 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-DoF Time Domain Passivity Approach based Drift Compensation for Telemanipulation
Sep 04, 2019

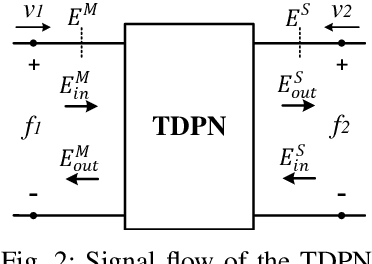
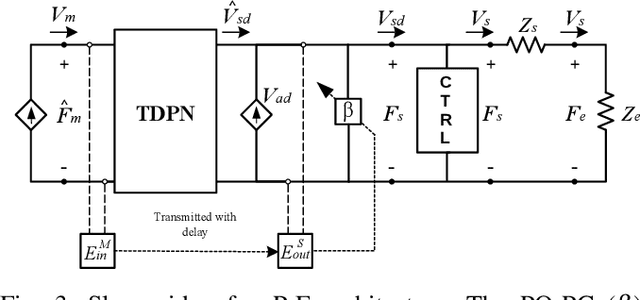
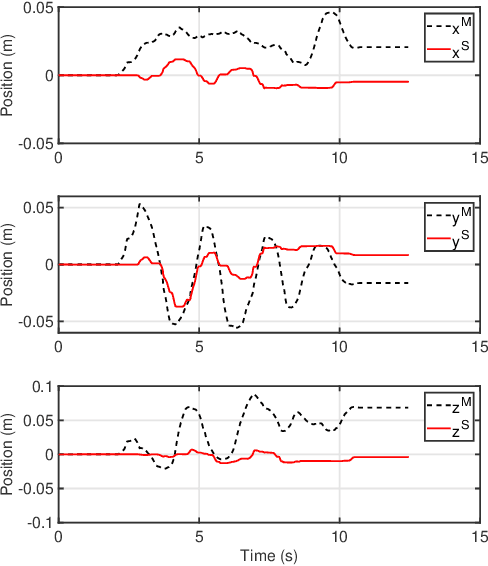
When, in addition to stability, position synchronization is also desired in bilateral teleoperation, Time Domain Passivity Approach (TDPA) alone might not be able to fulfill the desired objective. This is due to an undesired effect caused by admittance type passivity controllers, namely position drift. Previous works focused on developing TDPA-based drift compensation methods to solve this issue. It was shown that, in addition to reducing drift, one of the proposed methods was able to keep the force signals within their normal range, guaranteeing the safety of the task. However, no multi-DoF treatment of those approaches has been addressed. In that scope, this paper focuses on providing an extension of previous TDPA-based approaches to multi-DoF Cartesian-space teleoperation. An analysis of the convergence properties of the presented method is also provided. In addition, its applicability to multi-DoF devices is shown through hardware experiments and numerical simulation with round-trip time delays up to 700 ms.
Transformer-based Spatial-Temporal Feature Learning for EEG Decoding
Jun 11, 2021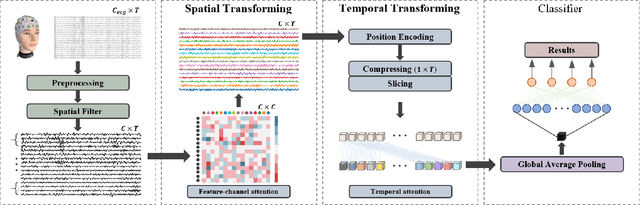
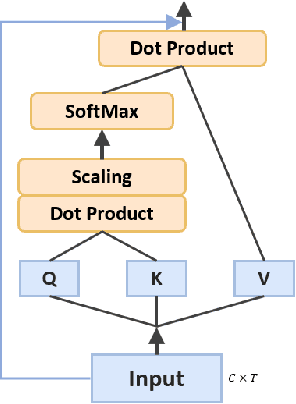
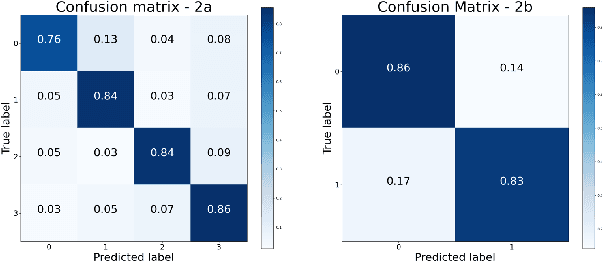
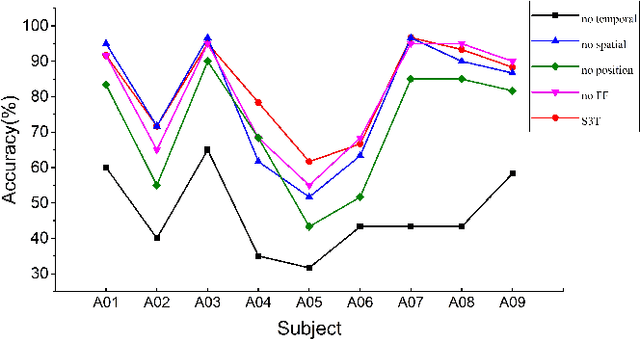
At present, people usually use some methods based on convolutional neural networks (CNNs) for Electroencephalograph (EEG) decoding. However, CNNs have limitations in perceiving global dependencies, which is not adequate for common EEG paradigms with a strong overall relationship. Regarding this issue, we propose a novel EEG decoding method that mainly relies on the attention mechanism. The EEG data is firstly preprocessed and spatially filtered. And then, we apply attention transforming on the feature-channel dimension so that the model can