 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Assessing Machine Learning Approaches to Address IoT Sensor Drift
Sep 02, 2021
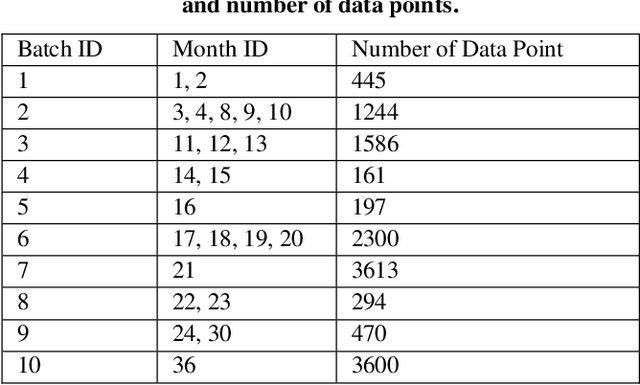
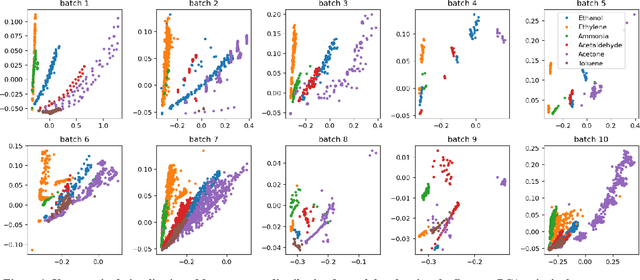
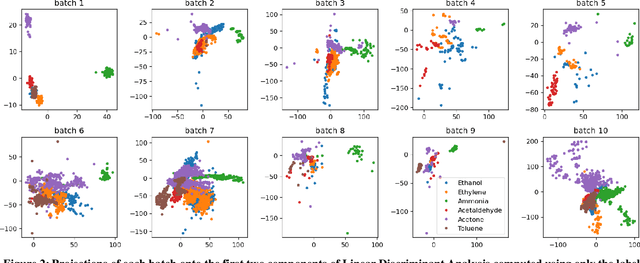
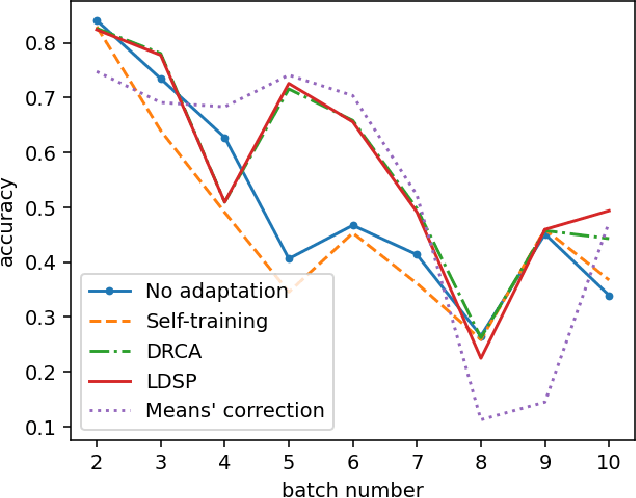
The proliferation of IoT sensors and their deployment in various industries and applications has brought about numerous analysis opportunities in this Big Data era. However, drift of those sensor measurements poses major challenges to automate data analysis and the ability to effectively train and deploy models on a continuous basis. In this paper we study and test several approaches from the literature with regard to their ability to cope with and adapt to sensor drift under realistic conditions. Most of these approaches are recent and thus are representative of the current state-of-the-art. The testing was performed on a publicly available gas sensor dataset exhibiting drift over time. The results show substantial drops in sensing performance due to sensor drift in spite of the approaches. We then discuss several issues identified with current approaches and outline directions for future research to tackle them.
