 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Keypoints-Based Deep Feature Fusion for Cooperative Vehicle Detection of Autonomous Driving
Sep 23, 2021
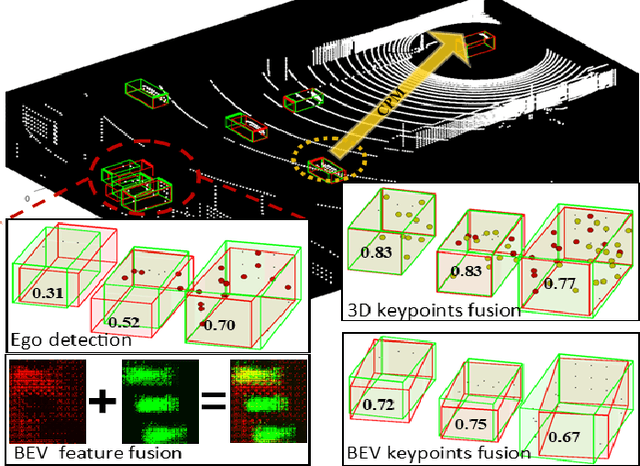



Sharing collective perception messages (CPM) between vehicles is investigated to decrease occlusions, so as to improve perception accuracy and safety of autonomous driving. However, highly accurate data sharing and low communication overhead is a big challenge for collective perception, especially when real-time communication is required among connected and automated vehicles. In this paper, we propose an efficient and effective keypoints-based deep feature fusion framework, called FPV-RCNN, for collective perception, which is built on top of the 3D object detector PV-RCNN. We introduce a bounding box proposal matching module and a keypoints selection strategy to compress the CPM size and solve the multi-vehicle data fusion problem. Compared to a bird's-eye view (BEV) keypoints feature fusion, FPV-RCNN achieves improved detection accuracy by about 14% at a high evaluation criterion (IoU 0.7) on a synthetic dataset COMAP dedicated to collective perception. Also, its performance is comparable to two raw data fusion baselines that have no data loss in sharing. Moreover, our method also significantly decreases the CPM size to less than 0.3KB, which is about 50 times smaller than the BEV feature map sharing used in previous works. Even with a further decreased number of CPM feature channels, i.e., from 128 to 32, the detection performance only drops about 1%. The code of our method is available at https://github.com/YuanYunshuang/FPV_RCNN.
A Fast Evidential Approach for Stock Forecasting
Apr 12, 2021

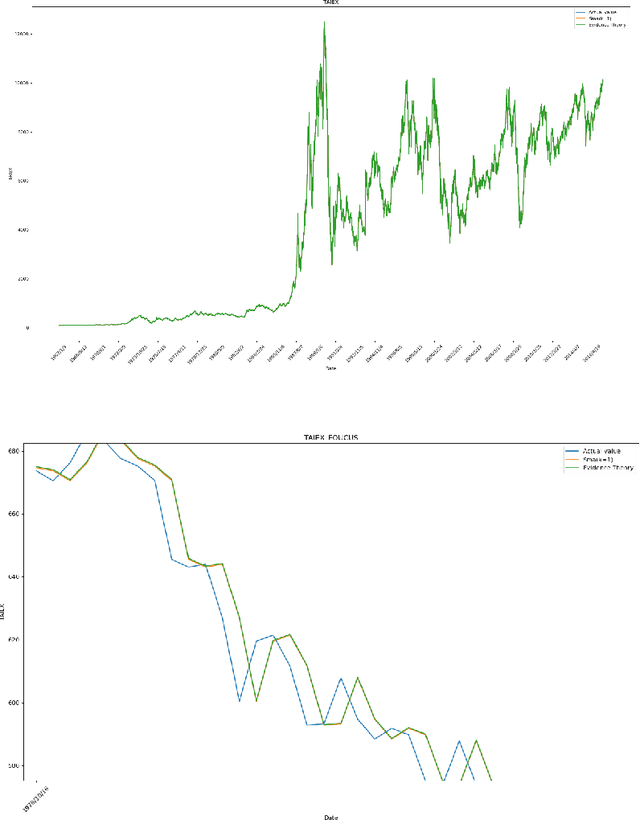

In the framework of evidence theory, data fusion combines the confidence functions of multiple different information sources to obtain a combined confidence function. Stock price prediction is the focus of economics. Stock price forecasts can provide reference data. The Dempster combination rule is a classic method of fusing different information. By using the Dempster combination rule and confidence function based on the entire time series fused at each time point and future time points, and the preliminary forecast value obtained through the time relationship, the accurate forecast value can be restored. This article will introduce the prediction method of evidence theory. This method has good running performance, can make a rapid response on a large amount of stock price data, and has far-reaching significance.
