 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Terminology Integration for COVID-19 and other Emerging Domains
Sep 10, 2021

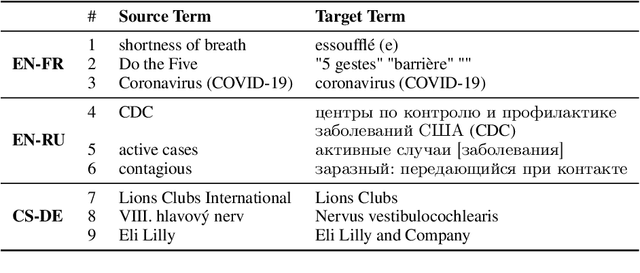
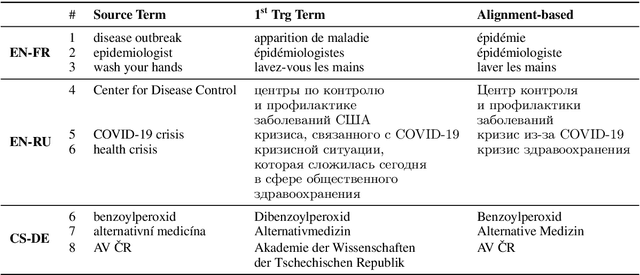
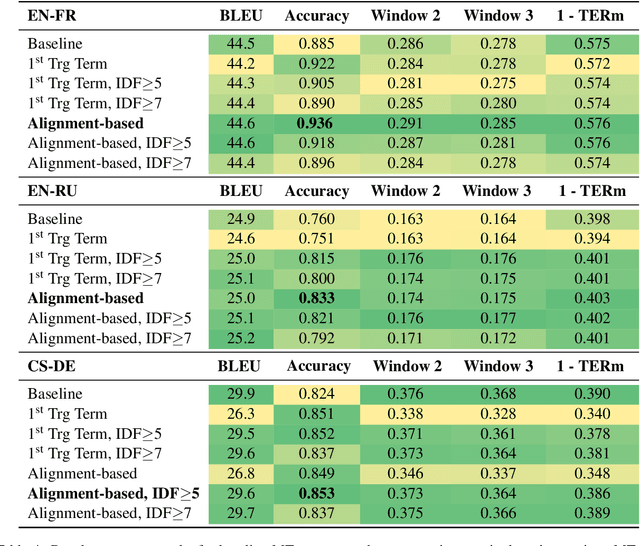
The majority of language domains require prudent use of terminology to ensure clarity and adequacy of information conveyed. While the correct use of terminology for some languages and domains can be achieved by adapting general-purpose MT systems on large volumes of in-domain parallel data, such quantities of domain-specific data are seldom available for less-resourced languages and niche domains. Furthermore, as exemplified by COVID-19 recently, no domain-specific parallel data is readily available for emerging domains. However, the gravity of this recent calamity created a high demand for reliable translation of critical information regarding pandemic and infection prevention. This work is part of WMT2021 Shared Task: Machine Translation using Terminologies, where we describe Tilde MT systems that are capable of dynamic terminology integration at the time of translation. Our systems achieve up to 94% COVID-19 term use accuracy on the test set of the EN-FR language pair without having access to any form of in-domain information during system training. We conclude our work with a broader discussion considering the Shared Task itself and terminology translation in MT.
