 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TuSeRACT: Turn-Sample-Based Real-Time Traffic Signal Control
Dec 13, 2018
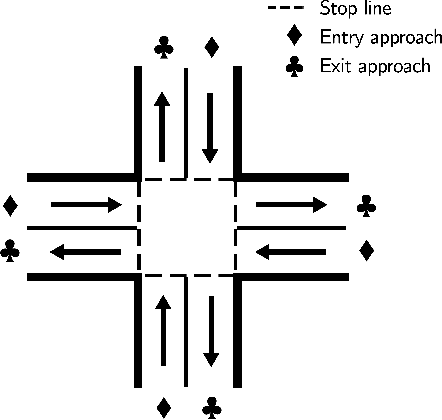
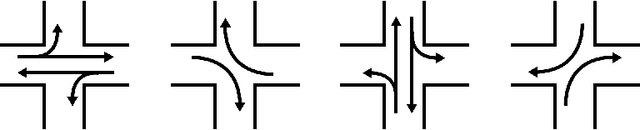
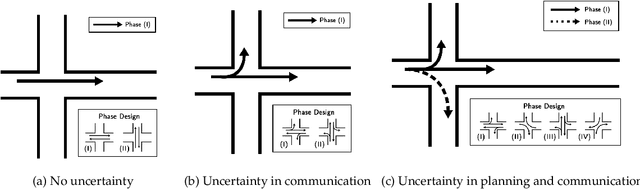
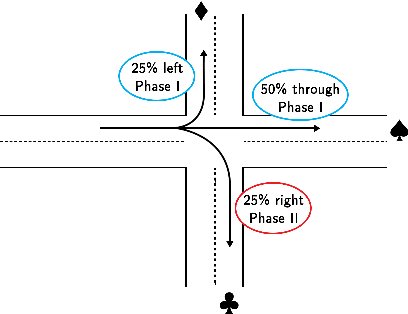
Real-time traffic signal control systems can effectively reduce urban traffic congestion but can also become significant contributors to congestion if poorly timed. Real-time traffic signal control is typically challenging owing to constantly changing traffic demand patterns, very limited planning time and various sources of uncertainty in the real world (due to vehicle detection or unobserved vehicle turn movements, for instance). SURTRAC (Scalable URban TRAffic Control) is a recently developed traffic signal control approach which computes delay-minimising and coordinated (across neighbouring traffic lights) schedules of oncoming vehicle clusters in real time. To ensure real-time responsiveness in the presence of turn-induced uncertainty, SURTRAC computes schedules which minimize the delay for the expected turn movements as opposed to minimizing the expected delay under turn-induced uncertainty. Furthermore, expected outgoing traffic clusters are communicated to downstream intersections. These approximations ensure real-time tractability, but degrade solution quality in the presence of turn-induced uncertainty. To address this limitation, we introduce TuSeRACT (Turn-Sample-based Real-time trAffic signal ConTrol), a distributed sample-based scheduling approach to traffic signal control. Unlike SURTRAC, TuSeRACT computes schedules that minimize expected delay over sampled turn movements of observed traffic, and communicates samples of traffic outflows to neighbouring intersections. We formulate this sample-based scheduling problem as a constraint program, and empirically evaluate our approach on synthetic traffic networks. We demonstrate that our approach results in substantially lower average vehicle waiting times as compared to SURTRAC when turn-induced uncertainty is present.
