 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Learning using Monotonic Logical Properties
Aug 01, 2018
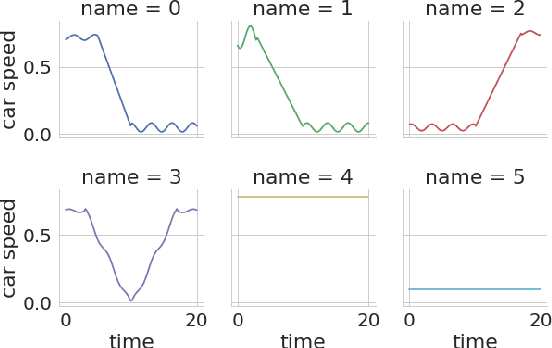
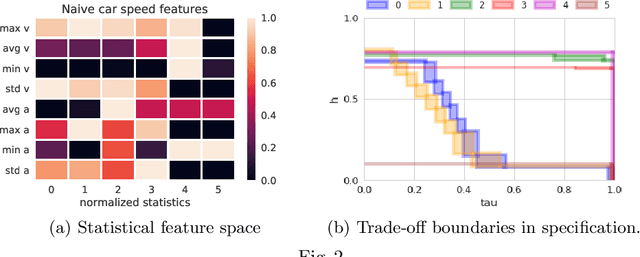
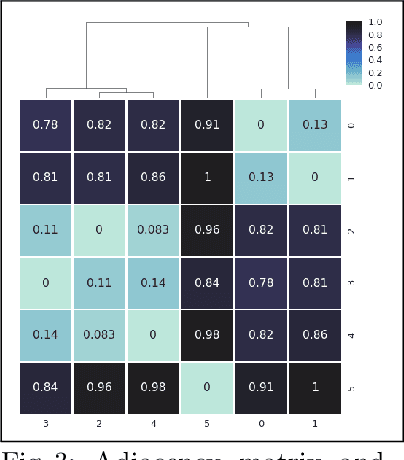
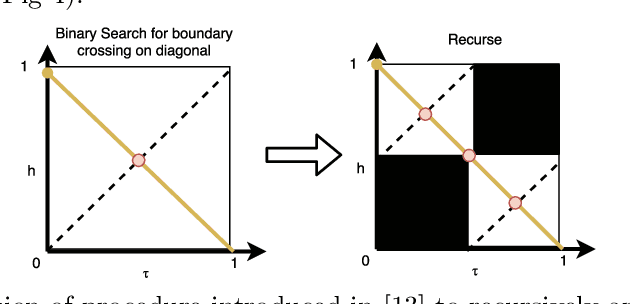
Cyber-physical systems of today are generating large volumes of time-series data. As manual inspection of such data is not tractable, the need for learning methods to help discover logical structure in the data has increased. We propose a logic-based framework that allows domain-specific knowledge to be embedded into formulas in a parametric logical specification over time-series data. The key idea is to then map a time series to a surface in the parameter space of the formula. Given this mapping, we identify the Hausdorff distance between boundaries as a natural distance metric between two time-series data under the lens of the parametric specification. This enables embedding non-trivial domain-specific knowledge into the distance metric and then using off-the-shelf machine learning tools to label the data. After labeling the data, we demonstrate how to extract a logical specification for each label. Finally, we showcase our technique on real world traffic data to learn classifiers/monitors for slow-downs and traffic jams.
