 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Computing in Robotics, Leveraging ROS 2 to Enable Software-Defined Hardware for FPGAs
Aug 30, 2021

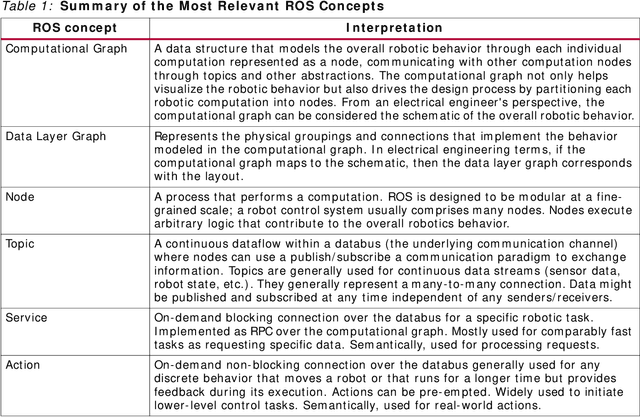
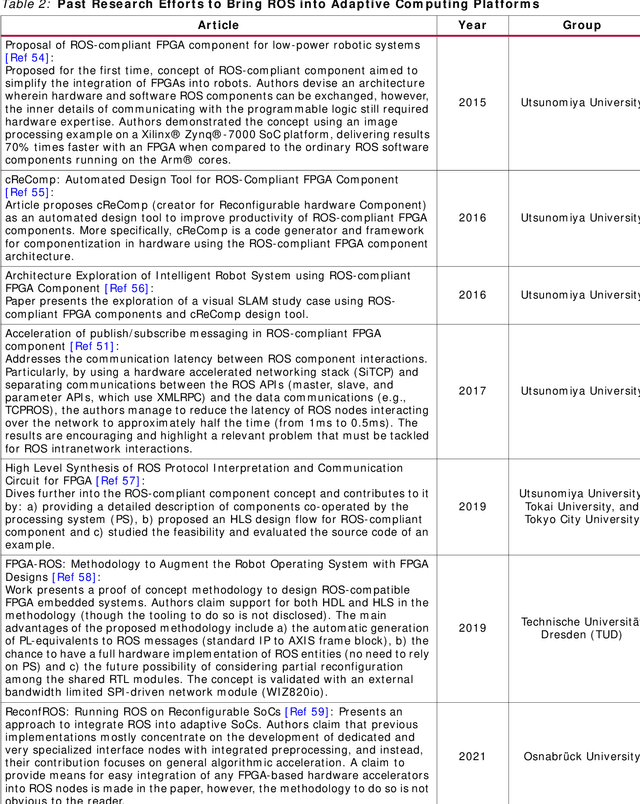
Traditional software development in robotics is about programming functionality in the CPU of a given robot with a pre-defined architecture and constraints. With adaptive computing, instead, building a robotic behavior is about programming an architecture. By leveraging adaptive computing, roboticists can adapt one or more of the properties of its computing systems (e.g. its determinism, power consumption, security posture, or throughput) at run time. Roboticists are not, however, hardware engineers, and embedded expertise is scarce among them. This white paper adopts a ROS 2 roboticist-centric view for adaptive computing and proposes an architecture to include FPGAs as a first-class participant of the ROS 2 ecosystem. The architecture proposed is platform- and technology-agnostic, and is easily portable. The core components of the architecture are disclosed under an Apache 2.0 license, paving the way for roboticists to leverage adaptive computing and create software-defined hardware.
