 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning-based Noise Component Map Estimation for Image Denoising
Sep 24, 2021
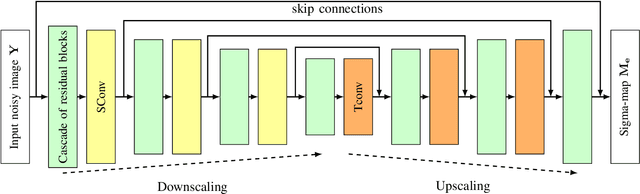
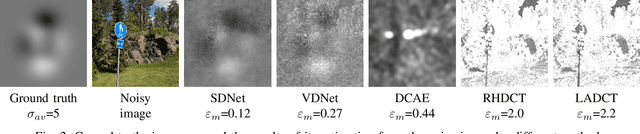
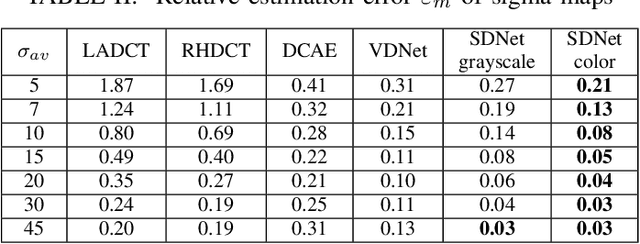
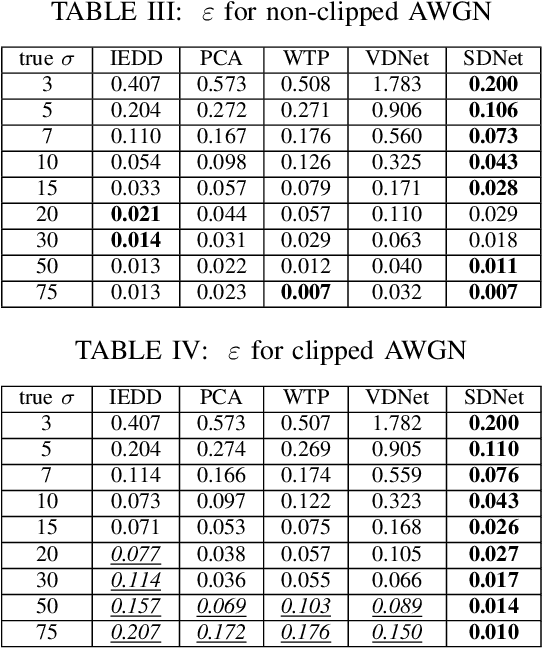
A problem of image denoising when images are corrupted by a non-stationary noise is considered in this paper. Since in practice no a priori information on noise is available, noise statistics should be pre-estimated for image denoising. In this paper, deep convolutional neural network (CNN) based method for estimation of a map of local, patch-wise, standard deviations of noise (so-called sigma-map) is proposed. It achieves the state-of-the-art performance in accuracy of estimation of sigma-map for the case of non-stationary noise, as well as estimation of noise variance for the case of additive white Gaussian noise. Extensive experiments on image denoising using estimated sigma-maps demonstrate that our method outperforms recent CNN-based blind image denoising methods by up to 6 dB in PSNR, as well as other state-of-the-art methods based on sigma-map estimation by up to 0.5 dB, providing same time better usage flexibility. Comparison with the ideal case, when denoising is applied using ground-truth sigma-map, shows that a difference of corresponding PSNR values for most of noise levels is within 0.1-0.2 dB and does not exceeds 0.6 dB.
