 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DEMix Layers: Disentangling Domains for Modular Language Modeling
Aug 20, 2021
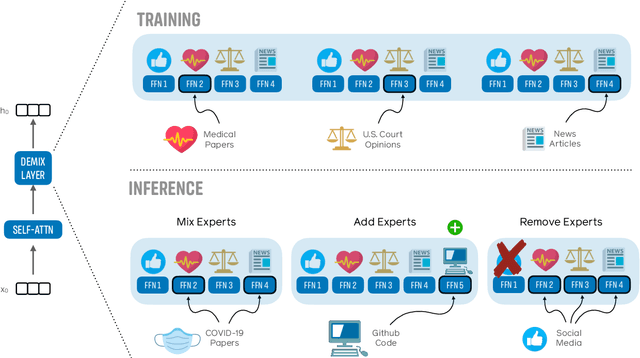
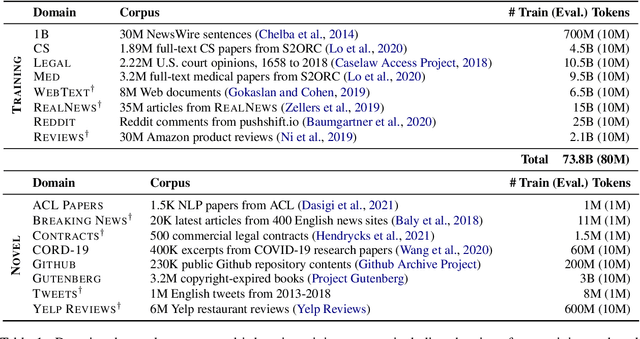
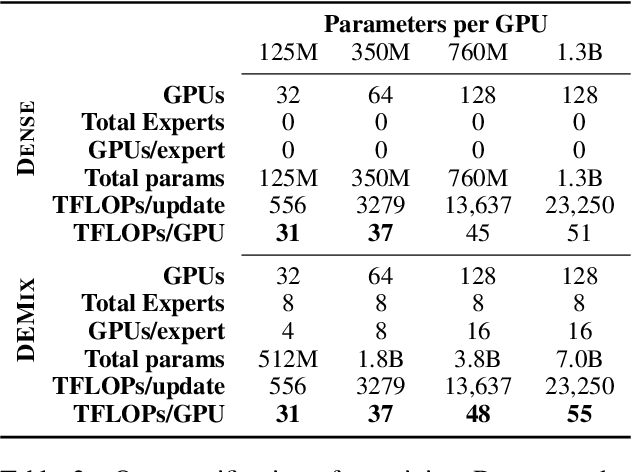
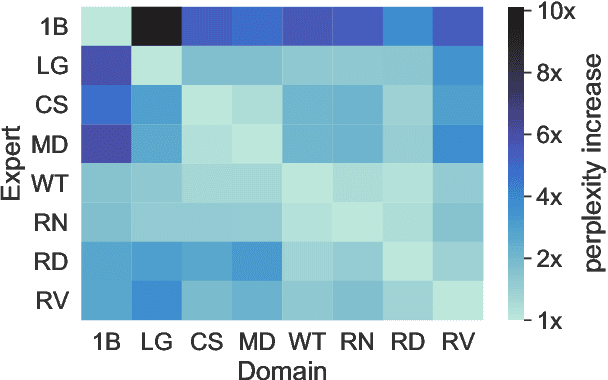
We introduce a new domain expert mixture (DEMix) layer that enables conditioning a language model (LM) on the domain of the input text. A DEMix layer is a collection of expert feedforward networks, each specialized to a domain, that makes the LM modular: experts can be mixed, added or removed after initial training. Extensive experiments with autoregressive transformer LMs (up to 1.3B parameters) show that DEMix layers reduce test-time perplexity, increase training efficiency, and enable rapid adaptation with little overhead. We show that mixing experts during inference, using a parameter-free weighted ensemble, allows the model to better generalize to heterogeneous or unseen domains. We also show that experts can be added to iteratively incorporate new domains without forgetting older ones, and that experts can be removed to restrict access to unwanted domains, without additional training. Overall, these results demonstrate benefits of explicitly conditioning on textual domains during language modeling.
