 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Biologically Plausible Training Mechanisms for Self-Supervised Learning in Deep Networks
Oct 13, 2021
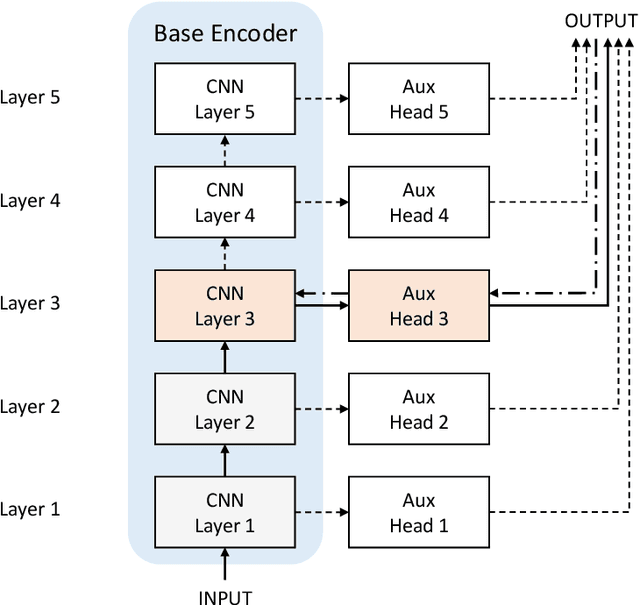
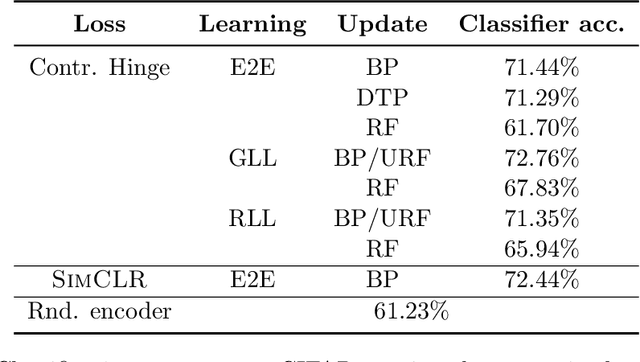
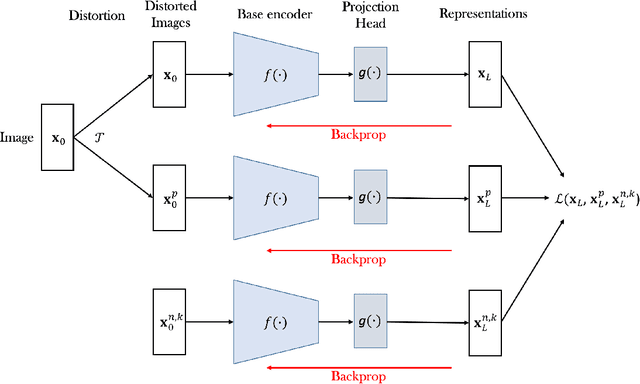
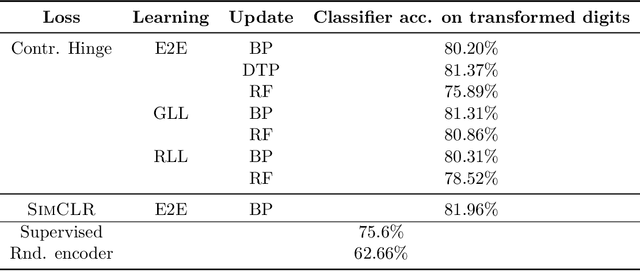
We develop biologically plausible training mechanisms for self-supervised learning (SSL) in deep networks. SSL, with a contrastive loss, is more natural as it does not require labelled data and its robustness to perturbations yields more adaptable embeddings. Moreover the perturbation of data required to create positive pairs for SSL is easily produced in a natural environment by observing objects in motion and with variable lighting over time. We propose a contrastive hinge based loss whose error involves simple local computations as opposed to the standard contrastive losses employed in the literature, which do not lend themselves easily to implementation in a network architecture due to complex computations involving ratios and inner products. Furthermore we show that learning can be performed with one of two more plausible alternatives to backpropagation. The first is difference target propagation (DTP), which trains network parameters using target-based local losses and employs a Hebbian learning rule, thus overcoming the biologically implausible symmetric weight problem in backpropagation. The second is simply layer-wise learning, where each layer is directly connected to a layer computing the loss error. The layers are either updated sequentially in a greedy fashion (GLL) or in random order (RLL), and each training stage involves a single hidden layer network. The one step backpropagation needed for each such network can either be altered with fixed random feedback weights as proposed in Lillicrap et al. (2016), or using updated random feedback as in Amit (2019). Both methods represent alternatives to the symmetric weight issue of backpropagation. By training convolutional neural networks (CNNs) with SSL and DTP, GLL or RLL, we find that our proposed framework achieves comparable performance to its implausible counterparts in both linear evaluation and transfer learning tasks.
Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Oct 05, 2021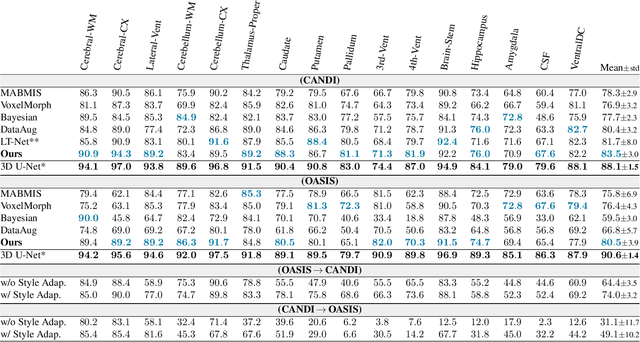
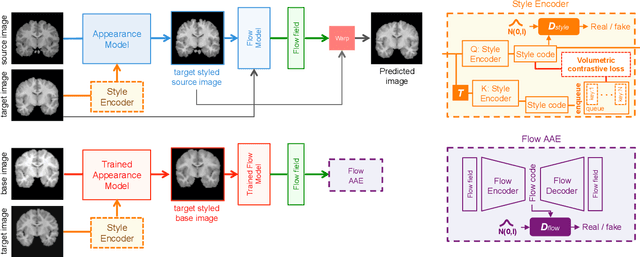
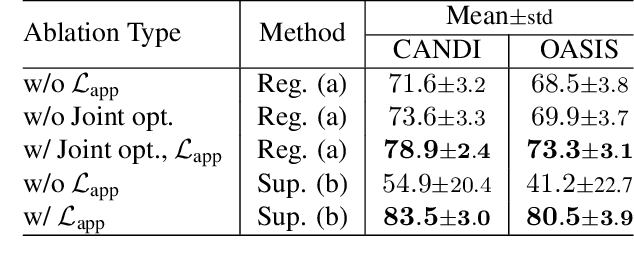
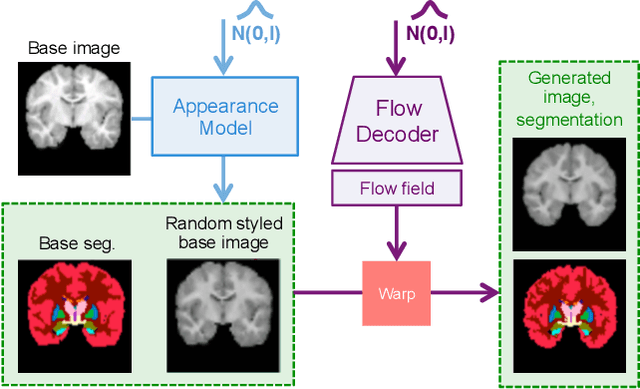
In medical image segmentation, supervised deep networks' success comes at the cost of requiring abundant labeled data. While asking domain experts to annotate only one or a few of the cohort's images is feasible, annotating all available images is impractical. This issue is further exacerbated when pre-trained deep networks are exposed to a new image dataset from an unfamiliar distribution. Using available open-source data for ad-hoc transfer learning or hand-tuned techniques for data augmentation only provides suboptimal solutions. Motivated by atlas-based segmentation, we propose a novel volumetric self-supervised learning for data augmentation capable of synthesizing volumetric image-segmentation pairs via learning transformations from a single labeled atlas to the unlabeled data. Our work's central tenet benefits from a combined view of one-shot generative learning and the proposed self-supervised training strategy that cluster unlabeled volumetric images with similar styles together. Unlike previous methods, our method does not require input volumes at inference time to synthesize new images. Instead, it can generate diversified volumetric image-segmentation pairs from a prior distribution given a single or multi-site dataset. Augmented data generated by our method used to train the segmentation network provide significant improvements over state-of-the-art deep one-shot learning methods on the task of brain MRI segmentation. Ablation studies further exemplified that the proposed appearance model and joint training are crucial to synthesize realistic examples compared to existing medical registration methods. The code, data, and models are available at https://github.com/devavratTomar/SST.
