 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the benefits of maximum likelihood estimation for Regression and Forecasting
Jun 18, 2021
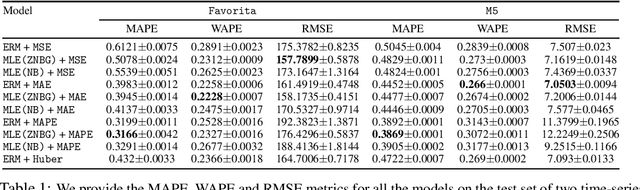
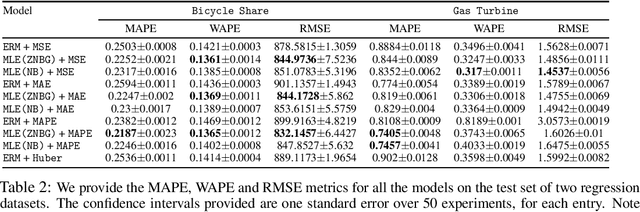
We advocate for a practical Maximum Likelihood Estimation (MLE) approach for regression and forecasting, as an alternative to the typical approach of Empirical Risk Minimization (ERM) for a specific target metric. This approach is better suited to capture inductive biases such as prior domain knowledge in datasets, and can output post-hoc estimators at inference time that can optimize different types of target metrics. We present theoretical results to demonstrate that our approach is always competitive with any estimator for the target metric under some general conditions, and in many practical settings (such as Poisson Regression) can actually be much superior to ERM. We demonstrate empirically that our method instantiated with a well-designed general purpose mixture likelihood family can obtain superior performance over ERM for a variety of tasks across time-series forecasting and regression datasets with different data distributions.
FinGAT: Financial Graph Attention Networks for Recommending Top-K Profitable Stocks
Jun 18, 2021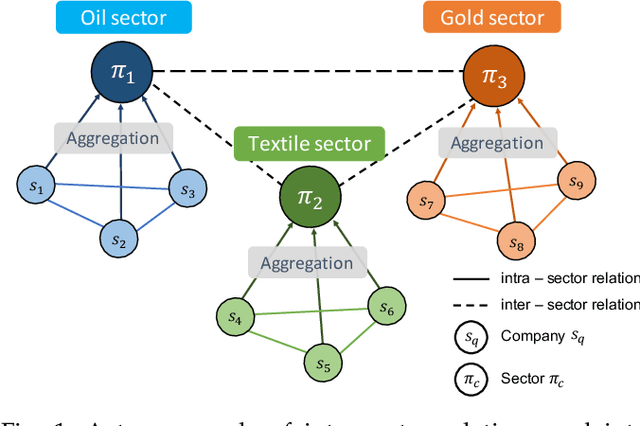

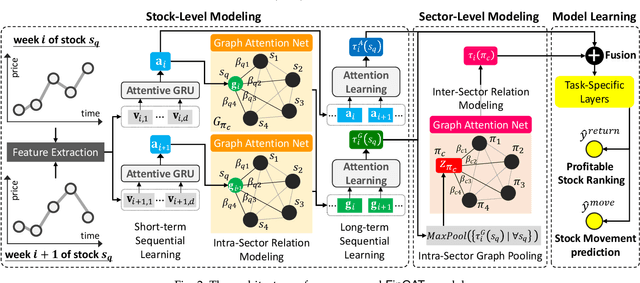
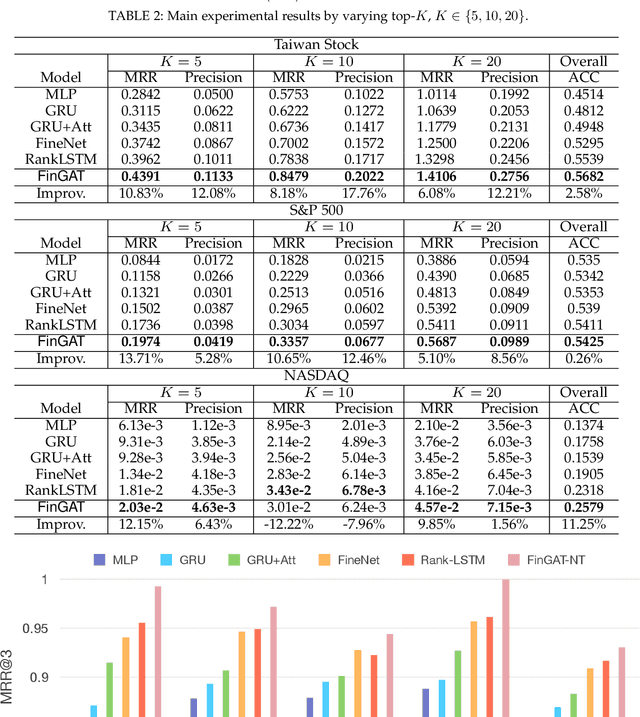
Financial technology (FinTech) has drawn much attention among investors and companies. While conventional stock analysis in FinTech targets at predicting stock prices, less effort is made for profitable stock recommendation. Besides, in existing approaches on modeling time series of stock prices, the relationships among stocks and sectors (i.e., categories of stocks) are either neglected or pre-defined. Ignoring stock relationships will miss the information shared between stocks while using pre-defined relationships cannot depict the latent interactions or influence of stock prices between stocks. In this work, we aim at recommending the top-K profitable stocks in terms of