 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 14, 2021


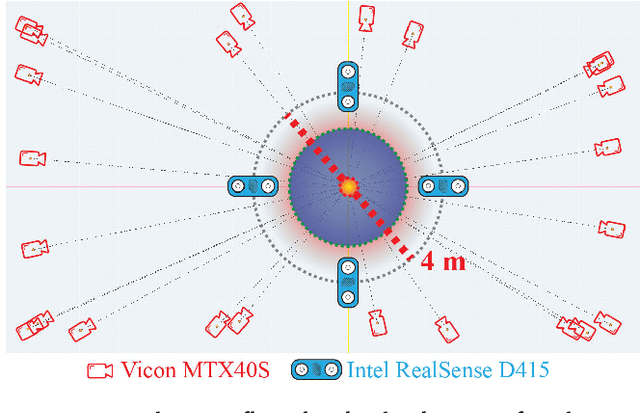
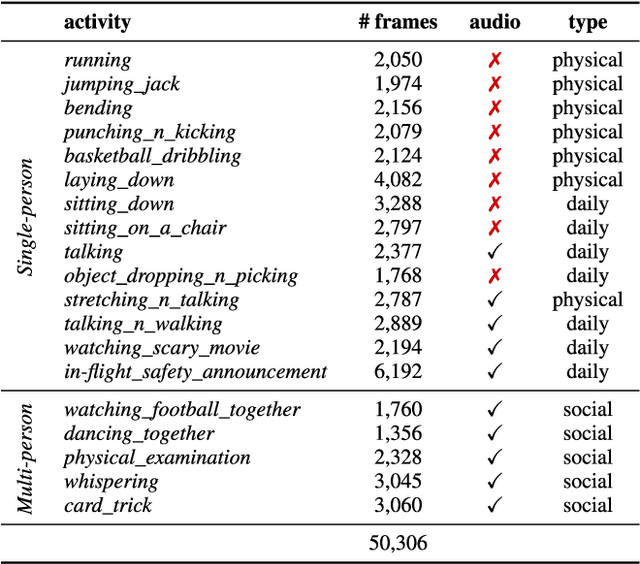
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
LODE: Deep Local Deblurring and A New Benchmark
Sep 19, 2021



While recent deep deblurring algorithms have achieved remarkable progress, most existing methods focus on the global deblurring problem, where the image blur mostly arises from severe camera shake. We argue that the local blur, which is mostly derived from moving objects with a relatively static background, is prevalent but remains under-explored. In this paper, we first lay the data foundation for local deblurring by constructing, for the first time, a LOcal-DEblur (LODE) dataset consisting of 3,700 real-world captured locally blurred images and their corresponding ground-truth. Then, we propose a novel framework, termed BLur-Aware DEblurring network (BladeNet), which contains three components: the Local Blur Synthesis module generates locally blurred training pairs, the Local Blur Perception module automatically captures the locally blurred region and the Blur-guided Spatial Attention module guides the deblurring network with spatial attention. This framework is flexible such that it can be combined with many existing SotA algorithms. We carry out extensive experiments on REDS and LODE datasets showing that BladeNet improves PSNR by 2.5dB over SotAs for local deblurring while keeping comparable performance for global deblurring. We will publish the dataset and codes.
