 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluation of Thematic Coherence in Microblogs
Jun 30, 2021

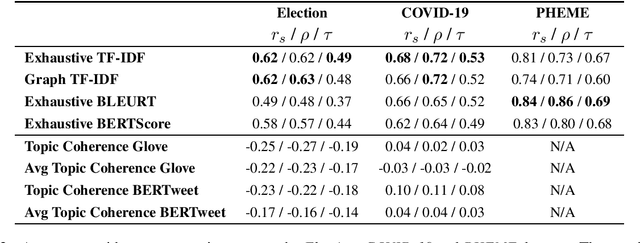


Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.
The importance of space and time in neuromorphic cognitive agents
Feb 26, 2019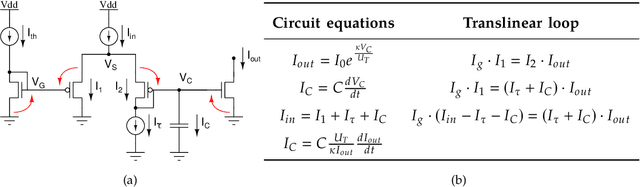
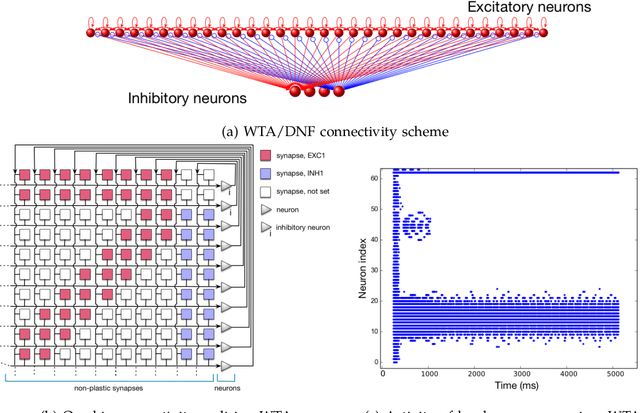
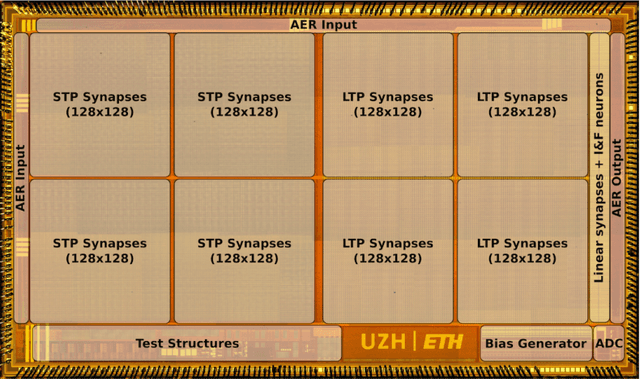
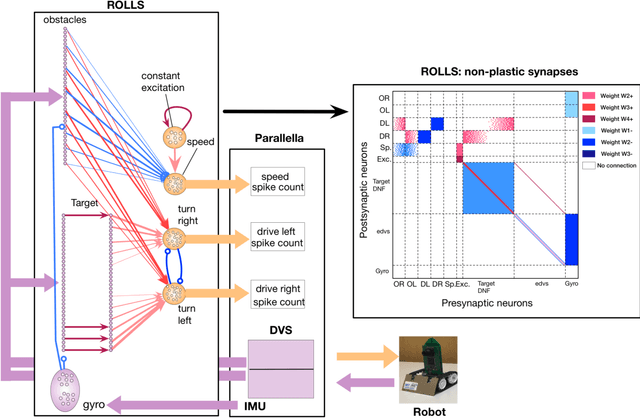
Artificial neural networks and computational neuroscience models have made tremendous progress, allowing computers to achieve impressive results in artificial intelligence (AI) applications, such as image recognition, natural language processing, or autonomous driving. Despite this remarkable progress, biological neural systems consume orders of magnitude less energy than today's artificial neural networks and are much more agile and adaptive. This efficiency and adaptivity gap is partially explained by the computing substrate of biological neural processing systems that is fundamentally different from the way today's computers are built. Biological systems use in-memory computing elements operating in a massively parallel way rather than time-multiplexed computing units that are reused in a sequential fashion. Moreover, activity of biological neurons follows continuous-time dynamics in real, physical time, instead of operating on discrete temporal cycles abstracted away from real-time. Here, we present neuromorphic processing devices that emulate the biological style of processing by using parallel instances of mixed-signal analog/digital circuits that operate in real time. We argue that this approach brings significant advantages in efficiency of computation. We show examples of embodied neuromorphic agents that use such devices to interact with the environment and exhibit autonomous learning.
