 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Team Power and Hierarchy: Understanding Team Success
Aug 09, 2021
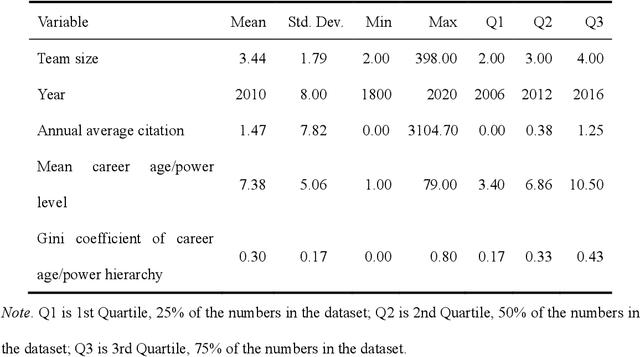
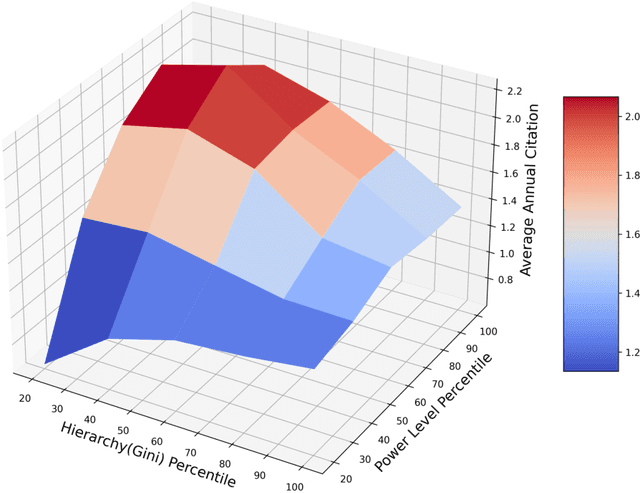
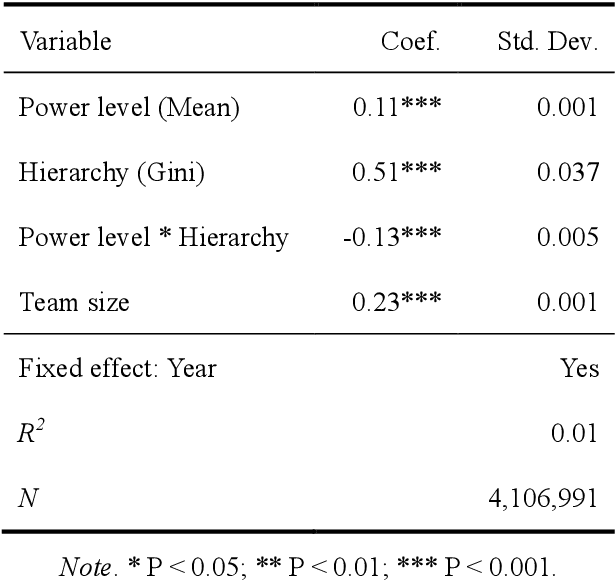
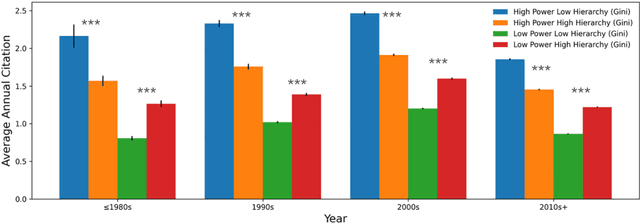
Teamwork is cooperative, participative and power sharing. In science of science, few studies have looked at the impact of team collaboration from the perspective of team power and hierarchy. This research examines in depth the relationships between team power and team success in the field of Computer Science (CS) using the DBLP dataset. Team power and hierarchy are measured using academic age and team success is quantified by citation. By analyzing 4,106,995 CS teams, we find that high power teams with flat structure have the best performance. On the contrary, low-power teams with hierarchical structure is a facilitator of team performance. These results are consistent across different time periods and team sizes.
