 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tell Me How to Survey: Literature Review Made Simple with Automatic Reading Path Generation
Oct 12, 2021
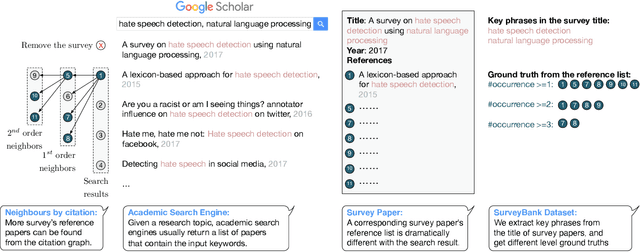
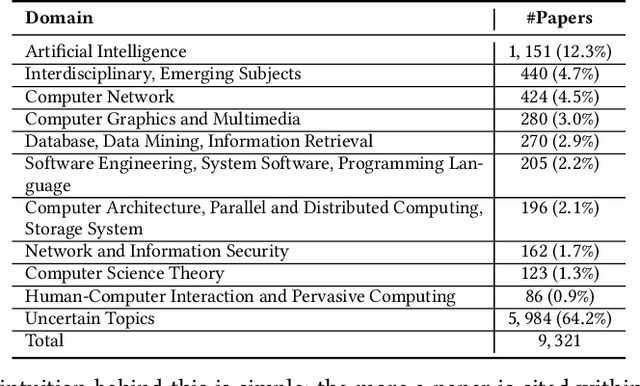
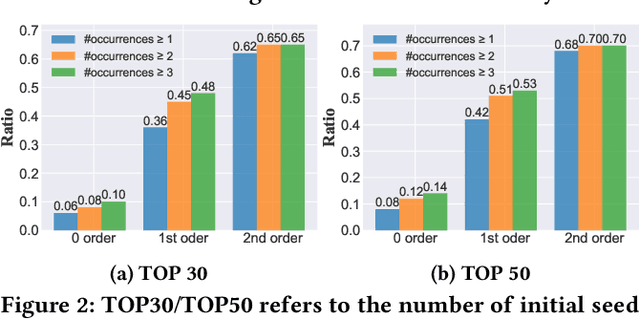

Recent years have witnessed the dramatic growth of paper volumes with plenty of new research papers published every day, especially in the area of computer science. How to glean papers worth reading from the massive literature to do a quick survey or keep up with the latest advancement about a specific research topic has become a challenging task. Existing academic search engines such as Google Scholar return relevant papers by individually calculating the relevance between each paper and query. However, such systems usually omit the prerequisite chains of a research topic and cannot form a meaningful reading path. In this paper, we introduce a new task named Reading Path Generation (RPG) which aims at automatically producing a path of papers to read for a given query. To serve as a research benchmark, we further propose SurveyBank, a dataset consisting of large quantities of survey papers in the field of computer science as well as their citation relationships. Each survey paper contains key phrases extracted from its title and multi-level reading lists inferred from its references. Furthermore, we propose a graph-optimization-based approach for reading path generation which takes the relationship between papers into account. Extensive evaluations demonstrate that our approach outperforms other baselines. A Real-time Reading Path Generation System (RePaGer) has been also implemented with our designed model. To the best of our knowledge, we are the first to target this important research problem. Our source code of RePaGer system and SurveyBank dataset can be found on here.
