 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepScale: An Online Frame Size Adaptation Approach to Accelerate Visual Multi-object Tracking
Aug 18, 2021
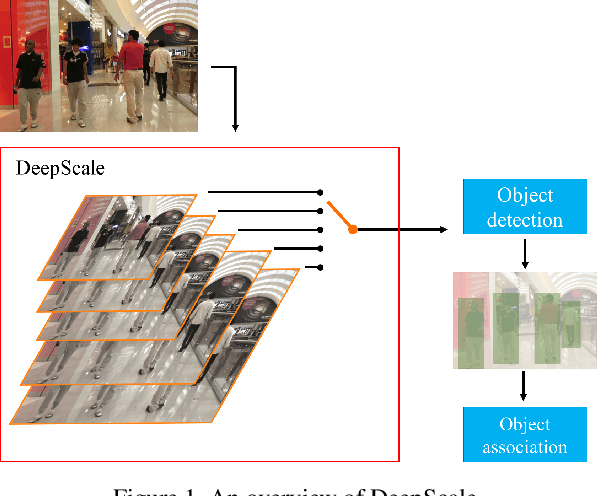

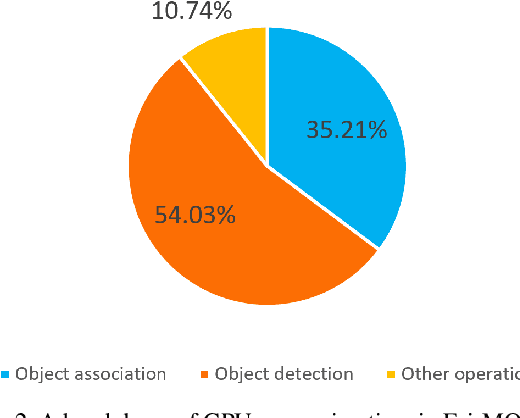
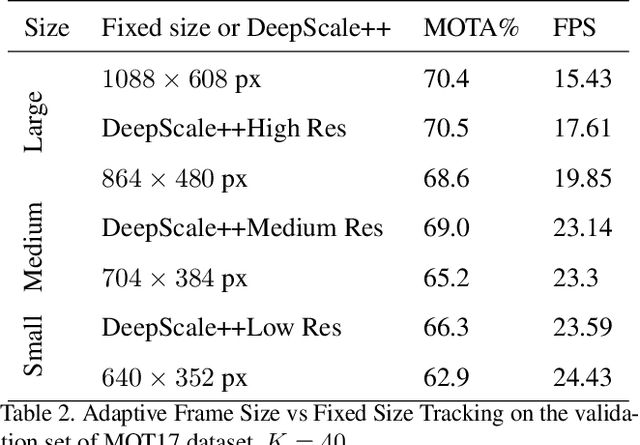
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today's MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. {During inference, it can adapt frame sizes according to the complexity of visual contents based on user-controlled parameters.} Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.3%) in tracking accuracy on the MOT15 dataset in one configuration.
