 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Infer Implicit Contexts in Real-time Online-to-Offline Recommendation
Jul 08, 2019
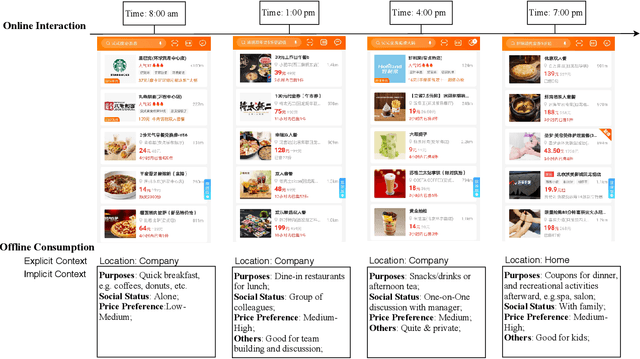
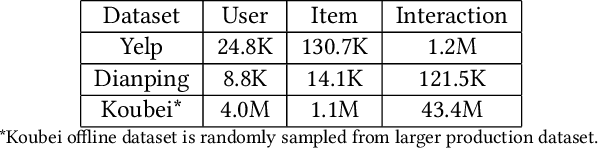
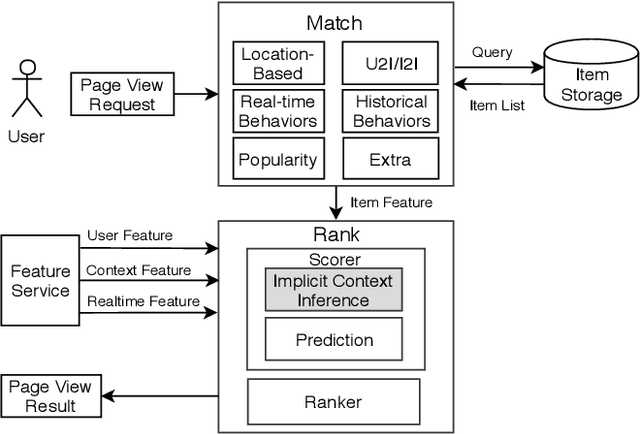
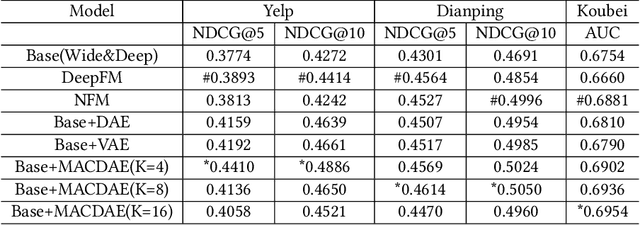
Understanding users' context is essential for successful recommendations, especially for Online-to-Offline (O2O) recommendation, such as Yelp, Groupon, and Koubei. Different from traditional recommendation where individual preference is mostly static, O2O recommendation should be dynamic to capture variation of users' purposes across time and location. However, precisely inferring users' real-time contexts information, especially those implicit ones, is extremely difficult, and it is a central challenge for O2O recommendation. In this paper, we propose a new approach, called Mixture Attentional Constrained Denoise AutoEncoder (MACDAE), to infer implicit contexts and consequently, to improve the quality of real-time O2O recommendation. In MACDAE, we first leverage the interaction among users, items, and explicit contexts to infer users' implicit contexts, then combine the learned implicit-context representation into an end-to-end model to make the recommendation. MACDAE works quite well in the real system. We conducted both offline and online evaluations of the proposed approach. Experiments on several real-world datasets (Yelp, Dianping, and Koubei) show our approach could achieve significant improvements over state-of-the-arts. Furthermore, online A/B test suggests a 2.9% increase for click-through rate and 5.6% improvement for conversion rate in real-world traffic. Our model has been deployed in the product of "Guess You Like" recommendation in Koubei.