Incentivizing Compliance with Algorithmic Instruments
Jul 21, 2021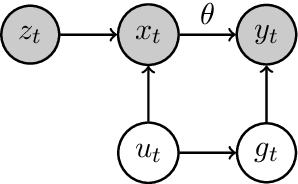
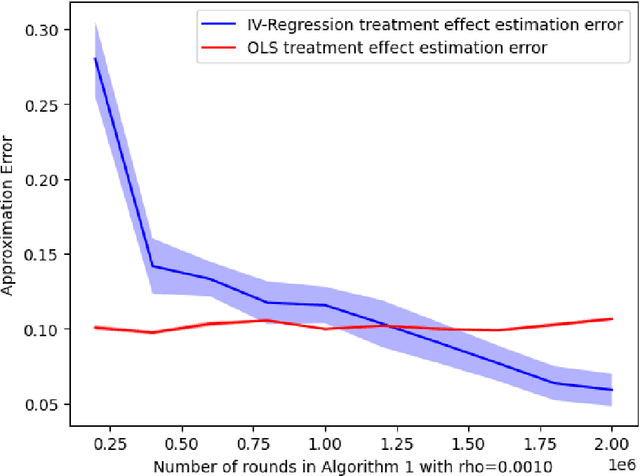
Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history -- the interactions between the planner and the previous agents -- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
A Joint Two-Phase Time-Sensitive Regularized Collaborative Ranking Model for Point of Interest Recommendation
Sep 16, 2019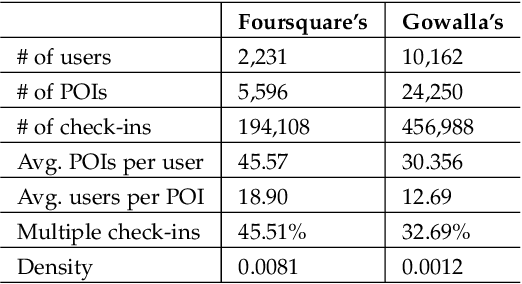
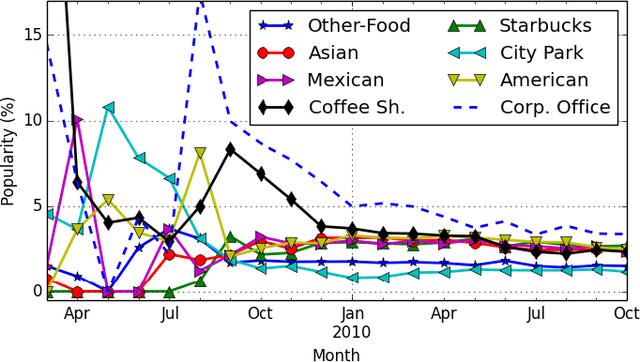
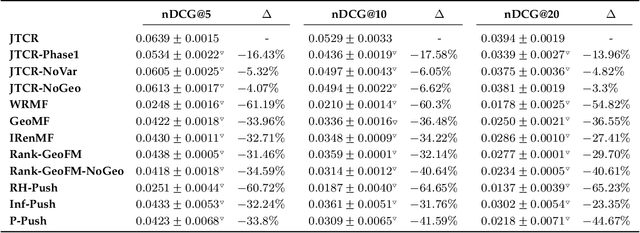
The popularity of location-based social networks (LBSNs) has led to a tremendous amount of user check-in data. Recommending points of interest (POIs) plays a key role in satisfying users' needs in LBSNs. While recent work has explored the idea of adopting collaborative ranking (CR) for recommendation, there have been few attempts to incorporate temporal information for POI recommendation using CR. In this article, we propose a two-phase CR algorithm that incorporates the geographical influence of POIs and is regularized based on the variance of POIs popularity and users' activities over time. The time-sensitive regularizer penalizes user and POIs that have been more time-sensitive in the past, helping the model to account for their long-term behavioral patterns while learning from user-POI interactions. Moreover, in the first phase, it attempts to rank visited POIs higher than the unvisited ones, and at the same time, apply the geographical influence. In the second phase, our algorithm tries to rank users' favorite POIs higher on the recommendation list. Both phases employ a collaborative learning strategy that enables the model to capture complex latent associations from two different perspectives. Experiments on real-world datasets show that our proposed time-sensitive collaborative ranking model beats state-of-the-art POI recommendation methods.
