 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Simulation by Conditional Generative Adversarial Net
Apr 25, 2019
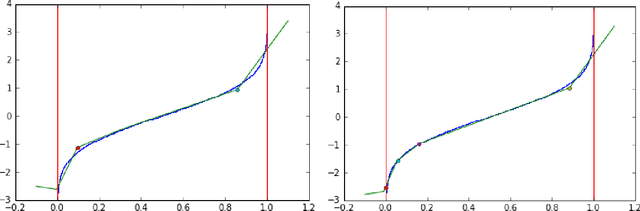
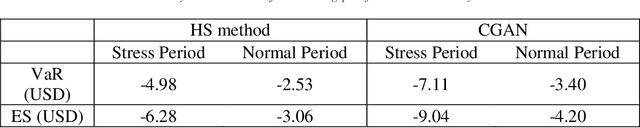

Generative Adversarial Net (GAN) has been proven to be a powerful machine learning tool in image data analysis and generation. In this paper, we propose to use Conditional Generative Adversarial Net (CGAN) to learn and simulate time series data. The conditions can be both categorical and continuous variables containing different kinds of auxiliary information. Our simulation studies show that CGAN is able to learn different kinds of normal and heavy tail distributions, as well as dependent structures of different time series and it can further generate conditional predictive distributions consistent with the training data distributions. We also provide an in-depth discussion on the rationale of GAN and the neural network as hierarchical splines to draw a clear connection with the existing statistical method for distribution generation. In practice, CGAN has a wide range of applications in the market risk and counterparty risk analysis: it can be applied to learn the historical data and generate scenarios for the calculation of Value-at-Risk (VaR) and Expected Shortfall (ES) and predict the movement of the market risk factors. We present a real data analysis including a backtesting to demonstrate CGAN is able to outperform the Historic Simulation, a popular method in market risk analysis for the calculation of VaR. CGAN can also be applied in the economic time series modeling and forecasting, and an example of hypothetical shock analysis for economic models and the generation of potential CCAR scenarios by CGAN is given at the end of the paper.
Bayesian Nonparametric Adaptive Spectral Density Estimation for Financial Time Series
Feb 09, 2019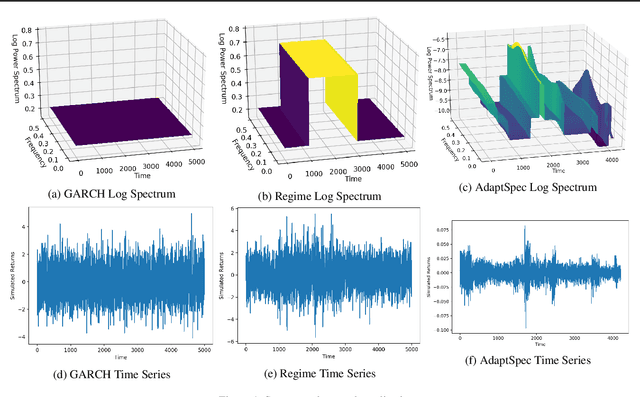
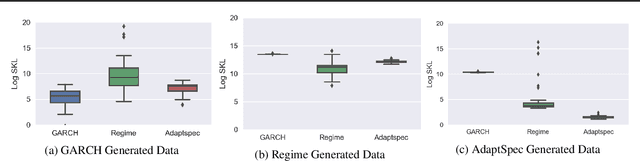
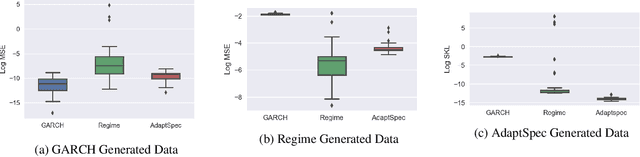
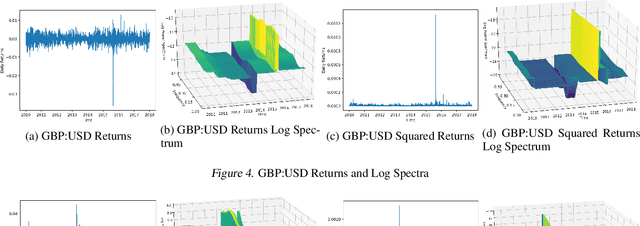
