 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An optimised deep spiking neural network architecture without gradients
Sep 27, 2021
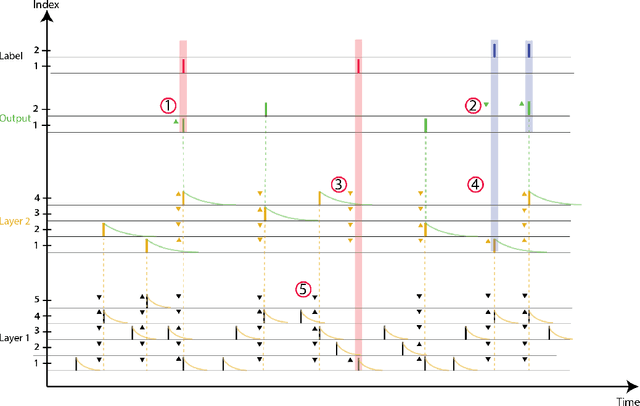
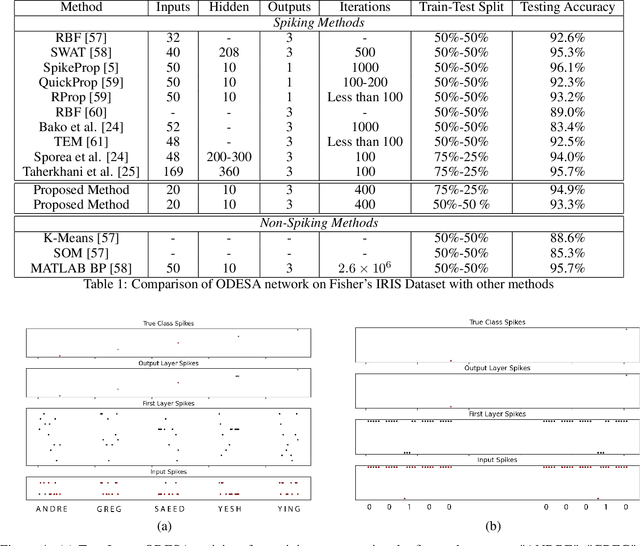
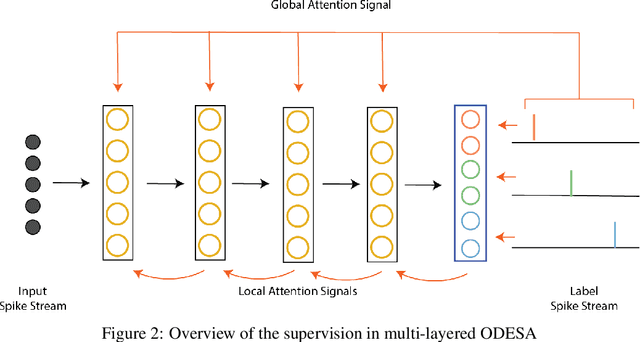
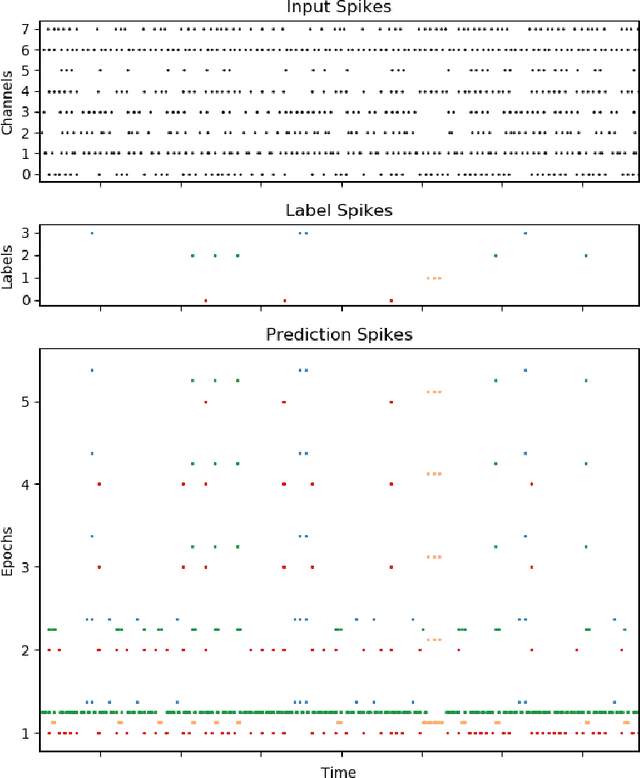
We present an end-to-end trainable modular event-driven neural architecture that uses local synaptic and threshold adaptation rules to perform transformations between arbitrary spatio-temporal spike patterns. The architecture represents a highly abstracted model of existing Spiking Neural Network (SNN) architectures. The proposed Optimized Deep Event-driven Spiking neural network Architecture (ODESA) can simultaneously learn hierarchical spatio-temporal features at multiple arbitrary time scales. ODESA performs online learning without the use of error back-propagation or the calculation of gradients. Through the use of simple local adaptive selection thresholds at each node, the network rapidly learns to appropriately allocate its neuronal resources at each layer for any given problem without using a real-valued error measure. These adaptive selection thresholds are the central feature of ODESA, ensuring network stability and remarkable robustness to