Real-Time EEG Classification via Coresets for BCI Applications
Jan 02, 2019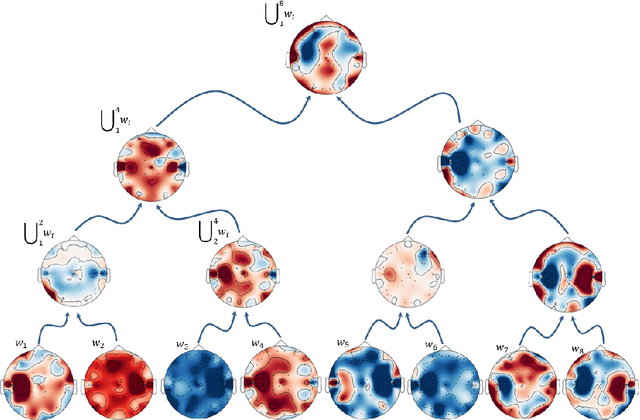

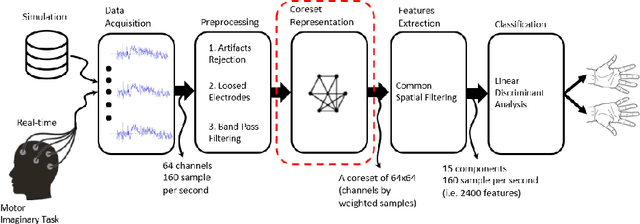
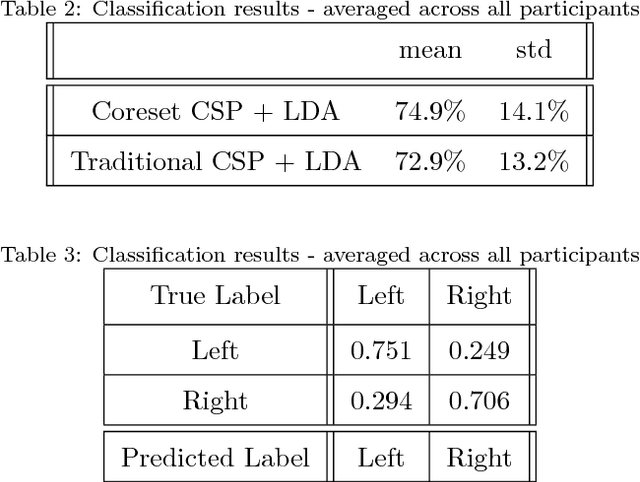
A brain-computer interface (BCI) based on the motor imagery (MI) paradigm translates one's motor intention into a control signal by classifying the Electroencephalogram (EEG) signal of different tasks. However, most existing systems either (i) use a high-quality algorithm to train the data off-line and run only classification in real-time, since the off-line algorithm is too slow, or (ii) use low-quality heuristics that are sufficiently fast for real-time training but introduces relatively large classification error. In this work, we propose a novel processing pipeline that allows real-time and parallel learning of EEG signals using high-quality but possibly inefficient algorithms. This is done by forging a link between BCI and core-sets, a technique that originated in computational geometry for handling streaming data via data summarization. We suggest an algorithm that maintains the representation such coreset tailored to handle the EEG signal which enables: (i) real time and continuous computation of the Common Spatial Pattern (CSP) feature extraction method on a coreset representation of the signal (instead on the signal itself) , (ii) improvement of the CSP algorithm efficiency with provable guarantees by applying CSP algorithm on the coreset, and (iii) real time addition of the data trials (EEG data windows) to the coreset. For simplicity, we focus on the CSP algorithm, which is a classic algorithm. Nevertheless, we expect that our coreset will be extended to other algorithms in future papers. In the experimental results we show that our system can indeed learn EEG signals in real-time for example a 64 channels setup with hundreds of time samples per second. Full open source is provided to reproduce the experiment and in the hope that it will be used and extended to more coresets and BCI applications in the future.
Unsupervised Landmark Detection Based Spatiotemporal Motion Estimation for 4D Dynamic Medical Images
Oct 12, 2021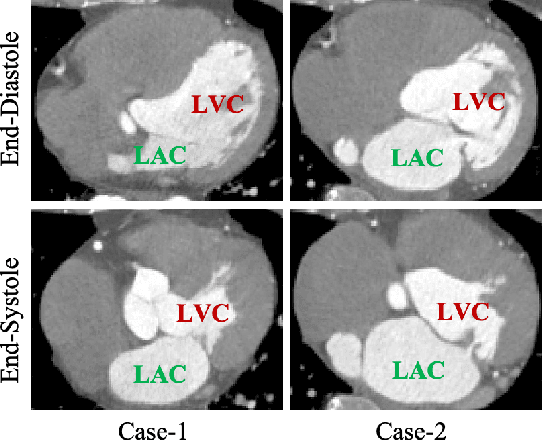

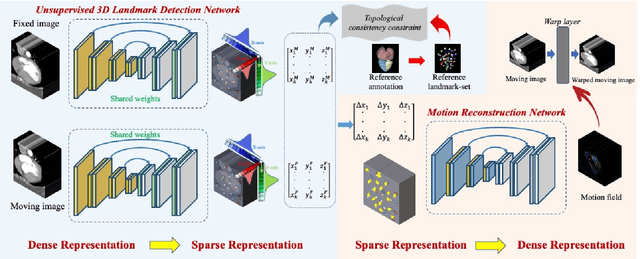
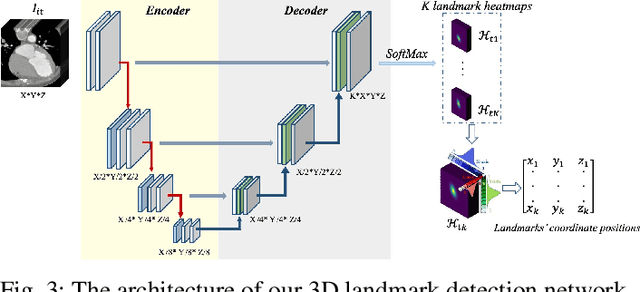
Motion estimation is a fundamental step in dynamic medical image processing for the assessment of target organ anatomy and function. However, existing image-based motion estimation methods, which optimize the motion field by evaluating the local image similarity, are prone to produce implausible estimation, especially in the presence of large motion. In this study, we provide a novel motion estimation framework of Dense-Sparse-Dense (DSD), which comprises two stages. In the first stage, we process the raw dense image to extract sparse landmarks to represent the target organ anatomical topology and discard the redundant information that is unnecessary for motion estimation. For this purpose, we introduce an unsupervised 3D landmark detection network to extract spatially sparse but representative landmarks for the target organ motion estimation. In the second stage, we derive the sparse motion displacement from the extracted sparse landmarks of two images of different time points. Then, we present a motion reconstruction network to construct the motion field by projecting the sparse landmarks displacement back into the dense image domain. Furthermore, we employ the estimated motion field from our two-stage DSD framework as initialization and boost the motion estimation quality in light-weight yet effective iterative optimization. We evaluate our method on two dynamic medical imaging tasks to model cardiac motion and lung respiratory motion, respectively. Our method has produced superior motion estimation accuracy compared to existing comparative methods. Besides, the extensive experimental results demonstrate that our solution can extract well representative anatomical landmarks without any requirement of manual annotation. Our code is publicly available online.