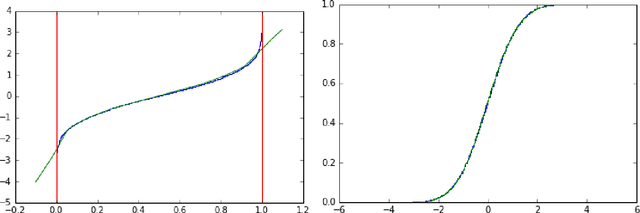
Discrimination between non-stationarity and long-range dependency is a difficult and long-standing issue in modelling financial time series. This paper uses an adaptive spectral technique which jointly models the non-stationarity and dependency of financial time series in a non-parametric fashion assuming that the time series consists of a finite, but unknown number, of locally stationary processes, the locations of which are also unknown. The model allows a non-parametric estimate of the dependency structure by modelling the auto-covariance function in the spectral domain. All our estimates are made within a Bayesian framework where we use aReversible Jump Markov Chain Monte Carlo algorithm for inference. We study the frequentist properties of our estimates via a simulation study, and present a novel way of generating time series data from a nonparametric spectrum. Results indicate that our techniques perform well across a range of data generating processes. We apply our method to a number of real examples and our results indicate that several financial time series exhibit both long-range dependency and non-stationarity.
Test-Time Adaptation for Super-Resolution: You Only Need to Overfit on a Few More Images
Apr 06, 2021
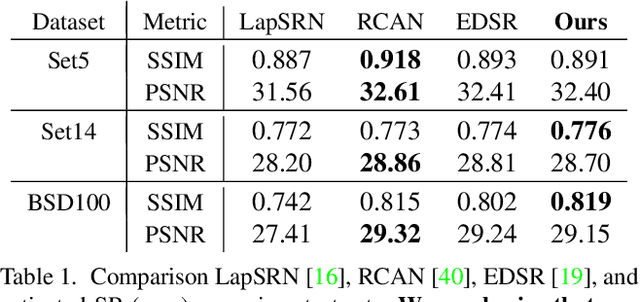
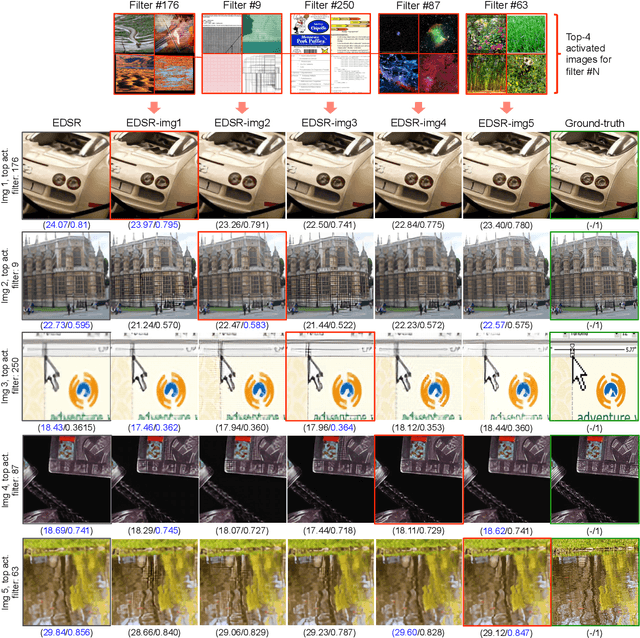
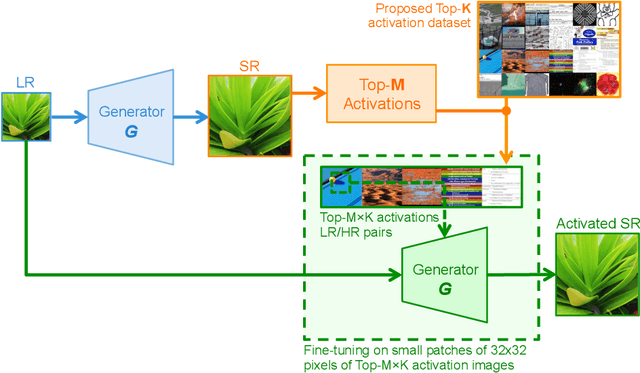
Existing reference (RF)-based super-resolution (SR) models try to improve perceptual quality in SR under the assumption of the availability of high-resolution RF images paired with low-resolution (LR) inputs at testing. As the RF images should be similar in terms of content, colors, contrast, etc. to the test image, this hinders the applicability in a real scenario. Other approaches to increase the perceptual quality of images, including perceptual loss and adversarial losses, tend to dramatically decrease fidelity to the ground-truth through significant decreases in PSNR/SSIM. Addressing both issues, we