Exploring a Unified Sequence-To-Sequence Transformer for Medical Product Safety Monitoring in Social Media
Sep 13, 2021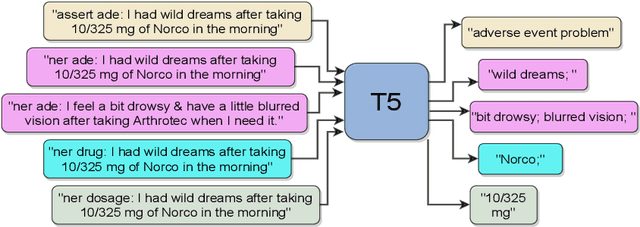

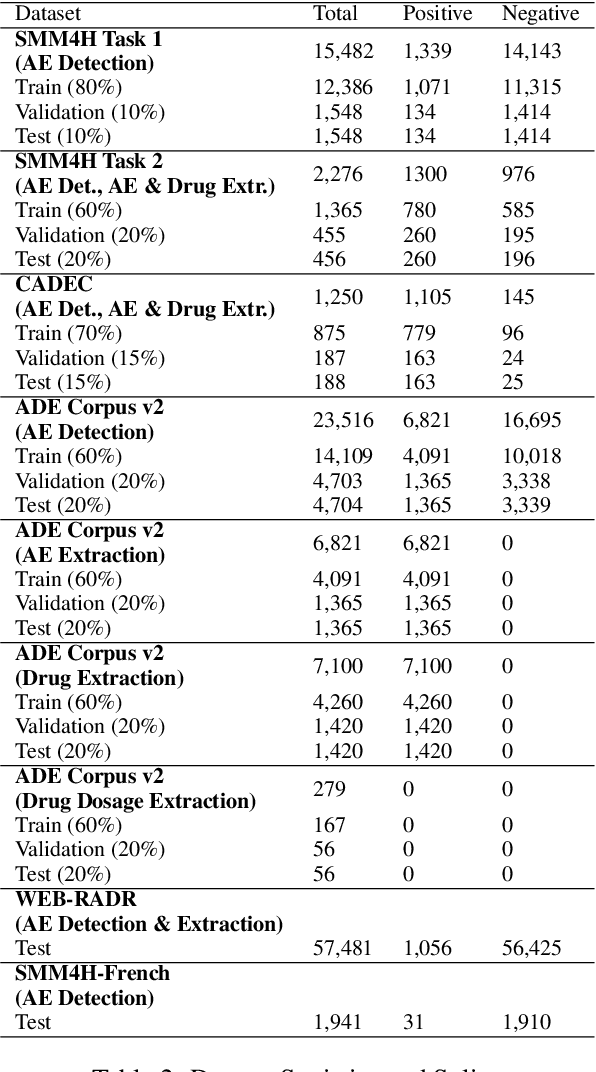
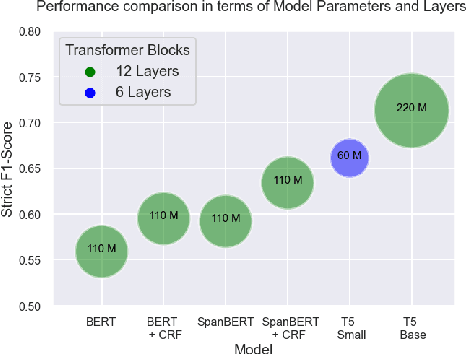
Adverse Events (AE) are harmful events resulting from the use of medical products. Although social media may be crucial for early AE detection, the sheer scale of this data makes it logistically intractable to analyze using human agents, with NLP representing the only low-cost and scalable alternative. In this paper, we frame AE Detection and Extraction as a sequence-to-sequence problem using the T5 model architecture and achieve strong performance improvements over competitive baselines on several English benchmarks (F1 = 0.71, 12.7% relative improvement for AE Detection; Strict F1 = 0.713, 12.4% relative improvement for AE Extraction). Motivated by the strong commonalities between AE-related tasks, the class imbalance in AE benchmarks and the linguistic and structural variety typical of social media posts, we propose a new strategy for multi-task training that accounts, at the same time, for task and dataset characteristics. Our multi-task approach increases model robustness, leading to further performance gains. Finally, our framework shows some language transfer capabilities, obtaining higher performance than Multilingual BERT in zero-shot learning on French data.
Learning to Perform Downlink Channel Estimation in Massive MIMO Systems
Sep 06, 2021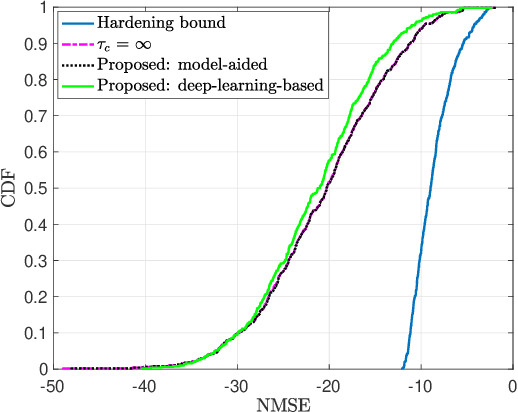
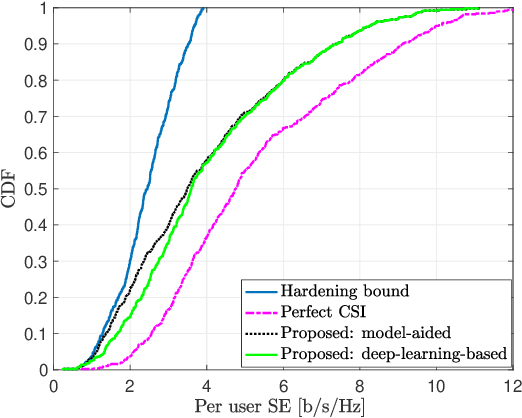
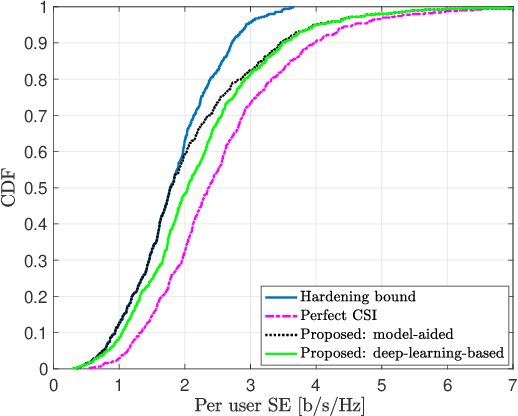

We study downlink (DL) channel estimation in a multi-cell Massive multiple-input multiple-output (MIMO) system operating in a time-division duplex. The users must know their effective channel gains to decode their received DL data signals. A common approach is to use the mean value as the estimate, motivated by channel hardening, but this is associated with a substantial performance loss in