noise as well as to the selection of initial system parameters. Network activations are inherently sparse due to a hard Winner-Take-All (WTA) constraint at each layer. We evaluate the architecture on existing spatio-temporal datasets, including the spike-encoded IRIS and TIDIGITS datasets, as well as a novel set of tasks based on International Morse Code that we created. These tests demonstrate the hierarchical spatio-temporal learning capabilities of ODESA. Through these tests, we demonstrate ODESA can optimally solve practical and highly challenging hierarchical spatio-temporal learning tasks with the minimum possible number of computing nodes.
Fast-Slow Streamflow Model Using Mass-Conserving LSTM
Jul 13, 2021

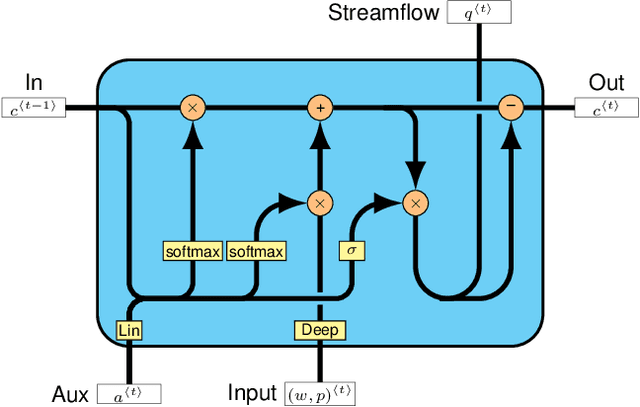
Streamflow forecasting is key to effectively managing water resources and preparing for the occurrence of natural calamities being exacerbated by climate change. Here we use the concept of fast and slow flow components to create a new mass-conserving Long Short-Term Memory (LSTM) neural network model. It uses hydrometeorological time series and catchment attributes to predict daily river discharges. Preliminary results evidence improvement in skills for different scores compared to the recent literature.
