 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
Oct 08, 2021

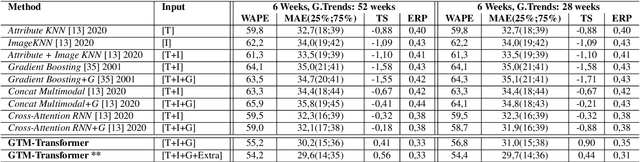
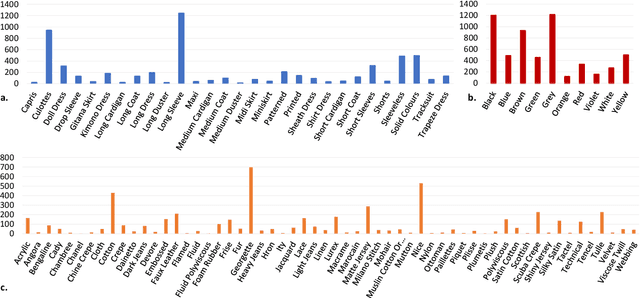
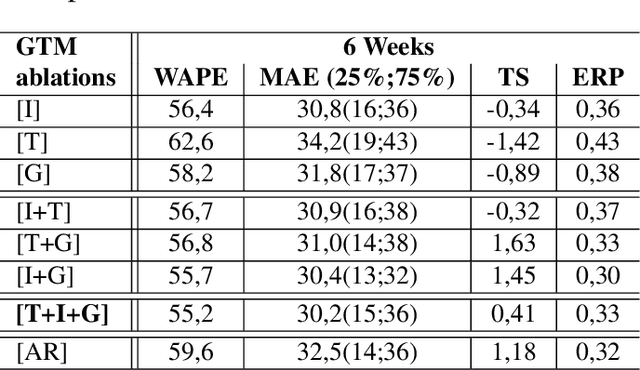
This paper investigates the effectiveness of systematically probing Google Trendsagainst textual translations of visual aspects as exogenous knowledge to predict the sales of brand-new fashion items, where past sales data is not available, but only an image and few metadata are available. In particular, we propose GTM-Transformer, standing for Google Trends Multimodal Transformer, whose encoder works on the representation of the exogenous time series, while the decoder forecasts the sales using the Google Trends encoding, and the available visual and metadata information. Our model works in a non-autoregressive manner, avoiding the compounding effect of the first-step errors. As a second contribution, we present the VISUELLE dataset, which is the first publicly available dataset for the task of new fashion product sales forecasting, containing the sales of 5577 new products sold between 2016-2019, derived from genuine historical data ofNunalie, an Italian fast-fashion company. Our dataset is equipped with images of products, metadata, related sales, and associated Google Trends. We use VISUELLE to compare our approach against state-of-the-art alternatives and numerous baselines, showing that GTM-Transformer is the most accurate in terms of both percentage and absolute error. It is worth noting that the addition of exogenous knowledge boosts the forecasting accuracy by 1.5% WAPE wise, showing the importance of exploiting Google Trends. The code and dataset are both available at https://github.com/HumaticsLAB/GTM-Transformer.
Voice-assisted Image Labelling for Endoscopic Ultrasound Classification using Neural Networks