A scalable and fast artificial neural network syndrome decoder for surface codes
Oct 12, 2021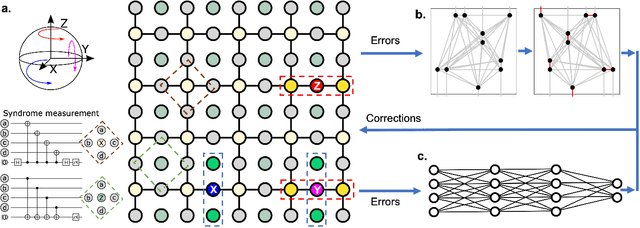
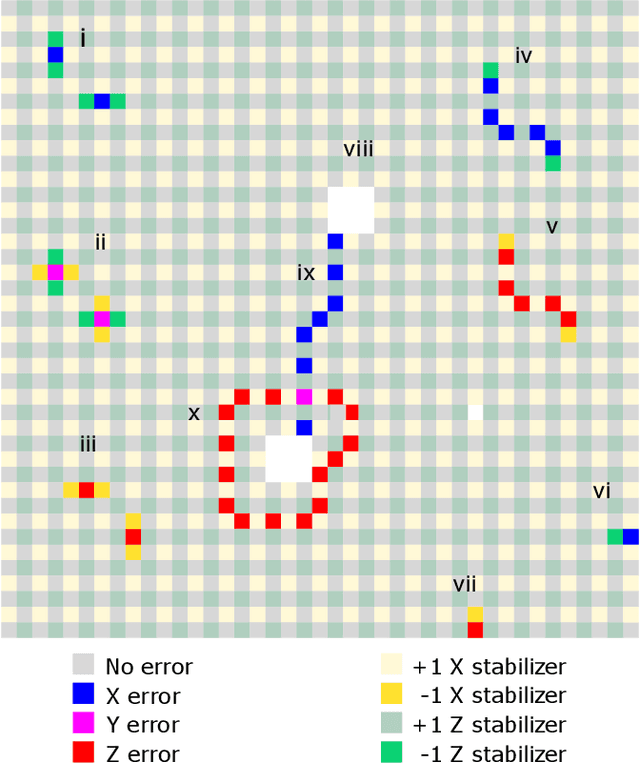
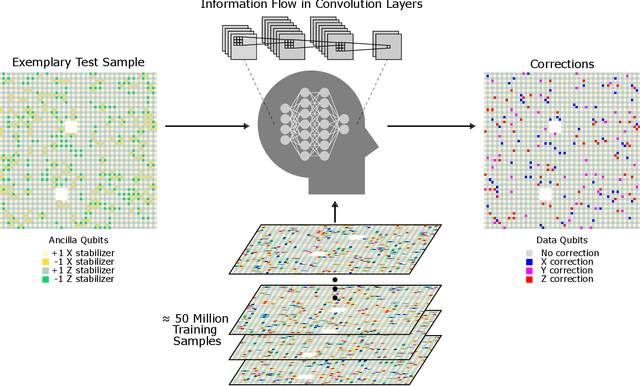
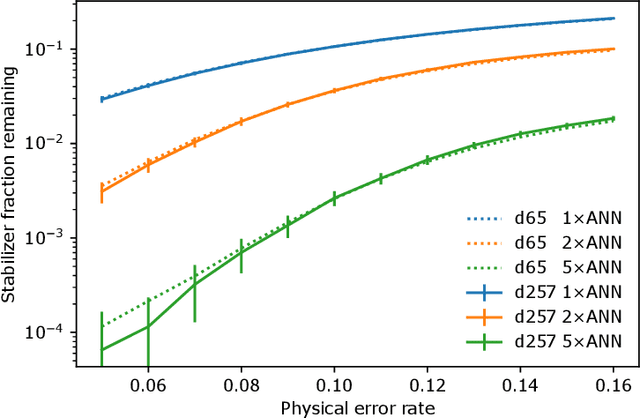
Surface code error correction offers a highly promising pathway to achieve scalable fault-tolerant quantum computing. When operated as stabilizer codes, surface code computations consist of a syndrome decoding step where measured stabilizer operators are used to determine appropriate corrections for errors in physical qubits. Decoding algorithms have undergone substantial development, with recent work incorporating machine learning (ML) techniques. Despite promising initial results, the ML-based syndrome decoders are still limited to small scale demonstrations with low latency and are incapable of handling surface codes with boundary conditions and various shapes needed for lattice surgery and braiding. Here, we report the development of an artificial neural network (ANN) based scalable and fast syndrome decoder capable of decoding surface codes of arbitrary shape and size with data qubits suffering from the depolarizing error model. Based on rigorous training over 50 million random quantum error instances, our ANN decoder is shown to work with code distances exceeding 1000 (more than 4 million physical qubits), which is the largest ML-based decoder demonstration to-date. The established ANN decoder demonstrates an execution time in principle independent of code distance, implying that its implementation on dedicated hardware could potentially offer surface code decoding times of O($\mu$sec), commensurate with the experimentally realisable qubit coherence times. With the anticipated scale-up of quantum processors within the next decade, their augmentation with a fast and scalable syndrome decoder such as developed in our work is expected to play a decisive role towards experimental implementation of fault-tolerant quantum information processing.