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
Jun 22, 2021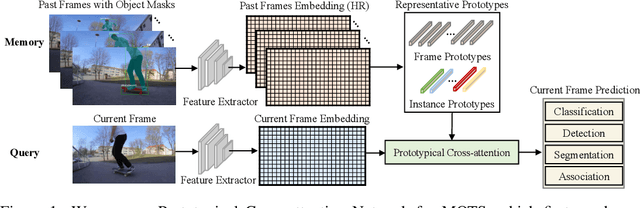
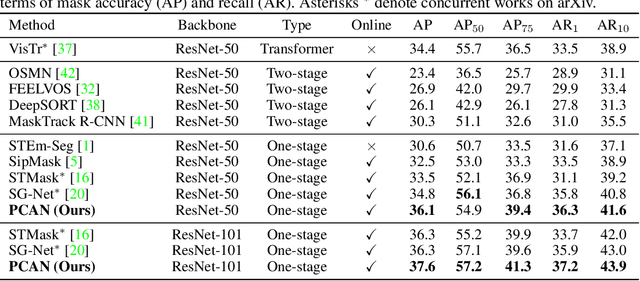
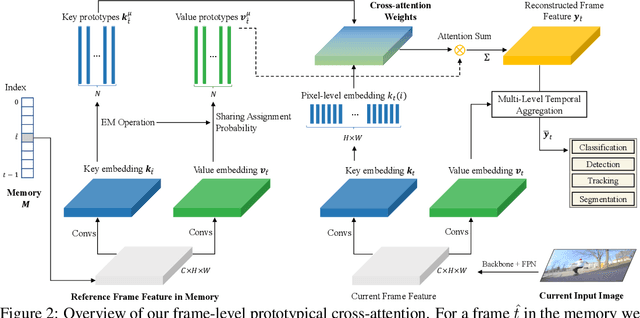

Multiple object tracking and segmentation requires detecting, tracking, and segmenting objects belonging to a set of given classes. Most approaches only exploit the temporal dimension to address the association problem, while relying on single frame predictions for the segmentation mask itself. We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation. PCAN first distills a space-time memory into a set of prototypes and then employs cross-attention to retrieve rich information from the past frames. To segment each object, PCAN adopts a prototypical appearance module to learn a set of contrastive foreground and background prototypes, which are then propagated over time. Extensive experiments demonstrate that PCAN outperforms current video instance tracking and segmentation competition winners on both Youtube-VIS and BDD100K datasets, and shows efficacy to both one-stage and two-stage segmentation frameworks. Code will be available at http://vis.xyz/pub/pcan.
It Takes Two to Tango: Mixup for Deep Metric Learning
Jun 09, 2021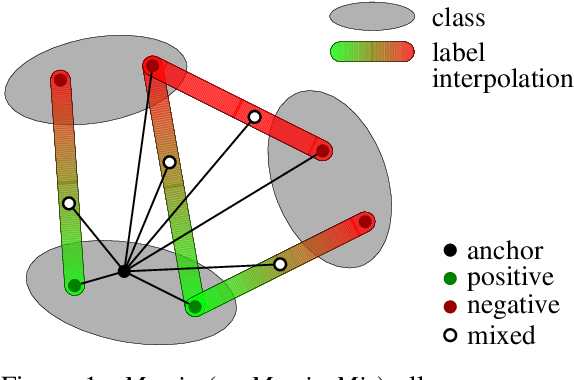

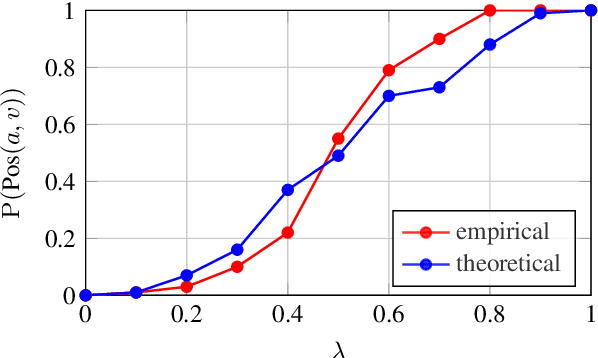
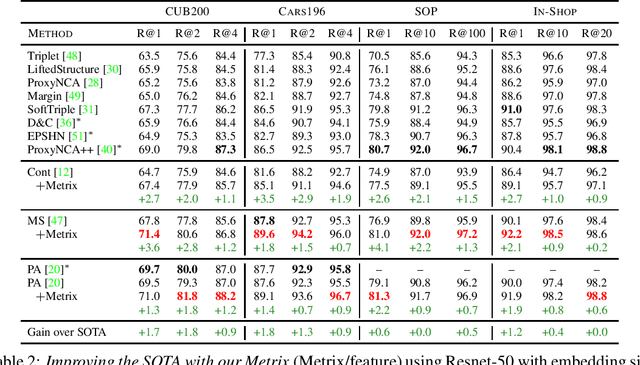
Metric learning involves learning a discriminative representation such that embeddings of similar classes are encouraged to be close, while embeddings of dissimilar classes are pushed far apart. State-of-the-art methods focus mostly on sophisticated loss functions or mining strategies. On the one hand, metric learning losses consider two or more examples at a time. On the other hand, modern data augmentation methods for classification consider two or more examples at a time. The combination of the two ideas is under-studied. In this work, we aim to bridge this gap and improve representations using mixup, which is a powerful data augmentation approach interpolating two or more examples and corresponding target labels at a time. This task is challenging because, unlike classification, the loss functions used in metric learning are not additive over examples, so the idea of interpolating target labels is not straightforward. To the best of our knowledge, we are the first to investigate mixing examples and target labels for deep metric learning. We develop a generalized formulation that encompasses existing metric learning loss functions and modify it to accommodate for mixup, introducing Metric Mix, or Metrix. We show that mixing inputs, intermediate representations or embeddings along with target labels significantly improves representations and outperforms state-of-the-art metric learning methods on four benchmark datasets.