The Average-Case Time Complexity of Certifying the Restricted Isometry Property
May 22, 2020In compressed sensing, the restricted isometry property (RIP) on $M \times N$ sensing matrices (where $M < N$) guarantees efficient reconstruction of sparse vectors. A matrix has the $(s,\delta)$-$\mathsf{RIP}$ property if behaves as a $\delta$-approximate isometry on $s$-sparse vectors. It is well known that an $M\times N$ matrix with i.i.d. $\mathcal{N}(0,1/M)$ entries is $(s,\delta)$-$\mathsf{RIP}$ with high probability as long as $s\lesssim \delta^2 M/\log N$. On the other hand, most prior works aiming to deterministically construct $(s,\delta)$-$\mathsf{RIP}$ matrices have failed when $s \gg \sqrt{M}$. An alternative way to find an RIP matrix could be to draw a random gaussian matrix and certify that it is indeed RIP. However, there is evidence that this certification task is computationally hard when $s \gg \sqrt{M}$, both in the worst case and the average case. In this paper, we investigate the exact average-case time complexity of certifying the RIP property for $M\times N$ matrices with i.i.d. $\mathcal{N}(0,1/M)$ entries, in the "possible but hard" regime $\sqrt{M} \ll s\lesssim M/\log N$, assuming that $M$ scales proportional to $N$. Based on analysis of the low-degree likelihood ratio, we give rigorous evidence that subexponential runtime $N^{\tilde\Omega(s^2/N)}$ is required, demonstrating a smooth tradeoff between the maximum tolerated sparsity and the required computational power. The lower bound is essentially tight, matching the runtime of an existing algorithm due to Koiran and Zouzias. Our hardness result allows $\delta$ to take any constant value in $(0,1)$, which captures the relevant regime for compressed sensing. This improves upon the existing average-case hardness result of Wang, Berthet, and Plan, which is limited to $\delta = o(1)$.
Solving Infinite-Domain CSPs Using the Patchwork Property
Jul 03, 2021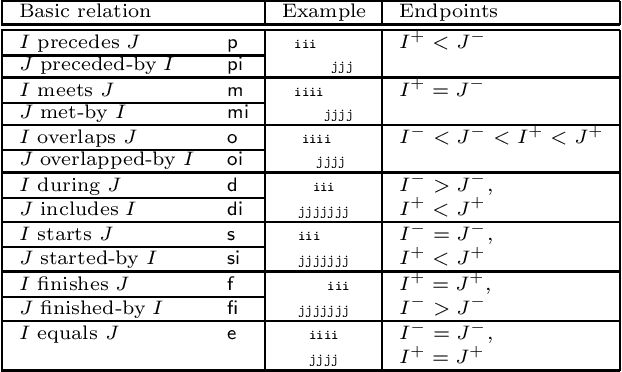
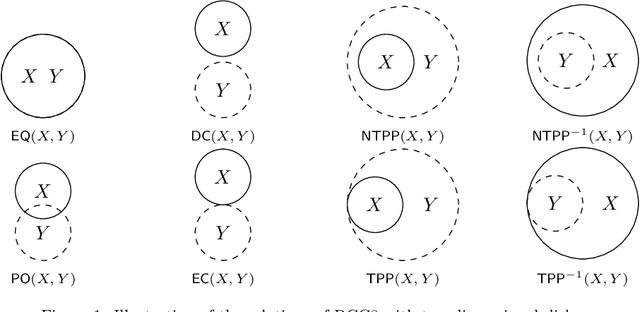
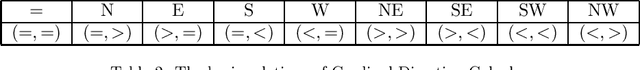
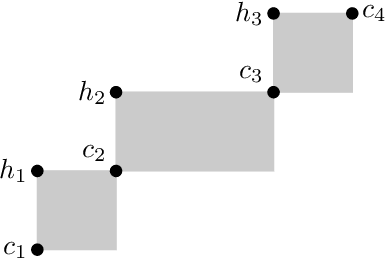
The constraint satisfaction problem (CSP) has important applications in computer science and AI. In particular, infinite-domain CSPs have been intensively used in subareas of AI such as spatio-temporal reasoning. Since constraint satisfaction is a computationally hard problem, much work has been devoted to identifying restricted problems that are efficiently solvable. One way of doing this is to restrict the interactions of variables and constraints, and a highly successful approach is to bound the treewidth of the underlying primal graph. Bodirsky & Dalmau [J. Comput. System. Sci. 79(1), 2013] and Huang et al. [Artif. Intell. 195, 2013] proved that CSP$(\Gamma)$ can be solved in $n^{f(w)}$ time (where $n$ is the size of the instance, $w$ is the treewidth of the primal graph and $f$ is a computable function) for certain classes of constraint languages $\Gamma$. We improve this bound to $f(w) \cdot n^{O(1)}$, where the function $f$ only depends on the language $\Gamma$, for CSPs whose basic relations have the patchwork property. Hence, such problems are fixed-parameter tractable and our algorithm is asymptotically faster than the previous ones. Additionally, our approach is not restricted to binary constraints, so it is applicable to a strictly larger class of problems than that of Huang et al. However, there exist natural problems that are covered by Bodirsky & Dalmau's algorithm but not by ours, and we begin investigating ways of generalising our results to larger families of languages. We also analyse our algorithm with respect to its running time and show that it is optimal (under the Exponential Time Hypothesis) for certain languages such as Allen's Interval Algebra.