Multiwavelet-based Operator Learning for Differential Equations
Sep 28, 2021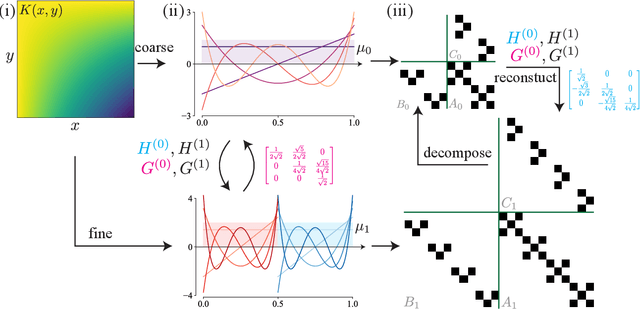
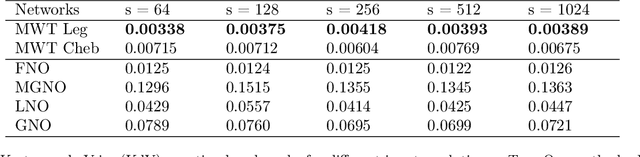
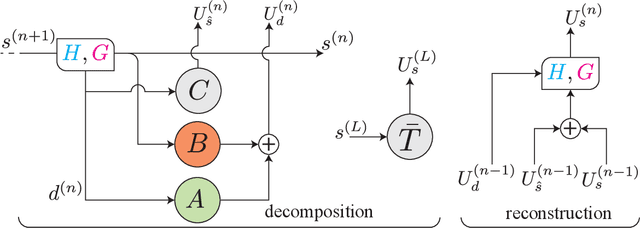
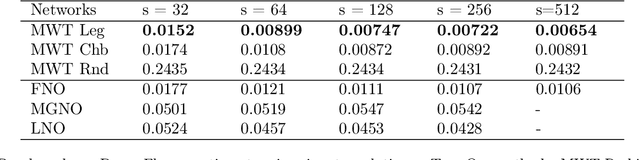
The solution of a partial differential equation can be obtained by computing the inverse operator map between the input and the solution space. Towards this end, we introduce a \textit{multiwavelet-based neural operator learning scheme} that compresses the associated operator's kernel using fine-grained wavelets. By explicitly embedding the inverse multiwavelet filters, we learn the projection of the kernel onto fixed multiwavelet polynomial bases. The projected kernel is trained at multiple scales derived from using repeated computation of multiwavelet transform. This allows learning the complex dependencies at various scales and results in a resolution-independent scheme. Compare to the prior works, we exploit the fundamental properties of the operator's kernel which enable numerically efficient representation. We perform experiments on the Korteweg-de Vries (KdV) equation, Burgers' equation, Darcy Flow, and Navier-Stokes equation. Compared with the existing neural operator approaches, our model shows significantly higher accuracy and achieves state-of-the-art in a range of datasets. For the time-varying equations, the proposed method exhibits a ($2X-10X$) improvement ($0.0018$ ($0.0033$) relative $L2$ error for Burgers' (KdV) equation). By learning the mappings between function spaces, the proposed method has the ability to find the solution of a high-resolution input after learning from lower-resolution data.