Qualitative and Quantitative Analysis of Diversity in Cross-document Coreference Resolution Datasets
Sep 11, 2021
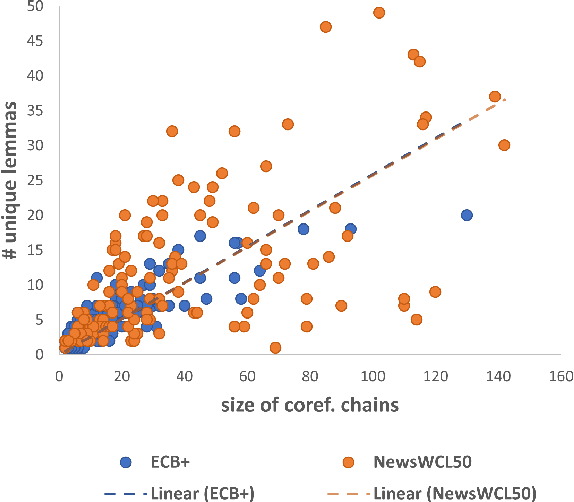
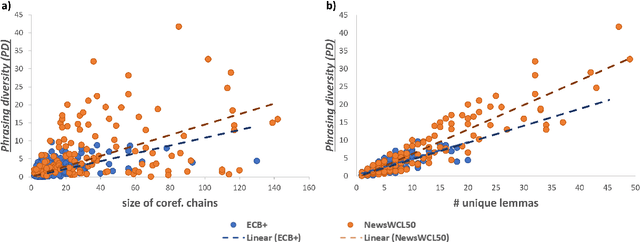
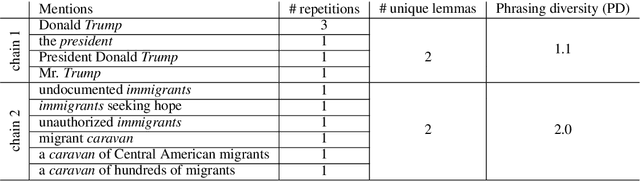
Cross-document coreference resolution (CDCR) datasets, such as ECB+, contain manually annotated event-centric mentions of events and entities that form coreference chains with identity relations. ECB+ is a state-of-the-art CDCR dataset that focuses on the resolution of events and their descriptive attributes, i.e., actors, location, and date-time. NewsWCL50 is a dataset that annotates coreference chains of both events and entities with a strong variance of word choice and more loosely-related coreference anaphora, e.g., bridging or near-identity relations. In this paper, we qualitatively and quantitatively compare annotation schemes of ECB+ and NewsWCL50 with multiple criteria. We propose a phrasing diversity metric (PD) that compares lexical diversity within coreference chains on a more detailed level than previously proposed metric, e.g., a number of unique lemmas. We discuss the different tasks that both CDCR datasets create, i.e., lexical disambiguation and lexical diversity challenges, and propose a direction for further CDCR evaluation.
Hypernetworks for Continual Semi-Supervised Learning
Oct 05, 2021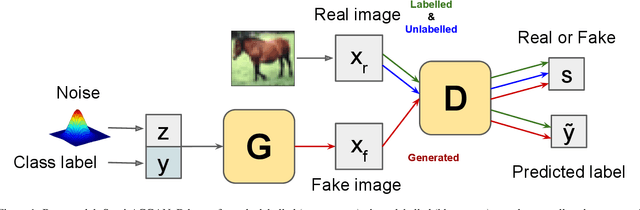


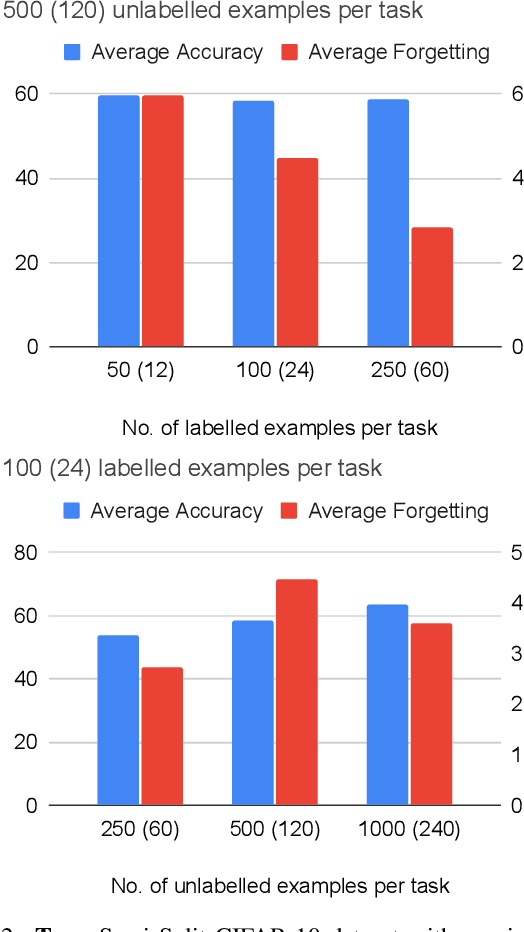
Learning from data sequentially arriving, possibly in a non i.i.d. way, with changing task distribution over time is called continual learning. Much of the work thus far in continual learning focuses on supervised learning and some recent works on unsupervised learning. In many domains, each task contains a mix of labelled (typically very few) and unlabelled (typically plenty) training examples, which necessitates a semi-supervised learning approach. To address this in a continual learning setting, we propose a framework for semi-supervised continual learning called Meta-Consolidation for Continual Semi-Supervised Learning (MCSSL). Our framework has a hypernetwork that learns the meta-distribution that generates the weights of a semi-supervised auxiliary classifier generative adversarial network $(\textit{Semi-ACGAN})$ as the base network. We consolidate the knowledge of sequential tasks in the hypernetwork, and the base network learns the semi-supervised learning task. Further, we present $\textit{Semi-Split CIFAR-10}$, a new benchmark for continual semi-supervised learning, obtained by modifying the $\textit{Split CIFAR-10}$ dataset, in which the tasks with labelled and unlabelled data arrive sequentially. Our proposed model yields significant improvements in the continual semi-supervised learning setting. We compare the performance of several existing continual learning approaches on the proposed continual semi-supervised learning benchmark of the Semi-Split CIFAR-10 dataset.