enhance more relevant spatial features. The most crucial step is to slice the data in the time dimension for attention transforming, and finally obtain a highly distinguishable representation. At this time, global averaging pooling and a simple fully-connected layer are used to classify different categories of EEG data. Experiments on two public datasets indicate that the strategy of attention transforming effectively utilizes spatial and temporal features. And we have reached the level of the state-of-the-art in multi-classification of EEG, with fewer parameters. As far as we know, it is the first time that a detailed and complete method based on the transformer idea has been proposed in this field. It has good potential to promote the practicality of brain-computer interface (BCI). The source code can be found at: \textit{https://github.com/anranknight/EEG-Transformer}.
Identification and Avoidance of Static and Dynamic Obstacles on Point Cloud for UAVs Navigation
May 14, 2021
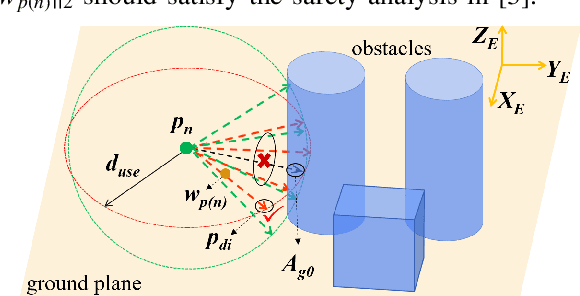
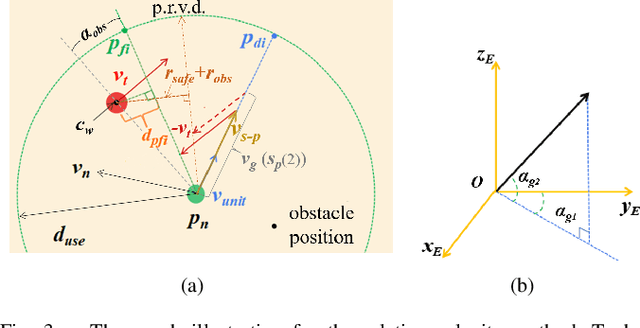
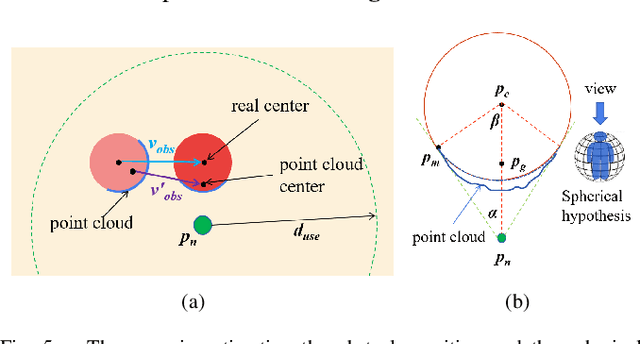
Avoiding hybrid obstacles in unknown scenarios with an efficient flight strategy is a key challenge for unmanned aerial vehicle applications. In this paper, we introduce a technique to distinguish dynamic obstacles from static ones with only point cloud input. Then, a computationally efficient obstacle avoidance motion planning approach is proposed and it is in line with an improved relative velocity method. The approach is able to avoid both static obstacles and dynamic ones in the same framework. For static and dynamic obstacles, the collision check and motion constraints are different, and they are integrated into one framework efficiently. In addition, we present several techniques to improve the algorithm performance and deal with the time gap between different submodules. The proposed approach is implemented to run onboard in real-time and validated extensively in simulation and hardware tests. Our average single step calculating time is less than 20 ms.