End-to-end Neural Information Status Classification
Sep 06, 2021
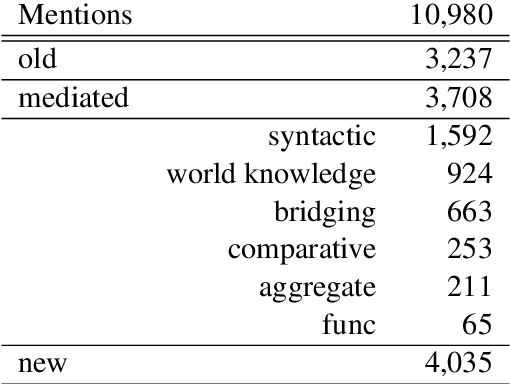
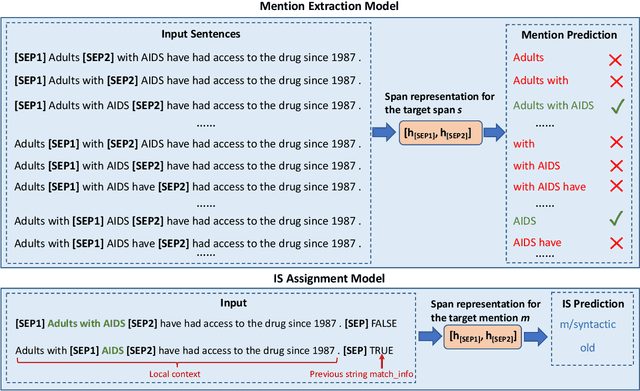
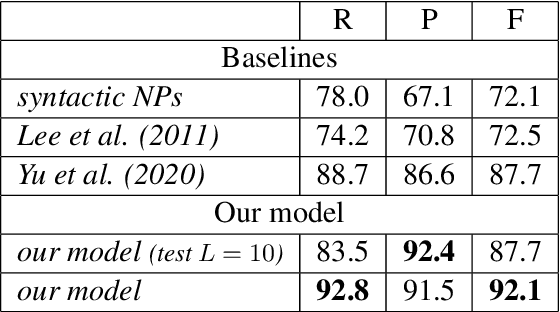
Most previous studies on information status (IS) classification and bridging anaphora recognition assume that the gold mention or syntactic tree information is given (Hou et al., 2013; Roesiger et al., 2018; Hou, 2020; Yu and Poesio, 2020). In this paper, we propose an end-to-end neural approach for information status classification. Our approach consists of a mention extraction component and an information status assignment component. During the inference time, our system takes a raw text as the input and generates mentions together with their information status. On the ISNotes corpus (Markert et al., 2012), we show that our information status assignment component achieves new state-of-the-art results on fine-grained IS classification based on gold mentions. Furthermore, our system performs significantly better than other baselines for both mention extraction and fine-grained IS classification in the end-to-end setting. Finally, we apply our system on BASHI (Roesiger, 2018) and SciCorp (Roesiger, 2016) to recognize referential bridging anaphora. We find that our end-to-end system trained on ISNotes achieves competitive results on bridging anaphora recognition compared to the previous state-of-the-art system that relies on syntactic information and is trained on the in-domain datasets (Yu and Poesio, 2020).
Speaker Adaptation with Continuous Vocoder-based DNN-TTS
Aug 02, 2021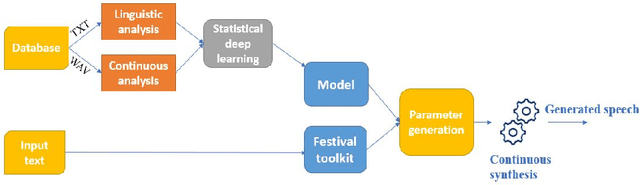
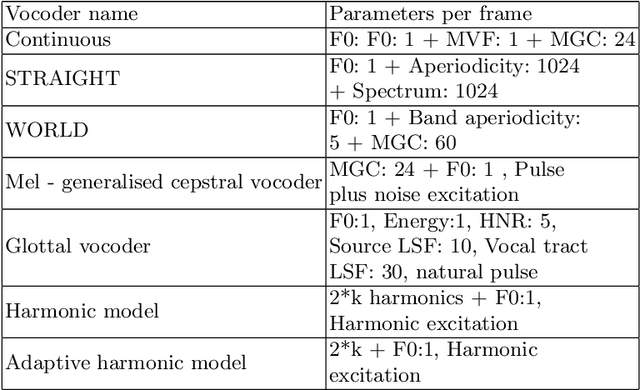
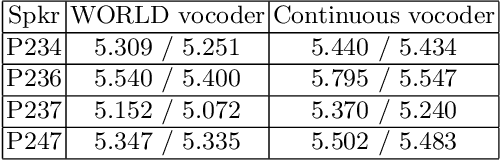
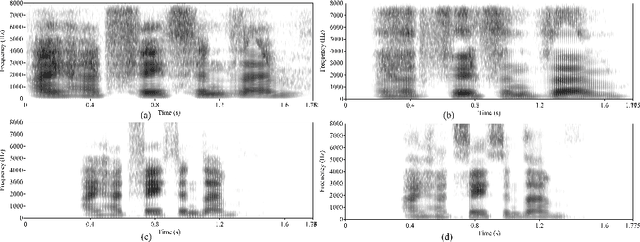