Neural Symbolic Regression that Scales
Jun 11, 2021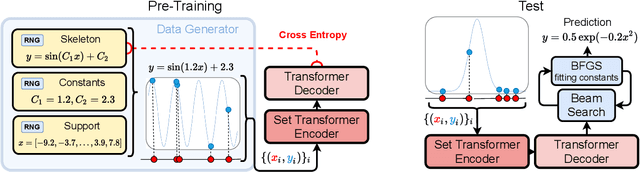
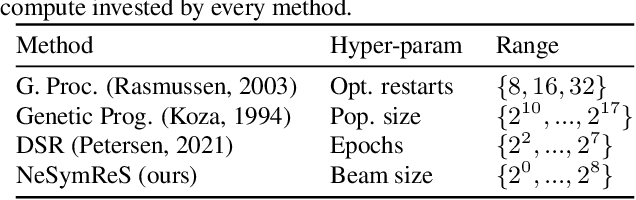
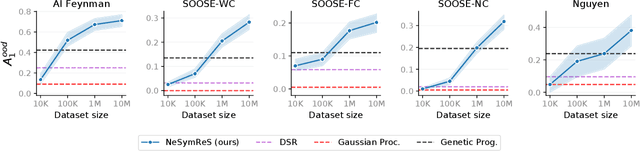
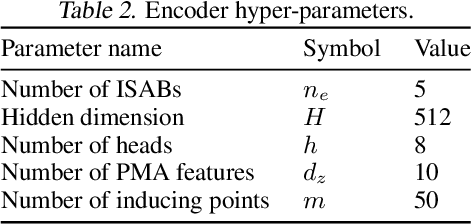
Symbolic equations are at the core of scientific discovery. The task of discovering the underlying equation from a set of input-output pairs is called symbolic regression. Traditionally, symbolic regression methods use hand-designed strategies that do not improve with experience. In this paper, we introduce the first symbolic regression method that leverages large scale pre-training. We procedurally generate an unbounded set of equations, and simultaneously pre-train a Transformer to predict the symbolic equation from a corresponding set of input-output-pairs. At test time, we query the model on a new set of points and use its output to guide the search for the equation. We show empirically that this approach can re-discover a set of well-known physical equations, and that it improves over time with more data and compute.
Decoupling Magnitude and Phase Estimation with Deep ResUNet for Music Source Separation
Sep 12, 2021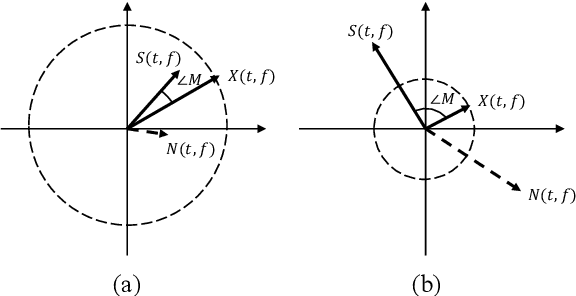
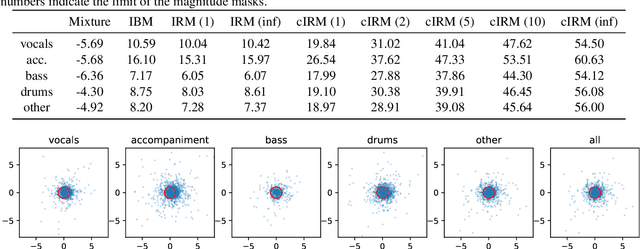
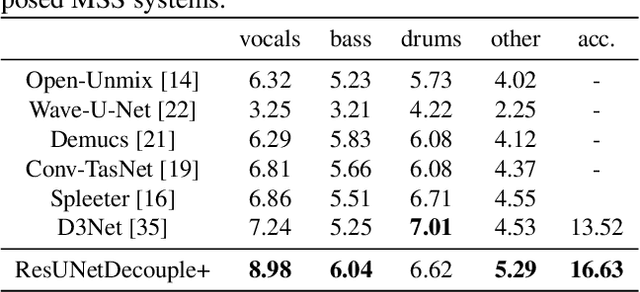
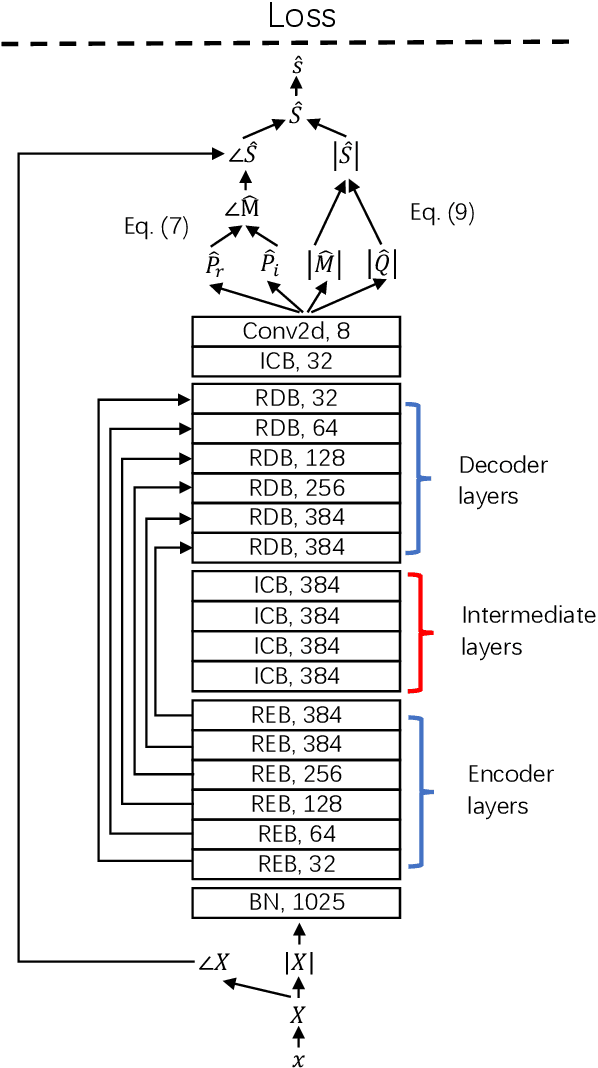
Deep neural network based methods have been successfully applied to music source separation. They typically learn a mapping from a mixture spectrogram to a set of source spectrograms, all with magnitudes only. This approach has several limitations: 1) its incorrect phase reconstruction degrades the performance, 2) it limits the magnitude of masks between 0 and 1 while we observe that 22% of time-frequency bins have