 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021
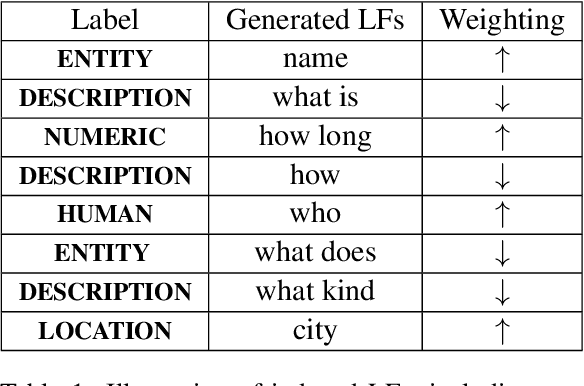
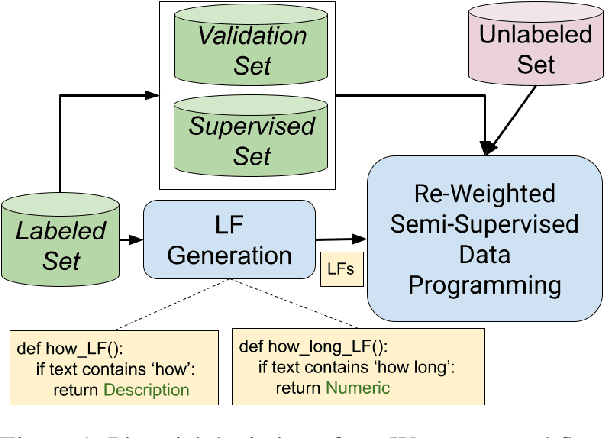
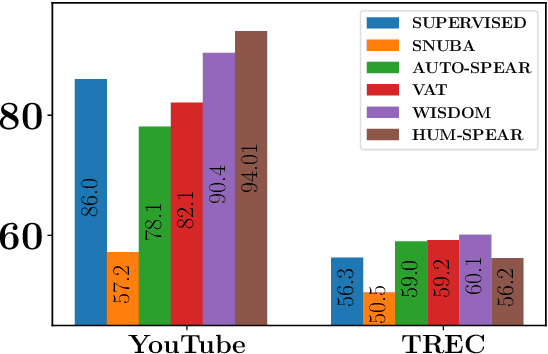
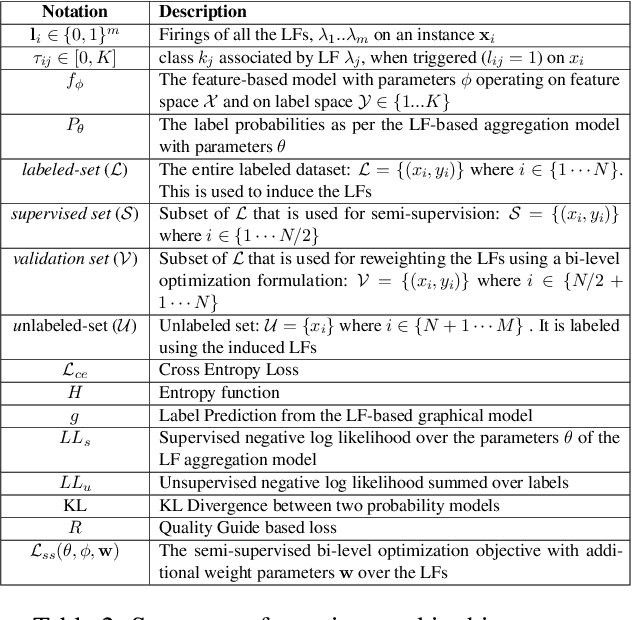
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021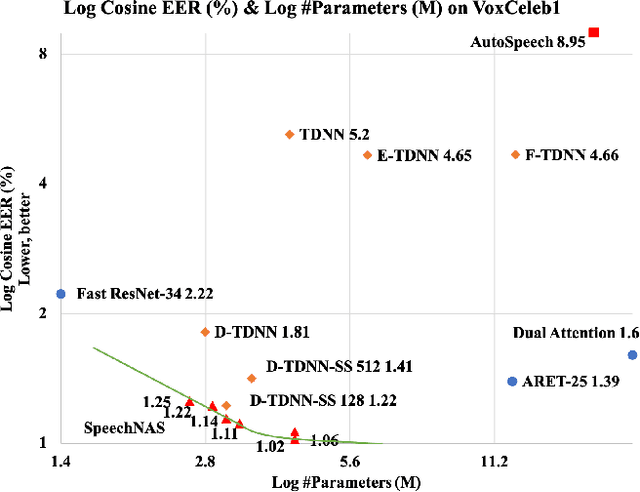
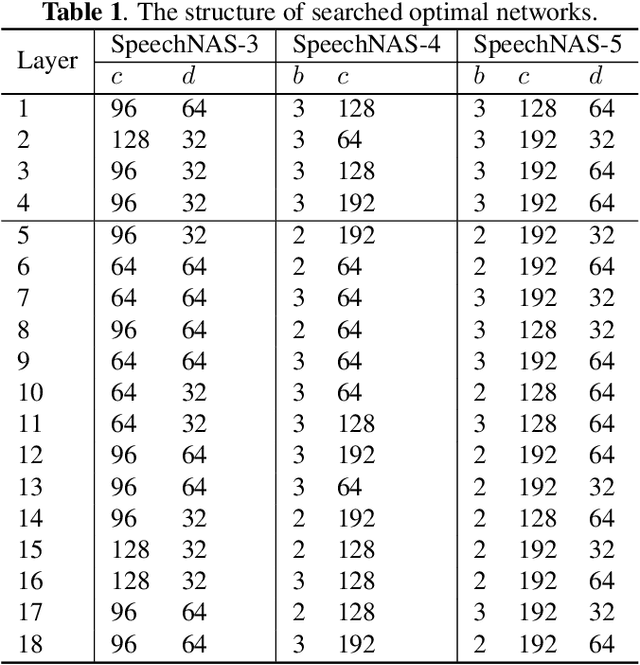
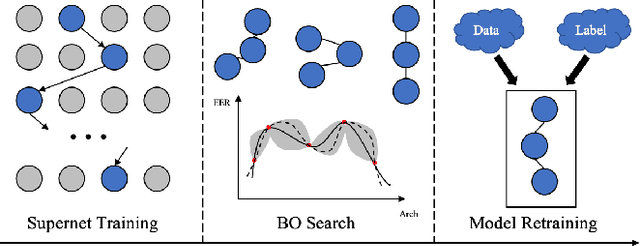
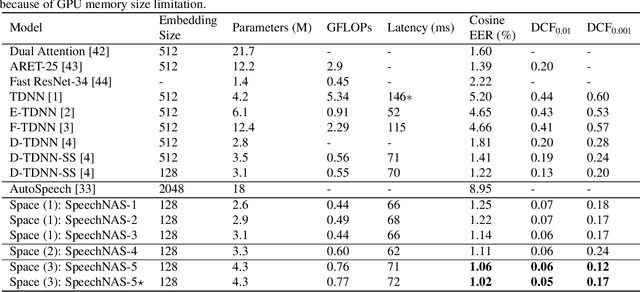
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
A Comparison of Supervised and Unsupervised Deep Learning Methods for Anomaly Detection in Images
Jul 20, 2021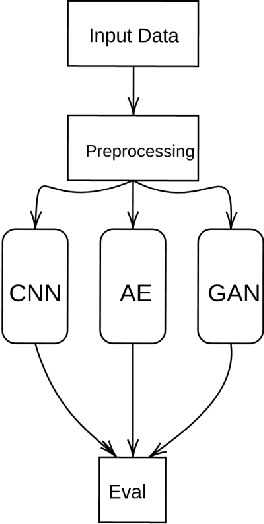
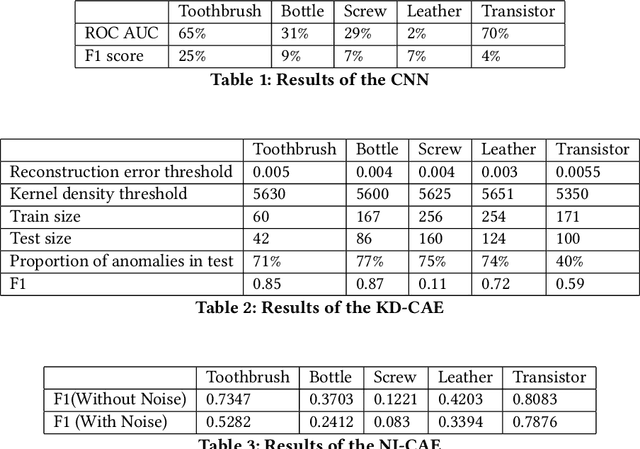
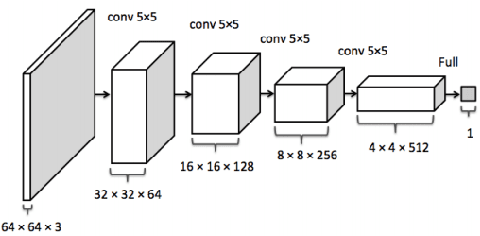

Anomaly detection in images plays a significant role for many applications across all industries, such as disease diagnosis in healthcare or quality assurance in manufacturing. Manual inspection of images, when extended over a monotonously repetitive period of time is very time consuming and can lead to anomalies being overlooked.Artificial neural networks have proven themselves very successful on simple, repetitive tasks, in some cases even outperforming humans. Therefore, in this paper we investigate different methods of deep