Two-Stage Channel Estimation Approach for Cell-Free IoT With Massive Random Access
Sep 28, 2021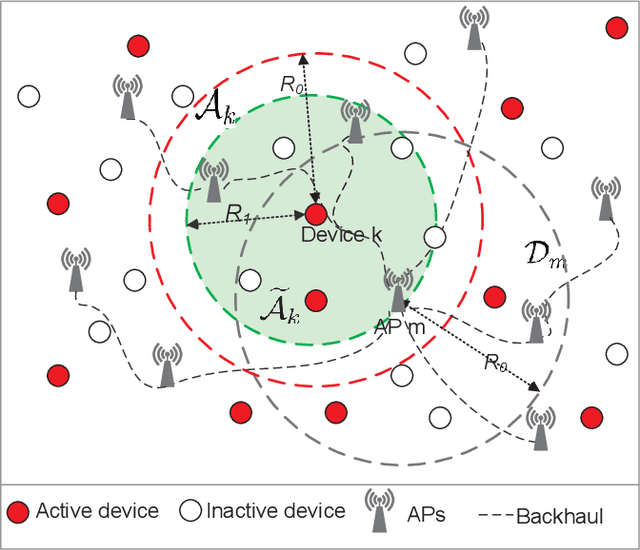
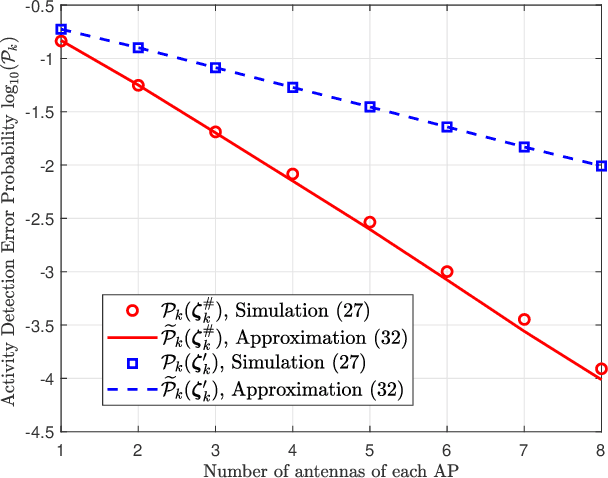
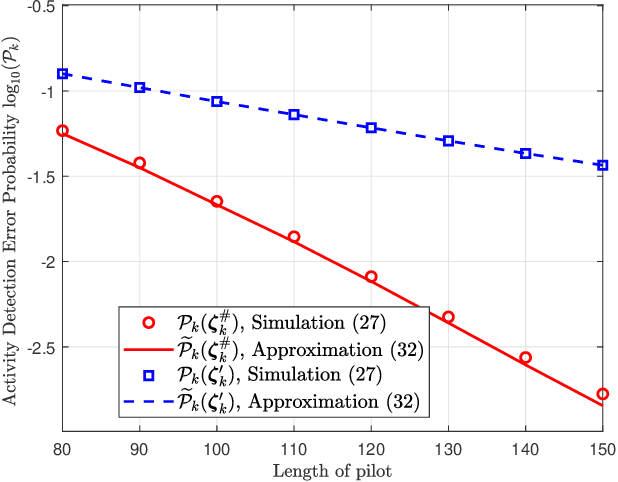
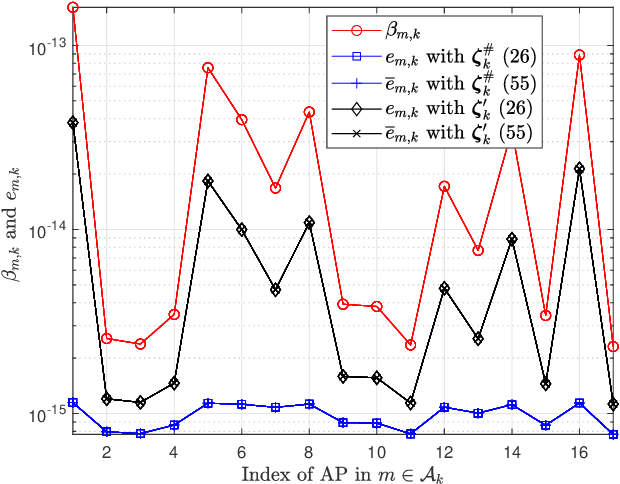
We investigate the activity detection and channel estimation issues for cell-free Internet of Things (IoT) networks with massive random access. In each time slot, only partial devices are active and communicate with neighboring access points (APs) using non-orthogonal random pilot sequences. Different from the centralized processing in cellular networks, the activity detection and channel estimation in cell-free IoT is more challenging due to the distributed and user-centric architecture. We propose a two-stage approach to detect the random activities of devices and estimate their channel states. In the first stage, the activity of each device is jointly detected by its adjacent APs based on the vector approximate message passing (Vector AMP) algorithm. In the second stage, each AP re-estimates the channel using the linear minimum mean square error (LMMSE) method based on the detected activities to improve the channel estimation accuracy. We derive closed-form expressions for the activity detection error probability and the mean-squared channel estimation errors for a typical device. Finally, we analyze the performance of the entire cell-free IoT network in terms of coverage probability. Simulation results validate the derived closed-form expressions and show that the cell-free IoT significantly outperforms the collocated massive MIMO and small-cell schemes in terms of coverage probability.