Oct 12, 2021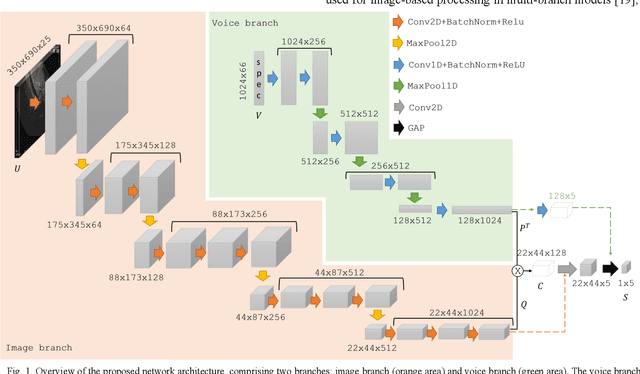
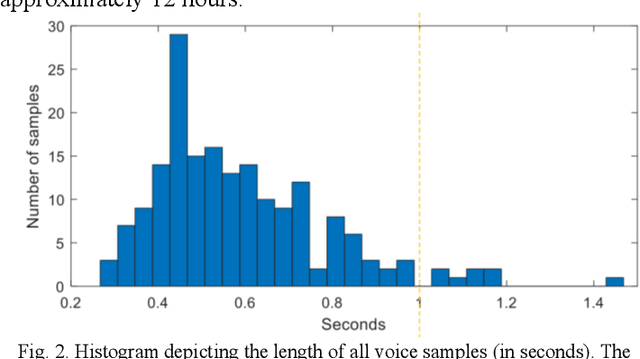
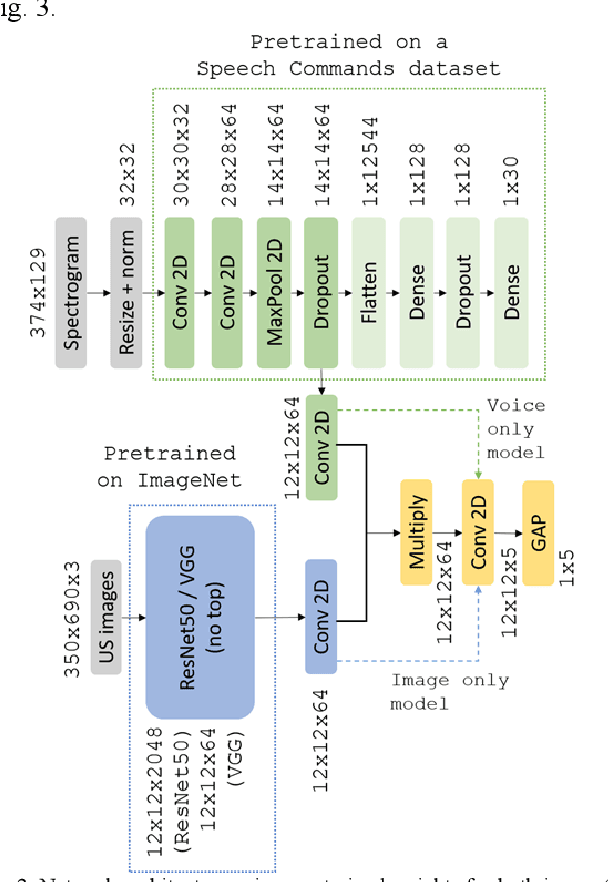
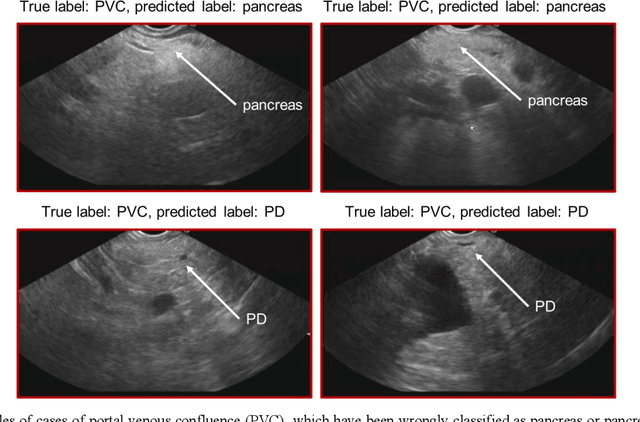
Ultrasound imaging is a commonly used technology for visualising patient anatomy in real-time during diagnostic and therapeutic procedures. High operator dependency and low reproducibility make ultrasound imaging and interpretation challenging with a steep learning curve. Automatic image classification using deep learning has the potential to overcome some of these challenges by supporting ultrasound training in novices, as well as aiding ultrasound image interpretation in patient with complex pathology for more experienced practitioners. However, the use of deep learning methods requires a large amount of data in order to provide accurate results. Labelling large ultrasound datasets is a challenging task because labels are retrospectively assigned to 2D images without the 3D spatial context available in vivo or that would be inferred while visually tracking structures between frames during the procedure. In this work, we propose a multi-modal convolutional neural network (CNN) architecture that labels endoscopic ultrasound (EUS) images from raw verbal comments provided by a clinician during the procedure. We use a CNN composed of two branches, one for voice data and another for image data, which are joined to predict image labels from the spoken names of anatomical landmarks. The network was trained using recorded verbal comments from expert operators. Our results show a prediction accuracy of 76% at image level on a dataset with 5 different labels. We conclude that the addition of spoken commentaries can increase the performance of ultrasound image classification, and eliminate the burden of manually labelling large EUS datasets necessary for deep learning applications.