propose a simple yet universal approach to improve the perceptual quality of the HR prediction from a pre-trained SR network on a given LR input by further fine-tuning the SR network on a subset of images from the training dataset with similar patterns of activation as the initial HR prediction, with respect to the filters of a feature extractor. In particular, we show the effects of fine-tuning on these images in terms of the perceptual quality and PSNR/SSIM values. Contrary to perceptually driven approaches, we demonstrate that the fine-tuned network produces a HR prediction with both greater perceptual quality and minimal changes to the PSNR/SSIM with respect to the initial HR prediction. Further, we present novel numerical experiments concerning the filters of SR networks, where we show through filter correlation, that the filters of the fine-tuned network from our method are closer to "ideal" filters, than those of the baseline network or a network fine-tuned on random images.
Module-Power Prediction from PL Measurements using Deep Learning
Aug 31, 2021
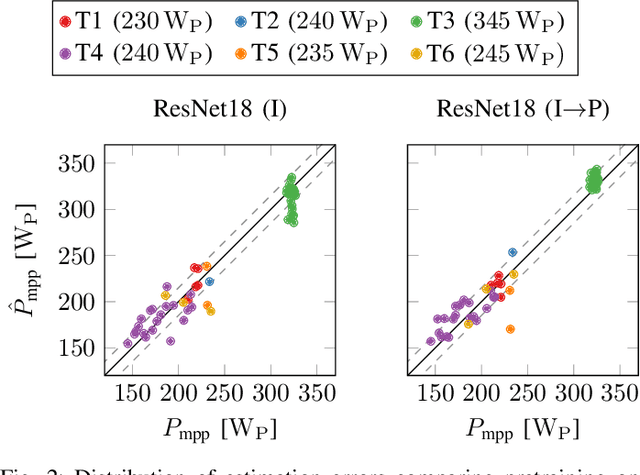
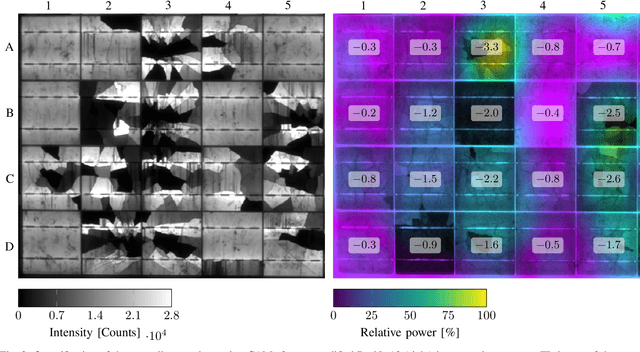
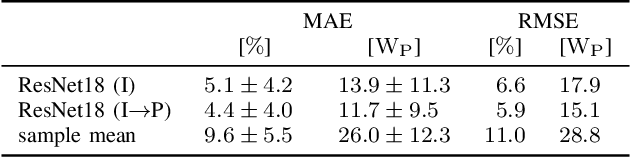
The individual causes for power loss of photovoltaic modules are investigated for quite some time. Recently, it has been shown that the power loss of a module is, for example, related to the fraction of inactive areas. While these areas can be easily identified from electroluminescense (EL) images, this is much harder for photoluminescence (PL) images. With this work, we close the gap between power regression from EL and PL images. We apply a deep convolutional neural network to predict the module power from PL images with a mean absolute error (MAE) of 4.4% or 11.7WP. Furthermore, we depict that regression maps computed from the embeddings of the trained network can be used to compute the localized power loss. Finally, we show that these regression maps can be used to identify inactive regions in PL images as well.