Mixed Control for Whole-Body Compliance of a Humanoid Robot
Sep 16, 2021
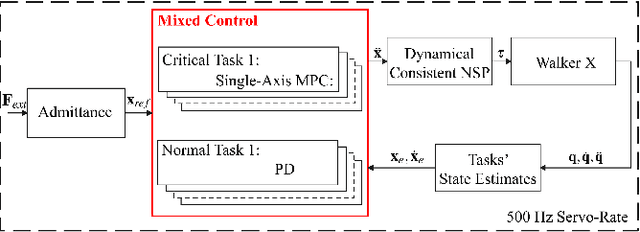
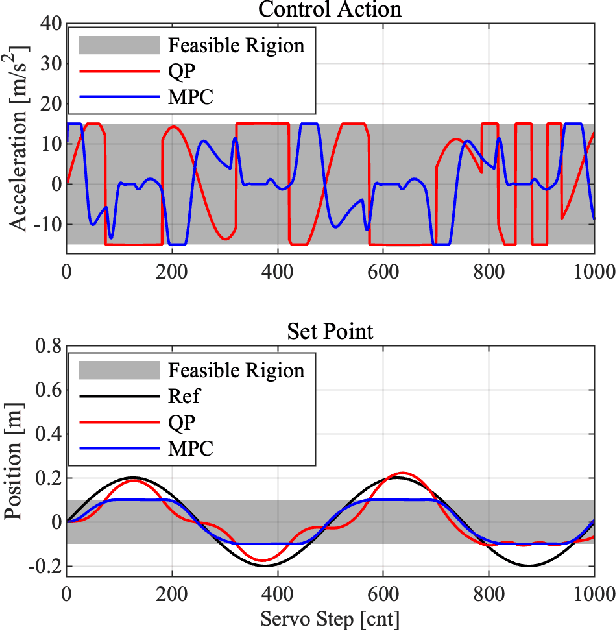
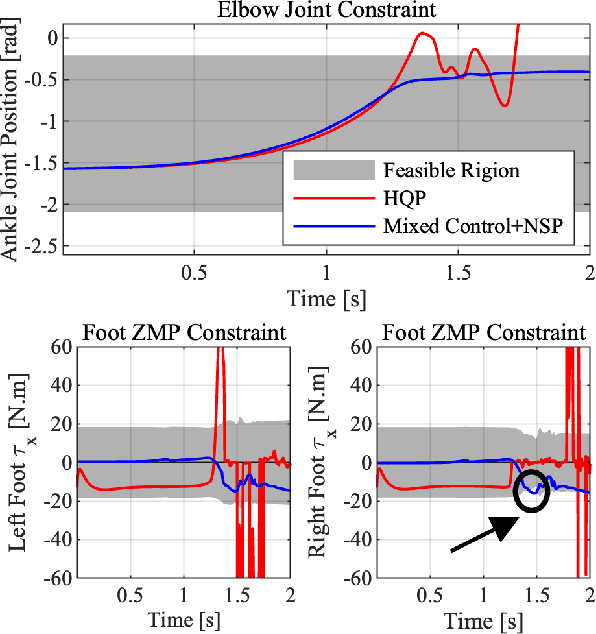
The hierarchical quadratic programming (HQP) is commonly applied to consider strict hierarchies of multi-tasks and robot's physical inequality constraints during whole-body compliance. However, for the one-step HQP, the solution can oscillate when it is close to the boundary of constraints. It is because the abrupt hit of the bounds gives rise to unrealisable jerks and even infeasible solutions. This paper proposes the mixed control, which blends the single-axis model predictive control (MPC) and proportional derivate (PD) control for the whole-body compliance to overcome these deficiencies. The MPC predicts the distances between the bounds and the control target of the critical tasks, and it provides smooth and feasible solutions by prediction and optimisation in advance. However, applying MPC will inevitably increase the computation time. Therefore, to achieve a 500 Hz servo rate, the PD controllers still regulate other tasks to save computation resources. Also, we use a more efficient null space projection (NSP) whole-body controller instead of the HQP and distribute the single-axis MPCs into four CPU cores for parallel computation. Finally, we validate the desired capabilities of the proposed strategy via Simulations and the experiment on the humanoid robot Walker X.