Joint Dynamic Passive Beamforming and Resource Allocation for IRS-Aided Full-Duplex WPCN
Aug 15, 2021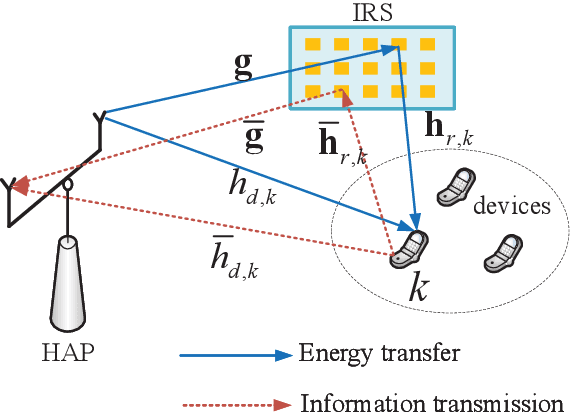
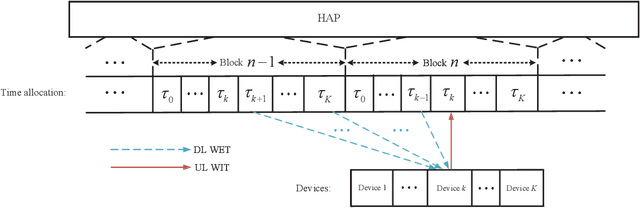
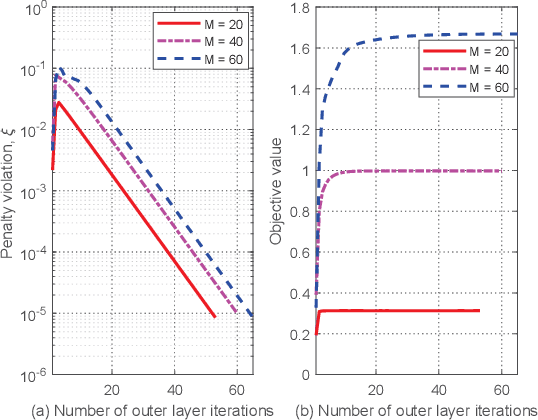
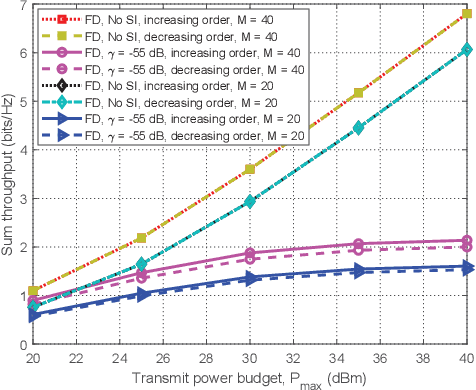
This paper studies intelligent reflecting surface (IRS)-aided full-duplex (FD) wireless-powered communication network (WPCN), where a hybrid access point (HAP) broadcasts energy signals to multiple devices for their energy harvesting in the downlink (DL) and meanwhile receives information signals in the uplink (UL) with the help of IRS. Particularly, we propose three types of IRS beamforming configurations to strike a balance between the system performance and signaling overhead as well as implementation complexity. We first propose the fully dynamic IRS beamforming, where the IRS phase-shift vectors vary with each time slot for both DL wireless energy transfer (WET) and UL wireless information transmission (WIT). To further reduce signaling overhead and implementation complexity, we then study two special cases, namely, partially dynamic IRS beamforming and static IRS beamforming. For the former case, two different phase-shift vectors can be exploited for the DL WET and the UL WIT, respectively, whereas for the latter case, the same phase-shift vector needs to be applied for both DL and UL transmissions. We aim to maximize the system throughput by jointly optimizing the time allocation, HAP transmit power, and IRS phase shifts for the above three cases. Two efficient algorithms based on alternating optimization and penalty-based algorithms are respectively proposed for both perfect self-interference cancellation (SIC) case and imperfect SIC case by applying successive convex approximation and difference-of-convex optimization techniques. Simulation results demonstrate the benefits of IRS for enhancing the performance of FD-WPCN, and also show that the IRS-aided FD-WPCN is able to achieve significantly performance gain compared to its counterpart with half-duplex when the self-interference (SI) is properly suppressed.