Towards efficient end-to-end speech recognition with biologically-inspired neural networks
Oct 04, 2021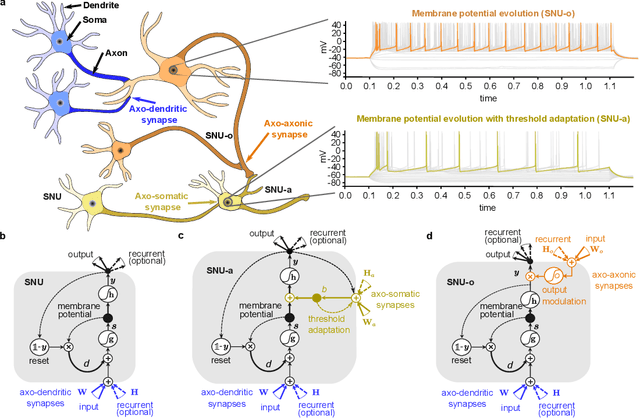


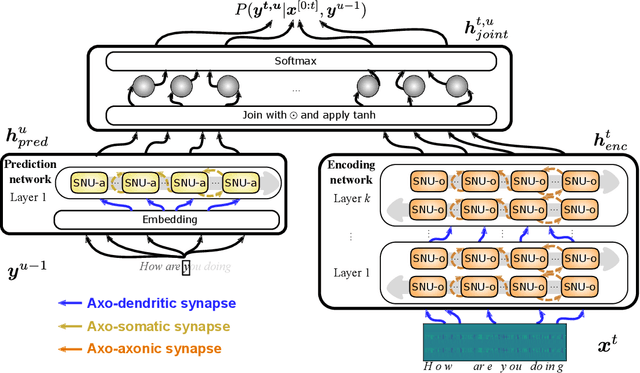
Automatic speech recognition (ASR) is a capability which enables a program to process human speech into a written form. Recent developments in artificial intelligence (AI) have led to high-accuracy ASR systems based on deep neural networks, such as the recurrent neural network transducer (RNN-T). However, the core components and the performed operations of these approaches depart from the powerful biological counterpart, i.e., the human brain. On the other hand, the current developments in biologically-inspired ASR models, based on spiking neural networks (SNNs), lag behind in terms of accuracy and focus primarily on small scale applications. In this work, we revisit the incorporation of biologically-plausible models into deep learning and we substantially enhance their capabilities, by taking inspiration from the diverse neural and synaptic dynamics found in the brain. In particular, we introduce neural connectivity concepts emulating the axo-somatic and the axo-axonic synapses. Based on this, we propose novel deep learning units with enriched neuro-synaptic dynamics and integrate them into the RNN-T architecture. We demonstrate for the first time, that a biologically realistic implementation of a large-scale ASR model can yield competitive performance levels compared to the existing deep learning models. Specifically, we show that such an implementation bears several advantages, such as a reduced computational cost and a lower latency, which are critical for speech recognition applications.
