 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AirDOS: Dynamic SLAM benefits from Articulated Objects
Sep 21, 2021

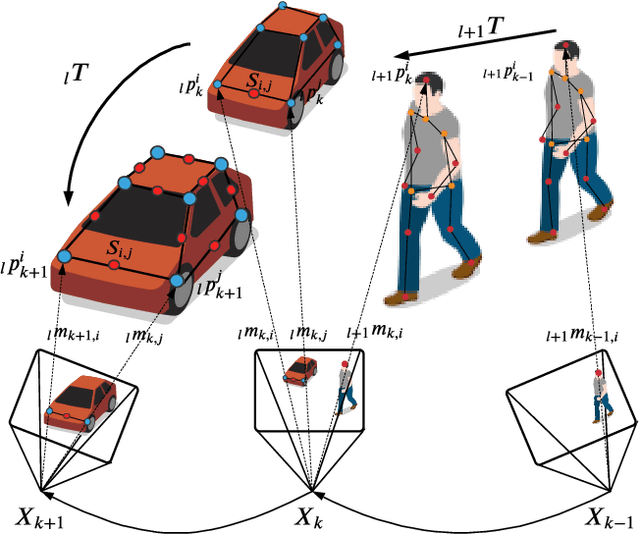
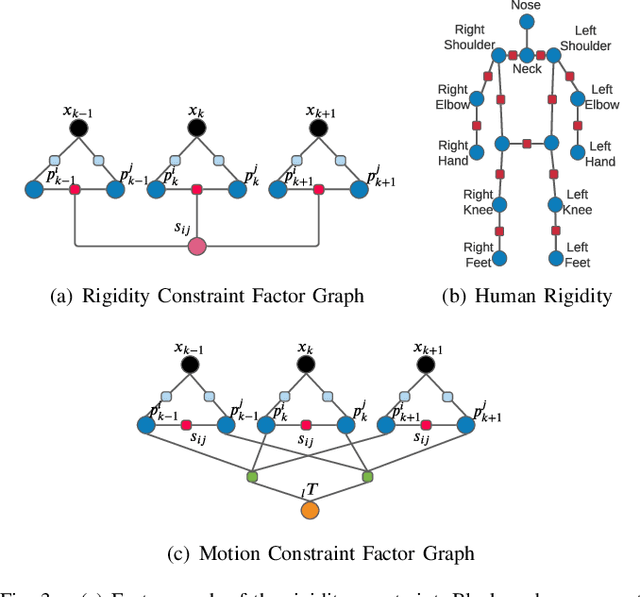
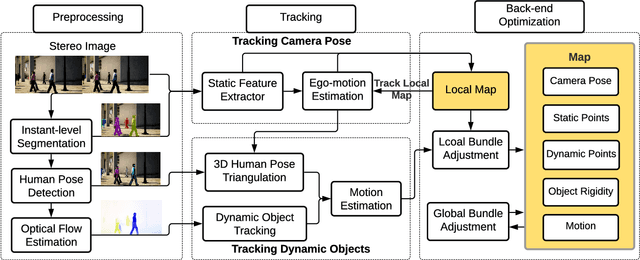
Dynamic Object-aware SLAM (DOS) exploits object-level information to enable robust motion estimation in dynamic environments. It has attracted increasing attention with the recent success of learning-based models. Existing methods mainly focus on identifying and excluding dynamic objects from the optimization. In this paper, we show that feature-based visual SLAM systems can also benefit from the presence of dynamic articulated objects by taking advantage of two observations: (1) The 3D structure of an articulated object remains consistent over time; (2) The points on the same object follow the same motion. In particular, we present AirDOS, a dynamic object-aware system that introduces rigidity and motion constraints to model articulated objects. By jointly optimizing the camera pose, object motion, and the object 3D structure, we can rectify the camera pose estimation, preventing tracking loss, and generate 4D spatio-temporal maps for both dynamic objects and static scenes. Experiments show that our algorithm improves the robustness of visual SLAM algorithms in challenging crowded urban environments. To the best of our knowledge, AirDOS is the first dynamic object-aware SLAM system demonstrating that camera pose estimation can be improved by incorporating dynamic articulated objects.