Tell Me How to Survey: Literature Review Made Simple with Automatic Reading Path Generation
Oct 12, 2021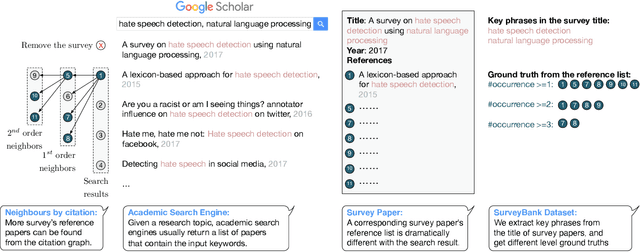
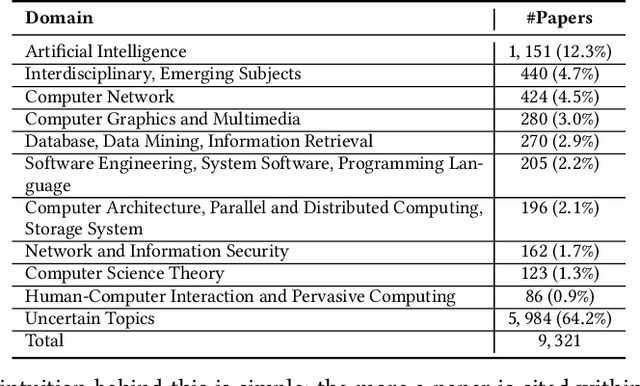
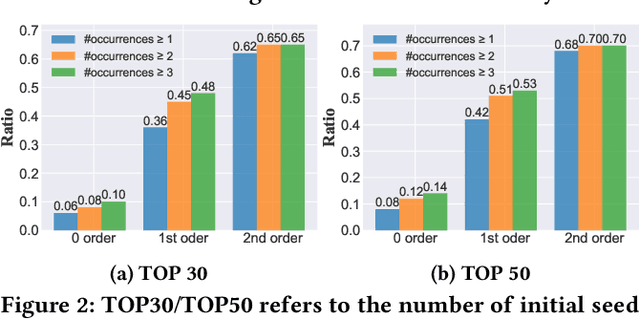

Recent years have witnessed the dramatic growth of paper volumes with plenty of new research papers published every day, especially in the area of computer science. How to glean papers worth reading from the massive literature to do a quick survey or keep up with the latest advancement about a specific research topic has become a challenging task. Existing academic search engines such as Google Scholar return relevant papers by individually calculating the relevance between each paper and query. However, such systems usually omit the prerequisite chains of a research topic and cannot form a meaningful reading path. In this paper, we introduce a new task named Reading Path Generation (RPG) which aims at automatically producing a path of papers to read for a given query. To serve as a research benchmark, we further propose SurveyBank, a dataset consisting of large quantities of survey papers in the field of computer science as well as their citation relationships. Each survey paper contains key phrases extracted from its title and multi-level reading lists inferred from its references. Furthermore, we propose a graph-optimization-based approach for reading path generation which takes the relationship between papers into account. Extensive evaluations demonstrate that our approach outperforms other baselines. A Real-time Reading Path Generation System (RePaGer) has been also implemented with our designed model. To the best of our knowledge, we are the first to target this important research problem. Our source code of RePaGer system and SurveyBank dataset can be found on here.
Accelerated MRI Reconstruction with Separable and Enhanced Low-Rank Hankel Regularization
Jul 24, 2021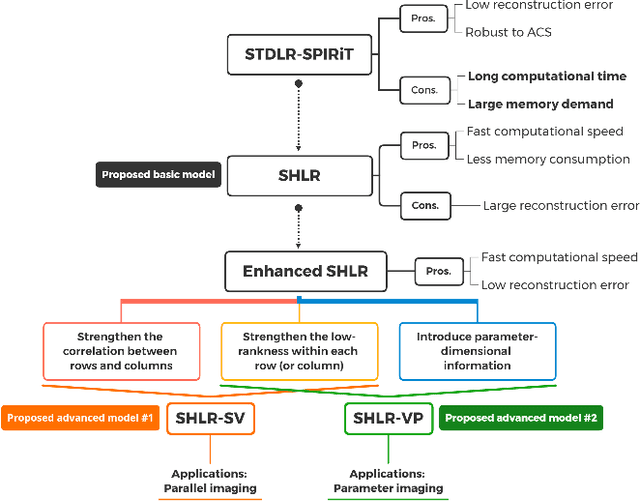
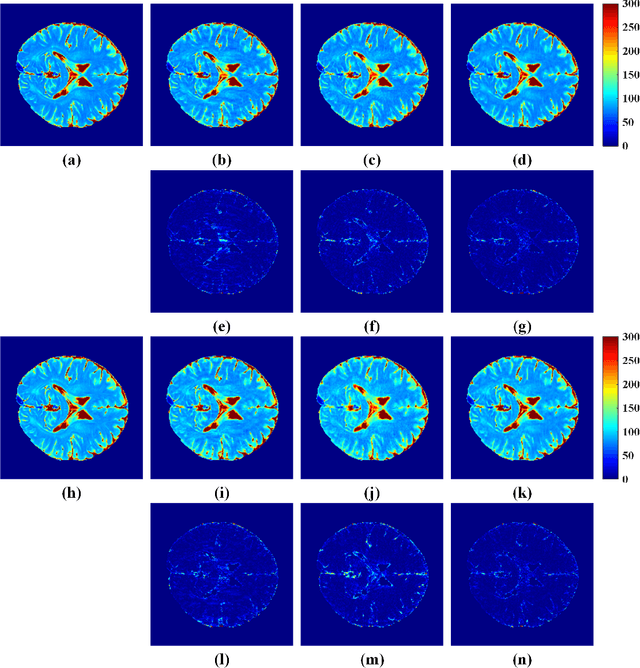
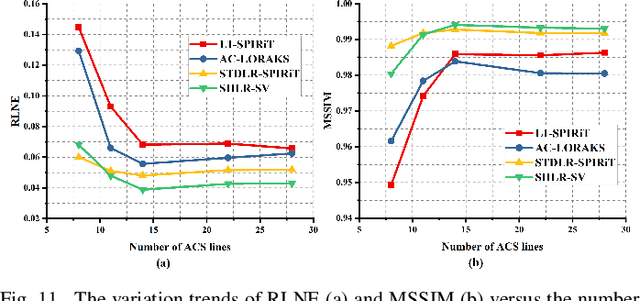
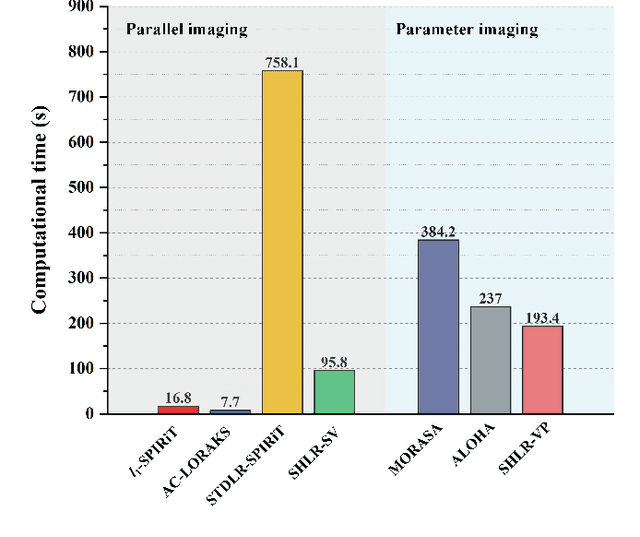
