategy to dynamically change the video compression level depending on different environmental conditions in order to maintain a high pedestrian detection accuracy. We conduct a case study to show the efficacy of our dynamic EBLC strategy for real-time vision-based pedestrian detection under adverse environmental conditions. Our strategy selects the error tolerances dynamically for lossy compression that can maintain a high detection accuracy across a representative set of environmental conditions. Analyses reveal that our strategy increases pedestrian detection accuracy up to 14% and reduces the communication bandwidth up to 14x for adverse environmental conditions compared to the same conditions but without our dynamic EBLC strategy. Our dynamic EBLC strategy is independent of detection models and environmental conditions allowing other detection models and environmental conditions to be easily incorporated in our strategy.
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
Jul 07, 2021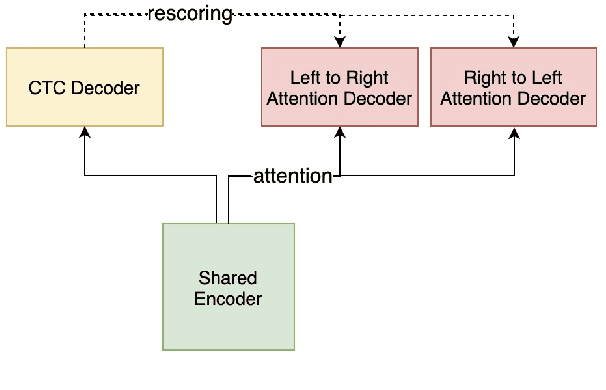
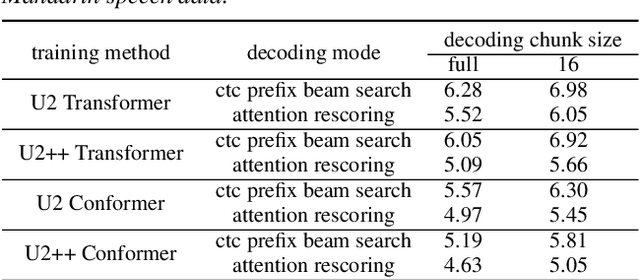
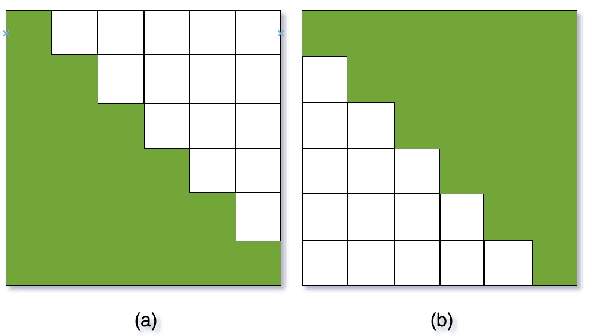
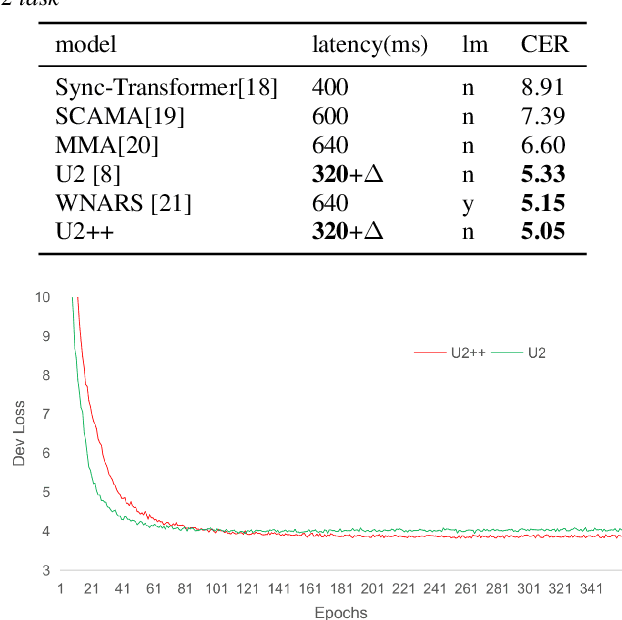
The unified streaming and non-streaming two-pass (U2) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy, real-time factor (RTF), and latency. In this paper, we present U2++, an enhanced version of U2 to further improve the accuracy. The core idea of U2++ is to use the forward and the backward information of the labeling sequences at the same time at training to learn richer information, and combine the forward and backward prediction at decoding to give more accurate recognition results. We also proposed a new data augmentation method called SpecSub to help the U2++ model to be more accurate and robust. Our experiments show that, compared with U2, U2++ shows faster convergence at training, better robustness to the decoding method, as well as consistent 5\% - 8\% word error rate reduction gain over U2. On the experiment of AISHELL-1, we achieve a 4.63\% character error rate (CER) with a non-streaming setup and 5.05\% with a streaming setup with 320ms latency by U2++. To the best of our knowledge, 5.05\% is the best-published streaming result on the AISHELL-1 test set.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.