Automated triaging of head MRI examinations using convolutional neural networks
Jun 15, 2021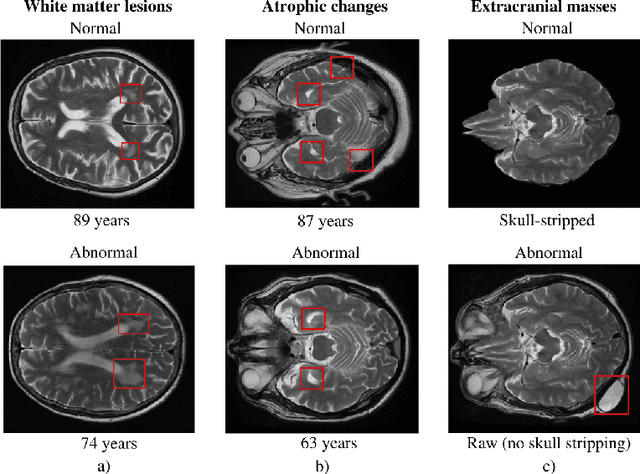
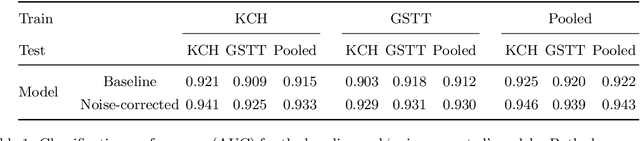
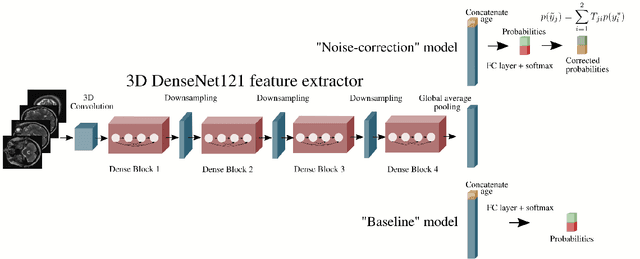
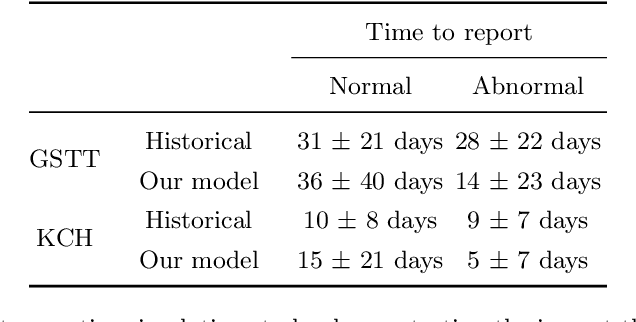
The growing demand for head magnetic resonance imaging (MRI) examinations, along with a global shortage of radiologists, has led to an increase in the time taken to report head MRI scans around the world. For many neurological conditions, this delay can result in increased morbidity and mortality. An automated triaging tool could reduce reporting times for abnormal examinations by identifying abnormalities at the time of imaging and prioritizing the reporting of these scans. In this work, we present a convolutional neural network for detecting clinically-relevant abnormalities in $\text{T}_2$-weighted head MRI scans. Using a validated neuroradiology report classifier, we generated a labelled dataset of 43,754 scans from two large UK hospitals for model training, and demonstrate accurate classification (area under the receiver operating curve (AUC) = 0.943) on a test set of 800 scans labelled by a team of neuroradiologists. Importantly, when trained on scans from only a single hospital the model generalized to scans from the other hospital ($\Delta$AUC $\leq$ 0.02). A simulation study demonstrated that our model would reduce the mean reporting time for abnormal examinations from 28 days to 14 days and from 9 days to 5 days at the two hospitals, demonstrating feasibility for use in a clinical triage environment.