Deep Structural Point Process for Learning Temporal Interaction Networks
Jul 08, 2021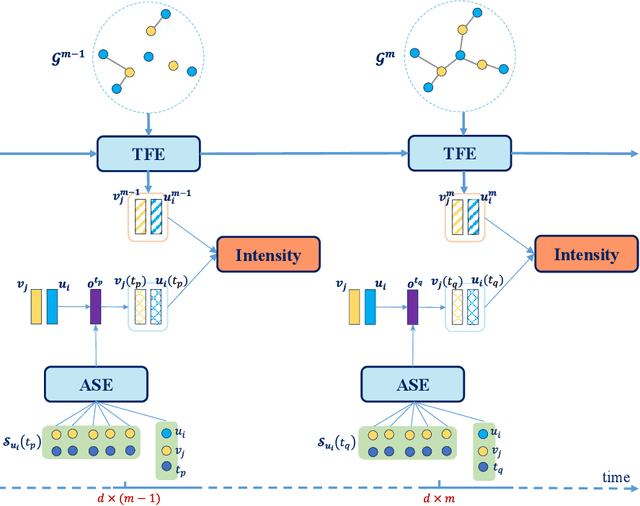

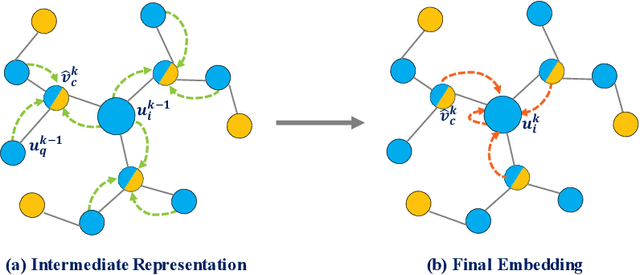
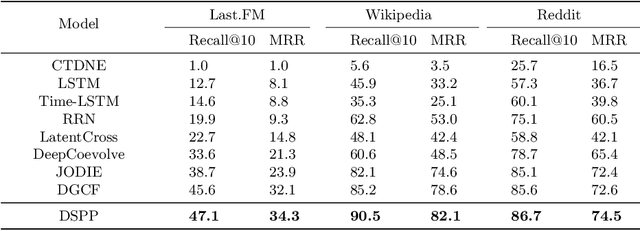
This work investigates the problem of learning temporal interaction networks. A temporal interaction network consists of a series of chronological interactions between users and items. Previous methods tackle this problem by using different variants of recurrent neural networks to model sequential interactions, which fail to consider the structural information of temporal interaction networks and inevitably lead to sub-optimal results. To this end, we propose a novel Deep Structural Point Process termed as DSPP for learning temporal interaction networks. DSPP simultaneously incorporates the topological structure and long-range dependency structure into our intensity function to enhance model expressiveness. To be specific, by using the topological structure as a strong prior, we first design a topological fusion encoder to obtain node embeddings. An attentive shift encoder is then developed to learn the long-range dependency structure between users and items in continuous time. The proposed two modules enable our model to capture the user-item correlation and dynamic influence in temporal interaction networks. DSPP is evaluated on three real-world datasets for both tasks of item prediction and time prediction. Extensive experiments demonstrate that our model achieves consistent and significant improvements over state-of-the-art baselines.