Temporal-Clustering Invariance in Irregular Healthcare Time Series
Apr 27, 2019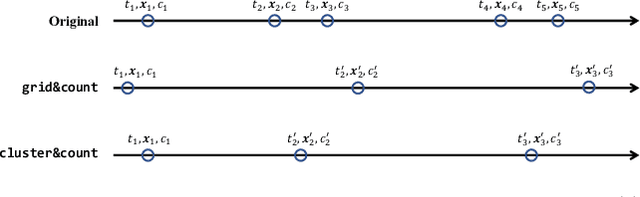
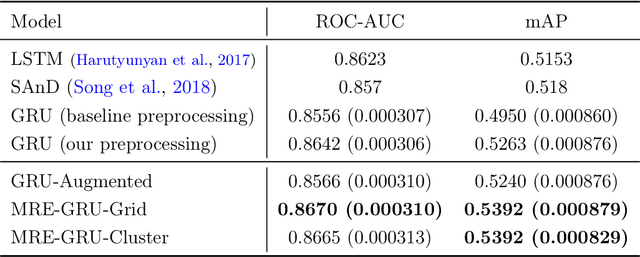
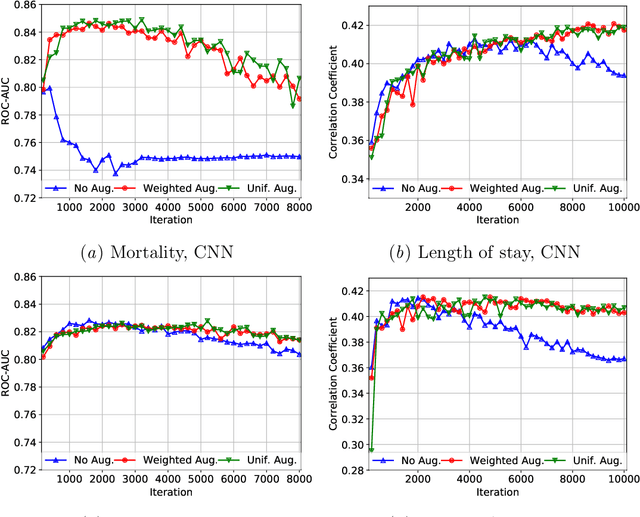
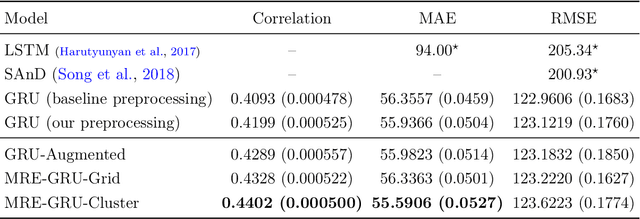
Electronic records contain sequences of events, some of which take place all at once in a single visit, and others that are dispersed over multiple visits, each with a different timestamp. We postulate that fine temporal detail, e.g., whether a series of blood tests are completed at once or in rapid succession should not alter predictions based on this data. Motivated by this intuition, we propose models for analyzing sequences of multivariate clinical time series data that are invariant to this temporal clustering. We propose an efficient data augmentation technique that exploits the postulated temporal-clustering invariance to regularize deep neural networks optimized for several clinical prediction tasks. We introduce two techniques to temporally coarsen (downsample) irregular time series: (i) grouping the data points based on regularly-spaced timestamps; and (ii) clustering them, yielding irregularly-paced timestamps. Moreover, we propose a MultiResolution Ensemble (MRE) model, improving predictive accuracy by ensembling predictions based on inputs sequences transformed by different coarsening operators. Our experiments show that MRE improves the mAP on the benchmark mortality prediction task from 51.53% to 53.92%.