Faster than LASER -- Towards Stream Reasoning with Deep Neural Networks
Jun 15, 2021
With the constant increase of available data in various domains, such as the Internet of Things, Social Networks or Smart Cities, it has become fundamental that agents are able to process and reason with such data in real time. Whereas reasoning over time-annotated data with background knowledge may be challenging, due to the volume and velocity in which such data is being produced, such complex reasoning is necessary in scenarios where agents need to discover potential problems and this cannot be done with simple stream processing techniques. Stream Reasoners aim at bridging this gap between reasoning and stream processing and LASER is such a stream reasoner designed to analyse and perform complex reasoning over streams of data. It is based on LARS, a rule-based logical language extending Answer Set Programming, and it has shown better runtime results than other state-of-the-art stream reasoning systems. Nevertheless, for high levels of data throughput even LASER may be unable to compute answers in a timely fashion. In this paper, we study whether Convolutional and Recurrent Neural Networks, which have shown to be particularly well-suited for time series forecasting and classification, can be trained to approximate reasoning with LASER, so that agents can benefit from their high processing speed.
Offline Meta-Reinforcement Learning for Industrial Insertion
Oct 12, 2021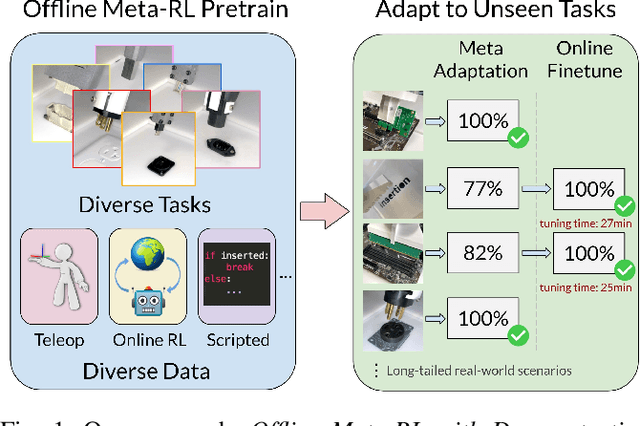
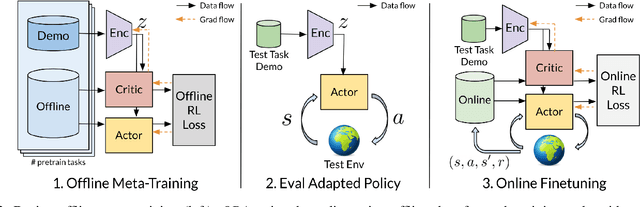


Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.
Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera
Aug 20, 2021This paper presents an effective method for generating a spatiotemporal (time-varying) texture map for a dynamic object using a single RGB-D camera. The input of our framework is a 3D template model and an RGB-D image sequence. Since there are invisible areas of the object at a frame in a single-camera setup, textures of such areas need to be borrowed from other frames. We formulate the problem as an MRF optimization and define cost functions to reconstruct a plausible spatiotemporal texture for a dynamic object. Experimental results demonstrate that our spatiotemporal textures can reproduce the active appearances of captured objects better than approaches using a single texture map.