Inferring Temporal Logic Properties from Data using Boosted Decision Trees
May 24, 2021
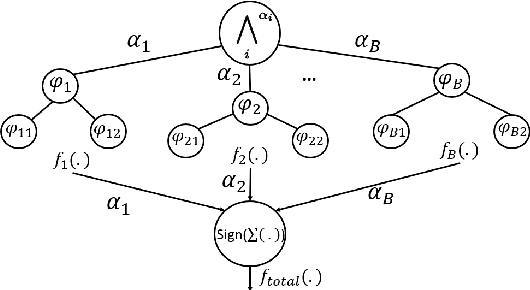
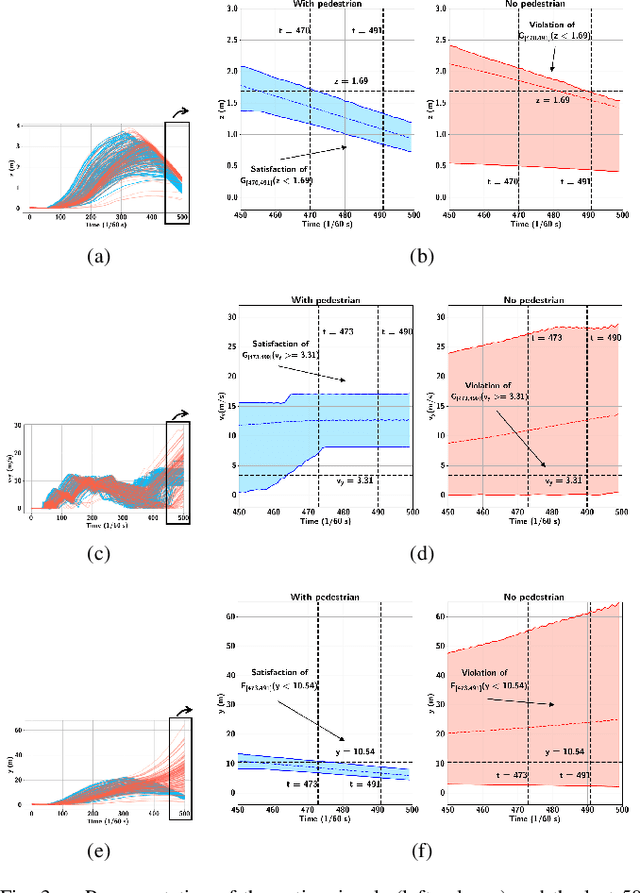
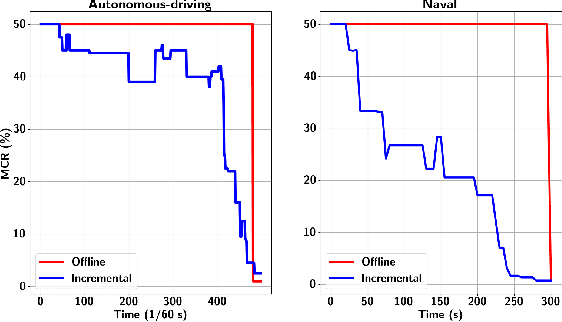
Many autonomous systems, such as robots and self-driving cars, involve real-time decision making in complex environments, and require prediction of future outcomes from limited data. Moreover, their decisions are increasingly required to be interpretable to humans for safe and trustworthy co-existence. This paper is a first step towards interpretable learning-based robot control. We introduce a novel learning problem, called incremental formula and predictor learning, to generate binary classifiers with temporal logic structure from time-series data. The classifiers are represented as pairs of Signal Temporal Logic (STL) formulae and predictors for their satisfaction. The incremental property provides prediction of labels for prefix signals that are revealed over time. We propose a boosted decision-tree algorithm that leverages weak, but computationally inexpensive, learners to increase prediction and runtime performance. The effectiveness and classification accuracy of our algorithms are evaluated on autonomous-driving and naval surveillance case studies.
