 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021
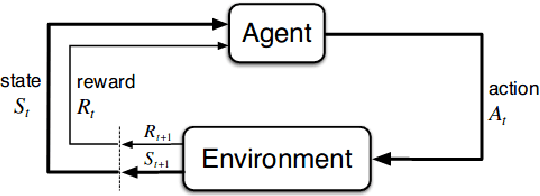
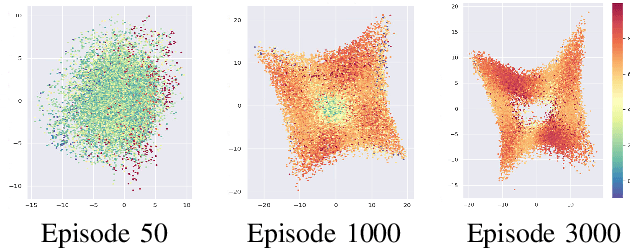
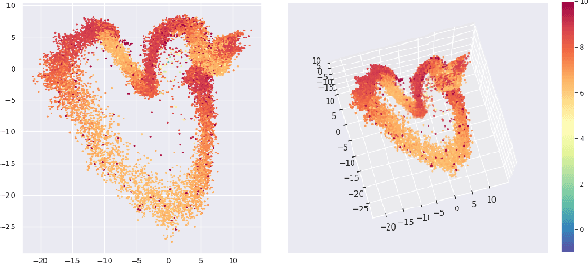
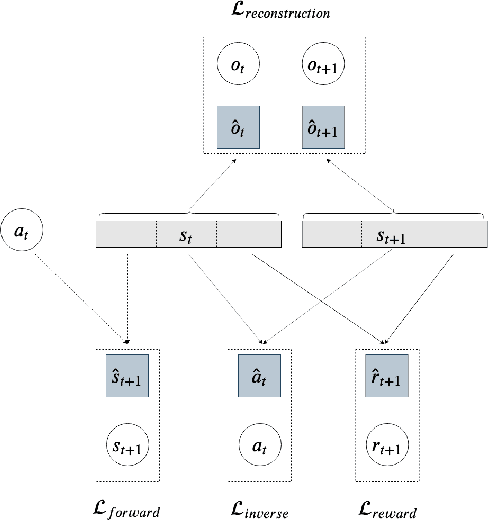
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
BotNet: A Simulator for Studying the Effects of Accurate Communication Models on Multi-agent and Swarm Control
Aug 31, 2021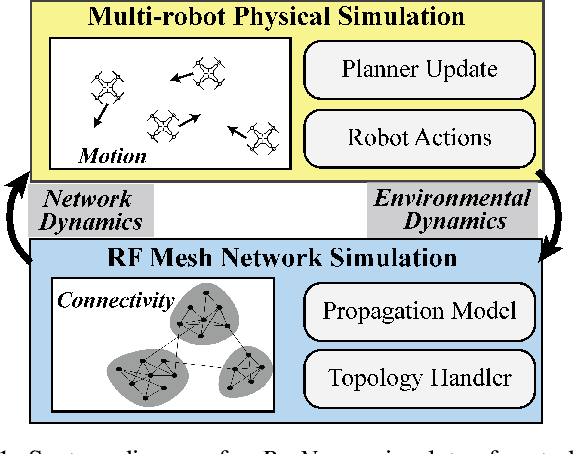
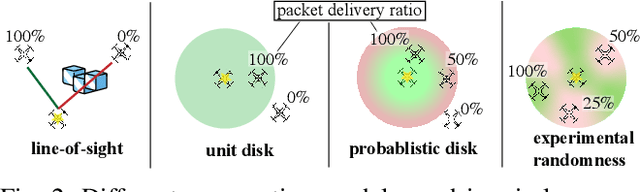
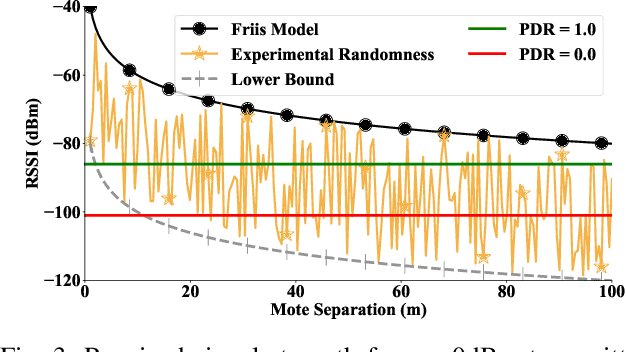
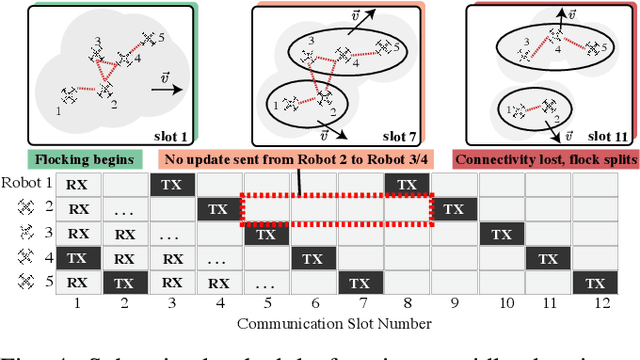
Decentralized control in multi-robot systems is dependent on accurate and reliable communication between agents. Important communication factors, such as latency and packet delivery ratio, are strong functions of the number of agents in the network. Findings from studies of mobile and high node-count radio-frequency (RF) mesh networks have only been transferred to the domain of multi-robot systems to a limited extent, and typical multi-agent robotic simulators often depend on simple propagation models that do not reflect the behavior of realistic RF networks. In this paper, we present a new open source swarm robotics simulator, BotNet, with an embedded standards-compliant time-synchronized channel hopping (6TiSCH) RF mesh network simulator. Using this simulator we show how more accurate communications models can limit even simple multi-robot control tasks such as flocking and formation control, with agent counts ranging from 10 up to 2500 agents. The experimental results are used to motivate changes to the inter-robot communication propagation models and other networking components currently used in practice in order to bridge the sim-to-real gap.