APPLE: Adaptive Planner Parameter Learning from Evaluative Feedback
Aug 22, 2021


Classical autonomous navigation systems can control robots in a collision-free manner, oftentimes with verifiable safety and explainability. When facing new environments, however, fine-tuning of the system parameters by an expert is typically required before the system can navigate as expected. To alleviate this requirement, the recently-proposed Adaptive Planner Parameter Learning paradigm allows robots to \emph{learn} how to dynamically adjust planner parameters using a teleoperated demonstration or corrective interventions from non-expert users. However, these interaction modalities require users to take full control of the moving robot, which requires the users to be familiar with robot teleoperation. As an alternative, we introduce \textsc{apple}, Adaptive Planner Parameter Learning from \emph{Evaluative Feedback} (real-time, scalar-valued assessments of behavior), which represents a less-demanding modality of interaction. Simulated and physical experiments show \textsc{apple} can achieve better performance compared to the planner with static default parameters and even yield improvement over learned parameters from richer interaction modalities.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021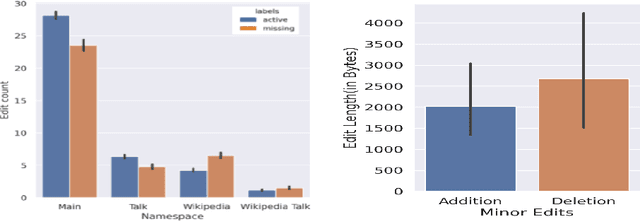

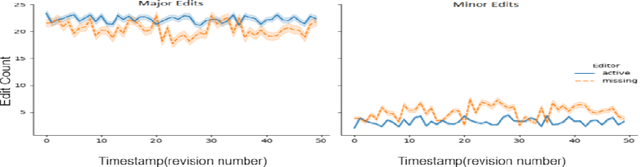

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
UltraBot: Autonomous Mobile Robot for Indoor UV-C Disinfection
Aug 22, 2021
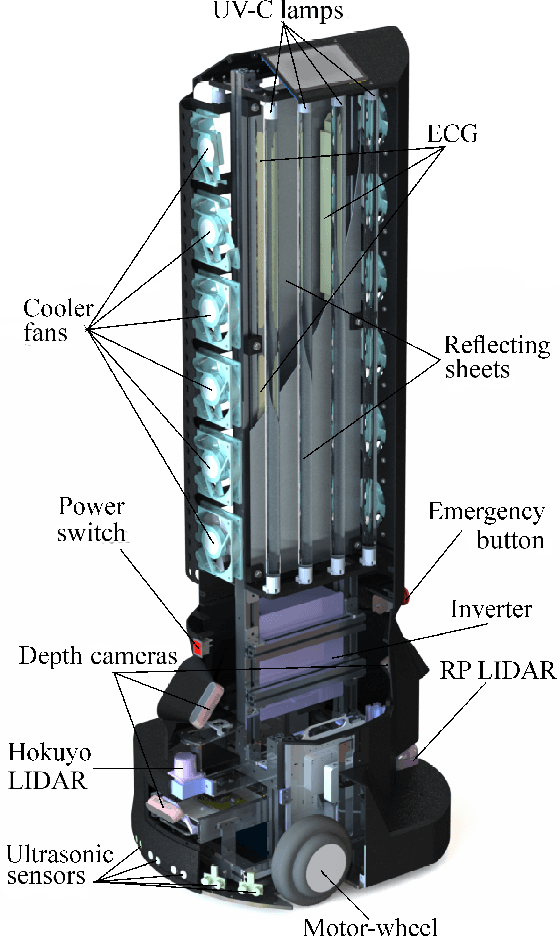
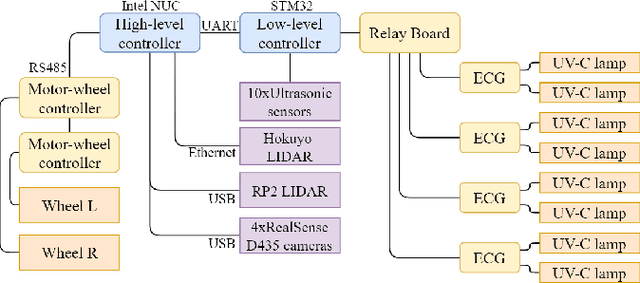
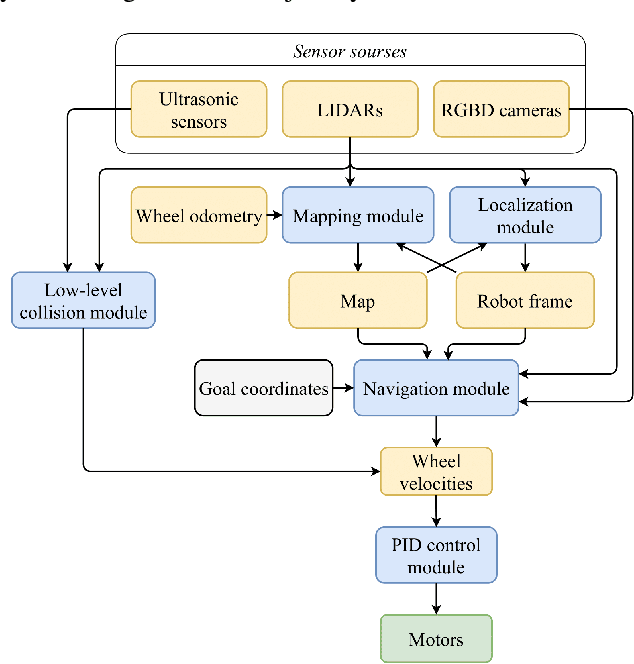
The paper focuses on the development of the autonomous robot UltraBot to reduce COVID-19 transmission and other harmful bacteria and viruses. The motivation behind the research is to develop such a robot that is capable of performing disinfection tasks without the use of harmful sprays and chemicals that can leave residues, require airing the room afterward for a long time, and can cause the corrosion of the metal structures. UltraBot