learning, including supervised and unsupervised learning, for anomaly detection applied to a quality assurance use case. We utilize the MVTec anomaly dataset and develop three different models, a CNN for supervised anomaly detection, KD-CAE for autoencoder anomaly detection, NI-CAE for noise induced anomaly detection and a DCGAN for generating reconstructed images. By experiments, we found that KD-CAE performs better on the anomaly datasets compared to CNN and NI-CAE, with NI-CAE performing the best on the Transistor dataset. We also implemented a DCGAN for the creation of new training data but due to computational limitation and lack of extrapolating the mechanics of AnoGAN, we restricted ourselves just to the generation of GAN based images. We conclude that unsupervised methods are more powerful for anomaly detection in images, especially in a setting where only a small amount of anomalous data is available, or the data is unlabeled.
Generating Active Explicable Plans in Human-Robot Teaming
Sep 18, 2021
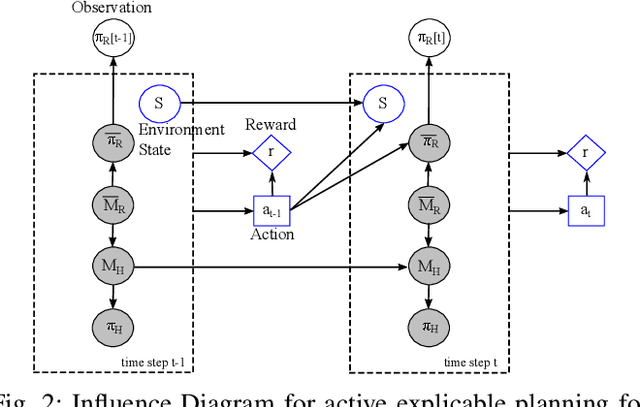
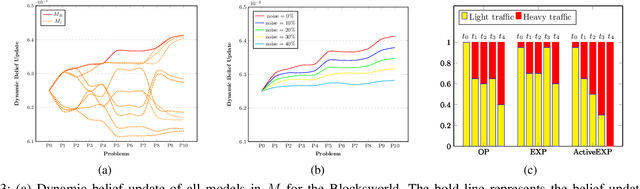
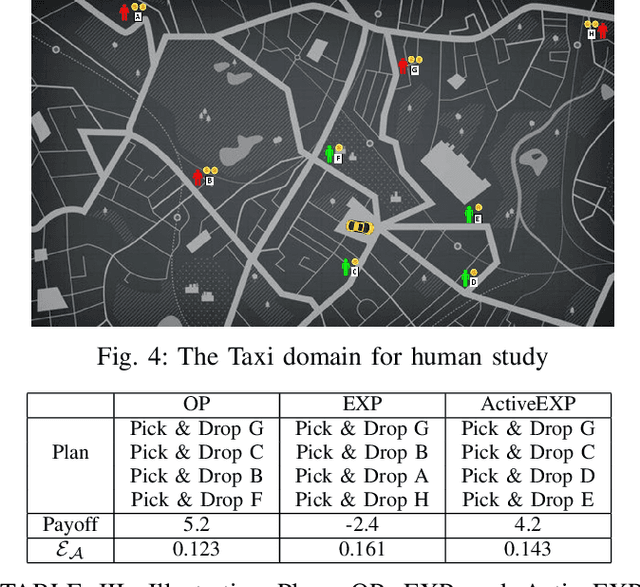
Intelligent robots are redefining a multitude of critical domains but are still far from being fully capable of assisting human peers in day-to-day tasks. An important requirement of collaboration is for each teammate to maintain and respect an understanding of the others' expectations of itself. Lack of which may lead to serious issues such as loose coordination between teammates, reduced situation awareness, and ultimately teaming failures. Hence, it is important for robots to behave explicably by meeting the human's expectations. One of the challenges here is that the expectations of the human are often hidden and can change dynamically as the human interacts with the robot. However, existing approaches to generating explicable plans often assume that the human's expectations are known and static. In this paper, we propose the idea of active explicable planning to relax this assumption. We apply a Bayesian approach to model and predict dynamic human belief and expectations to make explicable planning more anticipatory. We hypothesize that active explicable plans can be more efficient and explicable at the same time, when compared to explicable plans generated by the existing methods. In our experimental evaluation, we verify that our approach generates more efficient explicable plans while successfully capturing the dynamic belief change of the human teammate.