PEN4Rec: Preference Evolution Networks for Session-based Recommendation
Jun 17, 2021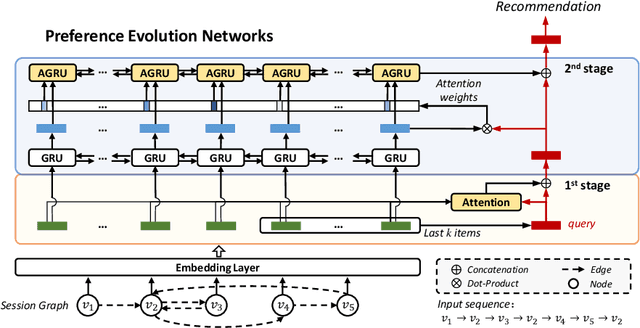

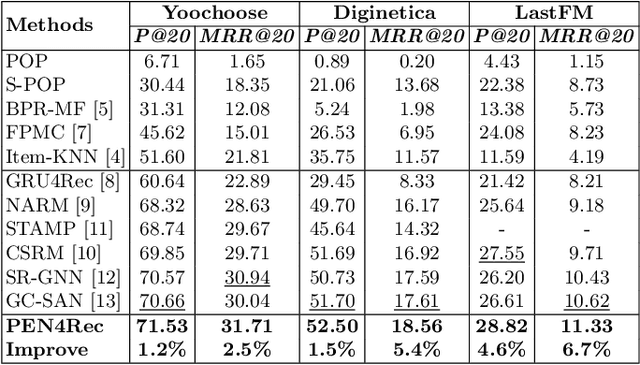
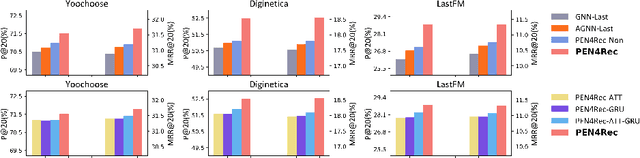
Session-based recommendation aims to predict user the next action based on historical behaviors in an anonymous session. For better recommendations, it is vital to capture user preferences as well as their dynamics. Besides, user preferences evolve over time dynamically and each preference has its own evolving track. However, most previous works neglect the evolving trend of preferences and can be easily disturbed by the effect of preference drifting. In this paper, we propose a novel Preference Evolution Networks for session-based Recommendation (PEN4Rec) to model preference evolving process by a two-stage retrieval from historical contexts. Specifically, the first-stage process integrates relevant behaviors according to recent items. Then, the second-stage process models the preference evolving trajectory over time dynamically and infer rich preferences. The process can strengthen the effect of relevant sequential behaviors during the preference evolution and weaken the disturbance from preference drifting. Extensive experiments on three public datasets demonstrate the effectiveness and superiority of the proposed model.