The Adaptive Multi-Factor Model and the Financial Market
Jul 30, 2021

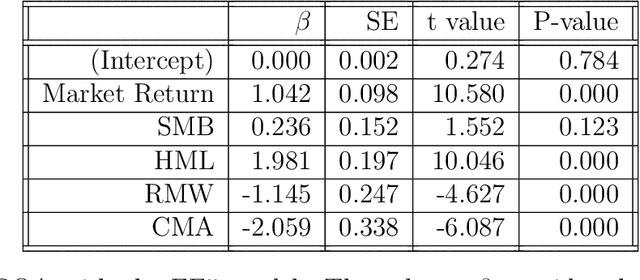
Modern evolvements of the technologies have been leading to a profound influence on the financial market. The introduction of constituents like Exchange-Traded Funds, and the wide-use of advanced technologies such as algorithmic trading, results in a boom of the data which provides more opportunities to reveal deeper insights. However, traditional statistical methods always suffer from the high-dimensional, high-correlation, and time-varying instinct of the financial data. In this dissertation, we focus on developing techniques to stress these difficulties. With the proposed methodologies, we can have more interpretable models, clearer explanations, and better predictions.
* PhD dissertation
A new CP-approach for a parallel machine scheduling problem with time constraints on machine qualifications
Oct 16, 2019


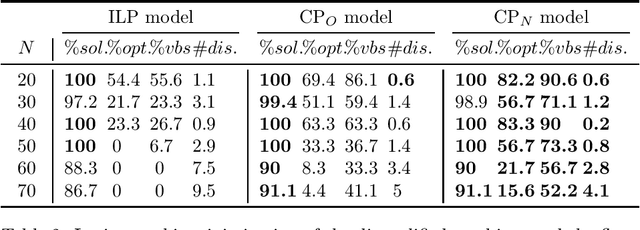
This paper considers the scheduling of job families on parallel machines with time constraints on machine qualifications. In this problem, each job belongs to a family and a family can only be executed on a subset of qualified machines. In addition, machines can lose their qualifications during the schedule. Indeed, if no job of a family is scheduled on a machine during a given amount of time, the machine loses its qualification for this family. The goal is to minimize the sum of job completion times, i.e. the flow time, while maximizing the number of qualifications at the end of the schedule. The paper presents a new Constraint Programming (CP) model taking more advantages of the CP feature to model machine disqualifications. This model is compared with two existing models: an Integer Linear Programming (ILP) model and a Constraint Programming model. The experiments show that the new CP model outperforms the other model when the priority is given to the number of disqualifications objective. Furthermore, it is competitive with the other model when the flow time objective is prioritized.