Shatter: An Efficient Transformer Encoder with Single-Headed Self-Attention and Relative Sequence Partitioning
Aug 30, 2021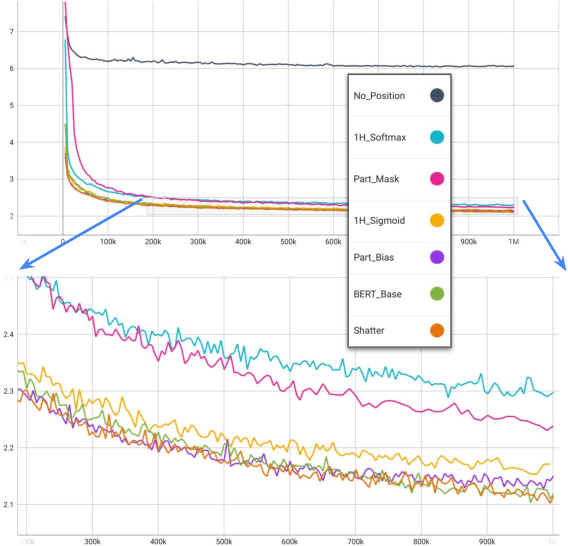
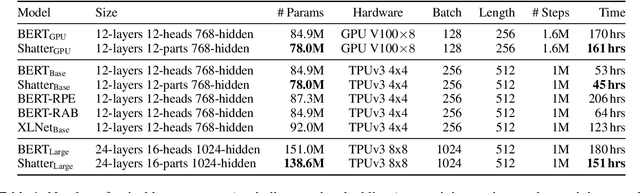

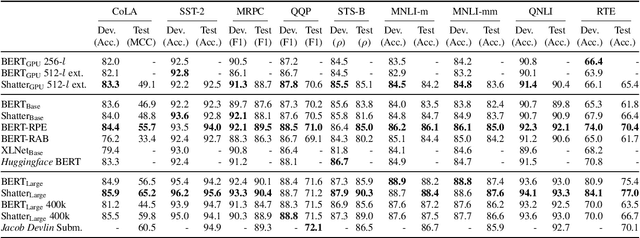
The highly popular Transformer architecture, based on self-attention, is the foundation of large pretrained models such as BERT, that have become an enduring paradigm in NLP. While powerful, the computational resources and time required to pretrain such models can be prohibitive. In this work, we present an alternative self-attention architecture, Shatter, that more efficiently encodes sequence information by softly partitioning the space of relative positions and applying different value matrices to different parts of the sequence. This mechanism further allows us to simplify the multi-headed attention in Transformer to single-headed. We conduct extensive experiments showing that Shatter achieves better performance than BERT, with pretraining being faster per step (15% on TPU), converging in fewer steps, and offering considerable memory savings (>50%). Put together, Shatter can be pretrained on 8 V100 GPUs in 7 days, and match the performance of BERT_Base -- making the cost of pretraining much more affordable.
