 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021
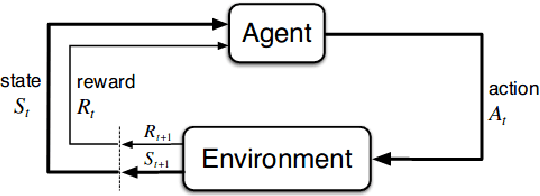
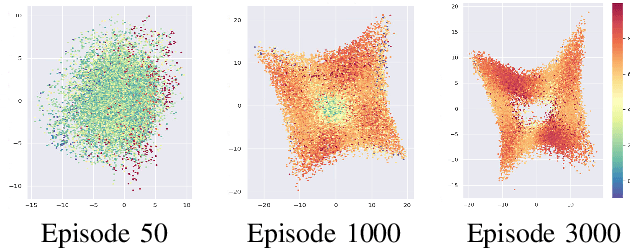
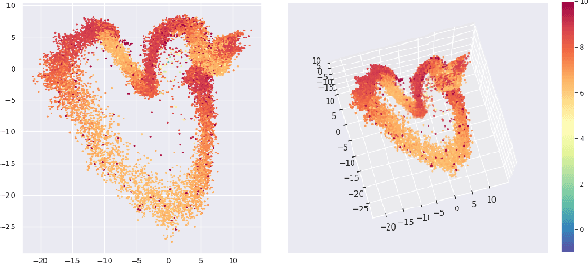
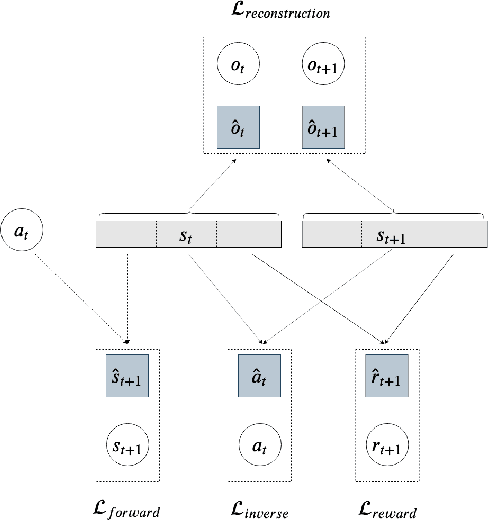
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
Performance evaluation of deep neural networks for forecasting time-series with multiple structural breaks and high volatility
Nov 14, 2019
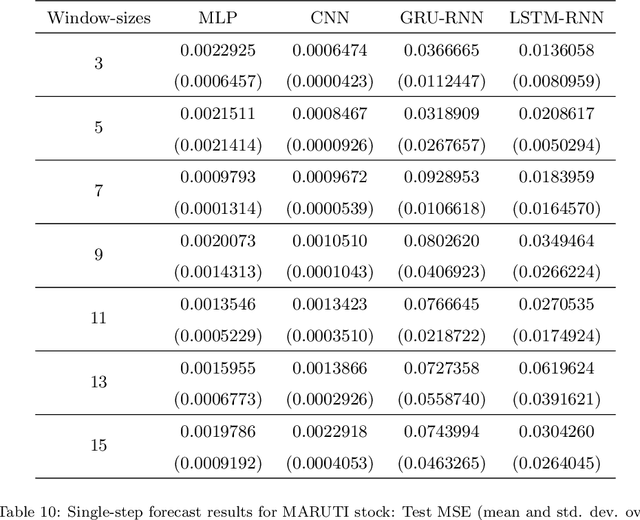
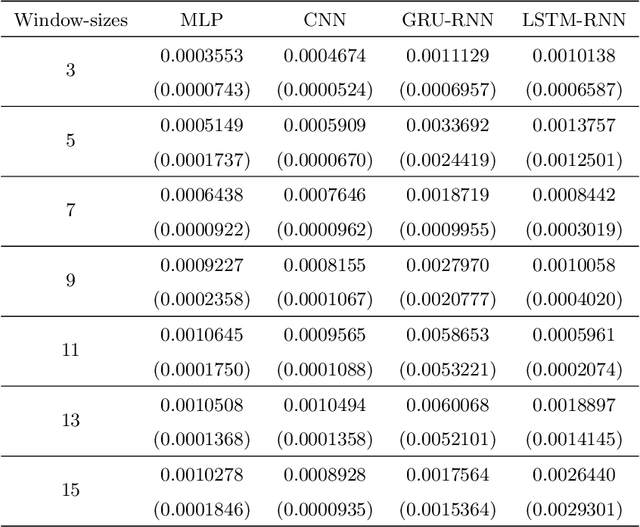
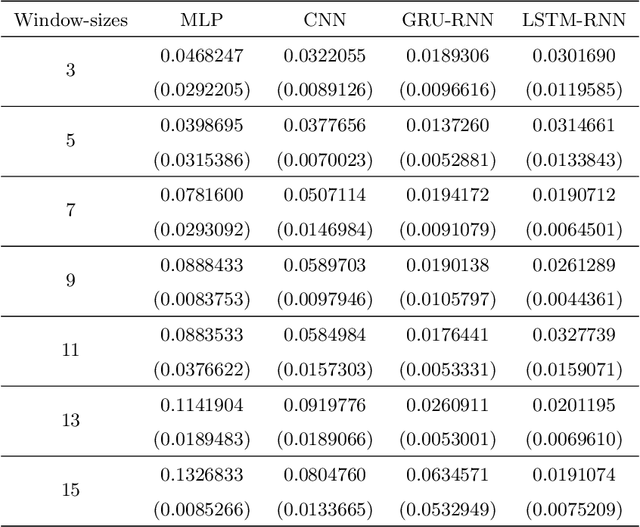
The problem of automatic forecasting of time-series data has been a long-standing challenge for the machine learning and forecasting community. The problem is relatively simple when the series is stationary. However, the majority of the real-world time-series problems have non-stationary characteristics making the understanding of the trend and seasonality very complex. Further, it is assumed that the future response is dependent on the past data and, therefore, can be modeled using a function approximator. Our interest in this paper is to study the applicability of the popular deep neural networks (DNN) comprehensively as function approximators for non-stationary time-series forecasting. We employ the following DNN models: Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN), and RNN with Long-Short Term Memory (LSTM-RNN) and RNN with Gated-Recurrent Unit (GRU-RNN). These powerful DNN methods have been evaluated over popular Indian financial stocks data comprising of five stocks from National Stock Exchange Nifty-50 (NSE-Nifty50), and five stocks from Bombay Stock Exchange 30 (BSE-30). Further, the performance evaluation of these DNNs in terms of their predictive power has been done using two fashions: (1) single-step forecasting, (2) multi-step forecasting. Our extensive simulation experiments on these ten datasets report that the performance of these DNNs for single-step forecasting is pretty convincing