Autoregressive-Model-Based Methods for Online Time Series Prediction with Missing Values: an Experimental Evaluation
Aug 27, 2019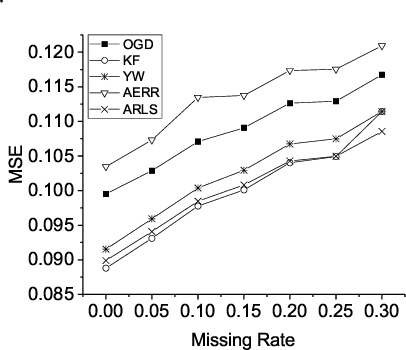
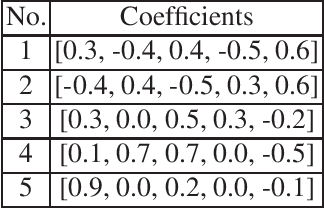
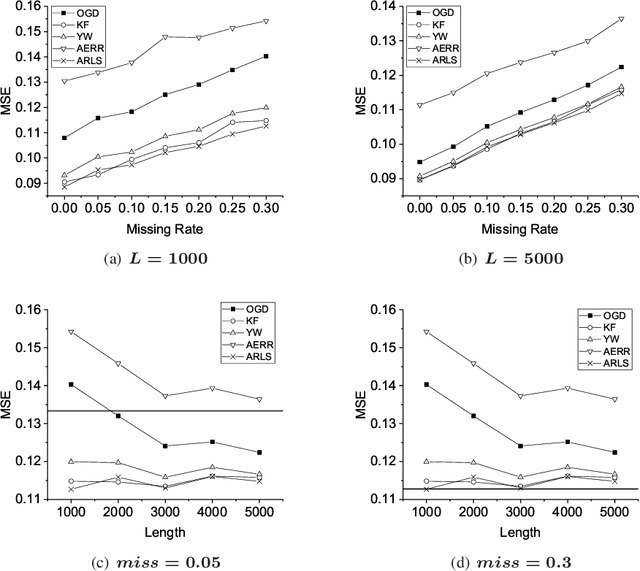
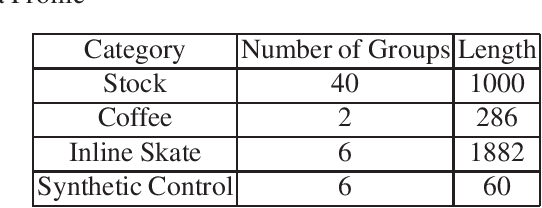
Time series prediction with missing values is an important problem of time series analysis since complete data is usually hard to obtain in many real-world applications. To model the generation of time series, autoregressive (AR) model is a basic and widely used one, which assumes that each observation in the time series is a noisy linear combination of some previous observations along with a constant shift. To tackle the problem of prediction with missing values, a number of methods were proposed based on various data models. For real application scenarios, how do these methods perform over different types of time series with different levels of data missing remains to be investigated. In this paper, we focus on online methods for AR-model-based time series prediction with missing values. We adapted five mainstream methods to fit in such a scenario. We make detailed discussion on each of them by introducing their core ideas about how to estimate the AR coefficients and their different strategies to deal with missing values. We also present algorithmic implementations for better understanding. In order to comprehensively evaluate these methods and do the comparison, we conduct experiments with various configurations of relative parameters over both synthetic and real data. From the experimental results, we derived several noteworthy conclusions and shows that imputation is a simple but reliable strategy to handle missing values in online prediction tasks.