Deep Learning of Movement Intent and Reaction Time for EEG-informed Adaptation of Rehabilitation Robots
Feb 18, 2020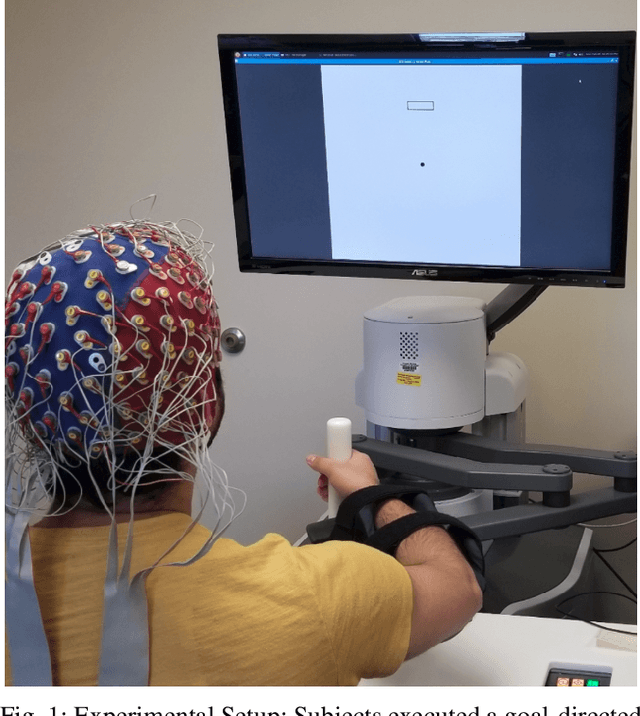

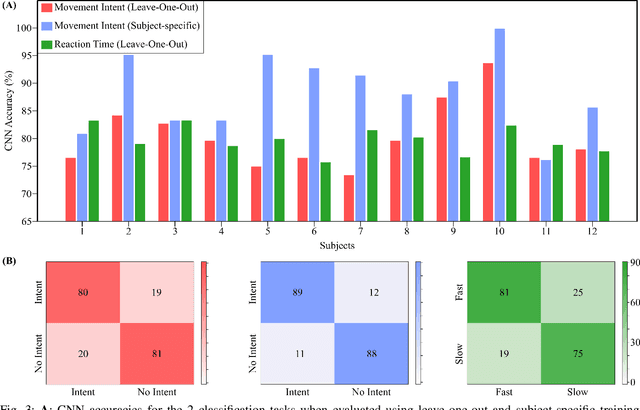
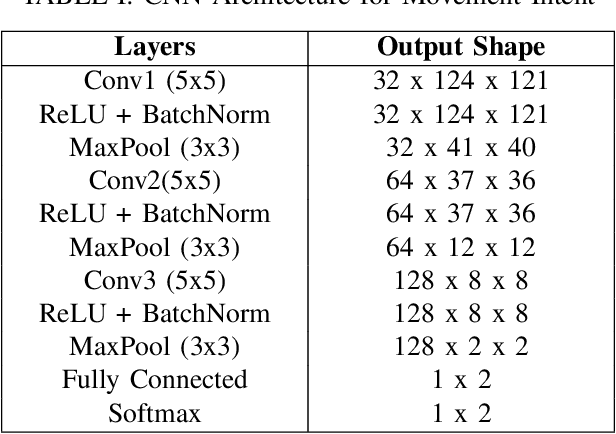
Mounting evidence suggests that adaptation is a crucial mechanism for rehabilitation robots in promoting motor learning. Yet, it is commonly based on robot-derived movement kinematics, which is a rather subjective measurement of performance, especially in the presence of a sensorimotor impairment. Here, we propose a deep convolutional neural network (CNN) that uses electroencephalography (EEG) as an objective measurement of two kinematics components that are typically used to assess motor learning and thereby adaptation: i) the intent to initiate a goal-directed movement, and ii) the reaction time (RT) of that movement. We evaluated our CNN on data acquired from an in-house experiment where 13 subjects moved a rehabilitation robotic arm in four directions on a plane, in response to visual stimuli. Our CNN achieved average test accuracies of 80.08% and 79.82% in a binary classification of the intent (intent vs. no intent) and RT (slow vs. fast), respectively. Our results demonstrate how individual movement components implicated in distinct types of motor learning can be predicted from synchronized EEG data acquired before the start of the movement. Our approach can, therefore, inform robotic adaptation in real-time and has the potential to further improve one's ability to perform the rehabilitation task.