as the predictions are found to follow the truely observed values closely. However, we also find that all these DNN models perform miserably in the case of multi-step time-series forecasting, based on the datasets used by us. Consequently, we observe that none of these DNN models are reliable for multi-step time-series forecasting.
Resource Allocation in Heterogeneously-Distributed Joint Radar-Communications under Asynchronous Bayesian Tracking Framework
Aug 23, 2021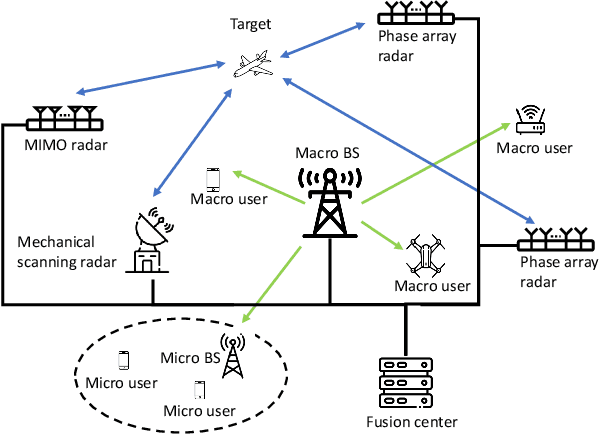
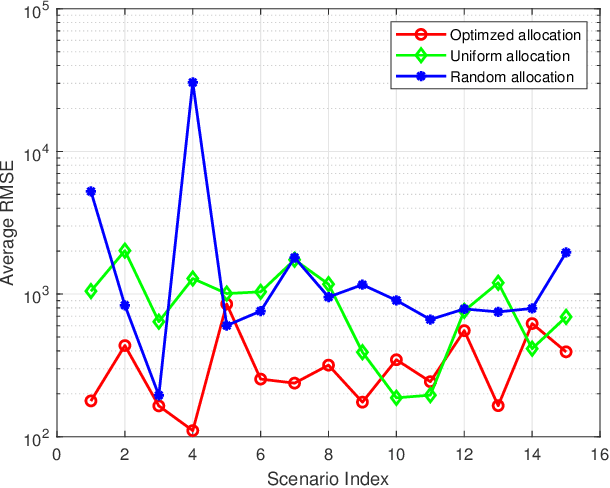
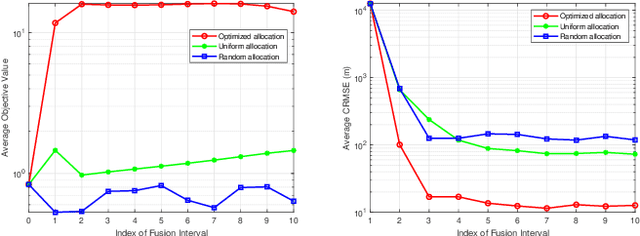
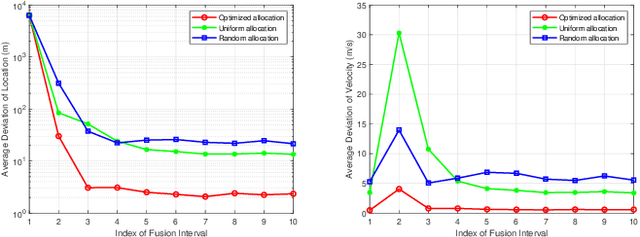
Optimal allocation of shared resources is key to deliver the promise of jointly operating radar and communications systems. In this paper, unlike prior works which examine synergistic access to resources in colocated joint radar-communications or among identical systems, we investigate this problem for a distributed system comprising heterogeneous radars and multi-tier communications. In particular, we focus on resource allocation in the context of multi-target tracking (MTT) while maintaining stable communication connections. By simultaneously allocating the available power, dwell time and shared bandwidth, we improve the MTT performance under a Bayesian tracking framework and guarantee the communications throughput. Our alternating allocation of heterogeneous resources (ANCHOR) approach solves the resulting nonconvex problem based on the alternating optimization method that monotonically improves the Bayesian Cram\'er-Rao bound. Numerical experiments demonstrate that ANCHOR significant improves the tracking error over two baseline allocations and stability under different target scenarios and radar-communications network distributions.
A Two-step-training Deep Learning Framework for Real-time Computational Imaging without Physics Priors
Jan 10, 2020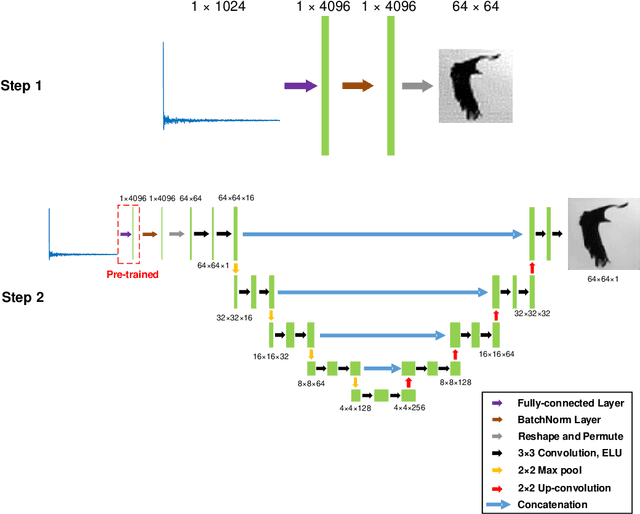