Learning Sparse Graph with Minimax Concave Penalty under Gaussian Markov Random Fields
Sep 17, 2021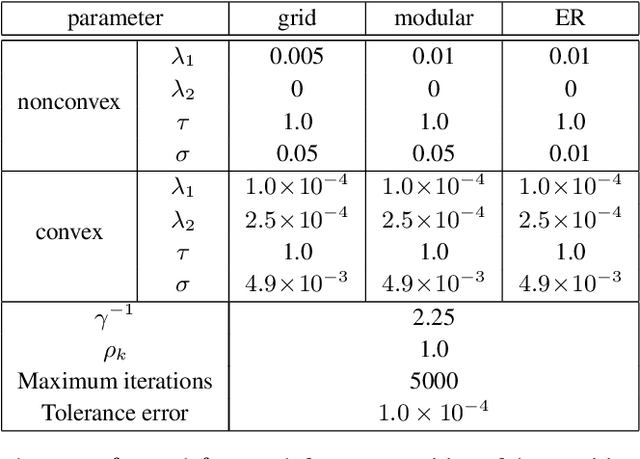
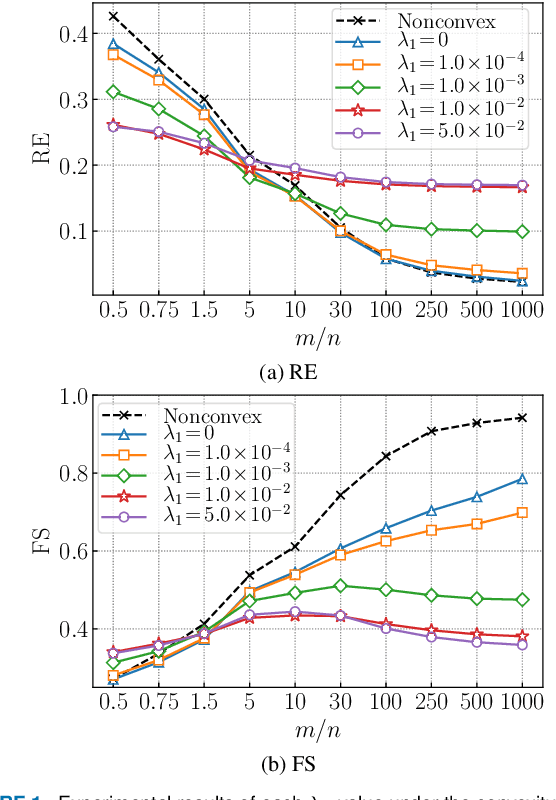
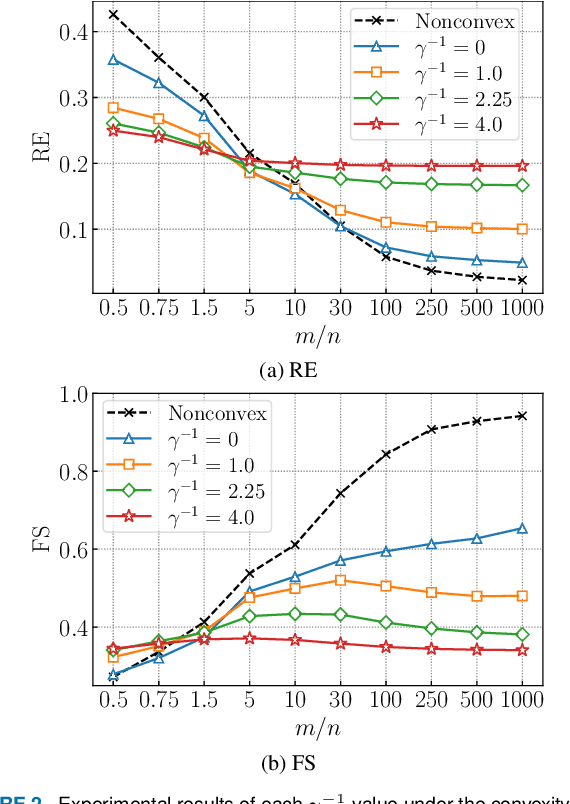
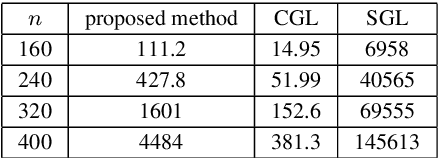
This paper presents a convex-analytic framework to learn sparse graphs from data. While our problem formulation is inspired by an extension of the graphical lasso using the so-called combinatorial graph Laplacian framework, a key difference is the use of a nonconvex alternative to the $\ell_1$ norm to attain graphs with better interpretability. Specifically, we use the weakly-convex minimax concave penalty (the difference between the $\ell_1$ norm and the Huber function) which is known to yield sparse solutions with lower estimation bias than $\ell_1$ for regression problems. In our framework, the graph Laplacian is replaced in the optimization by a linear transform of the vector corresponding to its upper triangular part. Via a reformulation relying on Moreau's decomposition, we show that overall convexity is guaranteed by introducing a quadratic function to our cost function. The problem can be solved efficiently by the primal-dual splitting method, of which the admissible conditions for provable convergence are presented. Numerical examples show that the proposed method significantly outperforms the existing graph learning methods with reasonable CPU time.