Next Generation Reservoir Computing
Jun 14, 2021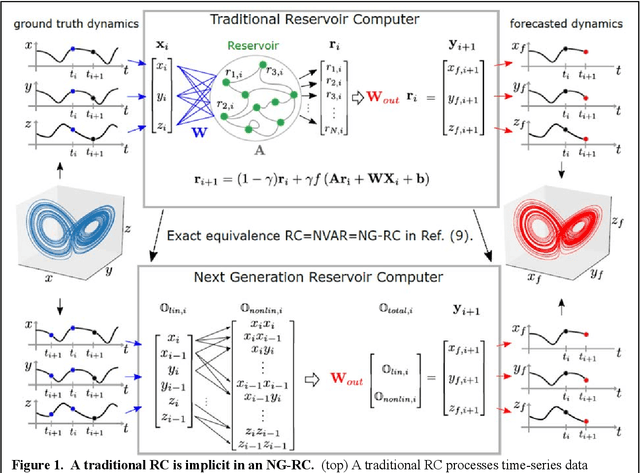
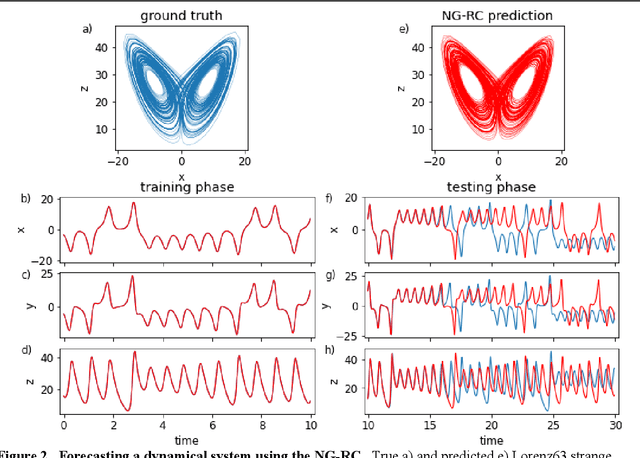
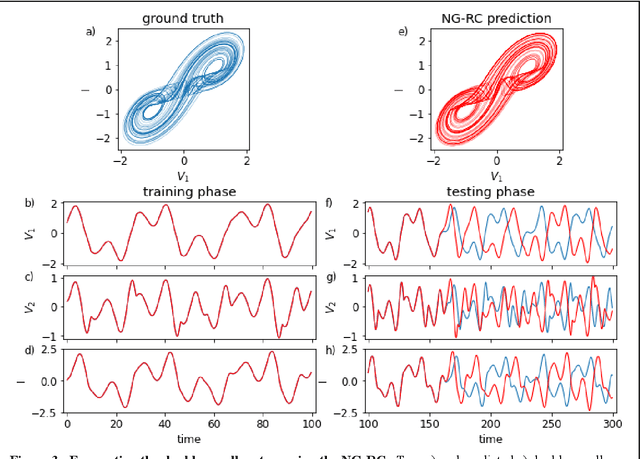
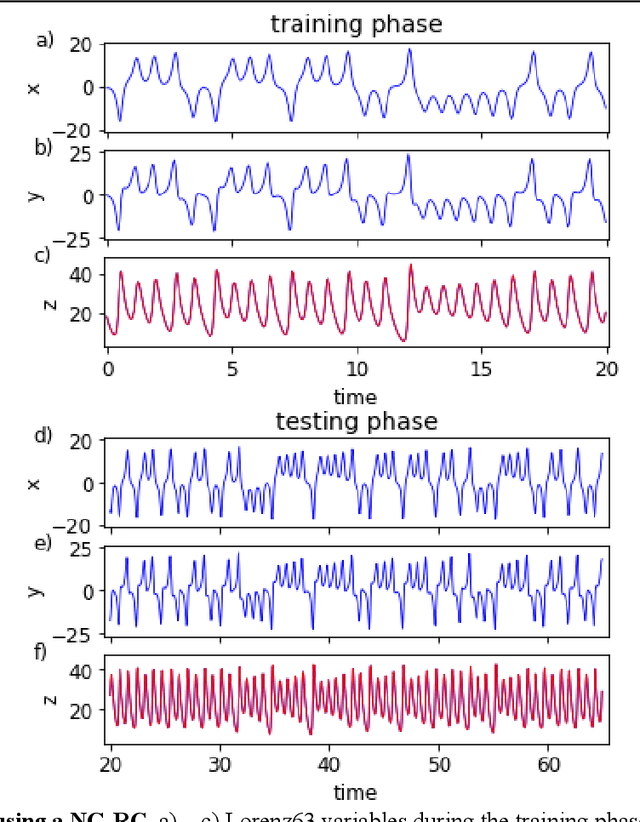
Reservoir computing is a best-in-class machine learning algorithm for processing information generated by dynamical systems using observed time-series data. Importantly, it requires very small training data sets, uses linear optimization, and thus requires minimal computing resources. However, the algorithm uses randomly sampled matrices to define the underlying recurrent neural network and has a multitude of metaparameters that must be optimized. Recent results demonstrate the equivalence of reservoir computing to nonlinear vector autoregression, which requires no random matrices, fewer metaparameters, and provides interpretable results. Here, we demonstrate that nonlinear vector autoregression excels at reservoir computing benchmark tasks and requires even shorter training data sets and training time, heralding the next generation of reservoir computing.