Scientific evidence extraction
Sep 30, 2021

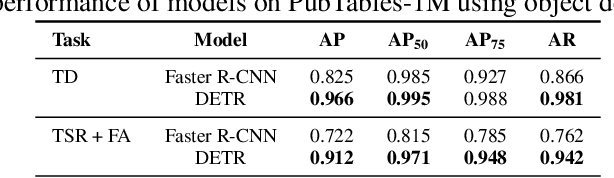
Recently, interest has grown in applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, progress in this area has been challenging both to make and to measure, due to several issues that arise in training and evaluating models from labeled data. This includes challenges as fundamental as the lack of a single definitive ground truth output for each input sample and the lack of an ideal metric for measuring partial correctness for this task. To address these we propose a new dataset, PubMed Tables One Million (PubTables-1M), and a new class of metric, grid table similarity (GriTS). PubTables-1M is nearly twice as large as the previous largest comparable dataset, can be used for models across multiple architectures and modalities, and addresses issues such as ambiguity and lack of consistency in the annotations. We apply DETR to table extraction for the first time and show that object detection models trained on PubTables-1M produce excellent results out-of-the-box for all three tasks of detection, structure recognition, and functional analysis. We describe the dataset in detail to enable others to build on our work and combine this data with other datasets for these and related tasks. It is our hope that PubTables-1M and the proposed metrics can further progress in this area by creating a benchmark suitable for training and evaluating a wide variety of models for table extraction. Data and code will be released at https://github.com/microsoft/table-transformer.
Real-Time Point Cloud Fusion of Multi-LiDAR Infrastructure Sensor Setups with Unknown Spatial Location and Orientation
Jul 28, 2020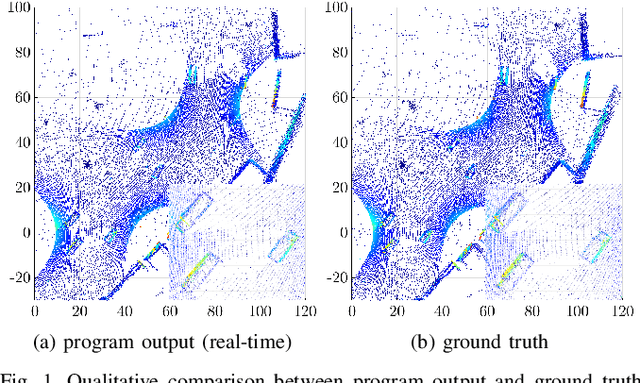
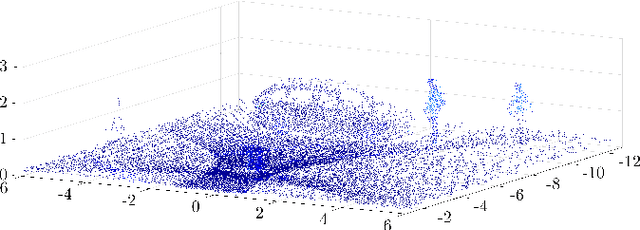
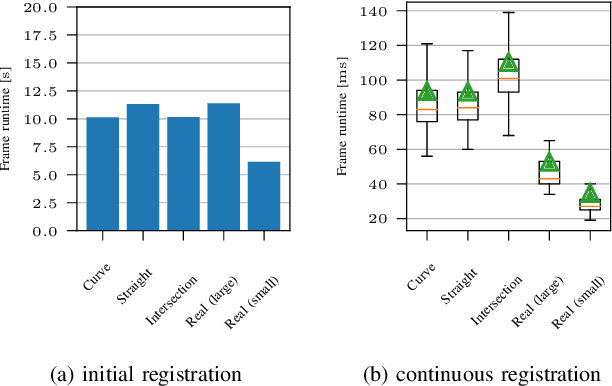
The use of infrastructure sensor technology for traffic detection has already been proven several times. However, extrinsic sensor calibration is still a challenge for the operator. While previous approaches are unable to calibrate the sensors without the use of reference objects in the sensor field of view (FOV), we present an algorithm that is completely detached from external assistance and runs fully automatically. Our method focuses on the high-precision fusion of LiDAR point clouds and is evaluated in simulation as well as on real measurements. We set the LiDARs in a continuous pendulum motion in order to simulate real-world operation as closely as possible and to increase the demands on the algorithm. However, it does not receive any information about the initial spatial location and orientation of the LiDARs throughout the entire measurement period. Experiments in simulation as well as with real measurements have shown that our algorithm performs a continuous point cloud registration of up to four 64-layer LiDARs in real-time. The averaged resulting translational error is within a few centimeters and the averaged error in rotation is below 0.15 degrees.