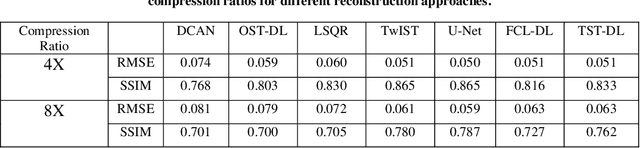

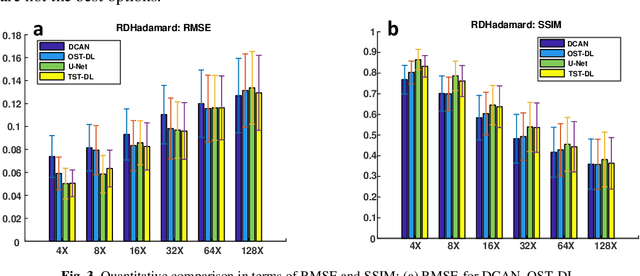
Deep learning (DL) is a powerful tool in computational imaging for many applications. A common strategy is to reconstruct a preliminary image as the input of a neural network to achieve an optimized image. Usually, the preliminary image is acquired with the prior knowledge of the model. One outstanding challenge, however, is that the model is sometimes difficult to acquire with high accuracy. In this work, a two-step-training DL (TST-DL) framework is proposed for real-time computational imaging without prior knowledge of the model. A single fully-connected layer (FCL) is trained to directly learn the model with the raw measurement data as input and the image as output. Then, this pre-trained FCL is fixed and connected with an un-trained deep convolutional network for a second-step training to improve the output image fidelity. This approach has three main advantages. First, no prior knowledge of the model is required since the first-step training is to directly learn the model. Second, real-time imaging can be achieved since the raw measurement data is directly used as the input to the model. Third, it can handle any dimension of the network input and solve the input-output dimension mismatch issues which arise in convolutional neural networks. We demonstrate this framework in the applications of single-pixel imaging and photoacoustic imaging for linear model cases. The results are quantitatively compared with those from other DL frameworks and model-based optimization approaches. Noise robustness and the required size of the training dataset are studied for this framework. We further extend this concept to nonlinear models in the application of image de-autocorrelation by using multiple FCLs in the first-step training. Overall, this TST-DL framework is widely applicable to many computational imaging techniques for real-time image reconstruction without the physics priors.