return ratio using time series of stock prices and sector information. We propose a novel deep learning-based model, Financial Graph Attention Networks (FinGAT), to tackle the task under the setting that no pre-defined relationships between stocks are given. The idea of FinGAT is three-fold. First, we devise a hierarchical learning component to learn short-term and long-term sequential patterns from stock time series. Second, a fully-connected graph between stocks and a fully-connected graph between sectors are constructed, along with graph attention networks, to learn the latent interactions among stocks and sectors. Third, a multi-task objective is devised to jointly recommend the profitable stocks and predict the stock movement. Experiments conducted on Taiwan Stock, S&P 500, and NASDAQ datasets exhibit remarkable recommendation performance of our FinGAT, comparing to state-of-the-art methods.
Coordinating Flexible Demand Response and Renewable Uncertainties for Scheduling of Community Integrated Energy Systems with an Electric Vehicle Charging Station: A Bi-level Approach
Jul 16, 2021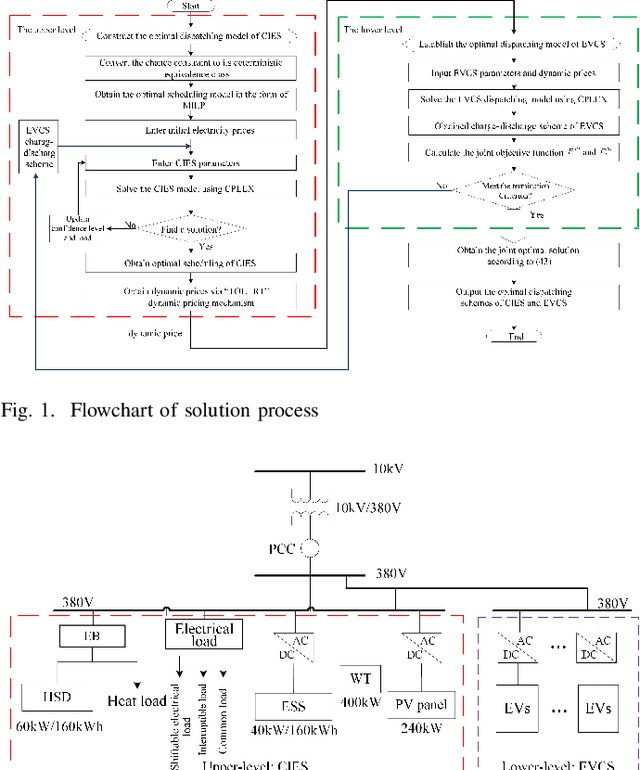
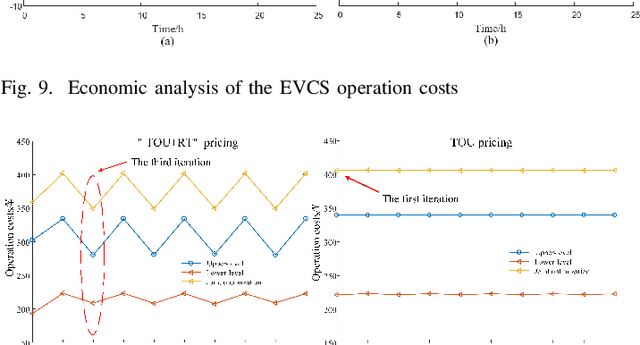
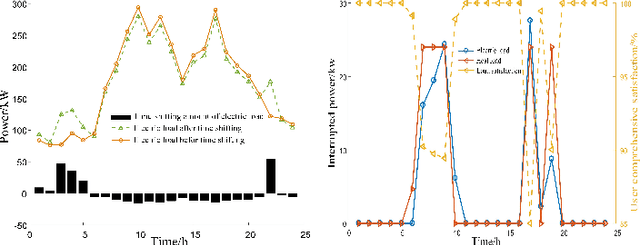
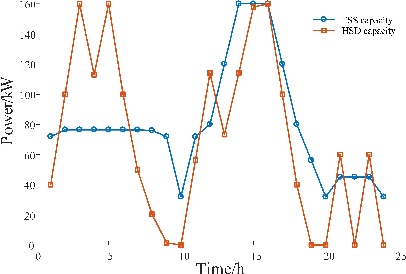
A community integrated energy system (CIES) with an electric vehicle charging station (EVCS) provides a new way for tackling growing concerns of energy efficiency and environmental pollution, it is a critical task to coordinate flexible demand response and multiple renewable uncertainties. To this end, a novel bi-level optimal dispatching model for the CIES with an EVCS in multi-stakeholder scenarios is established in this paper. In this model, an integrated demand response program is designed to promote a balance between energy supply and demand while maintaining a user comprehensive satisfaction within an acceptable range. To further tap the potential of demand response through flexibly guiding users' energy consumption and electric vehicles' behaviors (charging, discharging and providing spinning