Adjustable Real-time Style Transfer
Nov 21, 2018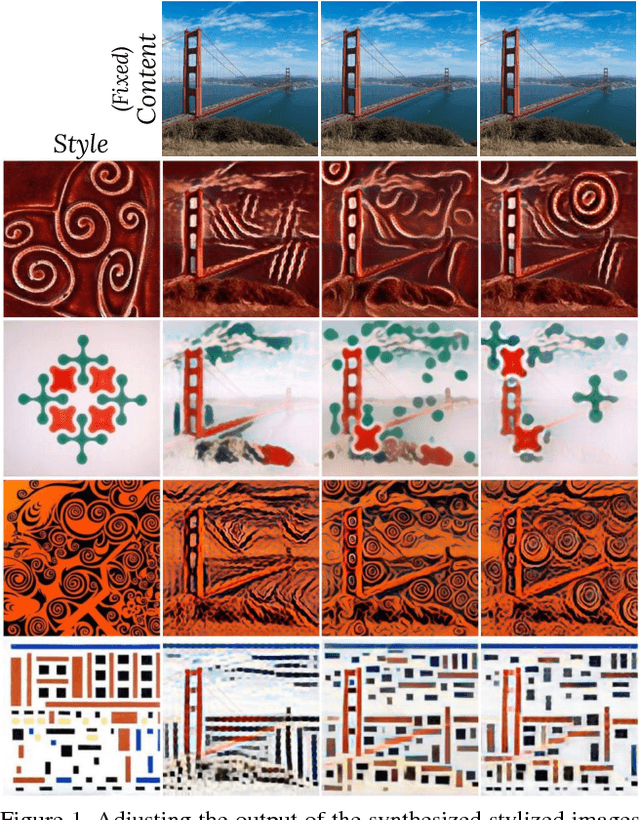

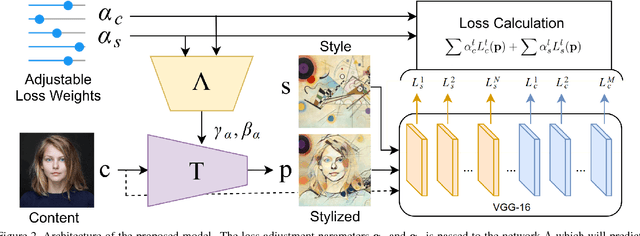
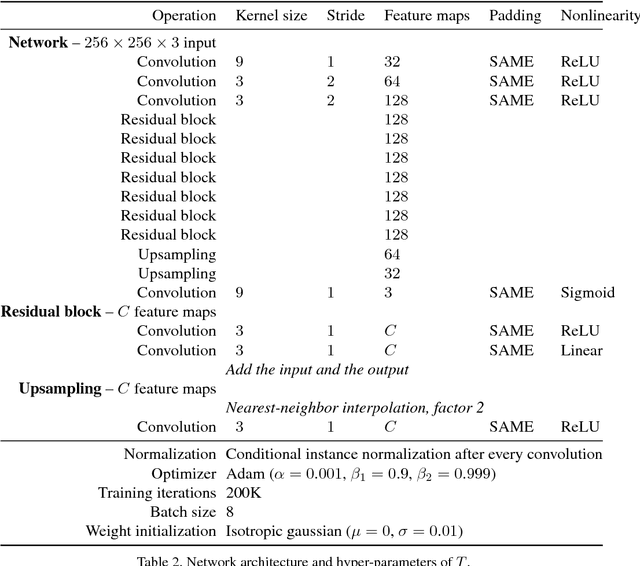
Artistic style transfer is the problem of synthesizing an image with content similar to a given image and style similar to another. Although recent feed-forward neural networks can generate stylized images in real-time, these models produce a single stylization given a pair of style/content images, and the user doesn't have control over the synthesized output. Moreover, the style transfer depends on the hyper-parameters of the model with varying "optimum" for different input images. Therefore, if the stylized output is not appealing to the user, she/he has to try multiple models or retrain one with different hyper-parameters to get a favorite stylization. In this paper, we address these issues by proposing a novel method which allows adjustment of crucial hyper-parameters, after the training and in real-time, through a set of manually adjustable parameters. These parameters enable the user to modify the synthesized outputs from the same pair of style/content images, in search of a favorite stylized image. Our quantitative and qualitative experiments indicate how adjusting these parameters is comparable to retraining the model with different hyper-parameters. We also demonstrate how these parameters can be randomized to generate results which are diverse but still very similar in style and content.