Extended Capture Point and Optimization-based Control for Quadrupedal Robot Walking on Dynamic Rigid Surfaces
Sep 10, 2021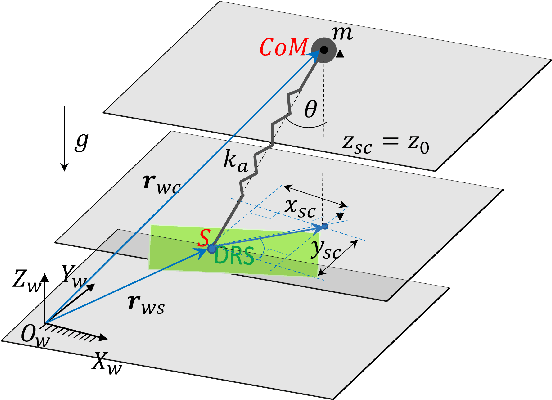
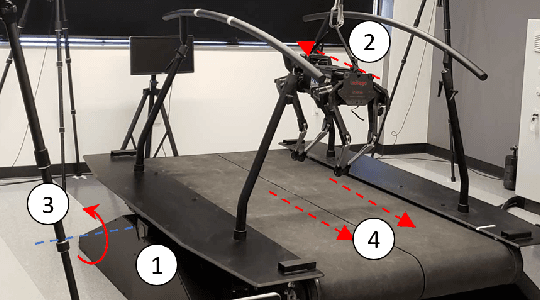
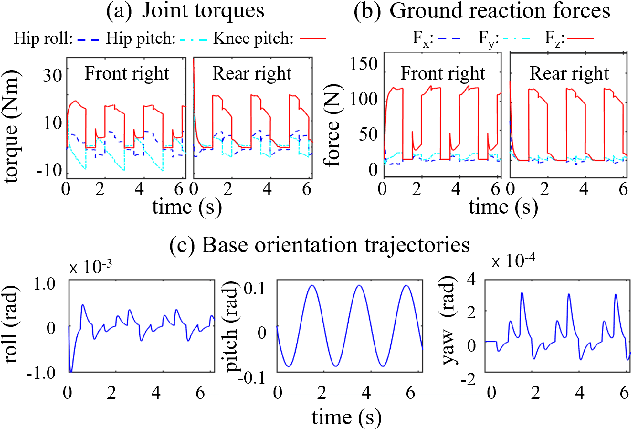
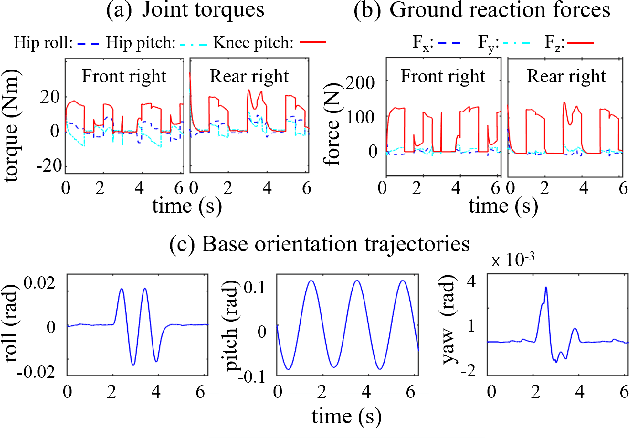
Stabilizing legged robot locomotion on a dynamic rigid surface (DRS) (i.e., rigid surface that moves in the inertial frame) is a complex planning and control problem. The complexity arises due to the hybrid nonlinear walking dynamics subject to explicitly time-varying holonomic constraints caused by the surface movement. The first main contribution of this study is the extension of the capture point from walking on a static surface to locomotion on a DRS as well as the use of the resulting capture point for online motion planning. The second main contribution is a quadratic-programming (QP) based feedback controller design that explicitly considers the DRS movement. The stability and robustness of the proposed control approach are validated through simulations of a quadrupedal robot walking on a DRS with a rocking motion. The simulation results also demonstrate the improved walking performance compared with our previous approach based on offline planning and input-output linearizing control that does not explicitly guarantee the feasibility of ground contact constraints.
Graph Learning for Cognitive Digital Twins in Manufacturing Systems
Sep 17, 2021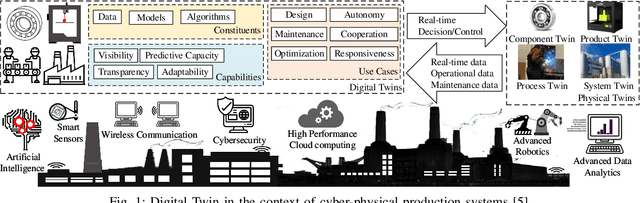
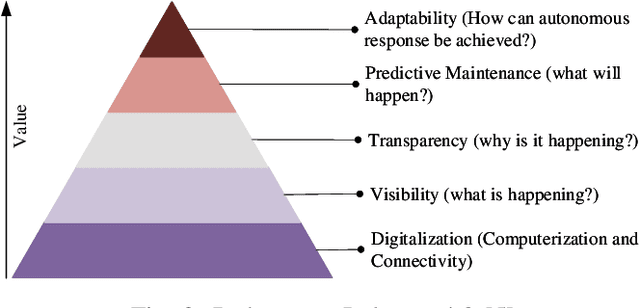
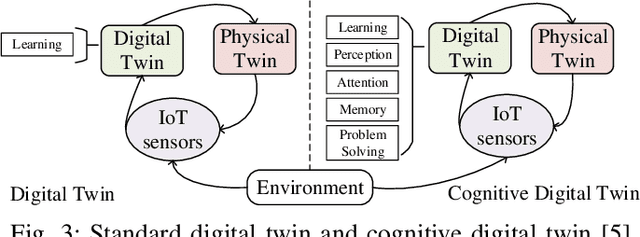

Future manufacturing requires complex systems that connect simulation platforms and virtualization with physical data from industrial processes. Digital twins incorporate a physical twin, a digital twin, and the connection between the two. Benefits of using digital twins, especially in manufacturing, are abundant as they can increase efficiency across an entire manufacturing life-cycle. The digital twin concept has become increasingly sophisticated and capable over time, enabled by rises in many technologies. In this paper, we detail the cognitive digital twin as the next stage of advancement of a digital twin that will help realize the vision of Industry 4.0. Cognitive digital twins will allow enterprises to creatively, effectively, and efficiently exploit implicit knowledge drawn from the experience of existing manufacturing systems. They also enable more autonomous decisions and control, while improving the performance across the enterprise (at scale). This paper presents graph learning as one potential pathway towards enabling cognitive functionalities in manufacturing digital twins. A novel approach to realize cognitive digital twins in the product design stage of manufacturing that utilizes graph learning is presented.