Traditional vocoder-based statistical parametric speech synthesis can be advantageous in applications that require low computational complexity. Recent neural vocoders, which can produce high naturalness, still cannot fulfill the requirement of being real-time during synthesis. In this paper, we experiment with our earlier continuous vocoder, in which the excitation is modeled with two one-dimensional parameters: continuous F0 and Maximum Voiced Frequency. We show on the data of 9 speakers that an average voice can be trained for DNN-TTS, and speaker adaptation is feasible 400 utterances (about 14 minutes). Objective experiments support that the quality of speaker adaptation with Continuous Vocoder-based DNN-TTS is similar to the quality of the speaker adaptation with a WORLD Vocoder-based baseline.
Learning spatiotemporal signals using a recurrent spiking network that discretizes time
Jul 20, 2019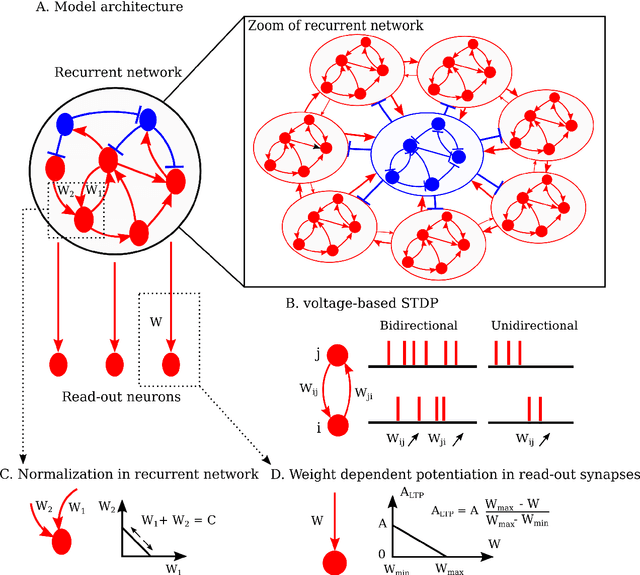

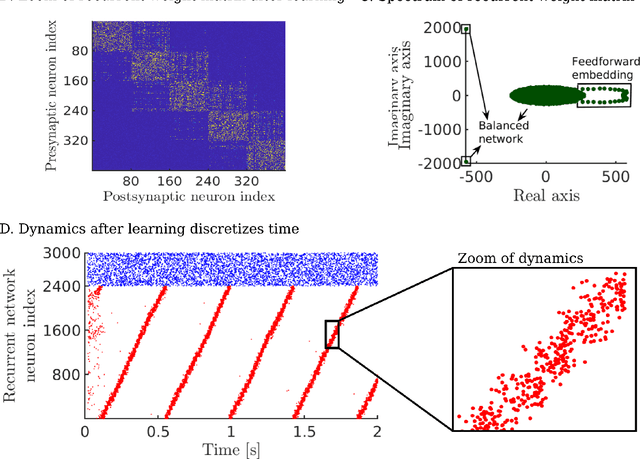

Learning to produce spatiotemporal sequences is a common task the brain has to solve. While many sequential behaviours differ superficially, the underlying organization of the computation might be similar. The way the brain learns these tasks remains unknown as current computational models do not typically use realistic biologically-plausible learning. Here, we propose a model where a spiking recurrent network drives a read-out layer. Plastic synapses follow common Hebbian learning rules. The dynamics of the recurrent network is constrained to encode time while the read-out neurons encode space. Space is then linked with time through Hebbian learning. Here we demonstrate that the model is able to learn spatiotemporal dynamics on a timescale that is behaviorally relevant. Learned sequences are robustly replayed during a regime of spontaneous activity.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021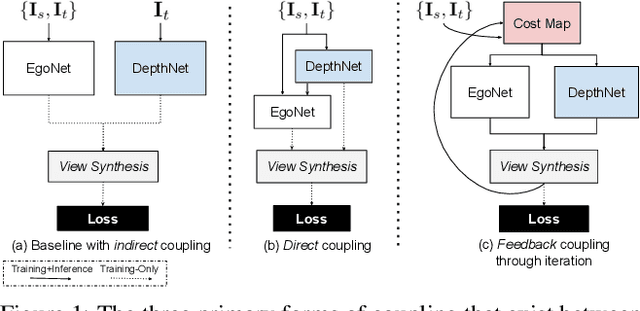
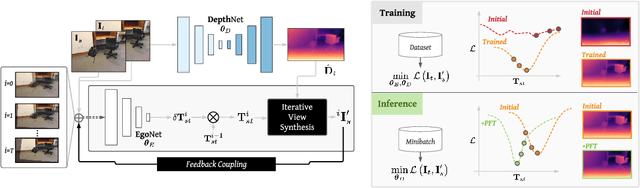
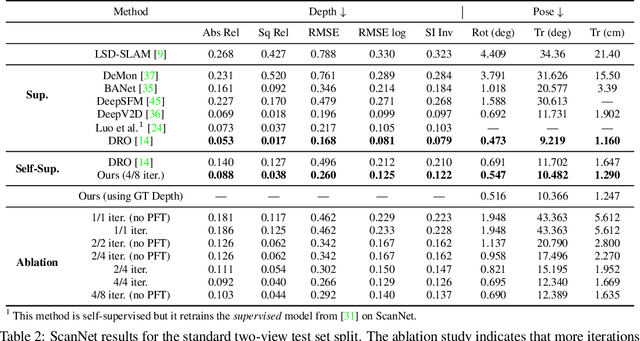

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
Backdoor Attacks on Network Certification via Data Poisoning
Aug 25, 2021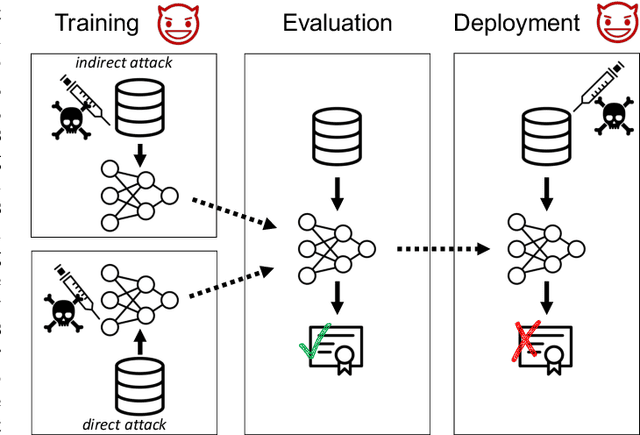

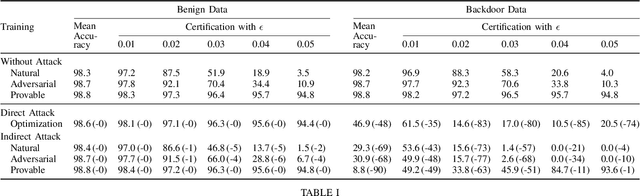
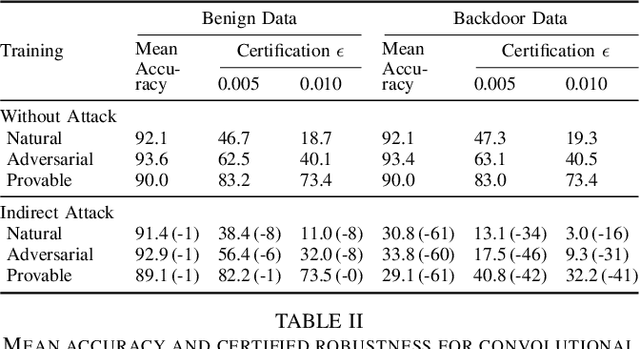