The combination of the sparse sampling and the low-rank structured matrix reconstruction has shown promising performance, enabling a significant reduction of the magnetic resonance imaging data acquisition time. However, the low-rank structured approaches demand considerable memory consumption and are time-consuming due to a noticeable number of matrix operations performed on the huge-size block Hankel-like matrix. In this work, we proposed a novel framework to utilize the low-rank property but meanwhile to achieve faster reconstructions and promising results. The framework allows us to enforce the low-rankness of Hankel matrices constructing from 1D vectors instead of 2D matrices from 1D vectors and thus avoid the construction of huge block Hankel matrix for 2D k-space matrices. Moreover, under this framework, we can easily incorporate other information, such as the smooth phase of the image and the low-rankness in the parameter dimension, to further improve the image quality. We built and validated two models for parallel and parameter magnetic resonance imaging experiments, respectively. Our retrospective in-vivo results indicate that the proposed approaches enable faster reconstructions than the state-of-the-art approaches, e.g., about 8x faster than STDLRSPIRiT, and faithful removal of undersampling artifacts.
Independent Deeply Learned Tensor Analysis for Determined Audio Source Separation
Jun 10, 2021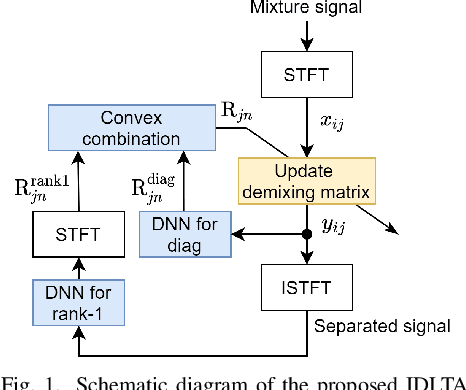

We address the determined audio source separation problem in the time-frequency domain. In independent deeply learned matrix analysis (IDLMA), it is assumed that the inter-frequency correlation of each source spectrum is zero, which is inappropriate for modeling nonstationary signals such as music signals. To account for the correlation between frequencies, independent positive semidefinite tensor analysis has been proposed. This unsupervised (blind) method, however, severely restrict the structure of frequency covariance matrices (FCMs) to reduce the number of model parameters. As an extension of these conventional approaches, we here propose a supervised method that models FCMs using deep neural networks (DNNs). It is difficult to directly infer FCMs using DNNs. Therefore, we also propose a new FCM model represented as a convex combination of a diagonal FCM and a rank-1 FCM. Our FCM model is flexible enough to not only consider inter-frequency correlation, but also capture the dynamics of time-varying FCMs of nonstationary signals. We infer the proposed FCMs using two DNNs: DNN for power spectrum estimation and DNN for time-domain signal estimation. An experimental result of separating music signals shows that the proposed method provides higher separation performance than IDLMA.