reserves), a dynamic pricing mechanism combining time-of-use and real-time pricing is put forward. In the solution phase, by using sequence operation theory (SOT), the original chance-constrained programming (CCP) model is converted into a readily solvable mixed-integer linear programming (MILP) formulation and finally solved by CPLEX solver. The simulation results on a practical CIES located in North China demonstrate that the presented method manages to balance the interests between CIES and EVCS via the coordination of flexible demand response and uncertain renewables.
Dependability Analysis of Deep Reinforcement Learning based Robotics and Autonomous Systems
Sep 14, 2021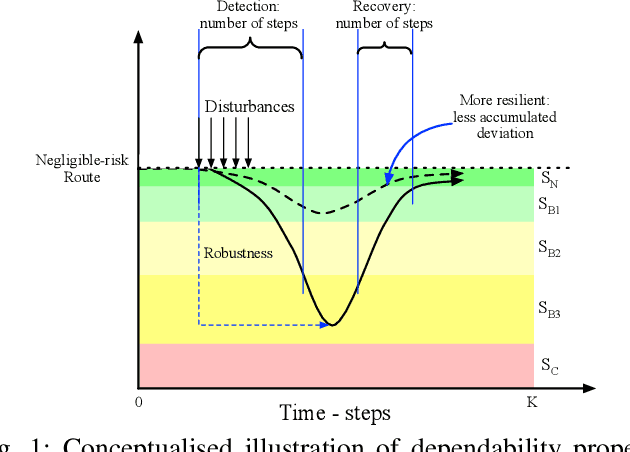
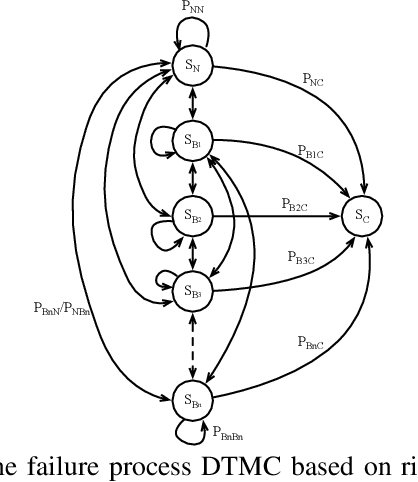
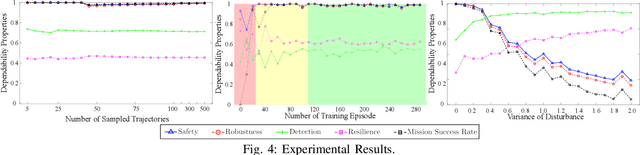
While Deep Reinforcement Learning (DRL) provides transformational capabilities to the control of Robotics and Autonomous Systems (RAS), the black-box nature of DRL and uncertain deployment-environments of RAS pose new challenges on its dependability. Although there are many existing works imposing constraints on the DRL policy to ensure a successful completion of the mission, it is far from adequate in terms of assessing the DRL-driven RAS in a holistic way considering all dependability properties. In this paper, we formally define a set of dependability properties in temporal logic and construct a Discrete-Time Markov Chain (DTMC) to model the dynamics of risk/failures of a DRL-driven RAS interacting with the stochastic environment. We then do Probabilistic Model Checking based on the designed DTMC to verify those properties. Our experimental results show that the proposed method is effective as a holistic assessment framework, while uncovers conflicts between the properties that may need trade-offs in the training. Moreover, we find the standard DRL training cannot improve dependability properties, thus requiring bespoke optimisation objectives concerning them. Finally, our method offers a novel dependability analysis to the Sim-to-Real challenge of DRL.