DeepSSM: A Blueprint for Image-to-Shape Deep Learning Models
Oct 14, 2021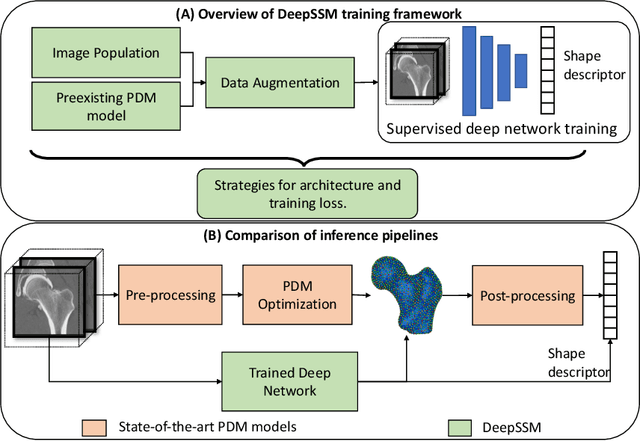

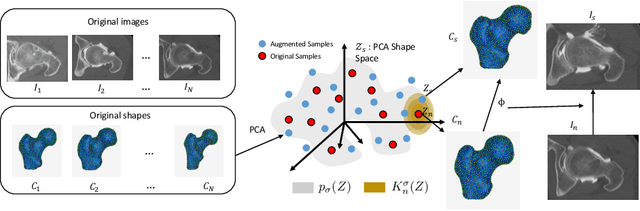
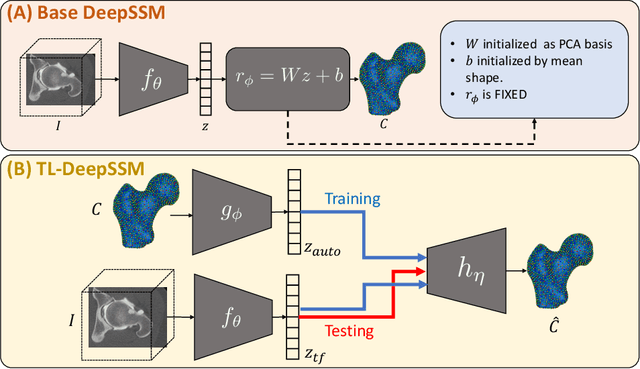
Statistical shape modeling (SSM) characterizes anatomical variations in a population of shapes generated from medical images. SSM requires consistent shape representation across samples in shape cohort. Establishing this representation entails a processing pipeline that includes anatomy segmentation, re-sampling, registration, and non-linear optimization. These shape representations are then used to extract low-dimensional shape descriptors that facilitate subsequent analyses in different applications. However, the current process of obtaining these shape descriptors from imaging data relies on human and computational resources, requiring domain expertise for segmenting anatomies of interest. Moreover, this same taxing pipeline needs to be repeated to infer shape descriptors for new image data using a pre-trained/existing shape model. Here, we propose DeepSSM, a deep learning-based framework for learning the functional mapping from images to low-dimensional shape descriptors and their associated shape representations, thereby inferring statistical representation of anatomy directly from 3D images. Once trained using an existing shape model, DeepSSM circumvents the heavy and manual pre-processing and segmentation and significantly improves the computational time, making it a viable solution for fully end-to-end SSM applications. In addition, we introduce a model-based data-augmentation strategy to address data scarcity. Finally, this paper presents and analyzes two different architectural variants of DeepSSM with different loss functions using three medical datasets and their downstream clinical application. Experiments showcase that DeepSSM performs comparably or better to the state-of-the-art SSM both quantitatively and on application-driven downstream tasks. Therefore, DeepSSM aims to provide a comprehensive blueprint for deep learning-based image-to-shape models.