Cost-Effective Federated Learning in Mobile Edge Networks
Sep 12, 2021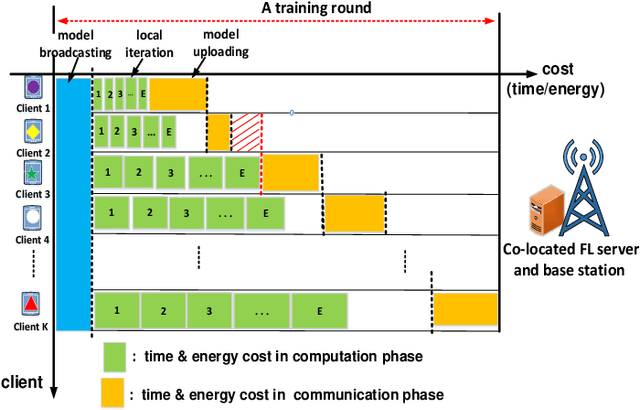
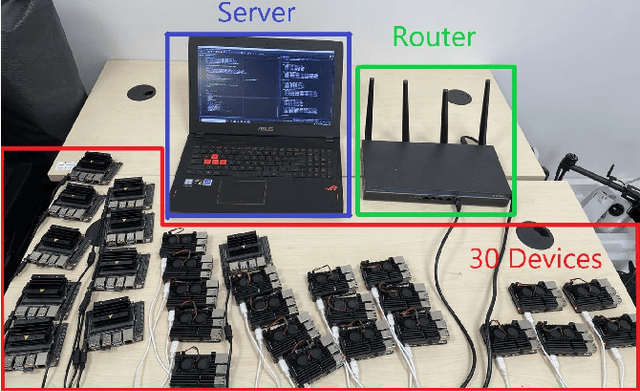
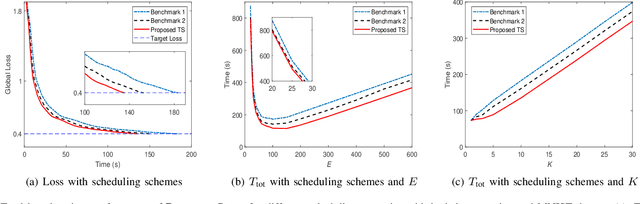
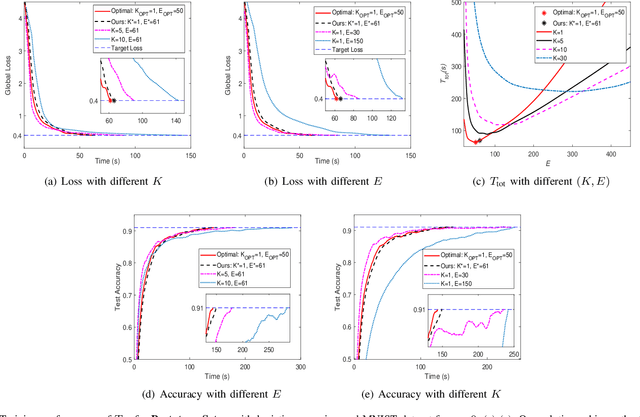
Federated learning (FL) is a distributed learning paradigm that enables a large number of mobile devices to collaboratively learn a model under the coordination of a central server without sharing their raw data. Despite its practical efficiency and effectiveness, the iterative on-device learning process (e.g., local computations and global communications with the server) incurs a considerable cost in terms of learning time and energy consumption, which depends crucially on the number of selected clients and the number of local iterations in each training round. In this paper, we analyze how to design adaptive FL in mobile edge networks that optimally chooses these essential control variables to minimize the total cost while ensuring convergence. We establish the analytical relationship between the total cost and the control variables with the convergence upper bound. To efficiently solve the cost minimization problem, we develop a low-cost sampling-based algorithm to learn the convergence related unknown parameters. We derive important solution properties that effectively identify the design principles for different optimization metrics. Practically, we evaluate our theoretical results both in a simulated environment and on a hardware prototype. Experimental evidence verifies our derived properties and demonstrates that our proposed solution achieves near-optimal performance for different optimization metrics for various datasets and heterogeneous system and statistical settings.