non-isotropic scattering environments. We propose two novel estimation methods. The first method is model-aided and utilizes asymptotic arguments to identify a connection between the effective channel gain and the average received power during a coherence block. The second one is a deep-learning-based approach that uses a neural network to identify a mapping between the available information and the effective channel gain. We compare the proposed methods against other benchmarks in terms of normalized mean-squared error and spectral efficiency (SE). The proposed methods provide substantial improvements, with the learning-based solution being the best of the considered estimators.
Causal affect prediction model using a facial image sequence
Jul 08, 2021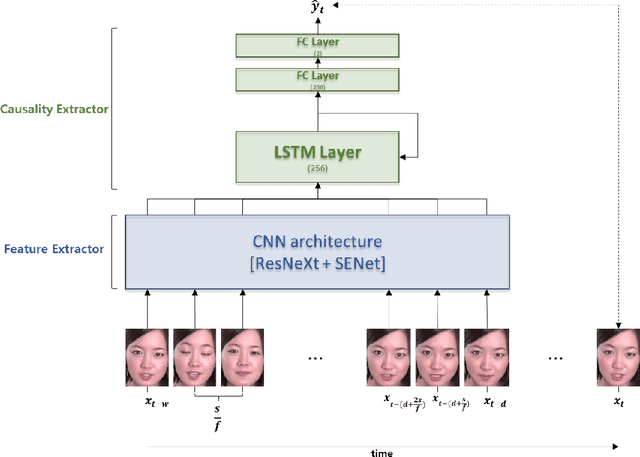
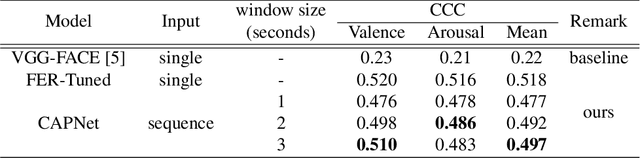
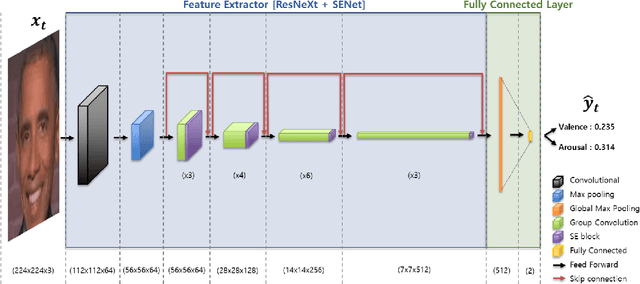
Among human affective behavior research, facial expression recognition research is improving in performance along with the development of deep learning. However, for improved performance, not only past images but also future images should be used along with corresponding facial images, but there are obstacles to the application of this technique to real-time environments. In this paper, we propose the causal affect prediction network (CAPNet), which uses only past facial images to predict corresponding affective valence and arousal. We train CAPNet to learn causal inference between past images and corresponding affective valence and arousal through supervised learning by pairing the sequence of past images with the current label using the Aff-Wild2 dataset. We show through experiments that the well-trained CAPNet outperforms the baseline of the second challenge of the Affective Behavior Analysis in-the-wild (ABAW2) Competition by predicting affective valence and arousal only with past facial images one-third of a second earlier. Therefore, in real-time application, CAPNet can reliably predict affective valence and arousal only with past data.