Diachronic Analysis of German Parliamentary Proceedings: Ideological Shifts through the Lens of Political Biases
Aug 13, 2021
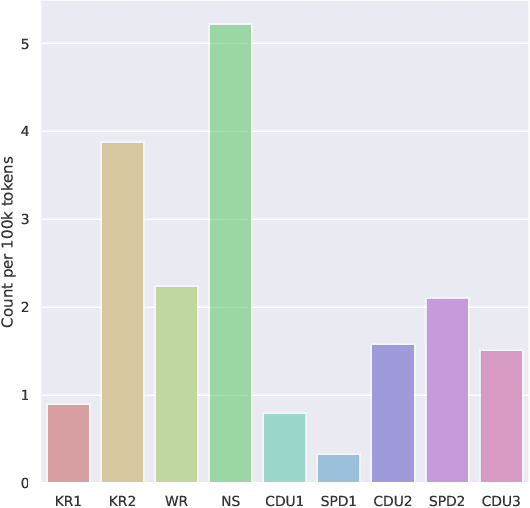

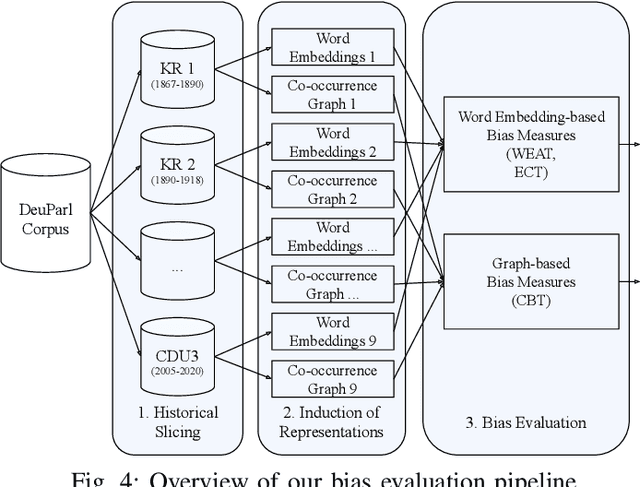
We analyze bias in historical corpora as encoded in diachronic distributional semantic models by focusing on two specific forms of bias, namely a political (i.e., anti-communism) and racist (i.e., antisemitism) one. For this, we use a new corpus of German parliamentary proceedings, DeuPARL, spanning the period 1867--2020. We complement this analysis of historical biases in diachronic word embeddings with a novel measure of bias on the basis of term co-occurrences and graph-based label propagation. The results of our bias measurements align with commonly perceived historical trends of antisemitic and anti-communist biases in German politics in different time periods, thus indicating the viability of analyzing historical bias trends using semantic spaces induced from historical corpora.
Distributed Optimization of Graph Convolutional Network using Subgraph Variance
Oct 06, 2021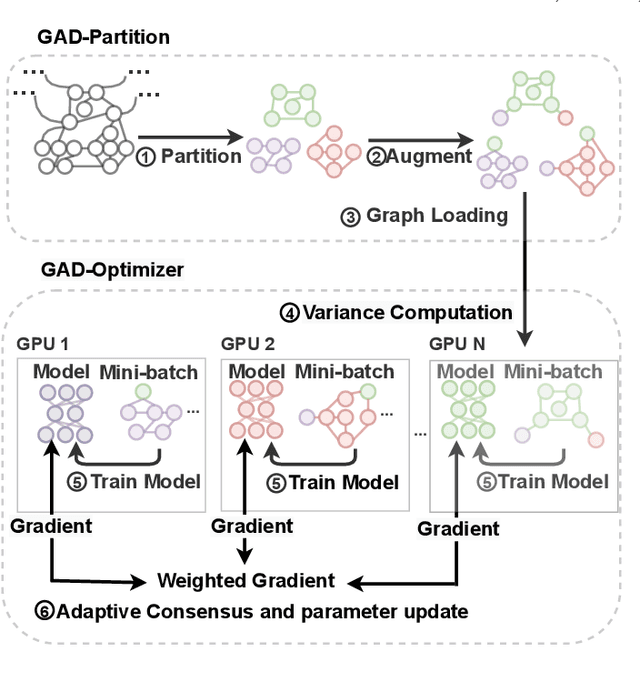

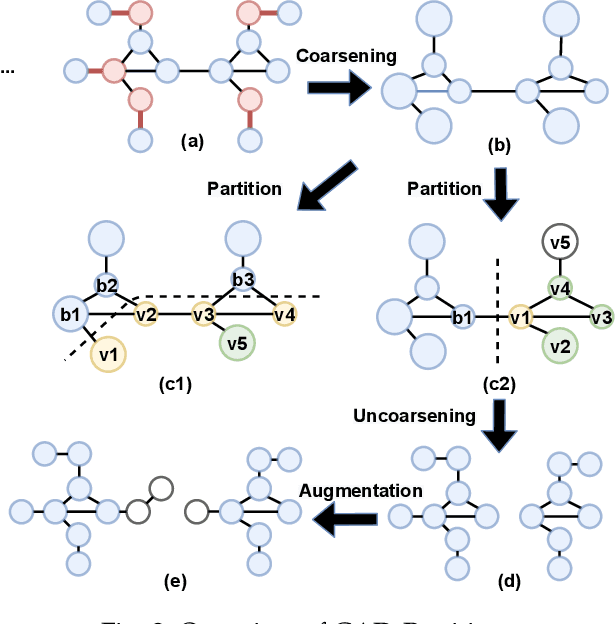
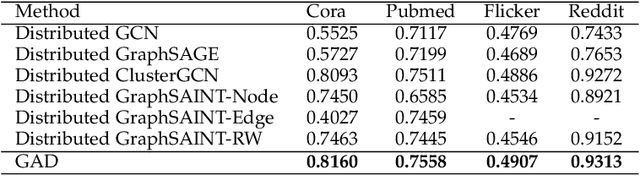
In recent years, Graph Convolutional Networks (GCNs) have achieved great success in learning from graph-structured data. With the growing tendency of graph nodes and edges, GCN training by single processor cannot meet the demand for time and memory, which led to a boom into distributed GCN training frameworks research. However, existing distributed GCN training frameworks require enormous communication costs between processors since multitudes of dependent nodes and edges information need to be collected and transmitted for GCN training from other processors. To address this issue, we propose a Graph Augmentation based Distributed GCN framework(GAD). In particular, GAD has two main components, GAD-Partition and GAD-Optimizer. We first propose a graph augmentation-based partition (GAD-Partition) that can divide original graph into augmented