Harnessing Unlabeled Data to Improve Generalization of Biometric Gender and Age Classifiers
Oct 09, 2021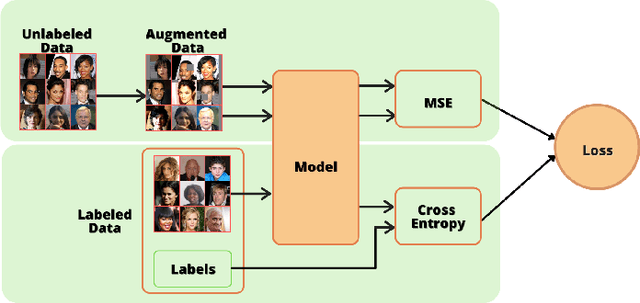
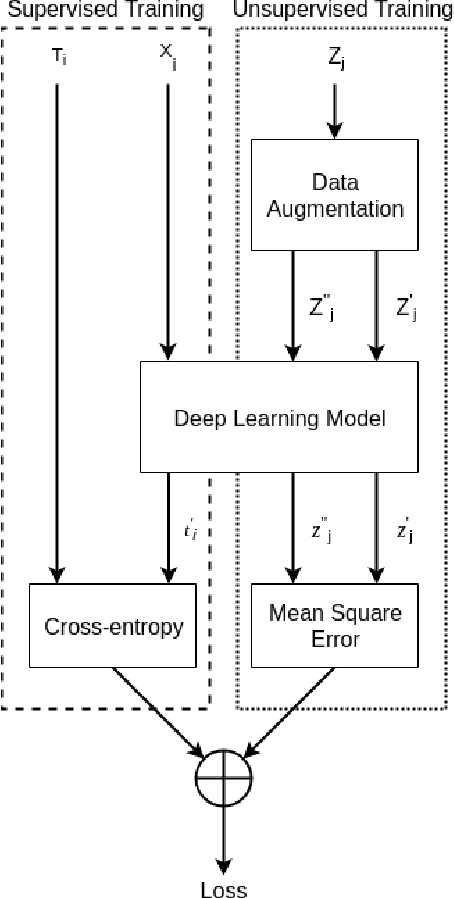


With significant advances in deep learning, many computer vision applications have reached the inflection point. However, these deep learning models need large amount of labeled data for model training and optimum parameter estimation. Limited labeled data for model training results in over-fitting and impacts their generalization performance. However, the collection and annotation of large amount of data is a very time consuming and expensive operation. Further, due to privacy and security concerns, the large amount of labeled data could not be collected for certain applications such as those involving medical field. Self-training, Co-training, and Self-ensemble methods are three types of semi-supervised learning methods that can be used to exploit unlabeled data. In this paper, we propose self-ensemble based deep learning model that along with limited labeled data, harness unlabeled data for improving the generalization performance. We evaluated the proposed self-ensemble based deep-learning model for soft-biometric gender and age classification. Experimental evaluation on CelebA and VISOB datasets suggest gender classification accuracy of 94.46% and 81.00%, respectively, using only 1000 labeled samples and remaining 199k samples as unlabeled samples for CelebA dataset and similarly,1000 labeled samples with remaining 107k samples as unlabeled samples for VISOB dataset. Comparative evaluation suggest that there is $5.74\%$ and $8.47\%$ improvement in the accuracy of the self-ensemble model when compared with supervised model trained on the entire CelebA and VISOB dataset, respectively. We also evaluated the proposed learning method for age-group prediction on Adience dataset and it outperformed the baseline supervised deep-learning learning model with a better exact accuracy of 55.55 $\pm$ 4.28 which is 3.92% more than the baseline.