Vision-Only Robot Navigation in a Neural Radiance World
Oct 01, 2021
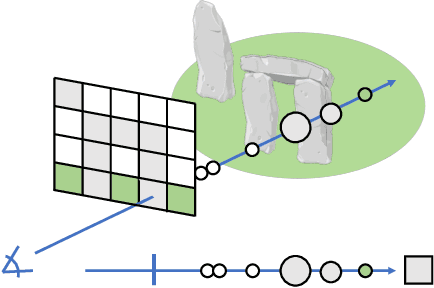
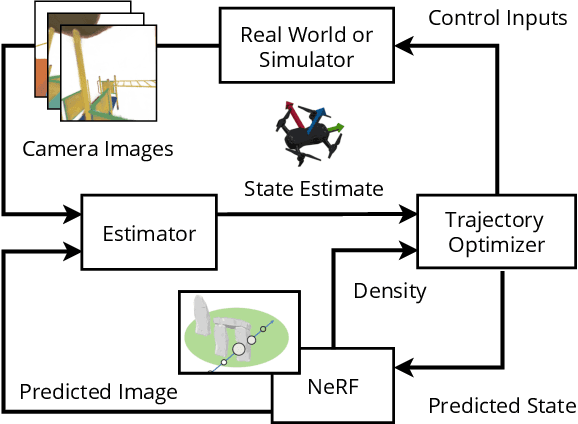
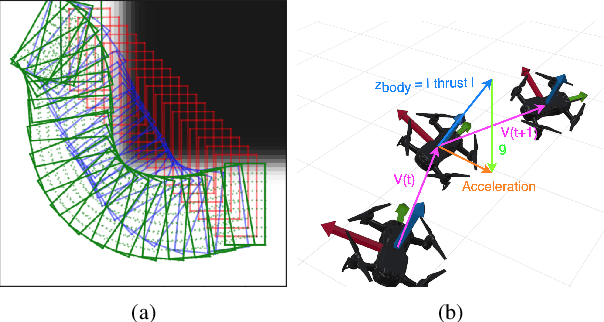
Neural Radiance Fields (NeRFs) have recently emerged as a powerful paradigm for the representation of natural, complex 3D scenes. NeRFs represent continuous volumetric density and RGB values in a neural network, and generate photo-realistic images from unseen camera viewpoints through ray tracing. We propose an algorithm for navigating a robot through a 3D environment represented as a NeRF using only an on-board RGB camera for localization. We assume the NeRF for the scene has been pre-trained offline, and the robot's objective is to navigate through unoccupied space in the NeRF to reach a goal pose. We introduce a trajectory optimization algorithm that avoids collisions with high-density regions in the NeRF based on a discrete time version of differential flatness that is amenable to constraining the robot's full pose and control inputs. We also introduce an optimization based filtering method to estimate 6DoF pose and velocities for the robot in the NeRF given only an onboard RGB camera. We combine the trajectory planner with the pose filter in an online replanning loop to give a vision-based robot navigation pipeline. We present simulation results with a quadrotor robot navigating through a jungle gym environment, the inside of a church, and Stonehenge using only an RGB camera. We also demonstrate an omnidirectional ground robot navigating through the church, requiring it to reorient to fit through the narrow gap. Videos of this work can be found at https://mikh3x4.github.io/nerf-navigation/ .