technology has the potential to offer the most optimal autonomous disinfection performance along with taking care of people, keeping them from getting under UV-C radiation. The paper highlights UltraBot's mechanical and electrical structures as well as low-level and high-level control systems. The conducted experiments demonstrate the effectiveness of the robot localization module and optimal trajectories for UV-C disinfection. The results of UV-C disinfection performance revealed a decrease of the total bacterial count (TBC) by 94% on the distance of 2.8 meters from the robot after 10 minutes of UV-C irradiation.
Asynchronous Stochastic Optimization Robust to Arbitrary Delays
Jun 22, 2021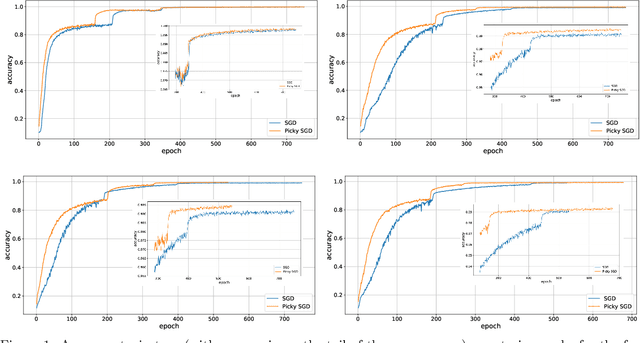
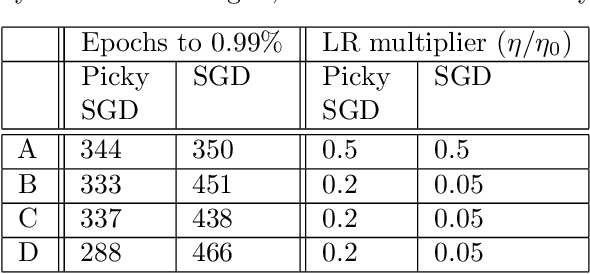
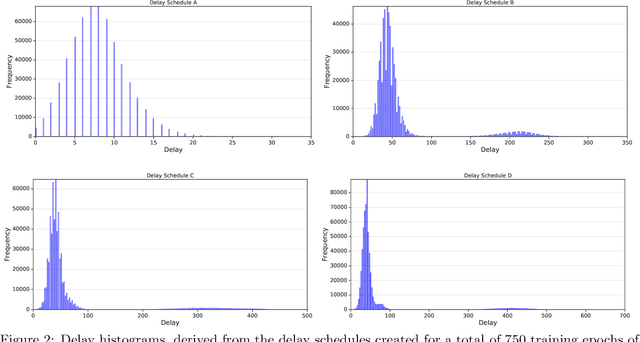
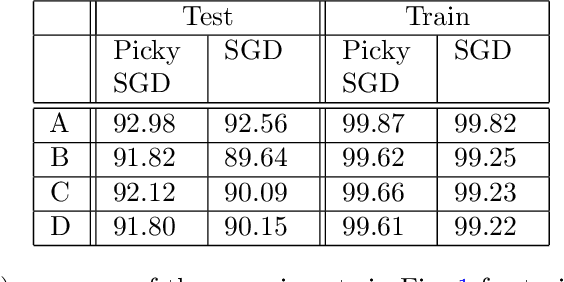
We consider stochastic optimization with delayed gradients where, at each time step $t$, the algorithm makes an update using a stale stochastic gradient from step $t - d_t$ for some arbitrary delay $d_t$. This setting abstracts asynchronous distributed optimization where a central server receives gradient updates computed by worker machines. These machines can experience computation and communication loads that might vary significantly over time. In the general non-convex smooth optimization setting, we give a simple and efficient algorithm that requires $O( \sigma^2/\epsilon^4 + \tau/\epsilon^2 )$ steps for finding an $\epsilon$-stationary point $x$, where $\tau$ is the \emph{average} delay $\smash{\frac{1}{T}\sum_{t=1}^T d_t}$ and $\sigma^2$ is the variance of the stochastic gradients. This improves over previous work, which showed that stochastic gradient decent achieves the same rate but with respect to the \emph{maximal} delay $\max_{t} d_t$, that can be significantly larger than the average delay especially in heterogeneous distributed systems. Our experiments demonstrate the efficacy and robustness of our algorithm in cases where the delay distribution is skewed or heavy-tailed.