Learning Residue-Aware Correlation Filters and Refining Scale Estimates with the GrabCut for Real-Time UAV Tracking
Apr 07, 2021

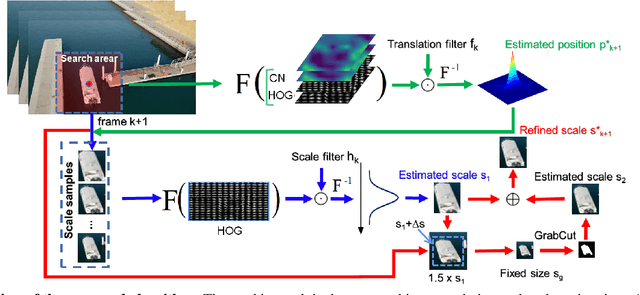
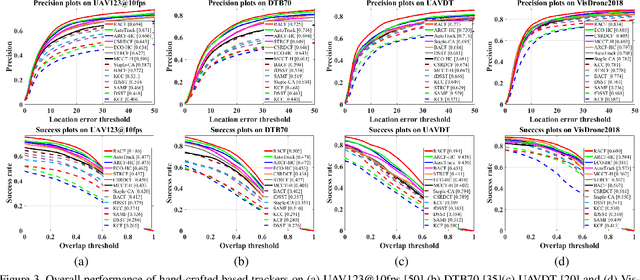
Unmanned aerial vehicle (UAV)-based tracking is attracting increasing attention and developing rapidly in applications such as agriculture, aviation, navigation, transportation and public security. Recently, discriminative correlation filters (DCF)-based trackers have stood out in UAV tracking community for their high efficiency and appealing robustness on a single CPU. However, due to limited onboard computation resources and other challenges the efficiency and accuracy of existing DCF-based approaches is still not satisfying. In this paper, we explore using segmentation by the GrabCut to improve the wildly adopted discriminative scale estimation in DCF-based trackers, which, as a mater of fact, greatly impacts the precision and accuracy of the trackers since accumulated scale error degrades the appearance model as online updating goes on. Meanwhile, inspired by residue representation, we exploit the residue nature inherent to videos and propose residue-aware correlation filters that show better convergence properties in filter learning. Extensive experiments are conducted on four UAV benchmarks, namely, UAV123@10fps, DTB70, UAVDT and Vistrone2018 (VisDrone2018-test-dev). The results show that our method achieves state-of-the-art performance.
Unsupervised Real Time Prediction of Faults Using the Support Vector Machine
Dec 30, 2020This paper aims at improving the classification accuracy of a Support Vector Machine (SVM) classifier with Sequential Minimal Optimization (SMO) training algorithm in order to properly classify failure and normal instances from oil and gas equipment data. Recent applications of failure analysis have made use of the SVM technique without implementing SMO training algorithm, while in our study we show that the proposed solution can perform much better when using the SMO training algorithm. Furthermore, we implement the ensemble approach, which is a hybrid rule based and neural network classifier to improve the performance of the SVM classifier (with SMO training algorithm). The optimization study is as a result of the underperformance of the classifier when dealing with imbalanced dataset. The selected best performing classifiers are combined together with SVM classifier (with SMO training algorithm) by using the stacking ensemble method which is to create an efficient ensemble predictive model that can handle the issue of imbalanced data. The classification performance of this predictive model is considerably better than the SVM with and without SMO training algorithm and many other conventional classifiers.