subgraphs to reduce communication by selecting and storing as few significant nodes of other processors as possible while guaranteeing the accuracy of the training. In addition, we further design a subgraph variance-based importance calculation formula and propose a novel weighted global consensus method, collectively referred to as GAD-Optimizer. This optimizer adaptively reduces the importance of subgraphs with large variances for the purpose of reducing the effect of extra variance introduced by GAD-Partition on distributed GCN training. Extensive experiments on four large-scale real-world datasets demonstrate that our framework significantly reduces the communication overhead (50%), improves the convergence speed (2X) of distributed GCN training, and slight gain in accuracy (0.45%) based on minimal redundancy compared to the state-of-the-art methods.
Adaptively Aligned Image Captioning via Adaptive Attention Time
Nov 01, 2019
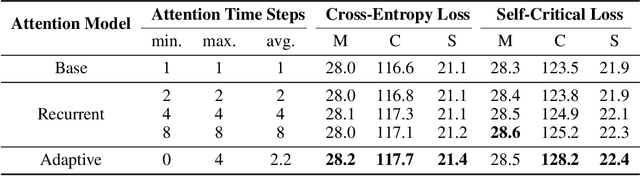
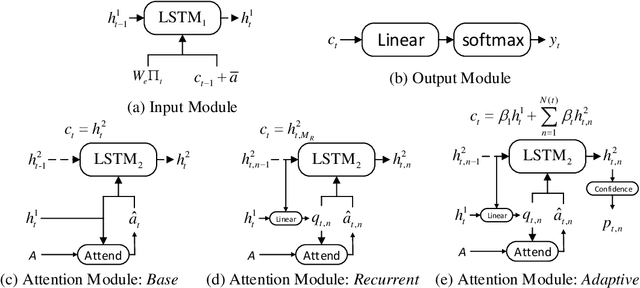

Recent neural models for image captioning usually employ an encoder-decoder framework with an attention mechanism. However, the attention mechanism in such a framework aligns one single (attended) image feature vector to one caption word, assuming one-to-one mapping from source image regions and target caption words, which is never possible. In this paper, we propose a novel attention model, namely Adaptive Attention Time (AAT), to align the source and the target adaptively for image captioning. AAT allows the framework to learn how many attention steps to take to output a caption word at each decoding step. With AAT, an image region can be mapped to an arbitrary number of caption words while a caption word can also attend to an arbitrary number of image regions. AAT is deterministic and differentiable, and doesn't introduce any noise to the parameter gradients. In this paper, we empirically show that AAT improves over state-of-the-art methods on the task of image captioning. Code is available at https://github.com/husthuaan/AAT.