Rethinking the constraints of multimodal fusion: case study in Weakly-Supervised Audio-Visual Video Parsing
May 30, 2021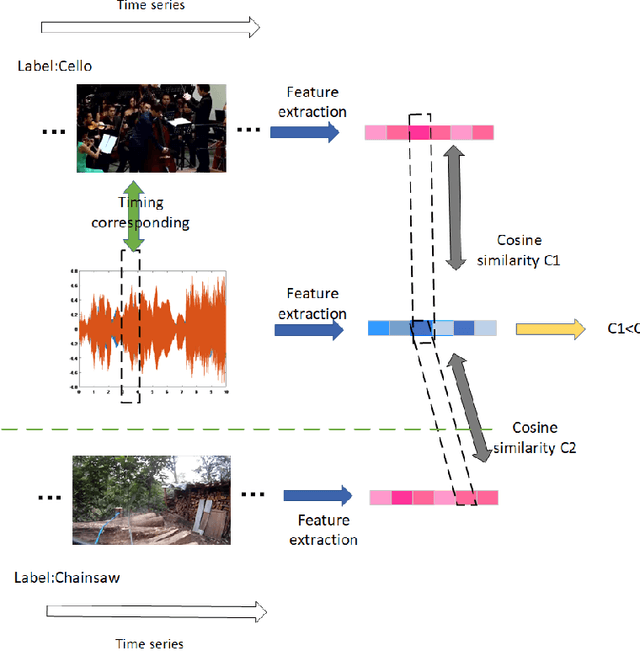

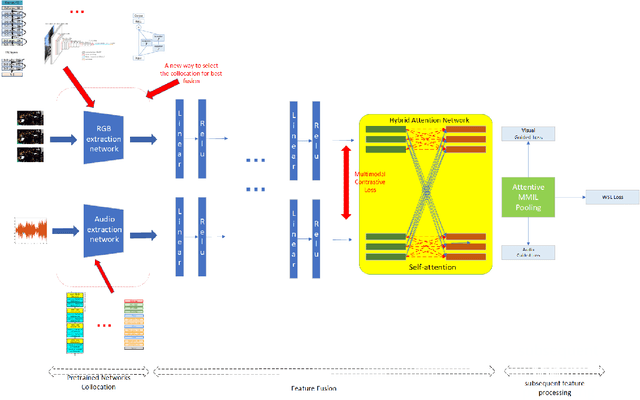
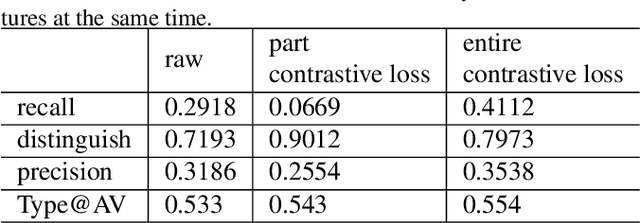
For multimodal tasks, a good feature extraction network should extract information as much as possible and ensure that the extracted feature embedding and other modal feature embedding have an excellent mutual understanding. The latter is often more critical in feature fusion than the former. Therefore, selecting the optimal feature extraction network collocation is a very important subproblem in multimodal tasks. Most of the existing studies ignore this problem or adopt an ergodic approach. This problem is modeled as an optimization problem in this paper. A novel method is proposed to convert the optimization problem into an issue of comparative upper bounds by referring to the general practice of extreme value conversion in mathematics. Compared with the traditional method, it reduces the time cost. Meanwhile, aiming at the common problem that the feature similarity and the feature semantic similarity are not aligned in the multimodal time-series problem, we refer to the idea of contrast learning and propose a multimodal time-series contrastive loss(MTSC). Based on the above issues, We demonstrated the feasibility of our approach in the audio-visual video parsing task. Substantial analyses verify that our methods promote the fusion of different modal features.