Detection of Deepfake Videos Using Long Distance Attention
Jun 24, 2021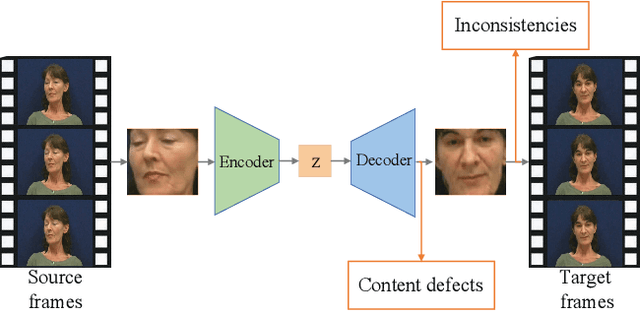
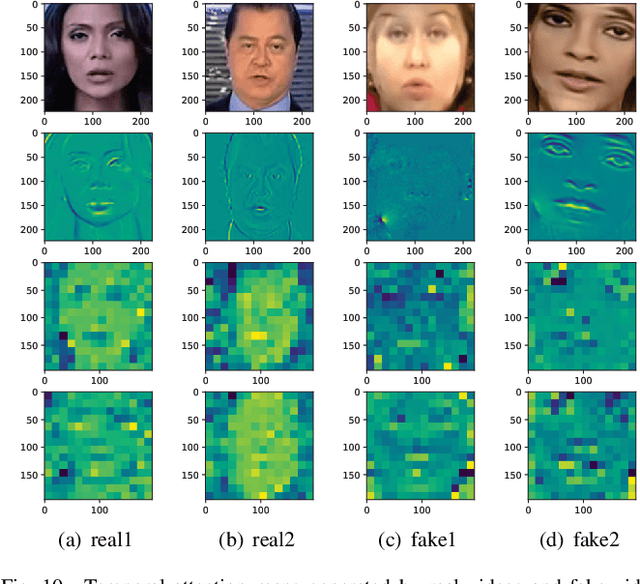
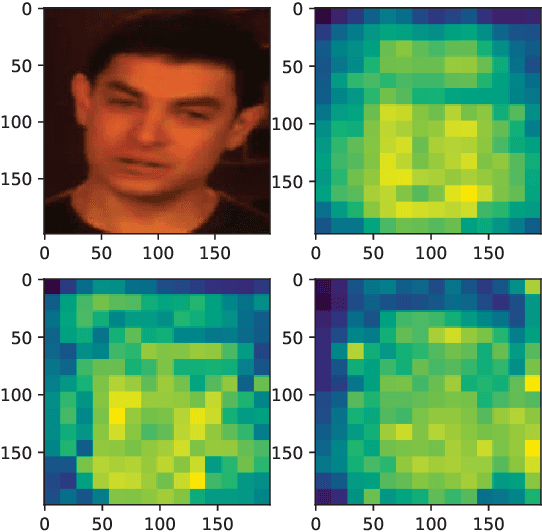

With the rapid progress of deepfake techniques in recent years, facial video forgery can generate highly deceptive video contents and bring severe security threats. And detection of such forgery videos is much more urgent and challenging. Most existing detection methods treat the problem as a vanilla binary classification problem. In this paper, the problem is treated as a special fine-grained classification problem since the differences between fake and real faces are very subtle. It is observed that most existing face forgery methods left some common artifacts in the spatial domain and time domain, including generative defects in the spatial domain and inter-frame inconsistencies in the time domain. And a spatial-temporal model is proposed which has two components for capturing spatial and temporal forgery traces in global perspective respectively. The two components are designed using a novel long distance attention mechanism. The one component of the spatial domain is used to capture artifacts in a single frame, and the other component of the time domain is used to capture artifacts in consecutive frames. They generate attention maps in the form of patches. The attention method has a broader vision which contributes to better assembling global information and extracting local statistic information. Finally, the attention maps are used to guide the network to focus on pivotal parts of the face, just like other fine-grained classification methods. The experimental results on different public datasets demonstrate that the proposed method achieves the state-of-the-art performance, and the proposed long distance attention method can effectively capture pivotal parts for face forgery.