Neural Network Based Model Predictive Control for an Autonomous Vehicle
Jul 30, 2021
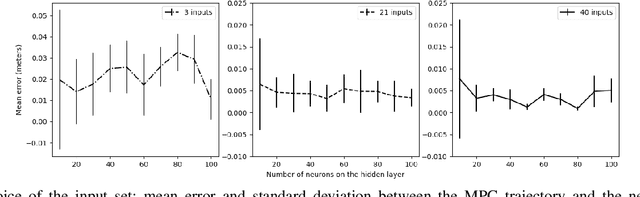
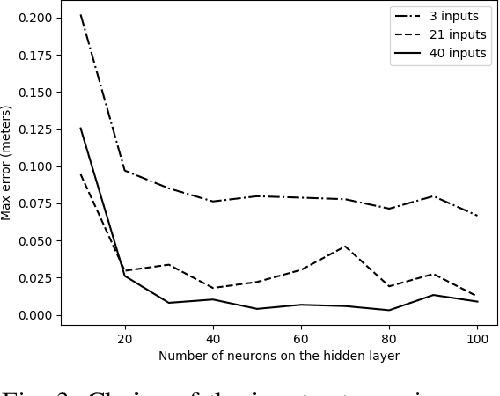
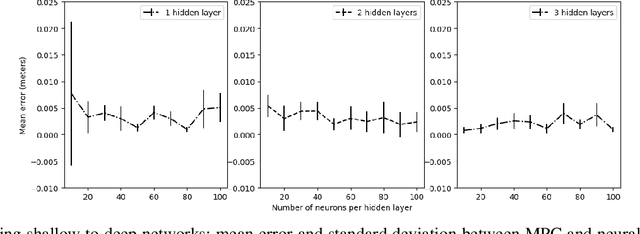
We study learning based controllers as a replacement for model predictive controllers (MPC) for the control of autonomous vehicles. We concentrate for the experiments on the simple yet representative bicycle model. We compare training by supervised learning and by reinforcement learning. We also discuss the neural net architectures so as to obtain small nets with the best performances. This work aims at producing controllers that can both be embedded on real-time platforms and amenable to verification by formal methods techniques.
A Comprehensive Evaluation of Multi-task Learning and Multi-task Pre-training on EHR Time-series Data
Jul 20, 2020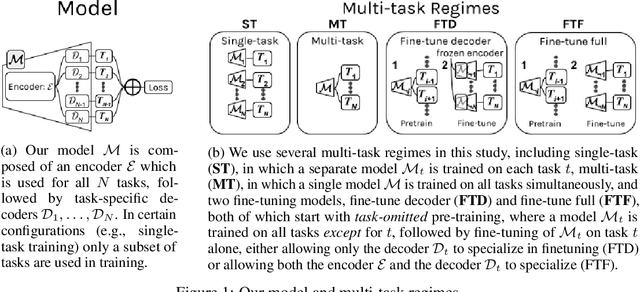
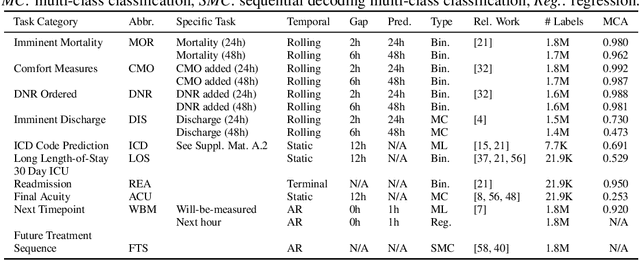
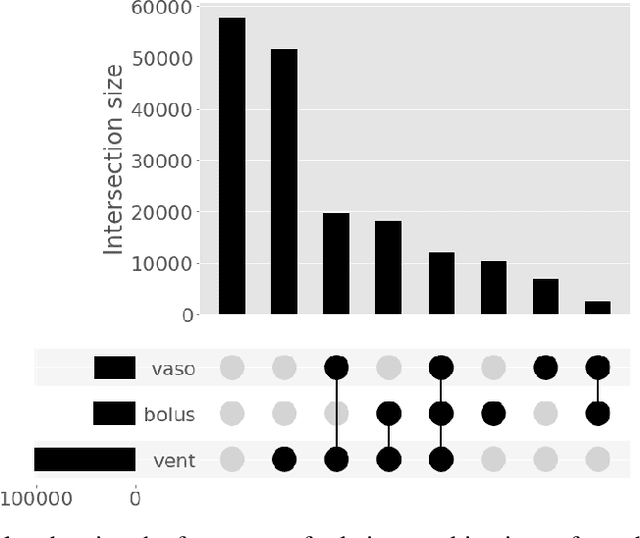
Multi-task learning (MTL) is a machine learning technique aiming to improve model performance by leveraging information across many tasks. It has been used extensively on various data