Out-of-Distribution Dynamics Detection: RL-Relevant Benchmarks and Results
Jul 11, 2021
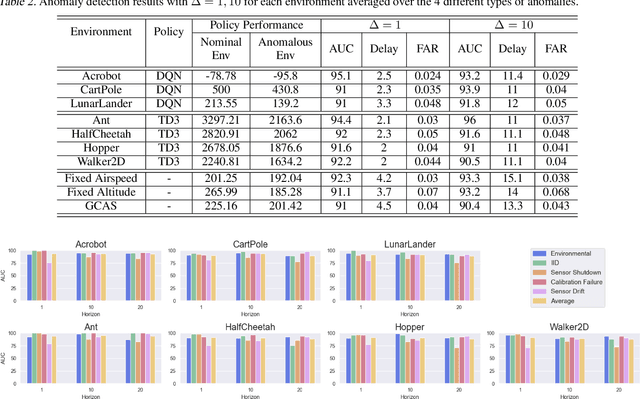
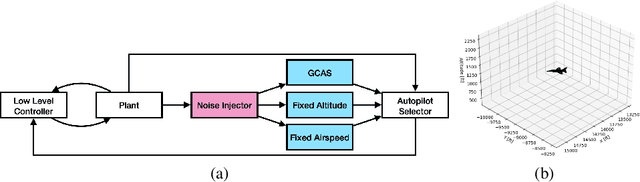
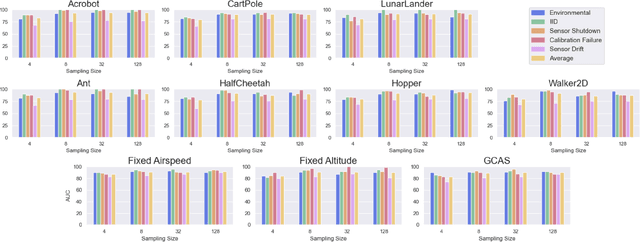
We study the problem of out-of-distribution dynamics (OODD) detection, which involves detecting when the dynamics of a temporal process change compared to the training-distribution dynamics. This is relevant to applications in control, reinforcement learning (RL), and multi-variate time-series, where changes to test time dynamics can impact the performance of learning controllers/predictors in unknown ways. This problem is particularly important in the context of deep RL, where learned controllers often overfit to the training environment. Currently, however, there is a lack of established OODD benchmarks for the types of environments commonly used in RL research. Our first contribution is to design a set of OODD benchmarks derived from common RL environments with varying types and intensities of OODD. Our second contribution is to design a strong OODD baseline approach based on recurrent implicit quantile networks (RIQNs), which monitors autoregressive prediction errors for OODD detection. Our final contribution is to evaluate the RIQN approach on the benchmarks to provide baseline results for future comparison.
Towards Incremental Transformers: An Empirical Analysis of Transformer Models for Incremental NLU