Analyzing the Travel and Charging Behavior of Electric Vehicles -- A Data-driven Approach
Jun 11, 2021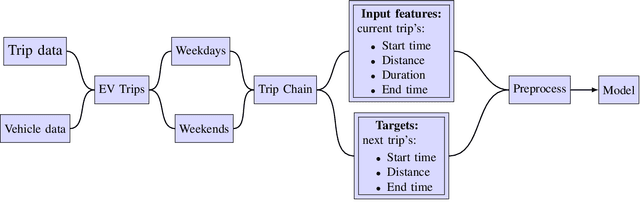
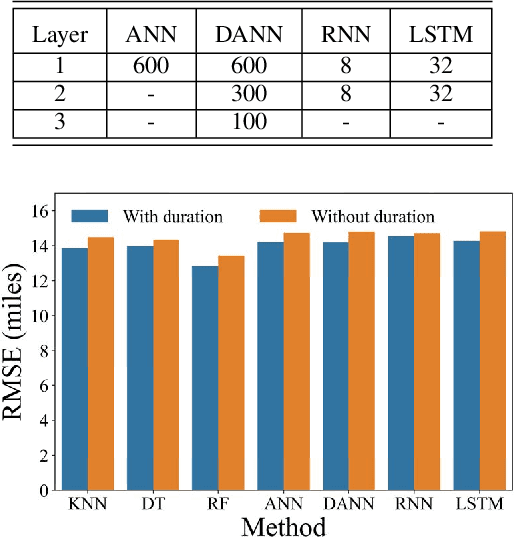
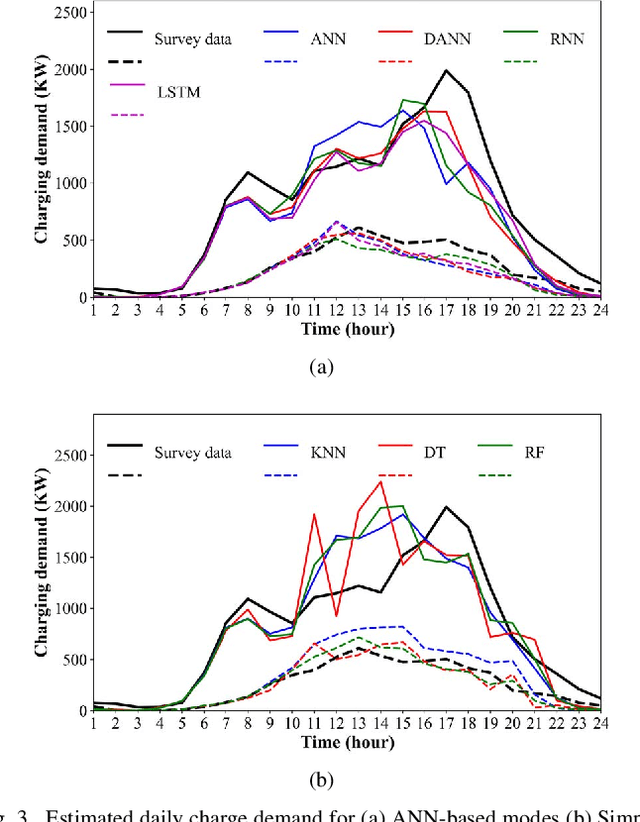
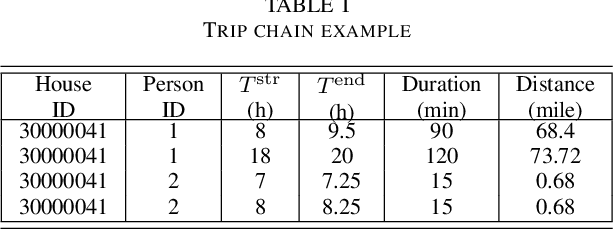
The increasing market penetration of electric vehicles (EVs) may pose significant electricity demand on power systems. This electricity demand is affected by the inherent uncertainties of EVs' travel behavior that makes forecasting the daily charging demand (CD) very challenging. In this project, we use the National House Hold Survey (NHTS) data to form sequences of trips, and develop machine learning models to predict the parameters of the next trip of the drivers, including trip start time, end time, and distance. These parameters are later used to model the temporal charging behavior of EVs. The simulation results show that the proposed modeling can effectively estimate the daily CD pattern based on travel behavior of EVs, and simple machine learning techniques can forecast the travel parameters with acceptable accuracy.