modalities, including electronic health record (EHR) data. However, despite significant use on EHR data, there has been little systematic investigation of the utility of MTL across the diverse set of possible tasks and training schemes of interest in healthcare. In this work, we examine MTL across a battery of tasks on EHR time-series data. We find that while MTL does suffer from common negative transfer, we can realize significant gains via MTL pre-training combined with single-task fine-tuning. We demonstrate that these gains can be achieved in a task-independent manner and offer not only minor improvements under traditional learning, but also notable gains in a few-shot learning context, thereby suggesting this could be a scalable vehicle to offer improved performance in important healthcare contexts.
Towards Incremental Transformers: An Empirical Analysis of Transformer Models for Incremental NLU
Sep 15, 2021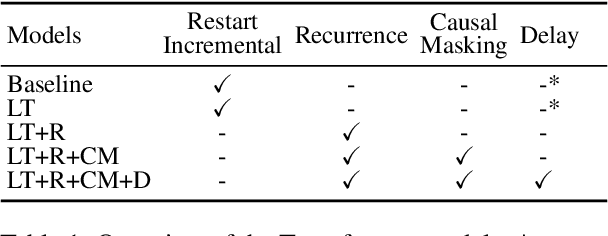
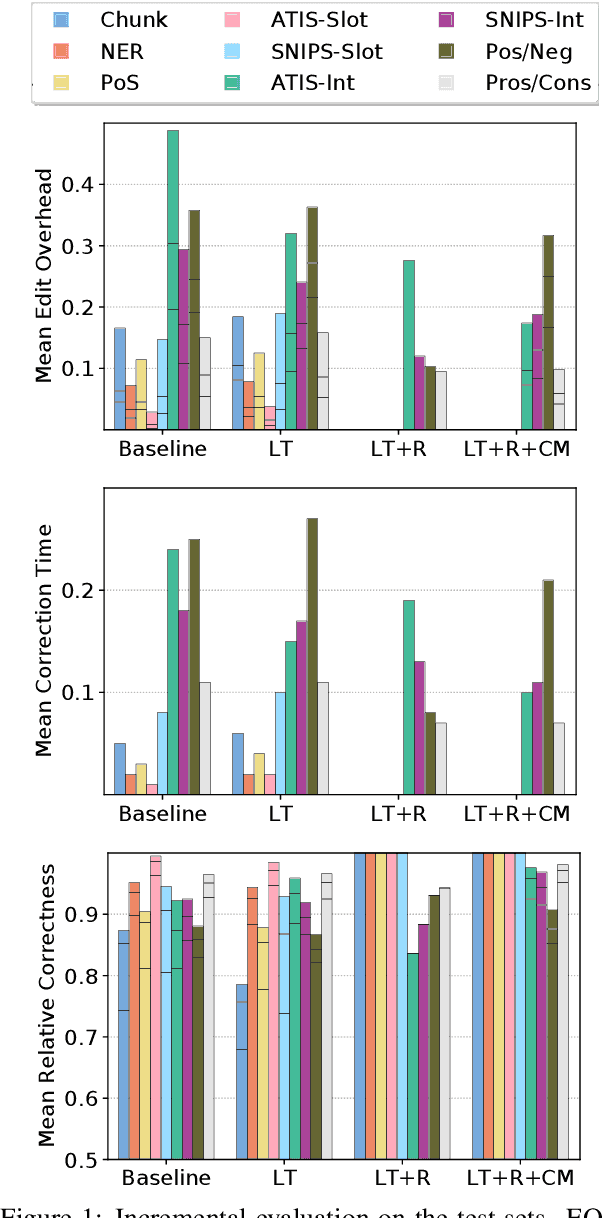
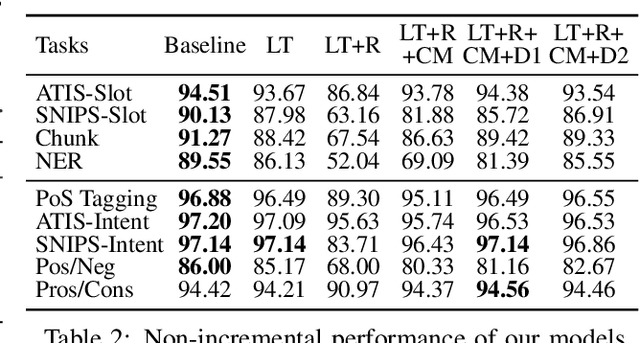
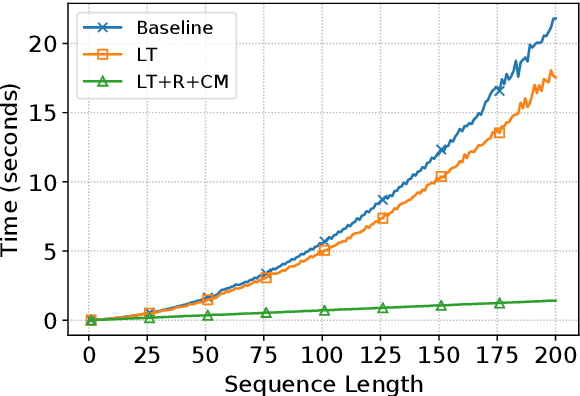
Incremental processing allows interactive systems to respond based on partial inputs, which is a desirable property e.g. in dialogue agents. The currently popular Transformer architecture inherently processes sequences as a whole, abstracting away the notion of time. Recent work attempts to apply Transformers incrementally via restart-incrementality by repeatedly feeding, to an unchanged model, increasingly longer input prefixes to produce partial outputs. However, this approach is computationally costly and does not scale efficiently for long sequences. In parallel, we witness efforts to make Transformers more efficient, e.g. the Linear Transformer (LT) with a recurrence mechanism. In this work, we examine the feasibility of LT for incremental NLU in English. Our results show that the recurrent LT model has better incremental performance and faster inference speed compared to the standard Transformer and LT with restart-incrementality, at the cost of part of the non-incremental (full sequence) quality. We show that the performance drop can be mitigated by training the model to wait for right context before committing to an output and that training with input prefixes is beneficial for delivering correct partial outputs.