Learning a subspace of policies for online adaptation in Reinforcement Learning
Oct 11, 2021
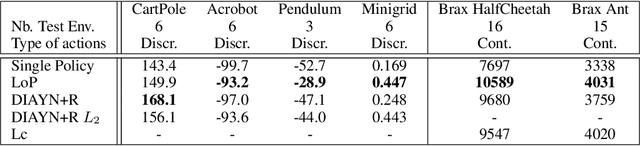

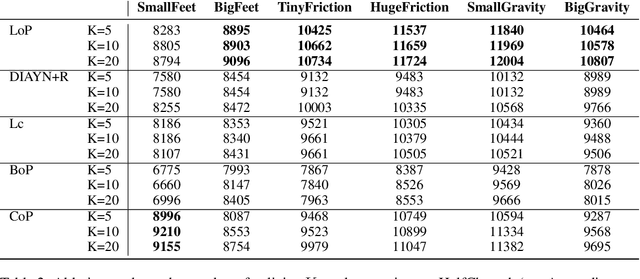
Deep Reinforcement Learning (RL) is mainly studied in a setting where the training and the testing environments are similar. But in many practical applications, these environments may differ. For instance, in control systems, the robot(s) on which a policy is learned might differ from the robot(s) on which a policy will run. It can be caused by different internal factors (e.g., calibration issues, system attrition, defective modules) or also by external changes (e.g., weather conditions). There is a need to develop RL methods that generalize well to variations of the training conditions. In this article, we consider the simplest yet hard to tackle generalization setting where the test environment is unknown at train time, forcing the agent to adapt to the system's new dynamics. This online adaptation process can be computationally expensive (e.g., fine-tuning) and cannot rely on meta-RL techniques since there is just a single train environment. To do so, we propose an approach where we learn a subspace of policies within the parameter space. This subspace contains an infinite number of policies that are trained to solve the training environment while having different parameter values. As a consequence, two policies in that subspace process information differently and exhibit different behaviors when facing variations of the train environment. Our experiments carried out over a large variety of benchmarks compare our approach with baselines, including diversity-based methods. In comparison, our approach is simple to tune, does not need any extra component (e.g., discriminator) and learns policies able to gather a high reward on unseen environments.
Automatic Modulation Classification Using Involution Enabled Residual Networks
Aug 23, 2021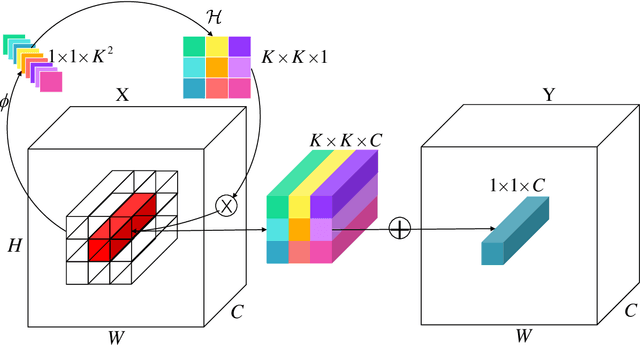
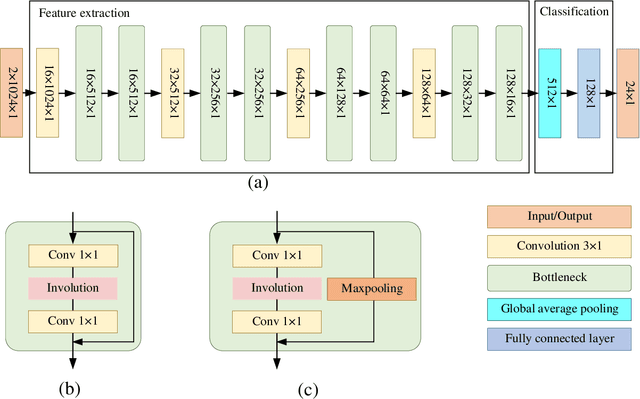
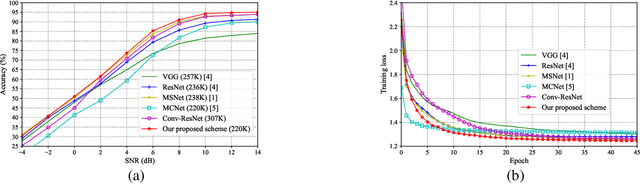
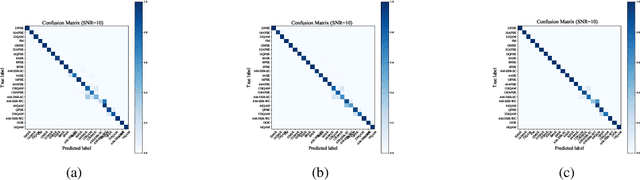
Automatic modulation classification (AMC) is of crucial importance for realizing wireless intelligence communications. Many deep learning based models especially convolution neural networks (CNNs) have been proposed for AMC. However, the computation cost is very high, which makes them inappropriate for beyond the fifth generation wireless communication networks that have stringent requirements on the classification accuracy and computing time. In order to tackle those challenges, a novel involution enabled AMC scheme is proposed by using the bottleneck structure of the residual networks. Involution is utilized instead of convolution to enhance the discrimination capability and expressiveness of the model by incorporating a self-attention mechanism. Simulation results demonstrate that our proposed scheme achieves superior classification performance and faster convergence speed comparing with other benchmark schemes.