Multiwavelet-based Operator Learning for Differential Equations
Sep 28, 2021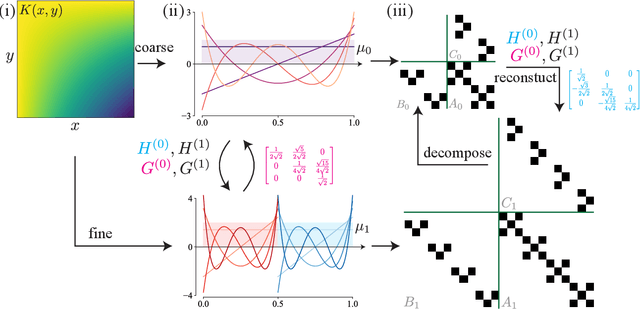
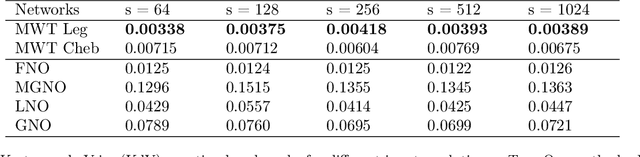
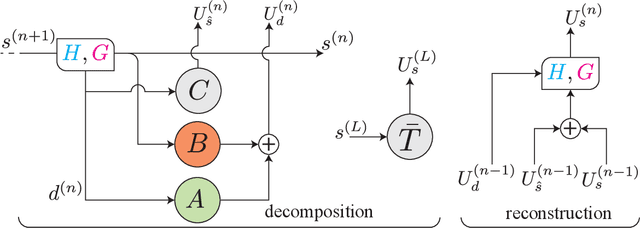
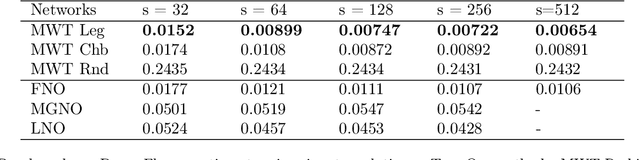
The solution of a partial differential equation can be obtained by computing the inverse operator map between the input and the solution space. Towards this end, we introduce a \textit{multiwavelet-based neural operator learning scheme} that compresses the associated operator's kernel using fine-grained wavelets. By explicitly embedding the inverse multiwavelet filters, we learn the projection of the kernel onto fixed multiwavelet polynomial bases. The projected kernel is trained at multiple scales derived from using repeated computation of multiwavelet transform. This allows learning the complex dependencies at various scales and results in a resolution-independent scheme. Compare to the prior works, we exploit the fundamental properties of the operator's kernel which enable numerically efficient representation. We perform experiments on the Korteweg-de Vries (KdV) equation, Burgers' equation, Darcy Flow, and Navier-Stokes equation. Compared with the existing neural operator approaches, our model shows significantly higher accuracy and achieves state-of-the-art in a range of datasets. For the time-varying equations, the proposed method exhibits a ($2X-10X$) improvement ($0.0018$ ($0.0033$) relative $L2$ error for Burgers' (KdV) equation). By learning the mappings between function spaces, the proposed method has the ability to find the solution of a high-resolution input after learning from lower-resolution data.