Solving Large Break Minimization Problems in a Mirrored Double Round-robin Tournament Using Quantum Annealing
Oct 18, 2021
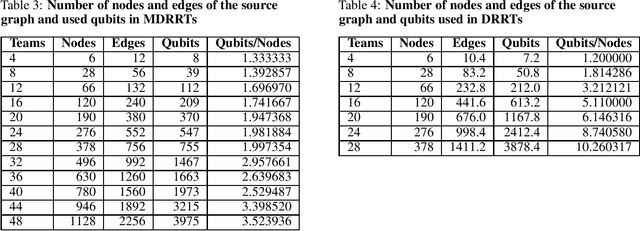
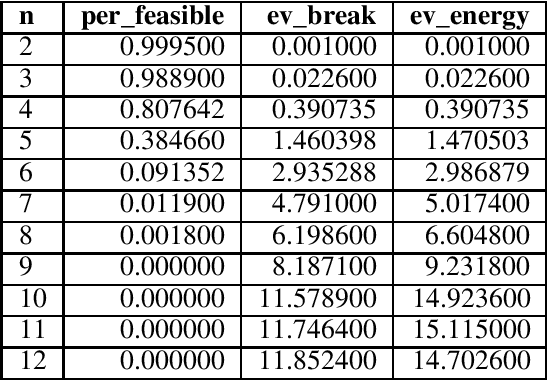
Quantum annealing (QA) has gained considerable attention because it can be applied to combinatorial optimization problems, which have numerous applications in logistics, scheduling, and finance. In recent years, research on solving practical combinatorial optimization problems using them has accelerated. However, researchers struggle to find practical combinatorial optimization problems, for which quantum annealers outperform other mathematical optimization solvers. Moreover, there are only a few studies that compare the performance of quantum annealers with one of the most sophisticated mathematical optimization solvers, such as Gurobi and CPLEX. In our study, we determine that QA demonstrates better performance than the solvers in the break minimization problem in a mirrored double round-robin tournament (MDRRT). We also explain the desirable performance of QA for the sparse interaction between variables and a problem without constraints. In this process, we demonstrate that the break minimization problem in an MDRRT can be expressed as a 4-regular graph. Through computational experiments, we solve this problem using our QA approach and two-integer programming approaches, which were performed using the latest quantum annealer D-Wave Advantage, and the sophisticated mathematical optimization solver, Gurobi, respectively. Further, we compare the quality of the solutions and the computational time. QA was able to determine the exact solution in 0.05 seconds for problems with 20 teams, which is a practical size. In the case of 36 teams, it took 84.8 s for the integer programming method to reach the objective function value, which was obtained by the quantum annealer in 0.05 s. These results not only present the break minimization problem in an MDRRT as an example of applying QA to practical optimization problems, but also contribute to find problems that can be effectively solved by QA.