A Generalized Theory of Power
Sep 08, 2021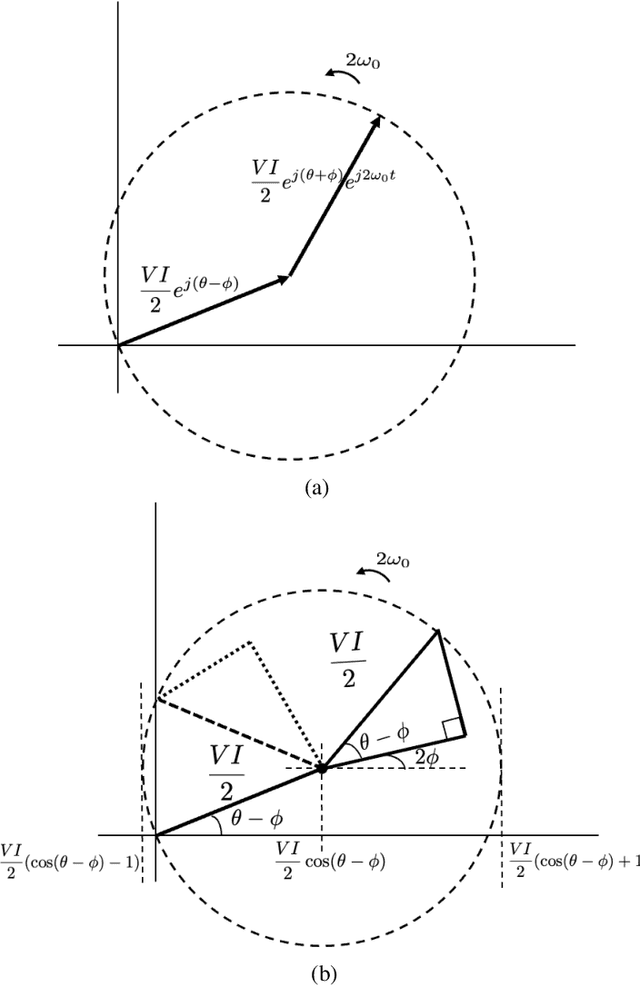
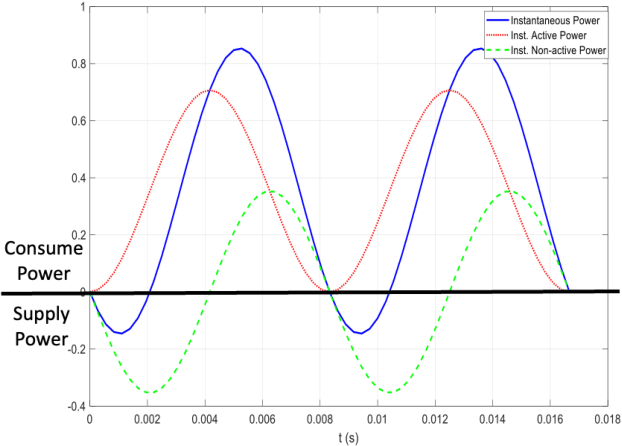
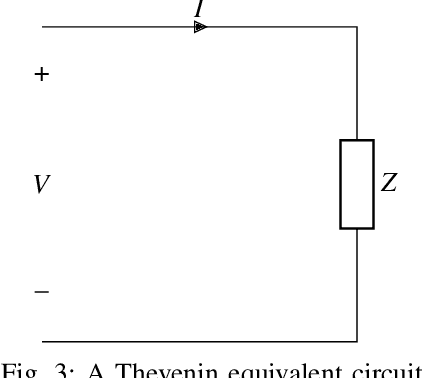
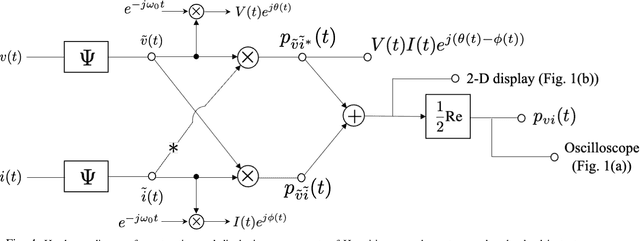
The complex representation of real-valued instantaneous power may be written as the sum of two complex powers, one Hermitian and the other non-Hermitian, or complementary. A virtue of this representation is that it consists of a power triangle rotating around a fixed phasor, thus clarifying what should be meant by the power triangle. The in-phase and quadrature components of complementary power encode for active and non-active power. When instantaneous power is defined for a Thevenin equivalent circuit, these are time-varying real and reactive power components. These claims hold for sinusoidal voltage and current, and for non-sinusoidal voltage and current. Spectral representations of Hermitian, complementary, and instantaneous power show that, frequency-by-frequency, these powers behave exactly as they behave in the single frequency sinusoidal case. Simple hardware diagrams show how instantaneous active and non-active power may be extracted from metered voltage and current, even in certain non-sinusoidal cases.