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 18, 2021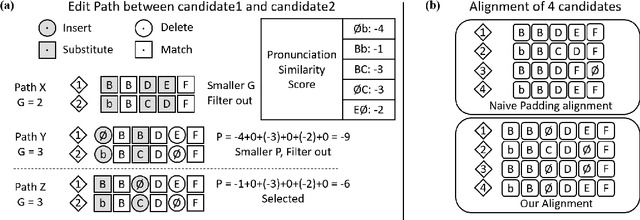
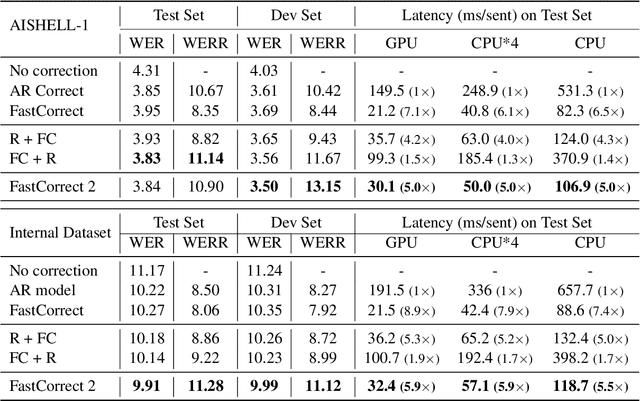
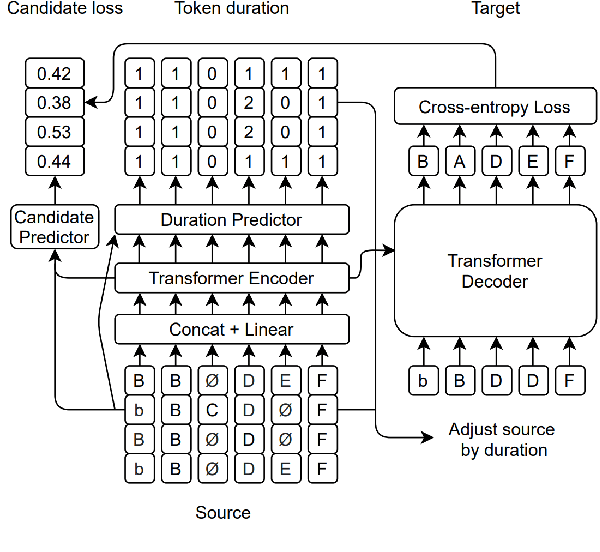
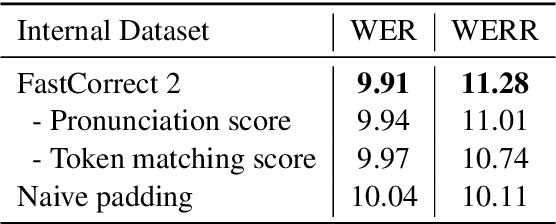
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
An Enhanced Machine Learning Topic Classification Methodology for Cybersecurity
Aug 30, 2021
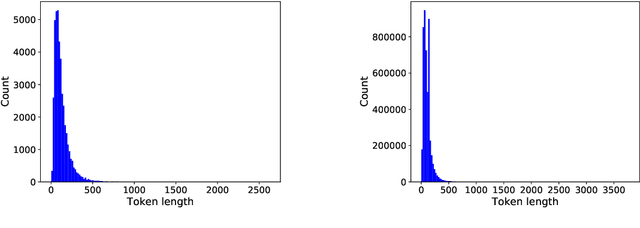
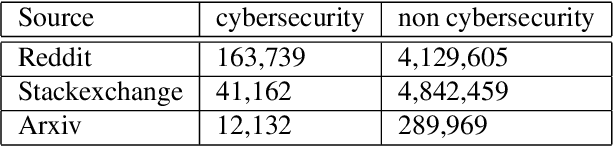
In this research, we use user defined labels from three internet text sources (Reddit, Stackexchange, Arxiv) to train 21 different machine learning models for the topic classification task of detecting cybersecurity discussions in natural text. We analyze the false positive and false negative rates of each of the 21 model's in a cross validation experiment. Then we present a Cybersecurity Topic Classification (CTC) tool, which takes the majority vote of the 21 trained machine learning models as the decision mechanism for detecting cybersecurity related text. We also show that the majority vote mechanism of the CTC tool provides lower false negative and false positive rates on average than any of the 21 individual models. We show that the CTC tool is scalable to the hundreds of thousands of documents with a wall clock time on the order of hours.