Certifiers for neural networks have made great progress towards provable robustness guarantees against evasion attacks using adversarial examples. However, introducing certifiers into deep learning systems also opens up new attack vectors, which need to be considered before deployment. In this work, we conduct the first systematic analysis of training time attacks against certifiers in practical application pipelines, identifying new threat vectors that can be exploited to degrade the overall system. Using these insights, we design two backdoor attacks against network certifiers, which can drastically reduce certified robustness when the backdoor is activated. For example, adding 1% poisoned data points during training is sufficient to reduce certified robustness by up to 95 percentage points, effectively rendering the certifier useless. We analyze how such novel attacks can compromise the overall system's integrity or availability. Our extensive experiments across multiple datasets, model architectures, and certifiers demonstrate the wide applicability of these attacks. A first investigation into potential defenses shows that current approaches only partially mitigate the issue, highlighting the need for new, more specific solutions.
Reinforcement Learning with Temporal Logic Constraints for Partially-Observable Markov Decision Processes
Apr 04, 2021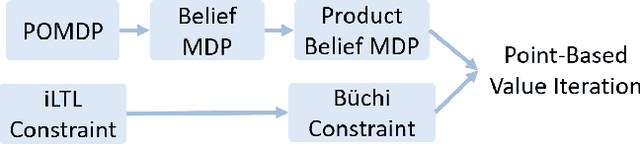
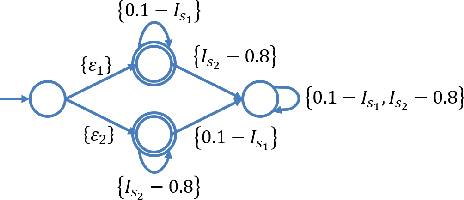
This paper proposes a reinforcement learning method for controller synthesis of autonomous systems in unknown and partially-observable environments with subjective time-dependent safety constraints. Mathematically, we model the system dynamics by a partially-observable Markov decision process (POMDP) with unknown transition/observation probabilities. The time-dependent safety constraint is captured by iLTL, a variation of linear temporal logic for state distributions. Our Reinforcement learning method first constructs the belief MDP of the POMDP, capturing the time evolution of estimated state distributions. Then, by