Multi-modal Affect Analysis using standardized data within subjects in the Wild
Jul 10, 2021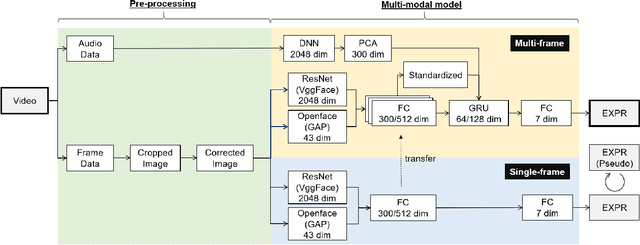


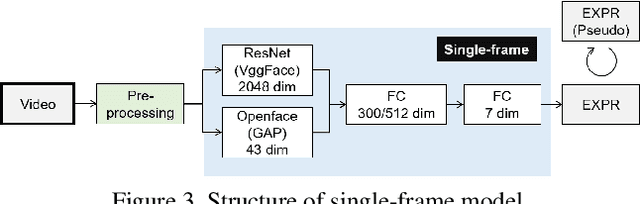
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on facial expression (EXP) and valence-arousal calculation that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest. When annotating facial expressions from a video, we thought that it would be judged not only from the features common to all people, but also from the relative changes in the time series of individuals. Therefore, after learning the common features for each frame, we constructed a facial expression estimation model and valence-arousal model using time-series data after combining the common features and the standardized features for each video. Furthermore, the above features were learned using multi-modal data such as image features, AU, Head pose, and Gaze. In the validation set, our model achieved a facial expression score of 0.546. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.
Reinforcement Learning for Systematic FX Trading
Oct 15, 2021
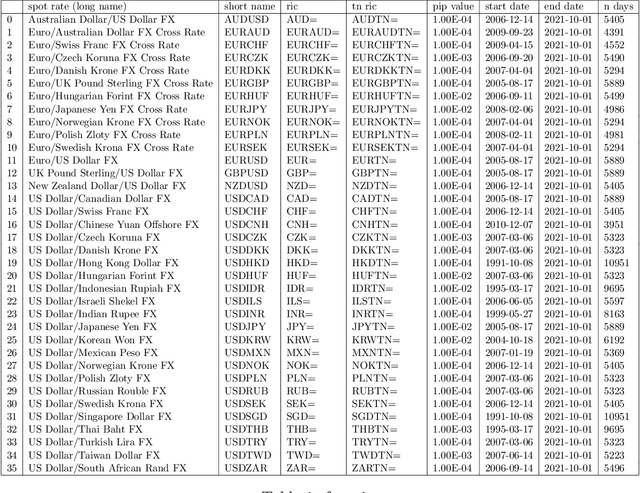
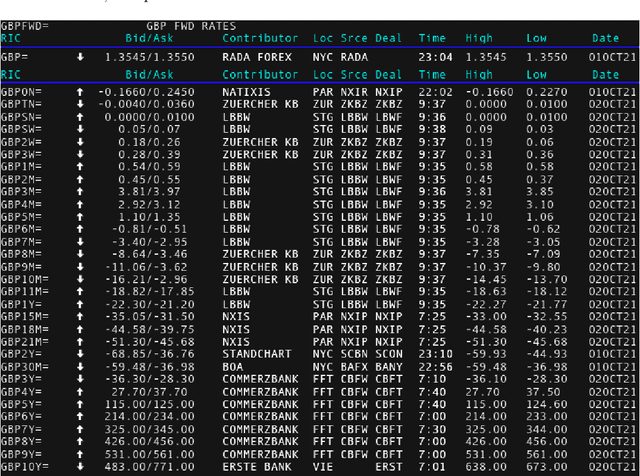
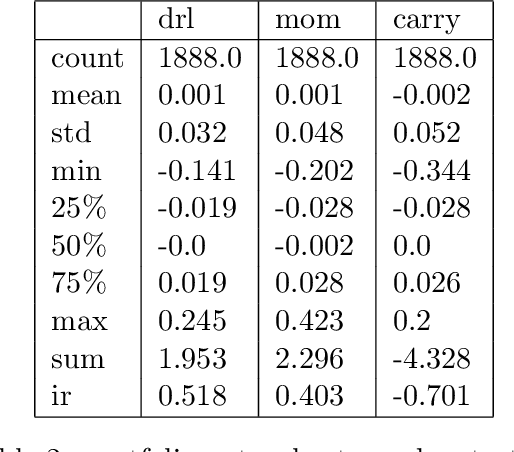
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Two Time-scale Off-Policy TD Learning: Non-asymptotic Analysis over Markovian Samples