Energy Minimization for IRS-aided WPCNs with Non-linear Energy Harvesting Model
Aug 31, 2021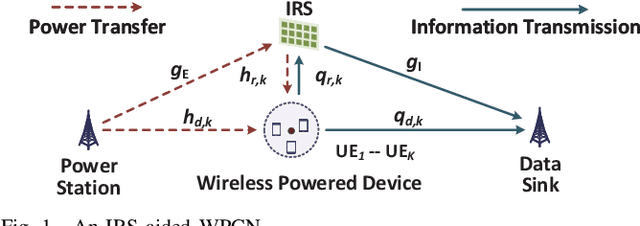
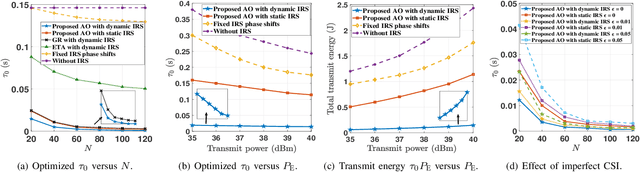
This paper considers an intelligent reflecting surface(IRS)-aided wireless powered communication network (WPCN), where devices first harvest energy from a power station (PS) in the downlink (DL) and then transmit information using non-orthogonal multiple access (NOMA) to a data sink in the uplink (UL). However, most existing works on WPCNs adopted the simplified linear energy-harvesting model and also cannot guarantee strict user quality-of-service requirements. To address these issues, we aim to minimize the total transmit energy consumption at the PS by jointly optimizing the resource allocation and IRS phase shifts over time, subject to the minimum throughput requirements of all devices. The formulated problem is decomposed into two subproblems, and solved iteratively in an alternative manner by employing difference of convex functions programming, successive convex approximation, and penalty-based algorithm. Numerical results demonstrate the significant performance gains achieved by the proposed algorithm over benchmark schemes and reveal the benefits of integrating IRS into WPCNs. In particular, employing different IRS phase shifts over UL and DL outperforms the case with static IRS beamforming.
E-DSSR: Efficient Dynamic Surgical Scene Reconstruction with Transformer-based Stereoscopic Depth Perception
Jul 01, 2021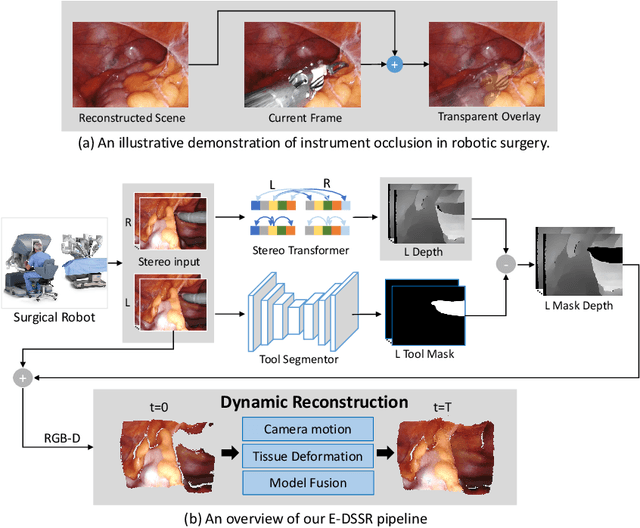
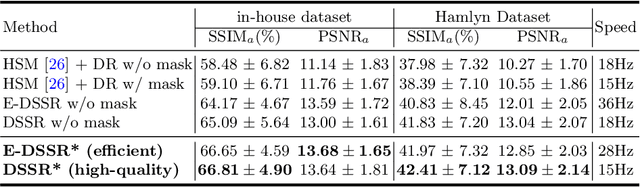
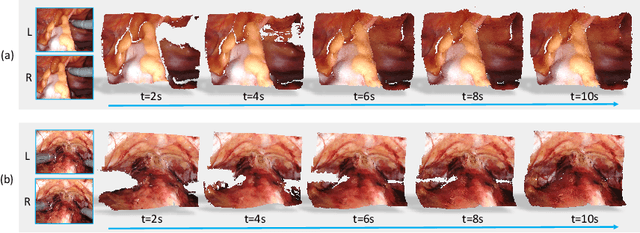
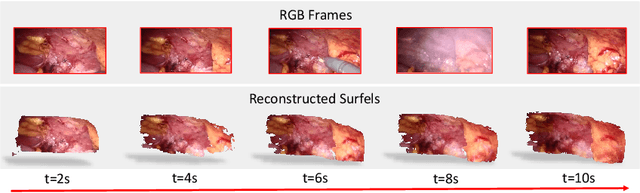
Reconstructing the scene of robotic surgery from the stereo endoscopic video is an important and promising topic in surgical data science, which potentially supports many applications such as surgical visual perception, robotic surgery education and intra-operative context awareness. However, current methods are mostly restricted to reconstructing static anatomy assuming no tissue deformation, tool occlusion and de-occlusion, and camera movement. However, these assumptions are not always satisfied in minimal invasive robotic surgeries. In this work, we present an efficient reconstruction pipeline for highly dynamic surgical scenes that runs at 28 fps. Specifically, we design a transformer-based stereoscopic depth perception for efficient depth estimation and a light-weight tool segmentor to handle tool occlusion. After that, a dynamic reconstruction algorithm which can estimate the tissue deformation and camera movement, and aggregate the information over time is proposed for surgical scene reconstruction. We evaluate the proposed pipeline on two datasets, the public Hamlyn Centre Endoscopic Video Dataset and our in-house DaVinci robotic surgery dataset. The results demonstrate that our method can recover the scene obstructed by the surgical tool and handle the movement of camera in realistic surgical scenarios effectively at real-time speed.