Permute Me Softly: Learning Soft Permutations for Graph Representations
Oct 05, 2021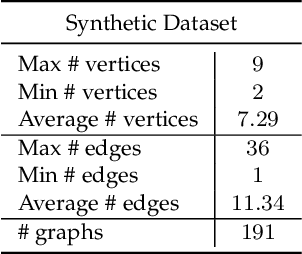
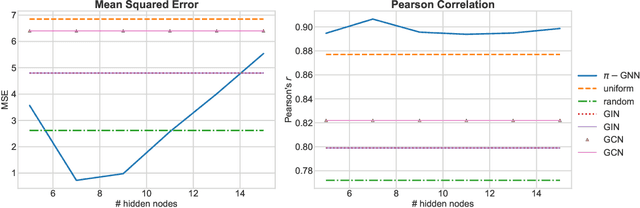
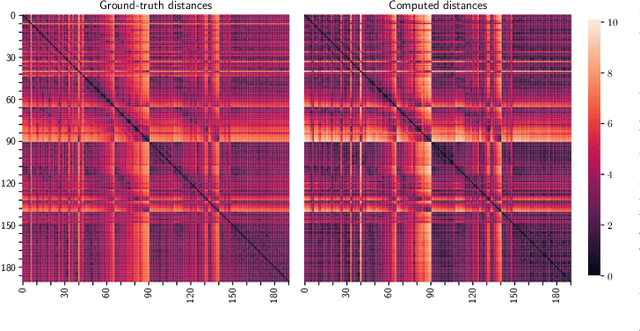
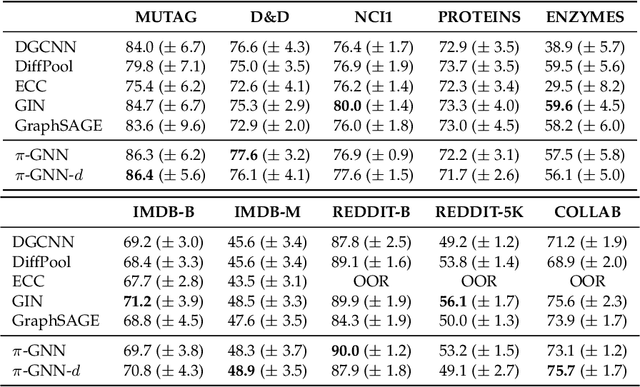
Graph neural networks (GNNs) have recently emerged as a dominant paradigm for machine learning with graphs. Research on GNNs has mainly focused on the family of message passing neural networks (MPNNs). Similar to the Weisfeiler-Leman (WL) test of isomorphism, these models follow an iterative neighborhood aggregation procedure to update vertex representations, and they next compute graph representations by aggregating the representations of the vertices. Although very successful, MPNNs have been studied intensively in the past few years. Thus, there is a need for novel architectures which will allow research in the field to break away from MPNNs. In this paper, we propose a new graph neural network model, so-called $\pi$-GNN which learns a "soft" permutation (i.e., doubly stochastic) matrix for each graph, and thus projects all graphs into a common vector space. The learned matrices impose a "soft" ordering on the vertices of the input graphs, and based on this ordering, the adjacency matrices are mapped into vectors. These vectors can be fed into fully-connected or convolutional layers to deal with supervised learning tasks. In case of large graphs, to make the model more efficient in terms of running time and memory, we further relax the doubly stochastic matrices to row stochastic matrices. We empirically evaluate the model on graph classification and graph regression datasets and show that it achieves performance competitive with state-of-the-art models.
A Time Series Analysis-Based Stock Price Prediction Using Machine Learning and Deep Learning Models
Apr 17, 2020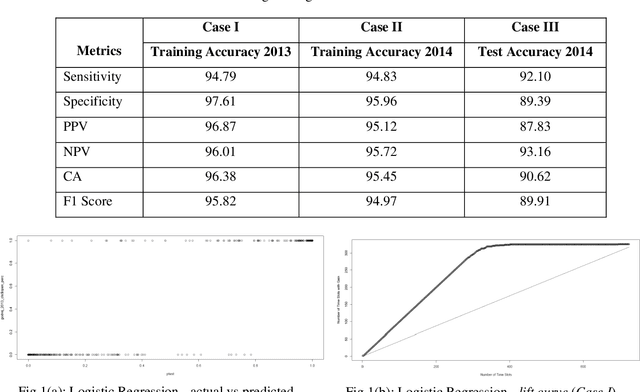
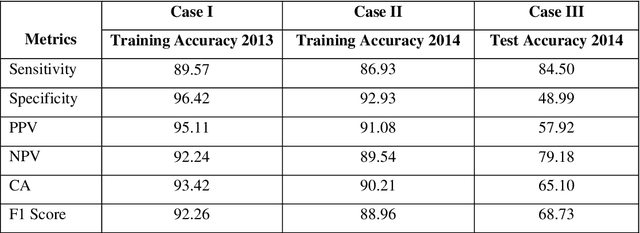
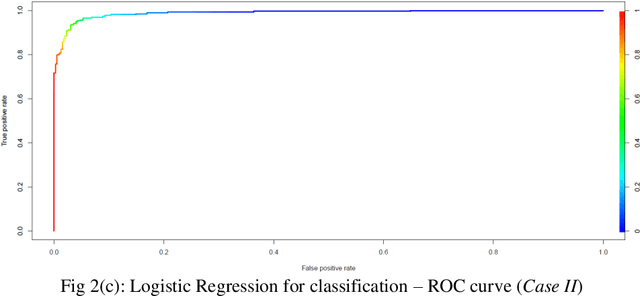
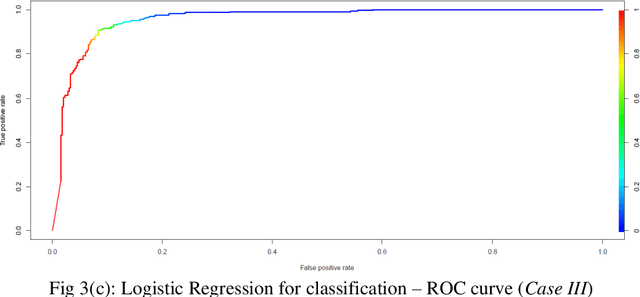
Prediction of future movement of stock prices has always been a challenging task for the researchers. While the advocates of the efficient market hypothesis (EMH) believe that it is impossible to design any predictive framework that can accurately predict the movement of stock prices, there are seminal work in the literature that have clearly demonstrated that the seemingly random movement patterns in the