A dynamic programming algorithm for informative measurements and near-optimal path-planning
Sep 24, 2021

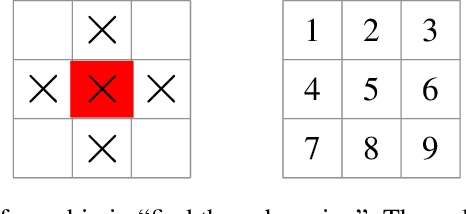
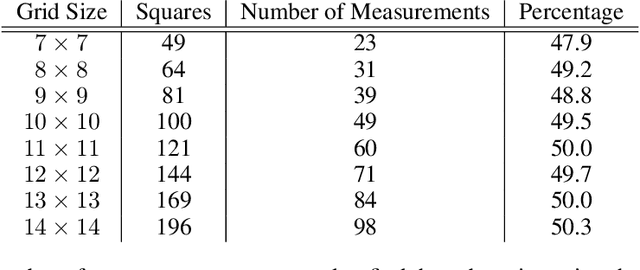
An informative measurement is the most efficient way to gain information about an unknown state. We give a first-principles derivation of a general-purpose dynamic programming algorithm that returns a sequence of informative measurements by sequentially maximizing the entropy of possible measurement outcomes. This algorithm can be used by an autonomous agent or robot to decide where best to measure next, planning a path corresponding to an optimal sequence of informative measurements. This algorithm is applicable to states and controls that are continuous or discrete, and agent dynamics that is either stochastic or deterministic; including Markov decision processes. Recent results from approximate dynamic programming and reinforcement learning, including on-line approximations such as rollout and Monte Carlo tree search, allow an agent or robot to solve the measurement task in real-time. The resulting near-optimal solutions include non-myopic paths and measurement sequences that can generally outperform, sometimes substantially, commonly-used greedy heuristics such as maximizing the entropy of each measurement outcome. This is demonstrated for a global search problem, where on-line planning with an extended local search is found to reduce the number of measurements in the search by half.
Linear Convergence of Entropy-Regularized Natural Policy Gradient with Linear Function Approximation
Jun 08, 2021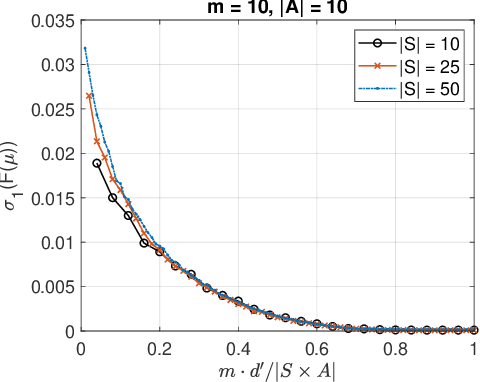
Natural policy gradient (NPG) methods with function approximation achieve impressive empirical success in reinforcement learning problems with large state-action spaces. However, theoretical understanding of their convergence behaviors remains limited in the function approximation setting. In this paper, we perform a finite-time analysis of NPG with linear function approximation and softmax parameterization, and prove for the first time that widely used entropy regularization method, which encourages exploration, leads to linear convergence rate. We adopt a Lyapunov drift analysis to prove the convergence results and explain the effectiveness of entropy regularization in improving the convergence rates.