PAC Best Arm Identification Under a Deadline
Jun 06, 2021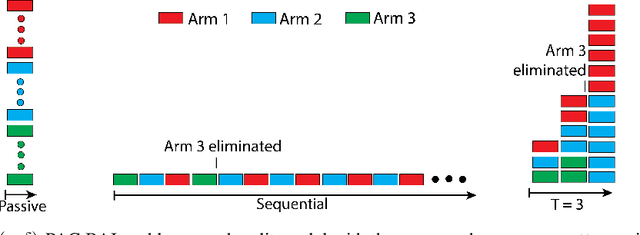
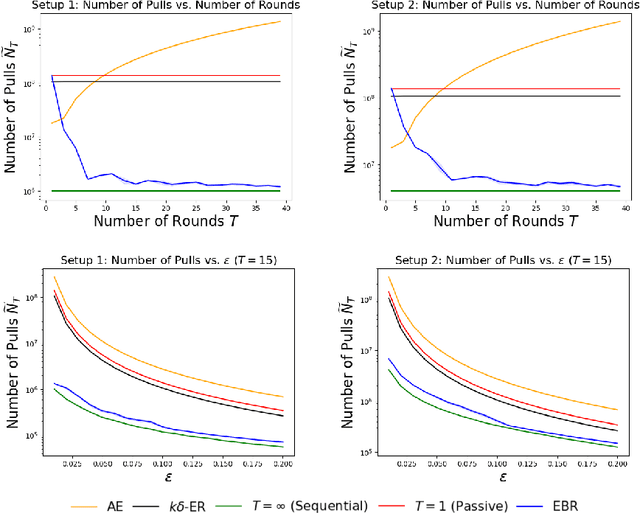
We study $(\epsilon, \delta)$-PAC best arm identification, where a decision-maker must identify an $\epsilon$-optimal arm with probability at least $1 - \delta$, while minimizing the number of arm pulls (samples). Most of the work on this topic is in the sequential setting, where there is no constraint on the \emph{time} taken to identify such an arm; this allows the decision-maker to pull one arm at a time. In this work, the decision-maker is given a deadline of $T$ rounds, where, on each round, it can adaptively choose which arms to pull and how many times to pull them; this distinguishes the number of decisions made (i.e., time or number of rounds) from the number of samples acquired (cost). Such situations occur in clinical trials, where one may need to identify a promising treatment under a deadline while minimizing the number of test subjects, or in simulation-based studies run on the cloud, where we can elastically scale up or down the number of virtual machines to conduct as many experiments as we wish, but need to pay for the resource-time used. As the decision-maker can only make $T$ decisions, she may need to pull some arms excessively relative to a sequential algorithm in order to perform well on all possible problems. We formalize this added difficulty with two hardness results that indicate that unlike sequential settings, the ability to adapt to the problem difficulty is constrained by the finite deadline. We propose Elastic Batch Racing (EBR), a novel algorithm for this setting and bound its sample complexity, showing that EBR is optimal with respect to both hardness results. We present simulations evaluating EBR in this setting, where it outperforms baselines by several orders of magnitude.
Extended Version of GTGraffiti: Spray Painting Graffiti Art from Human Painting Motions with a Cable Driven Parallel Robot
Sep 16, 2021
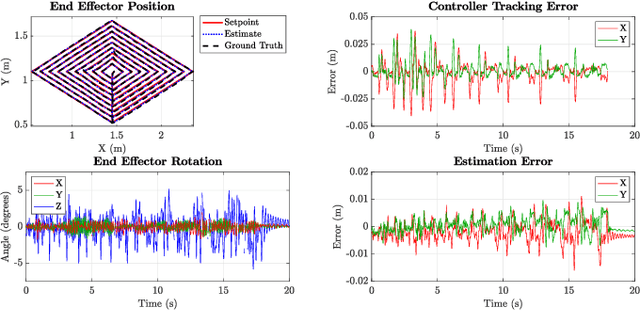


We present GTGraffiti, a graffiti painting system from Georgia Tech that tackles challenges in art, hardware, and human-robot collaboration. The problem of painting graffiti in a human style is particularly challenging and requires a system-level approach because the robotics and art must be designed around each other. The robot must be highly dynamic over a large workspace while the artist must work within the robot's limitations. Our approach consists of three stages: artwork capture, robot hardware, and planning & control. We use motion capture to capture collaborator painting motions which are then composed and processed into a time-varying linear feedback controller for a cable-driven parallel robot (CDPR) to execute. In this work, we will describe the capturing process, the design and construction of a purpose-built CDPR, and the software for turning an artist's vision into control commands. Our work represents an important step towards faithfully recreating human graffiti artwork by demonstrating that we can reproduce artist motions up to 2m/s and 20m/s$^2$ within 9.3mm RMSE to paint artworks. Added material not in the original work is colored in red.