Identification and Avoidance of Static and Dynamic Obstacles on Point Cloud for UAVs Navigation
May 14, 2021
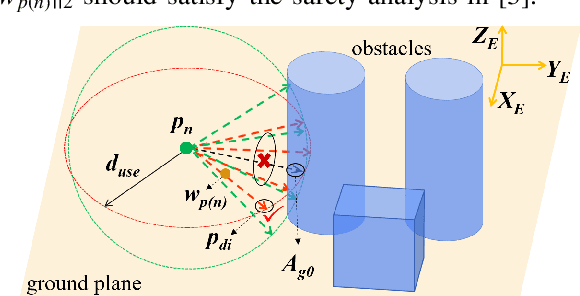
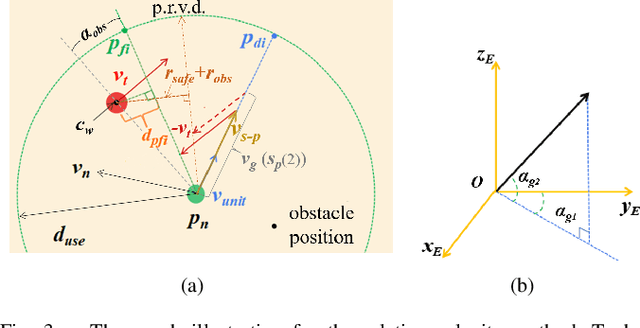
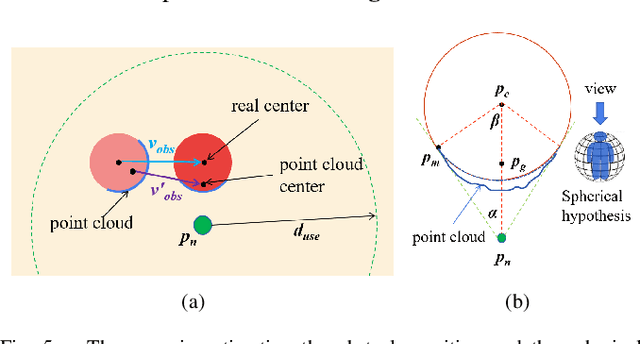
Avoiding hybrid obstacles in unknown scenarios with an efficient flight strategy is a key challenge for unmanned aerial vehicle applications. In this paper, we introduce a technique to distinguish dynamic obstacles from static ones with only point cloud input. Then, a computationally efficient obstacle avoidance motion planning approach is proposed and it is in line with an improved relative velocity method. The approach is able to avoid both static obstacles and dynamic ones in the same framework. For static and dynamic obstacles, the collision check and motion constraints are different, and they are integrated into one framework efficiently. In addition, we present several techniques to improve the algorithm performance and deal with the time gap between different submodules. The proposed approach is implemented to run onboard in real-time and validated extensively in simulation and hardware tests. Our average single step calculating time is less than 20 ms.
Stroke Correspondence by Labeling Closed Areas
Aug 10, 2021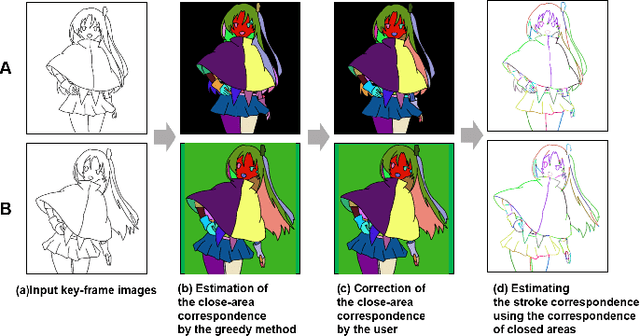

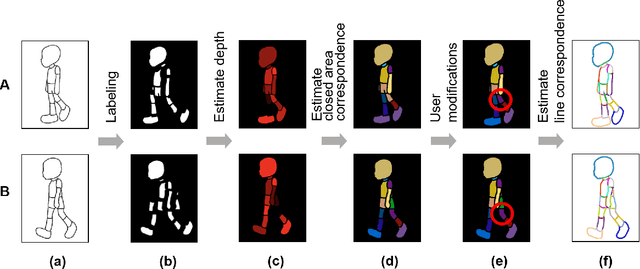
Constructing stroke correspondences between keyframes is one of the most important processes in the production pipeline of hand-drawn inbetweening frames. This process requires time-consuming manual work imposing a tremendous burden on the animators. We propose a method to estimate stroke correspondences between raster character images (keyframes) without vectorization processes. First, the proposed system separates the closed areas in each keyframe and estimates the correspondences between closed areas by using the characteristics of shape, depth, and closed area connection. Second, the proposed system estimates stroke correspondences from the estimated closed area correspondences. We demonstrate the effectiveness of our method by performing a user study and comparing the proposed system with conventional approaches.