Sent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021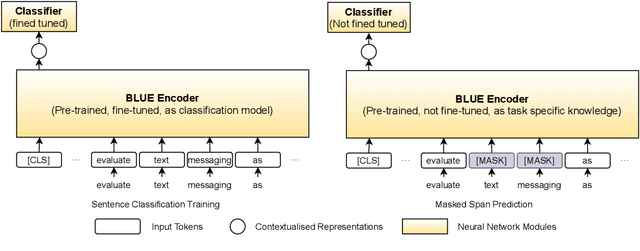
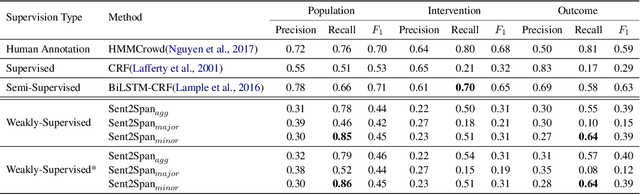
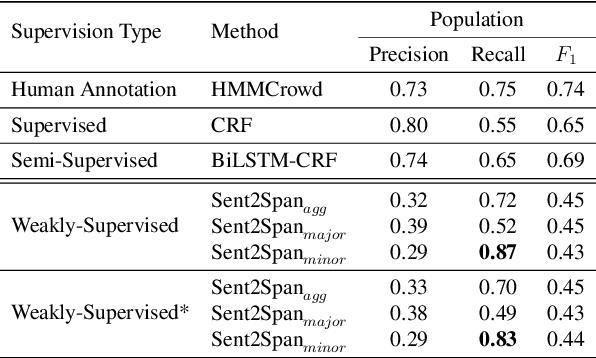
The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.
Explainable Machine Learning-driven Strategy for Automated Trading Pattern Extraction
Apr 13, 2021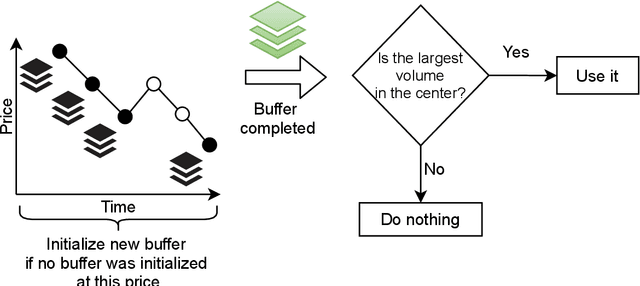

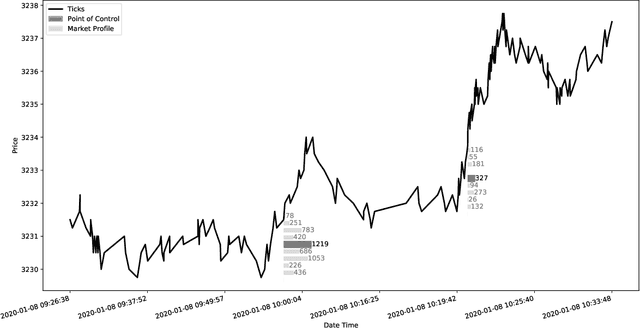
Financial markets are a source of non-stationary multidimensional time series which has been drawing attention for decades. Each financial instrument has its specific changing over time properties, making their analysis a complex task. Improvement of understanding and development of methods for financial time series analysis is essential for successful operation on financial markets. In this study we propose a volume-based data pre-processing method for making financial time series more suitable for machine learning pipelines. We use a statistical approach for assessing the performance of the method. Namely, we formally state the hypotheses, set up associated classification tasks, compute effect sizes with confidence intervals, and run statistical tests to validate the hypotheses. We additionally assess the trading performance of the proposed method on historical data and compare it to a previously published approach. Our analysis shows that the proposed volume-based method allows successful classification of the financial time series patterns, and also leads to better classification performance than a price action-based method, excelling specifically on more liquid financial instruments. Finally, we propose an approach for obtaining feature interactions directly from tree-based models on example of CatBoost estimator, as well as formally assess the relatedness of the proposed approach and SHAP feature interactions with a positive outcome.