FireNet: Real-time Segmentation of Fire Perimeter from Aerial Video
Oct 14, 2019

In this paper, we share our approach to real-time segmentation of fire perimeter from aerial full-motion infrared video. We start by describing the problem from a humanitarian aid and disaster response perspective. Specifically, we explain the importance of the problem, how it is currently resolved, and how our machine learning approach improves it. To test our models we annotate a large-scale dataset of 400,000 frames with guidance from domain experts. Finally, we share our approach currently deployed in production with inference speed of 20 frames per second and an accuracy of 92 (F1 Score).
Finite-Time Performance of Distributed Temporal Difference Learning with Linear Function Approximation
Jul 25, 2019We study the policy evaluation problem in multi-agent reinforcement learning, where a group of agents operates in a common environment. In this problem, the goal of the agents is to cooperatively evaluate the global discounted accumulative reward, which is composed of local rewards observed by the agents. Over a series of time steps, the agents act, get rewarded, update their local estimate of the value function, then communicate with their neighbors. The local update at each agent can be interpreted as a distributed variant of the popular temporal difference learning methods TD$(\lambda)$. Our main contribution is to provide a finite-analysis on the performance of this distributed TD$(\lambda)$ for both constant and time-varying step sizes. The key idea in our analysis is to utilize the geometric mixing time $\tau$ of the underlying Markov chain, that is, although the "noise" in our algorithm is Markovian, their dependence is almost weakened out every $\tau$ step. In particular, we provide an explicit formula for the upper bound on the rates of the proposed method as a function of the network topology, the discount factor, the constant $\lambda$, and the mixing time $\tau$. Our results theoretically address some numerical observations of TD$(\lambda)$, that is, $\lambda=1$ gives the best approximation of the function values while $\lambda = 0$ leads to better performance when there is a large variance in the algorithm. Our results complement the existing literature, where such an explicit formula for the rates of distributed TD$(\lambda)$ is not available.