The Impact of Negative Sampling on Contrastive Structured World Models
Jul 24, 2021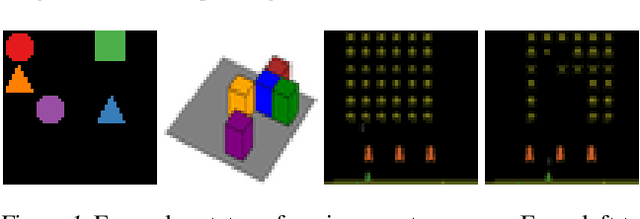
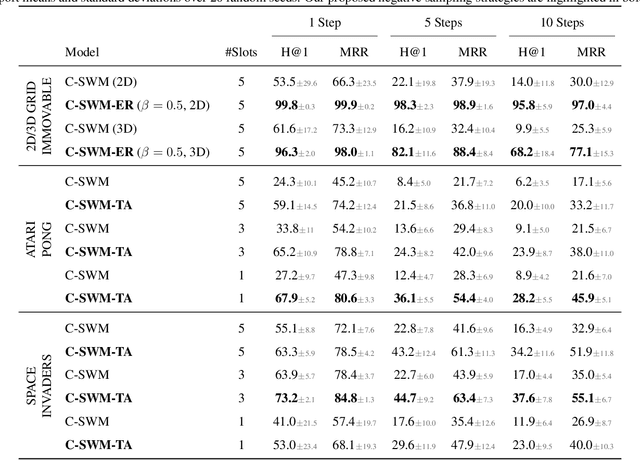

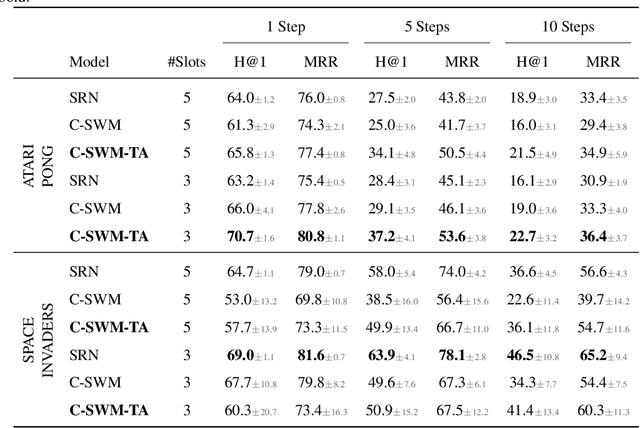
World models trained by contrastive learning are a compelling alternative to autoencoder-based world models, which learn by reconstructing pixel states. In this paper, we describe three cases where small changes in how we sample negative states in the contrastive loss lead to drastic changes in model performance. In previously studied Atari datasets, we show that leveraging time step correlations can double the performance of the Contrastive Structured World Model. We also collect a full version of the datasets to study contrastive learning under a more diverse set of experiences.