Toward Communication Efficient Adaptive Gradient Method
Sep 10, 2021

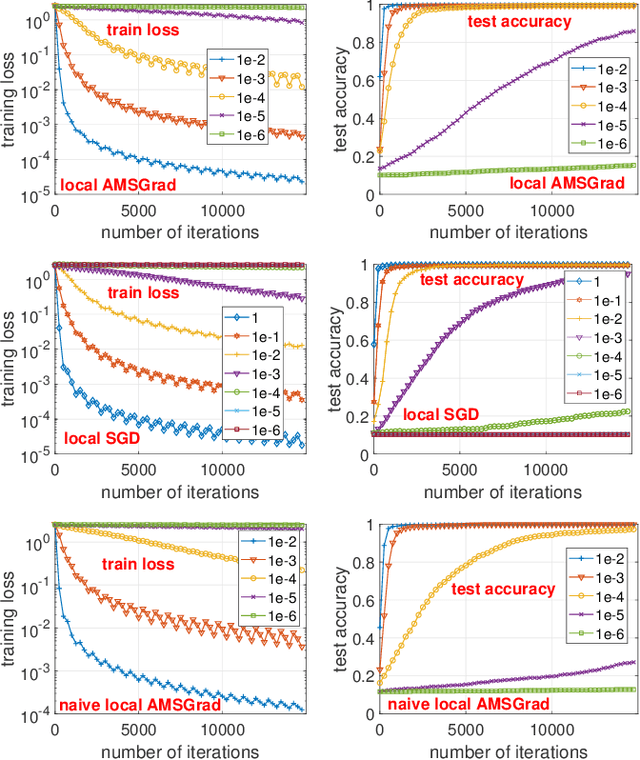

In recent years, distributed optimization is proven to be an effective approach to accelerate training of large scale machine learning models such as deep neural networks. With the increasing computation power of GPUs, the bottleneck of training speed in distributed training is gradually shifting from computation to communication. Meanwhile, in the hope of training machine learning models on mobile devices, a new distributed training paradigm called ``federated learning'' has become popular. The communication time in federated learning is especially important due to the low bandwidth of mobile devices. While various approaches to improve the communication efficiency have been proposed for federated learning, most of them are designed with SGD as the prototype training algorithm. While adaptive gradient methods have been proven effective for training neural nets, the study of adaptive gradient methods in federated learning is scarce. In this paper, we propose an adaptive gradient method that can guarantee both the convergence and the communication efficiency for federated learning.
Style Transfer based Coronary Artery Segmentation in X-ray Angiogram
Sep 03, 2021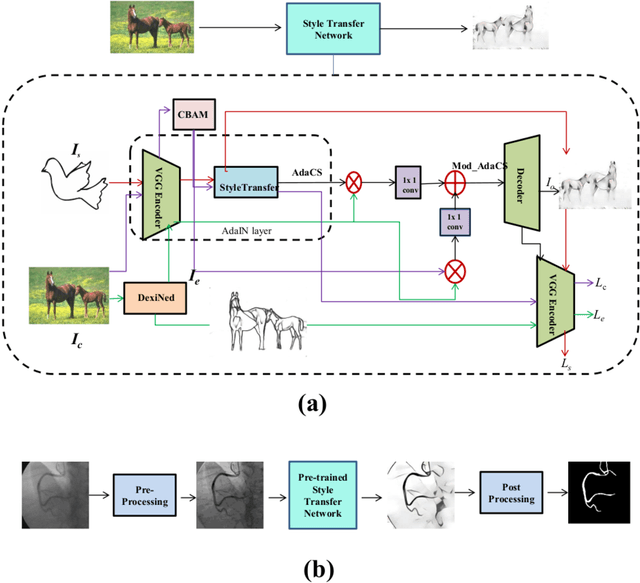

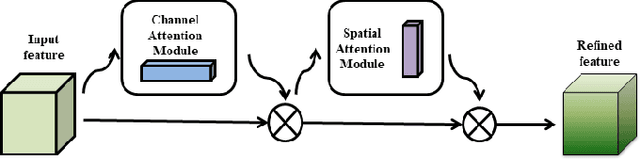
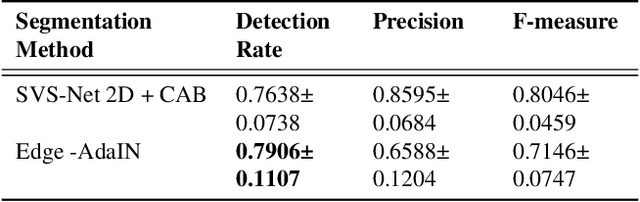
X-ray coronary angiography (XCA) is a principal approach employed for identifying coronary disorders. Deep learning-based networks have recently shown tremendous promise in the diagnosis of coronary disorder from XCA scans. A deep learning-based edge adaptive instance normalization style transfer technique for segmenting the coronary arteries, is presented in this paper. The proposed technique combines adaptive instance normalization style transfer with the dense extreme inception network and convolution block attention module to get the best artery segmentation performance. We tested the proposed method on two publicly available XCA datasets, and achieved a segmentation accuracy of 0.9658 and Dice coefficient of 0.71. We believe that the proposed method shows that the prediction can be completed in the fastest time with training on the natural images, and can be reliably used to diagnose and detect coronary disorders.