REVAMP$^2$T: Real-time Edge Video Analytics for Multi-camera Privacy-aware Pedestrian Tracking
Nov 25, 2019
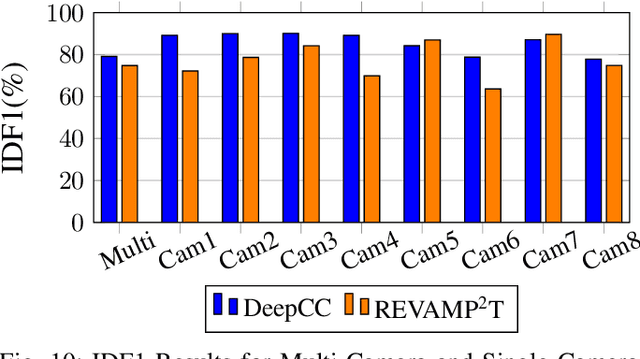
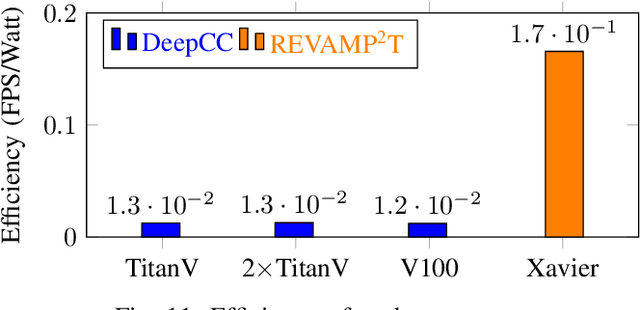
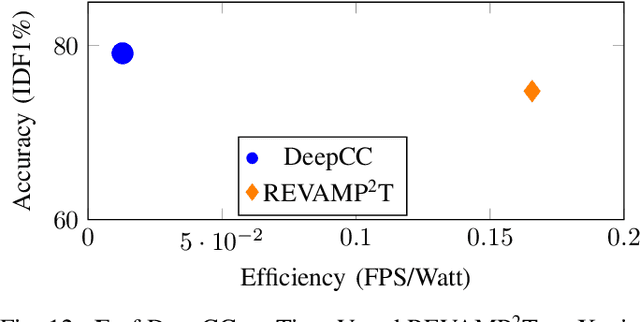
This article presents REVAMP$^2$T, Real-time Edge Video Analytics for Multi-camera Privacy-aware Pedestrian Tracking, as an integrated end-to-end IoT system for privacy-built-in decentralized situational awareness. REVAMP$^2$T presents novel algorithmic and system constructs to push deep learning and video analytics next to IoT devices (i.e. video cameras). On the algorithm side, REVAMP$^2$T proposes a unified integrated computer vision pipeline for detection, re-identification, and tracking across multiple cameras without the need for storing the streaming data. At the same time, it avoids facial recognition, and tracks and re-identifies pedestrians based on their key features at runtime. On the IoT system side, REVAMP$^2$T provides infrastructure to maximize hardware utilization on the edge, orchestrates global communications, and provides system-wide re-identification, without the use of personally identifiable information, for a distributed IoT network. For the results and evaluation, this article also proposes a new metric, Accuracy$\cdot$Efficiency (\AE), for holistic evaluation of IoT systems for real-time video analytics based on accuracy, performance, and power efficiency. REVAMP$^2$T outperforms current state-of-the-art by as much as thirteen-fold \AE~improvement.
