 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Non-Line-of-Sight Photography
Sep 16, 2021
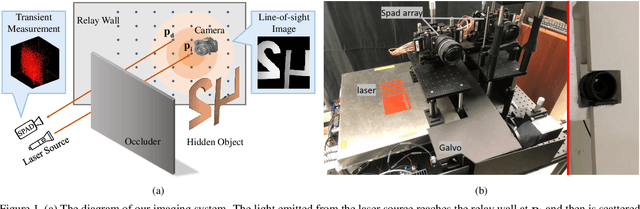
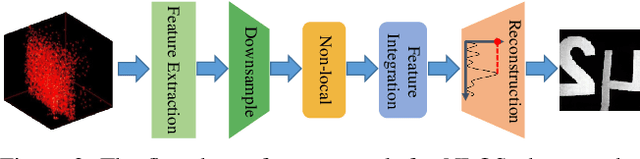


Non-line-of-sight (NLOS) imaging is based on capturing the multi-bounce indirect reflections from the hidden objects. Active NLOS imaging systems rely on the capture of the time of flight of light through the scene, and have shown great promise for the accurate and robust reconstruction of hidden scenes without the need for specialized scene setups and prior assumptions. Despite that existing methods can reconstruct 3D geometries of the hidden scene with excellent depth resolution, accurately recovering object textures and appearance with high lateral resolution remains an challenging problem. In this work, we propose a new problem formulation, called NLOS photography, to specifically address this deficiency. Rather than performing an intermediate estimate of the 3D scene geometry, our method follows a data-driven approach and directly reconstructs 2D images of a NLOS scene that closely resemble the pictures taken with a conventional camera from the location of the relay wall. This formulation largely simplifies the challenging reconstruction problem by bypassing the explicit modeling of 3D geometry, and enables the learning of a deep model with a relatively small training dataset. The results are NLOS reconstructions of unprecedented lateral resolution and image quality.
Value-Function-based Sequential Minimization for Bi-level Optimization
Oct 11, 2021
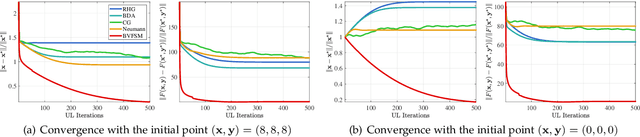

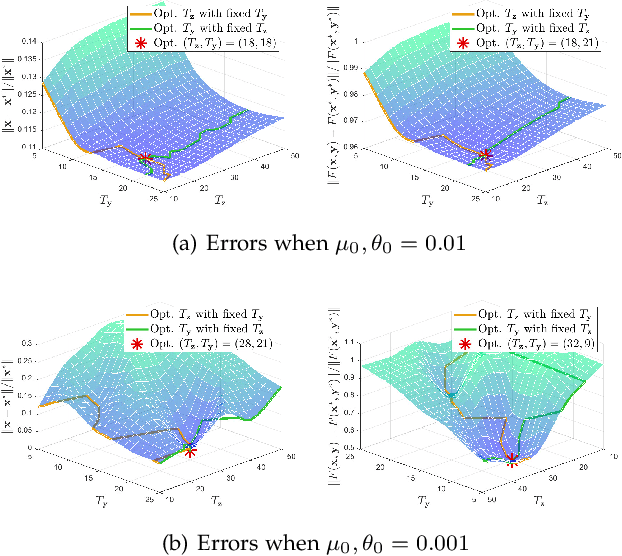
Gradient-based Bi-Level Optimization (BLO) methods have been widely applied to solve modern machine learning problems. However, most existing solution strategies are theoretically designed based on restrictive assumptions (e.g., convexity of the lower-level sub-problem), and computationally not applicable for high-dimensional tasks. Moreover, there are almost no gradient-based methods that can efficiently handle BLO in those challenging scenarios, such as BLO with functional constraints and pessimistic BLO. In this work, by reformulating BLO into an approximated single-level problem based on the value-function, we provide a new method, named Bi-level Value-Function-based Sequential Minimization (BVFSM), to partially address the above issues. To be specific, BVFSM constructs a series of value-function-based approximations, and thus successfully avoids the repeated calculations of recurrent gradient and Hessian inverse required by existing approaches, which are time-consuming (especially for high-dimensional tasks). We also extend BVFSM to address BLO with additional upper- and lower-level functional constraints. More importantly, we demonstrate that the algorithmic framework of BVFSM can also be used for the challenging pessimistic BLO, which has never been properly solved by existing gradient-based methods. On the theoretical side, we strictly prove the convergence of BVFSM on these types of BLO, in which the restrictive lower-level convexity assumption is completely discarded. To our best knowledge, this is the first gradient-based algorithm that can solve different kinds of BLO problems (e.g., optimistic, pessimistic and with constraints) all with solid convergence guarantees. Extensive experiments verify our theoretical investigations and demonstrate the superiority of BVFSM on various real-world applications.