Enhancing SUMO simulator for simulation based testing and validation of autonomous vehicles
Sep 23, 2021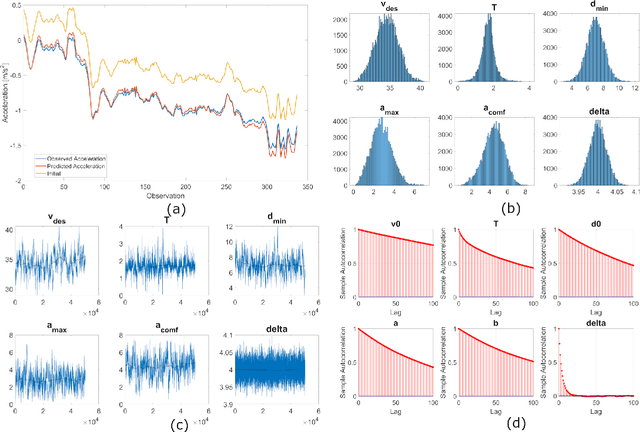
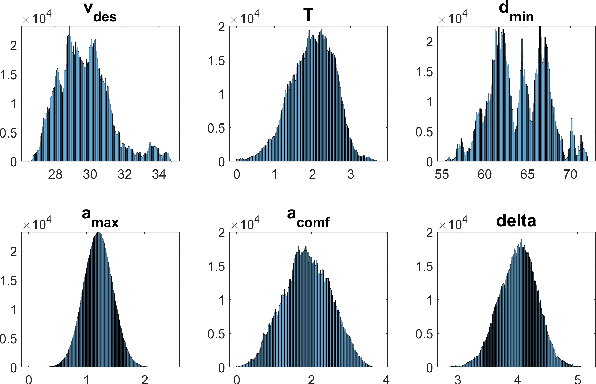
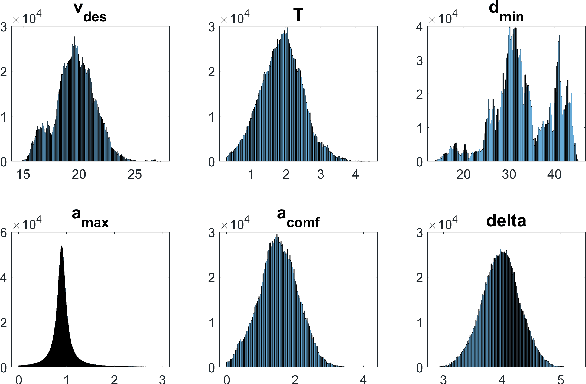
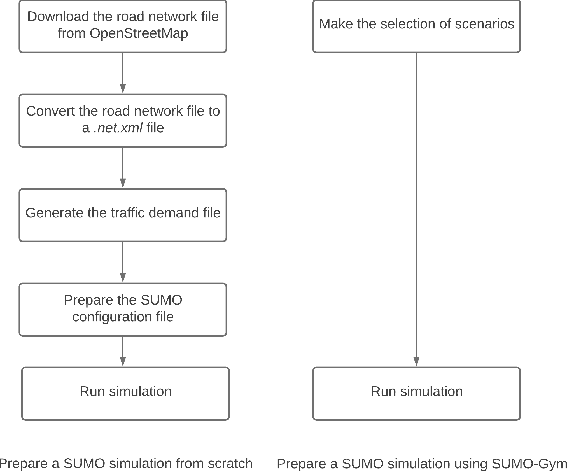
Current autonomous vehicle (AV) simulators are built to provide large-scale testing required to prove capabilities under varied conditions in controlled, repeatable fashion. However, they have certain failings including the need for user expertise and complex inconvenient tutorials for customized scenario creation. Simulation of Urban Mobility (SUMO) simulator, which has been presented as an open-source AV simulator, is used extensively but suffer from similar issues which make it difficult for entry-level practitioners to utilize the simulator without significant time investment. In that regard, we provide two enhancements to SUMO simulator geared towards massively improving user experience and providing real-life like variability for surrounding traffic. Firstly, we calibrate a car-following model, Intelligent Driver Model (IDM), for highway and urban naturalistic driving data and sample automatically from the parameter distributions to create the background vehicles. Secondly, we combine SUMO with OpenAI gym, creating a Python package which can run simulations based on real world highway and urban layouts with generic output observations and input actions that can be processed via any AV pipeline. Our aim through these enhancements is to provide an easy-to-use platform which can be readily used for AV testing and validation.