Efficient Detection of Botnet Traffic by features selection and Decision Trees
Jun 30, 2021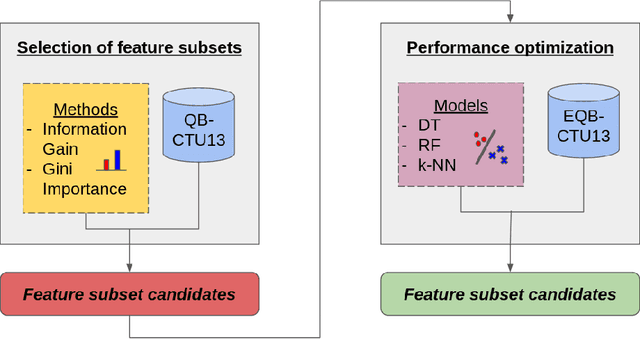
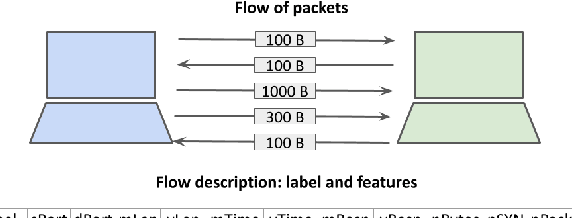
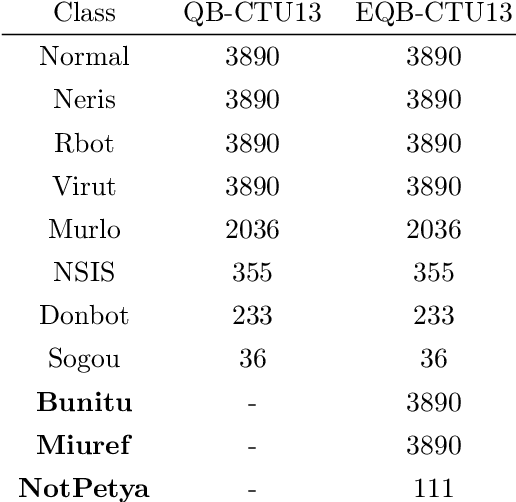
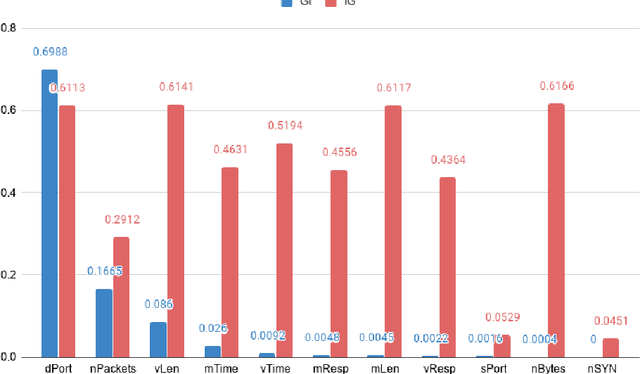
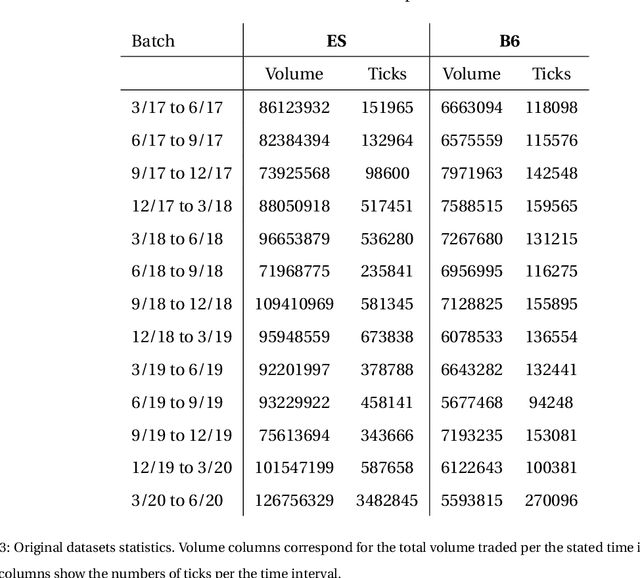
Botnets are one of the online threats with the biggest presence, causing billionaire losses to global economies. Nowadays, the increasing number of devices connected to the Internet makes it necessary to analyze large amounts of network traffic data. In this work, we focus on increasing the performance on botnet traffic classification by selecting those features that further increase the detection rate. For this purpose we use two feature selection techniques, Information Gain and Gini Importance, which led to three pre-selected subsets of five, six and seven features. Then, we evaluate the three feature subsets along with three models, Decision Tree, Random Forest and k-Nearest Neighbors. To test the performance of the three feature vectors and the three models we generate two datasets based on the CTU-13 dataset, namely QB-CTU13 and EQB-CTU13. We measure the performance as the macro averaged F1 score over the computational time required to classify a sample. The results show that the highest performance is achieved by Decision Trees using a five feature set which obtained a mean F1 score of 85% classifying each sample in an average time of 0.78 microseconds.