ideal ratio mask values of over~1 in a popular dataset, MUSDB18, 3) its potential on very deep architectures is under-explored. Our proposed system is designed to overcome these. First, we propose to estimate phases by estimating complex ideal ratio masks (cIRMs) where we decouple the estimation of cIRMs into magnitude and phase estimations. Second, we extend the separation method to effectively allow the magnitude of the mask to be larger than 1. Finally, we propose a residual UNet architecture with up to 143 layers. Our proposed system achieves a state-of-the-art MSS result on the MUSDB18 dataset, especially, a SDR of 8.98~dB on vocals, outperforming the previous best performance of 7.24~dB. The source code is available at: https://github.com/bytedance/music_source_separation
* 6 pages
Learning stable reduced-order models for hybrid twins
Jun 07, 2021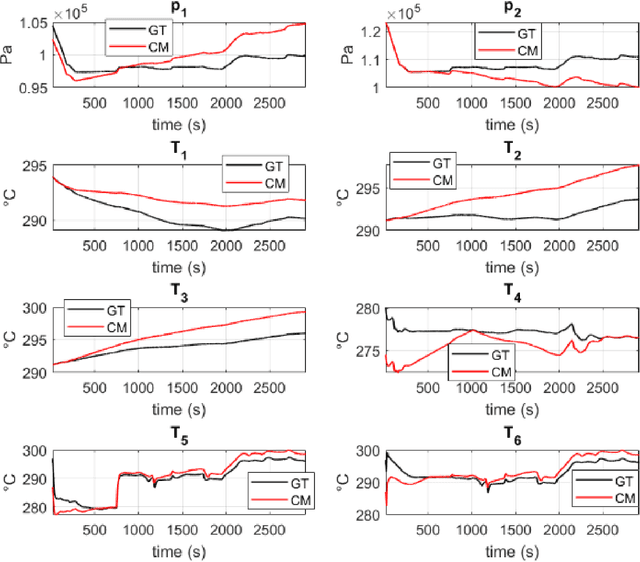
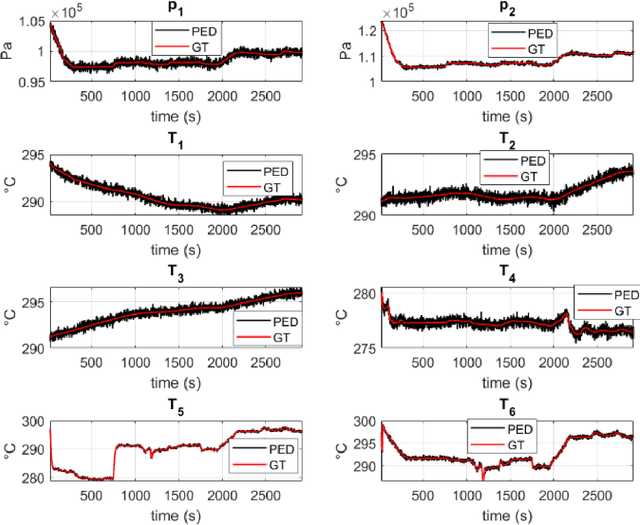
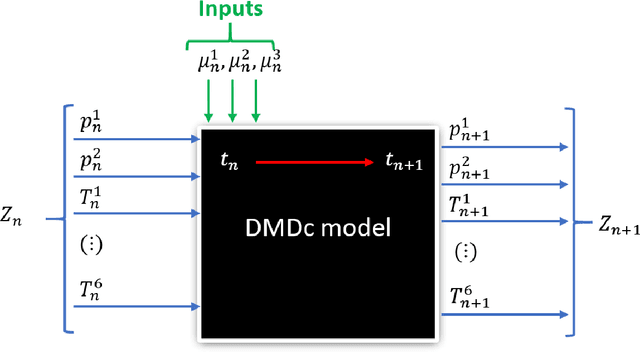
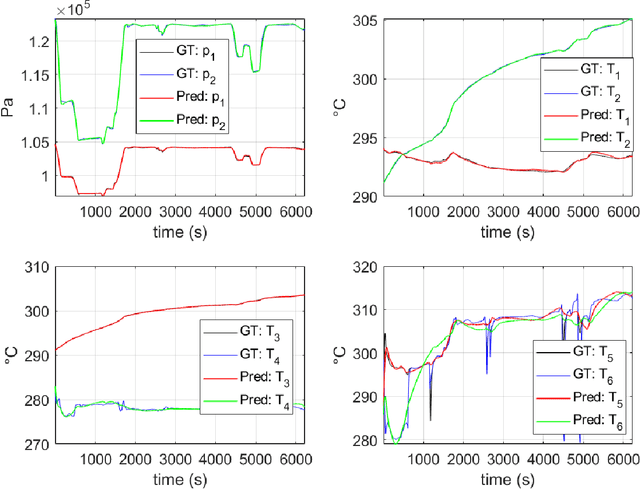
The concept of Hybrid Twin (HT) has recently received a growing interest thanks to the availability of powerful machine learning techniques. This twin concept combines physics-based models within a model-order reduction framework-to obtain real-time feedback rates-and data science. Thus, the main idea of the HT is to develop on-the-fly data-driven models to correct possible deviations between measurements and physics-based model predictions. This paper is focused on the computation of stable, fast and accurate corrections in the Hybrid Twin framework. Furthermore, regarding the delicate and important problem of stability, a new approach is proposed, introducing several sub-variants and guaranteeing a low computational cost as well as the achievement of a stable time-integration.