GPU Accelerated Batch Multi-Convex Trajectory Optimization for a Rectangular Holonomic Mobile Robot
Sep 27, 2021
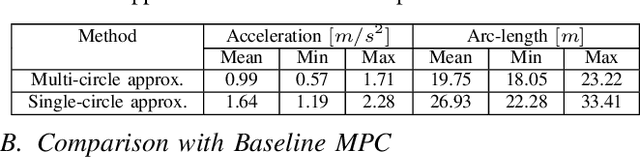
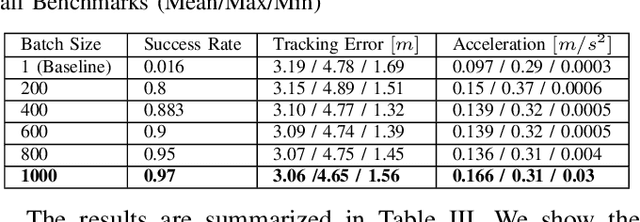
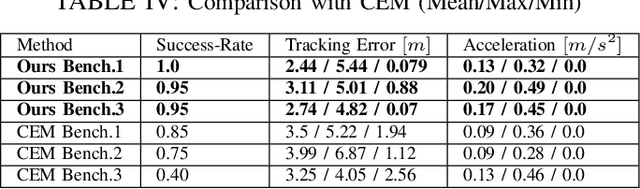
We present a batch trajectory optimizer that can simultaneously solve hundreds of different instances of the problem in real-time. We consider holonomic robots but relax the assumption of circular base footprint. Our main algorithmic contributions lie in: (i) improving the computational tractability of the underlying non-convex problem and (ii) leveraging batch computation to mitigate initialization bottlenecks and improve solution quality. We achieve both goals by deriving a multi-convex reformulation of the kinematics and collision avoidance constraints. We exploit these structures through an Alternating Minimization approach and show that the resulting batch operation reduces to computing just matrix-vector products that can be trivially accelerated over GPUs. We improve the state-of-the-art in three respects. First, we improve quality of navigation (success-rate, tracking) as compared to baseline approach that relies on computing a single locally optimal trajectory at each control loop. Second, we show that when initialized with trajectory samples from a Gaussian distribution, our batch optimizer outperforms state-of-the-art cross-entropy method in solution quality. Finally, our batch optimizer is several orders of magnitude faster than the conceptually simpler alternative of running different optimization instances in parallel CPU threads. \textbf{Codes:} \url{https://tinyurl.com/a3b99m8}
Proceedings of the 1st International Workshop on Adaptive Cyber Defense
Aug 19, 2021The 1st International Workshop on Adaptive Cyber Defense was held as part of the 2021 International Joint Conference on Artificial Intelligence. This workshop was organized to share research that explores unique applications of Artificial Intelligence (AI) and Machine Learning (ML) as foundational capabilities for the pursuit of adaptive cyber defense. The cyber domain cannot currently be reliably and effectively defended without extensive reliance on human experts. Skilled cyber defenders are in short supply and often cannot respond fast enough to cyber threats. Building on recent advances in AI and ML the Cyber defense research community has been motivated to develop new dynamic and sustainable defenses through the adoption of AI and ML techniques to both cyber and non-cyber settings. Bridging critical gaps between AI and Cyber researchers and practitioners can accelerate efforts to create semi-autonomous cyber defenses that can learn to recognize and respond to cyber attacks or discover and mitigate weaknesses in cooperation with other cyber operation systems and human experts. Furthermore, these defenses are expected to be adaptive and able to evolve over time to thwart changes in attacker behavior, changes in the system health and readiness, and natural shifts in user behavior over time. The Workshop (held on August 19th and 20th 2021 in Montreal-themed virtual reality) was comprised of technical presentations and a panel discussion focused on open problems and potential research solutions. Workshop submissions were peer reviewed by a panel of domain experts with a proceedings consisting of 10 technical articles exploring challenging problems of critical importance to national and global security. Participation in this workshop offered new opportunities to stimulate research and innovation in the emerging domain of adaptive and autonomous cyber defense.