Adjustable Real-time Style Transfer
Nov 21, 2018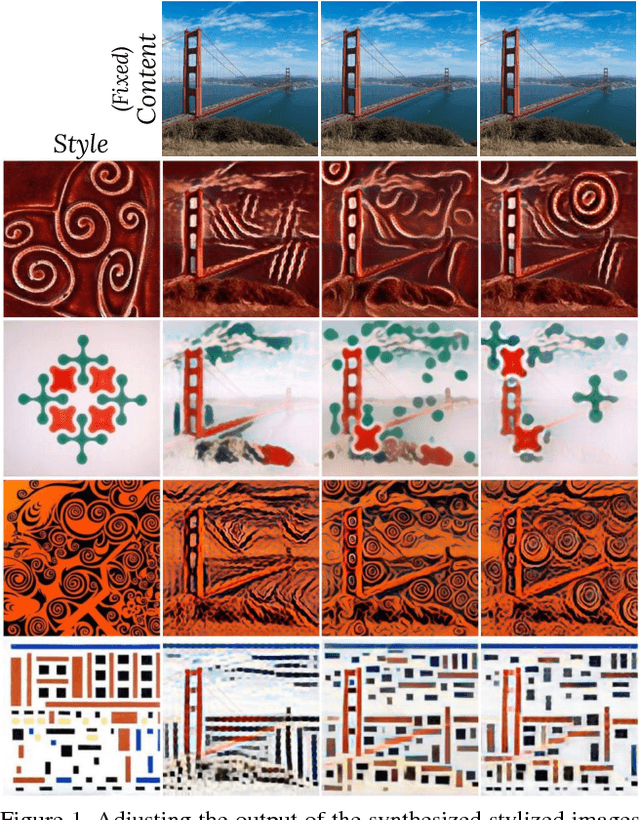

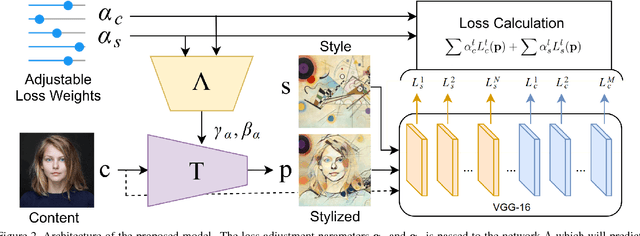
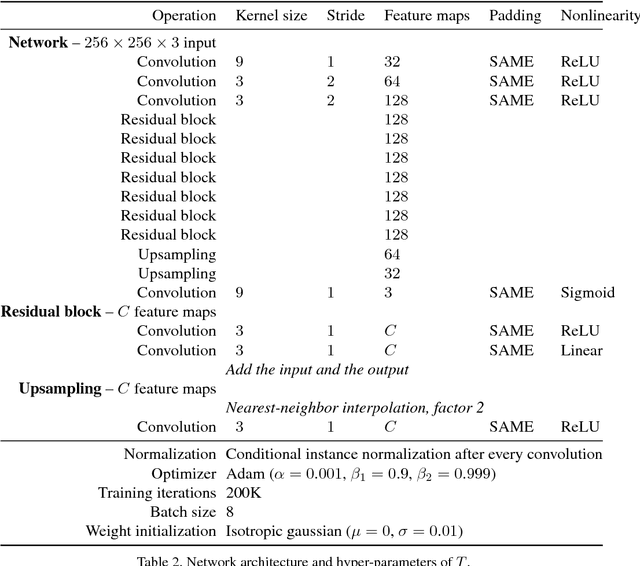
Artistic style transfer is the problem of synthesizing an image with content similar to a given image and style similar to another. Although recent feed-forward neural networks can generate stylized images in real-time, these models produce a single stylization given a pair of style/content images, and the user doesn't have control over the synthesized output. Moreover, the style transfer depends on the hyper-parameters of the model with varying "optimum" for different input images. Therefore, if the stylized output is not appealing to the user, she/he has to try multiple models or retrain one with different hyper-parameters to get a favorite stylization. In this paper, we address these issues by proposing a novel method which allows adjustment of crucial hyper-parameters, after the training and in real-time, through a set of manually adjustable parameters. These parameters enable the user to modify the synthesized outputs from the same pair of style/content images, in search of a favorite stylized image. Our quantitative and qualitative experiments indicate how adjusting these parameters is comparable to retraining the model with different hyper-parameters. We also demonstrate how these parameters can be randomized to generate results which are diverse but still very similar in style and content.