FastMVAE2: On improving and accelerating the fast variational autoencoder-based source separation algorithm for determined mixtures
Sep 28, 2021
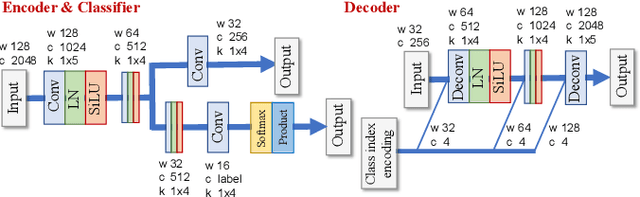
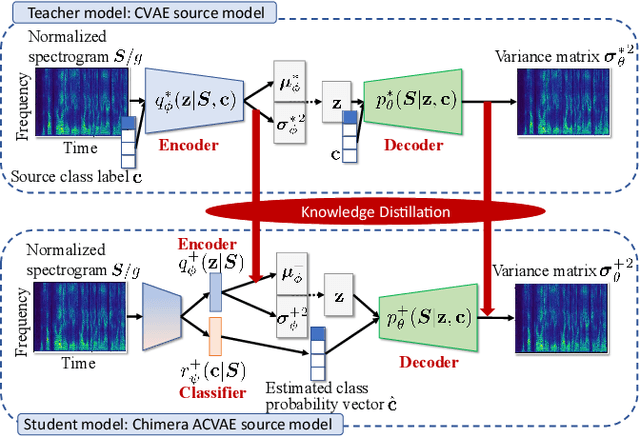
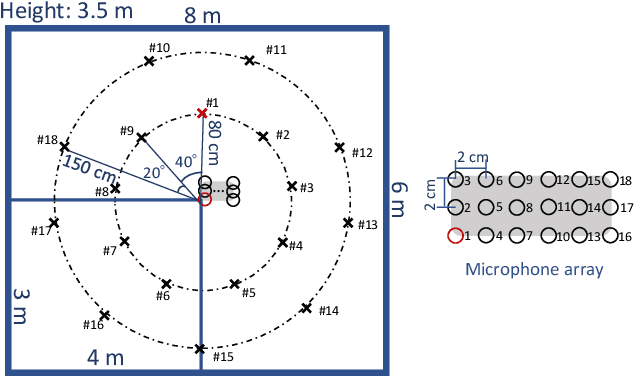
This paper proposes a new source model and training scheme to improve the accuracy and speed of the multichannel variational autoencoder (MVAE) method. The MVAE method is a recently proposed powerful multichannel source separation method. It consists of pretraining a source model represented by a conditional VAE (CVAE) and then estimating separation matrices along with other unknown parameters so that the log-likelihood is non-decreasing given an observed mixture signal. Although the MVAE method has been shown to provide high source separation performance, one drawback is the computational cost of the backpropagation steps in the separation-matrix estimation algorithm. To overcome this drawback, a method called "FastMVAE" was subsequently proposed, which uses an auxiliary classifier VAE (ACVAE) to train the source model. By using the classifier and encoder trained in this way, the optimal parameters of the source model can be inferred efficiently, albeit approximately, in each step of the algorithm. However, the generalization capability of the trained ACVAE source model was not satisfactory, which led to poor performance in situations with unseen data. To improve the generalization capability, this paper proposes a new model architecture (called the "ChimeraACVAE" model) and a training scheme based on knowledge distillation. The experimental results