Neural Waveshaping Synthesis
Jul 11, 2021
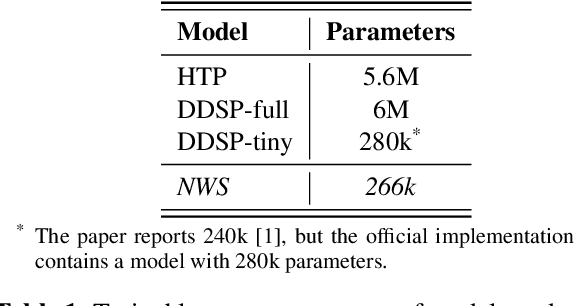
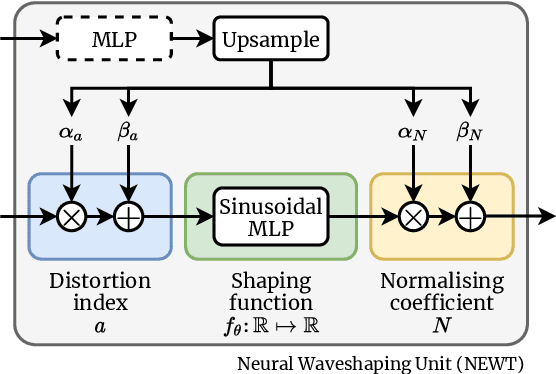
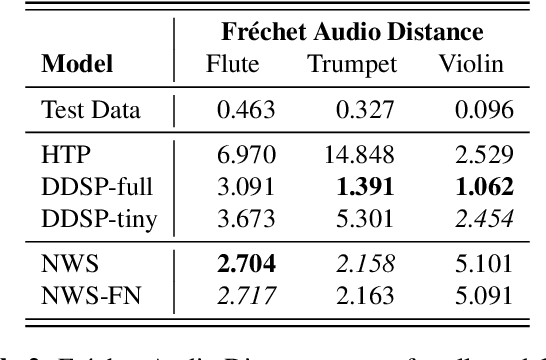
We present the Neural Waveshaping Unit (NEWT): a novel, lightweight, fully causal approach to neural audio synthesis which operates directly in the waveform domain, with an accompanying optimisation (FastNEWT) for efficient CPU inference. The NEWT uses time-distributed multilayer perceptrons with periodic activations to implicitly learn nonlinear transfer functions that encode the characteristics of a target timbre. Once trained, a NEWT can produce complex timbral evolutions by simple affine transformations of its input and output signals. We paired the NEWT with a differentiable noise synthesiser and reverb and found it capable of generating realistic musical instrument performances with only 260k total model parameters, conditioned on F0 and loudness features. We compared our method to state-of-the-art benchmarks with a multi-stimulus listening test and the Fr\'echet Audio Distance and found it performed competitively across the tested timbral domains. Our method significantly outperformed the benchmarks in terms of generation speed, and achieved real-time performance on a consumer CPU, both with and without FastNEWT, suggesting it is a viable basis for future creative sound design tools.