Two-Stage Channel Estimation Approach for Cell-Free IoT With Massive Random Access
Sep 28, 2021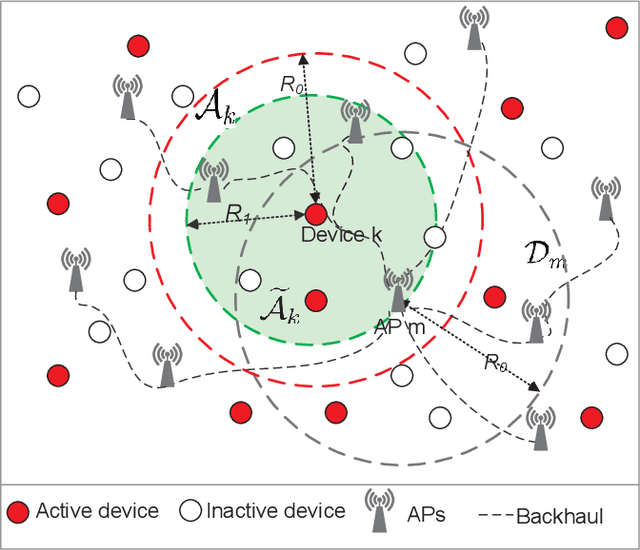
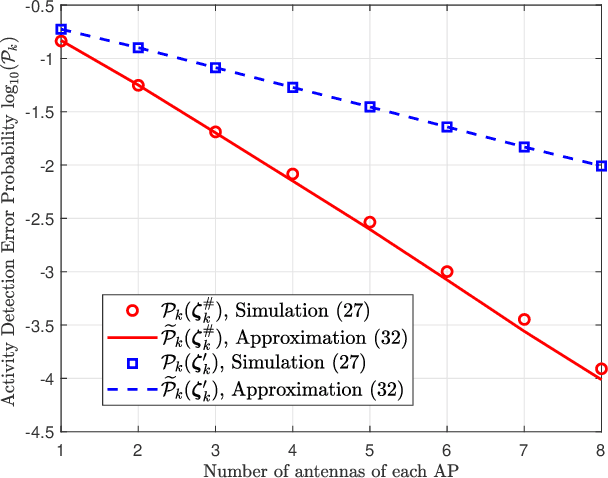
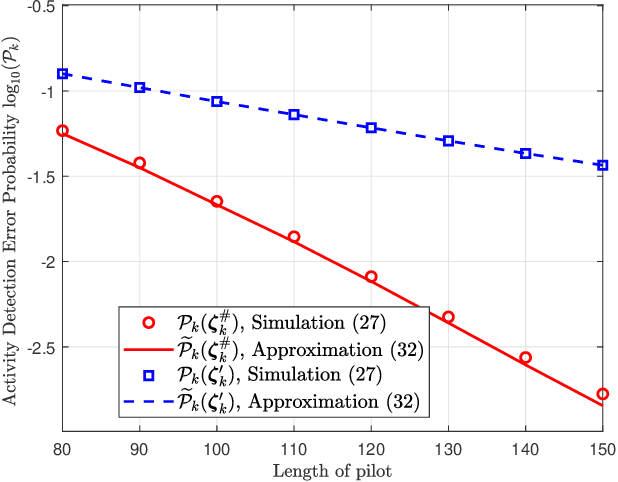
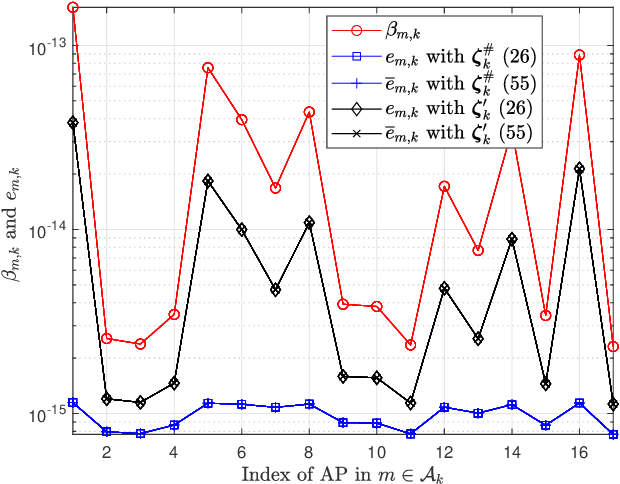
We investigate the activity detection and channel estimation issues for cell-free Internet of Things (IoT) networks with massive random access. In each time slot, only partial devices are active and communicate with neighboring access points (APs) using non-orthogonal random pilot sequences. Different from the centralized processing in cellular networks, the activity detection and channel estimation in cell-free IoT is more challenging due to the distributed and user-centric architecture. We propose a two-stage approach to detect the random activities of devices and estimate their channel states. In the first stage, the activity of each device is jointly detected by its adjacent APs based on the vector approximate message passing (Vector AMP) algorithm. In the second stage, each AP re-estimates the channel using the linear minimum mean square error (LMMSE) method based on the detected activities to improve the channel estimation accuracy. We derive closed-form expressions for the activity detection error probability and the mean-squared channel estimation errors for a typical device. Finally, we analyze the performance of the entire cell-free IoT network in terms of coverage probability. Simulation results validate the derived closed-form expressions and show that the cell-free IoT significantly outperforms the collocated massive MIMO and small-cell schemes in terms of coverage probability.