Learning Heterogeneous Temporal Patterns of User Preference for Timely Recommendation
Apr 29, 2021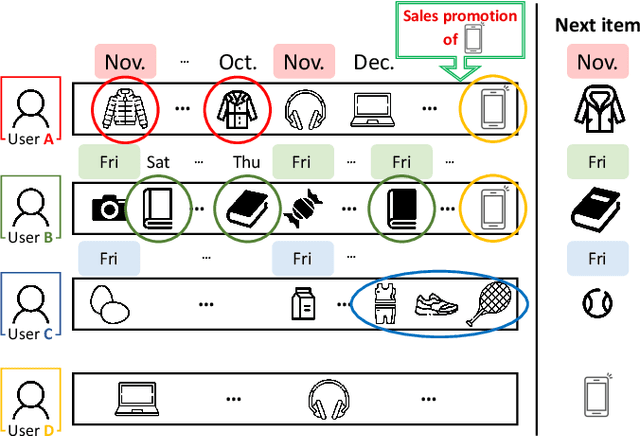
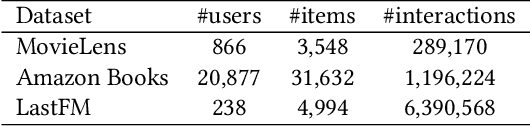
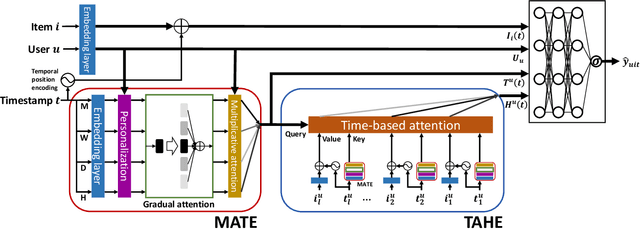
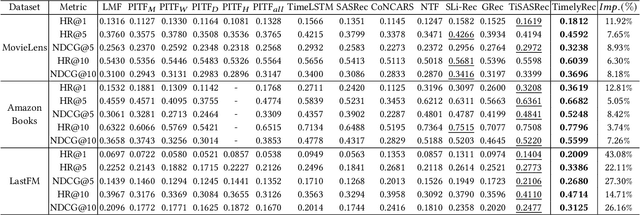
Recommender systems have achieved great success in modeling user's preferences on items and predicting the next item the user would consume. Recently, there have been many efforts to utilize time information of users' interactions with items to capture inherent temporal patterns of user behaviors and offer timely recommendations at a given time. Existing studies regard the time information as a single type of feature and focus on how to associate it with user preferences on items. However, we argue they are insufficient for fully learning the time information because the temporal patterns of user preference are usually heterogeneous. A user's preference for a particular item may 1) increase periodically or 2) evolve over time under the influence of significant recent events, and each of these two kinds of temporal pattern appears with some unique characteristics. In this paper, we first define the unique characteristics of the two kinds of temporal pattern of user preference that should be considered in time-aware recommender systems. Then we propose a novel recommender system for timely recommendations, called TimelyRec, which jointly learns the heterogeneous temporal patterns of user preference considering all of the defined characteristics. In TimelyRec, a cascade of two encoders captures the temporal patterns of user preference using a proposed attention module for each encoder. Moreover, we introduce an evaluation scenario that evaluates the performance on predicting an interesting item and when to recommend the item simultaneously in top-K recommendation (i.e., item-timing recommendation). Our extensive experiments on a scenario for item recommendation and the proposed scenario for item-timing recommendation on real-world datasets demonstrate the superiority of TimelyRec and the proposed attention modules.