A Mixed-Integer Linear Programming Formulation for Human Multi-Robot Task Allocation
Jun 12, 2021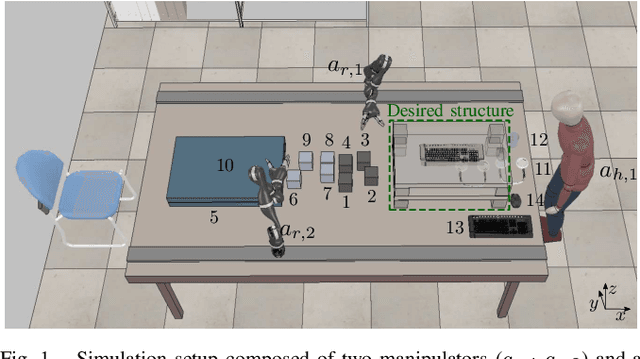
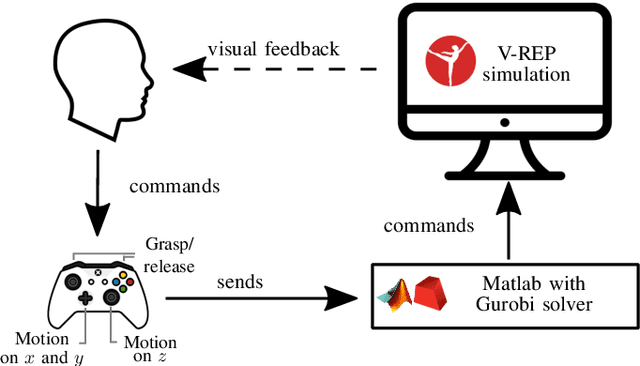
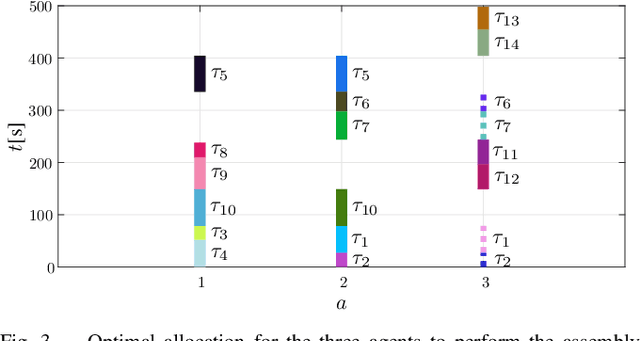
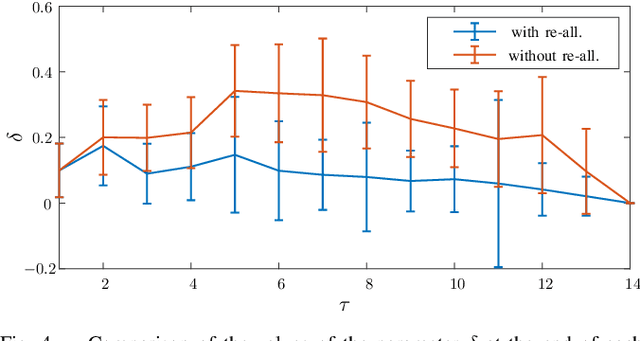
In this work, we address a task allocation problem for human multi-robot settings. Given a set of tasks to perform, we formulate a general Mixed-Integer Linear Programming (MILP) problem aiming at minimizing the overall execution time while optimizing the quality of the executed tasks as well as human and robotic workload. Different skills of the agents, both human and robotic, are taken into account and human operators are enabled to either directly execute tasks or play supervisory roles; moreover, multiple manipulators can tightly collaborate if required to carry out a task. Finally, as realistic in human contexts, human parameters are assumed to vary over time, e.g., due to increasing human level of fatigue. Therefore, online monitoring is required and re-allocation is performed if needed. Simulations in a realistic scenario with two manipulators and a human operator performing an assembly task validate the effectiveness of the approach.