Sep 26, 2019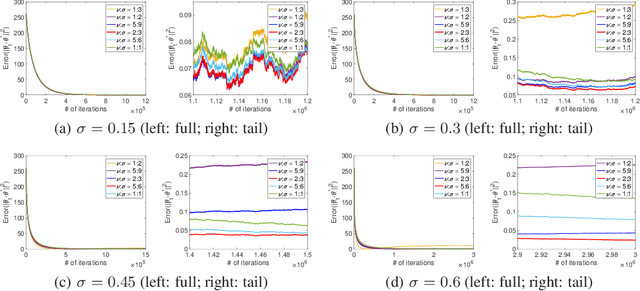
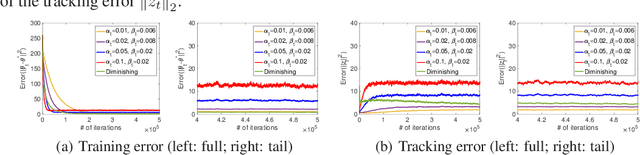
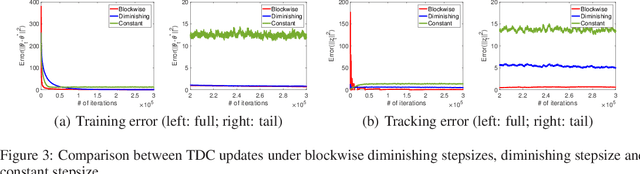
Gradient-based temporal difference (GTD) algorithms are widely used in off-policy learning scenarios. Among them, the two time-scale TD with gradient correction (TDC) algorithm has been shown to have superior performance. In contrast to previous studies that characterized the non-asymptotic convergence rate of TDC only under identical and independently distributed (i.i.d.) data samples, we provide the first non-asymptotic convergence analysis for two time-scale TDC under a non-i.i.d.\ Markovian sample path and linear function approximation. We show that the two time-scale TDC can converge as fast as O(log t/(t^(2/3))) under diminishing stepsize, and can converge exponentially fast under constant stepsize, but at the cost of a non-vanishing error. We further propose a TDC algorithm with blockwisely diminishing stepsize, and show that it asymptotically converges with an arbitrarily small error at a blockwisely linear convergence rate. Our experiments demonstrate that such an algorithm converges as fast as TDC under constant stepsize, and still enjoys comparable accuracy as TDC under diminishing stepsize.