Physics-informed Convolutional Neural Networks for Temperature Field Prediction of Heat Source Layout without Labeled Data
Sep 26, 2021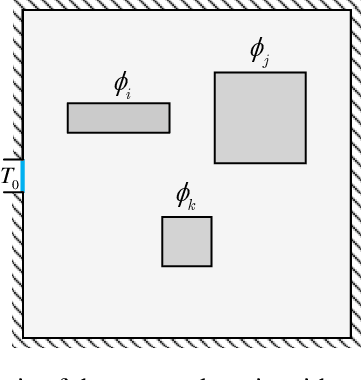
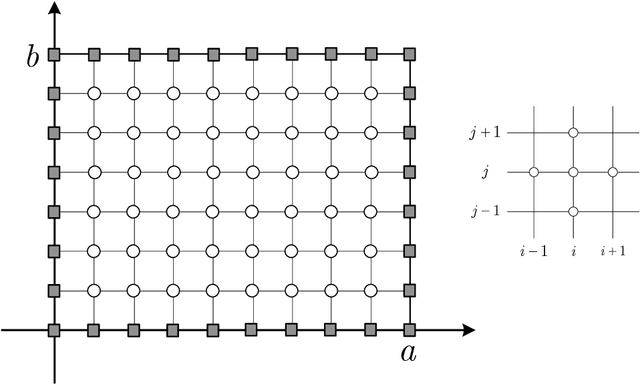
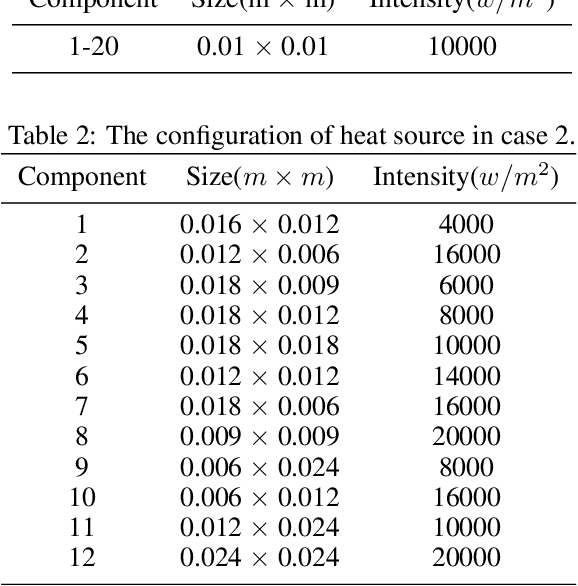
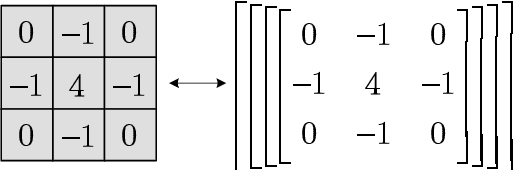
Recently, surrogate models based on deep learning have attracted much attention for engineering analysis and optimization. As the construction of data pairs in most engineering problems is time-consuming, data acquisition is becoming the predictive capability bottleneck of most deep surrogate models, which also exists in surrogate for thermal analysis and design. To address this issue, this paper develops a physics-informed convolutional neural network (CNN) for the thermal simulation surrogate. The network can learn a mapping from heat source layout to the steady-state temperature field without labeled data, which equals solving an entire family of partial difference equations (PDEs). To realize the physics-guided training without labeled data, we employ the heat conduction equation and finite difference method to construct the loss function. Since the solution is sensitive to boundary conditions, we properly impose hard constraints by padding in the Dirichlet and Neumann boundary conditions. In addition, the neural network architecture is well-designed to improve the prediction precision of the problem at hand, and pixel-level online hard example mining is introduced to overcome the imbalance of optimization difficulty in the computation domain. The experiments demonstrate that the proposed method can provide comparable predictions with numerical method and data-driven deep learning models. We also conduct various ablation studies to investigate the effectiveness of the network component and training methods proposed in this paper.
Ill-posed Surface Emissivity Retrieval from Multi-Geometry Hyperspectral Images using a Hybrid Deep Neural Network
Jul 17, 2021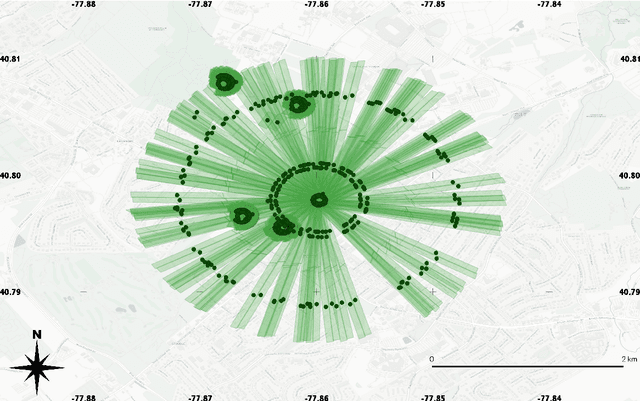
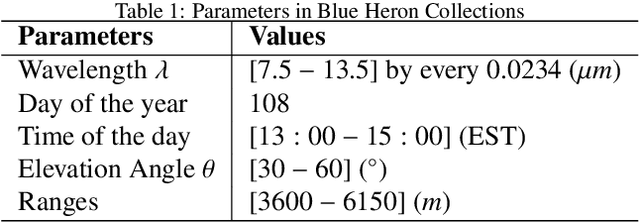
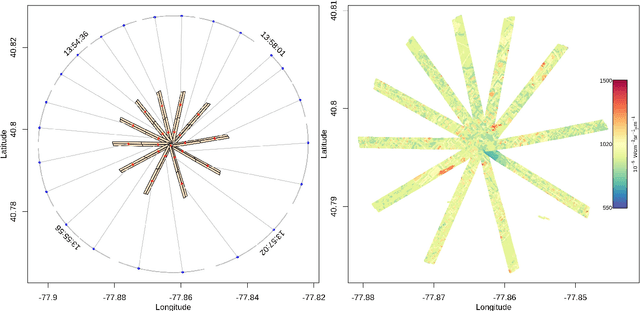
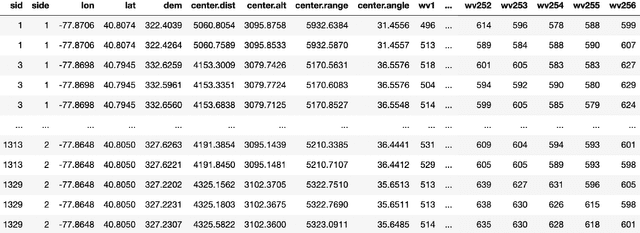
Atmospheric correction is a fundamental task in remote sensing because observations are taken either of the atmosphere or looking through the atmosphere. Atmospheric correction errors can significantly alter the spectral signature of the observations, and lead to invalid classifications or target detection. This is even more crucial when working with hyperspectral data, where a precise measurement of spectral properties is required. State-of-the-art physics-based atmospheric correction approaches require extensive prior knowledge about sensor characteristics, collection geometry, and environmental characteristics of the scene being collected. These approaches are computationally expensive, prone to inaccuracy due to lack of sufficient