FireNet: Real-time Segmentation of Fire Perimeter from Aerial Video
Oct 14, 2019

In this paper, we share our approach to real-time segmentation of fire perimeter from aerial full-motion infrared video. We start by describing the problem from a humanitarian aid and disaster response perspective. Specifically, we explain the importance of the problem, how it is currently resolved, and how our machine learning approach improves it. To test our models we annotate a large-scale dataset of 400,000 frames with guidance from domain experts. Finally, we share our approach currently deployed in production with inference speed of 20 frames per second and an accuracy of 92 (F1 Score).
Finite-Time Performance of Distributed Temporal Difference Learning with Linear Function Approximation
Jul 25, 2019We study the policy evaluation problem in multi-agent reinforcement learning, where a group of agents operates in a common environment. In this problem, the goal of the agents is to cooperatively evaluate the global discounted accumulative reward, which is composed of local rewards observed by the agents. Over a series of time steps, the agents act, get rewarded, update their local estimate of the value function, then communicate with their neighbors. The local update at each agent can be interpreted as a distributed variant of the popular temporal difference learning methods TD$(\lambda)$. Our main contribution is to provide a finite-analysis on the performance of this distributed TD$(\lambda)$ for both constant and time-varying step sizes. The key idea in our analysis is to utilize the geometric mixing time $\tau$ of the underlying Markov chain, that is, although the "noise" in our algorithm is Markovian, their dependence is almost weakened out every $\tau$ step. In particular, we provide an explicit formula for the upper bound on the rates of the proposed method as a function of the network topology, the discount factor, the constant $\lambda$, and the mixing time $\tau$. Our results theoretically address some numerical observations of TD$(\lambda)$, that is, $\lambda=1$ gives the best approximation of the function values while $\lambda = 0$ leads to better performance when there is a large variance in the algorithm. Our results complement the existing literature, where such an explicit formula for the rates of distributed TD$(\lambda)$ is not available.