Online Obstructive Sleep Apnea Detection Based on Hybrid Machine Learning And Classifier Combination For Home-based Applications
Oct 01, 2021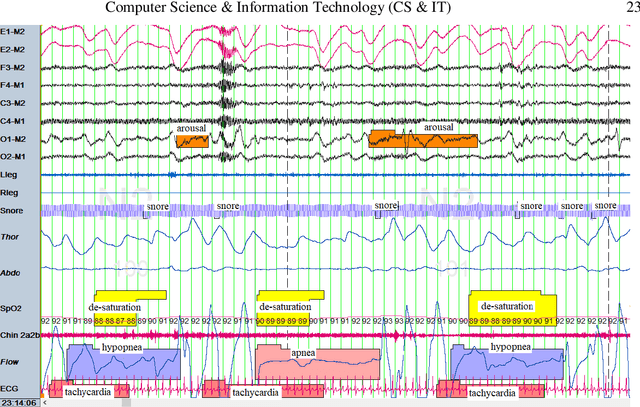
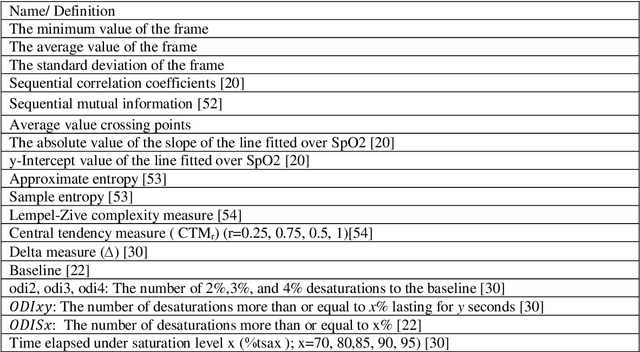


Automatic detection of obstructive sleep apnea (OSA) is in great demand. OSA is one of the most prevalent diseases of the current century and established comorbidity to Covid-19. OSA is characterized by complete or relative breathing pauses during sleep. According to medical observations, if OSA remained unrecognized and un-treated, it may lead to physical and mental complications. The gold standard of scoring OSA severity is the time-consuming and expensive method of polysomnography (PSG). The idea of online home-based surveillance of OSA is welcome. It serves as an effective way for spurred detection and reference of patients to sleep clinics. In addition, it can perform automatic control of the therapeutic/assistive devices. In this paper, several configurations for online OSA detection are proposed. The best configuration uses both ECG and SpO2 signals for feature extraction and MI analysis for feature reduction. Various methods of supervised machine learning are exploited for classification. Finally, to reach the best result, the most successful classifiers in sensitivity and specificity are combined in groups of three members with four different combination methods. The proposed method has advantages like limited use of biological signals, automatic detection, online working scheme, and uniform and acceptable performance (over 85%) in all the employed databases. These advantages have not been integrated in previous published methods.
Conditional Time Series Forecasting with Convolutional Neural Networks
Sep 17, 2018
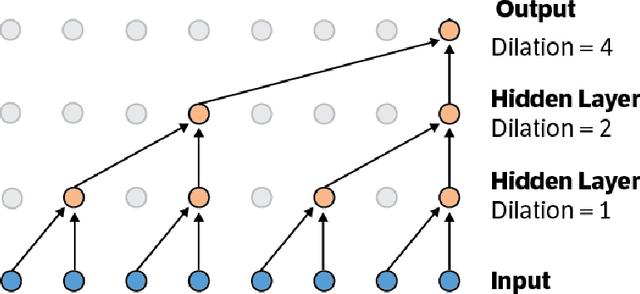
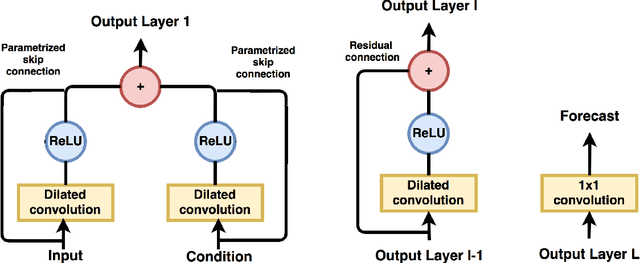
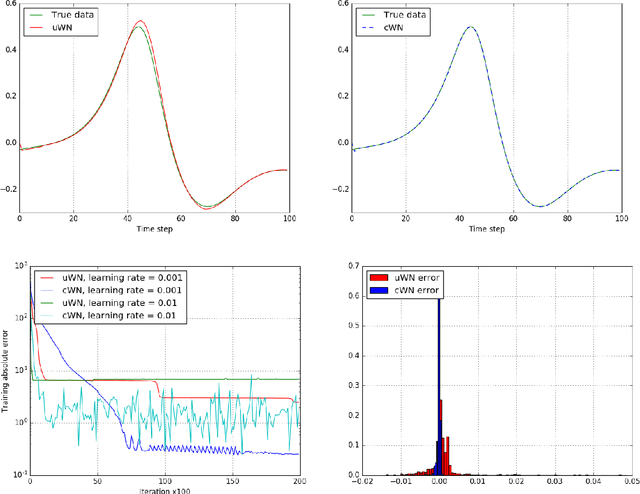