Performance Evaluation of Deep Transfer Learning on Multiclass Identification of Common Weed Species in Cotton Production Systems
Oct 11, 2021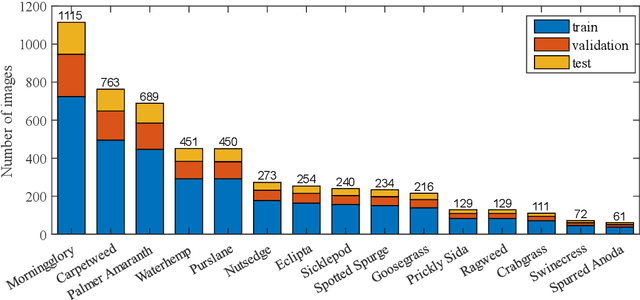
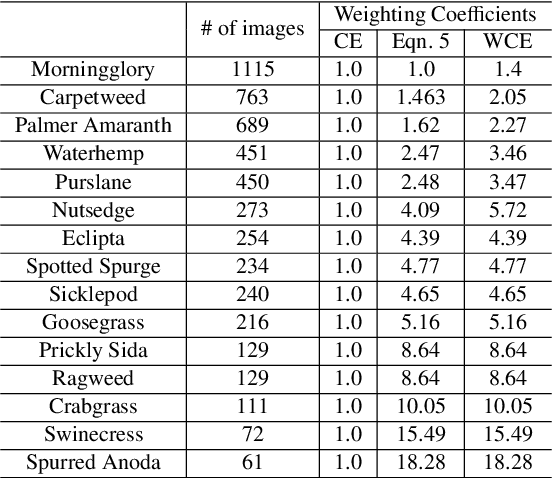

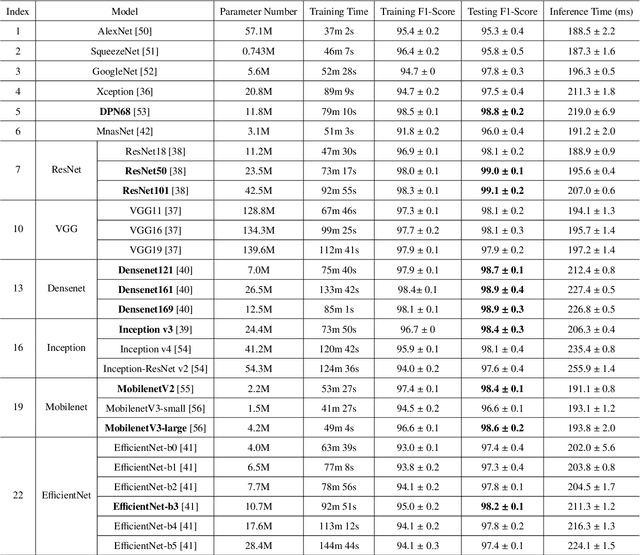
Precision weed management offers a promising solution for sustainable cropping systems through the use of chemical-reduced/non-chemical robotic weeding techniques, which apply suitable control tactics to individual weeds. Therefore, accurate identification of weed species plays a crucial role in such systems to enable precise, individualized weed treatment. This paper makes a first comprehensive evaluation of deep transfer learning (DTL) for identifying common weeds specific to cotton production systems in southern United States. A new dataset for weed identification was created, consisting of 5187 color images of 15 weed classes collected under natural lighting conditions and at varied weed growth stages, in cotton fields during the 2020 and 2021 field seasons. We evaluated 27 state-of-the-art deep learning models through transfer learning and established an extensive benchmark for the considered weed identification task. DTL achieved high classification accuracy of F1 scores exceeding 95%, requiring reasonably short training time (less than 2.5 hours) across models. ResNet101 achieved the best F1-score of 99.1% whereas 14 out of the 27 models achieved F1 scores exceeding 98.0%. However, the performance on minority weed classes with few training samples was less satisfactory for models trained with a conventional, unweighted cross entropy loss function. To address this issue, a weighted cross entropy loss function was adopted, which achieved substantially improved accuracies for minority weed classes. Furthermore, a deep learning-based cosine similarity metrics was employed to analyze the similarity among weed classes, assisting in the interpretation of classifications. Both the codes for model benchmarking and the weed dataset are made publicly available, which expect to be be a valuable resource for future research in weed identification and beyond.