environmental and collection information, and often impossible for real-time applications. In this paper, a geometry-dependent hybrid neural network is proposed for automatic atmospheric correction using multi-scan hyperspectral data collected from different geometries. The proposed network can characterize the atmosphere without any additional meteorological data. A grid-search method is also proposed to solve the temperature emissivity separation problem. Results show that the proposed network has the capacity to accurately characterize the atmosphere and estimate target emissivity spectra with a Mean Absolute Error (MAE) under 0.02 for 29 different materials. This solution can lead to accurate atmospheric correction to improve target detection for real time applications.
Bayesian logistic regression for online recalibration and revision of risk prediction models with performance guarantees
Oct 13, 2021

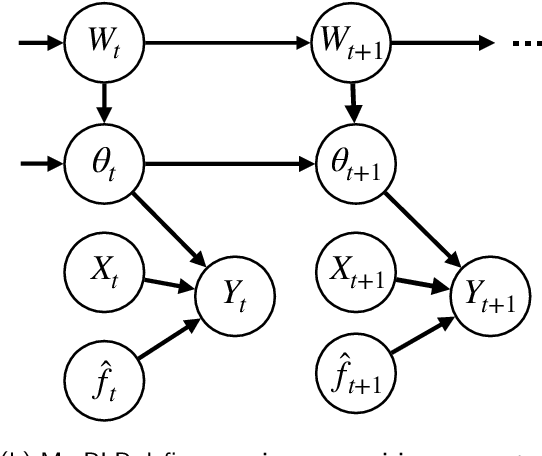
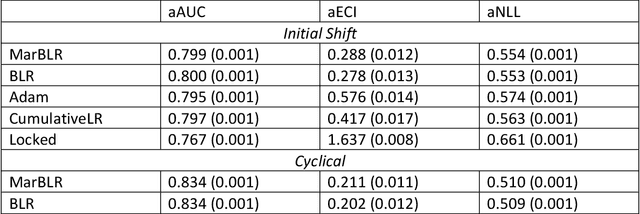
After deploying a clinical prediction model, subsequently collected data can be used to fine-tune its predictions and adapt to temporal shifts. Because model updating carries risks of over-updating/fitting, we study online methods with performance guarantees. We introduce two procedures for continual recalibration or revision of an underlying prediction model: Bayesian logistic regression (BLR) and a Markov variant that explicitly models distribution shifts (MarBLR). We perform empirical evaluation via simulations and a real-world study predicting COPD risk. We derive "Type I and II" regret bounds, which guarantee the procedures are non-inferior to a static model and competitive with an oracle logistic reviser in terms of the average loss. Both procedures consistently outperformed the static model and other online logistic revision methods. In simulations, the average estimated calibration index (aECI) of the original model was 0.828 (95%CI 0.818-0.938). Online recalibration using BLR and MarBLR improved the aECI, attaining 0.265 (95%CI 0.230-0.300) and 0.241 (95%CI 0.216-0.266), respectively. When performing more extensive logistic model revisions, BLR and MarBLR increased the average AUC (aAUC) from 0.767 (95%CI 0.765-0.769) to 0.800 (95%CI 0.798-0.802) and 0.799 (95%CI 0.797-0.801), respectively, in stationary settings and protected against substantial model decay. In the COPD study, BLR and MarBLR dynamically combined the original model with a continually-refitted gradient boosted tree to achieve aAUCs of 0.924 (95%CI 0.913-0.935) and 0.925 (95%CI 0.914-0.935), compared to the static model's aAUC of 0.904 (95%CI 0.892-0.916). Despite its simplicity, BLR is highly competitive with MarBLR. MarBLR outperforms BLR when its prior better reflects the data. BLR and MarBLR can improve the transportability of clinical prediction models and maintain their performance over time.