Development of Quantized DNN Library for Exact Hardware Emulation
Jun 15, 2021

Quantization is used to speed up execution time and save power when runnning Deep neural networks (DNNs) on edge devices like AI chips. To investigate the effect of quantization, we need performing inference after quantizing the weights of DNN with 32-bit floating-point precision by a some bit width, and then quantizing them back to 32-bit floating-point precision. This is because the DNN library can only handle floating-point numbers. However, the accuracy of the emulation does not provide accurate precision. We need accurate precision to detect overflow in MAC operations or to verify the operation on edge de vices. We have developed PyParch, a DNN library that executes quantized DNNs (QNNs) with exactly the same be havior as hardware. In this paper, we describe a new proposal and implementation of PyParch. As a result of the evaluation, the accuracy of QNNs with arbitrary bit widths can be estimated for la rge and complex DNNs such as YOLOv5, and the overflow can be detected. We evaluated the overhead of the emulation time and found that it was 5.6 times slower for QNN and 42 times slower for QNN with overflow detection compared to the normal DNN execution time.
Development of Deep Transformer-Based Models for Long-Term Prediction of Transient Production of Oil Wells
Oct 12, 2021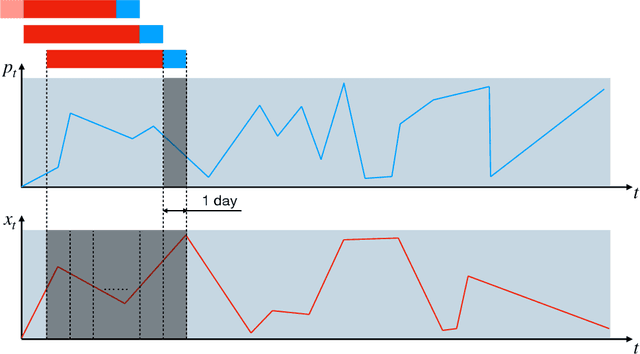

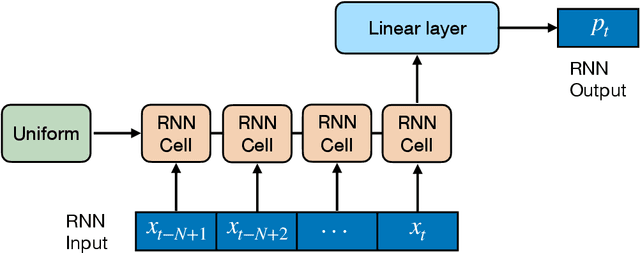

We propose a novel approach to data-driven modeling of a transient production of oil wells. We apply the transformer-based neural networks trained on the multivariate time series composed of various parameters of oil wells measured during their exploitation. By tuning the machine learning models for a single well (ignoring the effect of neighboring wells) on the open-source field datasets, we demonstrate that transformer outperforms recurrent neural networks with LSTM/GRU cells in the forecasting of the bottomhole pressure dynamics. We apply the transfer learning procedure to the transformer-based surrogate model, which includes the initial training on the dataset from a certain well and additional tuning of the model's weights on the dataset from a target well. Transfer learning approach helps to improve the prediction capability of the model. Next, we generalize the single-well model based on the transformer architecture for multiple wells to simulate complex transient oilfield-level patterns. In other words, we create the global model which deals with the dataset, comprised of the production history from multiple wells, and allows for capturing the well interference resulting in more accurate prediction of the bottomhole pressure or flow rate evolutions for each well under consideration. The developed instruments for a single-well and oilfield-scale modelling can be used to optimize the production process by selecting the operating regime and submersible equipment to increase the hydrocarbon recovery. In addition, the models can be helpful to perform well-testing avoiding costly shut-in operations.