EventPoint: Self-Supervised Local Descriptor Learning for Event Cameras
Sep 01, 2021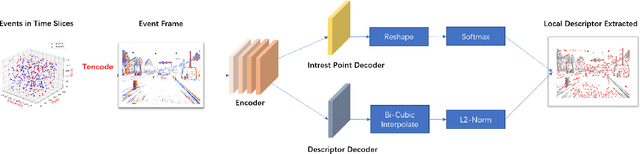

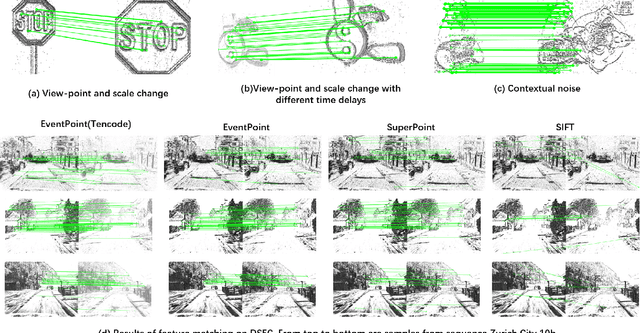
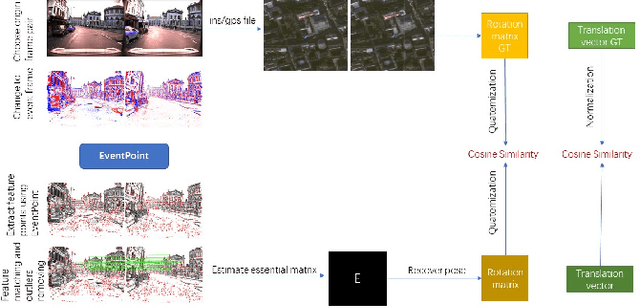
We proposes a method of extracting intrest points and descriptors using self-supervised learning method on frame-based event data, which is called EventPoint. Different from other feature extraction methods on event data, we train our model on real event-form driving dataset--DSEC with the self-supervised learning method we proposed, the training progress fully consider the characteristics of event data.To verify the effectiveness of our work,we conducted several complete evaluations: we emulated DART and carried out feature matching experiments on N-caltech101 dataset, the results shows that the effect of EventPoint is better than DART; We use Vid2e tool provided by UZH to convert Oxford robotcar data into event-based format, and combined with INS information provided to carry out the global pose estimation experiment which is important in SLAM. As far as we know, this is the first work to carry out this challenging task.Sufficient experimental data show that EventPoint can get better results while achieve real time on CPU.
Semi-supervised Learning for Marked Temporal Point Processes
Jul 16, 2021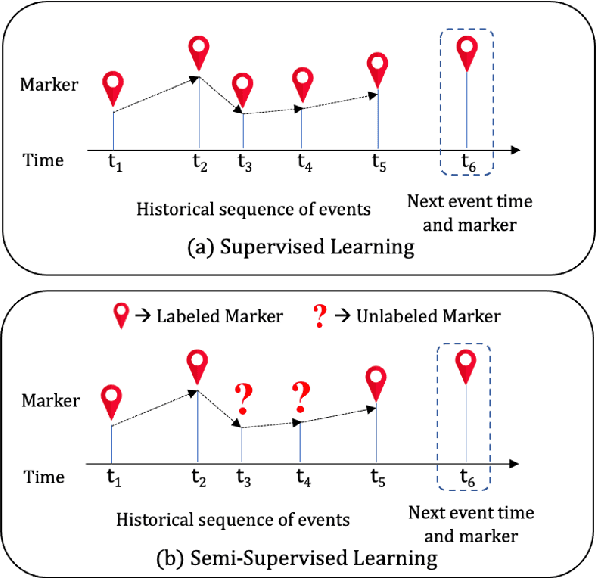
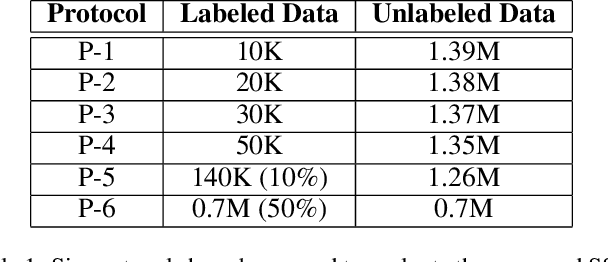
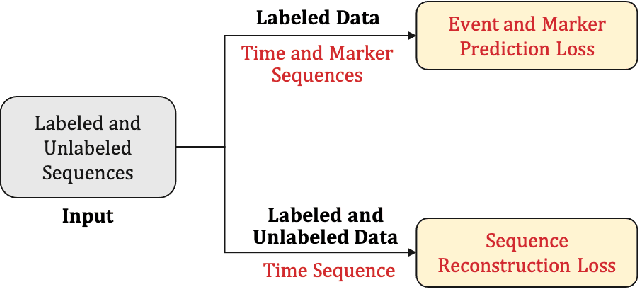
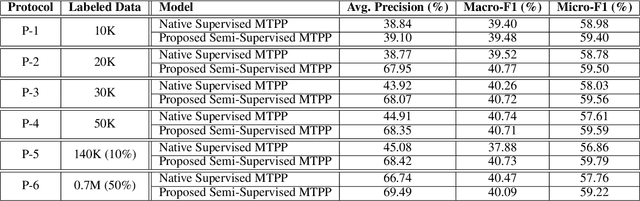
Temporal Point Processes (TPPs) are often used to represent the sequence of events ordered as per the time of occurrence. Owing to their flexible nature, TPPs have been used to model different scenarios and have shown applicability in various real-world applications. While TPPs focus on modeling the event occurrence, Marked Temporal Point Process (MTPP) focuses on modeling