MSTC*:Multi-robot Coverage Path Planning under Physical Constraints
Aug 10, 2021
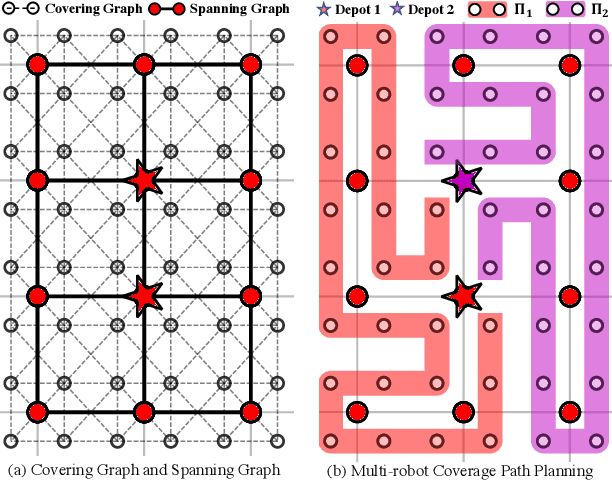
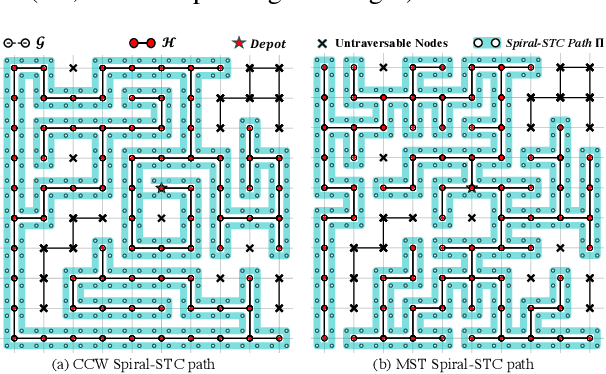

For large-scale tasks, coverage path planning (CPP) can benefit greatly from multiple robots. In this paper, we present an efficient algorithm MSTC* for multi-robot coverage path planning (mCPP) based on spiral spanning tree coverage (Spiral-STC). Our algorithm incorporates strict physical constraints like terrain traversability and material load capacity. We compare our algorithm against the state-of-the-art in mCPP for regular grid maps and real field terrains in simulation environments. The experimental results show that our method significantly outperforms existing spiral-STC based mCPP methods. Our algorithm can find a set of well-balanced workload distributions for all robots and therefore, achieve the overall minimum time to complete the coverage.
Artificial bandwidth extension using deep neural network and $H^\infty$ sampled-data control theory
Aug 30, 2021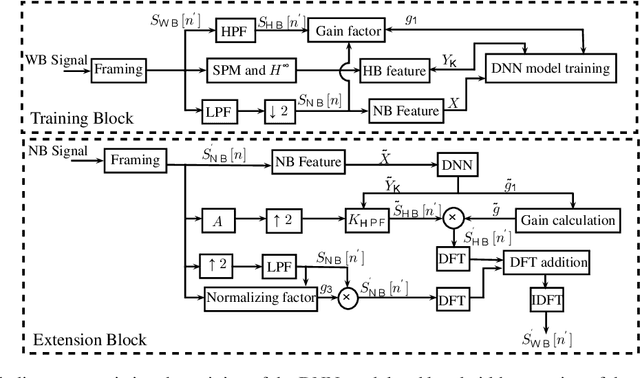


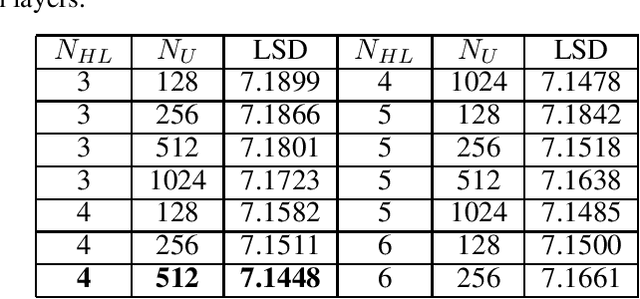
Artificial bandwidth extension is applied to speech signals to improve their quality in narrowband telephonic communication. For accomplishing this, the missing high-frequency (high-band) components of speech signals are recovered by utilizing a new extrapolation process based on sampled-data control theory and deep neural network (DNN). The $H^\infty$ sampled-data control theory helps in designing of a high-band filter to recover the high-frequency signals by optimally utilizing the inter-sample signals. Non-stationary (time-varying) characteristics of speech signals forces to use numerous high-band filters. Hence, we use a deep neural network for estimating the high-band filter information and a gain factor for a specified narrowband information of the unseen signal. The objective analysis is done on the TIMIT dataset and RSR15 dataset. Additionally, the objective analysis is performed separately for the voiced speech as well as for the unvoiced speech as generally needed in speech processing. Subjective analysis is done on the RSR15 dataset.