Causal structure learning from time series: Large regression coefficients may predict causal links better in practice than small p-values
Feb 21, 2020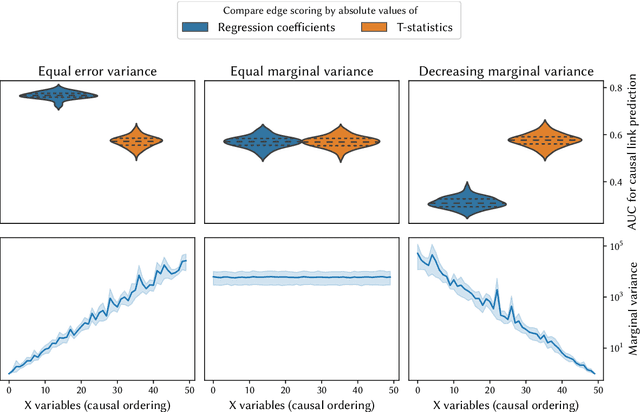
In this article, we describe the algorithms for causal structure learning from time series data that won the Causality 4 Climate competition at the Conference on Neural Information Processing Systems 2019 (NeurIPS). We examine how our combination of established ideas achieves competitive performance on semi-realistic and realistic time series data exhibiting common challenges in real-world Earth sciences data. In particular, we discuss a) a rationale for leveraging linear methods to identify causal links in non-linear systems, b) a simulation-backed explanation as to why large regression coefficients may predict causal links better in practice than small p-values and thus why normalising the data may sometimes hinder causal structure learning. For benchmark usage, we provide implementations at https://github.com/sweichwald/tidybench and detail the algorithms here. We propose the presented competition-proven methods for baseline benchmark comparisons to guide the development of novel algorithms for structure learning from time series.
Workshop on Autonomous Driving at CVPR 2021: Technical Report for Streaming Perception Challenge
Jul 27, 2021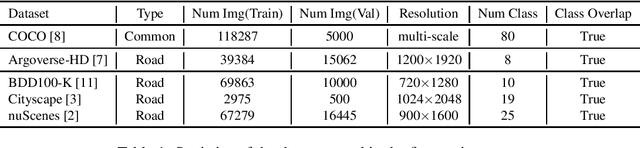
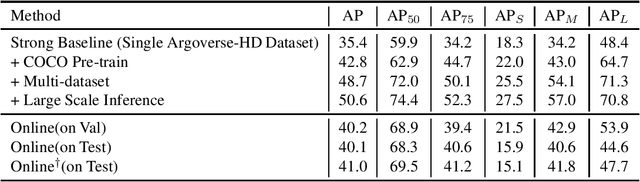
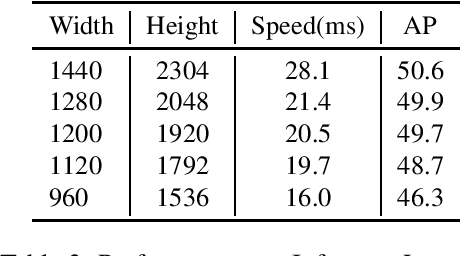
In this report, we introduce our real-time 2D object detection system for the realistic autonomous driving scenario. Our detector is built on a newly designed YOLO model, called YOLOX. On the Argoverse-HD dataset, our system achieves 41.0 streaming AP, which surpassed second place by 7.8/6.1 on detection-only track/fully track, respectively. Moreover, equipped with TensorRT, our model achieves the 30FPS inference speed with a high-resolution input size (e.g., 1440-2304). Code and models will be available at https://github.com/Megvii-BaseDetection/YOLOX