You should evaluate your language model on marginal likelihood overtokenisations
Sep 06, 2021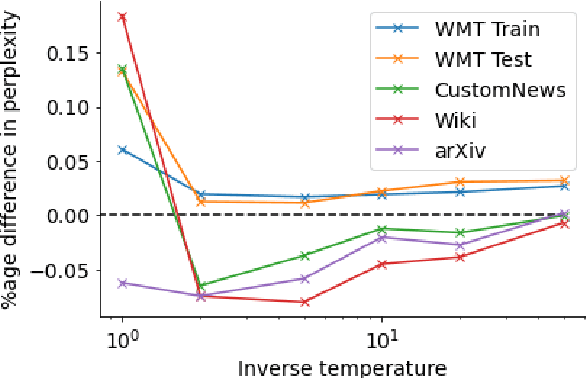
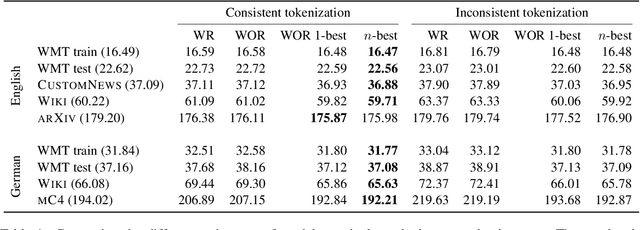
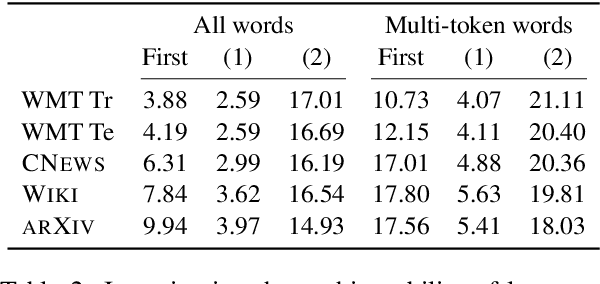
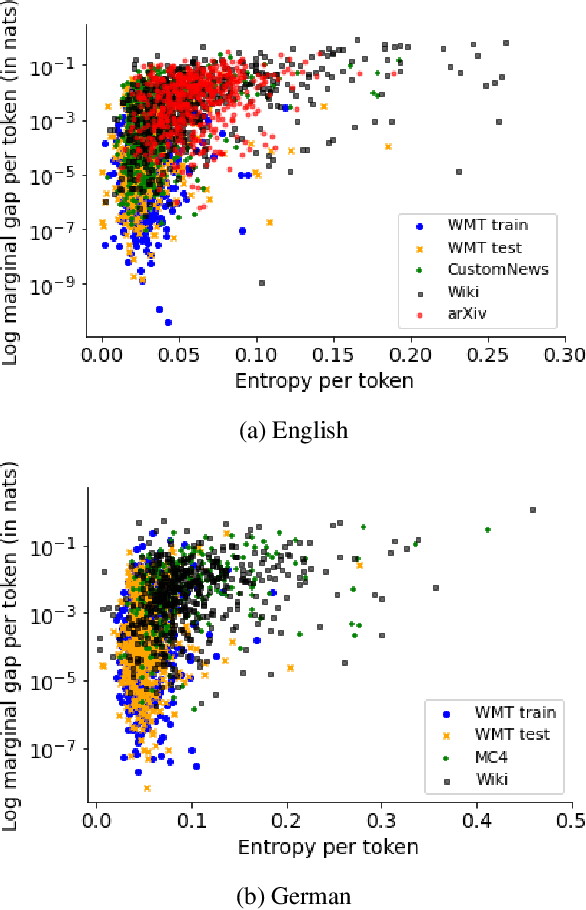
Neural language models typically tokenise input text into sub-word units to achieve an open vocabulary. The standard approach is to use a single canonical tokenisation at both train and test time. We suggest that this approach is unsatisfactory and may bottleneck our evaluation of language model performance. Using only the one-best tokenisation ignores tokeniser uncertainty over alternative tokenisations, which may hurt model out-of-domain performance. In this paper, we argue that instead, language models should be evaluated on their marginal likelihood over tokenisations. We compare different estimators for the marginal likelihood based on sampling, and show that it is feasible to estimate the marginal likelihood with a manageable number of samples. We then evaluate pretrained English and German language models on both the one-best-tokenisation and marginal perplexities, and show that the marginal perplexity can be significantly better than the one best, especially on out-of-domain data. We link this difference in perplexity to the tokeniser uncertainty as measured by tokeniser entropy. We discuss some implications of our results for language model training and evaluation, particularly with regard to tokenisation robustness.
Updating Embeddings for Dynamic Knowledge Graphs
Sep 22, 2021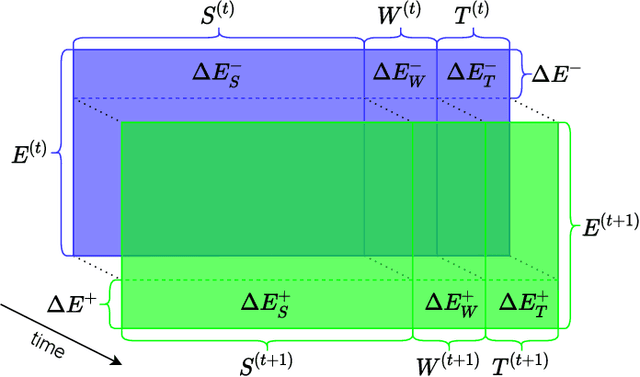
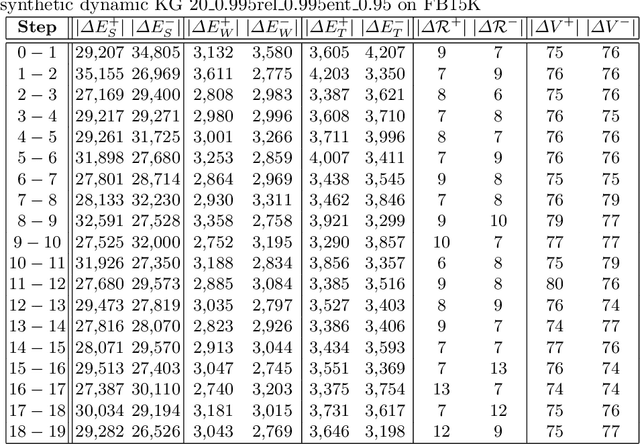
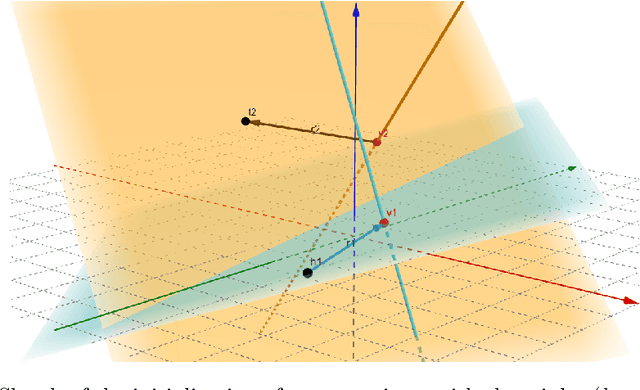
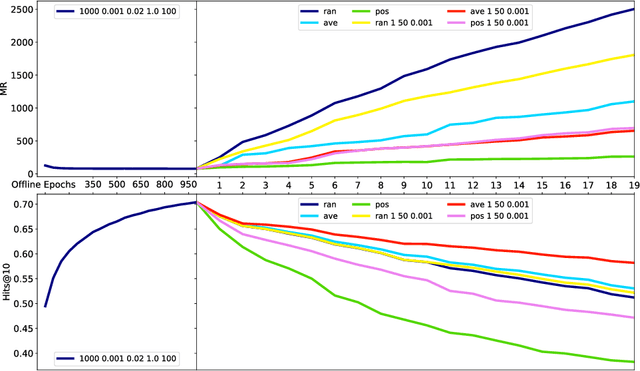