BRIMA: low-overhead BRowser-only IMage Annotation tool (Preprint)
Jul 13, 2021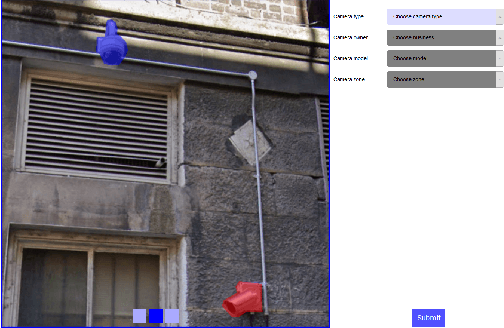

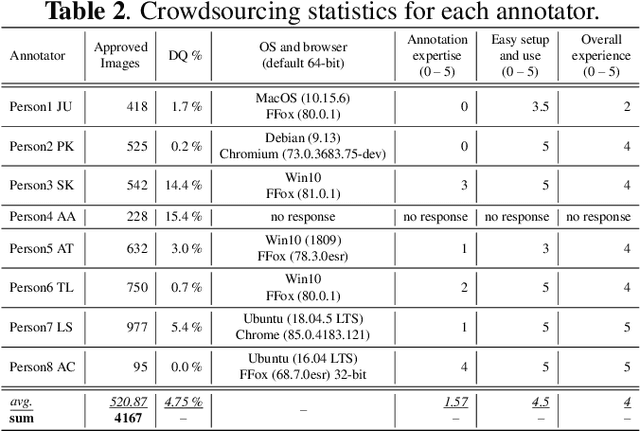
Image annotation and large annotated datasets are crucial parts within the Computer Vision and Artificial Intelligence fields.At the same time, it is well-known and acknowledged by the research community that the image annotation process is challenging, time-consuming and hard to scale. Therefore, the researchers and practitioners are always seeking ways to perform the annotations easier, faster, and at higher quality. Even though several widely used tools exist and the tools' landscape evolved considerably, most of the tools still require intricate technical setups and high levels of technical savviness from its operators and crowdsource contributors. In order to address such challenges, we develop and present BRIMA -- a flexible and open-source browser extension that allows BRowser-only IMage Annotation at considerably lower overheads. Once added to the browser, it instantly allows the user to annotate images easily and efficiently directly from the browser without any installation or setup on the client-side. It also features cross-browser and cross-platform functionality thus presenting itself as a neat tool for researchers within the Computer Vision, Artificial Intelligence, and privacy-related fields.
Linear-Time Inference for Pairwise Comparisons with Gaussian-Process Dynamics
Mar 18, 2019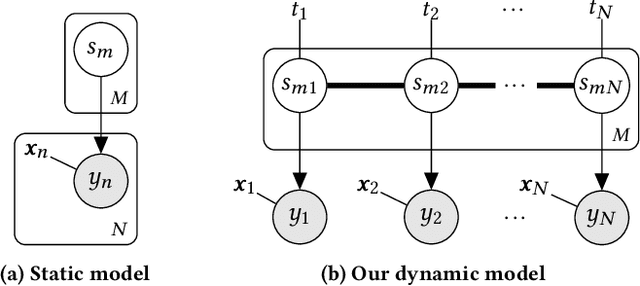
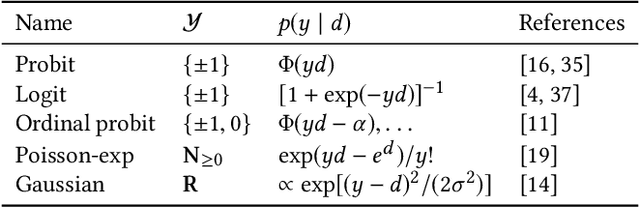

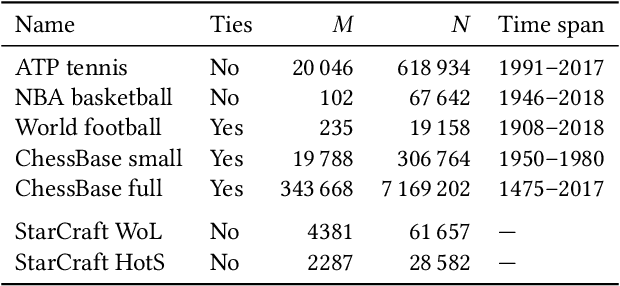
We present a probabilistic model of pairwise-comparison outcomes that can encode variations over time. To this end, we replace the real-valued parameters of a class of generalized linear comparison models by function-valued stochastic processes. In particular, we use Gaussian processes; their kernel function can express time dynamics in a flexible way. We give an algorithm that performs approximate Bayesian inference in linear time. We test our model on several sports datasets, and we find that our approach performs favorably in terms of predictive performance. Additionally, our method can be used to visualize the data effectively.