time series of a stock price can be predicted with a high level of accuracy. Design of such predictive models requires choice of appropriate variables, right transformation methods of the variables, and tuning of the parameters of the models. In this work, we present a very robust and accurate framework of stock price prediction that consists of an agglomeration of statistical, machine learning and deep learning models. We use the daily stock price data, collected at five minutes interval of time, of a very well known company that is listed in the National Stock Exchange (NSE) of India. The granular data is aggregated into three slots in a day, and the aggregated data is used for building and training the forecasting models. We contend that the agglomerative approach of model building that uses a combination of statistical, machine learning, and deep learning approaches, can very effectively learn from the volatile and random movement patterns in a stock price data. We build eight classification and eight regression models based on statistical and machine learning approaches. In addition to these models, a deep learning regression model using a long-and-short-term memory (LSTM) network is also built. Extensive results have been presented on the performance of these models, and the results are critically analyzed.
* 46 Pages, 36 Figures, 21 Tables
Multi-modal Affect Analysis using standardized data within subjects in the Wild
Jul 08, 2021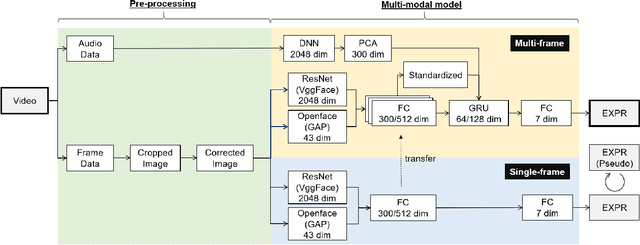


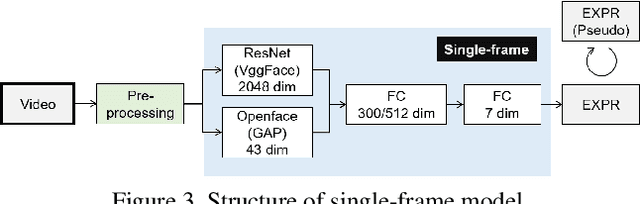
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on facial expression (EXP) and valence-arousal calculation that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest. When annotating facial expressions from a video, we thought that it would be judged not only from the features common to all people, but also from the relative changes in the time series of individuals. Therefore, after learning the common features for each frame, we constructed a facial expression estimation model and valence-arousal model using time-series data after combining the common features and the standardized features for each video. Furthermore, the above features were learned using multi-modal data such as image features, AU, Head pose, and Gaze. In the validation set, our model achieved a facial expression score of 0.546. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.