Elbert: Fast Albert with Confidence-Window Based Early Exit
Jul 01, 2021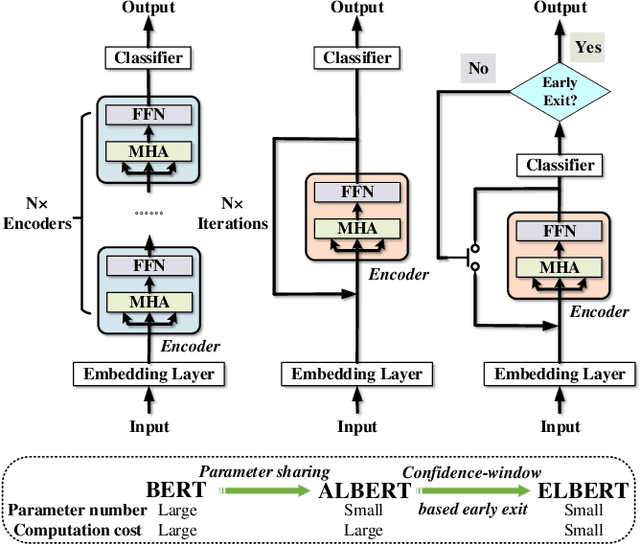
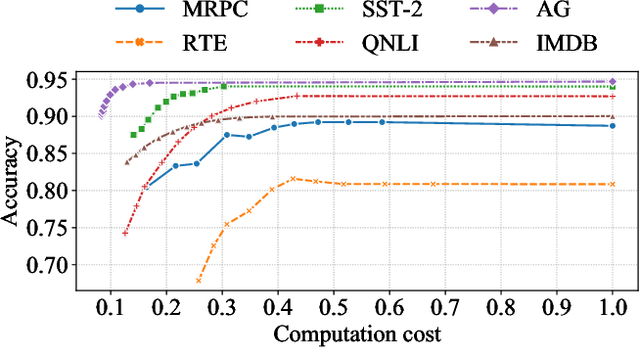
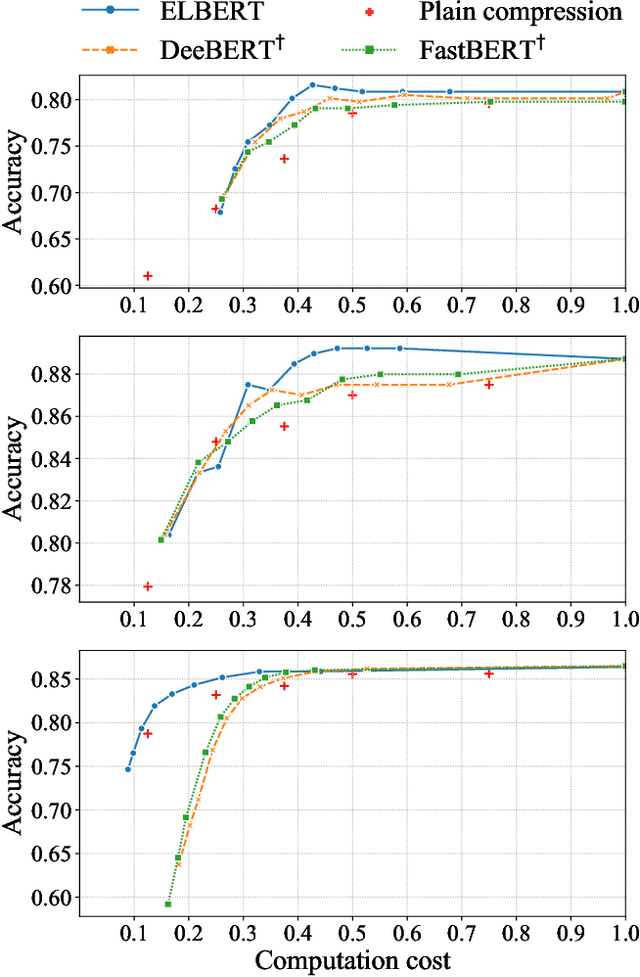
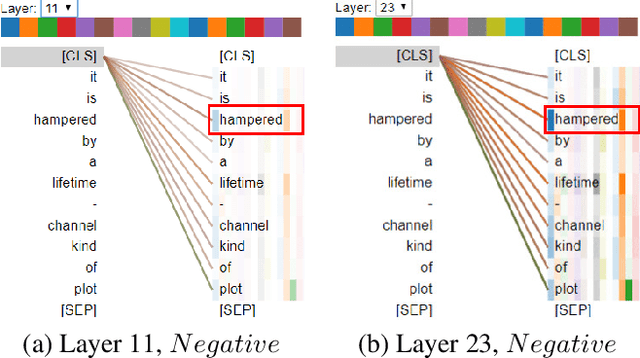
Despite the great success in Natural Language Processing (NLP) area, large pre-trained language models like BERT are not well-suited for resource-constrained or real-time applications owing to the large number of parameters and slow inference speed. Recently, compressing and accelerating BERT have become important topics. By incorporating a parameter-sharing strategy, ALBERT greatly reduces the number of parameters while achieving competitive performance. Nevertheless, ALBERT still suffers from a long inference time. In this work, we propose the ELBERT, which significantly improves the average inference speed compared to ALBERT due to the proposed confidence-window based early exit mechanism, without introducing additional parameters or extra training overhead. Experimental results show that ELBERT achieves an adaptive inference speedup varying from 2$\times$ to 10$\times$ with negligible accuracy degradation compared to ALBERT on various datasets. Besides, ELBERT achieves higher accuracy than existing early exit methods used for accelerating BERT under the same computation cost. Furthermore, to understand the principle of the early exit mechanism, we also visualize the decision-making process of it in ELBERT.