Data in Knowledge Graphs often represents part of the current state of the real world. Thus, to stay up-to-date the graph data needs to be updated frequently. To utilize information from Knowledge Graphs, many state-of-the-art machine learning approaches use embedding techniques. These techniques typically compute an embedding, i.e., vector representations of the nodes as input for the main machine learning algorithm. If a graph update occurs later on -- specifically when nodes are added or removed -- the training has to be done all over again. This is undesirable, because of the time it takes and also because downstream models which were trained with these embeddings have to be retrained if they change significantly. In this paper, we investigate embedding updates that do not require full retraining and evaluate them in combination with various embedding models on real dynamic Knowledge Graphs covering multiple use cases. We study approaches that place newly appearing nodes optimally according to local information, but notice that this does not work well. However, we find that if we continue the training of the old embedding, interleaved with epochs during which we only optimize for the added and removed parts, we obtain good results in terms of typical metrics used in link prediction. This performance is obtained much faster than with a complete retraining and hence makes it possible to maintain embeddings for dynamic Knowledge Graphs.
A Comparative Study of Nonlinear MPC and Differential-Flatness-Based Control for Quadrotor Agile Flight
Sep 06, 2021
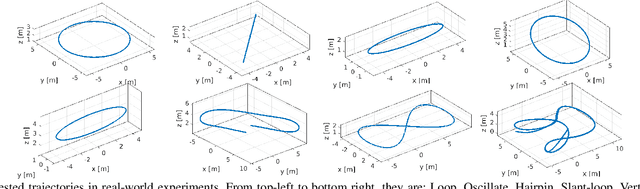
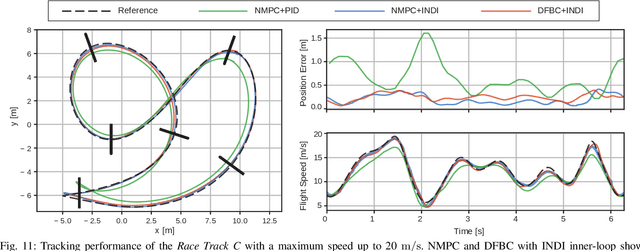
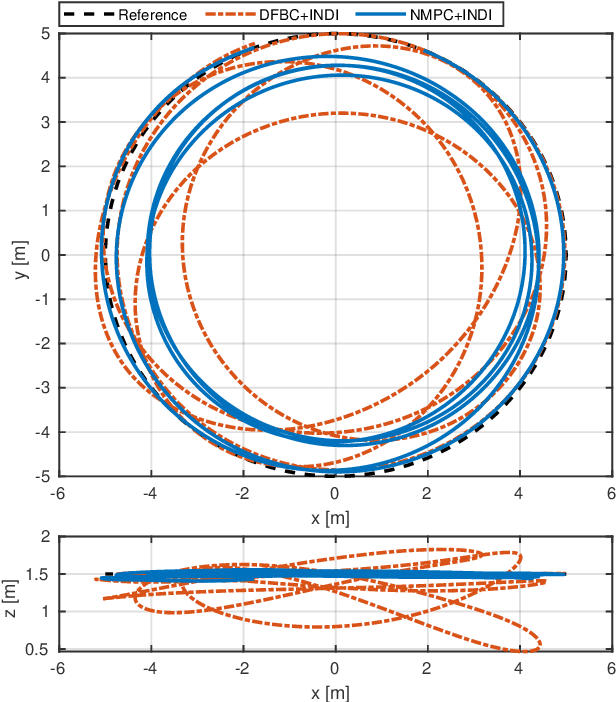
Accurate trajectory tracking control for quadrotors is essential for safe navigation in cluttered environments. However, this is challenging in agile flights due to nonlinear dynamics, complex aerodynamic effects, and actuation constraints. In this article, we empirically compare two state-of-the-art control frameworks: the nonlinear-model-predictive controller (NMPC) and the differential-flatness-based controller (DFBC), by tracking a wide variety of agile trajectories at speeds up to 72 km/h. The comparisons are performed in both simulation and real-world environments to