G2L-Net: Global to Local Network for Real-time 6D Pose Estimation with Embedding Vector Features
Mar 26, 2020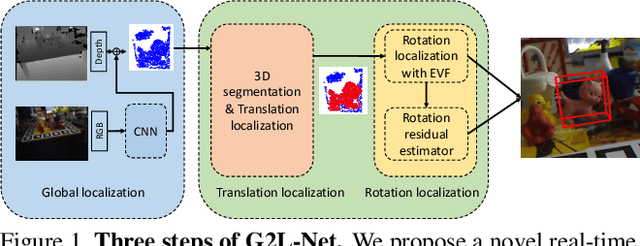
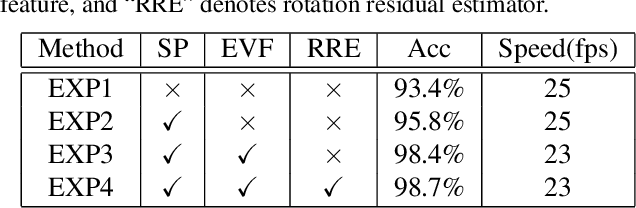
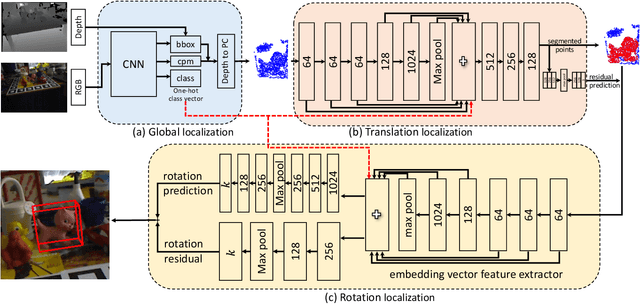
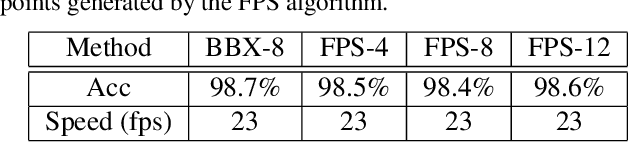
In this paper, we propose a novel real-time 6D object pose estimation framework, named G2L-Net. Our network operates on point clouds from RGB-D detection in a divide-and-conquer fashion. Specifically, our network consists of three steps. First, we extract the coarse object point cloud from the RGB-D image by 2D detection. Second, we feed the coarse object point cloud to a translation localization network to perform 3D segmentation and object translation prediction. Third, via the predicted segmentation and translation, we transfer the fine object point cloud into a local canonical coordinate, in which we train a rotation localization network to estimate initial object rotation. In the third step, we define point-wise embedding vector features to capture viewpoint-aware information. To calculate more accurate rotation, we adopt a rotation residual estimator to estimate the residual between initial rotation and ground truth, which can boost initial pose estimation performance. Our proposed G2L-Net is real-time despite the fact multiple steps are stacked via the proposed coarse-to-fine framework. Extensive experiments on two benchmark datasets show that G2L-Net achieves state-of-the-art performance in terms of both accuracy and speed.