revealed that the proposed source model trained with the proposed loss function achieved better source separation performance with less computation time than FastMVAE. We also confirmed that our methods were able to separate 18 sources with a reasonably good accuracy.
Application of Video-to-Video Translation Networks to Computational Fluid Dynamics
Sep 12, 2021
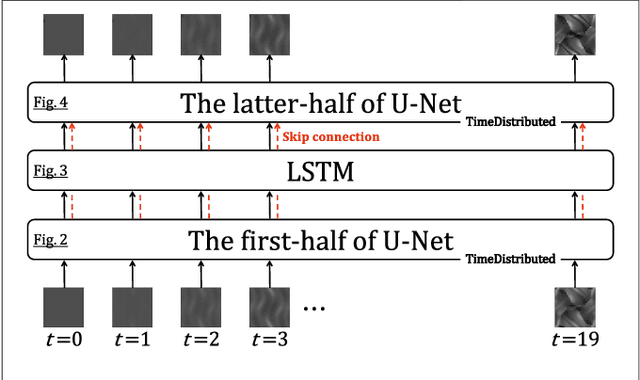
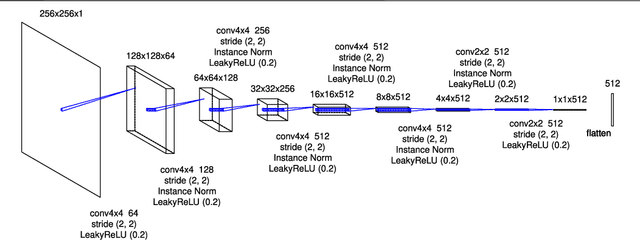

In recent years, the evolution of artificial intelligence, especially deep learning, has been remarkable, and its application to various fields has been growing rapidly. In this paper, I report the results of the application of generative adversarial networks (GANs), specifically video-to-video translation networks, to computational fluid dynamics (CFD) simulations. The purpose of this research is to reduce the computational cost of CFD simulations with GANs. The architecture of GANs in this research is a combination of the image-to-image translation networks (the so-called "pix2pix") and Long Short-Term Memory (LSTM). It is shown that the results of high-cost and high-accuracy simulations (with high-resolution computational grids) can be estimated from those of low-cost and low-accuracy simulations (with low-resolution grids). In particular, the time evolution of density distributions in the cases of a high-resolution grid is reproduced from that in the cases of a low-resolution grid through GANs, and the density inhomogeneity estimated from the image generated by GANs recovers the ground truth with good accuracy. Qualitative and quantitative comparisons of the results of the proposed method with those of several super-resolution algorithms are also presented.