systematically evaluate both methods from the aspect of tracking accuracy, robustness, and computational efficiency. We show the superiority of NMPC in tracking dynamically infeasible trajectories, at the cost of higher computation time and risk of numerical convergence issues. For both methods, we also quantitatively study the effect of adding an inner-loop controller using the incremental nonlinear dynamic inversion (INDI) method, and the effect of adding an aerodynamic drag model. Our real-world experiments, performed in one of the world's largest motion capture systems, demonstrate more than 78% tracking error reduction of both NMPC and DFBC, indicating the necessity of using an inner-loop controller and aerodynamic drag model for agile trajectory tracking.
Contextualized Embeddings based Convolutional Neural Networks for Duplicate Question Identification
Sep 06, 2021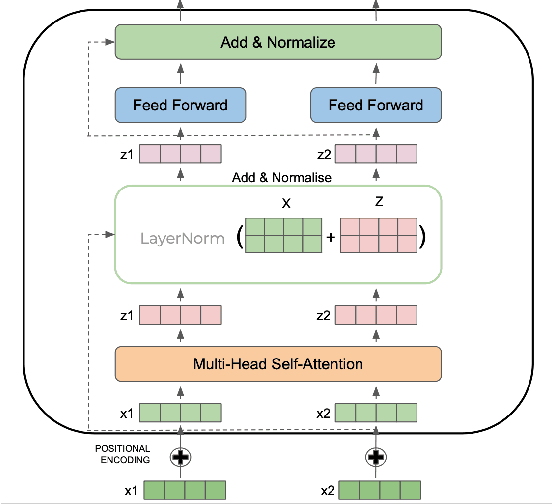

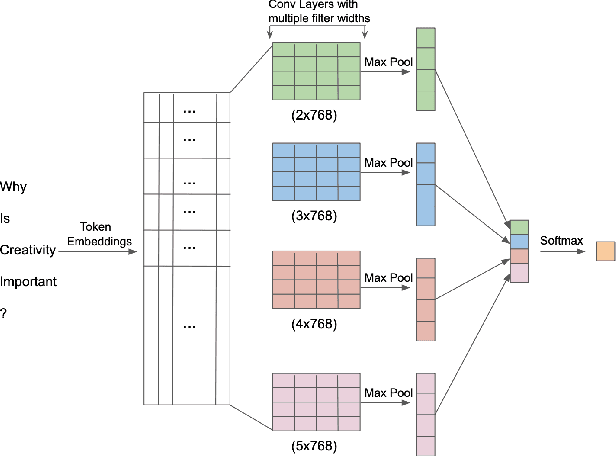
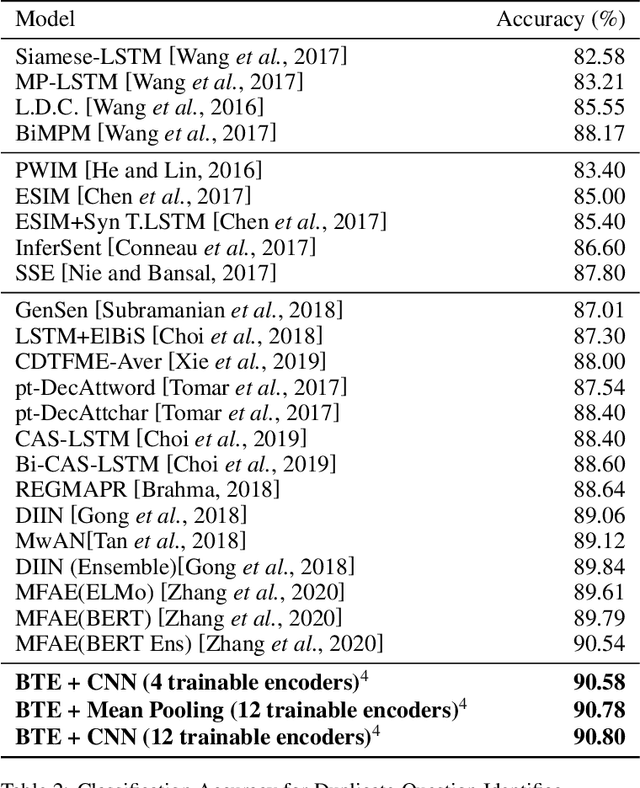
Question Paraphrase Identification (QPI) is a critical task for large-scale Question-Answering forums. The purpose of QPI is to determine whether a given pair of questions are semantically identical or not. Previous approaches for this task have yielded promising results, but have often relied on complex recurrence mechanisms that are expensive and time-consuming in nature. In this paper, we propose a novel architecture combining a Bidirectional Transformer Encoder with Convolutional Neural Networks for the QPI task. We produce the predictions from the proposed architecture using two different inference setups: Siamese and Matched Aggregation. Experimental results demonstrate that our model achieves state-of-the-art performance on the Quora Question Pairs dataset. We empirically prove that the addition of convolution layers to the model architecture improves the results in both inference setups. We also investigate the impact of partial and complete fine-tuning and analyze the trade-off between computational power and accuracy in the process. Based on the obtained results, we conclude that the Matched-Aggregation setup consistently outperforms the Siamese setup. Our work provides insights into what architecture combinations and setups are likely to produce better results for the QPI task.