Adversarial Auto-Encoding for Packet Loss Concealment
Jul 08, 2021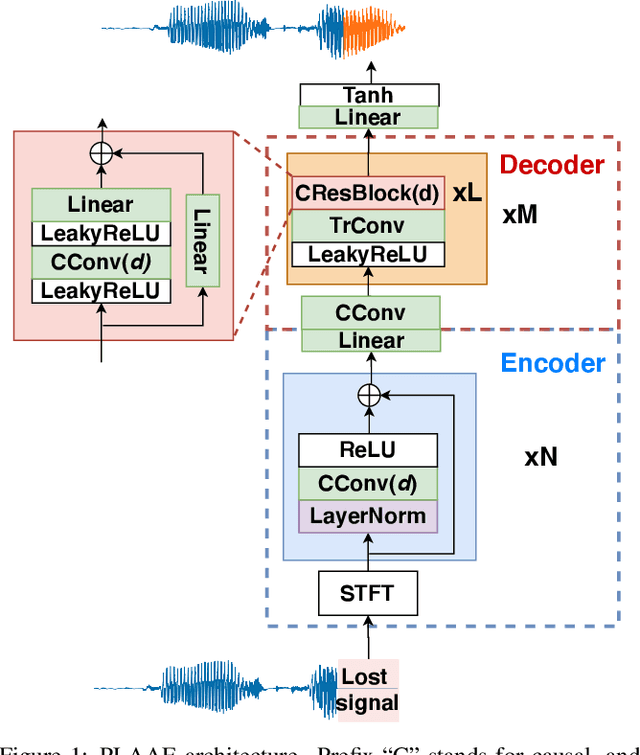
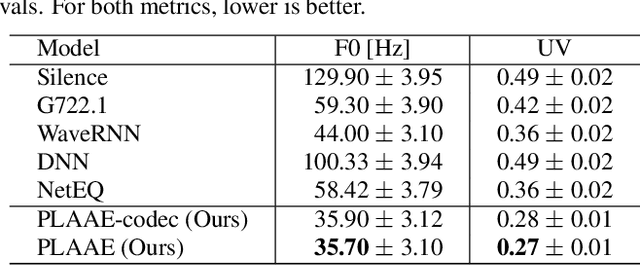
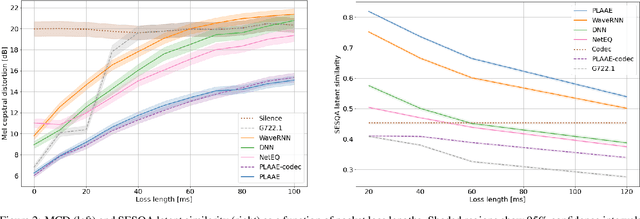
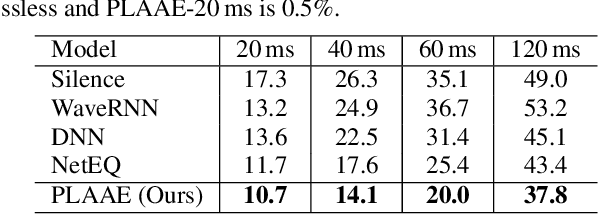
Communication technologies like voice over IP operate under constrained real-time conditions, with voice packets being subject to delays and losses from the network. In such cases, the packet loss concealment (PLC) algorithm reconstructs missing frames until a new real packet is received. Recently, autoregressive deep neural networks have been shown to surpass the quality of signal processing methods for PLC, specially for long-term predictions beyond 60 ms. In this work, we propose a non-autoregressive adversarial auto-encoder, named PLAAE, to perform real-time PLC in the waveform domain. PLAAE has a causal convolutional structure, and it learns in an auto-encoder fashion to reconstruct signals with gaps, with the help of an adversarial loss. During inference, it is able to predict smooth and coherent continuations of such gaps in a single feed-forward step, as opposed to autoregressive models. Our evaluation highlights the superiority of PLAAE over two classic PLCs and two deep autoregressive models in terms of spectral and intonation reconstruction, perceptual quality, and intelligibility.