building the product belief MDP of the belief MDP and the limiting deterministic B\uchi automaton (LDBA) of the temporal logic constraint, we transform the time-dependent safety constraint on the POMDP into a state-dependent constraint on the product belief MDP. Finally, we learn the optimal policy by value iteration under the state-dependent constraint.
Dropout's Dream Land: Generalization from Learned Simulators to Reality
Sep 17, 2021

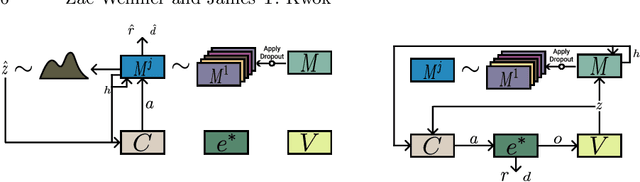

A World Model is a generative model used to simulate an environment. World Models have proven capable of learning spatial and temporal representations of Reinforcement Learning environments. In some cases, a World Model offers an agent the opportunity to learn entirely inside of its own dream environment. In this work we explore improving the generalization capabilities from dream environments to real environments (Dream2Real). We present a general approach to improve a controller's ability to transfer from a neural network dream environment to reality at little additional cost. These improvements are gained by drawing on inspiration from Domain Randomization, where the basic idea is to randomize as much of a simulator as possible without fundamentally changing the task at hand. Generally, Domain Randomization assumes access to a pre-built simulator with configurable parameters but oftentimes this is not available. By training the World Model using dropout, the dream environment is capable of creating a nearly infinite number of different dream environments. Previous use cases of dropout either do not use dropout at inference time or averages the predictions generated by multiple sampled masks (Monte-Carlo Dropout). Dropout's Dream Land leverages each unique mask to create a diverse set of dream environments. Our experimental results show that Dropout's Dream Land is an effective technique to bridge the reality gap between dream environments and reality. Furthermore, we additionally perform an extensive set of ablation studies.