A Proposed Artificial intelligence Model for Real-Time Human Action Localization and Tracking
Nov 09, 2019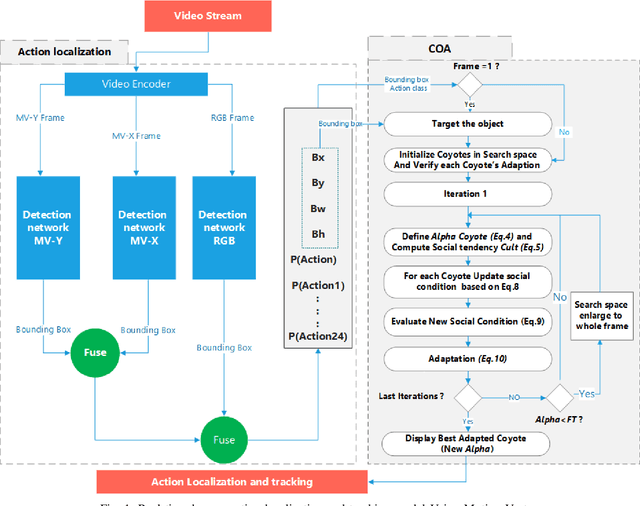



In recent years, artificial intelligence (AI) based on deep learning (DL) has sparked tremendous global interest. DL is widely used today and has expanded into various interesting areas. It is becoming more popular in cross-subject research, such as studies of smart city systems, which combine computer science with engineering applications. Human action detection is one of these areas. Human action detection is an interesting challenge due to its stringent requirements in terms of computing speed and accuracy. High-accuracy real-time object tracking is also considered a significant challenge. This paper integrates the YOLO detection network, which is considered a state-of-the-art tool for real-time object detection, with motion vectors and the Coyote Optimization Algorithm (COA) to construct a real-time human action localization and tracking system. The proposed system starts with the extraction of motion information from a compressed video stream and the extraction of appearance information from RGB frames using an object detector. Then, a fusion step between the two streams is performed, and the results are fed into the proposed action tracking model. The COA is used in object tracking due to its accuracy and fast convergence. The basic foundation of the proposed model is the utilization of motion vectors, which already exist in a compressed video bit stream and provide sufficient information to improve the localization of the target action without requiring high consumption of computational resources compared with other popular methods of extracting motion information, such as optical flows. This advantage allows the proposed approach to be implemented in challenging environments where the computational resources are limited, such as Internet of Things (IoT) systems.