Robust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021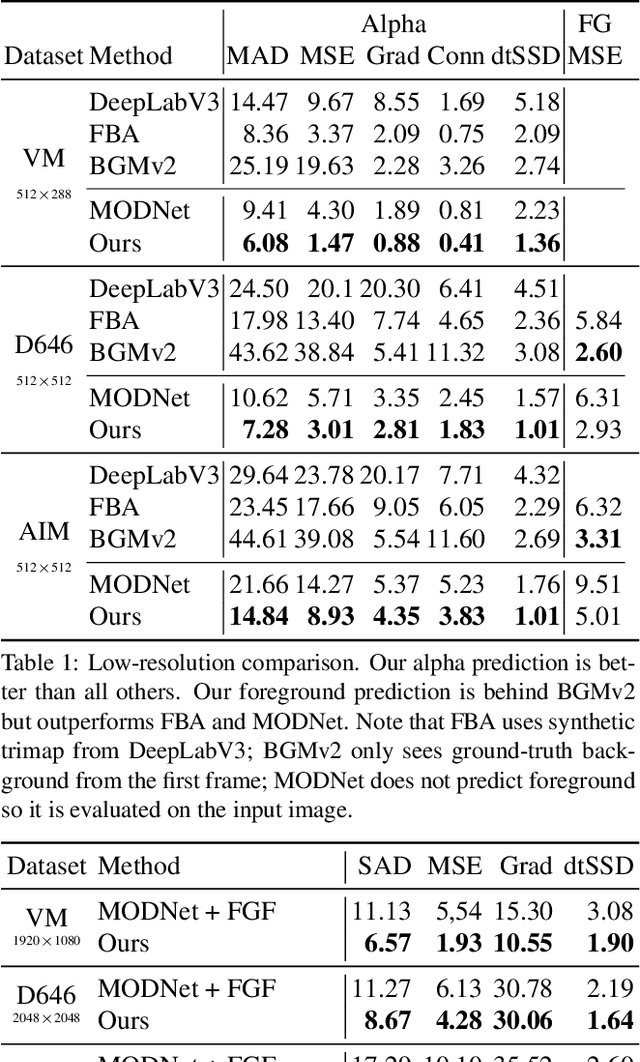
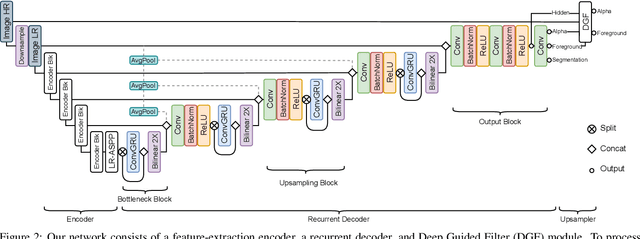
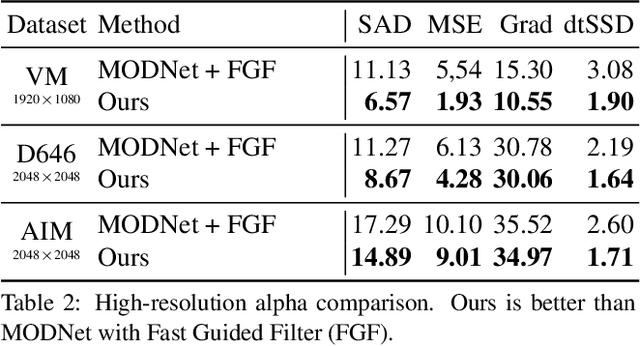
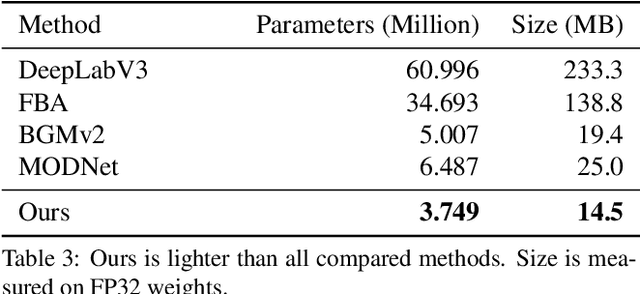
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.