Abstraction of Markov Population Dynamics via Generative Adversarial Nets
Jun 24, 2021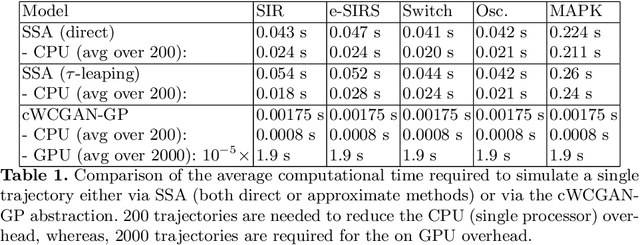
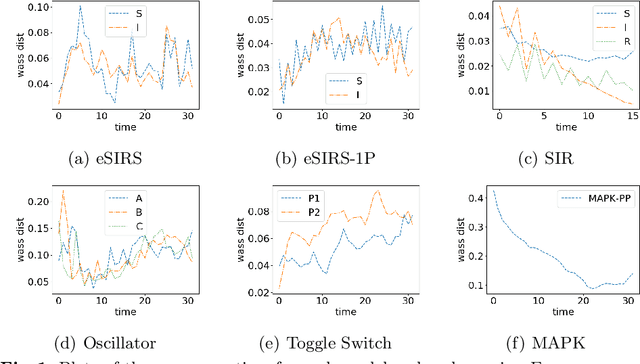
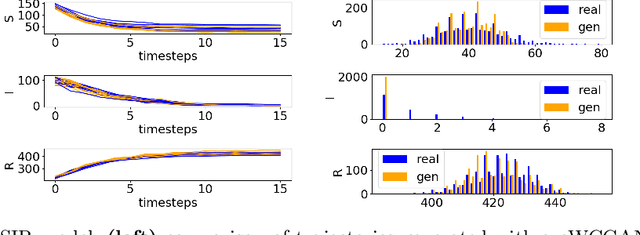
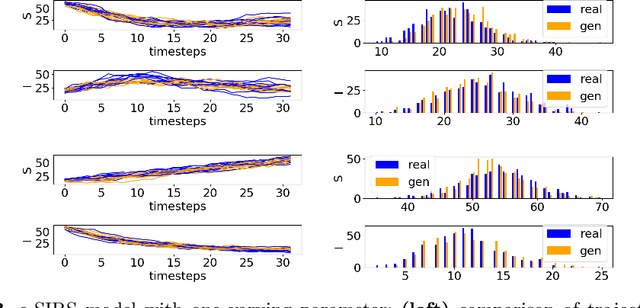
Markov Population Models are a widespread formalism used to model the dynamics of complex systems, with applications in Systems Biology and many other fields. The associated Markov stochastic process in continuous time is often analyzed by simulation, which can be costly for large or stiff systems, particularly when a massive number of simulations has to be performed (e.g. in a multi-scale model). A strategy to reduce computational load is to abstract the population model, replacing it with a simpler stochastic model, faster to simulate. Here we pursue this idea, building on previous works and constructing a generator capable of producing stochastic trajectories in continuous space and discrete time. This generator is learned automatically from simulations of the original model in a Generative Adversarial setting. Compared to previous works, which rely on deep neural networks and Dirichlet processes, we explore the use of state of the art generative models, which are flexible enough to learn a full trajectory rather than a single transition kernel.