Graph2Pix: A Graph-Based Image to Image Translation Framework
Aug 22, 2021
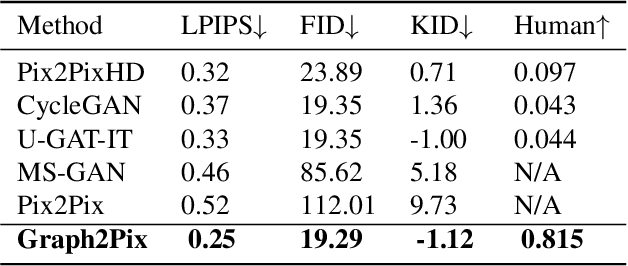
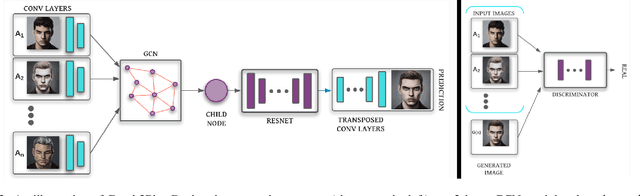
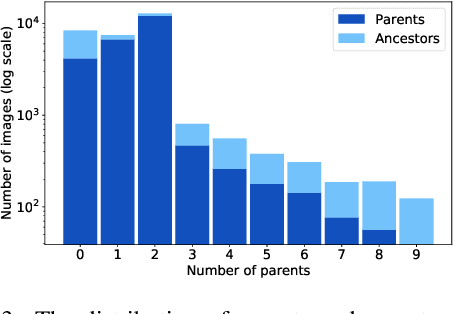
In this paper, we propose a graph-based image-to-image translation framework for generating images. We use rich data collected from the popular creativity platform Artbreeder (http://artbreeder.com), where users interpolate multiple GAN-generated images to create artworks. This unique approach of creating new images leads to a tree-like structure where one can track historical data about the creation of a particular image. Inspired by this structure, we propose a novel graph-to-image translation model called Graph2Pix, which takes a graph and corresponding images as input and generates a single image as output. Our experiments show that Graph2Pix is able to outperform several image-to-image translation frameworks on benchmark metrics, including LPIPS (with a 25% improvement) and human perception studies (n=60), where users preferred the images generated by our method 81.5% of the time. Our source code and dataset are publicly available at https://github.com/catlab-team/graph2pix.