Arbitrage-Free Implied Volatility Surface Generation with Variational Autoencoders
Aug 13, 2021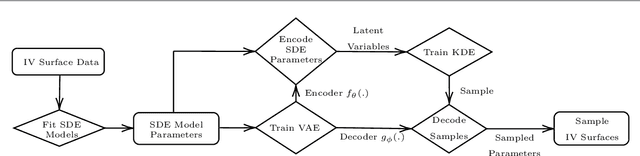

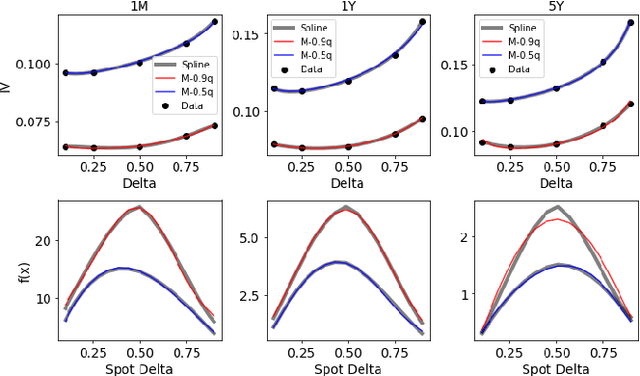

We propose a hybrid method for generating arbitrage-free implied volatility (IV) surfaces consistent with historical data by combining model-free Variational Autoencoders (VAEs) with continuous time stochastic differential equation (SDE) driven models. We focus on two classes of SDE models: regime switching models and L\'evy additive processes. By projecting historical surfaces onto the space of SDE model parameters, we obtain a distribution on the parameter subspace faithful to the data on which we then train a VAE. Arbitrage-free IV surfaces are then generated by sampling from the posterior distribution on the latent space, decoding to obtain SDE model parameters, and finally mapping those parameters to IV surfaces.
Bagging, optimized dynamic mode decomposition (BOP-DMD) for robust, stable forecasting with spatial and temporal uncertainty-quantification
Jul 22, 2021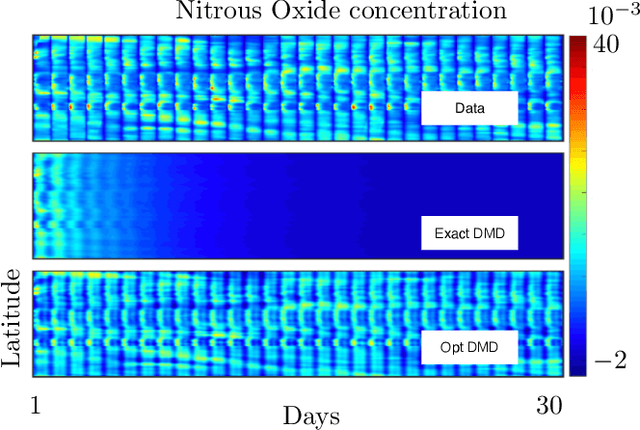
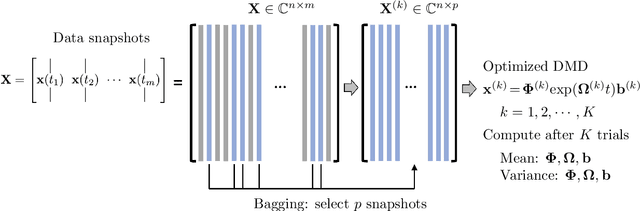
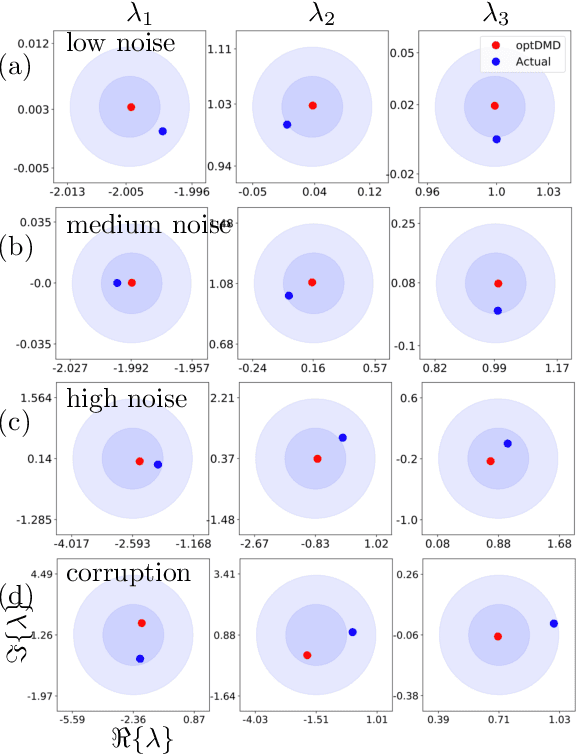
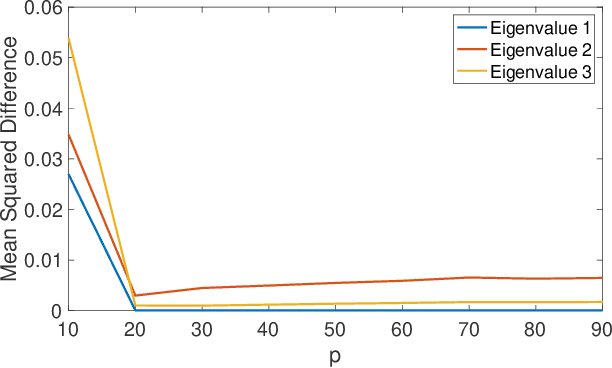
Dynamic mode decomposition (DMD) provides a regression framework for adaptively learning a best-fit linear dynamics model over snapshots of temporal, or spatio-temporal, data. A diversity of regression techniques have been developed for producing the linear model approximation whose solutions are exponentials in time. For spatio-temporal data, DMD provides low-rank and interpretable models in the form of dominant modal structures along with their exponential/oscillatory behavior in time. The majority of DMD algorithms, however, are prone to bias errors from noisy measurements of the dynamics, leading to poor model fits and unstable forecasting capabilities. The optimized DMD algorithm minimizes the model bias with a variable projection optimization, thus leading to stabilized forecasting capabilities. Here, the optimized DMD algorithm is improved by using statistical bagging methods whereby a single set of snapshots is used to produce an ensemble of optimized DMD models. The outputs of these models are averaged to produce a bagging, optimized dynamic mode decomposition (BOP-DMD). BOP-DMD not only improves performance, it also robustifies the model and provides both spatial and temporal uncertainty quantification (UQ). Thus unlike currently available DMD algorithms, BOP-DMD provides a stable and robust model for probabilistic, or Bayesian forecasting with comprehensive UQ metrics.