Designing a Robust Carrier Frequency Offset Estimation Scheme for Meeting Target Decoding Performance in an OFDM System
Jul 19, 2021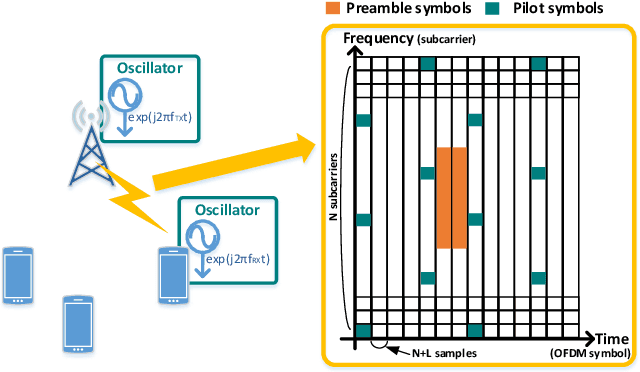
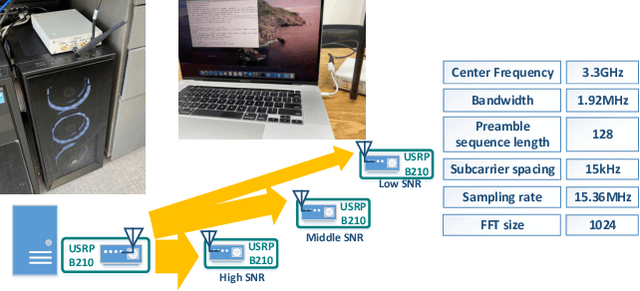
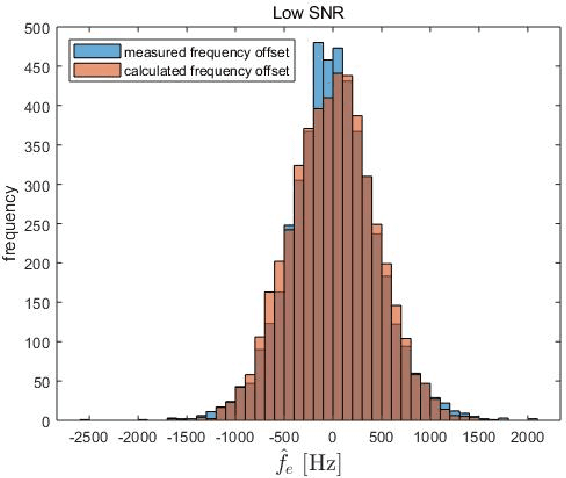
In a target communication system, a delicately designed frequency offset estimation scheme is required to meet certain decoding performance. In this paper, we proposed at wo-step estimation scheme, coarse and residual, with different value of an time interval parameter. A result of RF conduction test shows that the proposed method has an 1dB gain of SNR compared to coarse-only estimator. A result of the commercial test also indicates the proposed method outperforms coarse-only estimator especially in low SNR condition.
Understanding Longitudinal Dynamics of Recommender Systems with Agent-Based Modeling and Simulation
Aug 25, 2021Today's research in recommender systems is largely based on experimental designs that are static in a sense that they do not consider potential longitudinal effects of providing recommendations to users. In reality, however, various important and interesting phenomena only emerge or become visible over time, e.g., when a recommender system continuously reinforces the popularity of already successful artists on a music streaming site or when recommendations that aim at profit maximization lead to a loss of consumer trust in the long run. In this paper, we discuss how Agent-Based Modeling and Simulation (ABM) techniques can be used to study such important longitudinal dynamics of recommender systems. To that purpose, we provide an overview of the ABM principles, outline a simulation framework for recommender systems based on the literature, and discuss various practical research questions that can be addressed with such an ABM-based simulation framework.