Infer Implicit Contexts in Real-time Online-to-Offline Recommendation
Jul 08, 2019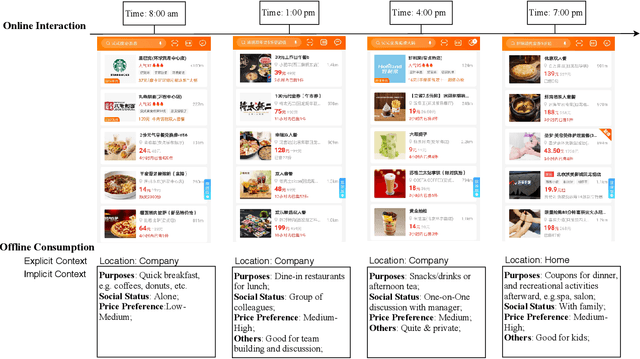
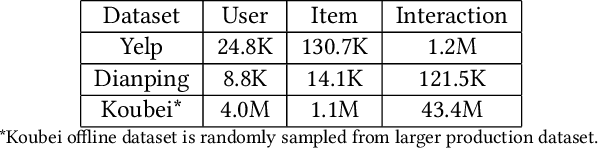
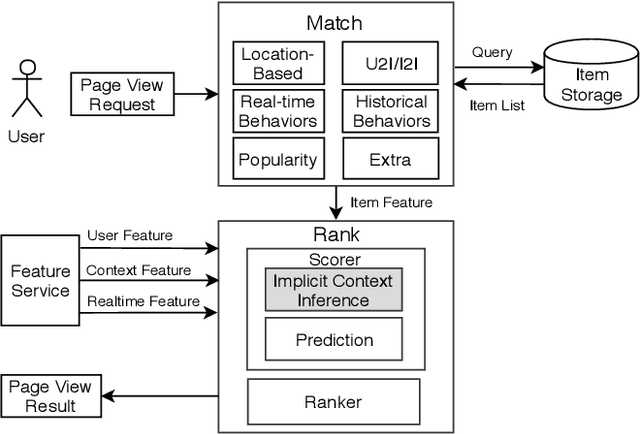
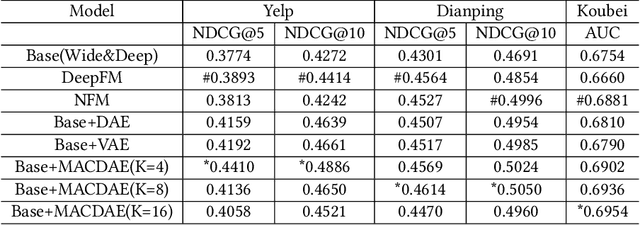
Understanding users' context is essential for successful recommendations, especially for Online-to-Offline (O2O) recommendation, such as Yelp, Groupon, and Koubei. Different from traditional recommendation where individual preference is mostly static, O2O recommendation should be dynamic to capture variation of users' purposes across time and location. However, precisely inferring users' real-time contexts information, especially those implicit ones, is extremely difficult, and it is a central challenge for O2O recommendation. In this paper, we propose a new approach, called Mixture Attentional Constrained Denoise AutoEncoder (MACDAE), to infer implicit contexts and consequently, to improve the quality of real-time O2O recommendation. In MACDAE, we first leverage the interaction among users, items, and explicit contexts to infer users' implicit contexts, then combine the learned implicit-context representation into an end-to-end model to make the recommendation. MACDAE works quite well in the real system. We conducted both offline and online evaluations of the proposed approach. Experiments on several real-world datasets (Yelp, Dianping, and Koubei) show our approach could achieve significant improvements over state-of-the-arts. Furthermore, online A/B test suggests a 2.9% increase for click-through rate and 5.6% improvement for conversion rate in real-world traffic. Our model has been deployed in the product of "Guess You Like" recommendation in Koubei.