Time Distance: A Novel Collision Prediction and Path Planning Method
Jul 07, 2019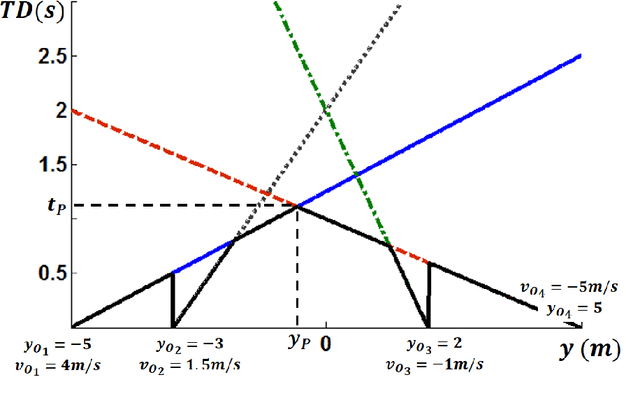
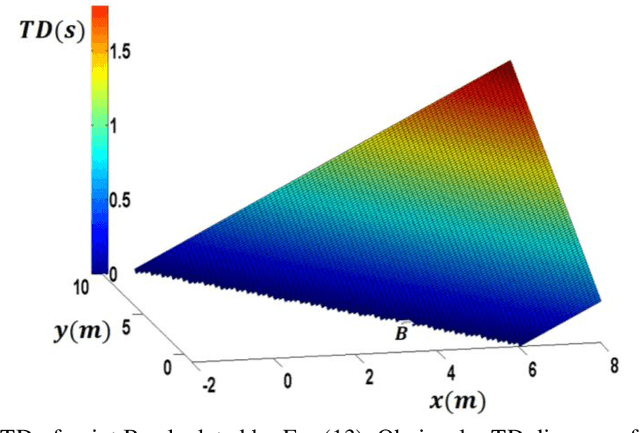
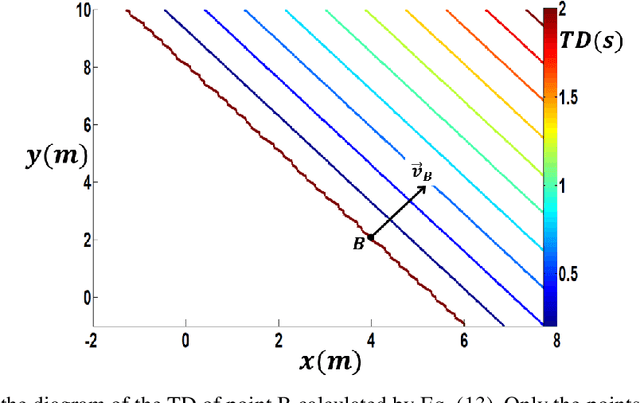
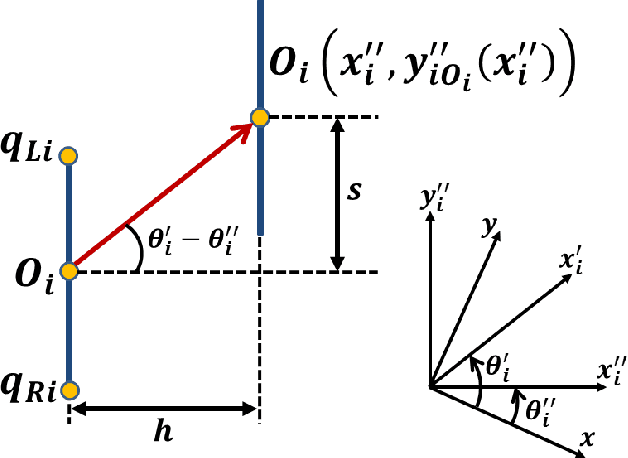
Motion planning is an active field of research in robot navigation and autonomous driving. There are plenty of classical and heuristic motion planning methods applicable to mobile robots and ground vehicles. This paper is dedicated to introducing a novel method for collision prediction and path planning. The method is called Time Distance (TD), and its basis returns to the swept volume idea. However, there are considerable differences between the TD method and existing methods associated with the swept volume concept. In this method, time is obtained as a dependent variable in TD functions. TD functions are functions of location, velocity, and geometry of objects, determining the TD of objects with respect to any location. Known as a relative concept, TD is defined as the time interval that must be spent in order for an object to reach a certain location. It is firstly defined for the one-dimensional case and then generalized to 2D space. The collision prediction algorithm consists of obtaining the TD of different points of an object (the vehicle) with respect to all objects of the environment using an explicit function which is a function of TD functions. The path planning algorithm uses TD functions and two other functions called Z-Infinity and Route Function to create the collision-free path in a dynamic environment. Both the collision prediction and the path planning algorithms are evaluated in simulations. Comparisons indicate the capability of the method to generate length optimal paths as the most effective methods do.