Real-Time MDNet
Aug 27, 2018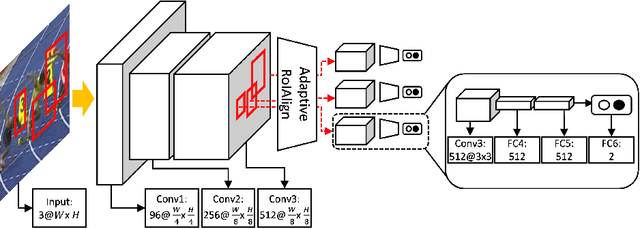

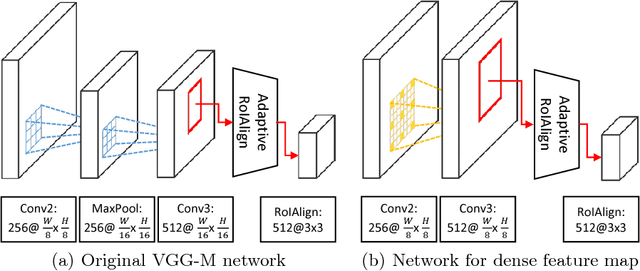
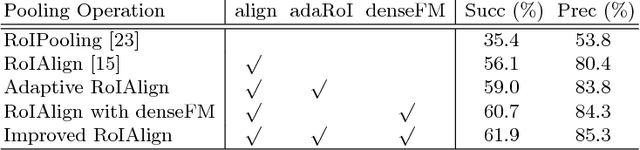
We present a fast and accurate visual tracking algorithm based on the multi-domain convolutional neural network (MDNet). The proposed approach accelerates feature extraction procedure and learns more discriminative models for instance classification; it enhances representation quality of target and background by maintaining a high resolution feature map with a large receptive field per activation. We also introduce a novel loss term to differentiate foreground instances across multiple domains and learn a more discriminative embedding of target objects with similar semantics. The proposed techniques are integrated into the pipeline of a well known CNN-based visual tracking algorithm, MDNet. We accomplish approximately 25 times speed-up with almost identical accuracy compared to MDNet. Our algorithm is evaluated in multiple popular tracking benchmark datasets including OTB2015, UAV123, and TempleColor, and outperforms the state-of-the-art real-time tracking methods consistently even without dataset-specific parameter tuning.
Cost-Effective Federated Learning in Mobile Edge Networks
Sep 12, 2021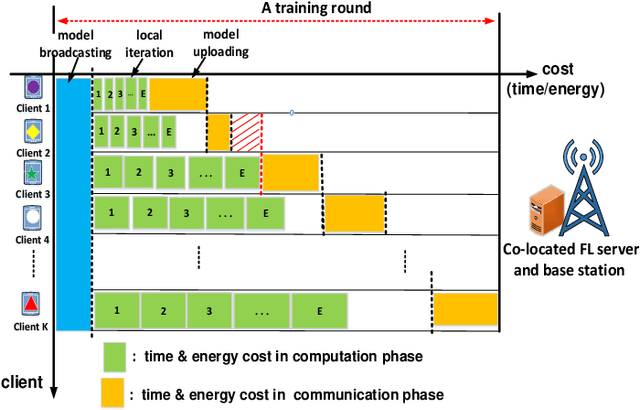
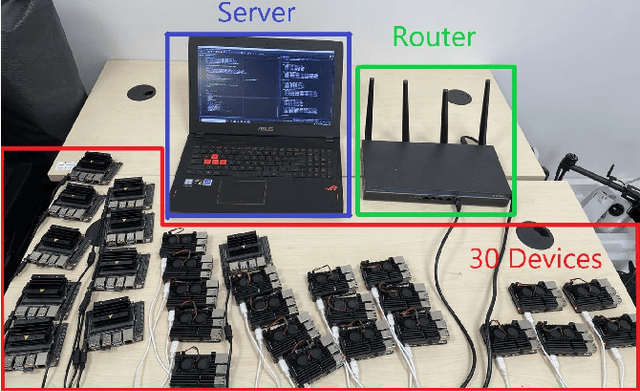
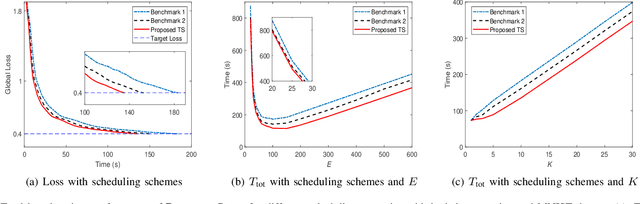
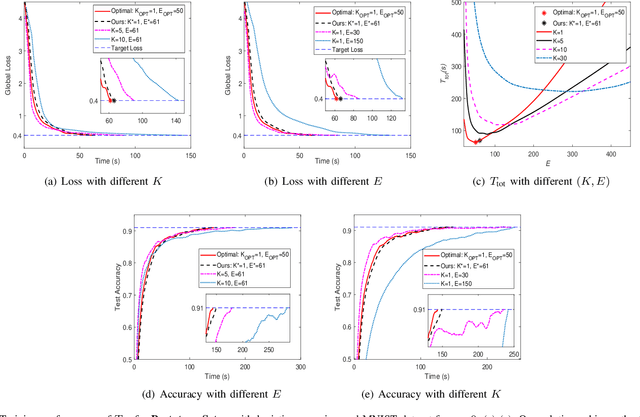
Federated learning (FL) is a distributed learning paradigm that enables a large number of mobile devices to collaboratively learn a model under the coordination of a central server without sharing their raw data. Despite its practical efficiency and effectiveness, the iterative on-device learning process (e.g., local computations and global communications with the server) incurs a considerable cost in terms of learning time and energy consumption, which depends crucially on the number of selected clients and the number of local iterations in each training round. In this paper, we analyze how to design adaptive FL in mobile edge networks that optimally chooses these