Path classification by stochastic linear recurrent neural networks
Aug 06, 2021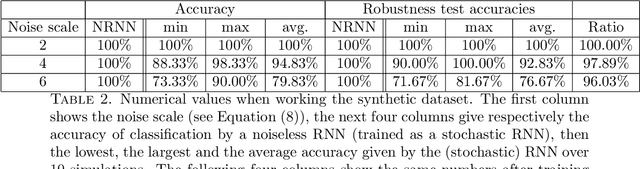
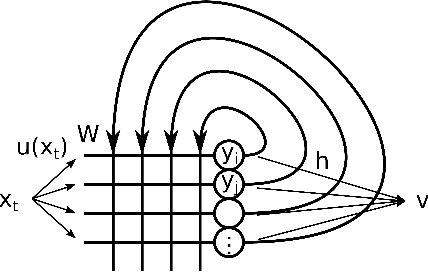
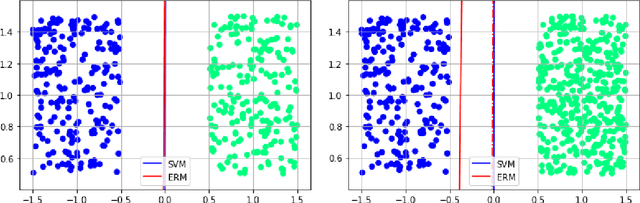
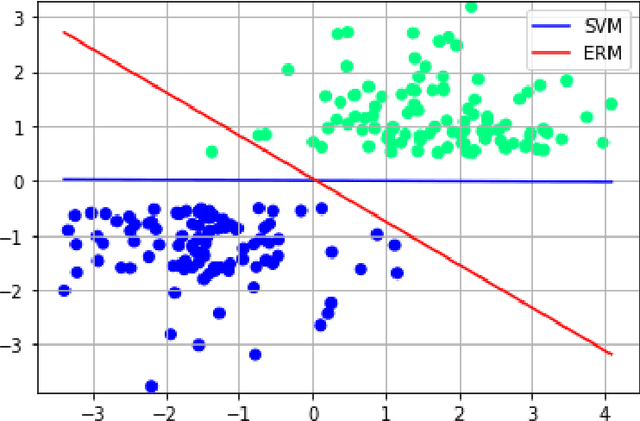
We investigate the functioning of a classifying biological neural network from the perspective of statistical learning theory, modelled, in a simplified setting, as a continuous-time stochastic recurrent neural network (RNN) with identity activation function. In the purely stochastic (robust) regime, we give a generalisation error bound that holds with high probability, thus showing that the empirical risk minimiser is the best-in-class hypothesis. We show that RNNs retain a partial signature of the paths they are fed as the unique information exploited for training and classification tasks. We argue that these RNNs are easy to train and robust and back these observations with numerical experiments on both synthetic and real data. We also exhibit a trade-off phenomenon between accuracy and robustness.
Differentiable Surface Rendering via Non-Differentiable Sampling
Aug 10, 2021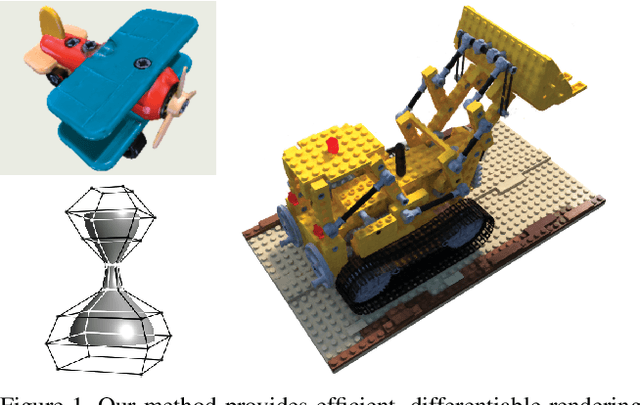

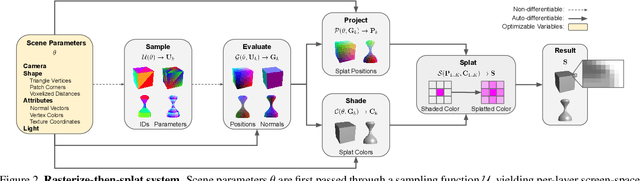
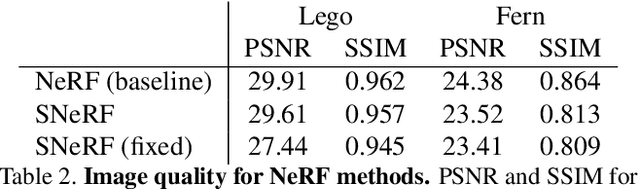
We present a method for differentiable rendering of 3D surfaces that supports both explicit and implicit representations, provides derivatives at occlusion boundaries, and is fast and simple to implement. The method first samples the surface using non-differentiable rasterization, then applies differentiable, depth-aware point splatting to produce the final image. Our approach requires no differentiable meshing or rasterization steps, making it efficient for large 3D models and applicable to isosurfaces extracted from implicit surface definitions. We demonstrate the effectiveness of our method for implicit-, mesh-, and parametric-surface-based inverse rendering and neural-network training applications. In particular, we show for the first time efficient, differentiable rendering of an isosurface extracted from a neural radiance field (NeRF), and demonstrate surface-based, rather than volume-based, rendering of a NeRF.