Probabilistic Adaptive Computation Time
Dec 01, 2017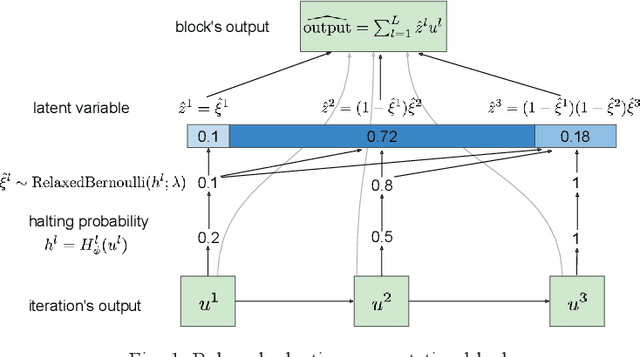
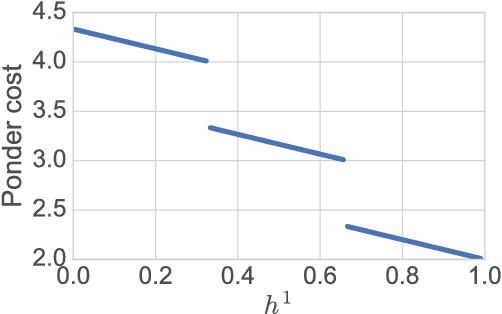
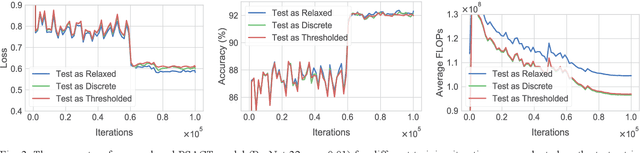
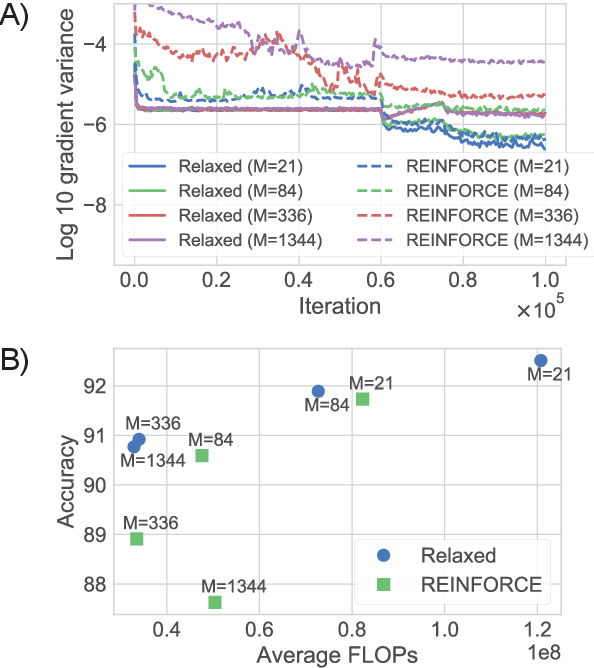
We present a probabilistic model with discrete latent variables that control the computation time in deep learning models such as ResNets and LSTMs. A prior on the latent variables expresses the preference for faster computation. The amount of computation for an input is determined via amortized maximum a posteriori (MAP) inference. MAP inference is performed using a novel stochastic variational optimization method. The recently proposed Adaptive Computation Time mechanism can be seen as an ad-hoc relaxation of this model. We demonstrate training using the general-purpose Concrete relaxation of discrete variables. Evaluation on ResNet shows that our method matches the speed-accuracy trade-off of Adaptive Computation Time, while allowing for evaluation with a simple deterministic procedure that has a lower memory footprint.
Offline Meta-Reinforcement Learning for Industrial Insertion
Oct 12, 2021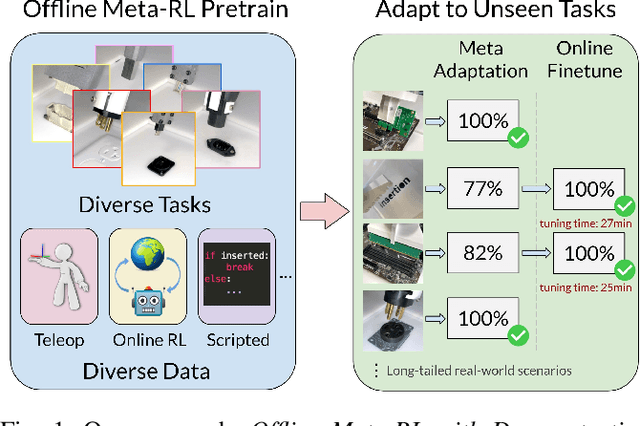
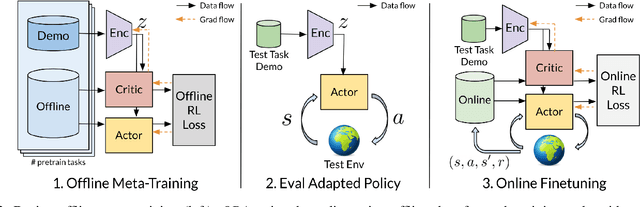


Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.