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021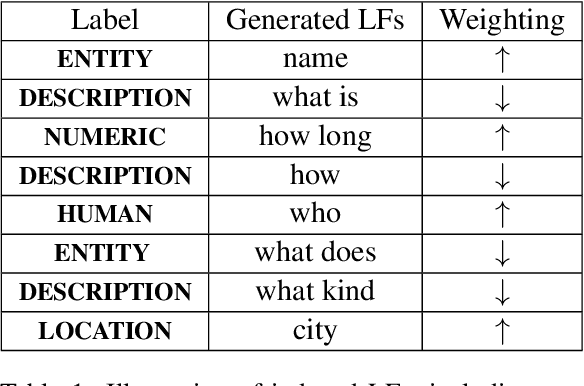
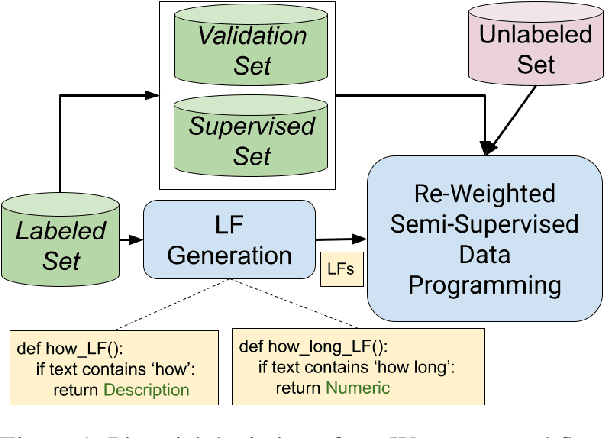
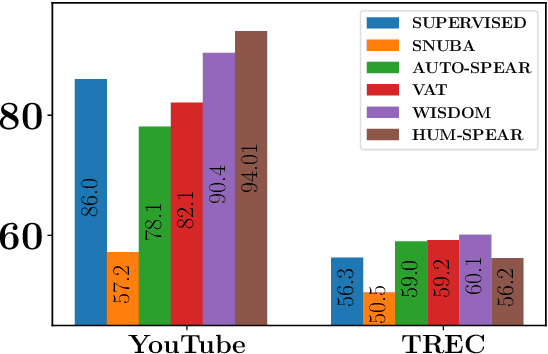
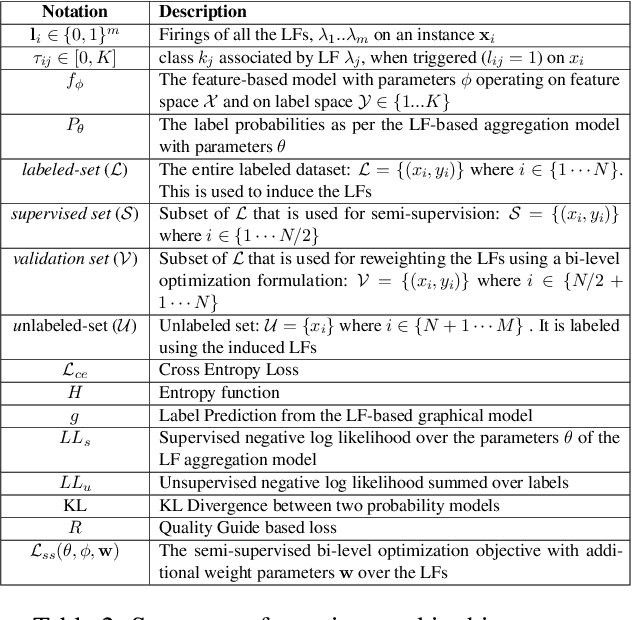
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.