Sep 15, 2021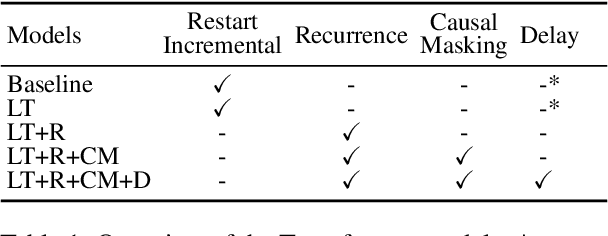
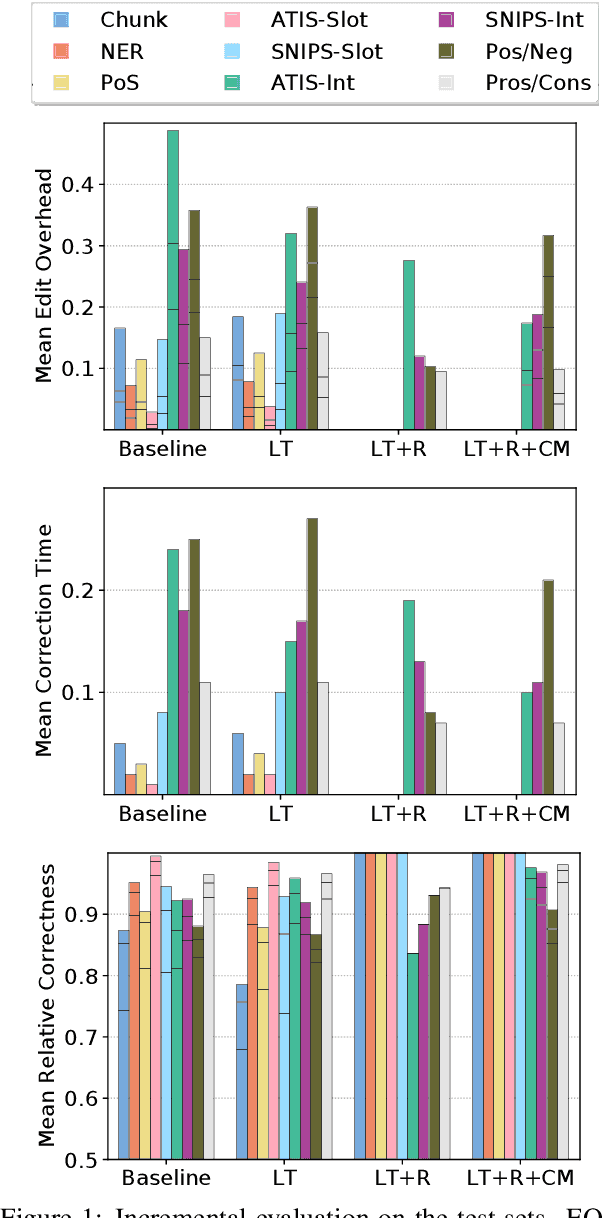
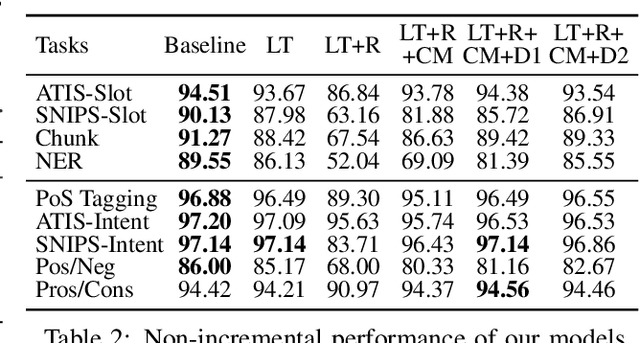
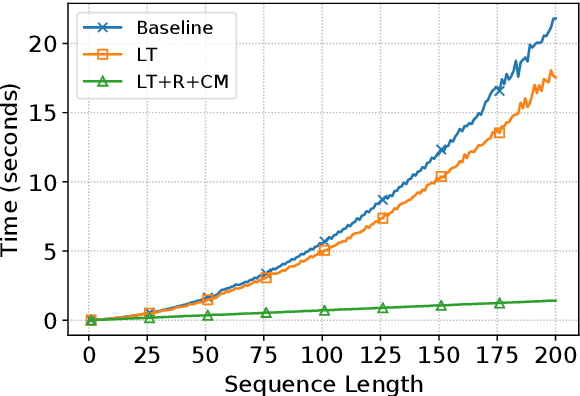
Incremental processing allows interactive systems to respond based on partial inputs, which is a desirable property e.g. in dialogue agents. The currently popular Transformer architecture inherently processes sequences as a whole, abstracting away the notion of time. Recent work attempts to apply Transformers incrementally via restart-incrementality by repeatedly feeding, to an unchanged model, increasingly longer input prefixes to produce partial outputs. However, this approach is computationally costly and does not scale efficiently for long sequences. In parallel, we witness efforts to make Transformers more efficient, e.g. the Linear Transformer (LT) with a recurrence mechanism. In this work, we examine the feasibility of LT for incremental NLU in English. Our results show that the recurrent LT model has better incremental performance and faster inference speed compared to the standard Transformer and LT with restart-incrementality, at the cost of part of the non-incremental (full sequence) quality. We show that the performance drop can be mitigated by training the model to wait for right context before committing to an output and that training with input prefixes is beneficial for delivering correct partial outputs.