Spectral Temporal Graph Neural Network for Trajectory Prediction
Jun 05, 2021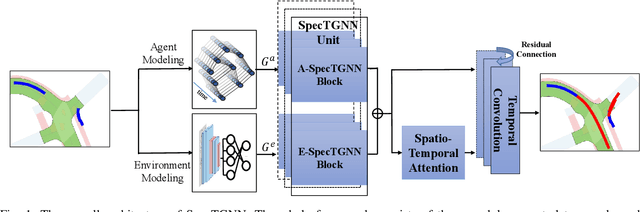
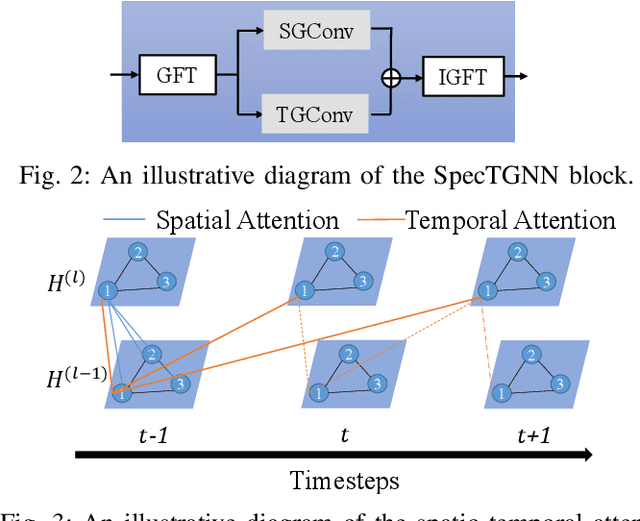
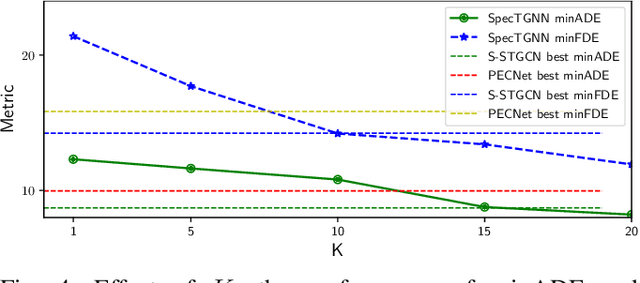
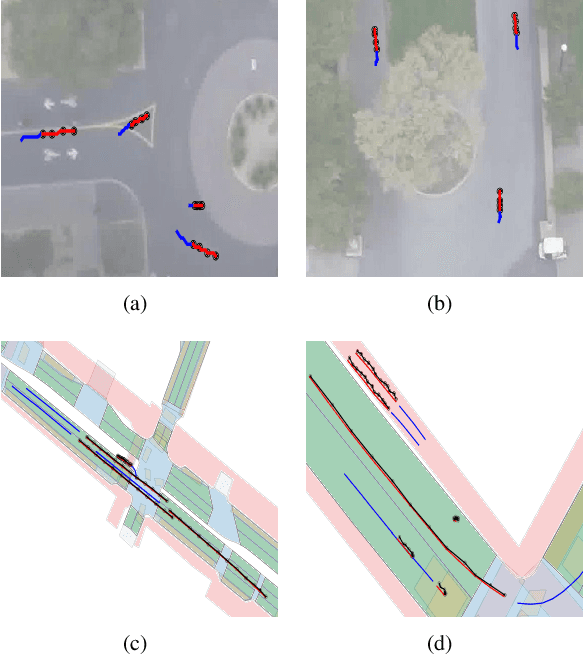
An effective understanding of the contextual environment and accurate motion forecasting of surrounding agents is crucial for the development of autonomous vehicles and social mobile robots. This task is challenging since the behavior of an autonomous agent is not only affected by its own intention, but also by the static environment and surrounding dynamically interacting agents. Previous works focused on utilizing the spatial and temporal information in time domain while not sufficiently taking advantage of the cues in frequency domain. To this end, we propose a Spectral Temporal Graph Neural Network (SpecTGNN), which can capture inter-agent correlations and temporal dependency simultaneously in frequency domain in addition to time domain. SpecTGNN operates on both an agent graph with dynamic state information and an environment graph with the features extracted from context images in two streams. The model integrates graph Fourier transform, spectral graph convolution and temporal gated convolution to encode history information and forecast future trajectories. Moreover, we incorporate a multi-head spatio-temporal attention mechanism to mitigate the effect of error propagation in a long time horizon. We demonstrate the performance of SpecTGNN on two public trajectory prediction benchmark datasets, which achieves state-of-the-art performance in terms of prediction accuracy.