Safe Control with Neural Network Dynamic Models
Oct 03, 2021
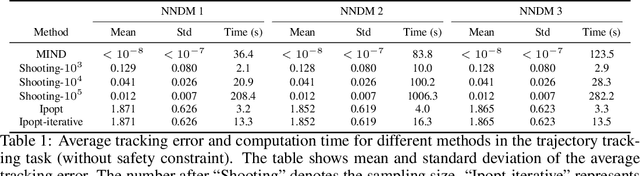
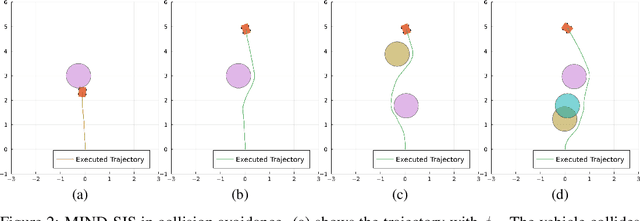

Safety is critical in autonomous robotic systems. A safe control law ensures forward invariance of a safe set (a subset in the state space). It has been extensively studied regarding how to derive a safe control law with a control-affine analytical dynamic model. However, in complex environments and tasks, it is challenging and time-consuming to obtain a principled analytical model of the system. In these situations, data-driven learning is extensively used and the learned models are encoded in neural networks. How to formally derive a safe control law with Neural Network Dynamic Models (NNDM) remains unclear due to the lack of computationally tractable methods to deal with these black-box functions. In fact, even finding the control that minimizes an objective for NNDM without any safety constraint is still challenging. In this work, we propose MIND-SIS (Mixed Integer for Neural network Dynamic model with Safety Index Synthesis), the first method to derive safe control laws for NNDM. The method includes two parts: 1) SIS: an algorithm for the offline synthesis of the safety index (also called as barrier function), which uses evolutionary methods and 2) MIND: an algorithm for online computation of the optimal and safe control signal, which solves a constrained optimization using a computationally efficient encoding of neural networks. It has been theoretically proved that MIND-SIS guarantees forward invariance and finite convergence. And it has been numerically validated that MIND-SIS achieves safe and optimal control of NNDM. From our experiments, the optimality gap is less than $10^{-8}$, and the safety constraint violation is $0$.