Assessing the Causal Impact of COVID-19 Related Policies on Outbreak Dynamics: A Case Study in the US
May 29, 2021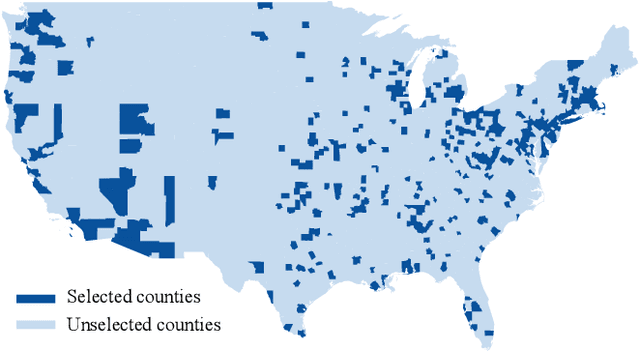

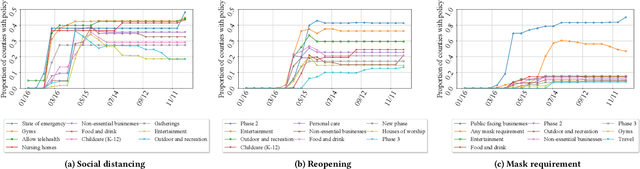
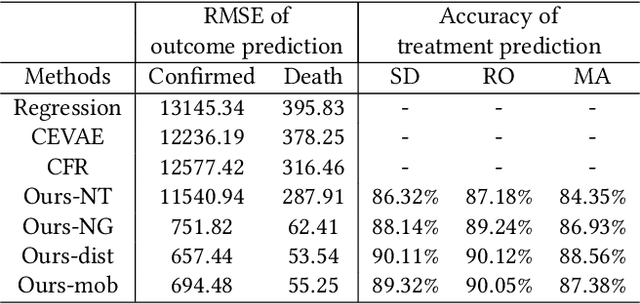
To mitigate the spread of COVID-19 pandemic, decision-makers and public authorities have announced various non-pharmaceutical policies. Analyzing the causal impact of these policies in reducing the spread of COVID-19 is important for future policy-making. The main challenge here is the existence of unobserved confounders (e.g., vigilance of residents). Besides, as the confounders may be time-varying during COVID-19 (e.g., vigilance of residents changes in the course of the pandemic), it is even more difficult to capture them. In this paper, we study the problem of assessing the causal effects of different COVID-19 related policies on the outbreak dynamics in different counties at any given time period. To this end, we integrate data about different COVID-19 related policies (treatment) and outbreak dynamics (outcome) for different United States counties over time and analyze them with respect to variables that can infer the confounders, including the covariates of different counties, their relational information and historical information. Based on these data, we develop a neural network based causal effect estimation framework which leverages above information in observational data and learns the representations of time-varying (unobserved) confounders. In this way, it enables us to quantify the causal impact of policies at different granularities, ranging from a category of policies with a certain goal to a specific policy type in this category. Besides, experimental results also indicate the effectiveness of our proposed framework in capturing the confounders for quantifying the causal impact of different policies. More specifically, compared with several baseline methods, our framework captures the outbreak dynamics more accurately, and our assessment of policies is more consistent with existing epidemiological studies of COVID-19.
SWAT Watershed Model Calibration using Deep Learning
Oct 06, 2021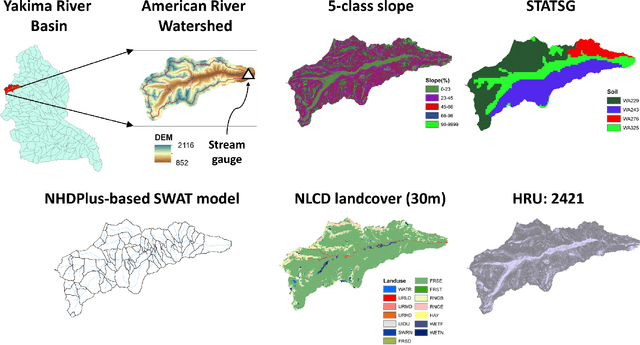
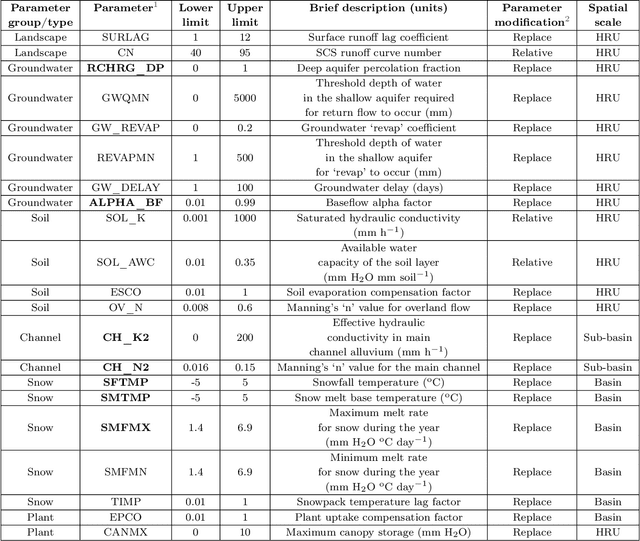
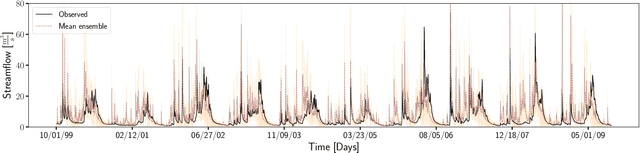

Watershed models such as the Soil and Water Assessment Tool (SWAT) consist of high-dimensional physical and empirical parameters. These parameters need to be accurately calibrated for models to produce reliable predictions for streamflow, evapotranspiration, snow water equivalent, and nutrient loading. Existing parameter estimation methods are time-consuming, inefficient, and computationally intensive, with reduced accuracy when estimating high-dimensional parameters. In this paper, we present a fast, accurate, and reliable methodology to calibrate the SWAT model (i.e., 21 parameters) using deep learning (DL). We develop DL-enabled inverse models based on convolutional