Trajectory Design for UAV-Based Internet-of-Things Data Collection: A Deep Reinforcement Learning Approach
Jul 23, 2021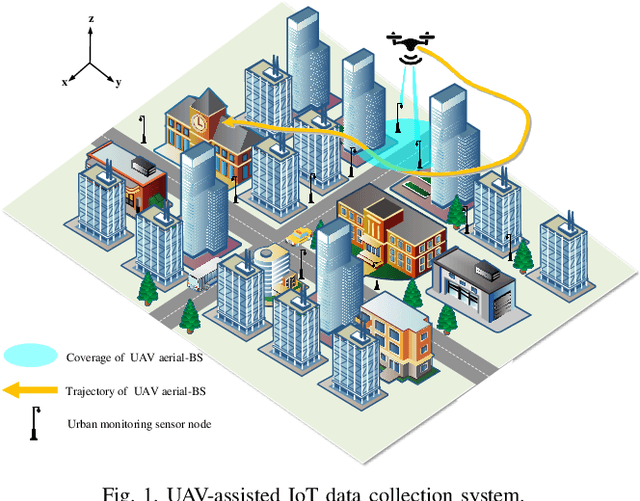
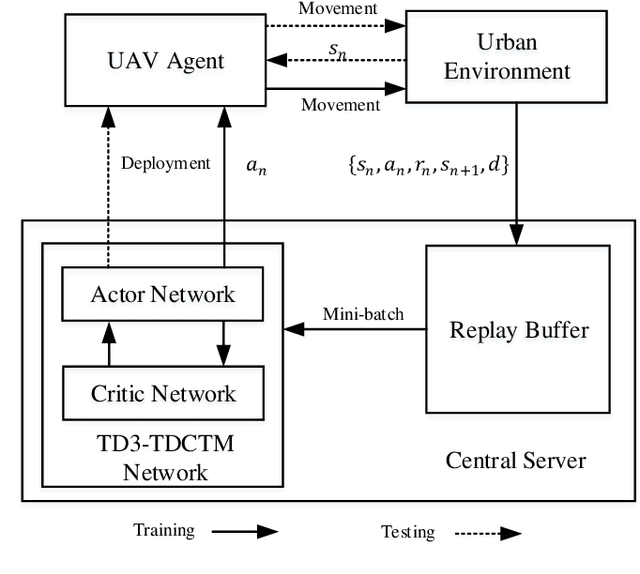
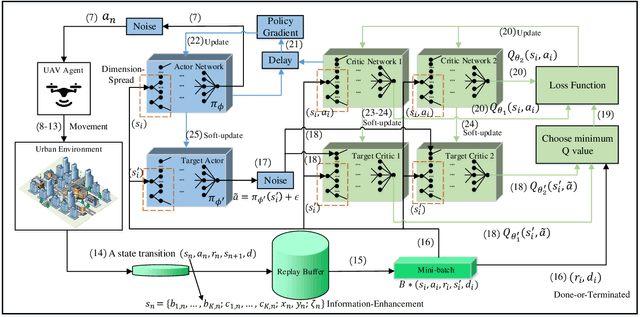
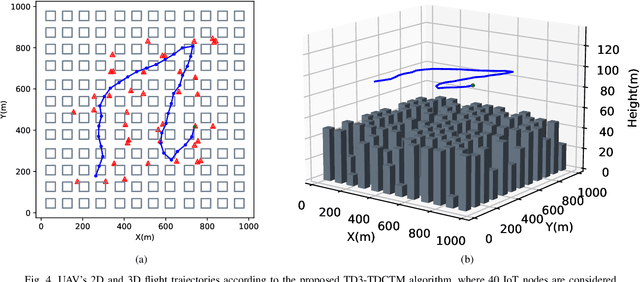
In this paper, we investigate an unmanned aerial vehicle (UAV)-assisted Internet-of-Things (IoT) system in a sophisticated three-dimensional (3D) environment, where the UAV's trajectory is optimized to efficiently collect data from multiple IoT ground nodes. Unlike existing approaches focusing only on a simplified two-dimensional scenario and the availability of perfect channel state information (CSI), this paper considers a practical 3D urban environment with imperfect CSI, where the UAV's trajectory is designed to minimize data collection completion time subject to practical throughput and flight movement constraints. Specifically, inspired from the state-of-the-art deep reinforcement learning approaches, we leverage the twin-delayed deep deterministic policy gradient (TD3) to design the UAV's trajectory and present a TD3-based trajectory design for completion time minimization (TD3-TDCTM) algorithm. In particular, we set an additional information, i.e., the merged pheromone, to represent the state information of UAV and environment as a reference of reward which facilitates the algorithm design. By taking the service statuses of IoT nodes, the UAV's position, and the merged pheromone as input, the proposed algorithm can continuously and adaptively learn how to adjust the UAV's movement strategy. By interacting with the external environment in the corresponding Markov decision process, the proposed algorithm can achieve a near-optimal navigation strategy. Our simulation results show the superiority of the proposed TD3-TDCTM algorithm over three conventional non-learning based baseline methods.