Distributed Optimization of Graph Convolutional Network using Subgraph Variance
Oct 06, 2021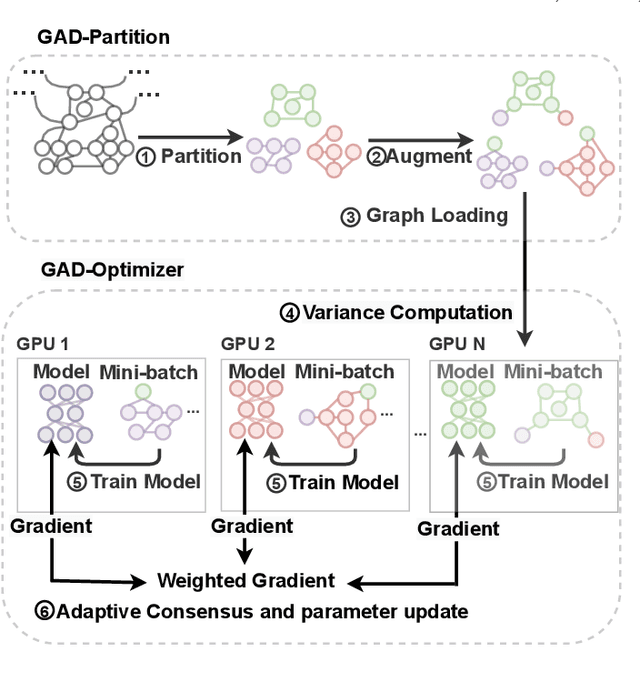

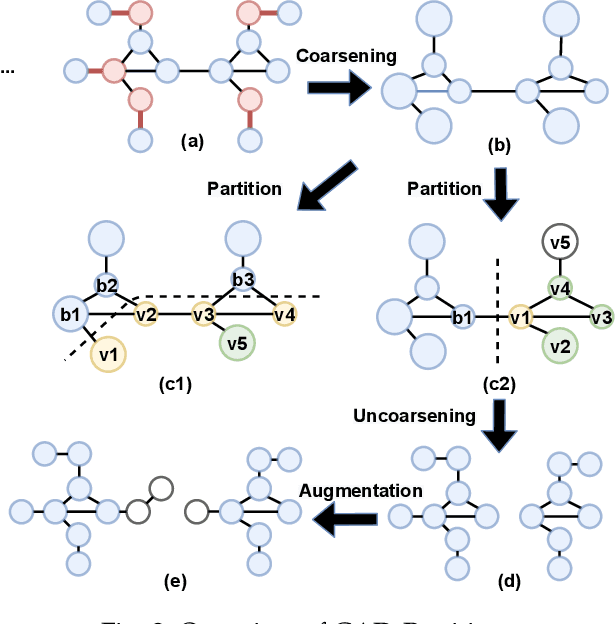
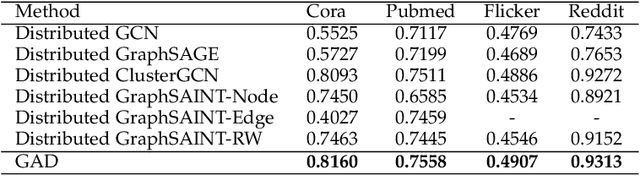
In recent years, Graph Convolutional Networks (GCNs) have achieved great success in learning from graph-structured data. With the growing tendency of graph nodes and edges, GCN training by single processor cannot meet the demand for time and memory, which led to a boom into distributed GCN training frameworks research. However, existing distributed GCN training frameworks require enormous communication costs between processors since multitudes of dependent nodes and edges information need to be collected and transmitted for GCN training from other processors. To address this issue, we propose a Graph Augmentation based Distributed GCN framework(GAD). In particular, GAD has two main components, GAD-Partition and GAD-Optimizer. We first propose a graph augmentation-based partition (GAD-Partition) that can divide original graph into augmented subgraphs to reduce communication by selecting and storing as few significant nodes of other processors as possible while guaranteeing the accuracy of the training. In addition, we further design a subgraph variance-based importance calculation formula and propose a novel weighted global consensus method, collectively referred to as GAD-Optimizer. This optimizer adaptively reduces the importance of subgraphs with large variances for the purpose of reducing the effect of extra variance introduced by GAD-Partition on distributed GCN training. Extensive experiments on four large-scale real-world datasets demonstrate that our framework significantly reduces the communication overhead (50%), improves the convergence speed (2X) of distributed GCN training, and slight gain in accuracy (0.45%) based on minimal redundancy compared to the state-of-the-art methods.