essential control variables to minimize the total cost while ensuring convergence. We establish the analytical relationship between the total cost and the control variables with the convergence upper bound. To efficiently solve the cost minimization problem, we develop a low-cost sampling-based algorithm to learn the convergence related unknown parameters. We derive important solution properties that effectively identify the design principles for different optimization metrics. Practically, we evaluate our theoretical results both in a simulated environment and on a hardware prototype. Experimental evidence verifies our derived properties and demonstrates that our proposed solution achieves near-optimal performance for different optimization metrics for various datasets and heterogeneous system and statistical settings.
Layer Pruning on Demand with Intermediate CTC
Jun 17, 2021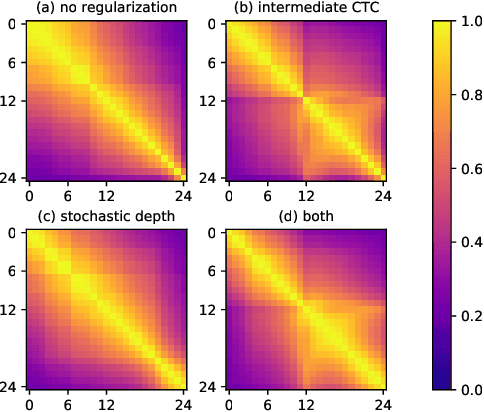
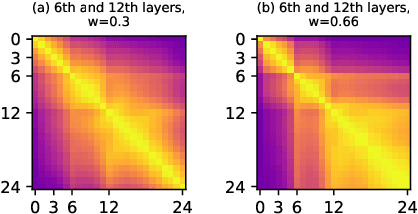
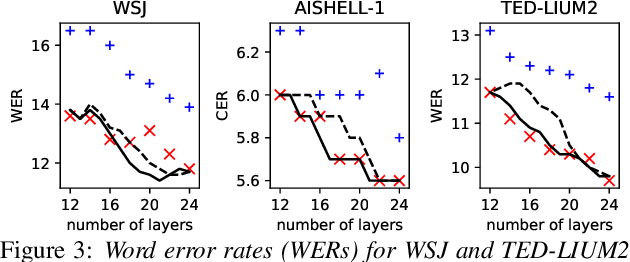
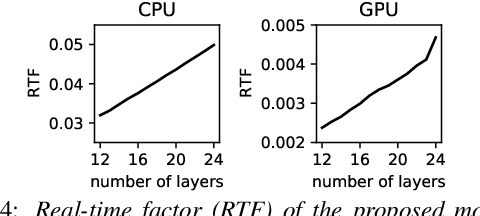
Deploying an end-to-end automatic speech recognition (ASR) model on mobile/embedded devices is a challenging task, since the device computational power and energy consumption requirements are dynamically changed in practice. To overcome the issue, we present a training and pruning method for ASR based on the connectionist temporal classification (CTC) which allows reduction of model depth at run-time without any extra fine-tuning. To achieve the goal, we adopt two regularization methods, intermediate CTC and stochastic depth, to train a model whose performance does not degrade much after pruning. We present an in-depth analysis of layer behaviors using singular vector canonical correlation analysis (SVCCA), and efficient strategies for finding layers which are safe to prune. Using the proposed method, we show that a Transformer-CTC model can be pruned in various depth on demand, improving real-time factor from 0.005 to 0.002 on GPU, while each pruned sub-model maintains the accuracy of individually trained model of the same depth.