We present a method for conditional time series forecasting based on an adaptation of the recent deep convolutional WaveNet architecture. The proposed network contains stacks of dilated convolutions that allow it to access a broad range of history when forecasting, a ReLU activation function and conditioning is performed by applying multiple convolutional filters in parallel to separate time series which allows for the fast processing of data and the exploitation of the correlation structure between the multivariate time series. We test and analyze the performance of the convolutional network both unconditionally as well as conditionally for financial time series forecasting using the S&P500, the volatility index, the CBOE interest rate and several exchange rates and extensively compare it to the performance of the well-known autoregressive model and a long-short term memory network. We show that a convolutional network is well-suited for regression-type problems and is able to effectively learn dependencies in and between the series without the need for long historical time series, is a time-efficient and easy to implement alternative to recurrent-type networks and tends to outperform linear and recurrent models.
EEEA-Net: An Early Exit Evolutionary Neural Architecture Search
Aug 13, 2021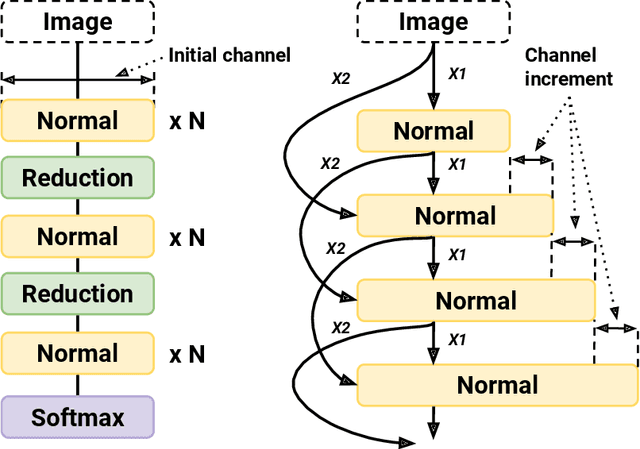

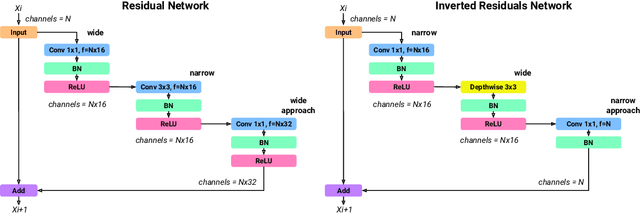
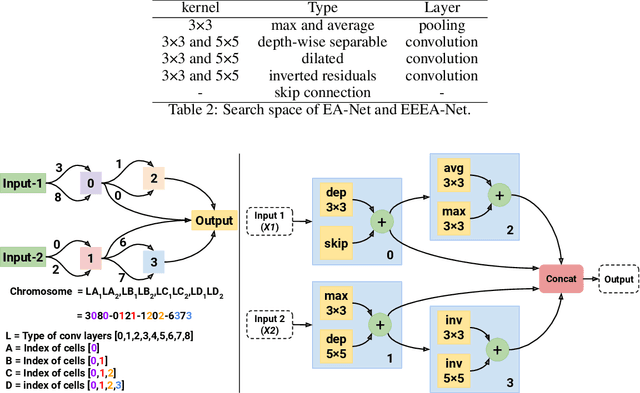
The goals of this research were to search for Convolutional Neural Network (CNN) architectures, suitable for an on-device processor with limited computing resources, performing at substantially lower Network Architecture Search (NAS) costs. A new algorithm entitled an Early Exit Population Initialisation (EE-PI) for Evolutionary Algorithm (EA) was developed to achieve both goals. The EE-PI reduces the total number of parameters in the search process by filtering the models with fewer parameters than the maximum threshold. It will look for a new model to replace those models with parameters more than the threshold. Thereby, reducing the number of parameters, memory usage for model storage and processing time while maintaining the same performance or accuracy. The search time was reduced to 0.52 GPU day. This is a huge and significant achievement