neural networks to ingest streamflow data and estimate the SWAT model parameters. Hyperparameter tuning is performed to identify the optimal neural network architecture and the nine next best candidates. We use ensemble SWAT simulations to train, validate, and test the above DL models. We estimated the actual parameters of the SWAT model using observational data. We test and validate the proposed DL methodology on the American River Watershed, located in the Pacific Northwest-based Yakima River basin. Our results show that the DL models-based calibration is better than traditional parameter estimation methods, such as generalized likelihood uncertainty estimation (GLUE). The behavioral parameter sets estimated by DL have narrower ranges than GLUE and produce values within the sampling range even under high relative observational errors. This narrow range of parameters shows the reliability of the proposed workflow to estimate sensitive parameters accurately even under noise. Due to its fast and reasonably accurate estimations of process parameters, the proposed DL workflow is attractive for calibrating integrated hydrologic models for large spatial-scale applications.
Individualized Time-Series Segmentation for Mining Mobile Phone User Behavior
Nov 15, 2018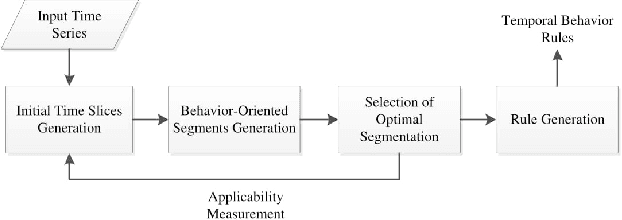
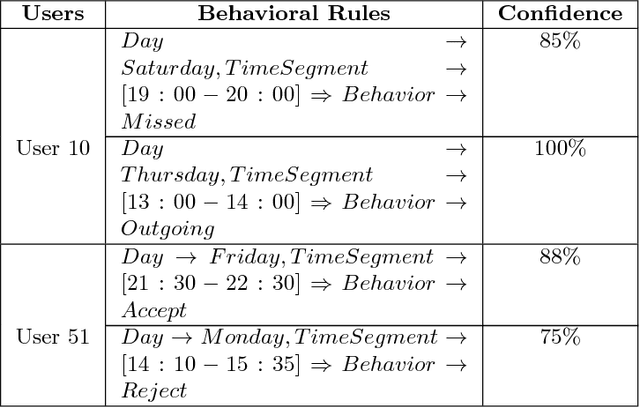

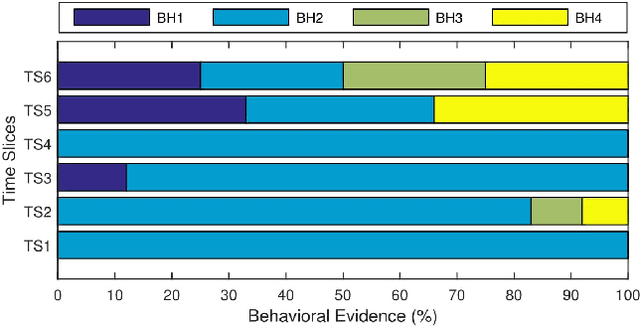
Mobile phones can record individual's daily behavioral data as a time-series. In this paper, we present an effective time-series segmentation technique that extracts optimal time segments of individual's similar behavioral characteristics utilizing their mobile phone data. One of the determinants of an individual's behavior is the various activities undertaken at various times-of-the-day and days-of-the-week. In many cases, such behavior will follow temporal patterns. Currently, researchers use either equal or unequal interval-based segmentation of time for mining mobile phone users' behavior. Most of them take into account static temporal coverage of 24-h-a-day and few of them take into account the number of incidences in time-series data. However, such segmentations do not necessarily map to the patterns of individual user activity and subsequent behavior because of not taking into account the diverse behaviors of individuals over time-of-the-week. Therefore, we propose a behavior-oriented time segmentation (BOTS) technique that takes into account not only the temporal coverage of the week but also the number of incidences of diverse behaviors dynamically for producing similar behavioral time segments over the week utilizing time-series data. Experiments on the real mobile phone datasets show that our proposed segmentation technique better captures the user's dominant behavior at various times-of-the-day and days-of-the-week enabling the generation of high confidence temporal rules in order to mine individual mobile phone users' behavior.