Rethinking the constraints of multimodal fusion: case study in Weakly-Supervised Audio-Visual Video Parsing
May 30, 2021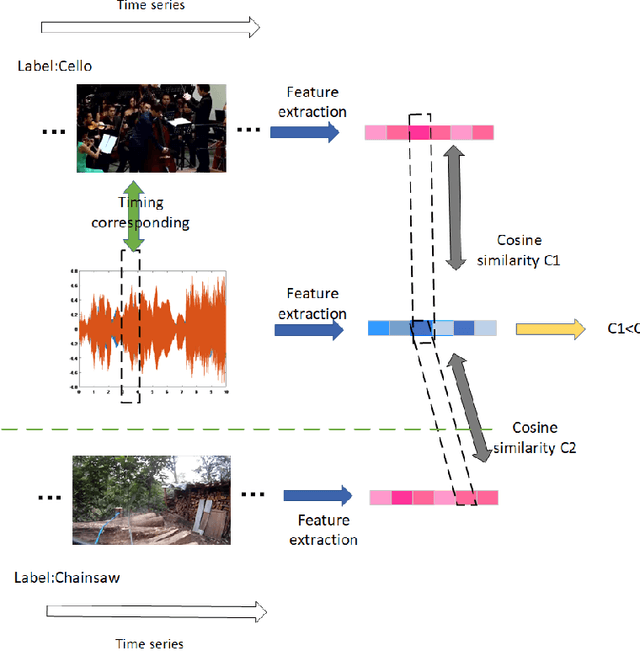

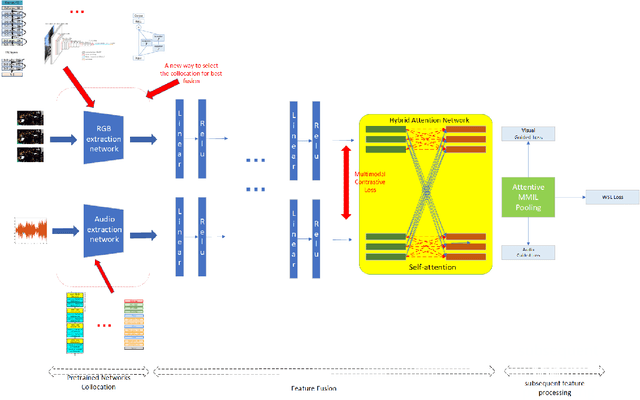
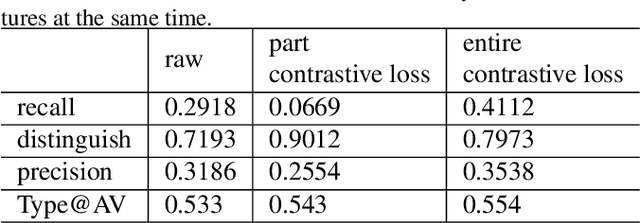
For multimodal tasks, a good feature extraction network should extract information as much as possible and ensure that the extracted feature embedding and other modal feature embedding have an excellent mutual understanding. The latter is often more critical in feature fusion than the former. Therefore, selecting the optimal feature extraction network collocation is a very important subproblem in multimodal tasks. Most of the existing studies ignore this problem or adopt an ergodic approach. This problem is modeled as an optimization problem in this paper. A novel method is proposed to convert the optimization problem into an issue of comparative upper bounds by referring to the general practice of extreme value conversion in mathematics. Compared with the traditional method, it reduces the time cost. Meanwhile, aiming at the common problem that the feature similarity and the feature semantic similarity are not aligned in the multimodal time-series problem, we refer to the idea of contrast learning and propose a multimodal time-series contrastive loss(MTSC). Based on the above issues, We demonstrated the feasibility of our approach in the audio-visual video parsing task. Substantial analyses verify that our methods promote the fusion of different modal features.
Diabetic Retinopathy Screening Using Custom-Designed Convolutional Neural Network
Oct 08, 2021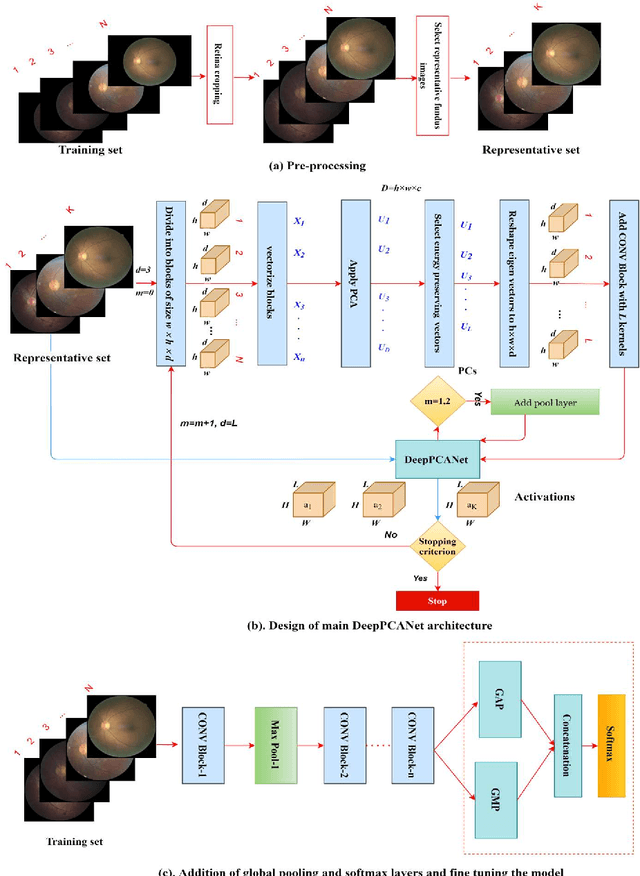
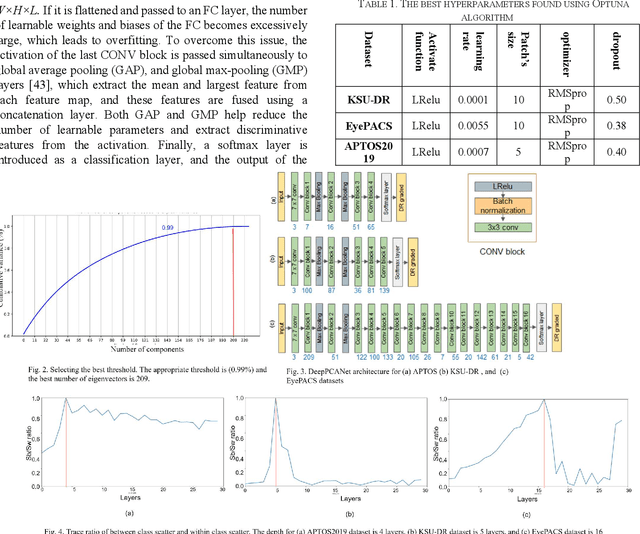
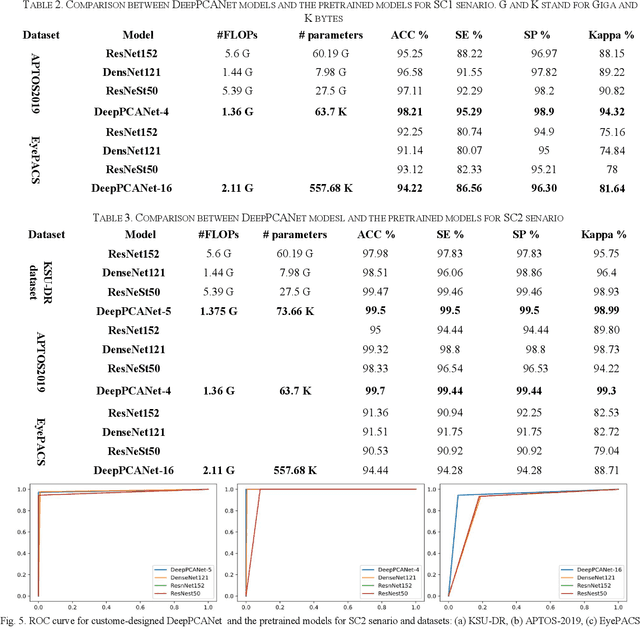