A Bayesian Approach to (Online) Transfer Learning: Theory and Algorithms
Sep 30, 2021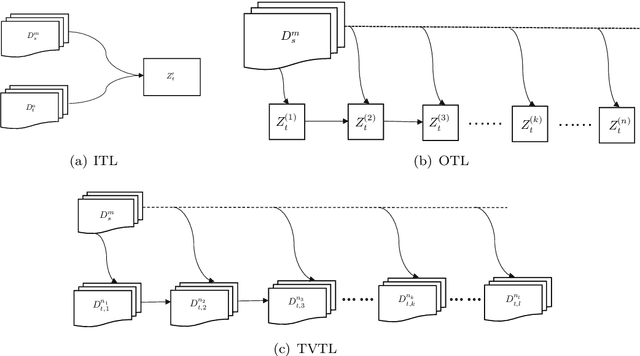

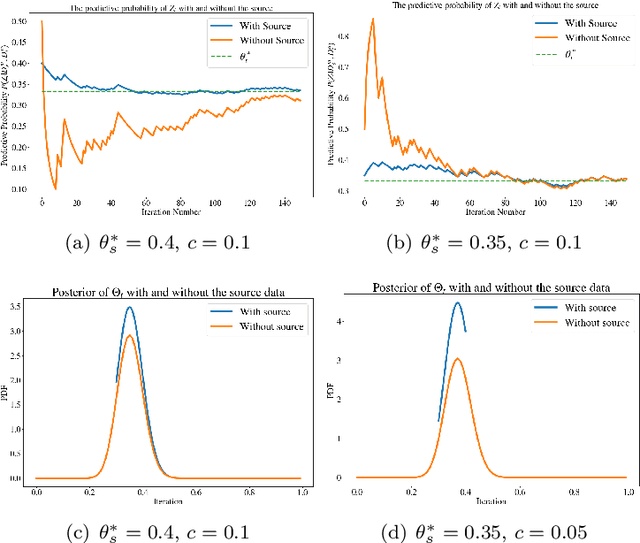
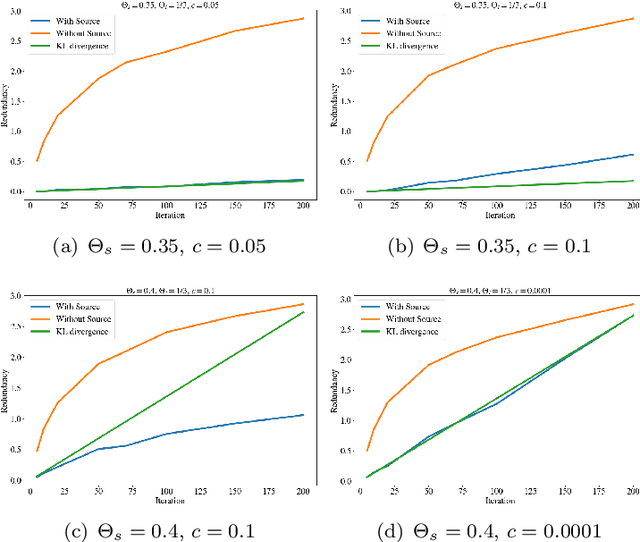
Transfer learning is a machine learning paradigm where knowledge from one problem is utilized to solve a new but related problem. While conceivable that knowledge from one task could be useful for solving a related task, if not executed properly, transfer learning algorithms can impair the learning performance instead of improving it -- commonly known as negative transfer. In this paper, we study transfer learning from a Bayesian perspective, where a parametric statistical model is used. Specifically, we study three variants of transfer learning problems, instantaneous, online, and time-variant transfer learning. For each problem, we define an appropriate objective function, and provide either exact expressions or upper bounds on the learning performance using information-theoretic quantities, which allow simple and explicit characterizations when the sample size becomes large. Furthermore, examples show that the derived bounds are accurate even for small sample sizes. The obtained bounds give valuable insights into the effect of prior knowledge for transfer learning, at least with respect to our Bayesian formulation of the transfer learning problem. In particular, we formally characterize the conditions under which negative transfer occurs. Lastly, we devise two (online) transfer learning algorithms that are amenable to practical implementations, one of which does not require the parametric assumption. We demonstrate the effectiveness of our algorithms with real data sets, focusing primarily on when the source and target data have strong similarities.