Mixed Control for Whole-Body Compliance of a Humanoid Robot
Sep 16, 2021
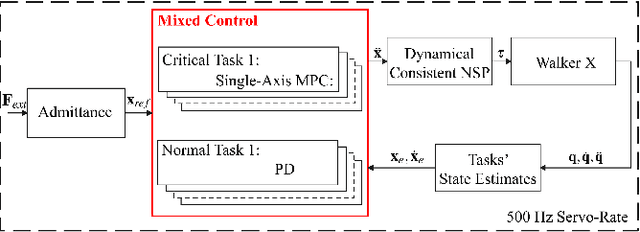
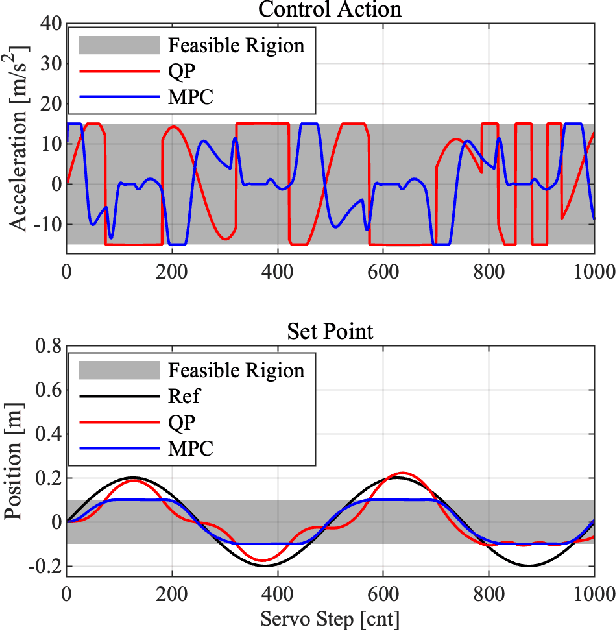
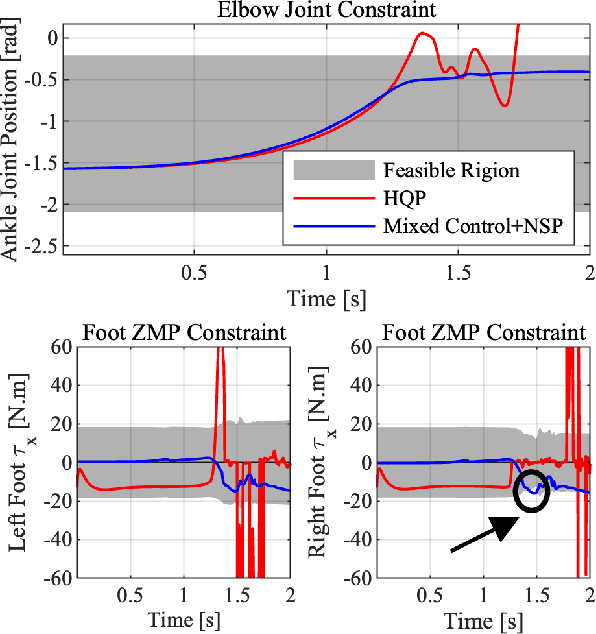
The hierarchical quadratic programming (HQP) is commonly applied to consider strict hierarchies of multi-tasks and robot's physical inequality constraints during whole-body compliance. However, for the one-step HQP, the solution can oscillate when it is close to the boundary of constraints. It is because the abrupt hit of the bounds gives rise to unrealisable jerks and even infeasible solutions. This paper proposes the mixed control, which blends the single-axis model predictive control (MPC) and proportional derivate (PD) control for the whole-body compliance to overcome these deficiencies. The MPC predicts the distances between the bounds and the control target of the critical tasks, and it provides smooth and feasible solutions by prediction and optimisation in advance. However, applying MPC will inevitably increase the computation time. Therefore, to achieve a 500 Hz servo rate, the PD controllers still regulate other tasks to save computation resources. Also, we use a more efficient null space projection (NSP) whole-body controller instead of the HQP and distribute the single-axis MPCs into four CPU cores for parallel computation. Finally, we validate the desired capabilities of the proposed strategy via Simulations and the experiment on the humanoid robot Walker X.
Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training
Aug 13, 2021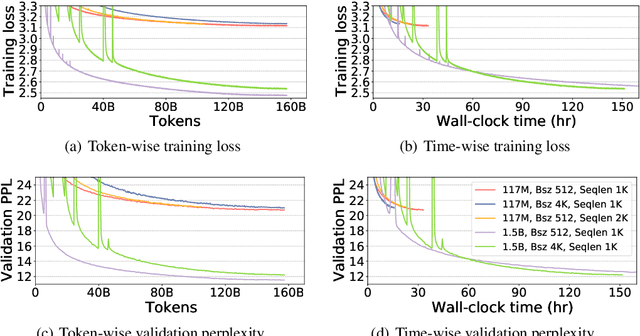
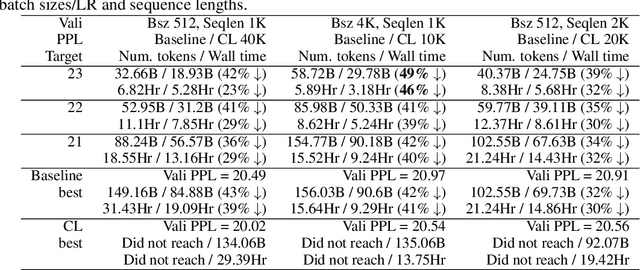
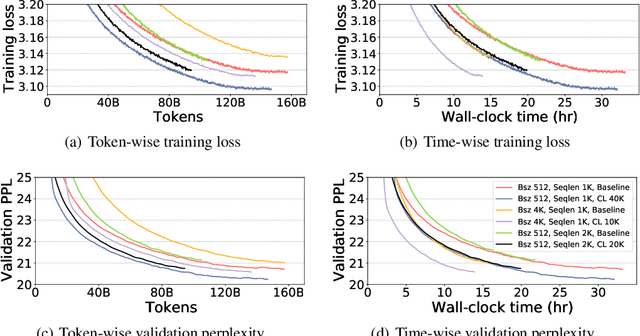
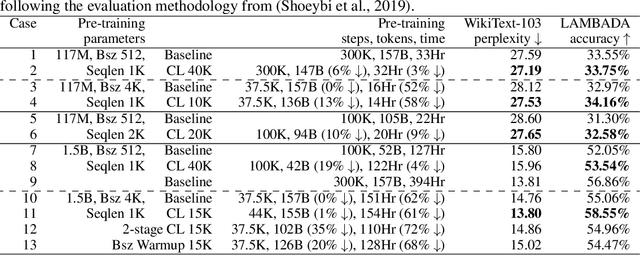
Recent works have demonstrated great success in training high-capacity autoregressive language models (GPT, GPT-2, GPT-3) on a huge amount of unlabeled text corpus for text generation. Despite showing great results, this generates two training efficiency challenges. First, training large corpora can be extremely timing consuming, and how to present training samples to the model to improve the token-wise convergence speed remains a challenging and open question. Second, many of these large models have to be trained with hundreds or even thousands of processors using data-parallelism with a very large batch size. Despite of its better compute efficiency, it has been observed that large-batch training often runs into training instability issue or converges to solutions with bad generalization performance. To overcome these two challenges, we present a study of a curriculum learning based approach, which helps improves the pre-training convergence speed of autoregressive models. More importantly, we find that curriculum learning, as a regularization method, exerts a gradient variance reduction effect and enables to train autoregressive models with much larger batch sizes and learning rates without training instability, further improving the training speed. Our evaluations demonstrate that curriculum learning enables training GPT-2 models (with up to 1.5B parameters) with 8x larger batch size and 4x larger learning rate, whereas the baseline approach struggles with training divergence. To achieve the same validation perplexity targets during pre-training, curriculum learning reduces the required number of tokens and wall clock time by up to 59% and 54%, respectively. To achieve the same or better zero-shot WikiText-103/LAMBADA evaluation results at the end of pre-training, curriculum learning reduces the required number of tokens and wall clock time by up to 13% and 61%, respectively.