Intelligent Motion Planning for a Cost-effective Object Follower Mobile Robotic System with Obstacle Avoidance
Sep 06, 2021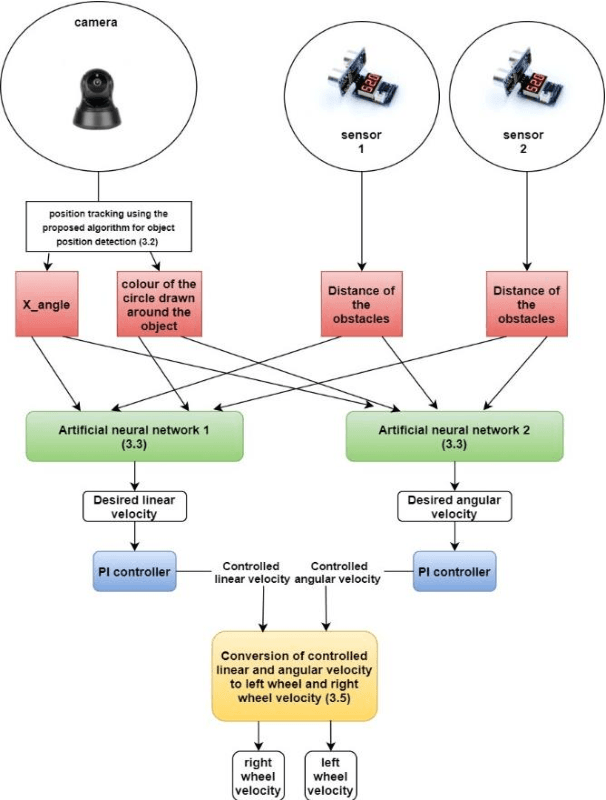
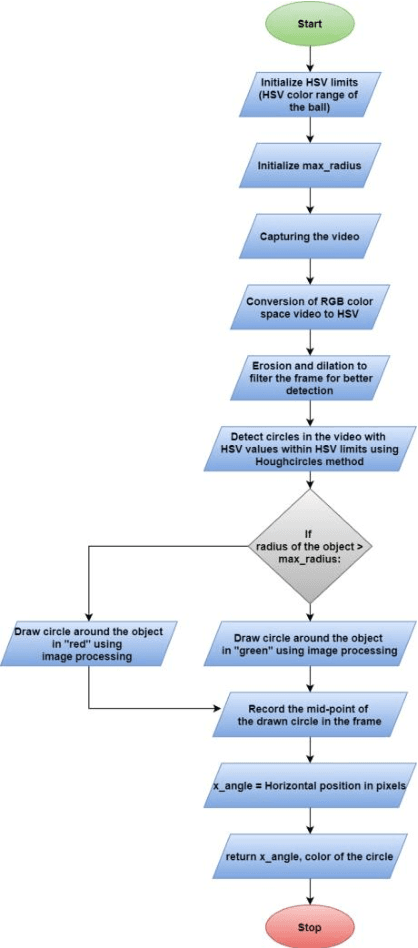
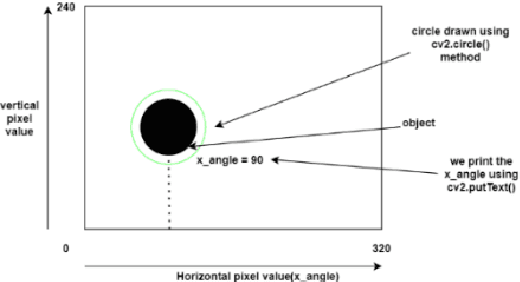
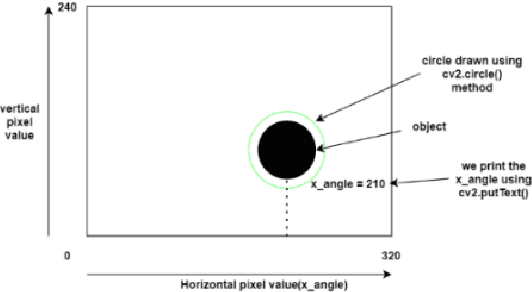
There are few industries which use manually controlled robots for carrying material and this cannot be used all the time in all the places. So, it is very tranquil to have robots which can follow a specific human by following the unique coloured object held by that person. So, we propose a robotic system which uses robot vision and deep learning to get the required linear and angular velocities which are {\nu} and {\omega}, respectively. Which in turn makes the robot to avoid obstacles when following the unique coloured object held by the human. The novel methodology that we are proposing is accurate in detecting the position of the unique coloured object in any kind of lighting and tells us the horizontal pixel value where the robot is present and also tells if the object is close to or far from the robot. Moreover, the artificial neural networks that we have used in this problem gave us a meagre error in linear and angular velocity prediction and the PI controller which was used to control the linear and angular velocities, which in turn controls the position of the robot gave us impressive results and this methodology outperforms all other methodologies.