A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
Jul 11, 2021
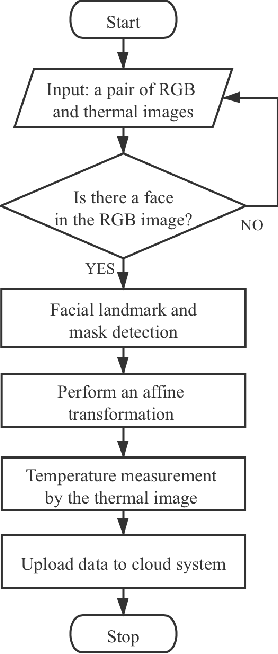
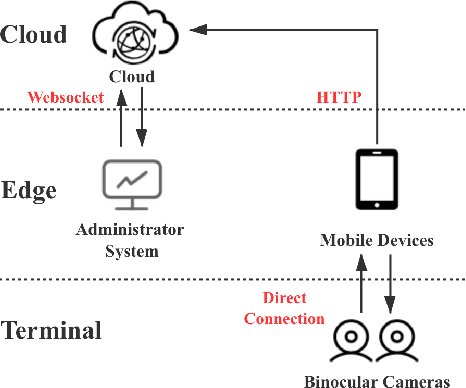

To prevent the spread of coronavirus disease 2019 (COVID-19), preliminary temperature measurement and mask detection in public areas are conducted. However, the existing temperature measurement methods face the problems of safety and deployment. In this paper, to realize safe and accurate temperature measurement even when a person's face is partially obscured, we propose a cloud-edge-terminal collaborative system with a lightweight infrared temperature measurement model. A binocular camera with an RGB lens and a thermal lens is utilized to simultaneously capture image pairs. Then, a mobile detection model based on a multi-task cascaded convolutional network (MTCNN) is proposed to realize face alignment and mask detection on the RGB images. For accurate temperature measurement, we transform the facial landmarks on the RGB images to the thermal images by an affine transformation and select a more accurate temperature measurement area on the forehead. The collected information is uploaded to the cloud in real time for COVID-19 prevention. Experiments show that the detection model is only 6.1M and the average detection speed is 257ms. At a distance of 1m, the error of indoor temperature measurement is about 3%. That is, the proposed system can realize real-time temperature measurement in public areas.