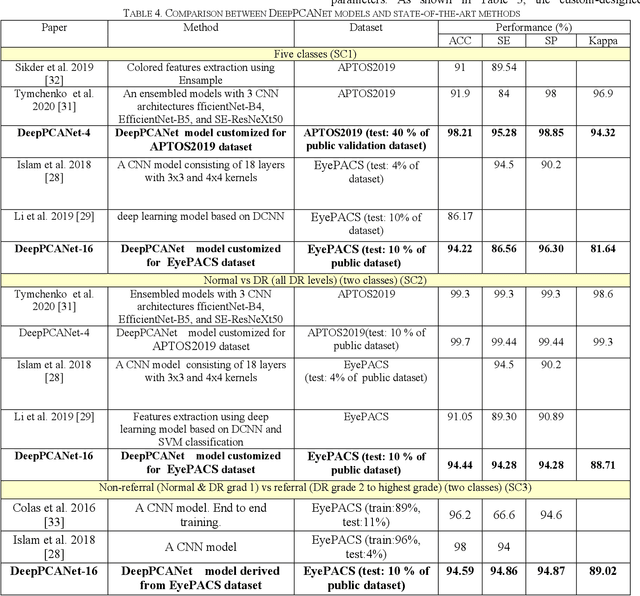
The prevalence of diabetic retinopathy (DR) has reached 34.6% worldwide and is a major cause of blindness among middle-aged diabetic patients. Regular DR screening using fundus photography helps detect its complications and prevent its progression to advanced levels. As manual screening is time-consuming and subjective, machine learning (ML) and deep learning (DL) have been employed to aid graders. However, the existing CNN-based methods use either pre-trained CNN models or a brute force approach to design new CNN models, which are not customized to the complexity of fundus images. To overcome this issue, we introduce an approach for custom-design of CNN models, whose architectures are adapted to the structural patterns of fundus images and better represent the DR-relevant features. It takes the leverage of k-medoid clustering, principal component analysis (PCA), and inter-class and intra-class variations to automatically determine the depth and width of a CNN model. The designed models are lightweight, adapted to the internal structures of fundus images, and encode the discriminative patterns of DR lesions. The technique is validated on a local dataset from King Saud University Medical City, Saudi Arabia, and two challenging benchmark datasets from Kaggle: EyePACS and APTOS2019. The custom-designed models outperform the famous pre-trained CNN models like ResNet152, Densnet121, and ResNeSt50 with a significant decrease in the number of parameters and compete well with the state-of-the-art CNN-based DR screening methods. The proposed approach is helpful for DR screening under diverse clinical settings and referring the patients who may need further assessment and treatment to expert ophthalmologists.