Exposing Length Divergence Bias of Textual Matching Models
Sep 06, 2021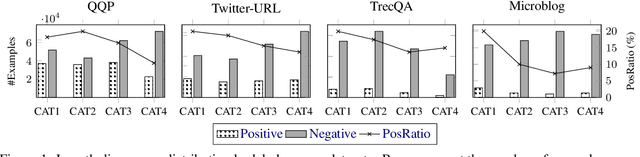

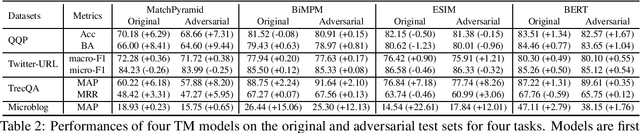
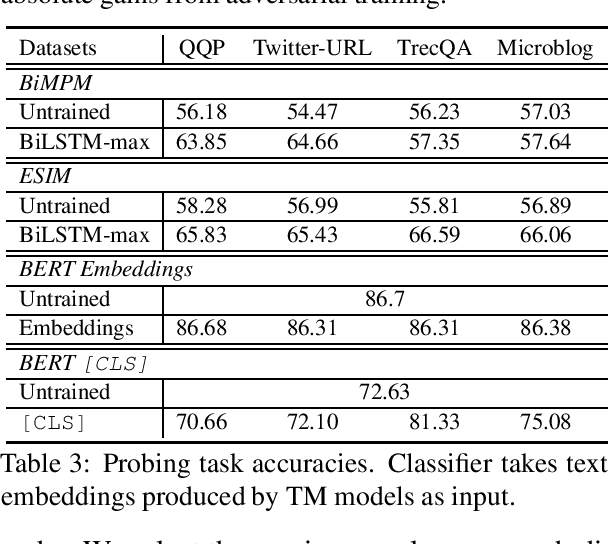
Despite the remarkable success deep models have achieved in Textual Matching (TM), their robustness issue is still a topic of concern. In this work, we propose a new perspective to study this issue -- via the length divergence bias of TM models. We conclude that this bias stems from two parts: the label bias of existing TM datasets and the sensitivity of TM models to superficial information. We critically examine widely used TM datasets, and find that all of them follow specific length divergence distributions by labels, providing direct cues for predictions. As for the TM models, we conduct adversarial evaluation and show that all models' performances drop on the out-of-distribution adversarial test sets we construct, which demonstrates that they are all misled by biased training sets. This is also confirmed by the \textit{SentLen} probing task that all models capture rich length information during training to facilitate their performances. Finally, to alleviate the length divergence bias in TM models, we propose a practical adversarial training method using bias-free training data. Our experiments indicate that we successfully improve the robustness and generalization ability of models at the same time.