Generic Ontology Design Patterns: Roles and Change over Time
Nov 18, 2020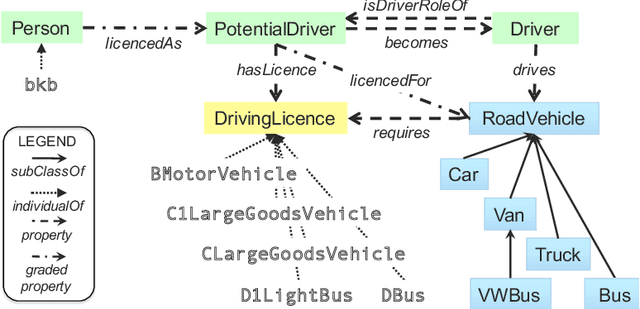

In this chapter we propose Generic Ontology Design Patterns, GODPs, as a methodology for representing and instantiating ontology design patterns in a way that is adaptable, and allows domain experts (and other users) to safely use them without cluttering their ontologies.
Warming-up recurrent neural networks to maximize reachable multi-stability greatly improves learning
Jun 02, 2021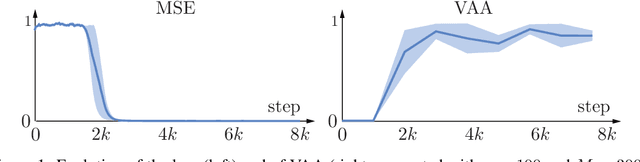
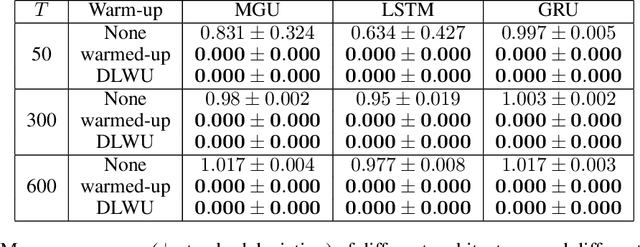

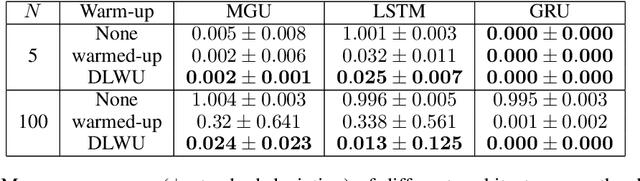
Training recurrent neural networks is known to be difficult when time dependencies become long. Consequently, training standard gated cells such as gated recurrent units and long-short term memory on benchmarks where long-term memory is required remains an arduous task. In this work, we propose a general way to initialize any recurrent network connectivity through a process called "warm-up" to improve its capability to learn arbitrarily long time dependencies. This initialization process is designed to maximize network reachable multi-stability, i.e. the number of attractors within the network that can be reached through relevant input trajectories. Warming-up is performed before training, using stochastic gradient descent on a specifically designed loss. We show that warming-up greatly improves recurrent neural network performance on long-term memory benchmarks for multiple recurrent cell types, but can sometimes impede precision. We therefore introduce a parallel recurrent network structure with partial warm-up that is shown to greatly improve learning on long time-series while maintaining high levels of precision. This approach provides a general framework for improving learning abilities of any recurrent cell type when long-term memory is required.