End-to-end Learning for Early Classification of Time Series
Jan 30, 2019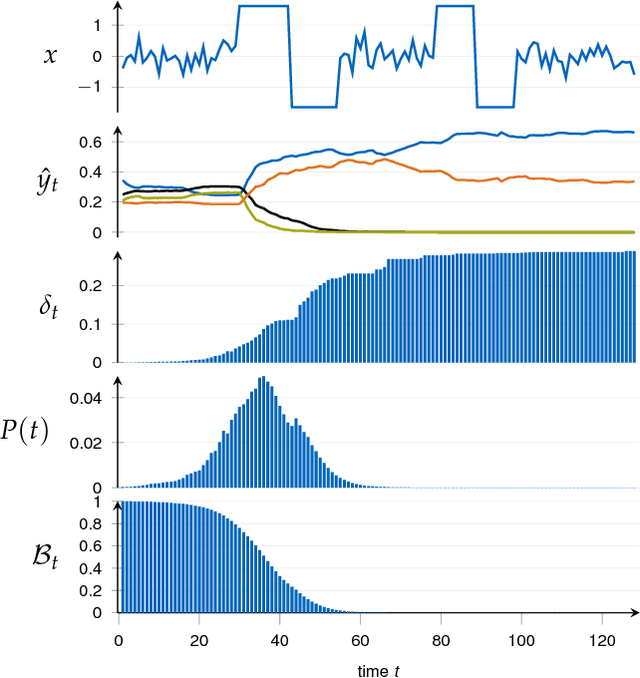

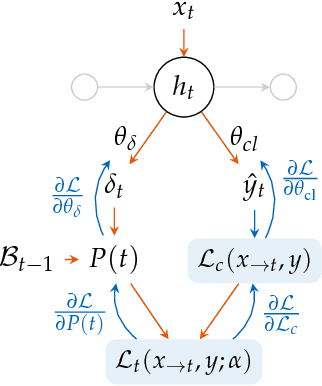
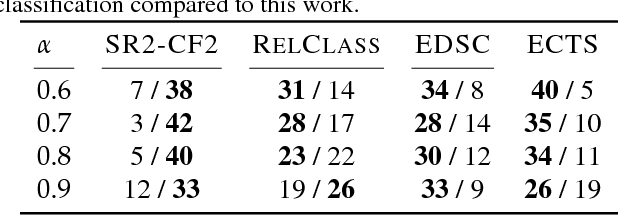
Classification of time series is a topical issue in machine learning. While accuracy stands for the most important evaluation criterion, some applications require decisions to be made as early as possible. Optimization should then target a compromise between earliness, i.e., a capacity of providing a decision early in the sequence, and accuracy. In this work, we propose a generic, end-to-end trainable framework for early classification of time series. This framework embeds a learnable decision mechanism that can be plugged into a wide range of already existing models. We present results obtained with deep neural networks on a diverse set of time series classification problems. Our approach compares well to state-of-the-art competitors while being easily adaptable by any existing neural network topology that evaluates a hidden state at each time step.