Individualized Time-Series Segmentation for Mining Mobile Phone User Behavior
Nov 15, 2018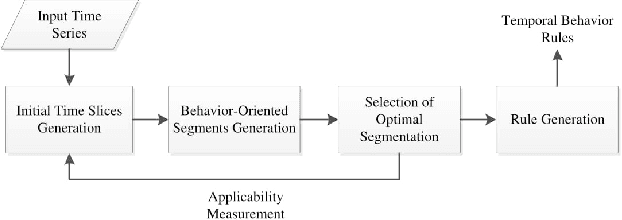
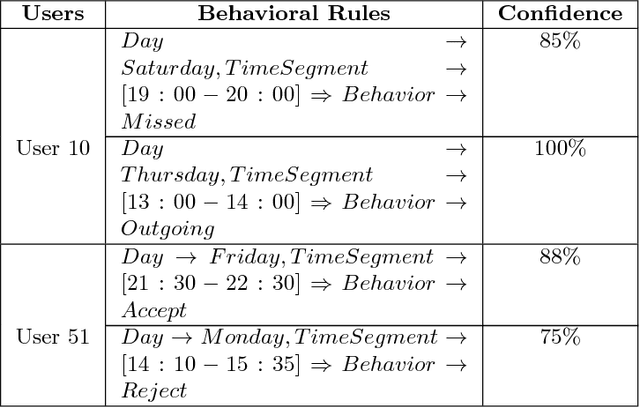

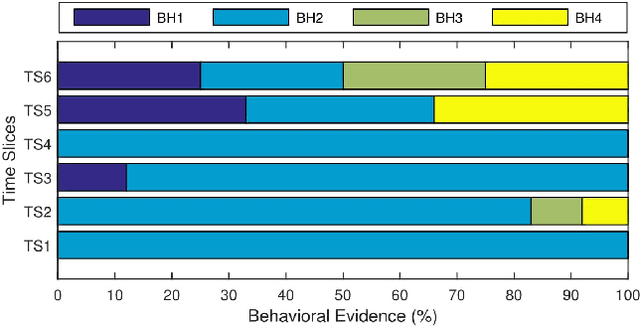
Mobile phones can record individual's daily behavioral data as a time-series. In this paper, we present an effective time-series segmentation technique that extracts optimal time segments of individual's similar behavioral characteristics utilizing their mobile phone data. One of the determinants of an individual's behavior is the various activities undertaken at various times-of-the-day and days-of-the-week. In many cases, such behavior will follow temporal patterns. Currently, researchers use either equal or unequal interval-based segmentation of time for mining mobile phone users' behavior. Most of them take into account static temporal coverage of 24-h-a-day and few of them take into account the number of incidences in time-series data. However, such segmentations do not necessarily map to the patterns of individual user activity and subsequent behavior because of not taking into account the diverse behaviors of individuals over time-of-the-week. Therefore, we propose a behavior-oriented time segmentation (BOTS) technique that takes into account not only the temporal coverage of the week but also the number of incidences of diverse behaviors dynamically for producing similar behavioral time segments over the week utilizing time-series data. Experiments on the real mobile phone datasets show that our proposed segmentation technique better captures the user's dominant behavior at various times-of-the-day and days-of-the-week enabling the generation of high confidence temporal rules in order to mine individual mobile phone users' behavior.