Automatic Detection Of Noise Events at Shooting Range Using Machine Learning
Jul 23, 2021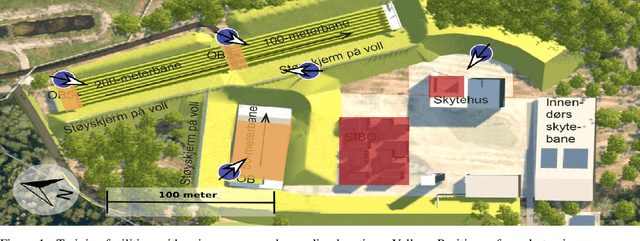
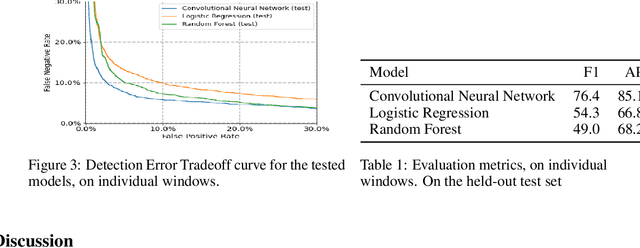
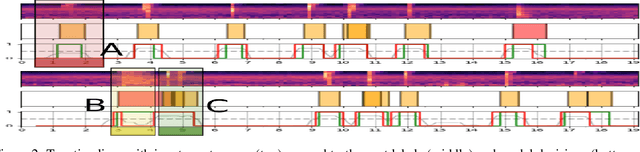

Outdoor shooting ranges are subject to noise regulations from local and national authorities. Restrictions found in these regulations may include limits on times of activities, the overall number of noise events, as well as limits on number of events depending on the class of noise or activity. A noise monitoring system may be used to track overall sound levels, but rarely provide the ability to detect activity or count the number of events, required to compare directly with such regulations. This work investigates the feasibility and performance of an automatic detection system to count noise events. An empirical evaluation was done by collecting data at a newly constructed shooting range and training facility. The data includes tests of multiple weapon configurations from small firearms to high caliber rifles and explosives, at multiple source positions, and collected on multiple different days. Several alternative machine learning models are tested, using as inputs time-series of standard acoustic indicators such as A-weighted sound levels and 1/3 octave spectrogram, and classifiers such as Logistic Regression and Convolutional Neural Networks. Performance for the various alternatives are reported in terms of the False Positive Rate and False Negative Rate. The detection performance was found to be satisfactory for use in automatic logging of time-periods with training activity.
Effective Sequence-to-Sequence Dialogue State Tracking
Sep 08, 2021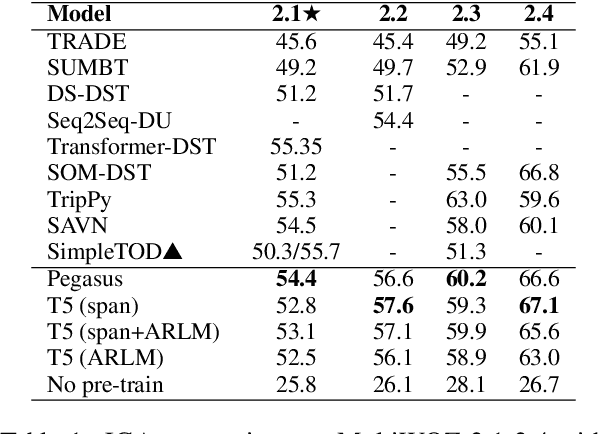
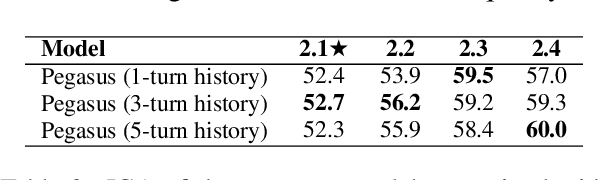
Sequence-to-sequence models have been applied to a wide variety of NLP tasks, but how to properly use them for dialogue state tracking has not been systematically investigated. In this paper, we study this problem from the perspectives of pre-training objectives as well as the formats of context representations. We demonstrate that the choice of pre-training objective makes a significant difference to the state tracking quality. In particular, we find that masked span prediction is more effective than auto-regressive language modeling. We also explore using Pegasus, a span prediction-based pre-training objective for text summarization, for the state tracking model. We found that pre-training for the seemingly distant summarization task works surprisingly well for dialogue state tracking. In addition, we found that while recurrent state context representation works also reasonably well, the model may have a hard time recovering from earlier mistakes. We conducted experiments on the MultiWOZ 2.1-2.4, WOZ 2.0, and DSTC2 datasets with consistent observations.