Efficient Domain Adaptation of Language Models via Adaptive Tokenization
Sep 15, 2021
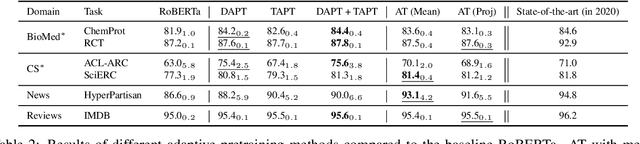

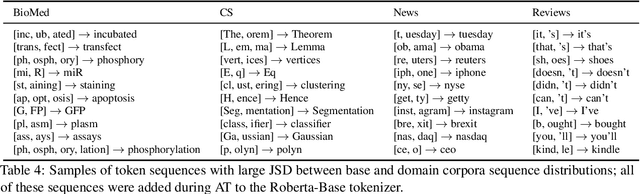
Contextual embedding-based language models trained on large data sets, such as BERT and RoBERTa, provide strong performance across a wide range of tasks and are ubiquitous in modern NLP. It has been observed that fine-tuning these models on tasks involving data from domains different from that on which they were pretrained can lead to suboptimal performance. Recent work has explored approaches to adapt pretrained language models to new domains by incorporating additional pretraining using domain-specific corpora and task data. We propose an alternative approach for transferring pretrained language models to new domains by adapting their tokenizers. We show that domain-specific subword sequences can be efficiently determined directly from divergences in the conditional token distributions of the base and domain-specific corpora. In datasets from four disparate domains, we find adaptive tokenization on a pretrained RoBERTa model provides >97% of the performance benefits of domain specific pretraining. Our approach produces smaller models and less training and inference time than other approaches using tokenizer augmentation. While adaptive tokenization incurs a 6% increase in model parameters in our experimentation, due to the introduction of 10k new domain-specific tokens, our approach, using 64 vCPUs, is 72x faster than further pretraining the language model on domain-specific corpora on 8 TPUs.
Neural HMMs are all you need (for high-quality attention-free TTS)
Sep 03, 2021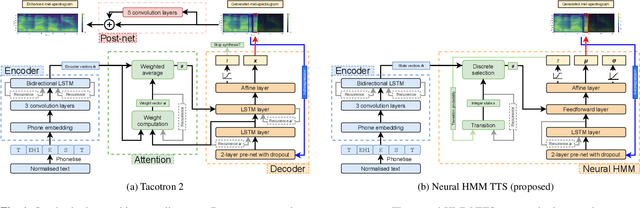
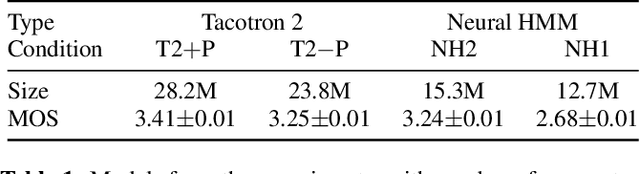
Neural sequence-to-sequence TTS has demonstrated significantly better output quality over classical statistical parametric speech synthesis using HMMs. However, the new paradigm is not probabilistic and the use of non-monotonic attention both increases training time and introduces "babbling" failure modes that are unacceptable in production. In this paper, we demonstrate that the old and new paradigms can be combined to obtain the advantages of both worlds, by replacing the attention in Tacotron 2 with an autoregressive left-right no-skip hidden Markov model defined by a neural network. This leads to an HMM-based neural TTS model with monotonic alignment, trained to maximise the full sequence likelihood without approximations. We discuss how to combine innovations from both classical and contemporary TTS for best results. The final system is smaller and simpler than Tacotron 2 and learns to align and speak with fewer iterations, whilst achieving the same naturalness prior to the post-net. Our system also allows easy control over speaking rate. Audio examples and code are available at https://shivammehta007.github.io/Neural-HMM/
Liquid Time-constant Recurrent Neural Networks as Universal Approximators
Nov 01, 2018In this paper, we introduce the notion of liquid time-constant (LTC) recurrent neural networks (RNN)s, a subclass of continuous-time RNNs, with varying neuronal time-constant realized by their nonlinear synaptic transmission model. This feature is inspired by the communication principles in the nervous system of small species. It enables the model to approximate continuous mapping with a small number of computational units. We show that any finite trajectory of an $n$-dimensional continuous dynamical system can be approximated by the internal state of the hidden units and $n$ output units of an LTC network. Here, we also theoretically find bounds on their neuronal states and varying time-constant.