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Cloud
Aug 13, 2021
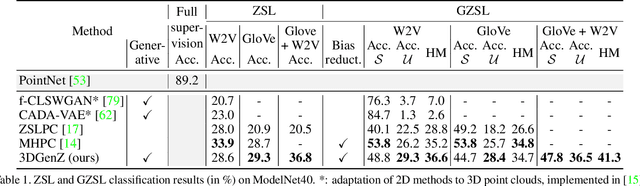
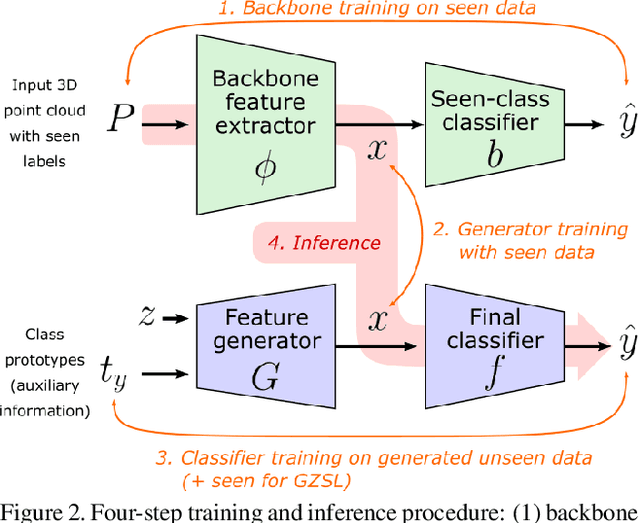
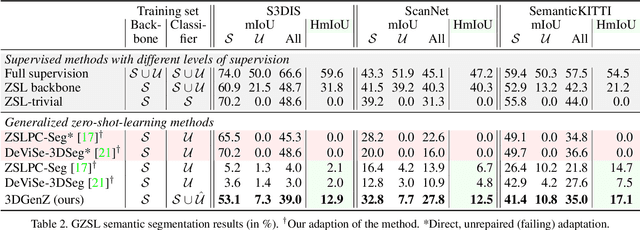
While there has been a number of studies on Zero-Shot Learning (ZSL) for 2D images, its application to 3D data is still recent and scarce, with just a few methods limited to classification. We present the first generative approach for both ZSL and Generalized ZSL (GZSL) on 3D data, that can handle both classification and, for the first time, semantic segmentation. We show that it reaches or outperforms the state of the art on ModelNet40 classification for both inductive ZSL and inductive GZSL. For semantic segmentation, we created three benchmarks for evaluating this new ZSL task, using S3DIS, ScanNet and SemanticKITTI. Our experiments show that our method outperforms strong baselines, which we additionally propose for this task.
8-bit Optimizers via Block-wise Quantization
Oct 06, 2021



Stateful optimizers maintain gradient statistics over time, e.g., the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. In this paper, we develop the first optimizers that use 8-bit statistics while maintaining the performance levels of using 32-bit optimizer states. To overcome the resulting computational, quantization, and stability challenges, we develop block-wise dynamic quantization. Block-wise quantization divides input tensors into smaller blocks that are independently quantized. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization. To maintain stability and performance, we combine block-wise quantization with two additional changes: (1) dynamic quantization, a form of non-linear optimization that is precise for both large and small magnitude values, and (2) a stable embedding layer to reduce gradient variance that comes from the highly non-uniform distribution of input tokens in language models. As a result, our 8-bit optimizers maintain 32-bit performance with a small fraction of the memory footprint on a range of tasks, including 1.5B parameter language modeling, GLUE finetuning, ImageNet classification, WMT'14 machine translation, MoCo v2 contrastive ImageNet pretraining+finetuning, and RoBERTa pretraining, without changes to the original optimizer hyperparameters. We open-source our 8-bit optimizers as a drop-in replacement that only requires a two-line code change.