* 20 pages
MSTC*:Multi-robot Coverage Path Planning under Physical Constraints
Aug 10, 2021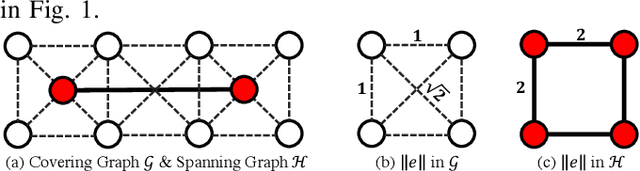
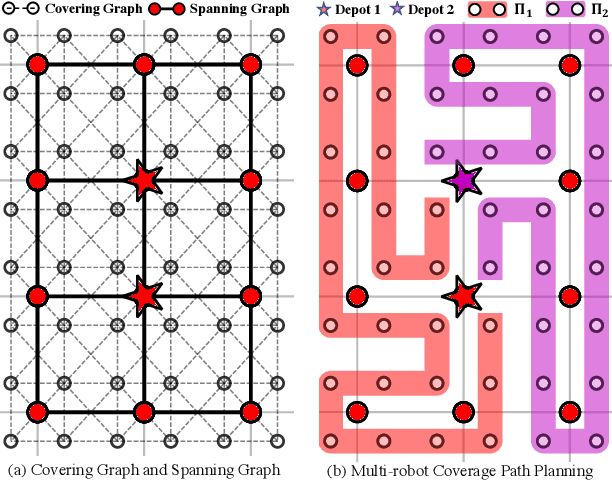
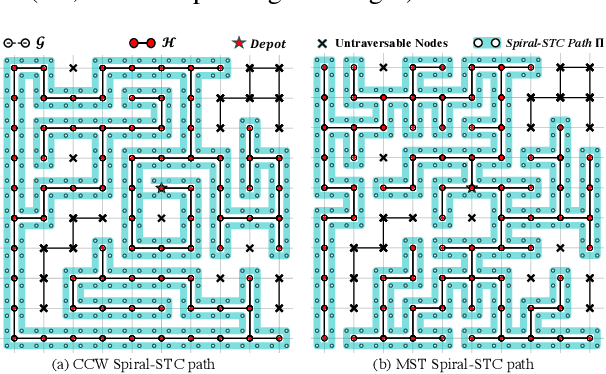

For large-scale tasks, coverage path planning (CPP) can benefit greatly from multiple robots. In this paper, we present an efficient algorithm MSTC* for multi-robot coverage path planning (mCPP) based on spiral spanning tree coverage (Spiral-STC). Our algorithm incorporates strict physical constraints like terrain traversability and material load capacity. We compare our algorithm against the state-of-the-art in mCPP for regular grid maps and real field terrains in simulation environments. The experimental results show that our method significantly outperforms existing spiral-STC based mCPP methods. Our algorithm can find a set of well-balanced workload distributions for all robots and therefore, achieve the overall minimum time to complete the coverage.
Towards Understanding Persuasion in Computational Argumentation
Oct 03, 2021


Opinion formation and persuasion in argumentation are affected by three major factors: the argument itself, the source of the argument, and the properties of the audience. Understanding the role of each and the interplay between them is crucial for obtaining insights regarding argument interpretation and generation. It is particularly important for building effective argument generation systems that can take both the discourse and the audience characteristics into account. Having such personalized argument generation systems would be helpful to expose individuals to different viewpoints and help them make a more fair and informed decision on an issue. Even though studies in Social Sciences and Psychology have shown that source and audience effects are essential components of the persuasion process, most research in computational persuasion has focused solely on understanding the characteristics of persuasive language. In this thesis, we make several contributions to understand the relative effect of the source, audience, and language in computational persuasion. We first introduce a large-scale dataset with extensive user information to study these factors' effects simultaneously. Then, we propose models to understand the role of the audience's prior beliefs on their perception of arguments. We also investigate the role of social interactions and engagement in understanding users' success in online debating over time. We find that the users' prior beliefs and social interactions play an essential role in predicting their success in persuasion. Finally, we explore the importance of incorporating contextual information to predict argument impact and show improvements compared to encoding only the text of the arguments.