compared to the NAS of 4 GPU days achieved using NSGA-Net, 3,150 GPU days by the AmoebaNet model, and the 2,000 GPU days by the NASNet model. As well, Early Exit Evolutionary Algorithm networks (EEEA-Nets) yield network architectures with minimal error and computational cost suitable for a given dataset as a class of network algorithms. Using EEEA-Net on CIFAR-10, CIFAR-100, and ImageNet datasets, our experiments showed that EEEA-Net achieved the lowest error rate among state-of-the-art NAS models, with 2.46% for CIFAR-10, 15.02% for CIFAR-100, and 23.8% for ImageNet dataset. Further, we implemented this image recognition architecture for other tasks, such as object detection, semantic segmentation, and keypoint detection tasks, and, in our experiments, EEEA-Net-C2 outperformed MobileNet-V3 on all of these various tasks. (The algorithm code is available at https://github.com/chakkritte/EEEA-Net).
* Published at Engineering Applications of Artificial Intelligence; Code and pretrained models available at https://github.com/chakkritte/EEEA-Net
Module-Power Prediction from PL Measurements using Deep Learning
Aug 31, 2021
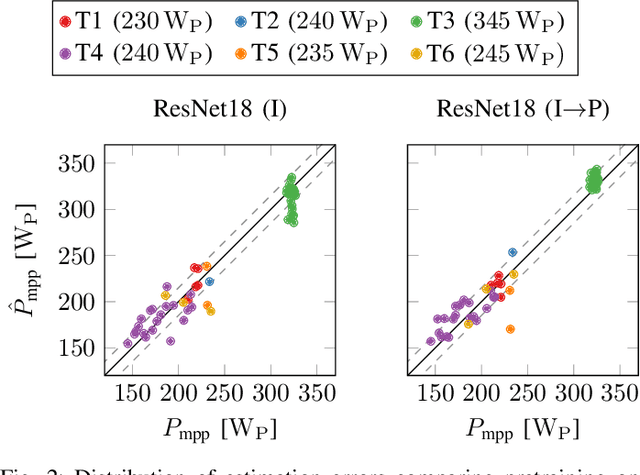
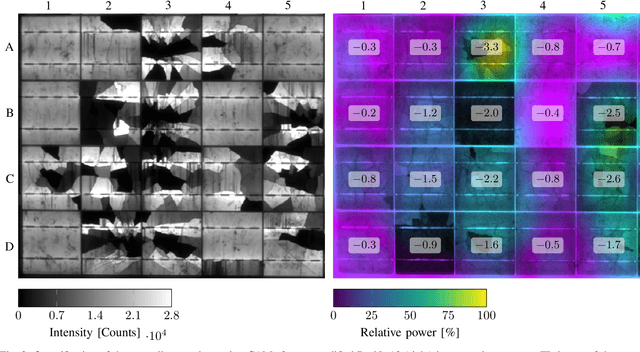
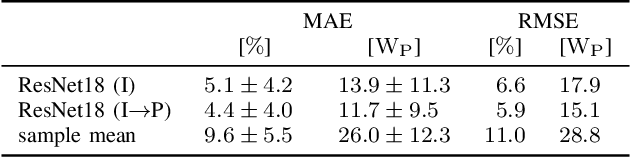
The individual causes for power loss of photovoltaic modules are investigated for quite some time. Recently, it has been shown that the power loss of a module is, for example, related to the fraction of inactive areas. While these areas can be easily identified from electroluminescense (EL) images, this is much harder for photoluminescence (PL) images. With this work, we close the gap between power regression from EL and PL images. We apply a deep convolutional neural network to predict the module power from PL images with a mean absolute error (MAE) of 4.4% or 11.7WP. Furthermore, we depict that regression maps computed from the embeddings of the trained network can be used to compute the localized power loss. Finally, we show that these regression maps can be used to identify inactive regions in PL images as well.