the category/class of the event as well (termed as the marker). Research in MTPP has garnered substantial attention over the past few years, with an extensive focus on supervised algorithms. Despite the research focus, limited attention has been given to the challenging problem of developing solutions in semi-supervised settings, where algorithms have access to a mix of labeled and unlabeled data. This research proposes a novel algorithm for Semi-supervised Learning for Marked Temporal Point Processes (SSL-MTPP) applicable in such scenarios. The proposed SSL-MTPP algorithm utilizes a combination of labeled and unlabeled data for learning a robust marker prediction model. The proposed algorithm utilizes an RNN-based Encoder-Decoder module for learning effective representations of the time sequence. The efficacy of the proposed algorithm has been demonstrated via multiple protocols on the Retweet dataset, where the proposed SSL-MTPP demonstrates improved performance in comparison to the traditional supervised learning approach.
Confidence-Aware Scheduled Sampling for Neural Machine Translation
Jul 22, 2021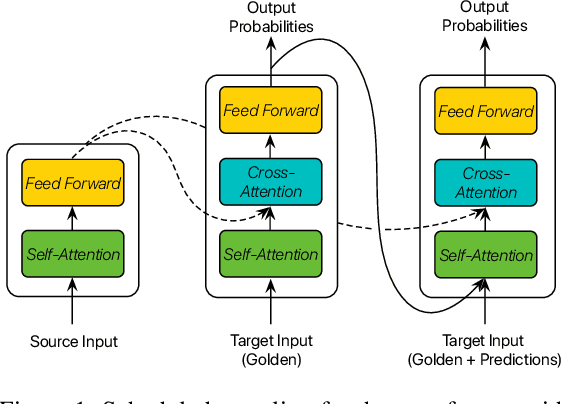
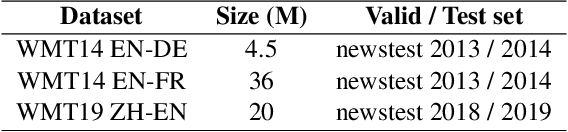
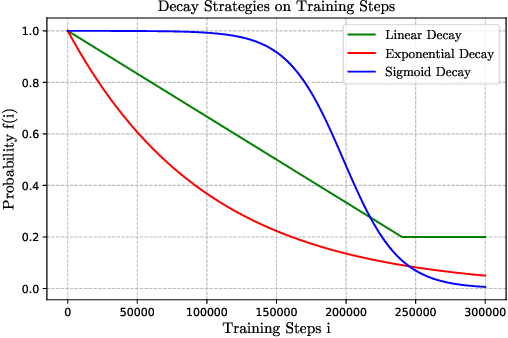
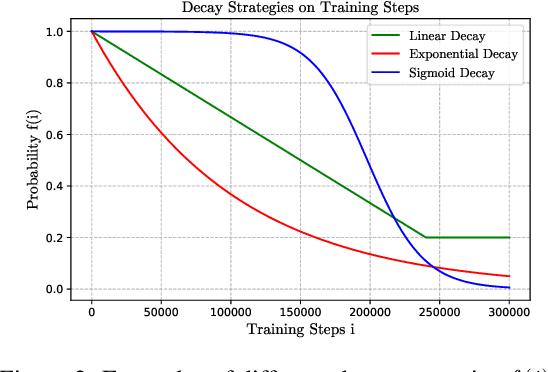
Scheduled sampling is an effective method to alleviate the exposure bias problem of neural machine translation. It simulates the inference scene by randomly replacing ground-truth target input tokens with predicted ones during training. Despite its success, its critical schedule strategies are merely based on training steps, ignoring the real-time model competence, which limits its potential performance and convergence speed. To address this issue, we propose confidence-aware scheduled sampling. Specifically, we quantify real-time model competence by the confidence