* 20 pages
Towards Resilient UAV: Escape Time in GPS Denied Environment with Sensor Drift
Jun 11, 2019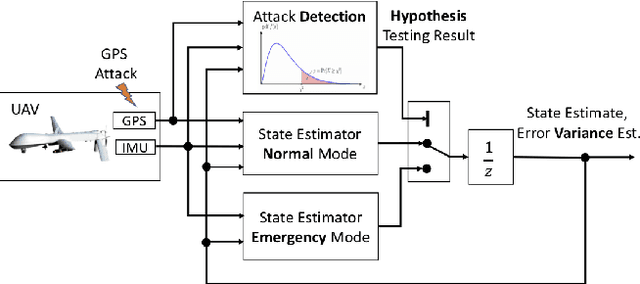
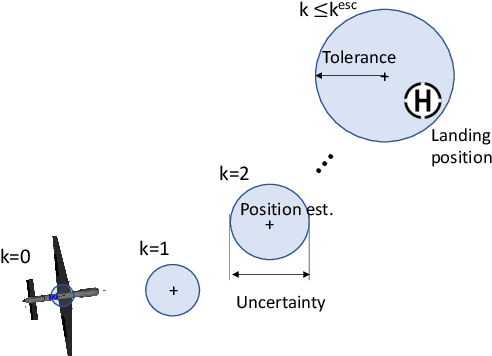
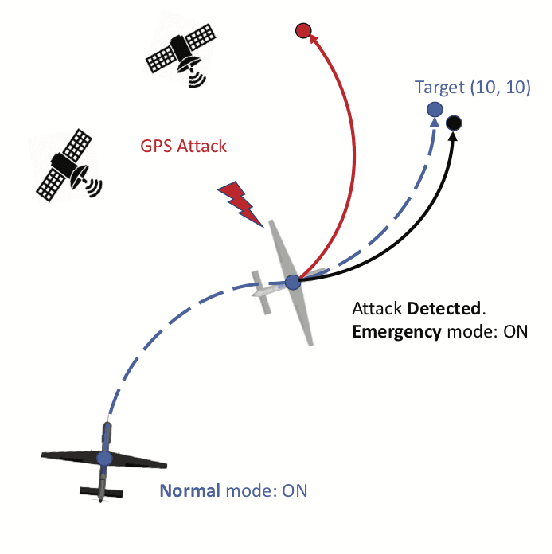
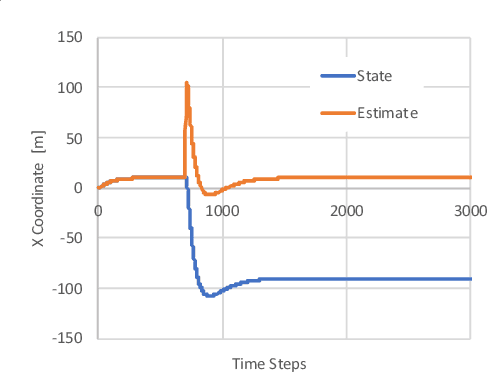
This paper considers a resilient state estimation framework for unmanned aerial vehicles (UAVs) that integrates a Kalman filter-like state estimator and an attack detector. When an attack is detected, the state estimator uses only IMU signals as the GPS signals do not contain legitimate information. This limited sensor availability induces a sensor drift problem questioning the reliability of the sensor estimates. We propose a new resilience measure, escape time, as the safe time within which the estimation errors remain in a tolerable region with high probability. This paper analyzes the stability of the proposed resilient estimation framework and quantifies a lower bound for the escape time. Moreover, simulations of the UAV model demonstrate the performance of the proposed framework and provide analytical results.