Neural Compression and Filtering for Edge-assisted Real-time Object Detection in Challenged Networks
Jul 31, 2020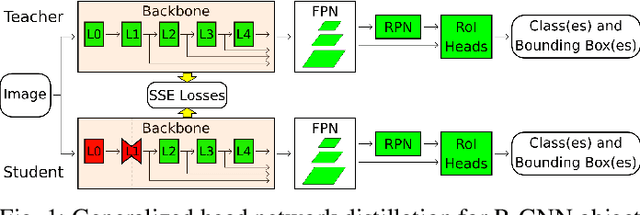
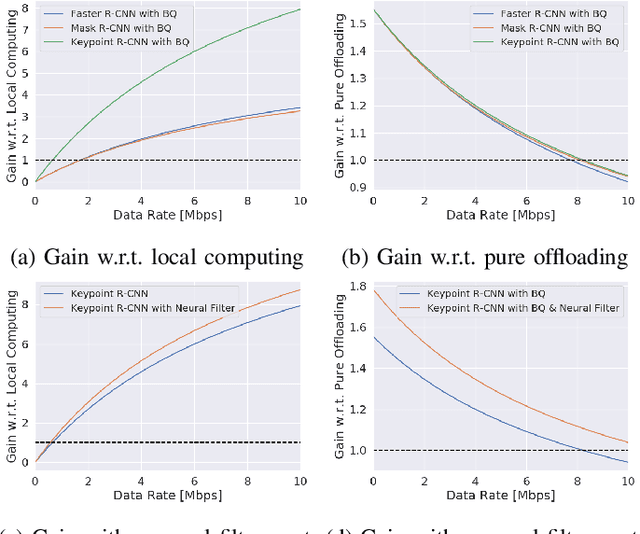
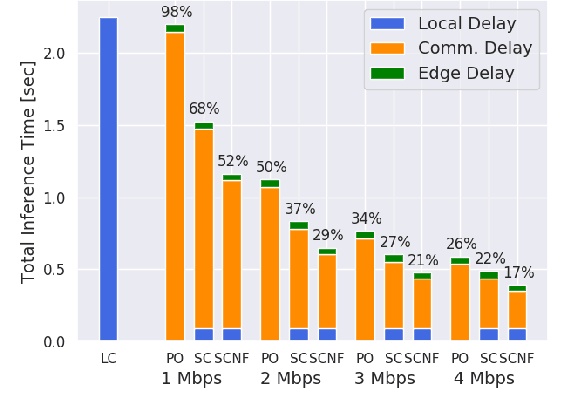
The edge computing paradigm places compute-capable devices - edge servers - at the network edge to assist mobile devices in executing data analysis tasks. Intuitively, offloading compute-intense tasks to edge servers can reduce their execution time. However, poor conditions of the wireless channel connecting the mobile devices to the edge servers may degrade the overall capture-to-output delay achieved by edge offloading. Herein, we focus on edge computing supporting remote object detection by means of Deep Neural Networks (DNNs), and develop a framework to reduce the amount of data transmitted over the wireless link. The core idea we propose builds on recent approaches splitting DNNs into sections - namely head and tail models - executed by the mobile device and edge server, respectively. The wireless link, then, is used to transport the output of the last layer of the head model to the edge server, instead of the DNN input. Most prior work focuses on classification tasks and leaves the DNN structure unaltered. Herein, our focus is on DNNs for three different object detection tasks, which present a much more convoluted structure, and modify the architecture of the network to: (i) achieve in-network compression by introducing a bottleneck layer in the early layers on the head model, and (ii) prefilter pictures that do not contain objects of interest using a convolutional neural network. Results show that the proposed technique represents an effective intermediate option between local and edge computing in a parameter region where these extreme point solutions fail to provide satisfactory performance. We release the code and trained models at https://github.com/yoshitomo-matsubara/hnd-ghnd-object-detectors .
A Study of Fake News Reading and Annotating in Social Media Context
Sep 26, 2021



The online spreading of fake news is a major issue threatening entire societies. Much of this spreading is enabled by new media formats, namely social networks and online media sites. Researchers and practitioners have been trying to answer this by characterizing the fake news and devising automated methods for detecting them. The detection methods had so far only limited success, mostly due to the complexity of the news content and context and lack of properly annotated datasets. One possible way to boost the efficiency of automated misinformation detection methods, is to imitate the detection work of humans. It is also important to understand the news consumption behavior of online users. In this paper, we present an eye-tracking study, in which we let 44 lay participants to casually read through a social media feed containing posts with news articles, some of which were fake. In a second run, we asked the participants to decide on the truthfulness of these articles. We also describe a follow-up qualitative study with a similar scenario but this time with 7 expert fake news annotators. We present the description of both studies, characteristics of the resulting dataset (which we hereby publish) and several findings.