Sparse Factorization of Large Square Matrices
Sep 16, 2021
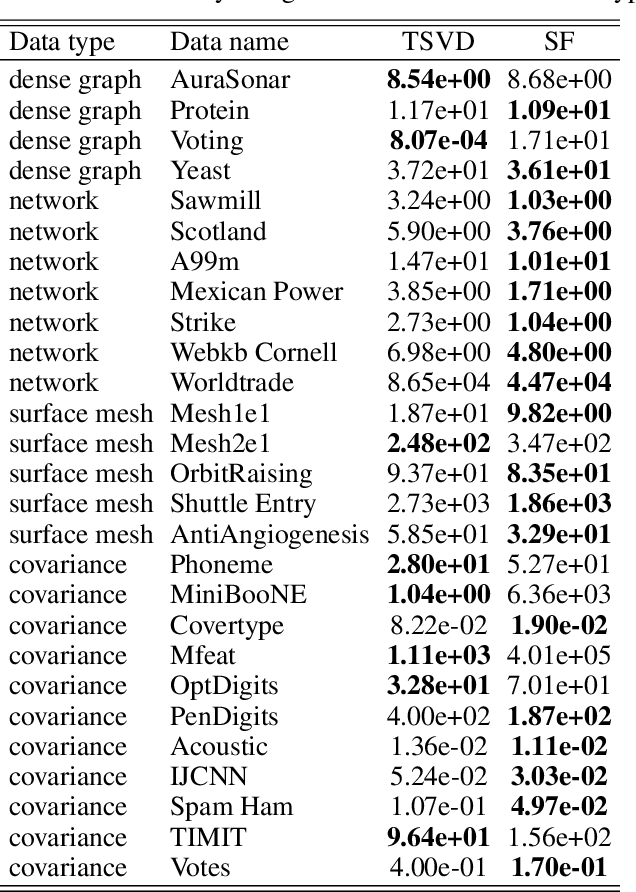
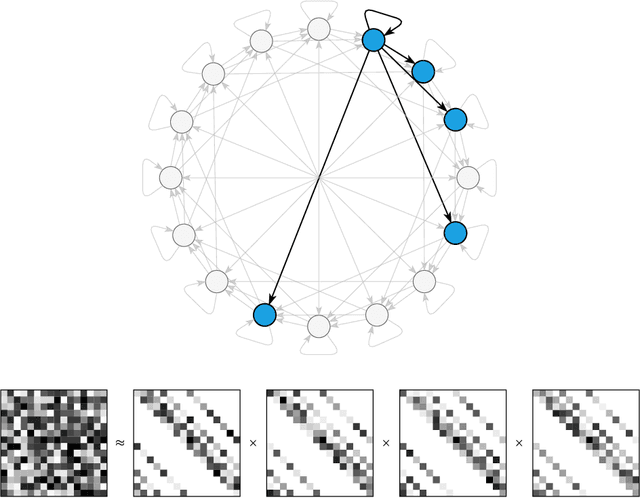
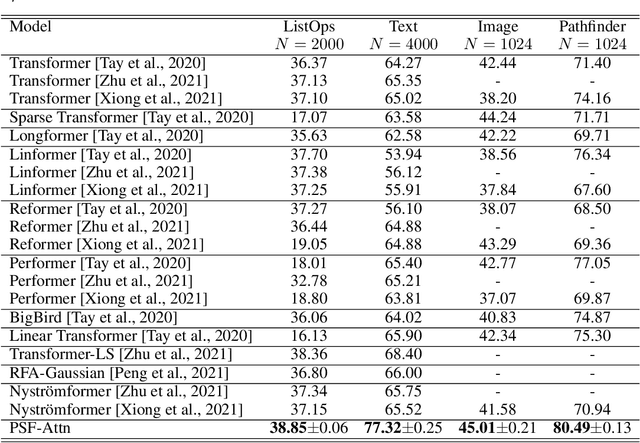
Square matrices appear in many machine learning problems and models. Optimization over a large square matrix is expensive in memory and in time. Therefore an economic approximation is needed. Conventional approximation approaches factorize the square matrix into a number matrices of much lower ranks. However, the low-rank constraint is a performance bottleneck if the approximated matrix is intrinsically high-rank or close to full rank. In this paper, we propose to approximate a large square matrix with a product of sparse full-rank matrices. In the approximation, our method needs only $N(\log N)^2$ non-zero numbers for an $N\times N$ full matrix. We present both non-parametric and parametric ways to find the factorization. In the former, we learn the factorizing matrices directly, and in the latter, we train neural networks to map input data to the non-zero matrix entries. The sparse factorization method is tested for a variety of synthetic and real-world square matrices. The experimental results demonstrate that our method gives a better approximation when the approximated matrix is sparse and high-rank. Based on this finding, we use our parametric method as a scalable attention architecture that performs strongly in learning tasks for long sequential data and defeats Transformer and its several variants.