Compressing Deep ODE-Nets using Basis Function Expansions
Jun 21, 2021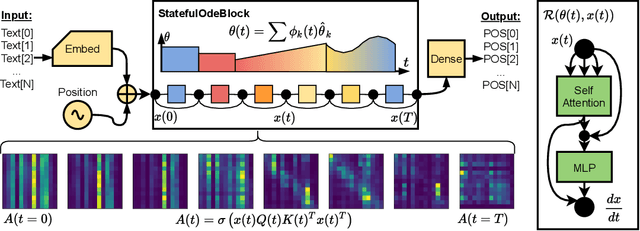

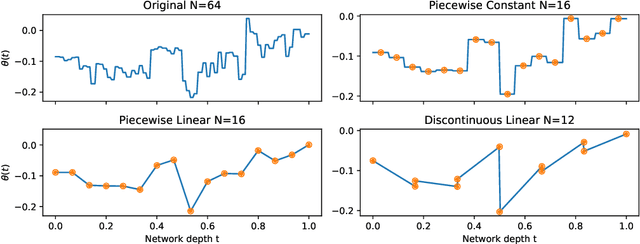
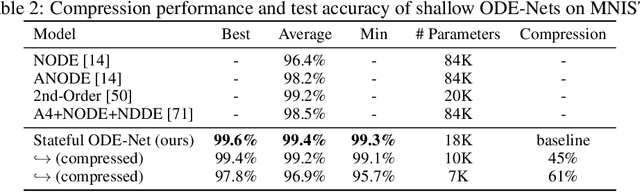
The recently-introduced class of ordinary differential equation networks (ODE-Nets) establishes a fruitful connection between deep learning and dynamical systems. In this work, we reconsider formulations of the weights as continuous-depth functions using linear combinations of basis functions. This perspective allows us to compress the weights through a change of basis, without retraining, while maintaining near state-of-the-art performance. In turn, both inference time and the memory footprint are reduced, enabling quick and rigorous adaptation between computational environments. Furthermore, our framework enables meaningful continuous-in-time batch normalization layers using function projections. The performance of basis function compression is demonstrated by applying continuous-depth models to (a) image classification tasks using convolutional units and (b) sentence-tagging tasks using transformer encoder units.
Online Robust Reinforcement Learning with Model Uncertainty
Sep 29, 2021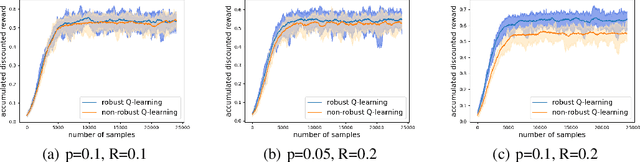
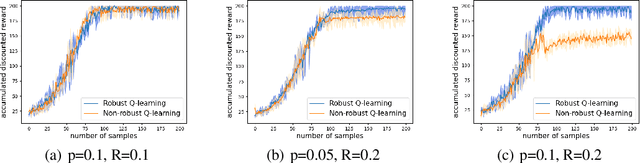
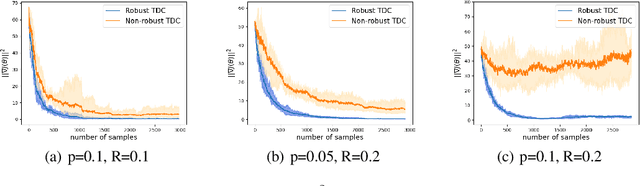
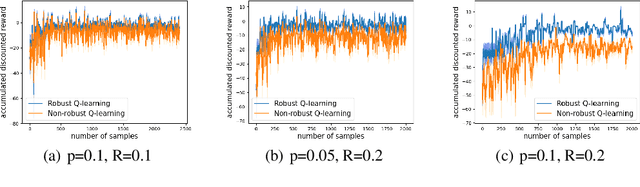
Robust reinforcement learning (RL) is to find a policy that optimizes the worst-case performance over an uncertainty set of MDPs. In this paper, we focus on model-free robust RL, where the uncertainty set is defined to be centering at a misspecified MDP that generates a single sample trajectory sequentially and is assumed to be unknown. We develop a sample-based approach to estimate the unknown uncertainty set and design a robust Q-learning algorithm (tabular case) and robust TDC algorithm (function approximation setting), which can be implemented in an online and incremental fashion. For the robust Q-learning algorithm, we prove that it converges to the optimal robust Q function, and for the robust TDC algorithm, we prove that it converges asymptotically to some stationary points. Unlike the results in [Roy et al., 2017], our algorithms do not need any additional conditions on the discount factor to guarantee the convergence. We further characterize the finite-time error bounds of the two algorithms and show that both the robust Q-learning and robust TDC algorithms converge as fast as their vanilla counterparts(within a constant factor). Our numerical experiments further demonstrate the robustness of our algorithms. Our approach can be readily extended to robustify many other algorithms, e.g., TD, SARSA, and other GTD algorithms.