Quantized convolutional neural networks through the lens of partial differential equations
Aug 31, 2021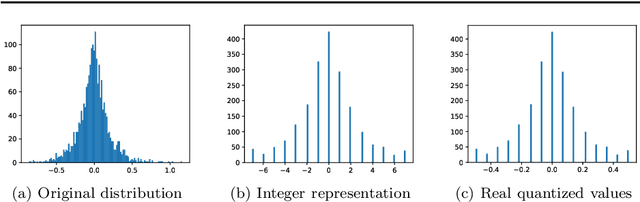
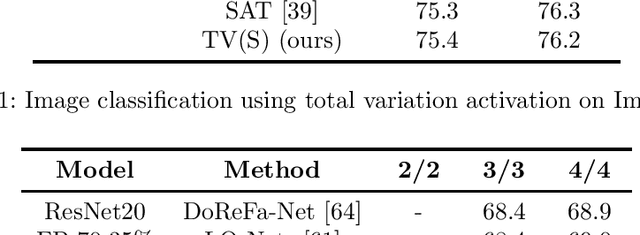


Quantization of Convolutional Neural Networks (CNNs) is a common approach to ease the computational burden involved in the deployment of CNNs, especially on low-resource edge devices. However, fixed-point arithmetic is not natural to the type of computations involved in neural networks. In this work, we explore ways to improve quantized CNNs using PDE-based perspective and analysis. First, we harness the total variation (TV) approach to apply edge-aware smoothing to the feature maps throughout the network. This aims to reduce outliers in the distribution of values and promote piece-wise constant maps, which are more suitable for quantization. Secondly, we consider symmetric and stable variants of common CNNs for image classification, and Graph Convolutional Networks (GCNs) for graph node-classification. We demonstrate through several experiments that the property of forward stability preserves the action of a network under different quantization rates. As a result, stable quantized networks behave similarly to their non-quantized counterparts even though they rely on fewer parameters. We also find that at times, stability even aids in improving accuracy. These properties are of particular interest for sensitive, resource-constrained, low-power or real-time applications like autonomous driving.