Adaptive Computing in Robotics, Leveraging ROS 2 to Enable Software-Defined Hardware for FPGAs
Aug 30, 2021
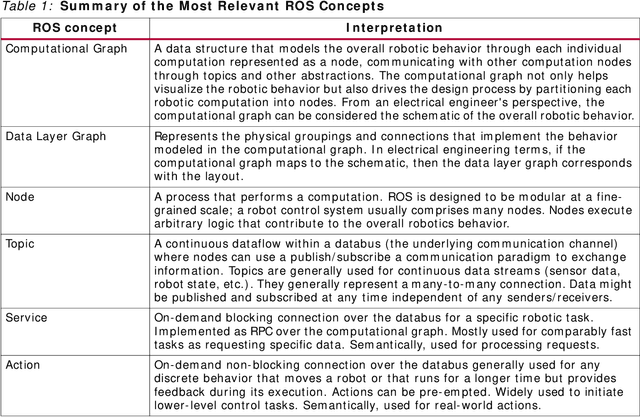
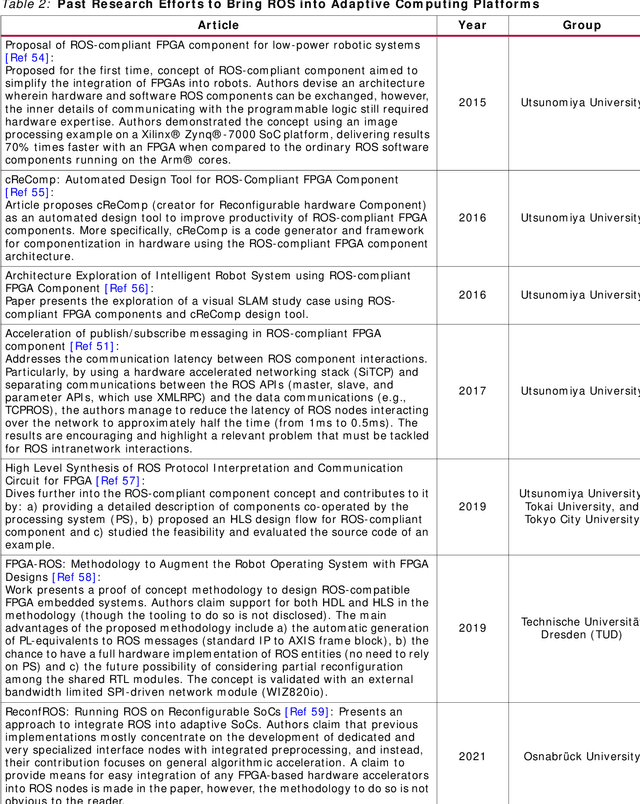
Traditional software development in robotics is about programming functionality in the CPU of a given robot with a pre-defined architecture and constraints. With adaptive computing, instead, building a robotic behavior is about programming an architecture. By leveraging adaptive computing, roboticists can adapt one or more of the properties of its computing systems (e.g. its determinism, power consumption, security posture, or throughput) at run time. Roboticists are not, however, hardware engineers, and embedded expertise is scarce among them. This white paper adopts a ROS 2 roboticist-centric view for adaptive computing and proposes an architecture to include FPGAs as a first-class participant of the ROS 2 ecosystem. The architecture proposed is platform- and technology-agnostic, and is easily portable. The core components of the architecture are disclosed under an Apache 2.0 license, paving the way for roboticists to leverage adaptive computing and create software-defined hardware.