Anxious Depression Prediction in Real-time Social Data
Mar 25, 2019
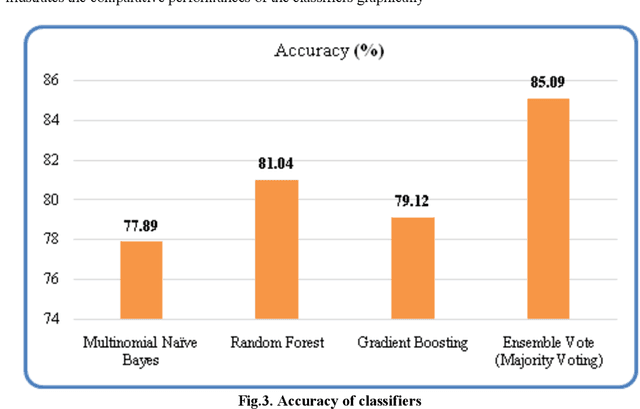
Mental well-being and social media have been closely related domains of study. In this research a novel model, AD prediction model, for anxious depression prediction in real-time tweets is proposed. This mixed anxiety-depressive disorder is a predominantly associated with erratic thought process, restlessness and sleeplessness. Based on the linguistic cues and user posting patterns, the feature set is defined using a 5-tuple vector <word, timing, frequency, sentiment, contrast>. An anxiety-related lexicon is built to detect the presence of anxiety indicators. Time and frequency of tweet is analyzed for irregularities and opinion polarity analytics is done to find inconsistencies in posting behaviour. The model is trained using three classifiers (multinomial na\"ive bayes, gradient boosting, and random forest) and majority voting using an ensemble voting classifier is done. Preliminary results are evaluated for tweets of sampled 100 users and the proposed model achieves a classification accuracy of 85.09%.
Attempt to Predict Failure Case Classification in a Failure Database by using Neural Network Models
Aug 29, 2021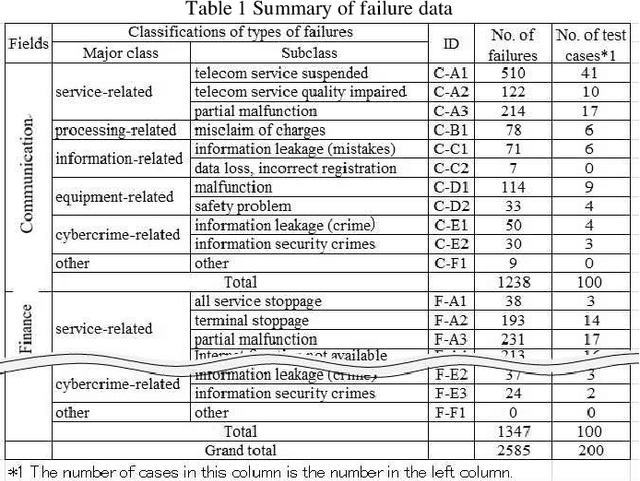
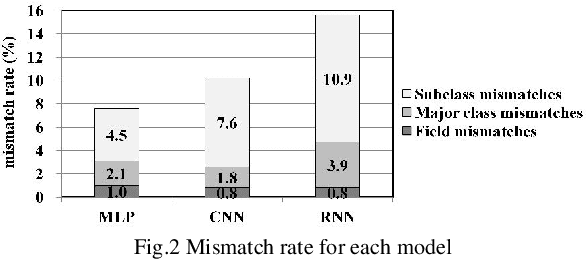
With the recent progress of information technology, the use of networked information systems has rapidly expanded. Electronic commerce and electronic payments between banks and companies, and online shopping and social networking services used by the general public are examples of such systems. Therefore, in order to maintain and improve the dependability of these systems, we are constructing a failure database from past failure cases. When importing new failure cases to the database, it is necessary to classify these cases according to failure type. The problems are the accuracy and efficiency of the classification. Especially when working with multiple individuals, unification of classification is required. Therefore, we are attempting to automate classification using machine learning. As evaluation models, we selected the multilayer perceptron (MLP), the convolutional neural network (CNN), and the recurrent neural network (RNN), which are models that use neural networks. As a result, the optimal model in terms of accuracy is first the MLP followed by the CNN, and the processing time of the classification is practical.