A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]
Jul 22, 2021![Figure 1 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F10-Table2-1.png&w=640&q=75)
With the rapid development of smart mobile devices, the car-hailing platforms (e.g., Uber or Lyft) have attracted much attention from both the academia and the industry. In this paper, we consider an important dynamic car-hailing problem, namely \textit{maximum revenue vehicle dispatching} (MRVD), in which rider requests dynamically arrive and drivers need to serve as many riders as possible such that the entire revenue of the platform is maximized. We prove that the MRVD problem is NP-hard and intractable. In addition, the dynamic car-hailing platforms have no information of the future riders, which makes the problem even harder. To handle the MRVD problem, we propose a queueing-based vehicle dispatching framework, which first uses existing machine learning algorithms to predict the future vehicle demand of each region, then estimates the idle time periods of drivers through a queueing model for each region. With the information of the predicted vehicle demands and estimated idle time periods of drivers, we propose two batch-based vehicle dispatching algorithms to efficiently assign suitable drivers to riders such that the expected overall revenue of the platform is maximized during each batch processing. Through extensive experiments, we demonstrate the efficiency and effectiveness of our proposed approaches over both real and synthetic datasets.
Matching Underwater Sonar Images by the Learned Descriptor Based on Style Transfer Method
Aug 27, 2021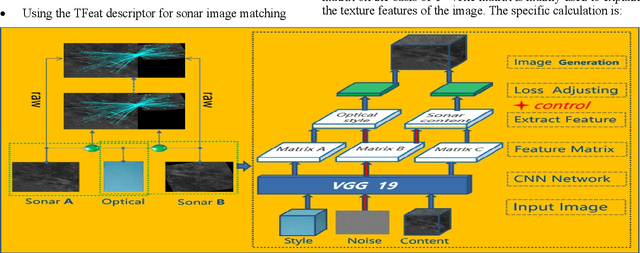
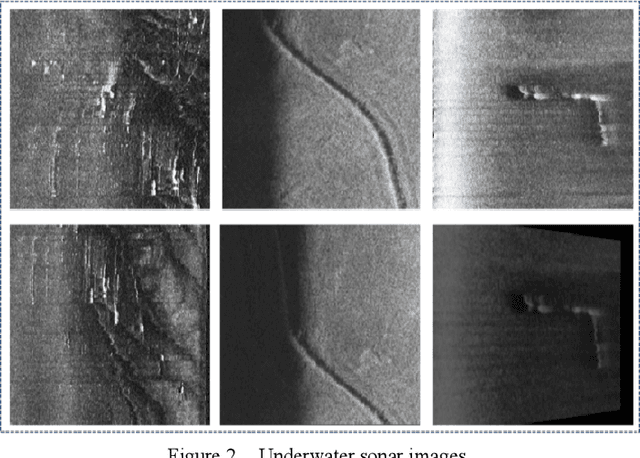

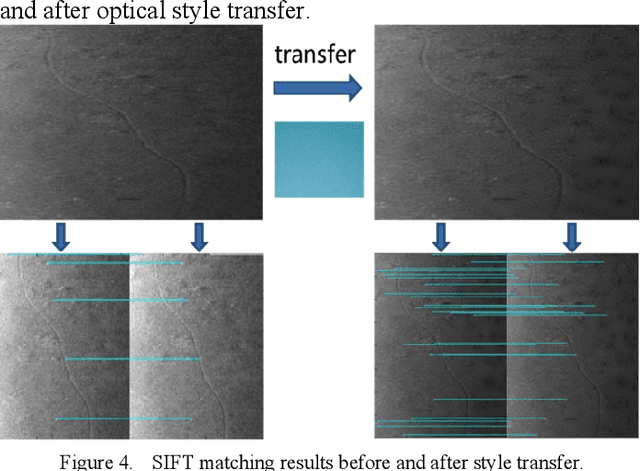
This paper proposes a method that combines the style transfer technique and the learned descriptor to enhance the matching performances of underwater sonar images. In the field of underwater vision, sonar is currently the most effective long-distance detection sensor, it has excellent performances in map building and target search tasks. However, the traditional image matching algorithms are all developed based on optical images. In order to solve this contradiction, the style transfer method is used to convert the sonar images into optical styles, and at the same time, the learned descriptor with excellent expressiveness for sonar images matching is introduced. Experiments show that this method significantly enhances the matching quality of sonar images. In addition, it also provides new ideas for the preprocessing of underwater sonar images by using the style transfer approach.