of model predictions, based on which we design fine-grained schedule strategies. In this way, the model is exactly exposed to predicted tokens for high-confidence positions and still ground-truth tokens for low-confidence positions. Moreover, we observe vanilla scheduled sampling suffers from degenerating into the original teacher forcing mode since most predicted tokens are the same as ground-truth tokens. Therefore, under the above confidence-aware strategy, we further expose more noisy tokens (e.g., wordy and incorrect word order) instead of predicted ones for high-confidence token positions. We evaluate our approach on the Transformer and conduct experiments on large-scale WMT 2014 English-German, WMT 2014 English-French, and WMT 2019 Chinese-English. Results show that our approach significantly outperforms the Transformer and vanilla scheduled sampling on both translation quality and convergence speed.
Failures detection at directional drilling using real-time analogues search
Jun 06, 2019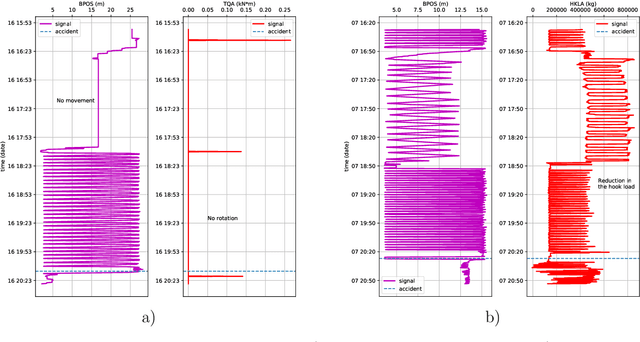
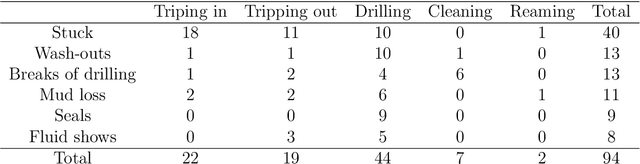
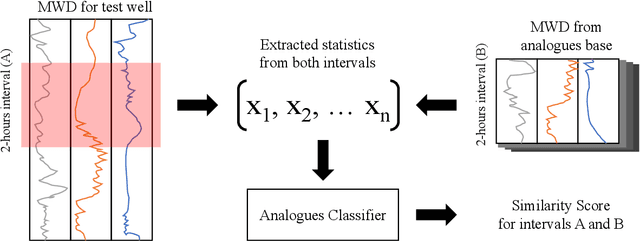
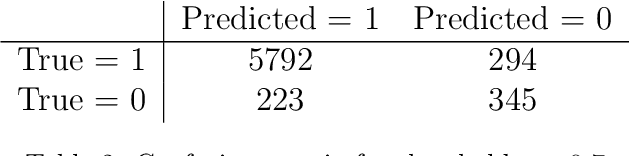
One of the main challenges in the construction of oil and gas wells is the need to detect and avoid abnormal situations, which can lead to accidents. Accidents have some indicators that help to find them during the drilling process. In this article, we present a data-driven model trained on historical data from drilling accidents that can detect different types of accidents using real-time signals. The results show that using the time-series comparison, based on aggregated statistics and gradient boosting classification, it is possible to detect an anomaly and identify its type by comparing current measurements while drilling with the stored ones from the database of accidents.