On the Initial Behavior Monitoring Issues in Federated Learning
Sep 11, 2021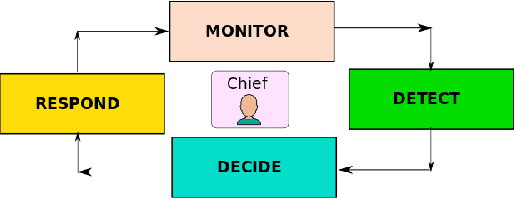
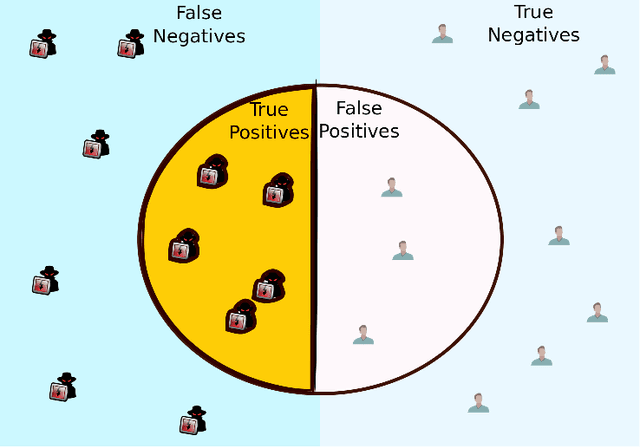
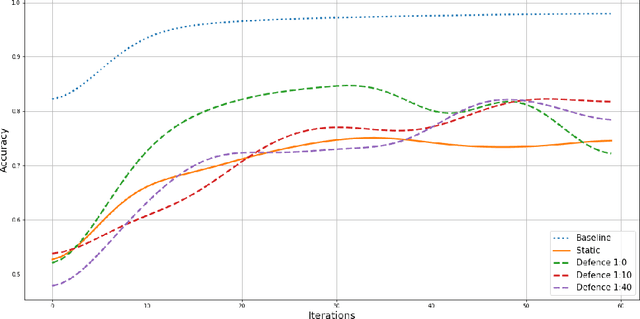
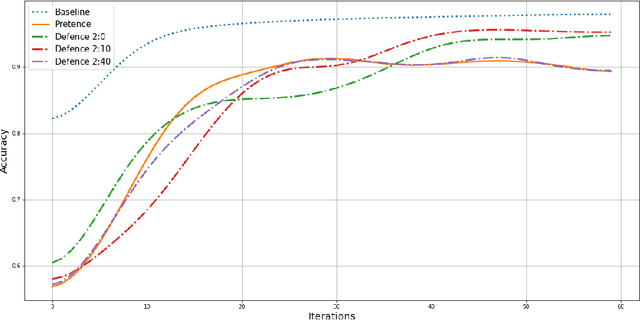
In Federated Learning (FL), a group of workers participate to build a global model under the coordination of one node, the chief. Regarding the cybersecurity of FL, some attacks aim at injecting the fabricated local model updates into the system. Some defenses are based on malicious worker detection and behavioral pattern analysis. In this context, without timely and dynamic monitoring methods, the chief cannot detect and remove the malicious or unreliable workers from the system. Our work emphasize the urgency to prepare the federated learning process for monitoring and eventually behavioral pattern analysis. We study the information inside the learning process in the early stages of training, propose a monitoring process and evaluate the monitoring period required. The aim is to analyse at what time is it appropriate to start the detection algorithm in order to remove the malicious or unreliable workers from the system and optimise the defense mechanism deployment. We tested our strategy on a behavioral pattern analysis defense applied to the FL process of different benchmark systems for text and image classification. Our results show that the monitoring process lowers false positives and false negatives and consequently increases system efficiency by enabling the distributed learning system to achieve better performance in the early stage of training.