Fast Hypergraph Regularized Nonnegative Tensor Ring Factorization Based on Low-Rank Approximation
Sep 06, 2021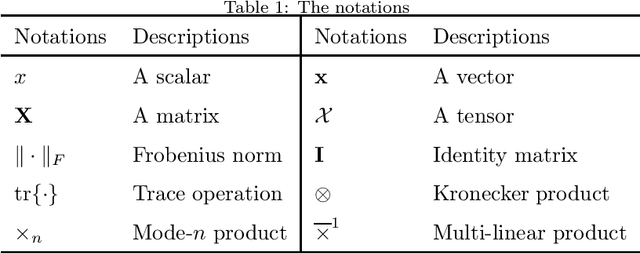
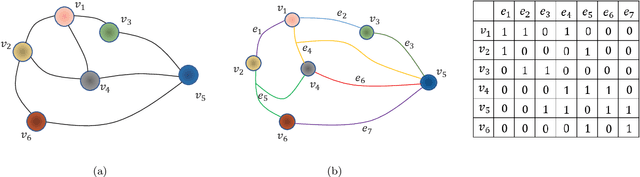
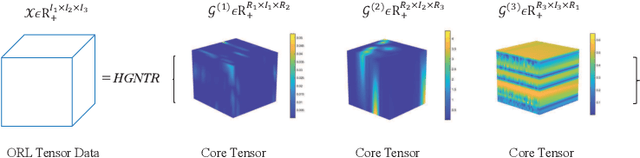
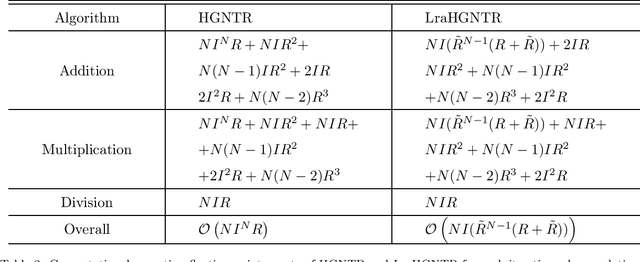
For the high dimensional data representation, nonnegative tensor ring (NTR) decomposition equipped with manifold learning has become a promising model to exploit the multi-dimensional structure and extract the feature from tensor data. However, the existing methods such as graph regularized tensor ring decomposition (GNTR) only models the pair-wise similarities of objects. For tensor data with complex manifold structure, the graph can not exactly construct similarity relationships. In this paper, in order to effectively utilize the higher-dimensional and complicated similarities among objects, we introduce hypergraph to the framework of NTR to further enhance the feature extraction, upon which a hypergraph regularized nonnegative tensor ring decomposition (HGNTR) method is developed. To reduce the computational complexity and suppress the noise, we apply the low-rank approximation trick to accelerate HGNTR (called LraHGNTR). Our experimental results show that compared with other state-of-the-art algorithms, the proposed HGNTR and LraHGNTR can achieve higher performance in clustering tasks, in addition, LraHGNTR can greatly reduce running time without decreasing accuracy.
Adaptively Aligned Image Captioning via Adaptive Attention Time
Nov 01, 2019
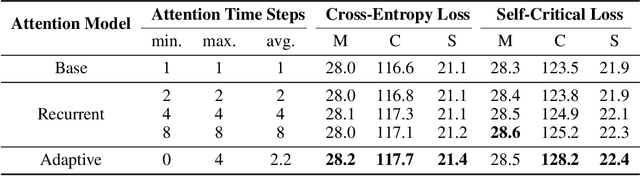
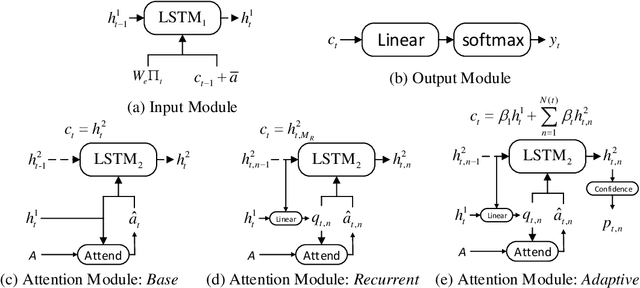

Recent neural models for image captioning usually employ an encoder-decoder framework with an attention mechanism. However, the attention mechanism in such a framework aligns one single (attended) image feature vector to one caption word, assuming one-to-one mapping from source image regions and target caption words, which is never possible. In this paper, we propose a novel attention model, namely Adaptive Attention Time (AAT), to align the source and the target adaptively for image captioning. AAT allows the framework to learn how many attention steps to take to output a caption word at each decoding step. With AAT, an image region can be mapped to an arbitrary number of caption words while a caption word can also attend to an arbitrary number of image regions. AAT is deterministic and differentiable, and doesn't introduce any noise to the parameter gradients. In this paper, we empirically show that AAT improves over state-of-the-art methods on the task of image captioning. Code is available at https://github.com/husthuaan/AAT.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.