A Generalized Theory of Power
Sep 08, 2021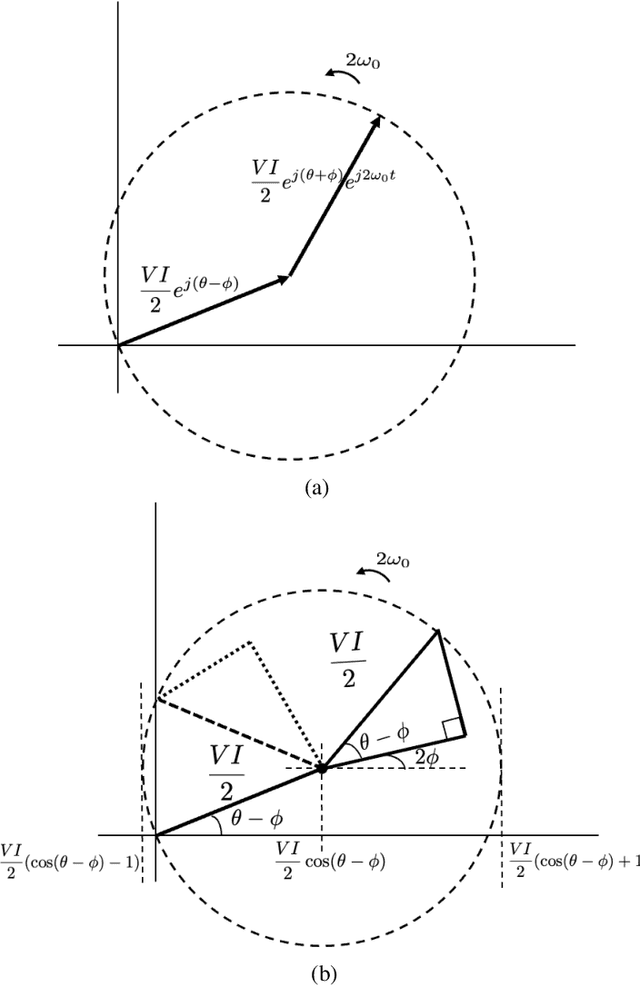
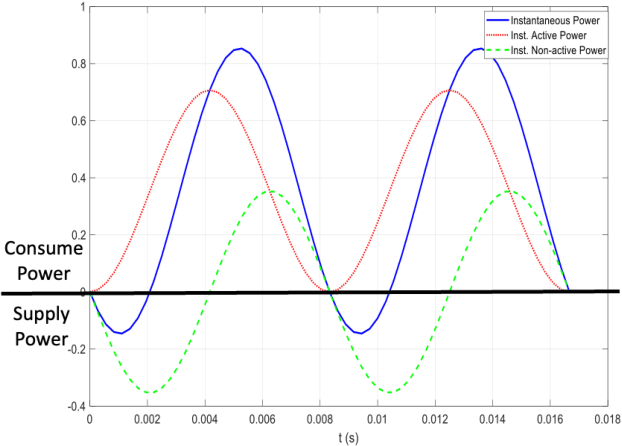
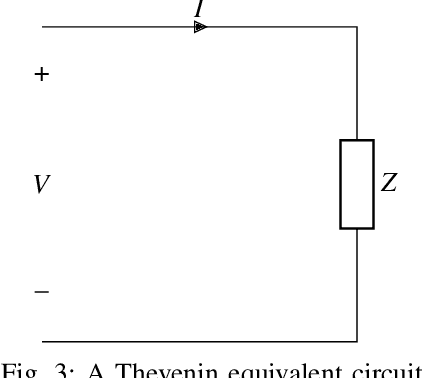
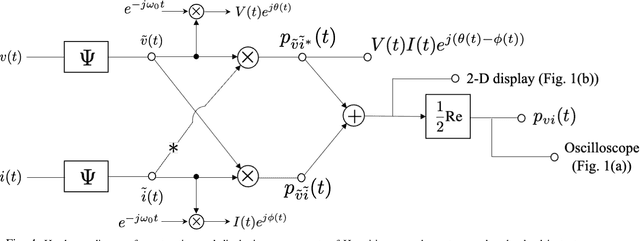
The complex representation of real-valued instantaneous power may be written as the sum of two complex powers, one Hermitian and the other non-Hermitian, or complementary. A virtue of this representation is that it consists of a power triangle rotating around a fixed phasor, thus clarifying what should be meant by the power triangle. The in-phase and quadrature components of complementary power encode for active and non-active power. When instantaneous power is defined for a Thevenin equivalent circuit, these are time-varying real and reactive power components. These claims hold for sinusoidal voltage and current, and for non-sinusoidal voltage and current. Spectral representations of Hermitian, complementary, and instantaneous power show that, frequency-by-frequency, these powers behave exactly as they behave in the single frequency sinusoidal case. Simple hardware diagrams show how instantaneous active and non-active power may be extracted from metered voltage and current, even in certain non-sinusoidal cases.
Evaluation of Thematic Coherence in Microblogs
Jun 30, 2021
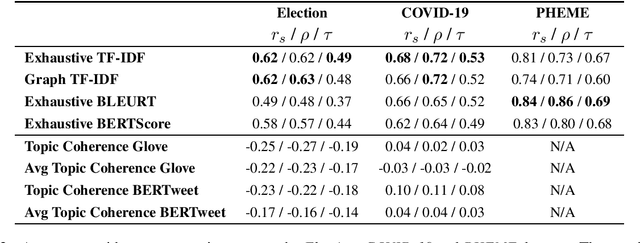


Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.